

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三维荧光光谱的原酒品质评价模型建立
[孙雍荣1, 2  , 权志熙
, 权志熙1, 2 , 丁林志1, 2 , 冯守帅1, 2 , 龙凌凤1, 2 , 杨海麟1, 2, * ]
, 权志熙]
|
|


作者简介: 孙雍荣, 女, 1996年生, 江南大学生物工程学院与工业生物技术教育部重点实验室硕士研究生 e-mail: 6210208050@stu.jiangnan.edu.cn
酒厂的生产主要采用传统的“看花摘酒”工艺, 依靠工人的主观经验进行评价。 实际生产中受到诸多因素的影响, 导致接酒过程的不确定性, 原酒品质的稳定性难以得到保证。 通过采集原酒样本并配制掺加不同浓度酒尾(0.0%~2.0%)的复合原酒, 进行荧光扫描得到三维荧光光谱, 建立物质变化与荧光数据变化之间的联系: 采取切除散射、 拉曼归一化、 Savitzky-Golay平滑、 去除异常值等方法进行光谱预处理, 通过平行因子分析将其分解为四个互不相关的组分, 结合单物质荧光光谱特点进行综合相似度分析, 对各组分进行了初步鉴别。 结果表明, 大部分酸类和酯类物质的荧光光谱与组分二相关性更大, 组分二的荧光特性受酸类和酯类物质影响更大; 数据集大小由781×61×164简化为4×164, 达到了数据降维的效果。 建立了支持向量机模型(SVM)对原酒品质进行评价, 采取遗传寻优算法(GA)对支持向量机模型优化。 GA-SVM模型较原始SVM模型性能有所提升, 优化后的模型准确率由88.64%提升至95.45%, 模型精确率由0.94提升至1.00。 三维荧光结合化学计量学可以作为一种快速检测的有效手段对原酒质量进行评价, 为酒厂摘酒过程实现在线检测提供支持。
, QUAN Zhi-xi
At present, traditional liquor selection commonly employs the method of “liquor picking by flowers” during production, relying on workers′ subjective experience for evaluation. However, multiple influencing factors affect the actual production, resulting in uncertainty in the process of liquor connection, posing challenges in ensuring the stability of original liquor quality. This study collected samples of the original and composite original liquor with varying concentrations of tail liquor (0.0%~2.0%). The three-dimensional fluorescence spectra were obtained by fluorescence scanning, establishing a correlation between substance changes and fluorescence data. The fluorescence spectra underwent pre-processing steps such as removing scattering, Raman normalization, Savitzky-Golay smoothing, and removing outliers. Subsequently, parallel factor analysis was used to decompose the spectra into four uncorrelated components, and these components were initially identified through composite similarity analysis in conjunction with the attributes observed in single-substance fluorescence spectra. The results show a higher correlation between the fluorescence spectra of most acids and esters with component 2, suggesting that acids and esters have a stronger influence on the fluorescence properties of component 2. The dataset is reduced from 781×61×164 to 4×164, achieving data dimensionality reduction. A support vector machine (SVM) model was developed to assess the quality of the original liquor. A genetic algorithm (GA) was also employed to optimize the SVM model. GA-SVM model performs better than the original SVM model in accuracy and precision. The optimized model achieved an accuracy of 88.64% compared to 95.45% of the original model, and the precision improved from 0.94 to 1.00. This suggests that integrating 3-D fluorescence and chemometrics is an effective method for rapid detection to evaluate the quality of the original liquor. And provide support for online detection during the distillate liquor selection process, thereby enhancing the overall quality control.
浓香型白酒作为中国传统白酒的四大香型之一, 因其窖香浓郁、 绵柔甘冽、 香味协调、 尾净余长的特点, 深受消费者喜欢, 在白酒消费市场中占据最大份额[1]。 白酒的主要成分为水和乙醇, 占到物质含量的98.0%~99.0%, 其他微量成分仅占比1.0%~2.0%, 这些微量物质含量的差别, 决定了白酒香型与风格。 酒尾是在蒸酒时通过“ 量质摘酒” 工艺获得的尾段酒, 酒精度较低(一般小于35.0%)。 酒尾中含有较多的高沸点香味物质, 杂醇油、 高级脂肪酸和酯类的含量较高, 由于物质含量与比例很不协调, 导致酒尾味道很怪[2], 适当加入酒尾, 基酒中的香味成分含量会增加, 有助于基酒的香味丰富。 因此摘酒操作是在白酒生产过程中对原酒品质影响较大的工艺环节。 在实际生产中, 接酒工人主要依靠主观经验, 通过酒精度与温度等指标完成摘酒操作, 由于工人的经验不足等客观因素的存在, 原酒的品质难以保证稳定。 通过加强对摘酒过程中原酒参数的快速检测, 有助于控制原酒品质的稳定和酒厂后续调酒操作的进行。
对白酒品质检测分析的研究很多, 目前广泛使用的方法是感官评价、 气相色谱、 液相色谱、 质谱分析等[3]。 光谱作为快速检测技术, 因其具有无需样品制备, 检测限度低, 分析时间短, 可与化学计量学工具相结合的优点, 在食品检测中得到广泛的应用。 Cozzolino[4]等采用近红外和中红外光谱对澳大利亚夏敦埃和雷司令葡萄汁进行扫描, 通过主成分分析, 偏最小二乘法与线性判别的方法建立了产地分类模型。 Zhou[5]等采用红外光谱、 近红外光谱结合偏最小二乘与神经网络模型实现了在糖化、 煮沸阶段的含量对还原糖、 游离氨基氮和总酚的预测。
三维荧光光谱也叫总荧光光谱和激发-发射光谱(EEMs), 是以激发波长为x轴, 发射波长为y轴, 荧光强度为z轴的三维矩阵光谱, 包含了物质的荧光激发光谱与发射光谱的全部信息。 三维荧光光谱荧光峰位置与形状的不同使分析样品的物质组成成为可能[6]。 Geng等[7]已对其原理与分析方法进行了详细的叙述, 目前该方法以其操作简单和高效率的优势已经在环境[8]、 食品质量检测[9]等得到广泛应用, 已有研究采用三维荧光结合化学计量学建立了快速检测方法对绿茶、 食醋、 葡萄酒等食品真伪鉴定[10, 11, 12, 13]。 目前关于白酒中单体物质荧光特性的研究主要集中在几种含量较高的物质, 本实验增加了对浓香型白酒中香气影响较大的几种物质的三维荧光测量, 与平行因子分析相结合, 对白酒荧光峰的形成机理进行了进一步的探索; 建立了一个新的原酒品质评价模型, 为工厂原酒品质稳定的控制提供了一种新思路与方法。
乙醇、 正丁酸、 庚酸乙酯、 异丁酸乙酯购自上海麦克林生化科技有限公司, 己酸乙酯、 乳酸乙酯、 正己酸、 乙酸乙酯、 正丁醇、 丁酸乙酯、 戊酸乙酯、 辛酸乙酯、 正辛酸购自国药化学试剂有限公司, 所用试剂均为分析纯。
原酒与酒尾样本均来自江苏省某浓香型白酒工厂。 原酒样本均为由具有10年以上酿酒经验的酿酒师傅, 严格按照酒厂流酒标准蒸馏得到。
SmartFluo-Pro荧光光谱仪, 北京卓力公司生产, 氙灯功率150 W; 石英皿: 10 mm× 10 mm× 45 mm。
1.3.1 试剂制备
己酸乙酯、 乳酸乙酯、 正己酸、 乙酸乙酯、 正丁醇、 丁酸乙酯、 戊酸乙酯、 正丁酸、 庚酸乙酯、 异丁酸乙酯、 辛酸乙酯、 正辛酸分别加入到65.0%的乙醇溶液中, 形成物质浓度为2.0%的单物质乙醇溶液。
在车间收集原酒样本57个, 酒尾样本3个。 在原酒样品中随机添加0.0%~2.0%的尾酒, 得到复合原酒样本108个。
1.3.2 三维荧光数据采集
仪器预热0.5 h, 将样品溶液置于10 mm× 10 mm× 44 mm的石英池中, 设置荧光光谱仪步长为5 nm, 将发射波长从210 nm 增加到500 nm, 激发波长从200到500 nm。 在室温下记录所有样品的荧光强度。 每个样品测量三次求取平均值, 以减少仪器测量波动的影响。
由于荧光光谱数据测量容易受到光源、 仪器自身或外部噪声、 基线漂移等因素的干扰, 最终影响建模效果[14], 因此数据预处理是光谱分析中至关重要的一步。 测得的光谱数据中存在较大的瑞利散射和拉曼散射, 掩盖白酒的真实荧光信息, 故采用插值拟合的方法消除瑞利散射的影响, 通过减去空白水样减弱水拉曼散射带来的影响。 为提高光谱的信噪比, 降低仪器或外部噪声的影响, 将原始光谱进行Savitzky-Golay光滑处理; 为减轻不同阶段仪器自身不稳定带来的影响, 将所得三维荧光光谱均采取拉曼归一化[15]处理。
1.5.1 平行因子分析
平行因子分析(parallel factor analysis, PARAFAC)是一种采用交替最小二乘法实现数据分解的方法, 将原酒样品完全分解为几个主要荧光成分的激发光谱和发射光谱, 并给出各成分的载荷, 进一步简化复杂的数据集[16], 达到特征数据选择的效果。 当 EEMs 符合三线性模型, 则该三维矩阵可以写成三个向量乘积的和, 该模型可表示为
式(1)中, xijk为样品的三维荧光数据, 分解为每个组分激发载荷bif和发射载荷ckf, 与其对应的相对浓度aif, eijk为三维残差项, 代表数据中暂未被解释的部分。 每种组分即可以代表一种化学成分, 也可以代表一种或多种结构相似的物质[17]。 平行因子分析在Matlab R2021a版本中使用DOMFluor工具箱完成。
1.5.2 皮尔逊相关系数
皮尔逊相关系数(pearson correlation coefficient)为两向量间的协方差和标准差的商, 常用于度量两个向量之间的相关程度, 取值在-1到1之间, 可以表示为式(2)
1.5.3 余弦相似度
余弦相似度(cosine similarity), 也称为余弦距离, 用向量空间中两个向量夹角的余弦值作为衡量两个向量间差异的大小。 两个向量分别为a与b, 余弦相似度可以表示为式(3)
两个向量方向越相似, 其余弦值越接近于1。 将测试光谱与已知光谱视为维度等于波段数的空间中的矢量, 计算两个光谱夹角的余弦值, 可以确定两个光谱之间的光谱相似度[18]。 余弦相似性只与向量的方向有关, 对向量的大小不敏感, 可以降低荧光强度不同带来的影响。
1.5.4 支持向量机
支持向量机(support vector machines, SVM)是有监督的二分类机器学习算法模型, 通过寻找一个与样本间隔最大化的超平面来对样本进行分割, 最终将问题转化为凸二次规划问题求解。 支持向量机有利于解决小样本情况下的机器学习问题, 能够很好地避免模型过拟合问题, 具有较好的鲁棒性。 惩罚参数c与和函数参数gamma是支持向量机的两个重要的超参数: c值平衡模型的复杂度和分类误差之间的权衡; gamma值定义了样本点在高维特征空间中的影响范围, 选择合适的c值与gamma值可以避免模型的欠拟合与过拟合问题。 支持向量机模型在Matlab R2021a版本中使用, 在LIBSVM工具箱完成。
准确率描述模型正确分类的样本数占总样本数的比例, 准确率越高, 认为模型分类效果越好; 敏感性、 特异性与精确性分别描述了模型对对正样本的识别能力、 对负样本的识别能力以及对正样本判定的准确性。 对建立的两个分类模型进行验证, 将准确率、 敏感性、 特异性与精确性作为模型性能评价指标[19], 全面评估模型的性能。
式(4)—式(7)中, TP为真阳性、 FP为假阳性、 FN为假阴性、 TN为真阴性。
白酒的主要成分是乙醇和水, 其次是高级醇、 羰基化合物、 酯、 醛、 内酯、 有机酸等。 这些物质均有较强的呈香呈味作用: 有机酸是主要呈味物质, 酯类物质主要是呈香物质, 醇类物质主要呈现香与味的调和作用, 醛类物质主要使酒体芳香[20], 对其三维荧光光谱有较大影响。 不同的白酒几乎含有相同的荧光光谱, 是酒中复杂组分的化学、 物理和结构信息的综合展现, 通常由宽广重叠的荧光带组成[3]。 对浓香型白酒中含量相对较高且气味活性值(OAV)大于1的微量物质进行三维荧光检测[21]。
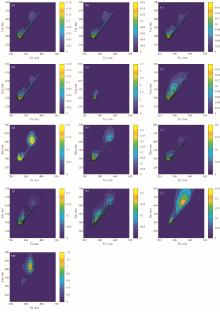
单物质的三维荧光谱分别如图1(a—m)所示, 所有物质的制备均以酒精为溶剂, 荧光光谱会受到乙醇的影响, 荧光强度较低的物质荧光峰被乙醇的荧光峰遮挡, 产生相似的影响的光谱。 乙醇与正丁醇的荧光峰大致在λ ex 260 nm/λ em 305 nm 处, 荧光光谱相似, 因其产生荧光的原理都是乙醇分子与正丁醇分子中的羟基为给电子基团, 羟基中的氧原子含有两对未共享电子, 吸收紫外光后, 从电子基态能级跃迁到电子激发态能级(n→ π * ), 又通过π * → n电子跃迁发出荧光。 大部分酸类与酯类物质具有相似的荧光光谱, 由于酯类与酸类物质中均含有得电子基团羰基, 在接受紫外光后可以产生π → π * 的电子跃迁。 该基团不能扩大电子共轭程度, 反而使S1→ T1系间跨越增强, 导致荧光量子产率降低, 荧光强度减弱, 并且这种电子跃迁形式很容易受到乙醇溶液的极性影响, 从而使荧光产生红移现象。 溶液的荧光强度也会受到分子平面性与分子刚性的性质影响, 在激发态时, 己酸乙酯的分子刚性略高于乙酸乙酯, 因而己酸乙酯荧光强度略高于乙酸乙酯。 各物质在复杂因素的综合影响下, 呈现独特的荧光特性, 为对白酒组分进行组分分解与初步鉴定提供了可能。
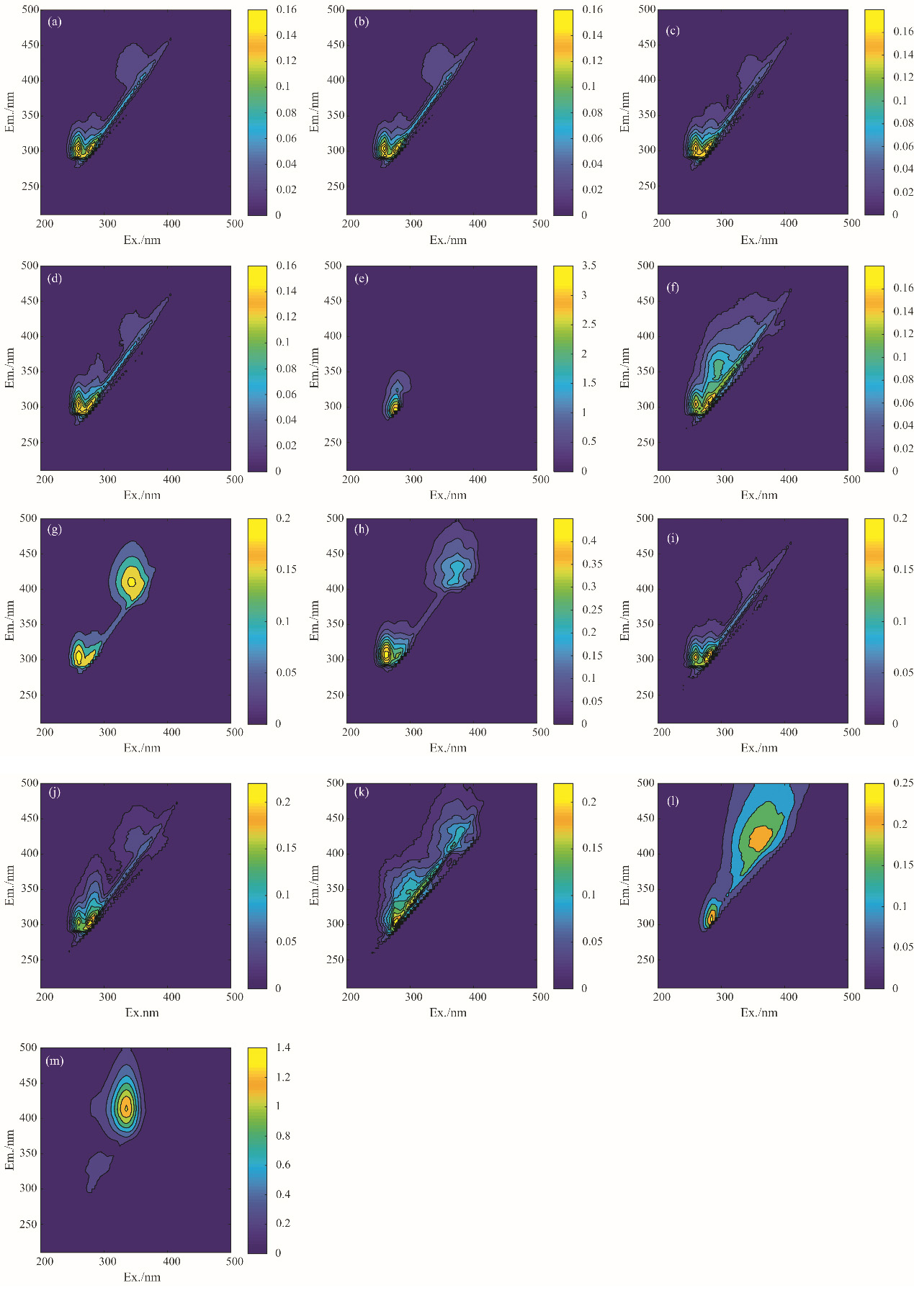 | 图1 单物质三维荧光图谱 (a): 乙醇; (b): 正丁醇; (c): 乳酸乙酯; (d): 辛酸乙酯; (e): 戊酸乙酯; (f): 正己酸乙酯; (g): 庚酸乙酯; (h): 异丁酸乙酯; (i): 乙酸乙酯; (j): 丁酸乙酯; (k): 正己酸; (l): 正丁酸; (m): 正辛酸Fig.1 Three-dimensional fluorescence mapping of single substances (a): Ethanol; (b): n-Butanol; (c): Ethyl lactate; (d): Ethyl caprylate; (e): Ethyl valerate; (f): Ethyl hexanoate; (g): Ethyl heptanoate; (h): Ethyl isobutyrate; (i): Ethyl acetate; (j): Ethyl butyrate; (k): n-Hexanoic acid; (l): n-Butyric acid; (m): n-Butyric acid |
将扫描获得的数据集进行初步分析, 样本34的杠杆率超过0.2, 作为异常样本删除。 将164个样本组成的大小为164× 781× 61的数据集进行2~10组分的模型构建, 对所有模型进行非负约束。 结合拆半分析和残差分析的结果, 获得核心一致性检测和解释方差值(见表1), 确定了4组分模型的稳定性和唯一性。
| 表1 不同组分模型核心一致性及解释率 Table 1 Core consistency and explanatory rate of different component models |
经过各组分相似性检验, 确定了四个组分相互独立, 没有成分冗余, 可以很好地代表样品荧光光谱的信息, 最终确定建立了四组分模型。 组分一的最大激发波长和发射波长分别在310和345 nm处。 组分二的最大激发波长和发射波长分别位于355和423 nm处; 组分三的最佳激发波长和发射波长分别位于335和391 nm处; 组分四的最佳激发波长和发射波长分别位于290和315 nm处。
研究了掺入不同比例酒尾(0.0%~2.0%)的原酒样本荧光光谱形状和荧光强度的变化趋势[图2(a, b, c)]。 原酒在λ ex 310 nm/λ em 340 nm 与λ ex 340 nm/λ em 415 nm 处存在两个荧光峰, 最大荧光强度大约为0.41 R.U[图2(a)]。 酒尾仅有一个荧光峰, 位于λ ex 350 nm/λ em 440 nm处, 最大荧光强度约0.92 R.U。 酒尾添加前后, 原酒的荧光范围并未发生明显变化, 荧光强度随酒尾添加量的变化而有所不同。 随着在原酒中添加的酒尾浓度增加, λ ex 310 nm/λ em 340 nm处荧光峰的强度逐渐降低, 而位于λ ex 340 nm/λ em 415 nm处的荧光峰强度逐渐变大, 从而显现出来, 形成双峰的光谱[图2(c)]。 原酒与酒尾的物质组成不同, 原酒中醇溶性物质、 沸点较低的物质含量较高, 酒尾中水溶性物质与沸点较高的物质含量较高[22]。 在原酒中加入一定量的酒尾, 物质组成发生改变, 荧光光谱也产生了一定的变化。
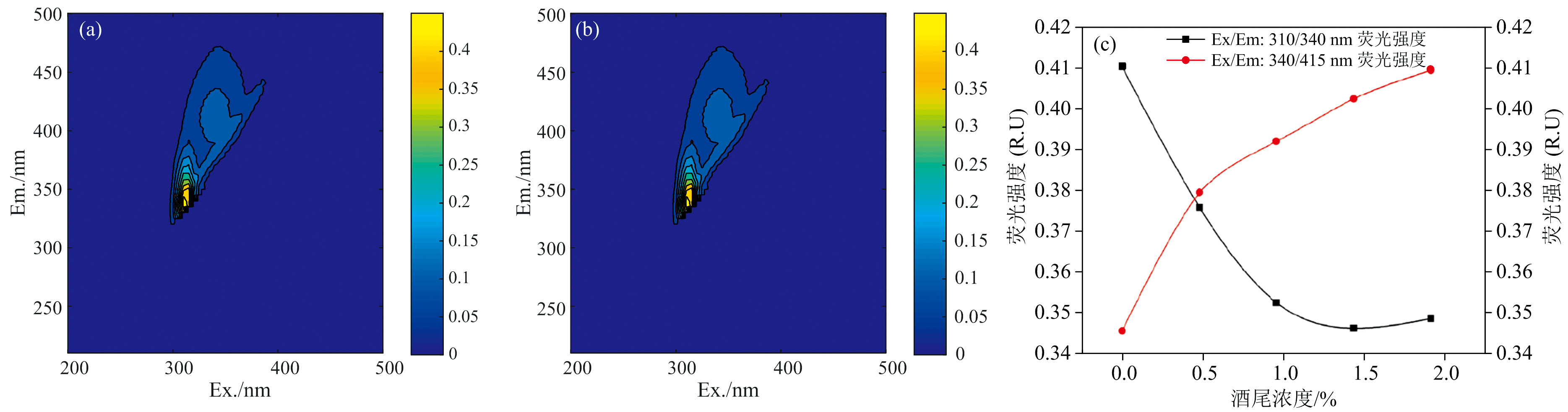 | 图2 添加不同浓度酒尾的原酒荧光光谱 (a): 原酒的三维荧光光谱; (b): 酒尾的三维荧光光谱; (c): 随酒尾浓度增加, 复合原酒光谱在310/340 nm; 340/415 nm处的荧光强度变化Fig.2 Fluorescence spectra of original liquor and tails liquor (a): Three-dimensional fluorescence spectroscopy of original liquor; (b): Three-dimensional fluorescence spectroscopy of tails liquor; (c): Changes in fluorescence intensity of the composite original liquor spectra at 310/340 nm; 340/415 nm with increasing concentration of tails liquor |
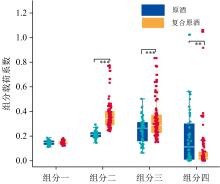
图3为原酒与复合原酒样本中各组分的载荷系数分布情况。 原酒样本与复合原酒样本组分一的数据分布没有显著差异(p> 0.05), 其余三个组分的数据分布存在明显差别: 原酒样品在组份四的数据分布明显高于复合原酒(p< 0.01), 而在组分二(p< 0.001)与组分三(p< 0.001)的数据分布规律则明显相反。 添加不同浓度酒尾的复合原酒, 原酒与复合原酒的各组分载荷系数存在显著差异, 为实现后续原酒品质评价模型的建立提供了依据。
 | 图3 原酒与复合原酒不同组分载荷系数箱型图 注: * * 和* * * 分别代表p< 0.01、 p< 0.001Fig.3 Box plots of loadings for different components of original and compounded original liquors Note: * * and * * * indicate significant correlations at the 0.01 and 0.001 levels, respectively |
同种物质的荧光特性相似, 仅荧光强度随物质浓度有所区别, 而不同物质的荧光特性有所区别。 通过将分解后的光谱与标准光谱进行对比, 可以实现光谱的成分识别。 通过分析载荷矩阵与标准光谱之间的相关性, 可以确定混合物中是否含有某种成分[23]。 为避免单个相似度指标产生的误差, 选取两种相似度计算方法同时度量。 只有当皮尔逊相关系数大于0.9, 同时余弦相似度大于0.8时, 两条光谱之间存在确定的相关。 不同物质与四个组分的激发载荷系数曲线的皮尔逊相关系数与余弦相似度计算如表2所示。
| 表2 各组分与单物质的相似度结果 Table 2 Results of the similarity of each component to a single substance |
浓香型白酒中对风味贡献较大且浓度较高的物质中, 绝大部分属于酸类及酯类物质。 通过表2可以看出, 除正辛酸、 乙酸乙酯与丁酸乙酯外, 大部分酸类与酯类物质与组分二处的相似性更高, 即这些物质对组分四的荧光贡献更大; 与靳喜庆[20]对白酒中物质荧光的研究得出的结论相同。 乙醇和正丁醇与组分四有很高的相似度, 与相关工作对醇类物质的研究一致。 随着酒尾浓度的增加, 酒中酸、 酯的浓度随之增加, 本研究中位于λ ex 340 nm/λ em 415 nm 处荧光峰强度的增强能够很好地对应这一现象。 几乎所有物质均与组分四具有较强的皮尔逊相关性, 可能与溶液中的乙醇-水分子相关。 乳酸乙酯与正丁醇整体荧光强度较低, 对白酒荧光峰的改变能力较弱, 受乙醇水溶液的影响较大, 可能因乳酸乙酯与几个组分的相似性整体均较高。
将去除离群值后的样本随机打乱顺序, 输入向量为平行因子分析得到的各组分权重系数组成的特征参数, 分类核函数为径向基函数, 分别采用网格寻优方法与遗传算法(GA)获得最佳惩罚函数c与gamma, 进行建模。 设置遗传算法求解优化的初始参数: 进化终止代数为100, 种群数量为20。
图4(a, b)为网格寻优过程与遗传算法寻优过程, 网格寻优得到最佳c值为5.278 0, 最佳gamma值为3.031 4; 遗传算法在进化代数遗传算法得到最佳c值为240.685 1, 最佳gamma值为1.561 0。 五折交叉验证对分类模型进行性能评价, 即将所有数据分成五份, 每次取其中不重复的一份作为验证集, 其他四份作为训练集, 最终取其评价指标的平均值以平衡模型。
 | 图4 不同模型寻优过程 (a): 网格搜寻法寻优过程; (b): 遗传算法寻优过程Fig.4 Optimization process of different models (a): Optimization process of grid search method; (b): Optimization process of genetic algorithm |
GA-SVM模型在五折交叉验证下的训练集准确率高于原始SVM模型(表3), GA-SVM模型的泛化能力较原始SVM模型有所提升。 根据测试集混淆矩阵(表4), SVM模型测试集准确率为88.64%, GA-SVM模型测试集准确率为95.45%, 并且GA-SVM模型验证集的准确率、 敏感性、 特异性以及精确性均高于原始SVM模型, 说明GA-SVM模型明显优于原始SVM模型, 该方法可以作为检测原酒品质评价的有效手段。
| 表3 模型参数及训练集准确率对比 Table 3 Comparison of model parameters and accuracy of training set |
| 表4 测试集混淆矩阵及品质系数 Table 4 Test set confusion matrix and quality factor |
通过对浓香型白酒的三维荧光数据进行平行因子分析, 将样品三维荧光光谱分解成四个互不相关的组分, 结合单物质荧光光谱进行相似性分析, 初步探究了各组分的主要影响物质。 结果表明, 酸类、 酯类物质对组分二的影响更为显著; 遗传算法优化的鉴别原酒品质的二分类支持向量机模型, 模型精确性达到1.00, 准确率达到95.45%, 比优化前的支持向量机模型性能有明显提升。 三维荧光结合化学计量学可以作为一种快速检测方式进行原酒质量快速鉴别的方法, 为酒厂进行原酒品质管理提供参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|