
{kind=link}
{kind=link}
{kind=link}
熟驴肉掺假近红外定性及定量检测
[牛晓颖1, 2, 3  , 牟晓晴
, 牟晓晴1, 2, 3 , 孙杰1, 2, 3 , 赵志磊1, 2, 3, * , 张春江4 ]
, 牟晓晴, 张春江|
|


作者简介: 牛晓颖,女, 1980年生,河北大学质量技术监督学院副教授 e-mail: xiaoyingniu@126.com
驴肉风味绝佳、 营养丰富, 价格高昂且供应量低。 驴肉火烧等熟驴肉中掺假马肉、 骡子肉等其他肉类的问题亟待解决。 为实现熟驴肉样品在不同掺假比例下的定性定量分析, 以10%为梯度, 分别制备驴肉含量为0%~100%的驴马掺假和驴骡掺假样品, 并在4 000~12 500 cm-1光谱范围采集样品光谱。 针对熟驴肉掺假问题, 采用线性判别分析、 支持向量机以及广义回归神经网络的方法结合平滑算法(5点、 15点、 25点)、 多元散射校正(MSC)、 标准正态变量变换(SNV)、 基线校正(Baseline)、 归一化和去趋势化(Detrend)等预处理方法建立了近红外鉴别模型。 采用偏最小二乘回归(PLSR)、 反向传播神经网络(BP)方法结合以上预处理方法分别对熟驴肉掺假样品建立定量模型检测驴肉含量。 SNV预处理结合支持向量机对熟肉碎掺假样品鉴别模型结果较优, 校正集和预测集判别正确率为98.70%和94.78%; Detrend预处理结合线性判别分析的熟肉糜掺假样品鉴别模型结果较优, 校正集和预测集的判别正确率分别达到98.47%和96.23%。 建立定量模型进行掺假样品中驴肉含量的检测, BP模型相较于PLSR模型均取得较好的结果, 具有较高的决定系数( R2)、 相对分析误差(RPD)和较低的均方根误差(RMSE)。 对于熟肉碎掺假样品, 驴骡掺假样品集在Detrend处理后的BP模型结果较好, 交叉验证集以及预测集的 R2、 RMSE、 RPD分别为0.971、 0.067、 5.844, 0.980、 0.086、 6.984; 驴马掺假样品集在归一化预处理后BP模型结果较好, 各项参数分别为0.997、 0.032、 18.026, 0.982、 0.089、 7.454。 对于熟肉糜掺假样品, 经Detrend预处理的BP模型结果均较优, 驴骡掺假样品最佳定量模型的参数分别为0.982、 0.041、 7.470, 0.986、 0.103、 8.452; 驴马掺假最佳模型参数分别为0.986、 0.036、 8.348, 0.961、 0.101、 5.044。 结果表明, 近红外光谱结合不同的建模算法实现了不同比例掺假的熟驴肉样品快速无损检测和鉴别, 能够用于此后熟驴肉掺假的定性、 定量分析。
Donkey meat has excellent flavor and rich nutrition and is in high price and low supply. The problem of cooked donkey meat adulterated with other meat, such as horse and mule meat, needs to be solved urgently. To realize the qualitative and quantitative analysis of cooked donkey meat samples of different adulteration ratios, horse and mule meat samples were used to degrade donkey meat. The gradient was 10%, and the donkey meat contents were 0%~100%. Spectra of samples were collected in the range of 4 000~12 500 cm-1. The methods of linear discriminant analysis, support vector machine, and generalized regression neural network combined with smoothing algorithm (5 points, 15 points, 25 points), multiplicative scattering correction (MSC), standard normal variable (SNV), Baseline correction, normalization, and Detrend were used to establish the NIR discriminant models of adulterated cooked donkey meat samples. Partial least squares regression (PLSR) and backpropagation (BP) were used to establish quantitative models to determine the content of donkey meat in adulterated samples. For minced after cooked meat samples, the results of SNV pretreatment combined with a support vector machine were optimal, and the discriminant accuracy of the calibration set and prediction set was 98.70% and 94.78%. The results of Detrend pretreatment combined with linear discriminant analysis were optimal for minced before cooked meat samples. The discriminant accuracy of the calibration and prediction sets reached 98.47% and 96.23%, respectively. Compared with the PLSR model, the BP model obtained better results, with a higher coefficient of determination ( R2), relative percent deviation (RPD), and lower root mean square error (RMSE). For the adulterated samples of minced after cooked meat samples, the BP model of the donkey and mule adulterated samples was better after Detrend pretreatment. R2, RMSE, and RPD of the cross-validation set and prediction set were 0.971, 0.067, 5.844, 0.980, 0.086, 6.984, respectively. After normalized treatment, the results of BP model of donkey and horse adulterated samples were optimal, and the parameters were 0.997, 0.032, 18.026, 0.982, 0.089, 7.454, respectively. For the adulterated samples of minced before cooked meat samples, the results of the BP model with Detrend pretreatment were better, and the optimal quantitative model parameters of donkey and mule adulterated samples were 0.982, 0.041, 7.470, 0.986, 0.103, 8.452, respectively. The best model parameters of donkey and horse adulteration were 0.986, 0.036, 8.348, 0.961, 0.101, and 5.044, respectively. The results show that the NIR spectroscopy combined with different modeling algorithms can realize the rapid, nondestructive detection of different donkey meat contents. The methodology can be used for future qualitative and quantitative analysis of cooked donkey meat adulteration.
驴肉营养价值较高, 具有高蛋白、 低脂肪、 低胆固醇的优点[1], 且风味绝佳。 但是驴肉产出效率低下、 供求错位。 马肉和骡子肉外表性状与驴肉较为相似, 同时价格较驴肉低, 因此常被不法商贩掺入驴肉, 导致驴肉火烧等熟驴肉产品掺假售假的问题层出不穷, 严重损害了消费者权益甚至威胁身体健康, 不利于市场公正。 因此亟需研究一种能够鉴别熟制后的驴肉和马肉、 骡子肉, 检测驴肉掺假情况的方法。
为解决肉类掺假[2, 3]以及质量问题[4], 近年来使用的检测方法有聚合酶链式反应(polymerase chain reaction, PCR)技术[5, 6]、 电子鼻检测技术[7, 8, 9, 10]、 液相色谱串联质谱法[11, 12, 13]、 多光谱成像技术[14]等, 但是PCR技术存在成本高、 操作复杂以及破坏肉类样品的缺点[15], 电子鼻技术虽然操作方便, 但价格高昂、 检测效率低[16], 液相色谱串联质谱结构复杂且多光谱成像技术维护成本较高, 均不适合大规模的熟驴肉实时掺假辨别。 近红外光谱技术具有快速、 无损、 环保、 易操作等优点, 非常适合市场监督。 近年来, 国内外研究人员使用近红外光谱对生肉样品的定性及定量鉴别的研究较多, 包括对牛肉[17]和猪肉[18]注水肉的研究, 对生鲜肉质量检测以及脂肪含量等的研究[19, 20], 以及对猪肉[21]、 羊肉[22, 23]、 鸭肉[24]、 牛肉[25, 26, 27]、 鸡肉[28]等生鲜肉及其加工制品[29, 30]掺假的研究较多, 但对熟驴肉样品的近红外掺假定性以及定量鉴别的研究报道较少。
基于以上情况, 本工作采用了近红外光谱分析技术对纯驴肉、 马肉、 骡子肉、 驴马掺假和驴骡掺假熟肉样品进行了定性定量分析。 首先结合不同的预处理方法比较了熟肉碎以及熟肉糜样品的线性判别分析、 支持向量机以及神经网络定性鉴别模型的结果, 然后使用偏最小二乘法和反向传播神经网络算法, 结合不同预处理方法, 建立并优化了掺假样品驴肉含量的定量模型。
驴肉、 骡子肉、 马肉生鲜肉样品, 均购自河北省张家口市某屠宰场; MPA近红外光谱仪、 OPUS 6.5, 德国Bruker公司; 绞肉机(MGH-090), 中国名健有限公司; 数显恒温水浴锅(HH-6), 中国杰瑞尔电器有限公司; 红外测温仪(MT4 MAX), 美国Fluke公司。
1.2.1 材料制备
驴肉、 骡子肉以及马肉的生鲜肉样品在当天取得后运至实验室保存于0~4 ℃的恒温保鲜箱。 将样品剔除脂肪和筋膜, 切割成肉块, 使用3 mm板孔的绞肉机将样品绞成肉糜, 精确称取50 g放入蒸煮袋于水浴锅80~85 ℃蒸煮30 min, 冷却至室温后获得熟肉糜样品, 放入直径为5 cm的圆柱形石英皿并压实, 以进行驴肉、 骡子肉以及马肉熟肉糜样品近红外光谱的采集。 将生肉块样品放入蒸煮袋于水浴锅80~85 ℃蒸煮30 min, 冷却至室温后切碎成3~5 mm见方小块, 精准称取50 g熟肉碎样品, 随后放入石英皿并压实, 以进行驴肉、 骡子肉以及马肉熟肉碎样品近红外光谱的采集。 分别使用马肉、 骡子肉的熟肉糜和熟肉碎样品, 以10%为梯度, 制备0%~100%的驴马掺假和驴骡掺假样品, 分别获得熟肉糜和熟肉碎状态的纯肉及掺假样品617和1 035个。
1.2.2 光谱采集和建模方法、 软件
样品近红外漫反射光谱采集参数如下: 以MPA近红外光谱仪自带金背景为背景光谱, 检测器为PbS , 波段范围4 000~12 500 cm-1, 分辨率2 cm-1。 采集石英皿内样品的不同3个点的光谱, 计算其平均光谱用作后续分析。 使用The Unscrambler X软件(挪威CAMO公司)和MatlabR2016b软件(美国Math Works公司), 对样品集建立并优化线性判别分析(linear discriminant analysis, LDA)、 支持向量机(support vector machine, SVM)以及广义回归神经网络(generalized regression neural network, GRNN)模型。 对熟肉碎以及熟肉糜样品集进行了定性鉴别分析, 并使用偏最小二乘回归(partial least squares regression, PLSR)、 反向传播神经网络(back propagation, BP)模型对样品中的驴肉含量进行了定量检测。 若模型具有较高的决定系数(R2)和相对分析误差(relative percent deviation, RPD), 以及较低的均方根误差(root mean square error, RMSE), 则认为结果较佳。
图1(a)、 (b)分别为熟肉碎和熟肉糜掺假样品和纯肉样品的平均光谱图, 掺假样品光谱的各吸收峰和轮廓均和纯肉样品非常相似且重叠在一起, 因此需要进行建模分析。
 | 图1 掺假样品和纯肉样品的近红外平均光谱 (a): 熟肉碎; (b): 熟肉糜Fig.1 NIR mean spectra of adulterated and pure meat samples of minced after cooked meat (a): Cooked chopped; (b): Cooked miced |
按照大约3∶1的比例随机划分出校正集和预测集以进行定性鉴别分析, 见表1。
| 表1 熟肉掺假样品定性分析的校正集与预测集 Table 1 Calibration sets and prediction sets for qualitative analysis of adulterated cooked meat samples |
使用LDA、 SVM、 GRNN三种有监督模式识别算法分别对熟肉碎、 熟肉糜样品集建立并优化了近红外光谱鉴别模型; 其中LDA包括LDA-Linear、 LDA-Quadratic、 LDA-Mahalanobis三种方法; SVM选用的是支持向量分类算法(C-SVM for classfication, C-SVC), 当惩罚参数C越大时, 表示对误差越不能容忍[31], 核函数类型为Linear, 惩罚参数C选择默认值为1。 LDA以及GRNN两种算法均选取光谱的前20个主成分得分作为输入变量, 使用平滑(5点、 15点及25点)、 平滑一阶导、 多元散射校正(multiplicative scatter correction, MSC)、 标准正态变量变换(standard normal variate, SNV)、 归一化(normalization)、 基线校正(baseline)和去趋势算法(detrend)对模型进行预处理, 这些方法均为近红外模型优化中常用的预处理方法[32], 比较不同预处理方法对建模结果的影响, 结果如表2所示。
| 表2 不同类型熟肉掺假样品集的定性预测结果 Table 2 Qualitative prediction results of different types of cooked meat adulteration sample sets |
表2展示了不同算法结合预处理建立模型的较优结果。 对于熟肉碎掺假样品, SNV预处理后的SVM模型相较于其他模型取得较好结果, 校正集和预测集的准确率分别为98.70%、 94.78%, 预测集样品共误判14个, 其中, 5个驴骡掺假样品被误判成驴马掺假样品, 8个驴肉样品被误判为6个马肉样品以及2个驴马掺假样品, 1个马肉样品被误判为驴马掺假样品, LDA三种方法的预测效果次之, GRNN方法虽然校正集正确率较高, 但对于熟肉碎样品集的预测性能较差; 对于熟肉糜掺假样品, LDA的三种方法均有较好的预测结果, 主成分为16的时候, Detrend预处理后的LDA-Linear模型预测效果较好, 校正集和预测集的准确率达到了98.47%和96.23%, 预测集的6个驴骡掺假样品被误判为5个驴马掺假和1个驴肉样品, 其他样品0误判。 综合这两类掺假样品的预测结果可见, 驴骡掺假和驴马掺假样品之间的误判率较高, 且熟肉糜掺假的预测结果相较于熟肉碎掺假准确度高, 这可能与熟肉糜掺假样品更加均匀有关。
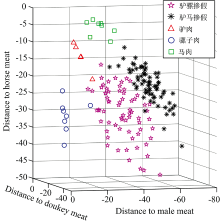
图2所示为熟肉糜掺假样品的距离三维图, 如图可以看出, 驴骡掺假、 驴马掺假、 驴肉、 骡子肉、 马肉样品通过建立定性模型能明显区分开, 驴肉、 马肉和骡子肉与其他样品基本没有重叠, 驴骡掺假与驴马掺假样品的距离较近, 有些许重叠现象, 说明两种样品特征较为相似, 从而造成了误判。
 | 图2 熟肉糜掺假样品的LDA-Linear三维距离图Fig.2 3-dimension distance plot of minced cooked adulterated meat samples using LDA-linear |
为分析掺假样品中驴肉的含量, 建立并优化了定量模型。 在建立定量模型之前, 按照大约2∶1的比例随机选取校正集和预测集如表3所示。 建立了PLSR和BP定量检测模型, 并比较了不同预处理方法对熟肉碎以及熟肉糜掺假定量模型预测结果的影响。
| 表3 不同类型熟肉掺假样品定量分析的校正集与预测集 Table 3 Calibration sets and prediction sets for quantitative analysis of adulterated samples of different types of cooked meat |
2.3.1 PLSR定量模型
选取前20个潜在变量数对样品的光谱数据进行降维, 结合交叉验证对熟肉碎以及熟肉糜性状的驴骡掺假和驴马掺假样品集建立PLSR定量检测模型, 比较不同预处理对建模结果的影响, 结果如表4、 表5所示。
| 表4 熟肉碎样品集的PLSR定量检测结果 Table 4 PLSR quantitative analysis for chopped and cooked meat samples |
| 表5 熟肉糜样品集的PLSR定量检测结果 Table 5 PLSR quantitative analysis for minced and cooked meat samples |
表4为熟肉碎掺假样品PLSR定量检测模型的结果。 驴骡掺假的检测中, 各种预处理后的模型校正集、 交叉验证集的预测精度相较于原始光谱均得到提升, 其中15点平滑后的模型结果最佳。 对于驴马掺假的检测, 经15点平滑预处理后预测集的精度略有提升, 同时校正集的过拟合现象有所缓解, 模型稳定性得到增强。
表5所示为熟肉糜掺假的PLSR定量检测结果。 驴骡掺假样品集原始光谱的检测结果较优, 经过平滑处理之后校正集和预测集的精度均降低, 其余大部分预处理之后交叉验证集精度提高, 但是预测精度降低, 模型性能减弱。 驴马掺假样品集在经过SNV、 Detrend、 Baseline预处理之后预测集和交叉验证集的结果相较于原始光谱的精度得到提升, 模型的稳定性提高。
2.3.2 BP定量模型
通过建立BP模型对熟肉碎、 熟肉糜样品集的驴肉、 骡子肉、 马肉以及掺假样品进行定量检测, 以确定驴骡、 驴马两种掺假样品集中驴肉的含量。 使用经过PLS降维后提取出的潜在变量作为熟肉碎和熟肉糜输入变量, 熟肉碎、 熟肉糜的驴骡掺假前10个潜在变量得分的方差累积百分比达到95.44%, 98.64%; 驴马掺假在前15个潜在变量得分的累计百分比为98.75%, 98.71%, 因此, 分别选取前10个和前15个潜在变量得分进行PLSR降维, 结合交叉验证建立BP定量检测模型, 设置训练参数如下: 训练次数为1 000, 学习速率为0.001, 训练目标最小误差为0.001, 训练方法选择莱文贝格-马夸特方法(Levenberg-Marquardt algorithm)。 分别选取前10个、 前15个潜在变量作为驴骡掺假和驴马掺假的BP模型输入, 输入层节点数按照输入变量个数分别设置为10、 15, 输出层节点数为1, 将隐含层节点数设置为5, 即拓扑结构分别为10-5-1, 15-5-1, 比较不同预处理对BP模型的结果影响。 结果如表6、 表7所示。
| 表6 熟肉碎样品集的BP定量检测结果 Table 6 BP quantitative analysis for chopped and cooked meat samples |
| 表7 熟肉糜样品集的BP定量检测结果 Table 7 BP quantitative analysis for minced and cooked meat samples |
表6为熟肉碎驴骡、 驴马掺假样品集的BP定量检测结果, 驴骡掺假样品集在经过5点、 15点、 25点平滑、 平滑一阶导、 MSC、 SNV、 Detrend以及归一化预处理之后均提高了模型的预测精度, 其中Detrend预处理之后较优, 交叉验证集以及预测集的R2、 RMSE、 RPD分别为0.971、 0.067、 5.844, 0.980、 0.086、 6.984, 模型的精度得到提升, 校正集的过拟合现象得到缓解, 模型稳定性提高。 驴马掺假样品集分别在经过MSC、 SNV、 Detrend、 Baseline以及归一化处理之后交叉验证集和预测集的精度均有所提升, 其中归一化处理后交叉验证集以及预测集的R2、 RMSE、 RPD分别为0.997、 0.032、 18.026, 0.982、 0.089、 7.454, 取得较优结果。
熟肉糜样品集的BP模型检测结果如表7可知, 驴骡掺假样品的原始光谱在经过15点平滑、 Detrend、 Baseline、 SNV处理后, 预测集的精度得到提升, 且模型稳定性略有增强, 其中Detrend预处理后模型的结果较佳, 交叉验证集和预测集的R2、 RMSE、 RPD分别为0.982、 0.041、 7.470, 0.986、 0.103、 8.452。 驴马掺假样品的原始光谱在经Detrend、 Baseline以及归一化处理后, 模型的预测精度得到了提高, 其中, Detrend预处理后的效果较佳, 交叉验证集和预测集的R2、 RMSE、 RPD分别为0.986、 0.036、 8.348, 0.961、 0.101、 5.044。
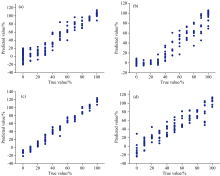
对比以上结果可见, 驴骡掺假样品集的PLSR检测结果均高于驴马掺假样品集, 且对比PLSR模型和BP模型结果由表8可见, BP模型对于不同掺假样品集的检测精度均得到了提高。 BP模型取得的较佳预测结果如图3所示, 驴骡掺假和驴马掺假样品集的预测值和真实值相关性均较高, 呈线性分布, 其中, 熟肉碎两种样品集的预测集误差均小于熟肉糜样品集, 同时校正集和预测集参数更接近, 模型稳定性更好。 这可能与样品的粉碎程度有关。
| 表8 掺假样品集的PLSR和BP定量预测结果 Table 8 Quantitative prediction results of adulterated sample sets using PLSR and BP |
 | 图3 BP定量预测结果 (a): 驴骡掺假熟肉碎; (b): 驴马掺假熟肉碎; (c): 驴骡掺假熟肉糜; (d): 驴马掺假熟肉糜Fig.3 BP quantitative results (a): Chopped and cooked donkey meat adulterated with mule; (b): Chopped and cooked donkey meat adulterated with horse; (c): Minced and cooked donkey meat adulterated with mule; (d): Miced and cooked donkey meat adulterated with horse |
建立并优化了驴肉熟肉碎、 熟肉糜掺假的定性鉴别以及定量检测模型。
对于熟驴肉掺假的定性鉴别, SNV预处理结合SVM方法的熟肉碎掺假样品鉴别模型结果较优, 校正集和预测集判别正确率为98.70%和94.78%; Detrend预处理结合LDA方法的熟肉糜掺假样品鉴别模型结果较优, 校正集和预测集的判别正确率分别为98.47%和96.23%。 建立定量模型对掺假样品中的驴肉含量进行进一步检测, 对比PLSR模型, BP模型均取得较优结果, 对于熟肉碎掺假样品, 驴骡掺假样品集在Detrend处理后的BP模型结果较好, 交叉验证集以及预测集的R2、 RMSE、 RPD分别为0.971、 0.067、 5.844, 0.980、 0.086、 6.984; 驴马掺假样品集在归一化预处理后BP模型结果较好, 各项参数分别为0.997、 0.032、 18.026, 0.982、 0.089、 7.454。 对于熟肉糜掺假样品, 经Detrend预处理的BP模型结果均较优, 驴骡掺假样品最佳定量模型的参数分别为0.982、 0.041、 7.470, 0.986、 0.103、 8.452; 驴马掺假最佳模型参数分别为0.986、 0.036、 8.348, 0.961、 0.101、 5.044。
研究结果表明, 基于近红外光谱技术对熟驴肉掺假的定性定量检测和鉴别是可行的, 建立的SVM模型和LDA模型较好, 分别适用于熟肉碎以及熟肉糜掺假样品的定性分类鉴别; 对于驴肉含量的定量检测, BP模型相较于PLSR模型检测结果较优, 更适用于掺假样品中驴肉含量的定量检测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|