
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱的干制黄花菜产地判别及可溶性蛋白质含量预测
[张雪莉1, 2  , 杨浩
, 杨浩1, 2 , 李晨斐1, 2 , 孙一乐1, 2 , 刘宗霖1, 2 , 郑德聪1, 2 , 宋海燕1, 2, * ]
, 杨浩]
|
|


作者简介: 张雪莉,女, 1990年生,山西农业大学农业工程学院博士研究生 e-mail: zxl_gem@sxau.edu.cn
黄花菜营养成分丰富, 具有很高的食用、 药用及经济价值, 在中国产地众多。 黄花菜的产地判别及可溶性蛋白质含量预测对黄花菜品质管理及农产品品牌建立和地方经济发展有着非常重要的意义。 鲜黄花菜因含有多种生物碱不宜多食, 市面上黄花菜多为干菜。 基于近红外光谱建立了干制黄花菜产地判别模型及可溶性蛋白质含量预测模型。 针对原有算法判别精确度不高及含量预测不准确等问题, 对原有模型进行改进, 通过结合不同的预处理方法及特征波长筛选算法有效地提高了模型的准确率。 基于偏最小二乘判别分析(PLS-DA)、 随机森林(RF)以及支持向量机(SVM), 分别与多元散射校正(MSC)、 标准正态变量变换(SNV)及Savitzky-Golay平滑 (SG)三种预处理方式相结合建立干制黄花菜产地判别模型并比较模型的优劣, 实验结果表明, 使用PLS-DA结合MSC预处理方法进行产地判别效果最好, 准确度达到93.33%, 三产地的精确度与召回率均在85%以上, 平均精确度达到91.9%, 平均召回率为91.9%, 说明该模型具有很好的准确性和稳定性, 能够很好地进行干制黄花菜的产地判别。 同时, 使用偏最小二乘回归(PLSR)分别与多种预处理方法及无信息变量去除算法(UVE)、 竞争性自适应重加权算法(CARS)和连续投影算法(SPA)三种特征波长筛选算法相结合, 建立干制黄花菜可溶性蛋白质含量预测模型并进行预测结果对比, 结果表明PLSR结合SG预处理及CARS特征波长筛选算法建立的模型预测效果最佳, 决定系数值达到0.981 5, 预测均方根误差RMSEP为0.021 4 g·kg-1, 与原PLSR算法对比, 值提高了0.12, RMSEP降低了0.033 1 g·kg-1, 该预测模型可很好地进行干制黄花菜可溶性蛋白质含量的预测。
, YANG Hao
Daylily is rich in nutrients and has high edible, medicinal, and economic value. It has many producing areas in China. The origin discrimination and soluble protein content prediction of daylilies are of great significance to the quality management of daylilies, the establishment of an agricultural product brand, and the development of the local economy. Because fresh daylily contains a variety of alkaloids, it is not suitable to eat in large quantities. Therefore, most of the daylilies on the market are dried daylilies. In this paper, the origin discrimination model and soluble protein content prediction model for dried daylily were established based on near-infrared spectroscopy. To address the issues of low discrimination accuracy and inaccurate content prediction in the original algorithm, the model was enhanced, resulting in a significant improvement in accuracy through the combination of various preprocessing methods and characteristic wavelength screening algorithms. In this study, Partial Least Squares Discriminant Analysis (PLS-DA), Random Forest (RF), and Support Vector Machine (SVM) were combined with Multiplicative Scatter Correction (MSC), Standard Normal Variate (SNV) and Savitzky-Golay smoothing (SG) respectively to establish the origin discrimination models of dried daylily and compare the model discrimination results. The experimental results show that PLS-DA combined with MSC has the best effect on origin discrimination, with an accuracy of 93.33%. The precision and recall of the three origins are all above 85%, with an average precision of 91.9% and an average recall of 91.9%. It demonstrates that the model exhibits good accuracy and stability, and can effectively distinguish the origin of dried daylilies. At the same time, Partial Least Squares Regression (PLSR) was combined with a variety of preprocessing methods and three characteristic wavelength screening algorithms: Unobserved Variable Elimination (UVE), Competitive Adaptive Reweighted Sampling (CARS) and Successive Projections Algorithm (SPA), respectively, to establish the prediction models of soluble protein content of dried daylily and compare the prediction results. The results show that the model established by PLSR, combined with SG and CARS, has the best predictive effect. The determination coefficient R2 reached 0.981 5, and the Root Mean Square Error of Prediction (RMSEP) was 0.021 4 g·kg-1. Compared with the original PLSR, the R2 increased by 0.12, and the RMSEP decreased by 0.033 1 g·kg-1. This prediction model can well predict the soluble protein content of dried daylily.
黄花菜(Hemerocallis Citrina Baroni), 阿福花科萱草属被子植物, 其花可食用, 为中国特产。 黄花菜营养价值丰富, 富含蛋白质、 脂肪、 糖类等, 药用价值也很高, 具有安神明目、 健脑、 抗衰老等功能。 黄花菜因含有多种生物碱, 其鲜花不宜多食, 会引起腹泻等中毒现象, 因此食用前需进行处理。 黄花菜主要以其花蕾为加工对象, 经蒸制加工后制成干菜[1]。 目前, 中国黄花菜的种植遍布全国, 湖南、 山西、 甘肃等地都有大规模的黄花菜种植基地, 黄花菜产业具有很高的经济价值。
黄花菜产地众多, 在现代农产品生产和管理中, 精确的产区划分有着非常重要的意义, 农产品产地判别不仅关乎农产品的生长环境、 种植技术, 还直接影响到农产品的品质和市场竞争力。 通过产地判别, 消费者可以清晰地了解农产品的产地、 生产过程和环境指标等信息。 同时, 产地判别要求生产者遵守一系列的生产标准和规定, 确保农产品的品质和安全性[2]。 农产品产地判别还可以使农产品获得独特的产地品牌优势, 同时促进地理标志保护, 提升了农产品的附加值, 保护了特色农产品的独特性和市场价值。 蛋白质含量是评价黄花菜食用品质的一项重要指标[3], 能够反映食品的营养价值, 同时还会影响黄花菜的口感, 从而影响消费者的选择。 因此, 对黄花菜中可溶性蛋白质含量进行分析预测对黄花菜产业的发展有非常重要的意义。
近红外(near infrared, NIR)光谱技术是一种快速检测方法, 因其可测样品范围广、 分析效率高、 无污染、 检测成本低等优点, 近年来, 被广泛应用于农产品识别检测等领域。 Eisenstecken[4]等基于近红外光谱结合化学计量学方法实现了对不同品种和海拔的苹果的鉴别, 通过主成分分析-二次判别分析(PCA-QDA)实现了根据果园海拔追踪苹果起源并对苹果品种进行分类。 张爱武[5]等基于近红外漫反射光谱对泰来绿豆和非泰来绿豆进行产地溯源研究, 结合一阶导数+5点平滑的预处理方式建立了定性分析模型, 同时采用Ward's algorithm聚类算法结合二阶导数+SNV+5点平滑的预处理方式建立了聚类分析模型, 对粉末状泰来绿豆的正确鉴别率分别为96.15%和92.30%。 杨群[6]等基于近红外光谱, 通过对原始光谱进行预处理结合反向传播神经网络构建了柑橘果实膨大期和转色期叶片功能性氮含量的监测模型。 Bartwal[7]等基于近红外光谱, 使用改进的偏最小二乘(mPLS)及PLS结合不同预处理方法和数学处理方法建立了绿豆蛋白质预测模型。 相志勇[8]等基于近红外光谱分析技术和一维卷积神经网络(1D-CNN)建立了蜜柑果实可溶性固形物含量预测模型。 目前, 近红外光谱技术的应用对象种类众多, 但尚未有针对黄花菜的研究。
本文以干制黄花菜为研究对象, 利用近红外光谱技术结合化学计量学的方法, 进行了干制黄花菜产地判别及可溶性蛋白质含量预测研究。 利用偏最小二乘判别分析(PLS-DA)[9]、 随机森林(RF)[10]以及支持向量机(SVM)[11]结合不同的预处理方法建立了干制黄花菜产地判别模型, 并通过偏最小二乘回归(PLSR)[9]结合不同预处理及特征波长筛选方法进行可溶性蛋白质含量的预测, 对不同判别模型及预测模型进行了优劣对比, 实现了干制黄花菜产地精准判别和可溶性蛋白质含量的准确预测。
使用三个产地的干制黄花菜, 经处理筛选后共获得103份样品, 分别是35份山西大同黄花菜, 34份湖南祁东黄花菜, 34份甘肃庆阳黄花菜。 对样品进行分类编号, 1— 35号为山西大同黄花菜, 36— 69号为湖南祁东黄花菜, 70— 103为甘肃庆阳黄花菜。 编号后用研磨机将每一份样品分别磨成颗粒均匀的粉状, 过100目筛, 如图1所示, 放入玻璃培养皿中准备进行后续数据采集。 通过对干制黄花菜产品及样品粉末的观察对比可知, 干制黄花菜产品外形单一, 三产地样品粉末外观没有明显区别, 肉眼无法区分, 因此需要采用近红外光谱分析方法进行产地判别。
 | 图1 干制黄花菜样品粉末Fig.1 Dried daylily powder samples |
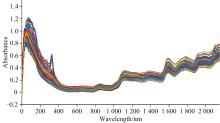
实验使用美国ASD公司的Field Spec3型号近红外光谱仪进行光谱数据采集, 光谱范围为350~2 500 nm, 采样间隔为1 nm, 波长精度是± 1 nm。 采集过程中室内温度: 20 ℃, 湿度: 40%, 光源和信号接收器高度约35 cm。 采集光谱数据前使用黑白板矫正, 消除暗电流的干扰。 采集每一个样本的光谱时, 通过旋转培养皿来实现每个样本不同部位信息的采集, 即完成一次采集后, 顺时针旋转培养皿120° 进行下一次采集, 每个样本共采集三次, 然后取平均值作为其光谱数据, 所有样品的原始光谱图如图2所示。
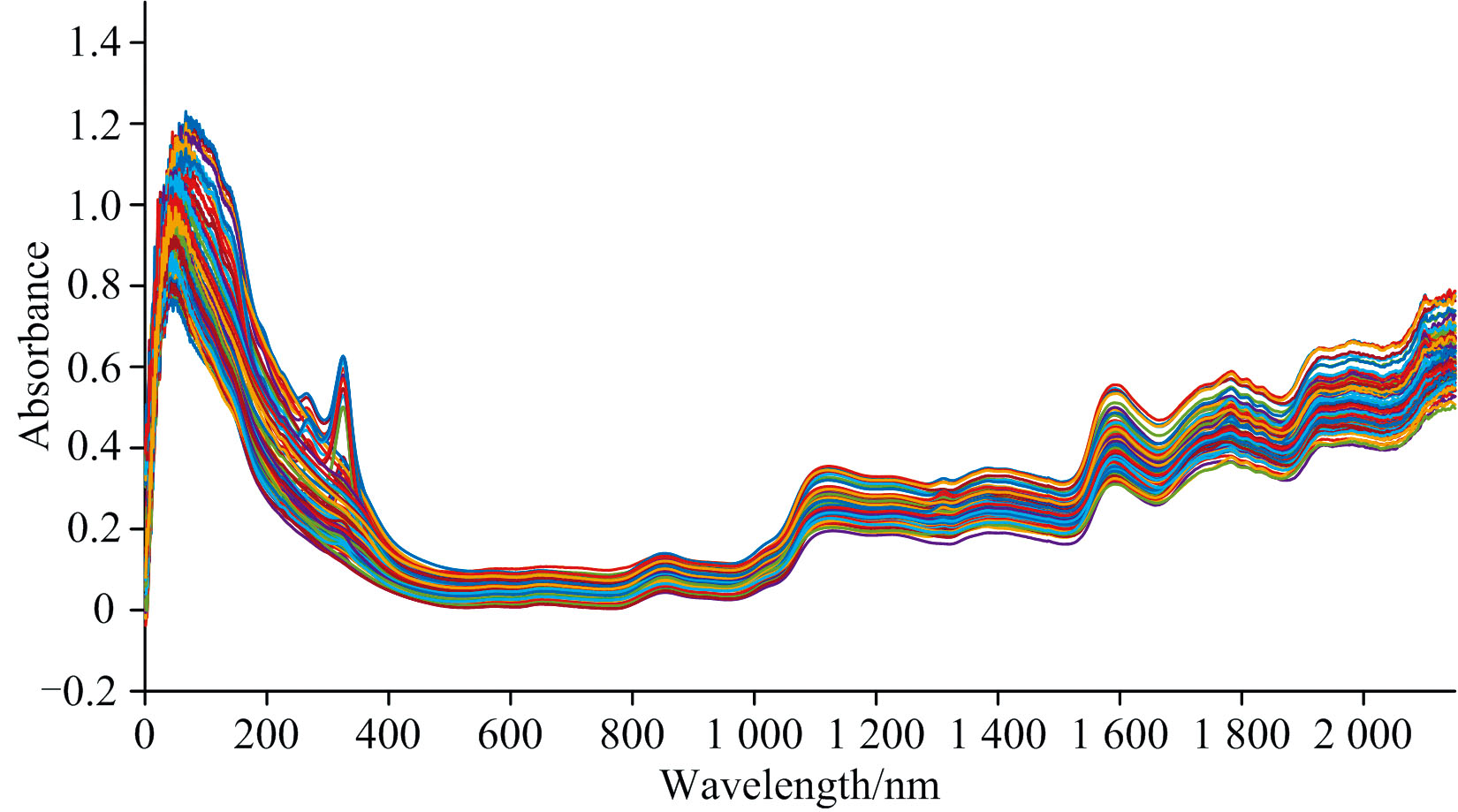 | 图2 干制黄花菜原始近红外光谱Fig.2 The original near-infrared spectra of dried daylily |
使用考马斯亮蓝法对干制黄花菜产品的可溶性蛋白质含量进行测定[12]。 实验所用试剂如下:
(1) 考马斯亮蓝G-250溶液: 将100 mg考马斯亮蓝G-250溶于50 mL 95%乙醇, 加入100 mL 85%的磷酸, 然后用蒸馏水补充至1 000 mL, 此染液放4 ℃保存, 保质期6个月。
(2) 标准蛋白质溶液: 称取25 mg牛血清清蛋白, 加蒸馏水溶解并定容100 mL, 再稀释2.5倍即为100 μ g· mL-1的标准溶液。
(3) 待测溶液: 分别称取0.2 g的样品粉末, 放入10 mL的离心管中, 并做好标记。
测得吸光度值后根据标准曲线计算待测样本可溶性蛋白质含量, 所得三产地样品的可溶性蛋白质含量范围及均值如表1所示, 其中, 山西大同黄花菜蛋白质含量均值最高, 其次为甘肃庆阳黄花菜, 湖南祁东黄花菜蛋白质含量略低于前两者。
| 表1 三产地干制黄花菜样品可溶性蛋白质含量情况 Table 1 Soluble protein content of dried daylily samples from three production areas |
产地判别实验使用偏最小二乘判别分析(PLS-DA)、 随机森林(RF)、 支持向量机(SVM)三种方法结合不同预处理方式建立产地判别模型[13], 使用准确度、 精确度和召回率对模型预测结果进行好坏判定, 并通过平均精确度和平均召回率对模型整体的判别结果进行评估。 准确度(Accuracy)、 精确度(Precision)与召回率(Recall)的公式如式(1)— 式(3)
式(1)— 式(3)中, TP为真阳性; TN为真阴性; FP为假阳性; FN为假阴性。
可溶性蛋白质含量预测实验使用偏最小二乘回归(PLSR)结合不同的预处理及特征波长筛选方法建立不同预测模型[14]。 通过决定系数R2值及预测均方根误差RMSEP(root mean square error of prediction)对模型性能进行评价。
式(4)和式(5)中, n为实验样本数, yi为第i个样本的真实值,
决定系数取值范围为0~1, 在建立模型时, R2越接近1越好。 RMSEP用于评估通过建立回归模型得到的预测值与真实值之间的误差的平均值, 较低的RMSEP值表示模型的预测能力较好。
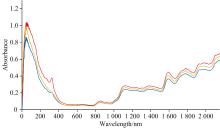
分别对三产地干制黄花菜样品光谱数据求平均值, 得到三产地平均光谱图如图3所示, 三产地产品光谱变化趋势大致相同, 说明三产地产品的组成成分类似, 无法由成分组成直接进行产地区分, 但吸光度有明显差异, 说明成分含量有差异。 根据近红外光谱解析可知, 蛋白质的特征谱带为973~1 020 nm附近的N— H伸缩振动的二级倍频, 1 500~1 530 nm附近的N— H伸缩振动的一级倍频, 以及2 050~2 060 nm附近的N— H伸缩振动组合频吸收[15]。 且光谱1 800~2 500 nm范围内主要是C— H键和N— H键的吸收波段, 一般与蛋白质和糖类有关[16]。 结合干制黄花菜光谱图变化趋势可得, 蛋白质含量对黄花菜的品类有较大影响, 三产地产品的蛋白质含量有区别。
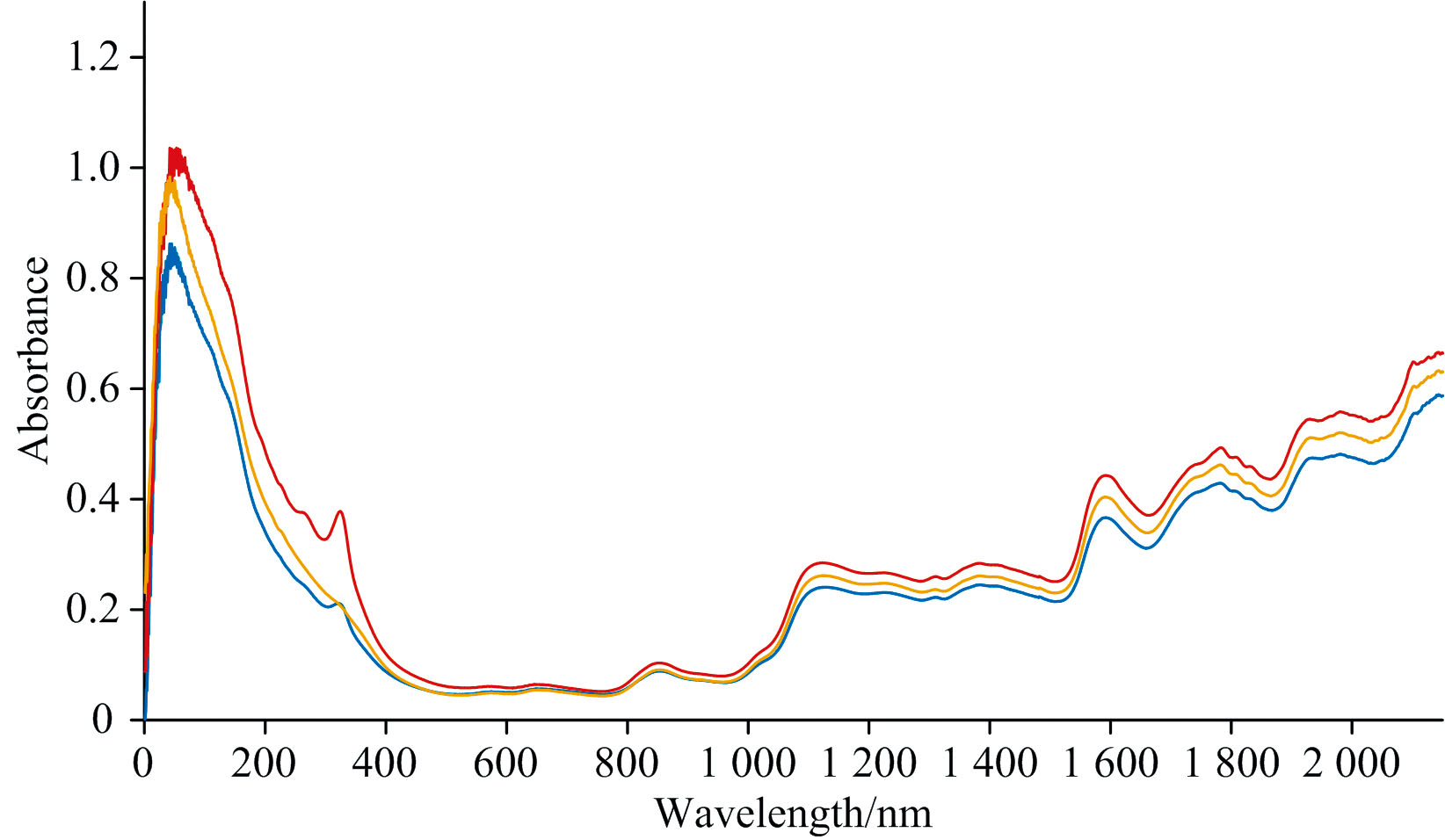 | 图3 不同产地干制黄花菜光谱平均值图Fig.3 The average spectra of dried daylily samples from different producing areas |
黄花菜产地不同则物候条件不同, 物候条件的差异会造成黄花菜品质有所差异, 经化学标准测试可得不同产地黄花菜蛋白质含量虽范围有交叉, 但均值有明显差异, 说明物候条件对其品质形成有影响。 蛋白质中的官能团包含C— H键, N— H键等, 均是近红外光谱检测的敏感官能团, 因此可以通过近红外光谱检测反映其产地差异。 如果不同产地产品蛋白质含量相同, 说明产地不同物候差异不会影响产品蛋白质含量。 因此, 针对黄花菜产品蛋白质含量的研究对不同产地产品的划分及不同产地黄花菜营养成分差异的研究有重要意义。
通过MATLAB R2022b进行数据处理和模型建立。 所有样本按2:1的比例划分为训练集和预测集。 主要选取了三种预处理方法: 多元散射校正(MSC)、 标准正态变量变换(SNV)及Savitzky-Golay平滑 (SG), 分别使用PLS-DA、 RF、 以及SVM结合不同的预处理方法建立干制黄花菜产地判别模型, 判别结果如表2所示。
| 表2 产地判别模型结果对比 Table 2 Comparison of the modeling results of origin discriminant models |
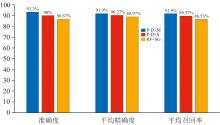
其中, 准确度在85%以上的三种方法的准确度, 平均精确度, 平均召回率结果对比如图4示。 根据实验结果可得, PLS-DA结合MSC预处理方法对三产地的综合判别效果最好, 准确度达到93.33%, 三产地判别精确度均在85%以上, 平均精确度达到91.9%, 且平均召回率为91.9%, 说明该模型有很好的准确性及稳定性, 可以有效地进行干制黄花菜产地判别。
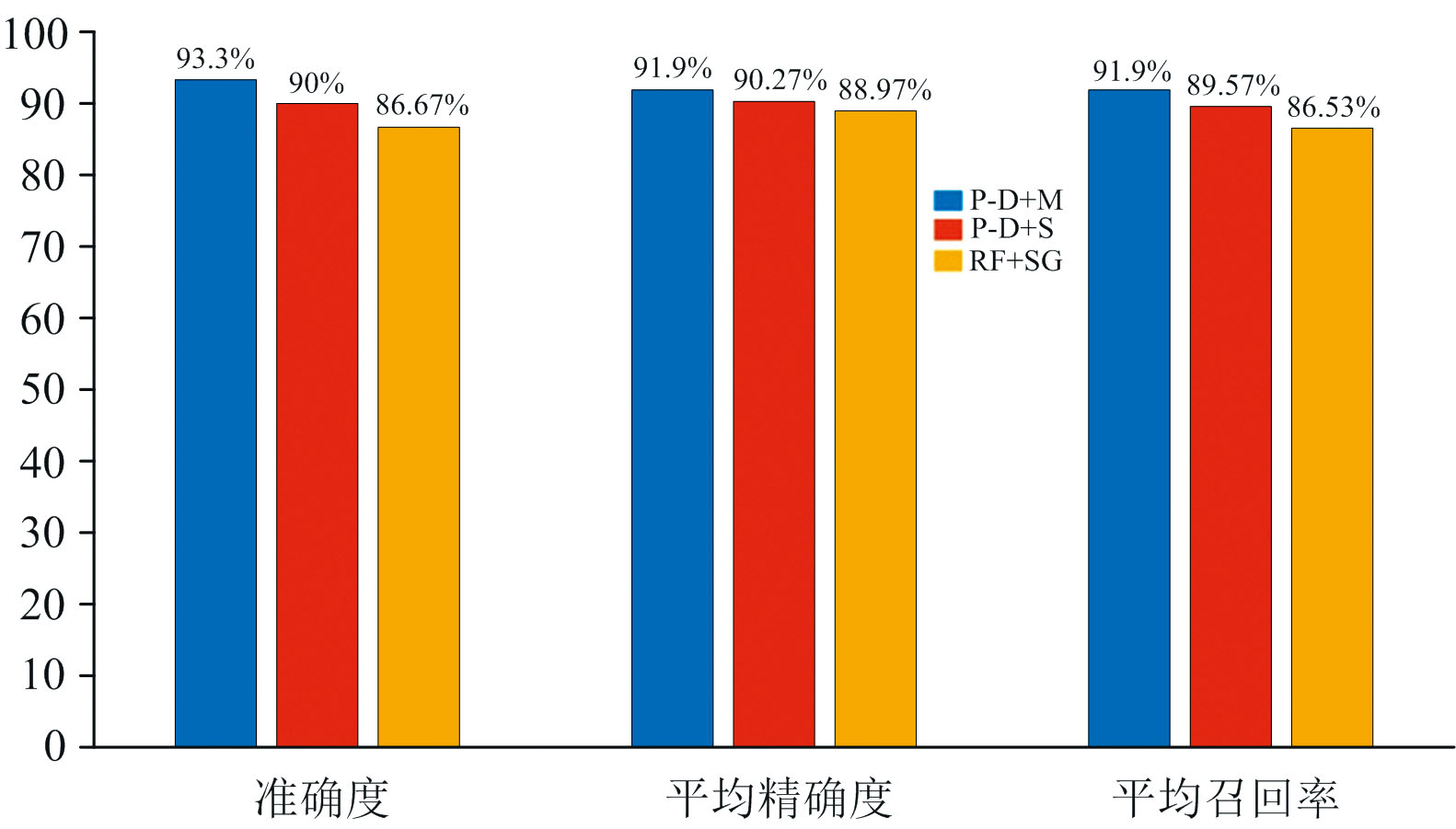 | 图4 三种高准确度判别方法结果对比Fig.4 Comparison of three high accuracy discriminant methods |
实验通过偏最小二乘回归(PLSR)结合不同的预处理及特征波长筛选算法建立了不同的可溶性蛋白质含量预测模型, 使用Kennard-Stone算法将所有样本按3:1的比例划分为训练集和预测集。 使用的预处理方法为: MSC、 SNV及SG, 选取了无信息变量去除算法(UVE)、 竞争性自适应重加权算法(CARS)及连续投影算法(SPA)三种特征波长筛选算法, 预测结果中预测集决定系数R2值在0.85以上的预测模型结果如表3所示。
| 表3 可溶性蛋白质含量预测模型结果对比 Table 3 Comparison of the modeling results of soluble protein content prediction models |
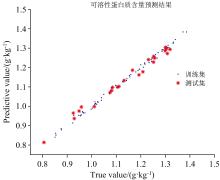
预测结果对比表明, PLSR结合SG预处理及CARS特征波长筛选算法的模型预测效果最佳, 预测集决定系数R2值达到0.981 5, 预测均方根误差RMSEP为0.021 4 g· kg-1, 与原PLSR算法对比, R2值提高了0.12, RMSEP降低了0.033 1 g· kg-1。 SG+CARS+PLSR定量模型预测结果散点图如图5所示。
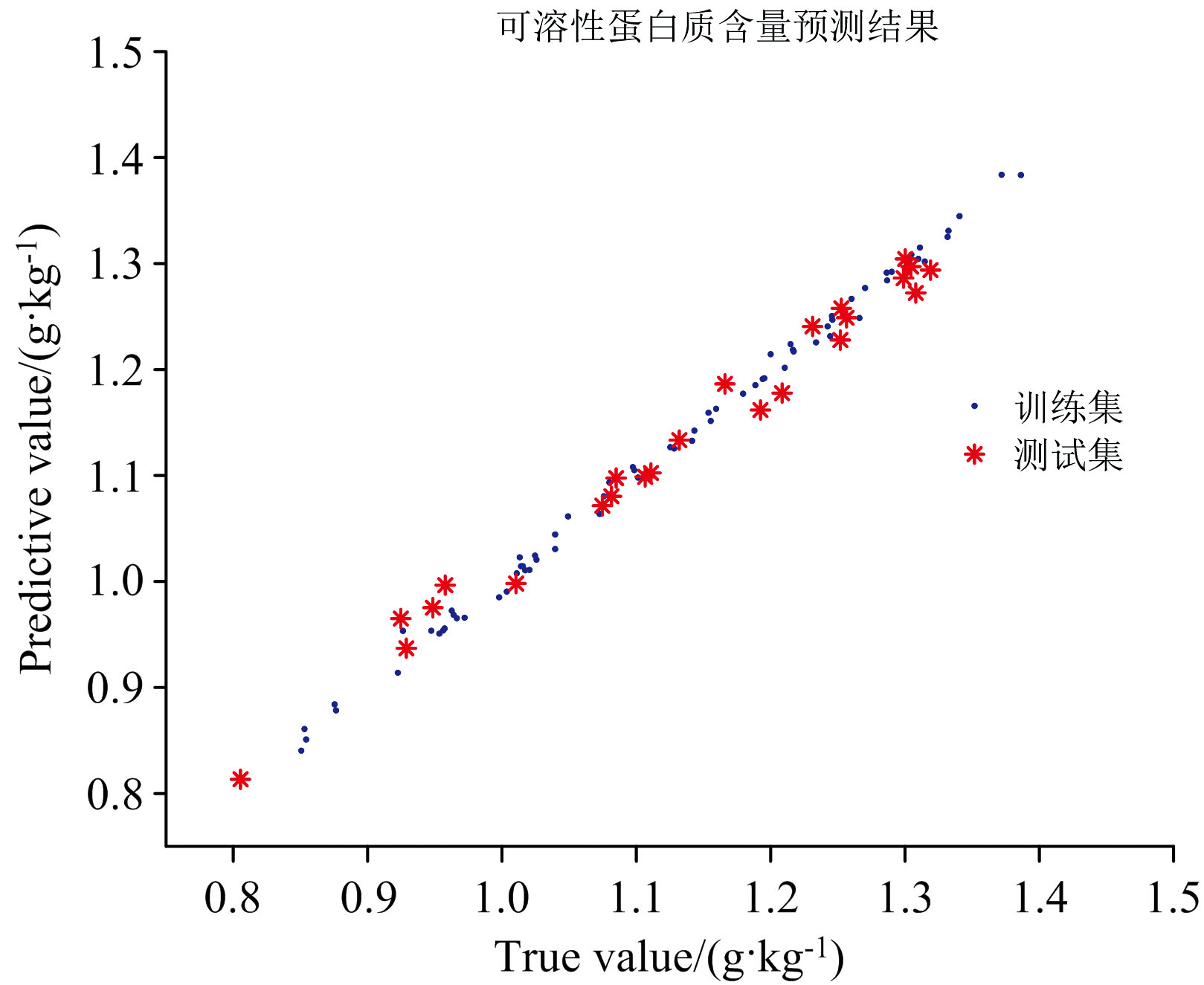 | 图5 SG+CARS+PLSR定量模型预测结果散点图Fig.5 Scatter plot of the prediction results of SG+CARS+PLSR |
利用近红外光谱对干制黄花菜进行产地判别以及可溶性蛋白质含量的预测。 使用PLS-DA、 RF以及SVM结合不同的预处理方法建立了干制黄花菜产地判别模型并进行模型判别结果优劣对比。 结果表明, 使用PLS-DA结合MSC预处理方法得到的模型判别效果最好, 准确度达到93.33%, 三产地的精确度与与召回率均在85%以上, 平均精确度达到91.9%, 平均召回率为91.9%, 说明该模型具有很好的准确性和稳定性, 能够很好地进行干制黄花菜产地辨别。 同时, 基于PLSR结合多种预处理方法及特征波长筛选算法建立了干制黄花菜可溶性蛋白质含量预测模型并对多种模型的预测结果进行对比。 结果表明, PLSR结合SG预处理及CARS特征波长筛选算法建立的预测模型预测效果最佳, 预测集决定系数R2值达到0.981 5, 预测均方根误差RMSEP为0.021 4 g· kg-1, 与原PLSR算法对比, R2值提高了0.12, RMSEP降低了0.033 1 g· kg-1, 该预测模型可以很好地进行干制黄花菜可溶性蛋白质含量的预测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|