
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于太赫兹时域光谱的淀粉品种分类研究
[魏涛1, 2, 3, 4  , 王恒
, 王恒1, 2, 4 , 葛宏义1, 2, 4 , 蒋玉英1, 2, 5, * , 张元1, 2, 4, 5 , 温茜茜1, 2, 4 , 郭春燕1, 2, 4 ]
, 王恒, 张元|
|


作者简介: 魏 涛, 1981年生,河南工程学院软件学院副教授 e-mail: wt20240128@163.com
淀粉作为一种主要的储存碳水化合物, 是人类饮食中的主要能量来源, 提供了人体50 %以上的能量需求。 同时, 淀粉及其深加工行业是关乎国计民生的基础产业。 然而, 鉴于淀粉种类的多样化, 并且它们在外观上相似度较高, 直接对它们进行区分比较困难, 一些不法商家往往会将价格较低的淀粉包装成价格较高的淀粉来抬高价格。 因此, 对淀粉品种进行分类对我国食品加工和工业生产具有重要的实际应用意义。 太赫兹(Terahertz, THz)技术作为一种高效的非破坏性、 非接触和无标签的光学方法, 在与物质作用时不会发生有害的电离辐射, 可同时获得样品的吸收系数等光学参数, 具有较高的信噪比和检测灵敏度, 已被众多学者应用于农产品品质检测方面。 为实现对淀粉品种的快速无损鉴别, 从禾谷类淀粉与根茎类淀粉中选取了五种最为常见的淀粉样品作为样本, 利用太赫兹时域光谱(THz-TDS)技术获取其光谱?畔ⅲ?并根据实验数据计算了不同品种淀粉在0.2~1.2 THz波段的吸收系数; 之后结合Savitzky-Golay(S-G)平滑、 多元散射校正(MSC)、 标准正态变换(SNV)三种预处理方法对原始光谱进行处理。 采用主成分分析(PCA)根据累计贡献率超过95%提取特征数据, 选取了前3个主成分, 随后应用支持向量机(SVM)方法建立多分类模型。 选取了三种核函数(linear, radial basis functions, polynomial)对不同品种淀粉类型进行了识别。 结果显示: PCA-SVM-polynomial结合SG平滑对淀粉品种分类建模效果最好, 其中测试集平均准确率为0.941 9, Kappa系数为0.933, F1得分为0.941 7。 此外, 还将该方法与逻辑回归(LR)、 决策树(DT)、 随机森林(RF)进行了比较, 研究结果表明PCA-SVM优于其他方法, 也证明了太赫兹技术对淀粉品种鉴别的可行性, 对食品加工业的现代化及淀粉基产品的开发具有重要的实际应用价值。
, WANG Heng, ZHANG YuanAs a major stored carbohydrate, starch is a major source of energy in the human diet and provides more than 50% of the energy needs of the human body. Meanwhile, the starch and its deep-processing industry are fundamental to the national economy and people's livelihoods. However, due to the diversity of starch types and their high similarity in appearance, it is relatively challenging to distinguish amongthem directly. Some illegal merchants often package lower-priced starches as higher-priced starches to increase profits. Consequently, the classification of starch types has significant practical relevance for food processing and industrial production in China. Terahertz (THz) technology, as an effective non-destructive, non-contact, and label-free optical approach, does not produce harmful ionizing radiation during interactions with materials,and can obtain optical parameters such as the absorption coefficient of samples simultaneously. It has a high signal-to-noise ratio and detection sensitivity, and many scholars have applied it to the quality detection of agricultural products. Five of the most common starch samples were selected from cereal starch and rhizome starch to achieve rapid and non-destructive identification of starch. The spectral information was obtained using Terahertz time-domain spectroscopy (THz-TDS) technology, and the absorption coefficient of different starch varieties in the range of 0.2~1.2 THz was calculated based on the experimental data. Subsequently, the original spectra were processed using three preprocessing methods: Savitzky-Golay (S-G) smoothing, multiplicative scatter correction (MSC), and standard normal variate (SNV). Principal component analysis (PCA) was employed to extract feature data based on a cumulative contribution rate exceeding 95%, resulting in the selection of the first three principal components. A multi-classification model was established using the support vector machine (SVM) method. Three types of kernels (linear, polynomial, and radial basis functions) were selected to identify different varieties of starch. The results showed that the PCA-SVM-polynomial combined with SG smoothing achieved the best modeling performance for starch variety classification, with an average accuracy of 0.941 9 on the test set, a Kappa of 0.933, and an F1 score of 0.941 7. Furthermore, this method was compared with logistic regression (LR), decision tree (DT), and random forest (RF). The research results indicated that PCA-SVM was superior to other methods,proving the feasibility of THz technology for starch variety identification and demonstrating important practical application value for the modernization of the food processing industry and the development of starch-based products.
淀粉作为一种主要的储存碳水化合物, 是人类饮食中的主要能量来源, 提供了人体50 %以上的能量需求[1]。 同时, 淀粉作为农副产品的重要组成部分, 在食品加工业和化学工业中扮演着至关重要的角色[2]。
近年来, 淀粉的生产和加工贸易呈现出明显的发展趋势[3], 应用范围极为广泛。 然而, 不同品种的淀粉价格相差很大, 但它们在外观上的差异却相对较小, 很难用肉眼直接进行识别。 以往, 淀粉种类的鉴别主要依赖传统的感官评定方法, 具有分析简单、 方法直观等优势, 但是这些方法容易受主观因素的影响, 准确度无法得到有效保证。 常规基于理化分析的质谱法(mass spectrometry, MS)[4]虽然精度较高, 但样品预处理十分复杂, 且设备维护成本高, 需要专业人员操作, 费时费力[5]。 基于生物物种特定片段的DNA条形码技术[6]操作简单, 重复性和稳定性高, 但需要对样品进行标定, 易破坏样本的完整性, 难以满足当前市场条件下无损检测的需求。 因此, 当前市场亟需一种能够弥补上述方法缺陷的检测手段。 近年来光谱法作为一种用于定性和定量分析的现代分析技术, 与传统的物理和化学检测方法相比, 具有快速、 无污染、 无需样品预处理、 可同时检测多种成分等优点[7, 8], 已广泛应用于农作物质量鉴别[9]、 农产品品质分析[10]和农业生产安全保障等领域[11]。 尽管以上方法可有效解决传统技术检测准确性不佳、 存在主观性等问题, 然而依然存在一些局限性, 如近红外光谱吸收强度弱, 分析困难, 且信噪比与检测灵敏度相对较低[12]; 拉曼光谱存在信号强度较低, 荧光干扰强等不足[13]; 高光谱成像技术检测速度慢, 数据维度高, 光谱信息大量冗余[14]; 荧光光谱吸收峰重叠严重, 响应值不稳定[15]。
太赫兹波[16]频率位于0.1~10 THz之间, 具有能量低、 穿透性强、 电离辐射小等特征。 太赫兹技术作为一种高效的非破坏性、 非接触和无标签的光学方法, 在与物质作用时不会发生有害的电离辐射, 具有较高的信噪比和检测灵敏度, 已被众多学者应用于农产品品质检测方面, 如农产品掺假[17]、 食品加工分析[18]、 农作物主要成分含量检测[19]、 转基因农作物鉴别[20]。 这些结果表明, 利用太赫兹光谱技术对淀粉品种进行检测鉴别是可行的。 本研究以最常见的五种食用淀粉(玉米、 小麦、 木薯、 红薯、 马铃薯淀粉)为研究对象, 利用太赫兹时域光谱技术与多种光谱预处理、 机器学习分类方法结合, 建立了淀粉品种的无损检测判别模型, 为淀粉品种的识别提供了一种高效的技术手段。
本研究的实验样品均采购于郑州市中原区当地农贸市场, 由玉米淀粉、 小麦淀粉、 木薯淀粉、 马铃薯淀粉和红薯淀粉组成, 主要厂商包括: 双塔(山东烟台)、 新良(河南新乡)、 古松(河北廊坊)、 展艺(浙江嘉兴)及古福(天津静海)。 采购的五类淀粉分别符合GB/T 8885— 2017《食用玉米淀粉》、 GB/T 8883— 2017《食用小麦淀粉》、 GB/T 29343— 2017《食用木薯淀粉》、 GB/T 8884— 2017《食用马铃薯淀粉》与GB 31637— 2016《食用安全国家标准-食用淀粉》标准。
本文采用型号为QT-TO1000的太赫兹时域光谱(Terahertz time-domain spectroscopy, THz-TDS)系统作为实验装置, 其原理为飞秒激光通过光纤传输到太赫兹发射天线, 在偏置电压的作用下产生太赫兹脉冲, 太赫兹脉冲经过透镜的准直与聚焦穿过待测样品后, 再通过对称的透镜准直聚焦到达太赫兹接收天线。 太赫兹接收天线进行光电信号转换后通过采集系统将信号采集, 并通过上位机系统对信号进行处理与显示。 实验过程中, 将实验室室温控制在292 K, 相对湿度控制在25%。 该系统频率范围为0.1~3.5 THz, 扫描范围为180 ps, 最大探测厚度为9 mm, 信噪比大于70 dB, 工作模式选择透射模式。
在样品制备时, 首先将每种淀粉样品通过玛瑙研钵研磨至粉末, 并通过200目筛网过滤以获得均匀的细粉。 之后, 每次用精密电子天平称200 mg的淀粉放入模具, 为了确保样品压片制作的合格性, 需要对模具中的样品粉末进行震荡处理, 直至其形成与模具平行的平面。 随后, 将完整的样品粉末连同模具一起放入压片机, 并施加10 MPa的压力, 持续2~3 min, 将粉末压制为直径约13 mm, 厚度约为1 mm的表面光滑无裂纹且均匀的圆形薄片, 压制完成后使用游标卡尺对薄片进行厚度测量。 五种淀粉样品各压制15个待测样片, 共计75个。 部分样本如图1所示。
 | 图1 部分实验样品实物图Fig.1 Physical diagrams of some experimental samples |
在测量前, 先将太赫兹系统进行30 min的预热, 以确保光谱信号的稳定性。 待系统稳定后, 对样品进行透射光谱扫描, 获取不同品种淀粉在0.2~1.2 THz范围内的时域光谱信息。 为减少测量误差, 提高数据精度, 每个样本点的光谱均为测量1 000次后取平均的结果。 为了更真实地表征样品的THz光谱, 每个淀粉样片均在10个不同位置各测量1条光谱数据, 最终得到每个样片的10条光谱数据。 其中每类淀粉的太赫兹时域光谱各150条, 共采集到750条光谱数据, 作为后续实验分析和模型训练使用的样本。 随后, 通过快速傅里叶变换(fast Fourier transform, FFT)将采集到的时域信号转换成频域信号, 然后依据Dorney[21]等和Dubillaret[22]等提出的光学参数提取方法获取所需的折射率、 吸收系数光谱信息, 对在透射模式下的太赫兹光谱吸收特性进行描述。 根据菲涅尔公式, 大多数低损耗材料的THz振幅透射率可用式(1)形式表示
式(1)中, Eref(ω )和Esam(ω )分别为参考信号与样品信号的太赫兹频域谱; A和φ 分别为参考信号与样品信号的幅值比和相位差, n为样品的折射率, ω 为角频率, d为压片的厚度信息, N为样品的复折射率, c是真空中的光速。 通过式(1)可以得到折射率、 消光系数和吸收系数等参数的计算公式
1.4.1 光谱预处理方法
获取到的太赫兹光谱除了有可以反映样品本身的数据信息外, 也存在一些与样品本身性质无关的干扰信息, 如样品背景、 噪声、 器件响应等, 这些干扰不仅影响光谱有效信息的提取, 而且影响分类模型的建立与最终的预测效果。 选取合适的预处理方法可以有效地消除干扰与冗余, 突出有效信息, 获取到高信噪比的数据, 而方法不当可能会导致信号的丢失或失真[23]。 因此, 采取恰当的光谱预处理算法在光谱化学计量学模型分析中至关重要。
本研究为了寻求对淀粉样品光谱最优的预处理方法, 主要用到了S-G平滑、 多元散射校正(multiplicative scatter correction, MSC)及标准正态变换(standard normal variate, SNV)三种预处理方法, 光谱预处理技术是为了消除光谱数据中的冗余信息, 提高模型判别的稳定性与准确性[24]。 不同预处理方法的类别及名称、 主要作用如表1所示。
| 表1 光谱预处理方法及其作用 Table 1 Spectral pretreatment methods and their functions |
1.4.2 光谱特征提取
由于样品光谱数据量较大, 会降低模型判别的精度与效率, 因此在建立分类模型时还需进行降维处理。 PCA是机器学习中应用最为广泛的特征提取与减少数据量的方法。 该方法通过提取表征样品主要特征的成分, 这些新变量能够尽可能多地反映原来变量的信息, 且彼此互不相关[25]; 具有最小的信息损失的可能性, 并可以对原始数据按其显著性进行排序[26], 同时降低数据维数, 提高模型识别的准确性与鲁棒性。
1.4.3 建模方法
机器学习方法能够自动挖掘光谱数据中的统计规律, 提取光谱曲线的特征, 并对复杂成分的光谱数据进行定性或定量分析, 适用于不同淀粉品种的分析与判别模型的构建。 为了进一步探讨不同机器学习分类方法在淀粉鉴别中的应用效果, 本实验选择支持向量机(support vector machine, SVM)、 逻辑回归(logistic regression, LR)、 决策树(decision tree, DT)和随机森林(random forest, RF)四种进行研究。
支持向量机: SVM是一种基于统计学习理论的监督学习分类算法。 它最初由Vapnik和Chervonenkis于1963年提出[27], 其本质是寻找最优超平面, 使每一类样本中的样本与支持向量的距离尽可能大, 而支持向量就是每一类样本中离最优超平面最近的样本。 为解决非线性问题, SVM引入了核函数, 将数据从原始特征空间映射到高维空间, 使得原本线性不可分的数据变为线性可分。
逻辑回归: LR是一种应用广泛的多元特征与二元响应变量之间关系建模的经验方法, 通过构建因变量(响应变量)与多个自变量(预测变量)之间的线性关系, 并利用非线性链接函数预测样本类别归属的概率。 由于其简单性和比其他非线性分类算法更高的预测精度, 已经成为一种常见的用于光谱分类的方法[28]。
决策树: DT分类是基于监督学习的, 通过输入带有标签的训练样本, 最后得到理想的分类效果[29]。 决策树是一种树形结构的分类模型, 其构建过程通常包括以下几个步骤: 数据收集、 数据准备、 选择合适的划分算法、 构建决策树、 模型测试及应用。 通过对样本特征进行递归划分, 决策树逐层构建树状结构, 每个节点根据特征的取值将样本分配到不同的分支, 最终在叶子节点上完成类别分类。 决策树算法能够有效处理高维数据, 并且具有较高的可解释性, 易于理解和应用。
随机森林: RF是一种基于决策树的集成学习算法, 具有良好的准确性和精度, 并且能够有效地处理高维数据和缺失数据, 通过构建和聚合多个决策树来提高模型的性能[30]。 其核心思想是通过构建多个决策树, 结合它们的结果实现样本的分类或回归。 它通过一系列的决策规则对数据进行分类或预测, 每棵树由多个节点组成, 每个节点代表一个决策点, 根据一个特征的值将数据划分到不同的分支中。
1.4.4 模型评价指标
验证和评估过程对于验证判别模型的性能至关重要。 本研究在模型构建过程中, 采用随机抽样方法将样本集分为训练集(70%)和测试集(30%), 以确保模型评估的科学性和有效性。 并将准确率、 精确率、 召回率、 F1分数及Kappa系数作为模型的评价指标, 计算公式如式(5)— 式(9)
其中, TP表示真实正样本被分为正样本的数量, TN表示真实负样本被分为负样本的数量, FP表示真实负样本被错误分为正样本的数量, FN表示真实正样本被错误分为负样本的数量。 p0为总体分类精度, 表示正确分类的每类样本数量之和与样本总数之比。 pe为所有类别的实际与预测数量乘积之和, 再除以样本总数的平方。
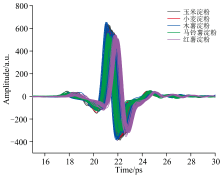
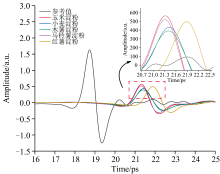
通过实验获取了五种淀粉共计750个样本的THz时域光谱。 如图2所示, 这些样本的时域波形在整体上表现出较高的相似性, 这表明系统具有良好的一致性。 为了进一步确定不同种类的淀粉之间存在的差异, 将每种淀粉的150个时域光谱数据平均化, 结果如图3所示。 从其平均时域波形可知, 与参考信号相比, 所有淀粉样品的光谱总趋势是一致的, 信号在幅值上均表现出一定程度的衰减, 且在时间上呈现出相应的时延, 表明淀粉对THz光谱具有一定的吸收特性。 此外, 每种淀粉的峰值衰减程度随着时间的推移有所不同。 如玉米淀粉的表现出最小的振幅衰减, 而木薯淀粉的振幅衰减最为明显, 这表明不同淀粉之间可能对太赫兹光谱的吸收特性不同, 从而影响太赫兹脉冲信号在样品内的传播速度和吸收水平。
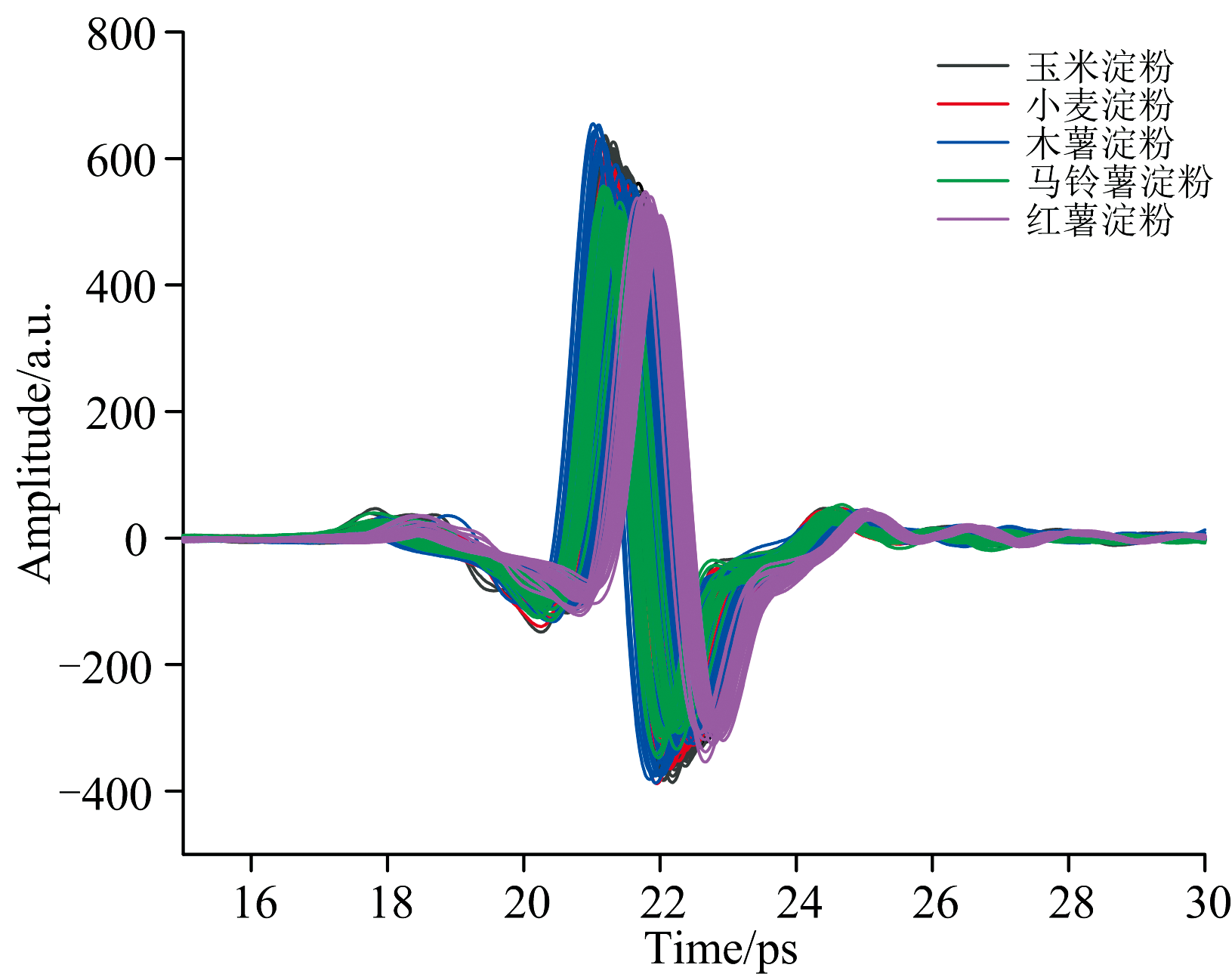 | 图2 750个淀粉样本的THz时域光谱Fig.2 THz time-domain spectra of 750 starch samples |
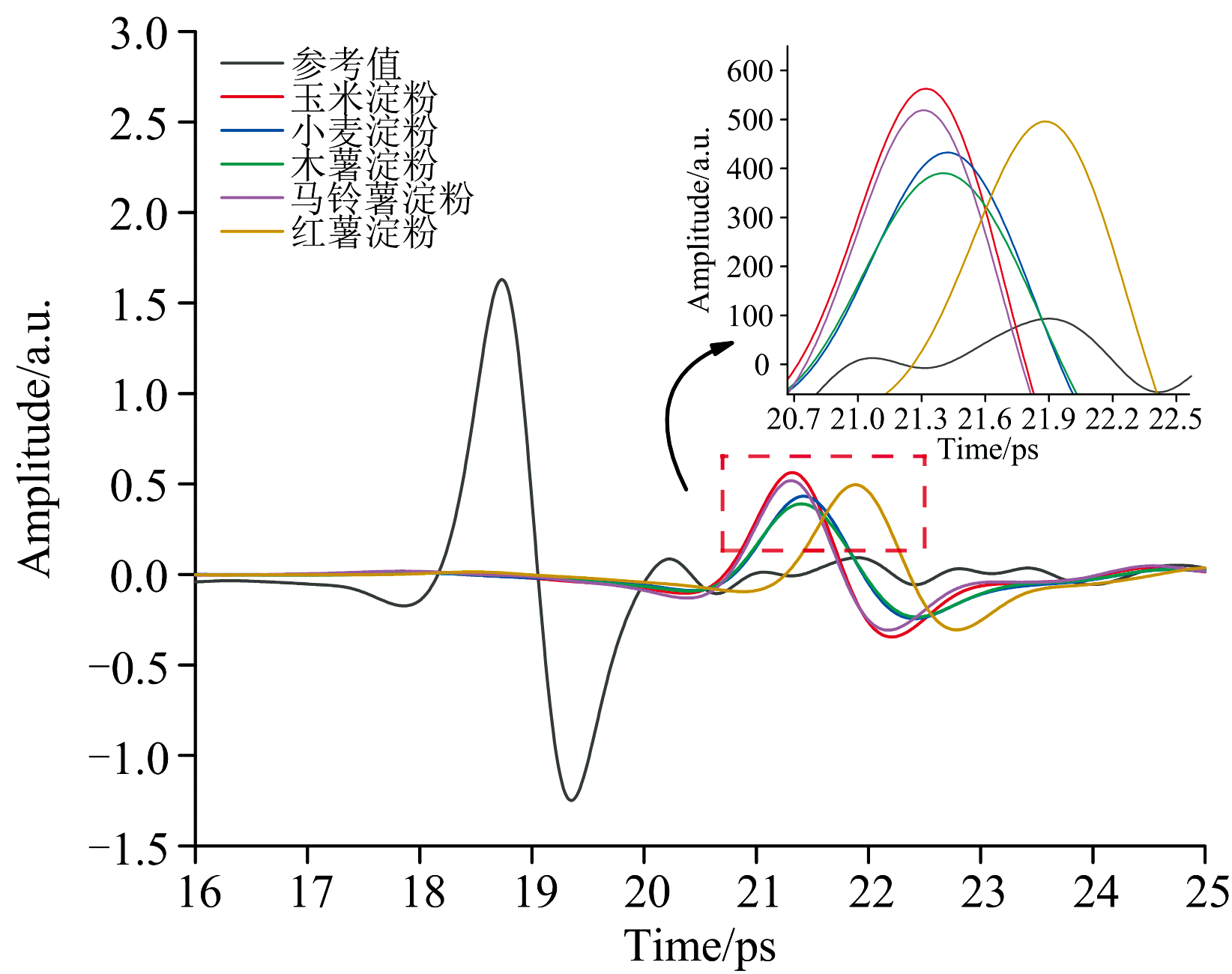 | 图3 五种淀粉的平均时域光谱图Fig.3 Mean time-domain spectra of five types of starch |
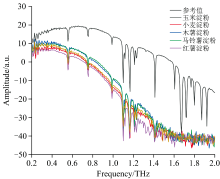
为了深入分析5种淀粉在THz波段的频率变化特性, 将时域光谱信息通过傅里叶变换转化为频域信息, 如图4所示。 从图中可以观察到, 样品信号相较于参考信号存在时延、 衰减和重叠的现象。 时延可能与太赫兹光谱穿透样品所需的时间较长有关, 衰减现象则可能源自样品表面颗粒的反射以及样品内部的吸收效应, 而各种淀粉中的主要成分均为葡萄糖的聚合物, 故导致光谱之间区分度不明显。
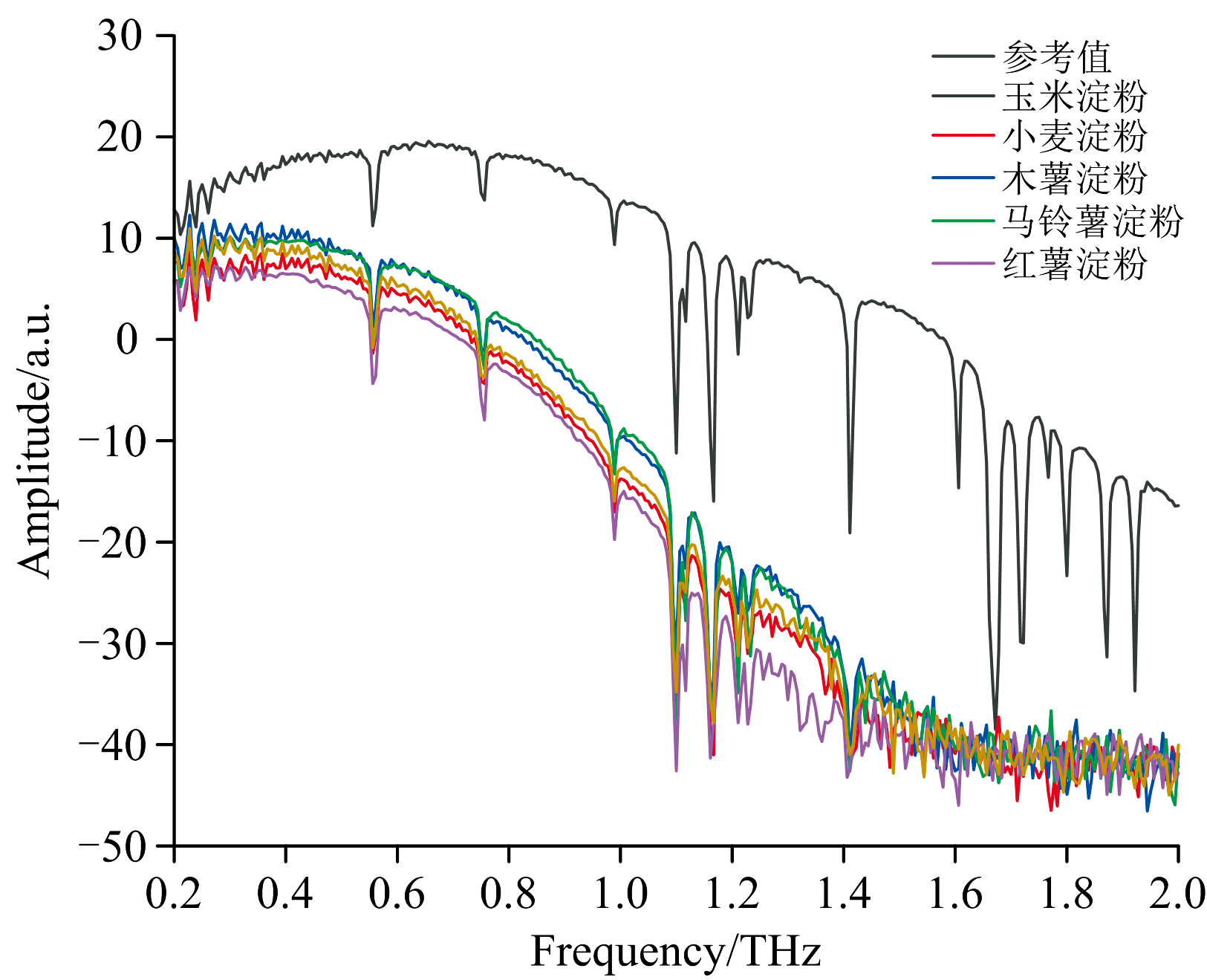 | 图4 五种淀粉的平均频域光谱图Fig.4 Mean frequency-domain spectra of five types of starch |
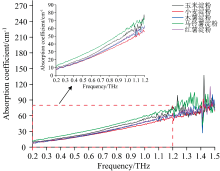
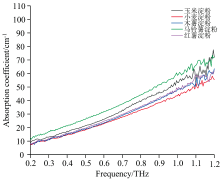
为减少背景噪声和外界因素的干扰, 通过对样品原始吸收系数进行预处理, 以提升数据质量。 中值滤波(Median Filtering)是一种非线性的平滑滤波技术, 广泛应用于信号处理与图像处理领域, 可以有效地抑制数据中的异常值和噪声[31]。 因此, 本文采取中值滤波算法对原始吸收光谱数据进行预处理, 该方法通过对水汽吸收峰引起的异常波动进行处理, 使得光谱曲线更加平滑, 为后续的机器学习分类模型提供了更为可靠的输入数据。 图5为不同品种淀粉在0.2~2 THz波段的平均吸收光谱图, 由于不同品种的淀粉成分相似, 因此很难通过直接观察来确定它们在THz光谱上的差异。 从图中可以看出, 五种淀粉的平均吸收光谱在0.2~1.2 THz频段范围内具有最高的信号强度, 而在这个范围之外的信号产生严重的衰减, 表明在1.2 THz之后信号受噪声影响加剧, 识别工作较为复杂, 因此本文选取0.2~1.2 THz频段区间的光谱数据用于进一步的处理与分析。
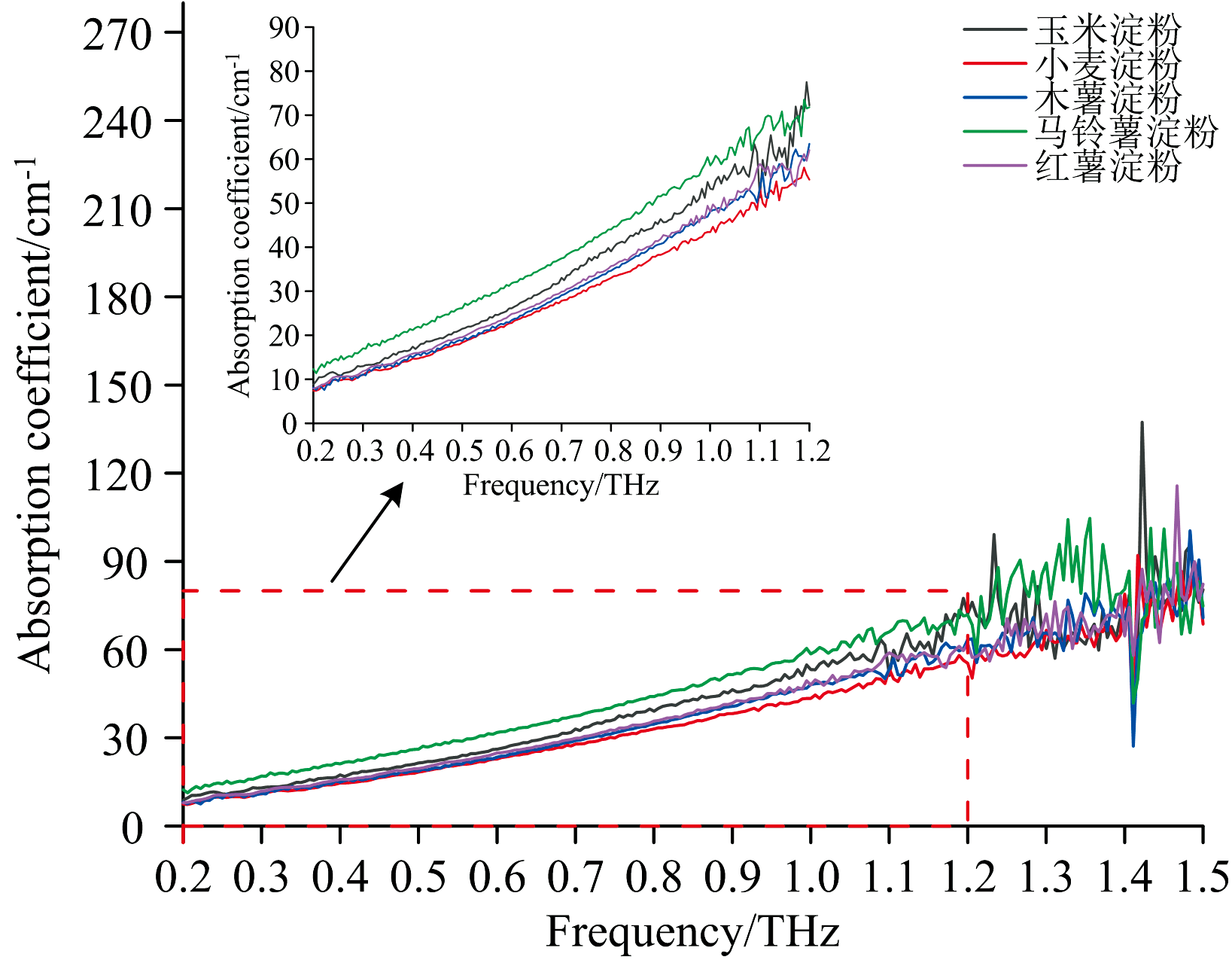 | 图5 五种淀粉的平均吸收光谱图Fig.5 Mean absorption coefficient spectra of five types of starch |
由图6可以看出, 5种淀粉在0.2~1.2 THz频段范围内未呈现明显的特征吸收峰, 随着频率的增加, 吸收系数逐渐上升, 同时不同样品之间的光谱差异性也随之增强。 谱线在低频波段重叠较为严重, 在高频区域马铃薯淀粉的吸收系数最高, 而小麦淀粉的吸收系数要明显低于其他4种淀粉, 这可能是由于不同淀粉的分子结构不同导致的。
不同种类淀粉的THz吸收光谱表现出的趋势一致, 表明其主要组分是一致的, 均为葡萄糖的聚合物, 存在一定的差异性可能是由于不同种类淀粉的结构和理化性质差异造成的。 由于淀粉样品的THz吸收光谱基本一致, 且均没有特征峰, 所以很难通过图像直接识别淀粉品种。 因此, 本研究考虑将应用广泛的机器学习与淀粉的太赫兹光谱信息相结合, 以期得到快速且准确的淀粉品种识别模型。
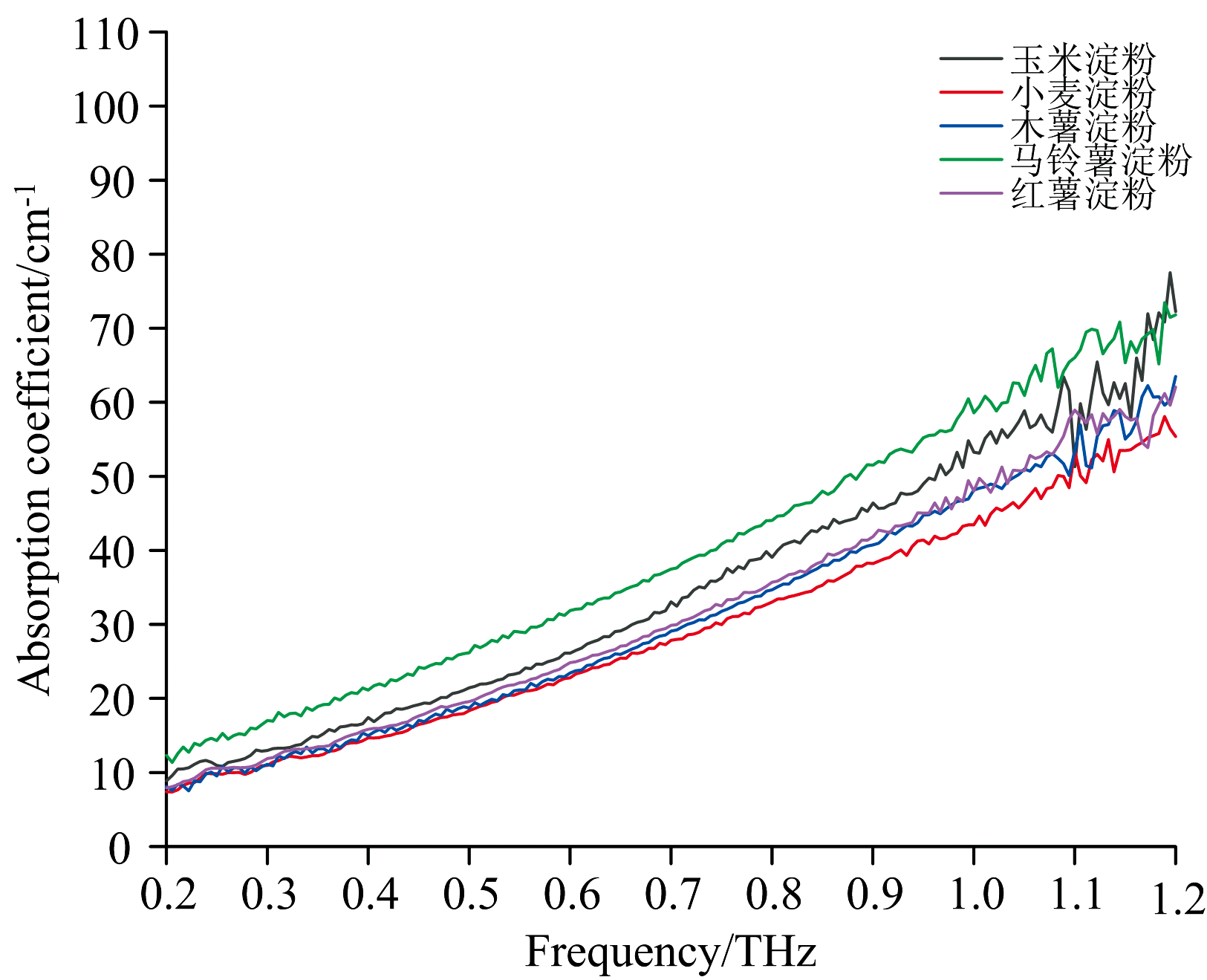 | 图6 五种淀粉在0.2~1.2 THz波段的平均吸收光谱图Fig.6 Mean absorption coefficient spectra of five types of starch in the 0.2~1.2 THz |
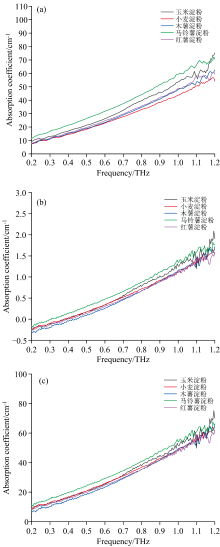
在获得样品的吸收系数后, 需要对吸收系数进行预处理操作, 以缓解高频随机噪声, 保证数据具有较高的信噪比。 SG平滑通过采用高阶多项式拟合和数据平滑来消除随机噪声, 同时能够最大程度保证光谱的宽度, 并具有将噪声抑制到较低范围等优点, 其结果图如图7(a)所示。 而标准正态变换(SNV)可以有效减轻表面粗糙度和粒度变化引起的散射效应, 从而减小光谱强度的总体差异, 其结果图如图7(b)所示。 此外, 不同品种的淀粉可能由于样品密度和粒径的变化而产生散射效应, 多元散射校正(MSC)可以有效地对其进行校正, 从而对光谱数据进行标准化处理。 由图7(c)可以看出经过MSC处理的太赫兹光谱数据表现出更一致的吸收峰位置和强度, 有效地降低了样品之间的差异性。
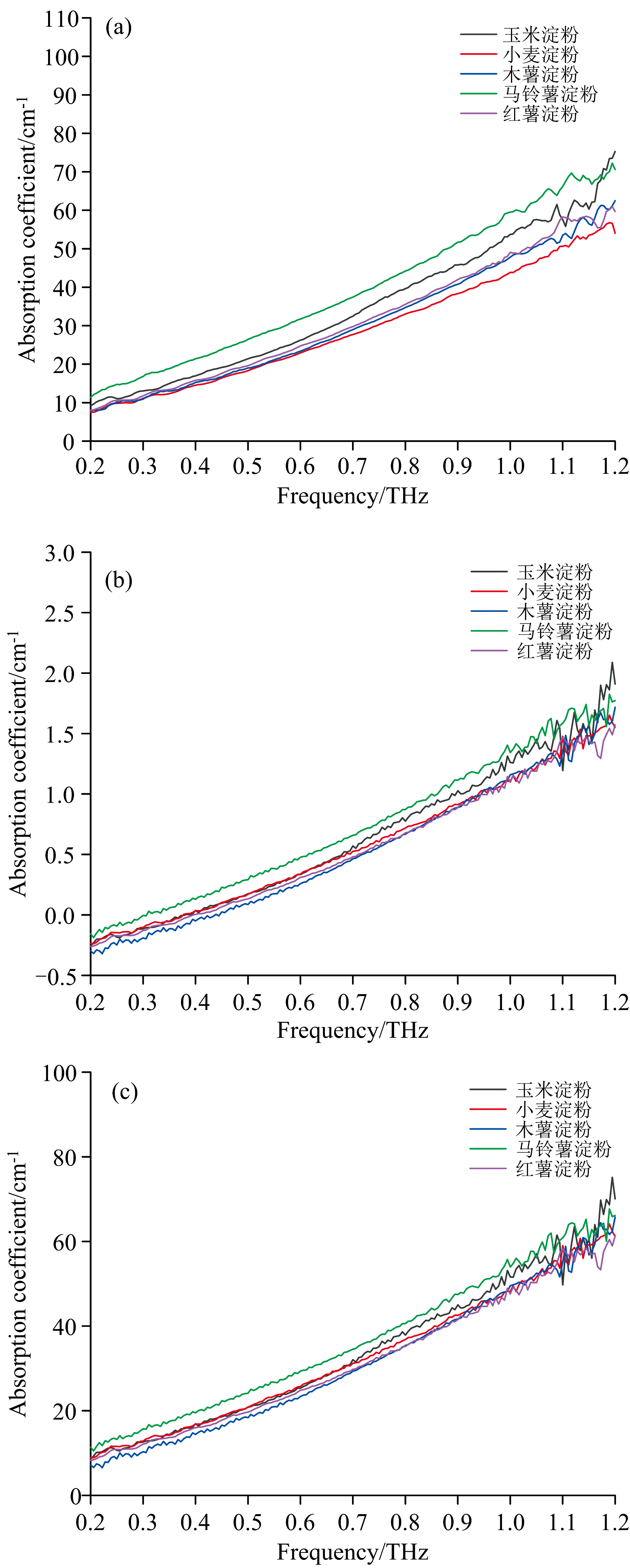 | 图7 光谱预处理结果 (a): SG预处理; (b): SNV预处理; (c): MSC预处理Fig.7 Results of spectral preprocessing (a): Spectrum processed with SG; (b): Spectrum processed with SNV; (c): Spectrum processed with MSC |
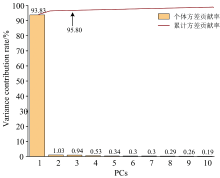
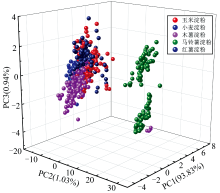
在THz吸收系数有效信号0.2~1.2 THz波段范围内共有180个频率点, 在所观测到的频率点中, 有一部分与样本的特征相关性较低, 存在的不相关信息可能对建模效果产生负面影响, 降低模型分类效率。 为了简化模型, 减少数据冗余并提高建模效率, 本文选取PCA算法在有效THz波段范围内对5种不同品种淀粉的吸收系数光谱信息进行特征提取。 如图8所示, 前3个主成分的方差贡献率分别为93.83%、 1.03%、 0.94%, 总贡献率达到了95.80%, 代表了原始数据的主要信息。 以PC1、 PC2、 PC3分别作为x、 y、 z轴绘制三维坐标系散点图。 如图9所示, 五种淀粉具有一定的区分性, 但会有部分区域重叠现象。 即可以采用PCA对五种淀粉进行分类识别, 但效果没有达到最佳, 为实现淀粉品种更精确的定性鉴别, 因此还需要结合其他机器学习算法对光谱信息进行分析。
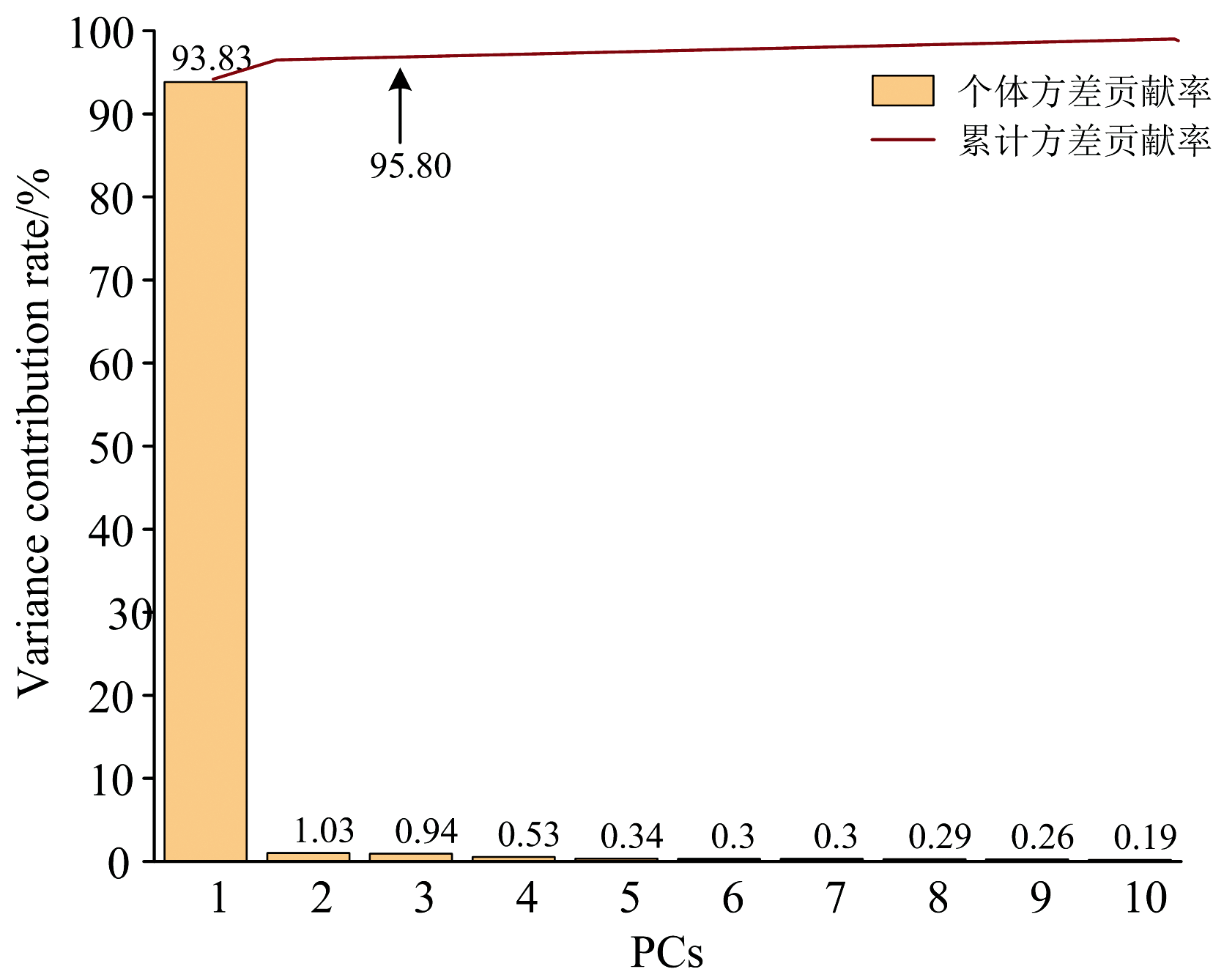 | 图8 吸收光谱的主成分方差贡献率变化条形图Fig.8 Bar chart of variance contribution rates for absorption coefficient principal components |
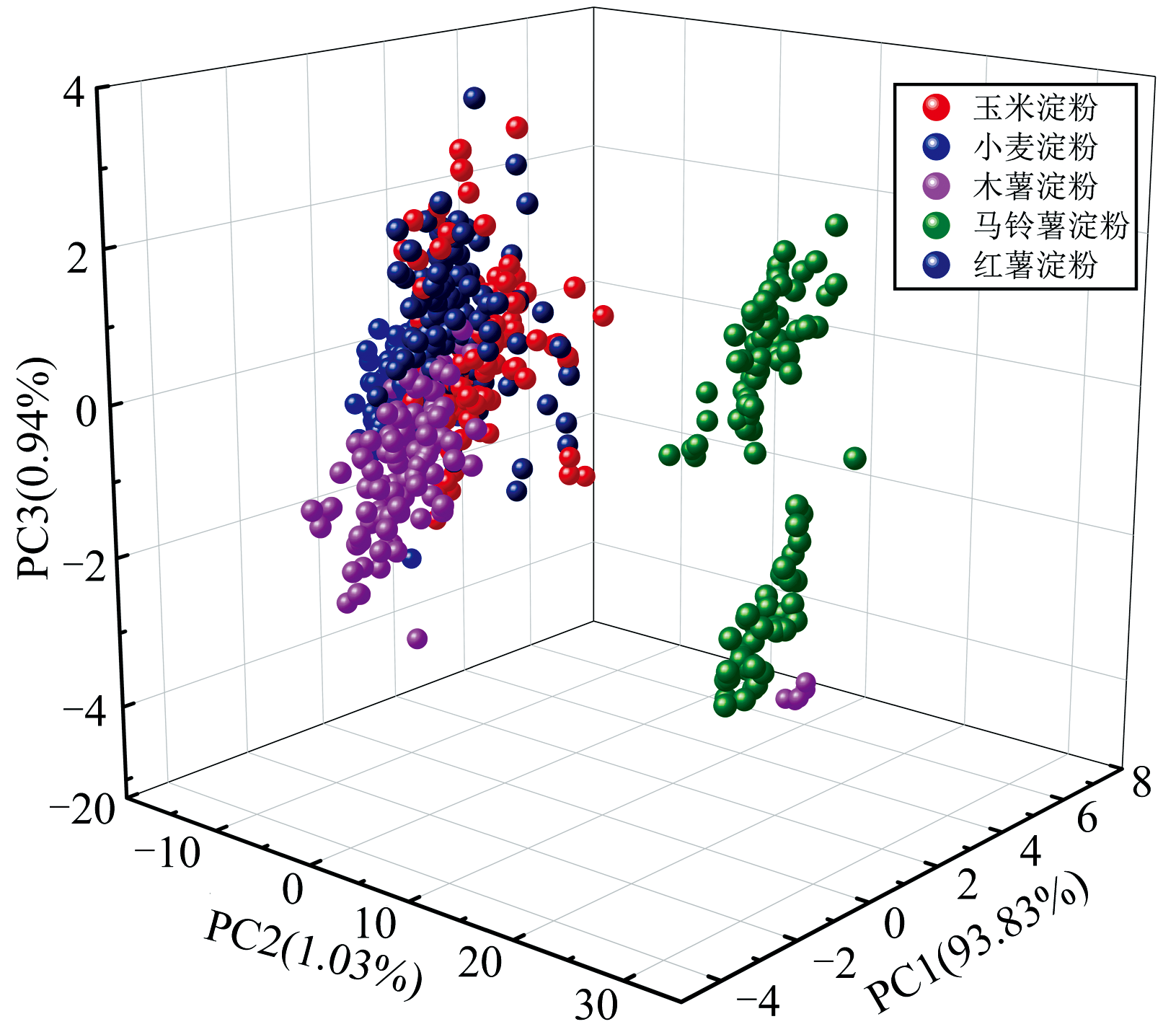 | 图9 吸收系数前3个主成分的PCA三维散点图Fig.9 3D scatter plot of the first three principal components of absorption coefficient |
对原始数据进行PCA降维后, 取累计贡献率大于95%的主成分作为识别模型的输入, 其中玉米、 小麦、 木薯、 马铃薯以及红薯淀粉的标签分别为1、 2、 3、 4、 5, 四种模型结合不同的预处理方法对不同品种淀粉的鉴别分类结果如表2— 表5所示。 研究结果表明, 4种机器学习算法结合合适的光谱预处理方法均可将5种不同品种的淀粉样品进行准确区分, 综合4种分类模型, SVM的多项式核函数Polynomial结合SG建模效果最好, 整体平均准确率达到了94.19%。
| 表2 SVM模型在不同预处理方法下的分类结果 Table 2 Classification results of the SVM model in different preprocessing |
| 表3 LR模型在不同预处理方法下的分类结果 Table 3 Classification results of the LR model in different preprocessing |
| 表4 DT模型在不同预处理方法下的分类结果 Table 4 Classification results of the DT model in different preprocessing |
| 表5 RF模型在不同预处理方法下的分类结果 Table 5 Classification results of the RF model in different preprocessing |
从表2可以看出, 除了SNV以外, 所有预处理方法都提高了SVM模型对不同品种淀粉的分类性能, 其中SG方法表现出的性能最为优秀, 测试集平均准确率为0.941 9, Kappa系数为0.933, F1得分为0.941 7。 不同核函数的模型预测精度不同, 线性和多项式核函数的分类性能优于RBF核函数的分类性能。 整体来看, 预处理方法如SNV在RF和LR模型中的表现不如原始光谱数据。 虽然该方法减少了散射效应, 但它也可能降低了样本的独特光谱特征。 此外, 从不同的机器学习分类模型对比中可以看出, 同一输入特征对于不同的机器学习模型影响是不同的。 因此, 在构建有效的机器学习分类模型时, 根据数据的特征与问题的性质去选取合适的数据预处理方法是至关重要的。
本文以5种常见淀粉为例, 探讨了太赫兹时域光谱技术与化学计量学方法在淀粉定性鉴别中的应用。 首先获取到不同品种淀粉在0.2~1.2 THz波段的太赫兹光谱信息, 为了消除背景噪声, 获取到高信噪比的数据, 对原始光谱信息进行预处理。 随后采用主成分分析提取主要光谱特征, 并结合不同机器学习方法建立了淀粉品种鉴别的多分类模型。 经过对比发现, SG-PCA-SVM优于其他分类方法, 其中测试集平均准确率高达0.941 9, Kappa系数为0.933, F1得分为0.941 7。 由此可见, 尽管5种淀粉的太赫兹吸收光谱未表现出明显的吸收峰, 但通过对光谱数据的预处理与特征提取, 并结合合理的分类模型, 可以实现相似淀粉的准确区分。 本研究证明了PCA-SVM识别不同品种淀粉的有效性, 对食品加工业的现代化及淀粉基产品的开发具有重要的实际应用价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|