{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三维荧光光谱预测大豆油掺假花生油含量的建模效果研究
[魏泉增1  , 刘雪影
, 刘雪影1 , 王至洁1 , 丁芳2 ]
, 刘雪影|
|


作者简介: 魏泉增, 1983年生,许昌学院食品与药学院副教授 e-mail: weiquanzeng@163.com
为实现大豆油掺假花生油含量测定, 采集自制不同含量大豆油和花生油伪品的三维荧光光谱数据, 采用三角形内插值法去除瑞利散射和拉曼散射, 而后对荧光光谱进行卷积平滑(Savitzky-Golar)处理。 采用三线性交替分解(ATLD)和平行因子(PARAFAC)算法预测花生油的含量。 同时, 对不同含量花生油的伪品的三维荧光数据去散射和平滑处理后, 对每个激发波长所对应的发射光谱进行小波包分解(WPD), 以最低频段的波包系数, 作为荧光发射光谱数据表征量。 并按照激发波长顺序数将所有发射波长数据重构为一阶荧光光谱数据向量, 构建偏最小二乘(PLS)和人工神经网络(ANN)数据模型预测伪品中花生油含量。 结果表明, PARAFAC, ATLD, WPD-PLS和WPD-ANN的回归系数 R2分别为0.898, 0.941, 0.961和0.981。 WPD-ANN算法模型的训练集、 验证集、 测试集和全部数据的平均绝对偏差(MAD)、 均方误差(MSE)和均方根误差(RMSE)均较小, WPD-ANN模型对伪品中的花生油含量进行预测, 预测偏差在±5%以内的样本百分比为82.5%。 对比分析WPD-ANN, WPD-PLS, ATLD和PARAFAC 4种算法模型的花生油含量预测结果。 WPD-ANN和WPD-PLS模型偏差的均值和中位数都在0%附近, 而ATLD和PARAFAC模型偏差的均值和中位数离0%较远。 相较于PARAFAC模型, ATLD模型的收敛速度更快, 偏差更小。 ATLD和PARAFAC模型可能受到非线性因素的影响, 预测效果不及WPD-ANN及WPD-PLS, 而ANN和PLS是基于WPD及数据重构后一阶数据回归建模, 同时ANN是非线性模型, WPD-ANN模型对伪花生油中花生油含量具有更强的预测能力且偏差更小, 是预测伪品中花生油含量4种算法中更优的算法。 这为定量分析掺假食用油提供了研究基础。
To determine the content of adulterated peanut oil in soybean oil, the three-dimensional fluorescence spectrum data of soybean oil and peanut oil counterfeit were collected. Rayleigh scattering and Raman scattering were removed using the triangular internal interpolation method. Then the fluorescence spectra were processed using Savitzky-Golay. The Alternating trilinear decomposition (ATLD) and Parallel factor (PARAFAC) algorithms were used to predict peanut oil content. Meanwhile, after scattering and smoothing the three-dimensional fluorescence data of the different contents of counterfeit peanut oil. The emission spectrum corresponding to each excitation wavelength is decomposed by wavelet packet decomposition (WPD), and the wave packet coefficient of the lowest frequency band is used as the characteristic amount of fluorescence emission spectrum data. All the emission wavelengths were reconstructed according to the sequence number of excitation wavelengths, and the data were reconstructed into a first-order fluorescence spectrum data vector. Partial least squares (PLS) and artificial neural network (ANN) data models were constructed to predict the content of peanut oil in counterfeit products. The results indicated the regression coefficients R2 of PARAFAC, ATLD, WPD-PLS, and WPD-ANN were 0.898, 0.941, 0.961, and 0.981, respectively. Mean absolute deviation (MAD), mean squared error (MSE), and root mean squared error (RMSE) of the training set, verification set, test set, and all data of the WPD-ANN algorithm model were all small. The peanut oil content in counterfeit products was predicted using the WPD-ANN model. The percentage of samples with prediction deviation within ±5% was 82.5%. The peanut oil content prediction results by WPD-ANN, WPD-PLS, ATLD, and PARAFAC were compared and analyzed. The mean and median deviations of WPD-ANN and WPD-PLS models are near 0%, while the mean and median deviations of ATLD and PARAFAC models are far from 0%. Compared with the PARAFAC model, the ATLD model has faster convergence and smaller deviation. ATLD and PARAFAC models may be affected by nonlinear factors, and their prediction effect was inferior to that of WPD-ANN and WPD-PLS, while ANN and PLS were based on first-order data regression modeling after WPD and data reconstruction. ANN was a nonlinear model. Therefore, the WPD-ANN model has stronger prediction ability and smaller deviation for peanut oil content in counterfeit peanut oil. The WPD-ANN model was the best algorithm among the four algorithms for predicting peanut oil content in counterfeit peanut oil. This provides a research basis for quantitative analysis of adulterated edible oil.
食用植物油是日常饮食中重要的组成部分, 能够提供热量及必需脂肪酸[1], 同时还可以改善和提高食物的风味和口感。 目前市场上的食用植物油种类繁多, 其价格相差很大。 一些不法商家为了经济利益, 对食用植物油造假, 常见的造假方式是食用油之间的相互掺假, 如大豆油掺假花生油, 小磨油等[2]。 食用油市场准入制度和新的食用油标准虽然已经开始实施, 但食用油的掺假比例还没有明确的检测方法。 因此, 亟需建立一种掺假食用油掺假含量的测定方法。
目前, 关于食用植物油掺伪的常用检测方法有理化分析法、 色谱法、 质谱法等, 其中国家标准GB/T 5539— 2008《粮油检验油脂定性试验》是采用理化分析, 仅适用于亚麻油、 矿物油、 芝麻油、 棉籽油、 猪脂等少数常见食用油定性[3]; 色谱法是对食用油脂肪酸组成、 含量进行分析, 从而判断食用油是否掺假, 及掺假食用油的种类; 质谱法通过测定食用油特定离子进行分析食用油是否掺假[4, 5]。 这些方法具有前处理费时费力, 操作复杂的缺点。 荧光光谱法具有不需要样品预处理、 选择性强、 分析快速、 极少使用有毒溶剂等优良特点。 现阶段针对食用油的掺假定性研究较多, 例如识别南瓜子油掺假[6], 芝麻油、 亚麻籽油、 油菜籽油和橄榄油[7]。 但针对食用油的掺假定量研究却罕见报道。
三维荧光光谱(excitation emission matrix spectroscopy, EEM)能提供比常规荧光光谱更加详细的信息。 例如, EEM能显示样品中组分的荧光强度、 荧光峰位置及荧光强度变化趋势等信息。 同时, EEM在白酒品质评价[8], 掺假食用油[9], 山茶花油的识别[10]取得的不错的效果。 植物性食用油的主要成分是脂肪酸甘油三酯, 其含量达94%~96%[11], 但是植物食用油还有一些含有共轭体系的分子(例如生育酚、 胡萝卜素、 甾醇等物质), 容易产生π → π * 的跃迁, 从而产生荧光效应。 由于不同植物食用油中的荧光物质的种类和含量不同, 为食用油的种类的鉴别和掺假含量的测定提供了检测基础。 但EEM原始数据存在散射, 噪声等影响因素, 对后续利用EEM数据进行定性和定量分析造成影响。 近几年, 多元校正技术尤其是二阶校正方法的发展, 使EEM检测有了长足的发展。 尤其是利用三角形内插值法消除EEM数据中瑞利散射和拉曼散射, 数据平滑技术删除EEM数据噪声后, 通过数学方法将重叠的谱图分辨为各个纯的分析物以及干扰物质的谱图。 即利用“ 数学分离” 代替“ 物理分离” , 快速准确地实现感兴趣组分的定性和定量分析。 二阶数据校正算法中常见的为交替三线性分解算法(alternating trilinear decomposition algorithm, ATLD)和平行因子算法(parallel factors algorithm, PARAFAC)。 目前, 基于最小二乘原理迭代算法的ATLD, 具有收敛速度快, 占用内存小等优点[12]。 PARAFAC是将多维数组简单地展开为矩阵然后进行标准的二阶主成分分析(PCA)。 尽管PARAFAC是PCA对高阶数组的推广, 但是PARAFAC不存在旋转问题, 纯光谱数据仍可以从多维数据变化中还原。 PARAFAC优点是模型在数学意义上非常简单, 因此更稳健和更容易解释[13]。 EEM-ATLD和EEM-PARAFAC已在食品中药领域得到了广泛应用[14, 15]。
随着大数据技术的发展, 对EEM数据进行预处理(包括去散射, 平滑, 数据重构, 提取特征参量)后, 构建大数据模型更适用于掺假食品的定性定量分析[16]。 人工神经网络(artificial neural network, ANN)是依据误差反向传播构建的数据模型, 是现在最常用的非线性模型。 偏最小二乘(partial least squares regression, PLS), 它可将大量的变量转化为少量的潜变量来建立多变量信号与目标值之间的线性关系。 在多元校正过程中, 光谱数据存在多重共线性、 噪声大、 变量多的问题, PLS则可以很好地解决。 ANN和PLS算法具有优良的回归性能, 已广泛地应用到食品药品的定量分析[17, 18]。
本文测定大豆油掺花生油伪品的EEM, 删除瑞利散射和拉曼散射, 利用数据平滑技术删除噪声后, 利用ATLD和PARAFAC算法预测花生油的含量; 同时, 利用小波包分解(wavelet packet decomposition, WPD)EEM数据, 提取激发波长对应的发射波长的最低频段小波系数, 重构数据后, 利用ANN和PLS算法预测伪品中花生油的含量。 对比三线性分解算法和小波包分解结合一阶数据回归算法两种策略, 构建4种算法模型, 对比其预测效果, 寻求最佳建模方案, 为实现快速检测掺假食用油含量。 同时, ATLD和PARAFAC算法通过数学分离, 计算样本中化合物的含量, 本研究计算花生油和大豆油的含量。 拓展了WPD算法在荧光光谱中的应用, 使之成为光谱数据处理的一种工具。 本研究思路与结果为食用油掺假定量鉴别提供了一种新途径, 也为相关部门及企业提供了参考依据。
荧光分光光度计F-7000, 日本日立株式会社。 品牌花生和大豆油购于许昌市胖东来超市。
1.2.1 样品的制备
从市场上3个不同批次的大豆油和花生油, 勾兑成大豆油与花生油的伪品, 花生油含量0~100%(体积比), 步长为5%。 共计63个样本。
1.2.2 EEM数据采集
将自制的花生油伪品放入10 mm× 10 mm石英荧光比色皿中测量, 其光源为150 W氙灯, PMT电压为700 V。 激发波长范围为250~550 nm, 采样间隔为10 nm, 共包含31个激发波长。 发射波长范围为260~750 nm, 采样间隔为10 nm, 共包含50个发射波长。 扫描速度为12 000 nm· min-1, 使用荧光光谱仪前预热30 min。
实验得到63个50× 31二维数据矩阵, 采用三角形内插值法去除拉曼散射和瑞利散射[19]。 去除拉曼散射和瑞利散射后再对荧光光谱进行卷积平滑(Savitzky-Golar)处理。
将每条激发波长下的发射波长展开, 并按照激发波长顺序数将所有发射波长重构, 从而将原EEM的二阶数据转化成一阶荧光光谱数据向量。 采用WPD对每个激发波长对应的发射光谱进行分解[16, 17, 18, 19, 20], 计算小波系数。 WPD的基函数一般采用4 阶Symlet小波。 选择3层WPD对EEM光谱数据进行分解。
EEM数据去除瑞利散射后对光谱进行Savitzky-Golar卷积平滑处理, 采用ATLD算法和PARAFAC算法预测花生油伪品中的花生油含量。 ATLD和PARAFAC算法请参考文献[21, 22]。 对EEM光谱数据进行Savitzky-Golar卷积平滑处理后, 进行3层WPD, 选取最低频段小波系数作为输入值, 花生油含量为输出值进行PLS和BP-ANN模型构建。 BP-ANN采用3层的网络结构: 输入层为199、 隐含层为4、 输出层为1, 训练函数为Scaled conjugate Gradient。 PLS算法、 ATLD算法和PARAFAC算法从样本中随机选取70%的样本构造训练集(43个样本), 30%的为测试集(20个样本)。 ANN算法随机选取70%的样本构造训练集(43个样本), 15%为测试集(10个样本), 15%为验证集(10个样本)。
使用平均绝对偏差(mean absolute deviation MAD)[式(1)]、 均方误差(mean squared error, MSE)[式(2)]和均方根误差(root mean squared error, RMSE)[式(3)]来评价模型[23]。
式(1)— 式(3)中: At为实际花生油含量; Ft为预测花生油含量; n为试验中使用的样品数。
采用软件Origin 2021(OriginLab公司)进行箱线图+正态曲线图的制作; PLS, ANN, ATLD, PARAFAC模型通过软件Matlab R2020b(美国MathWorks公司)自编程序完成。
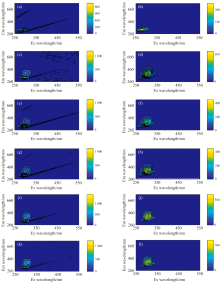
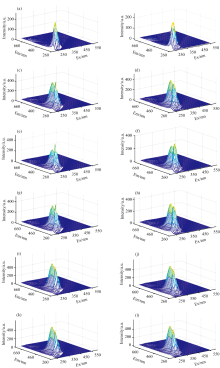
对大豆油、 花生油EEM光谱进行去散射处理前后情况如图1所示。 EEM光谱数据通过三角形内插值法消除瑞利散射和拉曼散射, 花生油和大豆油的EEM光谱存在差异。 结果表明, 纯花生油的EEM数据在(Ex=280 nm, Em=320 nm)附近有一个荧光强度较高的扇贝状峰, 纯大豆油的EEM数据在(Ex=300 nm, Em=410 nm)附近存在一个荧光强度较高的扇贝状峰, 但是花生油和大豆油荧光吸收峰的波长范围及荧光强度存在一定差异, 这可能是由于花生油含维生素E, 特别是α -生育酚, 而大豆油则以γ -生育酚为主, 其γ -生育酚EEM光谱特性与α -生育酚EEM光谱有差异, 另外可能是由于大豆油和花生油的加工条件差异所引起的, 维生素及其衍生物生育酚、 生育三烯酚所产生的EEM光谱主要在这个区域。 此外, 纯大豆油的EEM光谱在(Ex=330 nm, Em=400 nm)附近还有一个荧光强度较弱的峰, 这为大豆油掺假花生油提供了定量分析基础。 图2为EEM光谱平滑前后的对比图, 等高线边缘平整有利于后续进行花生油的含量预测。
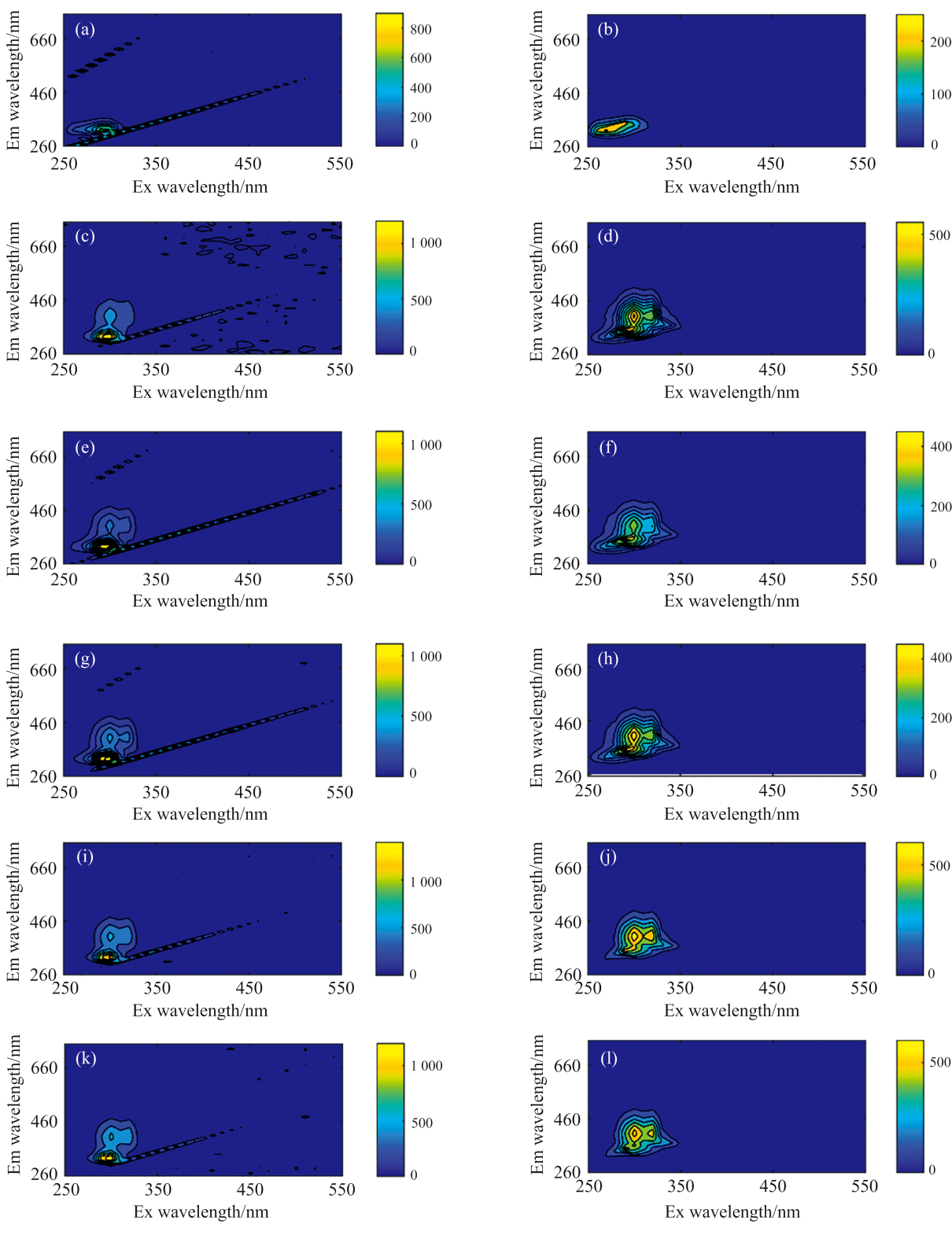 | 图1 大豆油和花生油去散射前后荧光光谱对比图 (a): 花生油荧光光谱去散射前; (b): 花生油荧光光谱去散射后; (c): 80%花生油荧光光谱去散射前; (d): 80%花生油荧光光谱去散射后; (e): 60%花生油荧光光谱去散射前; (f): 60%花生油荧光光谱去散射后; (g): 40%花生油荧光光谱去散射前; (h): 40%花生油荧光光谱去散射后; (i): 20%花生油荧光光谱去散射前; (j): 20%花生油荧光光谱去散射后; (k): 大豆油荧光光谱去散射前; (l): 大豆油荧光光谱去散射后Fig.1 Fluorescence spectra of soybean oil and peanut oil from before and after de-scattering (a): Peanut oil fluorescence spectrum before de-scattering; (b): Peanut oil fluorescence spectrum after de-scattering; (c): 80% peanut oil fluorescence spectrum before de-scattering; (d): 80% peanut oil fluorescence spectrum after de-scattering; (e): 60% peanut oil fluorescence spectrum before de-scattering; (f): 60% peanut oil fluorescence spectrum after de-scattering; (g): 40% peanut oil fluorescence spectrum before de-scattering; (h): 40% peanut oil fluorescence spectrum after de-scattering; (i): 20% peanut oil fluorescence spectrum before de-scattering; (j): 20% peanut oil fluorescence spectrum after de-scattering; (k): Soybean oil fluorescence spectrum before de-scattering; (l): Soybean oil fluorescence spectrum after de-scattering |
 | 图2 EEM光谱平滑前后对比图 (a): 花生油EEM平滑前; (b): 花生油EEM平滑后; (c): 80%花生油EEM平滑前; (d): 80%花生油EEM平滑后; (e): 60%花生油EEM平滑前; (f): 60%花生油EEM平滑后; (g): 40%花生油EEM平滑前; (h): 40%花生油EEM平滑后; (i): 20%花生油EEM平滑前; (j): 20%花生油EEM平滑后; (k): 大豆油EEM平滑前; (l): 大豆油EEM平滑后Fig.2 EEM spectra from before and after smoothing (a): Peanut oil EEM before smoothing; (b): Peanut oil EEM after smoothing; (c): 80% peanut oil EEM before smoothing; (d): 80% peanut oil EEM after smoothing; (e): 60% peanut oil EEM before smoothing; (f): 60% peanut oil EEM after smoothing; (g): 40% peanut oil EEM before smoothing; (h): 40% peanut oil EEM after smoothing; (i): 20% peanut oil EEM before smoothing; (j): 20% peanut oil EEM after smoothing; (k): Soybean oil EEM before smoothing; (l): Soybean oil EEM after smoothing |
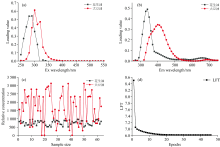
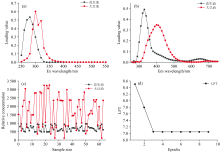
PARAFAC是利用最小二乘算法实现的一种多维数据基于三线性模型分解算法, 使用PARAFAC对EEM光谱数据三线性分解要进行降维和特征提取, 残差分析法和半劈裂分析(Split-half analysis)结合方差解释, 最终确定样品组分并验证平行因子模型的有效性[24]。 需要特别说明是, 所谓的“ 组分” 是荧光信号接近的物质(共因子)。 因此, 不需要进行降维和特征提取, 残差分析法和半劈裂分析(Split-half analysis)结合方差解释确定样品组分。 可以确定组分数为2。 经过PARAFAC 处理后, 得到了特征荧光组分的波长范围, 并通过载荷图确定了相应组分的最大激发和发射波长, 从图3(a, b)可以看出激发/发射波长为290/340 nm是花生油; 激发/发射波长为300/400 nm是大豆油。 图3(c)为相对浓度矩阵, 可以获得每个样本的浓度得分, 如此便可以得到伪花生油中花生油的含量。 图3(d)为迭代图, PARAFAC模型迭代了48次, 损失函数(loss function, LFT)值收敛。 PARAFAC的训练集, 测试集, 全部数据的回归系数R2分别为0.756, 0.895, 0.898。 PARAFAC模型预测花生油含量偏差在± 15%以内的样本为74.6%, 偏差在± 10%为61.9%, 偏差在± 5%为14.3%。 PARAFAC的误差函数值见表1, 训练集、 测试集和全部数据的MAD、 MSE、 RMSE均较大, 预测结果并不理想。
 | 图3 平行因子模型分析图 (a): 激发光载荷图; (b): 发射光载荷图; (c): 相对浓度; (d): 迭代曲线Fig.3 PARAFAC model analysis diagram (a): Loading diagrams of the excitation spectrum; (b): Loading diagrams of emission spectrum; (c): The relative concentration; (d): Iterative curve |
| 表1 PARAFAC模型误差函数值 Table 1 PARAFAC model error function value |
ATLD是基于三线性分析更高效的一种算法, 根据样品分解出来的组分轮廓进行定量分析[25]。 同样, 与PARAFAC算法相似, 组分数可以确定为2。 从图4(a, b)可以看出激发/发射波长为290/340 nm是花生油激发/发射波长为300/400 nm是大豆油。 ATLD的组分解析结果与PARAFAC的相同。 图4(c)为相对浓度矩阵, 获得每个样本的浓度得分, 也可以得到伪花生油中花生油的含量。 图4(d)为迭代图, ATLD模型迭代了9次, LFT值收敛。 相较于PARAFAC的迭代次数, ATLD的收敛速度明显更快。 ATLD的训练集, 测试集, 全部数据的R2分别为0.895, 0.826, 0.941。 ATLD模型预测花生油含量偏差在± 15%以内的样本百分比为93.65%, 偏差在± 10%为79.3%, 偏差在± 5%为50.8%。 ATLD模型预测效果优于PARAFAC模型。 ATLD模型的误差函数值见表2, ATLD模型的误差函数值除测试集的MSE外, 训练集、 测试集和全部数据的MAD、 MSE、 RMSE比PARAFAC模型小, 预测结果也并不理想。
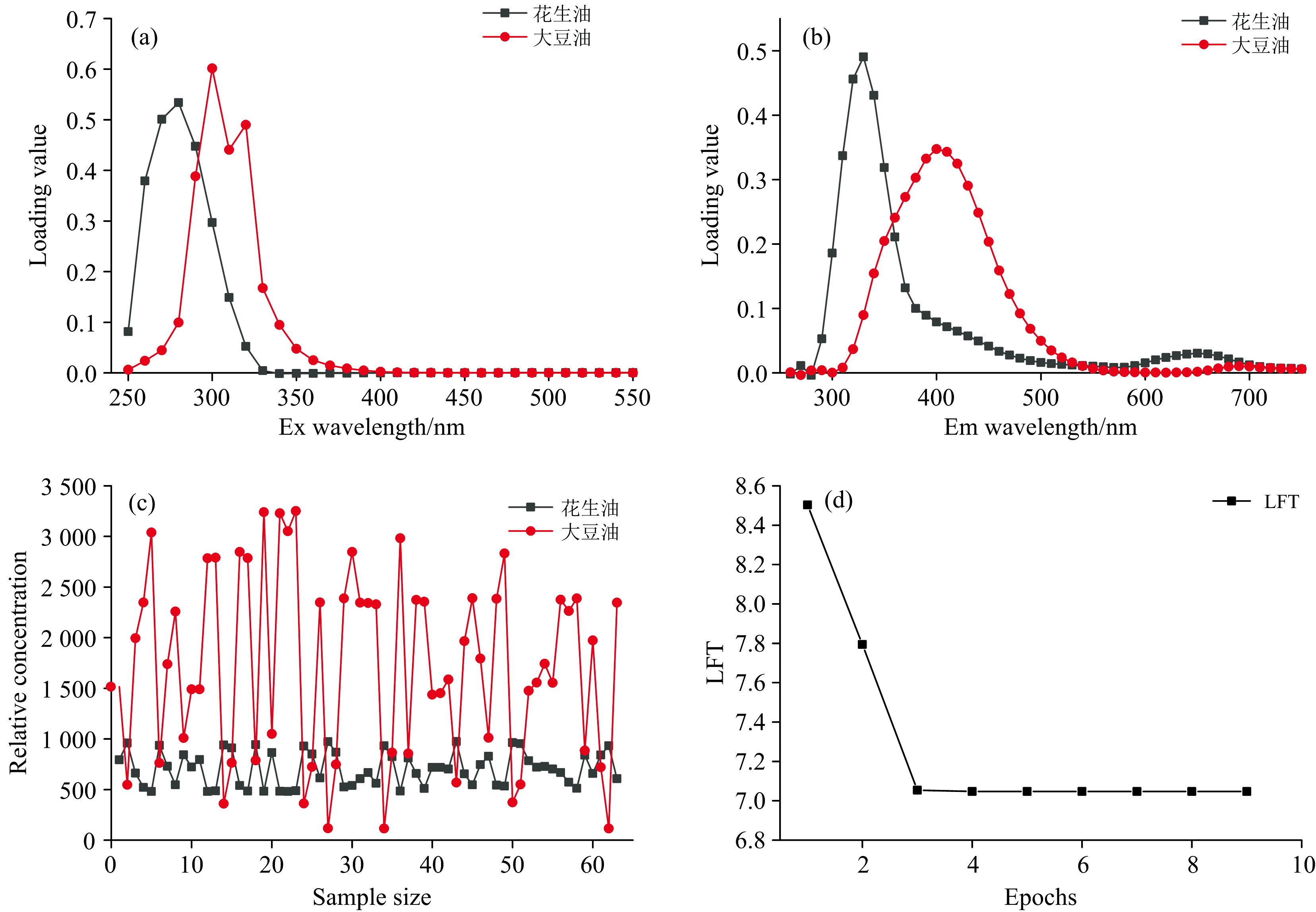 | 图4 交替三线性分解模型分析图 (a): 激发光载荷图; (b): 发射光载荷图; (c): 相对浓度; (d): 迭代曲线Fig.4 ATLD model analysis diagram (a): Loading diagrams of the excitation spectrum; (b): Loading diagrams of emission spectrum; (c): The relative concentration; (d): Iterative curve |
| 表2 ATLD模型误差函数值 Table 2 ATLD model error function value |
对EMM进行消除拉曼和瑞利散射, 平滑处理后的数据进行小波分解, 每个样本得到最低频段的小波包系数为199个, 以小波包系数表征不同样本EEM光谱。
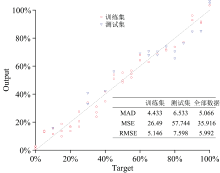
PLS是在20世纪70年代作为一种经济学工具发展起来, 后来作为一种统计学工具在需要领域被应用, 尤其是化学计量学和社会科学[26]。 PLS在食品行业中已经获得了普及, 因为它能够通过多变量线性模型将两组不同性质的数据相关联起来, 能够在有多重共线性即自变量之间也存在线性关系的情况下对数据进行建模, 在样本数量小于预测变量数量的情况下同样可行[27]。 PLS是一种多因变量对多自变量的一阶数据回归建模方法, 伪品中花生油的含量是因变量, 每个样本的最低频段小波包系数是自变量, 构建的WPD-PLS模型的训练集、 测试集与总体数据的回归系数R2分别为0.969, 0.907, 0.961。 图5为伪品中预测花生油含量训练集和测试集的真实值和预测值的对比图。 WPD-PLS算法模型的预测结果与真实值的偏差全部在± 15%以内, 偏差在± 10%的样本百分比为92%, 在± 5%为52%。 如图5所示, WPD-PLS算法模型训练集、 测试集和全部数据的MAD、 MSE、 RMSE均较小, 优于ATLD与PARAFAC模型。
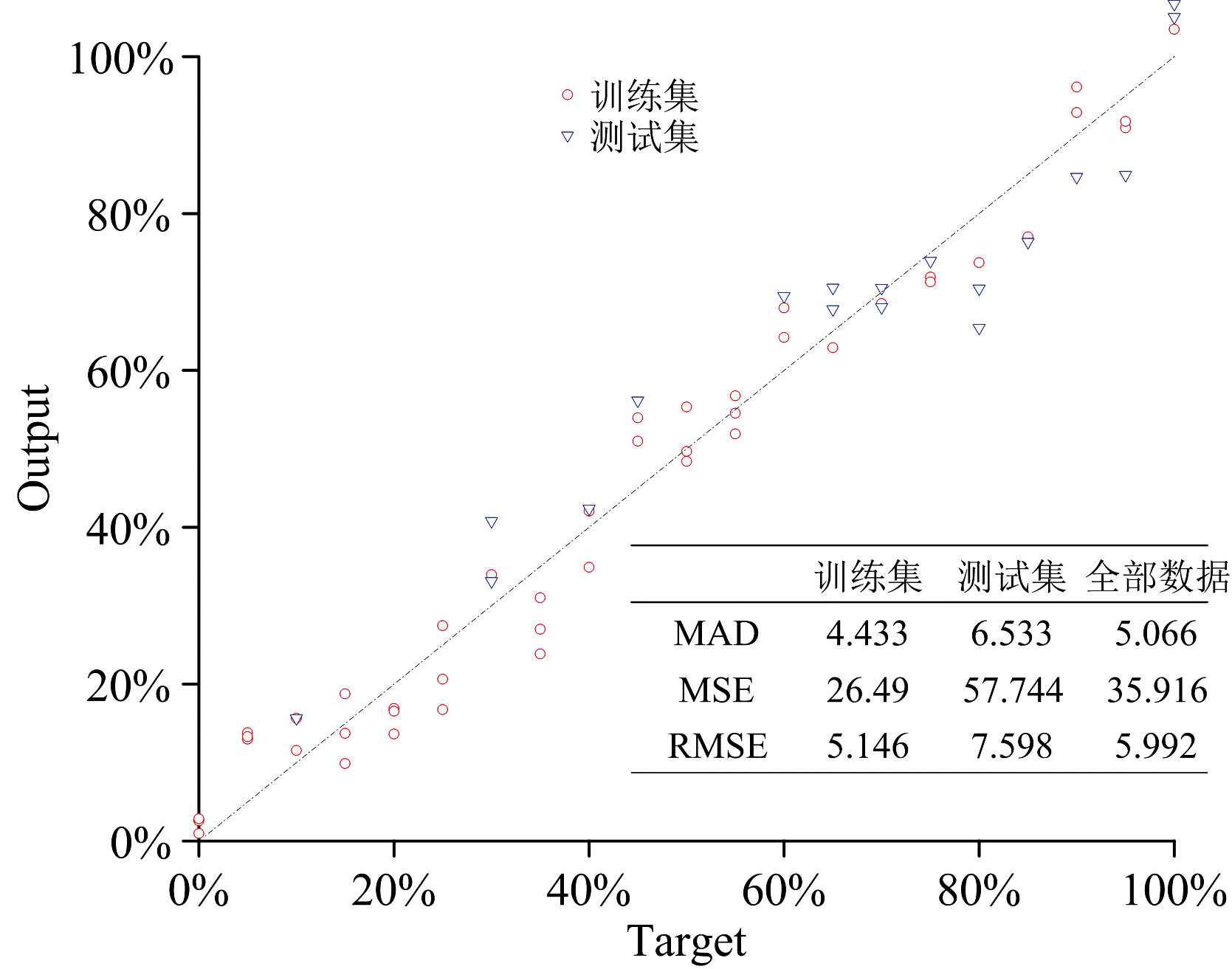 | 图5 PLS回归曲线及误差函数Fig.5 PLS regression curve and error function value |
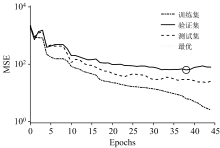
WPD分解EEM数据后, 重构的EEM数据为一阶数据, ANN构建的模型的训练曲线如图6, WPD-AAN算法模型的MSE值越小, 模型预测花生油含量试验数据的精确度越高。 当训练步数逐渐增加时, MSE逐渐趋近于误差的最优值。 WPD-ANN算法模型训练迭代到38次时, 训练集和测试集的MSE已低于验证集最优值, MSE为63.52; 说明该模型能够满足需求; 同时, 在验证集的MSE曲线增加之前, 测试集的MSE曲线未显著增加, WPD-ANN算法模型训练完成。 如图7所示, WPD-ANN算法模型的训练集、 验证集、 测试集和全部数据的MAD、 MSE、 RMSE均较小, 是4种算法模型中最优的。
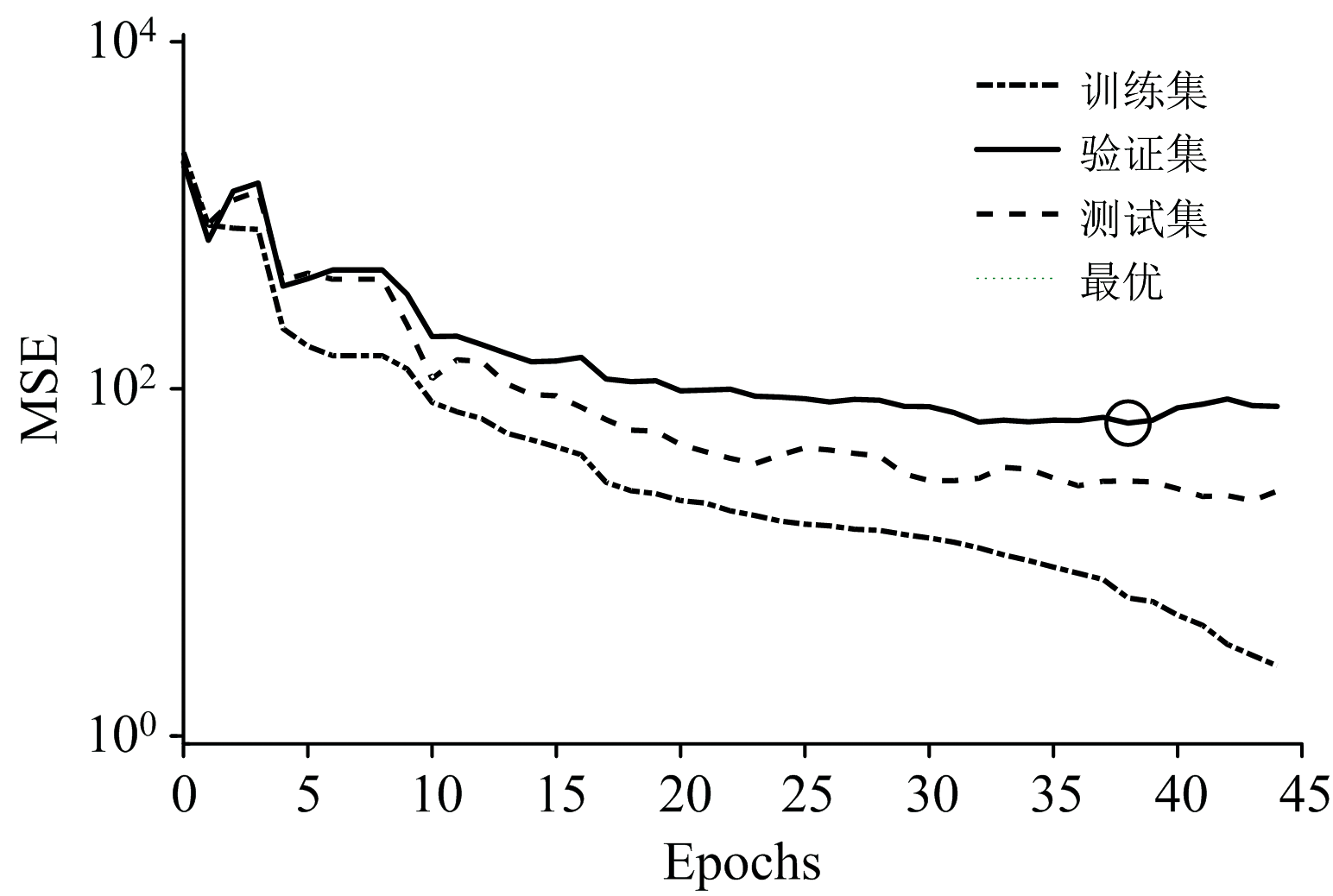 | 图6 人工神经网络训练曲线Fig.6 ANN training curve |
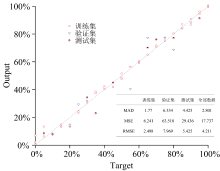
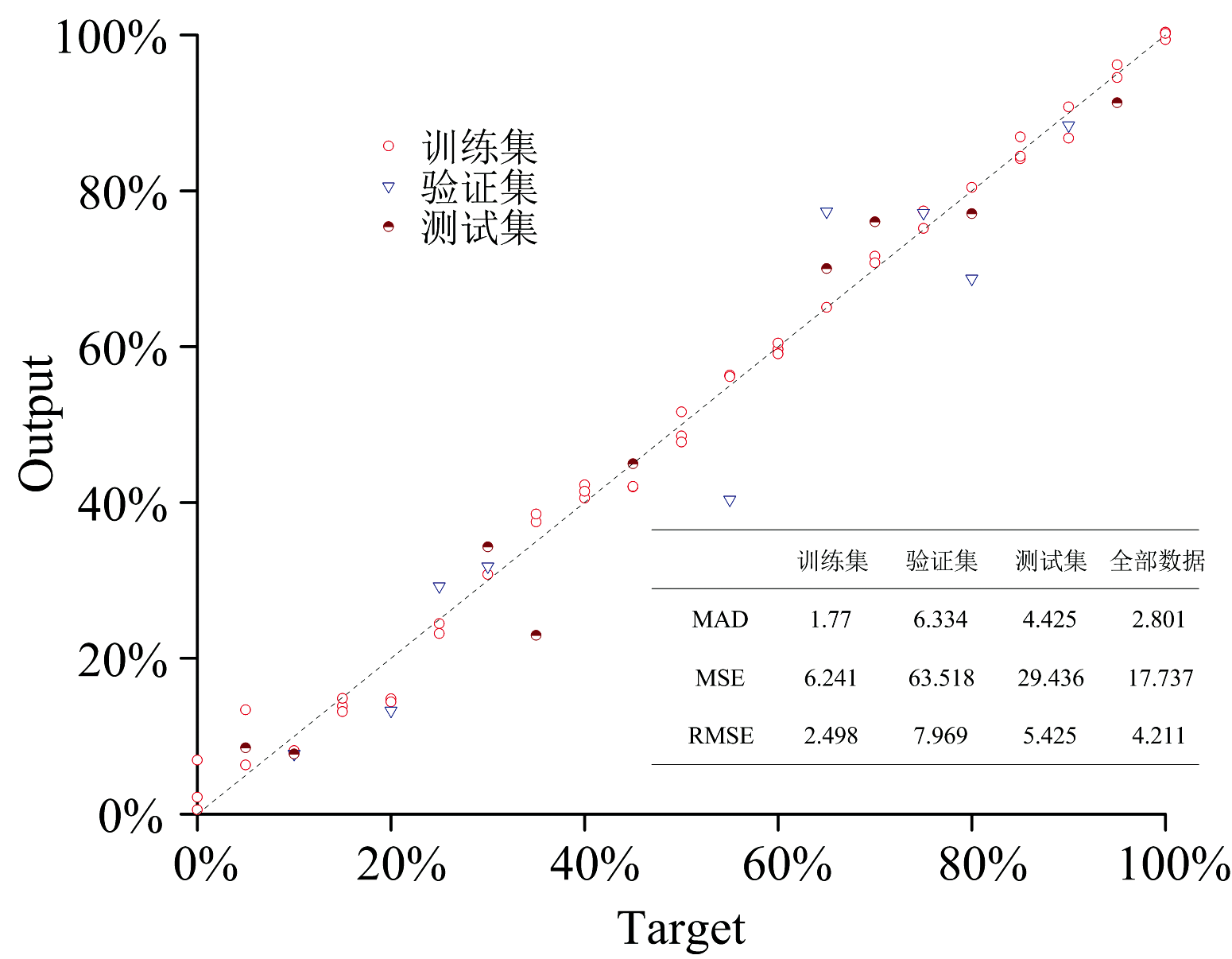 | 图7 人工神经网络的回归曲线及误差函数值Fig.7 ANN regression curve and error function value |
WPD-ANN模型预测伪品中花生油含量的训练集、 验证集、 测试集和全部数据预测结果与真实值的散点图如图7所示。 WPD-ANN算法模型的训练集、 验证集、 测试集与总体数据的回归系数R2分别为0.992、 0.925、 0.966和0.981, 表明WPD-ANN模型随机验证效果良好, WPD-ANN模型能很好地描述EEM和伪花生油中花生油含量的关系。 真实值与预测的数据点几乎都在直线Y=X附近, 表明伪品中花生油含量和WPD-ANN模型的预测值之间具有较好的兼容性。 WPD-ANN模型预测值与真实值的偏差全部在± 15%, 偏差在± 10%的样本百分比为93.6%, 偏差在± 5%为82.5%。 因此, 该WPD-ANN算法模型对伪花生油中花生油含量具有很强的预测能力且误差较小。 因此, WPD-ANN模型能够预测EEM与花生油含量之间的关系。
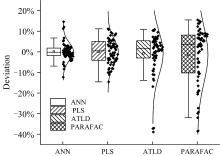
原始EEM数据通过三角形插值法去除了拉曼散射和瑞利散射, 进行PARAFAC与ATLD运算, ATLD明显所需内存大大减少, 提高运算的效率, 是迭代算法中收敛速度较快的一种算法。 通过WPD后, 进行PLS和ANN运算, PLS基于线性算法, 而ANN算法中使用激活函数, 基于非线性运算。 4种算法预测值与真实值的偏差箱线图和正态分布曲线图如图8, 箱线图具有一定的识别异常值的能力。 从图8表明, WPD -ANN算法模型偏差异常值为6个, WPD-PLS算法模型没有异常值, ATLD算法模型的异常值为6个, PARAFAC算法模型的异常值为3个。 产生异常值可能是由于不同批次的花生油和大豆油成分的差异造成的。 同时, 对于标准正态分布的样本, 异常值只占很小的比例。 如图8, WPD-ANN和WPD-PLS模型偏差的均值和中位数都在0%附近, 而ATLD和PARAFAC模型偏差的均值和中位数离0%较远。 PARAFAC, ATLD, WPD-PLS, WPD-ANN模型预测花生油含量偏差在± 15%以内的样本分别为74.6%, 93.65%, 100%, 100%; 偏差在± 10%分别为61.9%, 79.3%, 92%, 93.6%; 偏差在± 5%分别为14.3%, 50.8%, 52%, 82.5%。 原因为ATLD和PARAFAC都是基于求解三线性分量模型的算法, 在处理EEM数据时, 计算结果可能受到非线性因素的影响[21], 例如高浓度物质与荧光强度不是线性关系。 ANN和PLS是基于WPD及数据重构后一阶数据回归建模, 由于的荧光光强为吸收的激发光光强和荧光效率的乘积, 荧光强度只有在低浓度时荧光物质浓度成正比, PLS是线性模型, 而ANN是非线性模型。 因此, WPD-ANN算法偏差最小, 是4种算法中最优的。
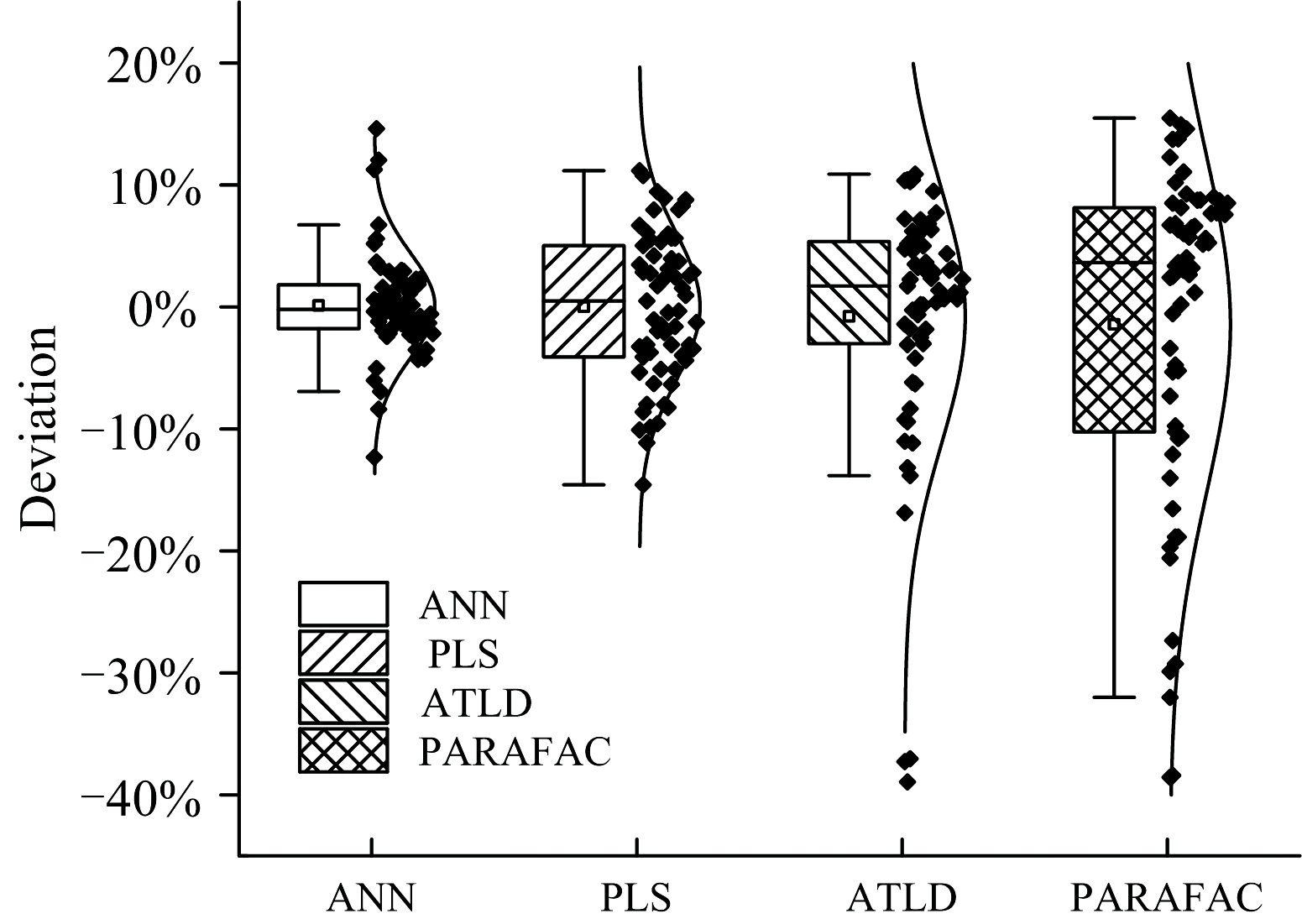 | 图8 4种算法偏差的箱式图及正态分布图Fig.8 Prediction deviation box and Normal distribution diagram of 4 algorithms |
采集不同花生油含量的伪花生油EEM光谱数据, 对荧光数据去除瑞利和拉曼散射、 平滑处理后。 然后利用PARAFAC和ATLD建模, 实现对伪品中花生油含量的预测。 对EEM数据去除瑞利和拉曼散射、 平滑处理后, 利用WPD提取伪花生油EEM数据最低频段小波系数。 以小波系数为自变量, 花生油含量为因变量, WPD-PLS和WPD-ANN算法建模。 通过构建4种算法模型实现了伪品中花生油含量的测定。 这为后续利用EEM技术测定掺假食用油含量提供了技术参考。 同时, 得到以下结论: (1) 利用三角形内插值法消除EEM数据的散射(包括拉曼散射和瑞利散射), 解卷积平滑EEM数据, WPD分解EEM数据, 得到最低频段小波系数。 数据重构后, 利用ANN模型对伪品中的花生油含量进行预测, WPD-ANN模型预测偏差在± 5%以内的样本百分比为82.5%。 因此, WPD-ANN模型对伪花生油中花生油含量具有很强的预测能力且误差较小, 从而为伪食用油中真品含量预测提供更有效的数据表征模式。 (2) 对比分析了WPD-ANN, WPD-PLS, ATLD和PARAFAC 4种算法模型的花生油含量预测结果。 相较于PARAFAC模型, ATLD的收敛速度更快, 偏差更小。 ATLD和PARAFAC模型可能受到非线性因素的影响, 预测效果不及WPD-ANN及WPD-PLS, 同时ANN基于非线性模型, ANN算法偏差更小, 是预测伪品中花生油含量更优的算法。 这一方法对其他流体食品(例如, 蜂蜜, 酿造食醋, 酿造酱油等)掺假含量鉴别也有一定的借鉴价值。 但对于多种掺假物(例如多种食用油掺假)含量计算, 还需进一步研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|