

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合高光谱图谱特征的油菜角果含水率反演研究
[魏薇1  , 王丹
, 王丹2 , 王博韬3 , 谭佐军1 , 刘泉1 , 谢静1, * ]
, 王丹]
|
|


作者简介: 魏 薇, 女, 1981年生, 华中农业大学工学院教授 e-mail: weiwei1981@mail.hzau.edu.cn
为了探讨基于油菜高光谱间接估测油菜角果皮含水率的潜力, 于2023年3月—5月采集试验田油菜光谱和实测油菜角果皮含水率, 经2种光谱预处理, 和3种特征波长筛选方法及其组合, 并融合高光谱图像空间纹理信息, 用偏最小二乘回归(PLSR)、 Lasso回归、 支持向量回归(SVR) 和极限学习机(ELM)建立角果皮含水率的回归模型, 同时对模型结果进行精度评价。 研究结果表明: (1)光谱预处理能够突出光谱中的一些隐藏信息, 对油菜光谱进行多元散射校正(MSC)和一阶导数(first derivative, FD)数学变换后更加有利于提取光谱敏感信息; (2)预处理后, 采用竞争性自适应重加权算法(CARS)和迭代的保持有信息变量(IRIV)相结合的特征波段筛选方法, 利用Lasso模型进行预测效果最好, 测试集的 R2为0.772 0; (3)针对油菜角果皮这一结构复杂、 体积小、 含水率分布易受几何结构影响的关键作物对象, 在纯光谱信息的基础上, 引入空间纹理信息, 空间纹理量化了角果表面与含水率相关的空间变异和结构细节(如皱纹、 凹凸), 并补偿单一像元光谱因角果形状、 朝向引起的变异, 提升模型回归精度和预测能力, 增强模型对噪声和异常值的鲁棒性, 为解决复杂小尺度作物对象生理参数精准反演提供了新的有效途径。
To explore the potential of indirectly estimating the moisture content in silique peel based on hyperspectral data, this study took the rapeseed experimental field as the research object. From March to May 2023, the rapeseed spectra and moisture content of rapeseed silique peel were collected from the experimental field. After two spectral preprocessing methods, three feature wavelength selection methods, and their combinations, hyperspectral image spatial texture information was introduced. Partial Least Squares Regression (PLSR), Lasso regression, Support Vector Regression (SVR), and Extreme Learning Machine (ELM) were used to establish a regression model for the moisture content of rapeseed silique peel, and the accuracy of the model results was evaluated. The research results indicate that: (1) Spectral preprocessing techniques can highlight some hidden information in the spectrum, and mathematical transformations such as Multiple Scatter Correction (MSC) and First Derivative (FD) are more conducive to extracting spectral sensitive information; (2) After performing preprocessing, a feature selecting method combining Competitive Adaptive Reweighted Sampling (CARS) and Iterative Retention Informative Variables (IRIV) was used. The Lasso model demonstrated the best prediction performance, with an R2 of 0.772 0 for test set 3.In response to the complex structure, small volume, and geometric influence of moisture content distribution in rapeseed silique peel, spatial texture information is introduced based on pure spectral information. Spatial texture quantifies the spatial variation and structural details (such as wrinkles and bumps) related to moisture content on the surface of silique, compensates for the variation caused by the shape and orientation of silique in a single pixel spectrum, improves the regression accuracy and prediction ability of the model, enhances the robustness of the model to noise and outliers, and provides a new effective way to solve the precise inversion of physiological parameters of complex small-scale crop objects.
油菜是我国第四大农作物, 同时也是我国最主要的食用植物油来源[1]。 在油菜的收获过程中, 准确判断角果的成熟度是提高产量的关键。 若收割过早, 籽粒尚未完全成熟, 最终会导致产量下降; 若收割过晚, 则可能因角果皮含水量(moisture content, MC)过低而导致角果皮破碎, 籽粒散落, 使得收割变得困难[2], 所以角果收获时机是影响油菜最终产量的重要因素。 研究表明, 油菜角果皮含水量和叶绿素含量经过一系列化学反应会转化为油菜籽粒的含油量, 因此, 角果皮含水率成为辅助界定适宜收割时间的关键指标[3]。
然而实际生产中, 角果皮含水量的判断往往来源于人工鉴别角果颜色或采摘后室内精密测定。 这些判断或测量方法不仅效率低下且存在不可避免的主观性。 此外, 该方法难以在大区域调查中开展实施[4]。 近年来随着无人机技术日趋完善、 普及, 小型化而精密的传感器被集成且成功应用于作物种植生产[5]。 凭借无损、 高通量式的监测手段, 无人机平台可连续采集极其丰富的作物生长数据, 为大范围作物种植管理提供统一、 有效的判断依据和监测响应[6]。 基于无人机平台的光谱和图像特征分析技术已应用于不同作物的含水量监测中。 周敏姑等[7]利用无人机的多光谱遥感数据, 提取冬小麦的整个生育时期反射率特征参数, 建立SPAD值的反演模型, 并与多种机器学习模型进行比较, SPAD值反演精度较高。 魏青等[8]利用无人机多光谱影像和田间实测冠层的叶绿素含量数据, 选取16种光谱指数, 建立冬小麦各时期和全生育期的SPAD估测模型, 分别建立一元二次线性回归和逐步回归分析, 研究表明逐步回归分析具有更好的预测效果。 Aasen和Bolten[9]利用无人机搭载高光谱相机, 设定飞行高度为30 m拍摄大麦图像, 利用植被指数对叶绿素含量进行预测, 建立的模型准确率为0.66。 朱志成等[10]利用无人机采集不同胁迫下冬小麦各期高光谱影像, 结合地面实测叶绿素数据, 分析冬小麦在水分胁迫下叶绿素和冠层反射率变化规律, 尝试寻找响应水分胁迫的敏感波段及其差异。
为了探讨基于油菜高光谱间接估测油菜角果皮含水率的潜力, 以华中农业大学油菜试验田为研究区域, 于2023年3月— 5月采集试验田油菜光谱和油菜角果皮含水率, 经不同的光谱变换预处理和特征波长筛选, 并融合高光谱图像空间纹理信息, 用偏最小二乘回归(partial least squares regression, PLSR)、 Lasso回归、 支持向量回归(support vector regression, SVR) 和极限学习机(extreme learning machine, ELM)对预处理后的光谱建立角果皮含水率的回归模型, 并对模型结果进行精度评价, 以期获得油菜高光谱遥感估测油菜角果皮含水率的最佳模型, 为建立大范围油菜种植管理系统提供参考。 相较于现有文献中主要利用高光谱或多光谱信息预测大麦、 冬小麦叶绿素含量, 本研究针对油菜角果皮这一结构复杂、 体积小、 含水率分布易受几何结构影响的关键作物对象, 创新性地提出利用高光谱成像的空间纹理信息来克服传统单一光谱方法在此类目标上的局限性。 空间纹理特征能有效表征角果表面的结构细节和空间异质性, 这些信息与含水状态密切相关, 并能缓解几何光学效应对光谱信号的干扰。 结合高光谱自身强大的化学信息识别能力, 这种光谱-空间双维度信息的协同利用, 为解决复杂小尺度作物对象生理参数精准反演提供了新的有效途径。
实验于2023年3月至5月在湖北省武汉市华中农业大学油菜试验田开展。 所选取的实验田的中心坐标为114° 21.1'E, 30° 28.0'N, 研究区内均匀种植500份不同品种油菜, 每个种植小区长约为1.5 m, 宽约为0.9 m, 小区内以等间隔的方式种植三行油菜。
利用大疆M600 Pro六旋翼无人机搭载Nano-Hyperspec高光谱成像仪, 在油菜的盛花期进行标记, 在标记后的第26天、 第37天、 第45天、 第55天和第66天分别在田间拍摄高光谱影像, 采集作物冠层400~1 000 nm的272个波段的高光谱反射率数据, 光谱采样间隔为2.2 nm· pixel-1。 考虑到太阳高度角对影像质量的影响, 无人机飞行实验于上午10:00至11:00之间进行, 起飞前布设定标板, 为了保证得到足够的覆盖面积和理想的地面分辨率, 飞行高度设置为22 m, 航向重叠度设置为80%, 旁向重叠度设置为75%, 最终高光谱影像的空间分辨率为0.02 m。
5个采集日, 同时在选择的55个感兴趣区域内(如图1所示), 从油菜角果冠层上部分到下部分均匀采集10颗油菜角果, 参照张宪政《作物生理研究法》(1992)的方法[11], 获取角果皮平均含水率。 具体的公式如式(1)
式(1)中, m为角果鲜重, m1为角果籽粒鲜重, m2为角果皮干重, 将计算出的平均含水量作为该小区的实测含水量值, 减小人工采样造成的误差, 提高原始数据精度, 试验中共计获得275条含水率数据样本。
 | 图1 感兴趣区域示意图Fig.1 Schematic of ROI |
为了确保高光谱影像数据能够准确反映地表的实际情况, 在应用之前还需要经过辐射定标、 几何校正和图像拼接。 另外高光谱影像数据可能包含各种噪声, 如仪器噪声、 大气干扰, 还可能受到光照条件、 传感器漂移等因素的影响, 所以需要采用一定的数据预处理方法对数据进行校正。
光在大气和地表之间相互作用会产生明显散射效应, 在光学中散射效应通常会导致信号的衰减、 扩散和失真。 针对性的采用多元散射校正(multiplicative scatter correction, MSC)可以校正大气和地物多次发生散射效应引起的光谱数据畸变, 以消除由于散射造成的影响[12]。 另外, 光谱导数处理方法通过识别出具有差异性的、 代表了有用信息的波峰和波谷, 从而能够从光谱中提取有价值的信息, 并消除背景干扰, 增强光谱的分辨率。 而一阶导数(firstderivative, FD)对信号中的边缘和细节特征比较敏感, 可以突出数据中的边缘信息, 使这些特征更加显著[13]。 同时高光谱数据中可能存在光谱基线, 即数据中的低频成分, 一阶导数还有助于减少或去除这些基线, 从而更好地展示数据中的高频特征[14]。 因此, 采用多元散射校正MSC和一阶导数FD两种预处理方法对数据进行预处理[15]。 预处理可以去除或减少这些噪声, 提高数据质量, 确保数据的一致性和可比性。
1.4.1 光谱特征提取
特征波段筛选对于提高数据的质量、 准确性和可解释性至关重要。 不同的特征提取方法原理不同, 对模型的影响也不同, 本研究采用多种特征提取方法对无人机获取的油菜高光谱数据进行分析。 离散小波变换(discrete wavelet transform, DWT)是一种基于小波函数的信号处理技术, 用于将信号分解成不同尺度(频率)的成分[16], 可以通过一系列尺度和平移参数的小波函数同时在时间和频率上提供信息。 竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)是对全部特征下的数据建立PLS模型, 最后筛选出效果较好的特征波长[17]。 迭代保留信息变量(iteratively retains informative variables, IRIV)是一种依靠二进制混合矩阵过滤来选择变量的新算法, 采用交叉验证均方差来评价各变量的性能[18], 赋予不同权重选择与目标变量高度相关的特征变量[19, 20]。
虽然CARS选择的特征波长数量可以大幅度减少, 但是CARS选择的特征波长存在一些共线性问题。 本工作利用CARS和IRIV结合的改进方法来选择有效波长, 首先利用CARS方法对波长进行初步选择, 得到一组与含水率相关的潜在波长子集。 然后, 利用IRIV进一步处理, 将潜在的波长子集进一步分为四组, 包括强信息变量、 弱信息变量、 无信息变量和干扰变量。 在每次迭代中, 从经过CARS方法筛选的保留变量中剔除无信息变量和干扰变量。 最后, 选出最有效的变量子集, 以利于后续建模。
1.4.2 纹理特征计算
基于灰度共生矩阵计算高光谱图像的纹理特征参数, 这些参数的具体计算公式和物理含义如表1所示。
| 表1 纹理特征参数及计算公式 Table 1 Texture feature parameters and calculation formulas |
表1中x(i, j)表示矩阵中第i行、 第j列的值, p(i, j)表示矩阵中第i行、 第j列的值占所有值之和的比例, Ng表示矩阵的长和宽, μ x和μ y分别为矩阵x和y的均值, σ x和σ y为矩阵x和y的方差。 基准窗口的大小选择、 移动窗口的步长和方向会影响到gray-level co-occurrence matrix(GLCM)的计算结果, 从而影响纹理特征参数的值。 如果步长较小, 能够得到更多的纹理特征信息, 但可能导致特征之间的冗余度增加; 如果步长较大, 能够获得更多独立的特征信息, 但可能导致局部细节被忽略; 较小的采样窗口对于捕获图像中的细节和局部纹理特征更为敏感, 但可能无法反映大尺度上的纹理结构; 较大的采样窗口可能包含更多的纹理信息, 能够捕捉到较大尺度上的纹理模式, 但可能会丧失细节信息; 纹理往往还具有方向性, 窗口的移动方向决定了其遍历图像的路线, 当窗口沿着特定方向移动时, 能更加有效地捕捉与该方向对应的纹理特征[24]。
1.5.1 油菜角果含水率预测模型
本工作主要是利用机器学习算法, 运用线性模型和非线性模型建立预测模型, 其中, 线性模型包括偏最小二乘回归和Lasso回归, 非线性模型包括支持向量回归和极限学习机。
偏最小二乘回归(partial least squares regression, PLSR)是一种多元统计分析方法, 特别适用于处理多重共线性和高维数据的问题。 它的目标是通过找到新的特征向量, 将自变量和因变量的信息都最大化地捕捉到这些新的特征向量中[21]。 Lasso回归是对线性回归的优化, 通过生成一个惩罚函数对回归模型中的变量系数进行压缩, 能够防止出现过拟合问题[22]。 支持向量回归(support vector regression, SVR)是通过分析输入变量与输出变量之间的数量关系, 与线性回归模型不同, SVR通过引入核函数和支持向量来处理非线性回归问题。 极限学习机(extreme learning machine, ELM)属于前馈神经网络中的一种[23]。 该算法的主要思想是在训练过程中, 随机初始化隐藏层的权重和偏置, 然后利用输入数据快速计算输出层的权重。 相比传统的神经网络训练方法, ELM不需要进行迭代优化, 因此具有训练参数少、 学习速度快、 泛化能力强的优点。
1.5.2 模型精度评价
采用10折交叉验证, 即将数据集分成10个子集, 然后执行10次训练和验证, 每次使用9个子集进行训练, 剩余的1个子集用于验证。 最后, 将这10次验证结果的平均值作为模型的性能指标。 为了评价所得最优模型的准确性, 选用的指标为决定系数(R2)、 均方根误差(RMSE), 计算公式如式(2)和式(3)
式(2)和式(3)中, yi为含水率的实测值,
2.1.1 全波段反射率数据预处理
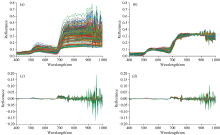
如图2所示为高光谱反射率曲线经过预处理之后的示意图。
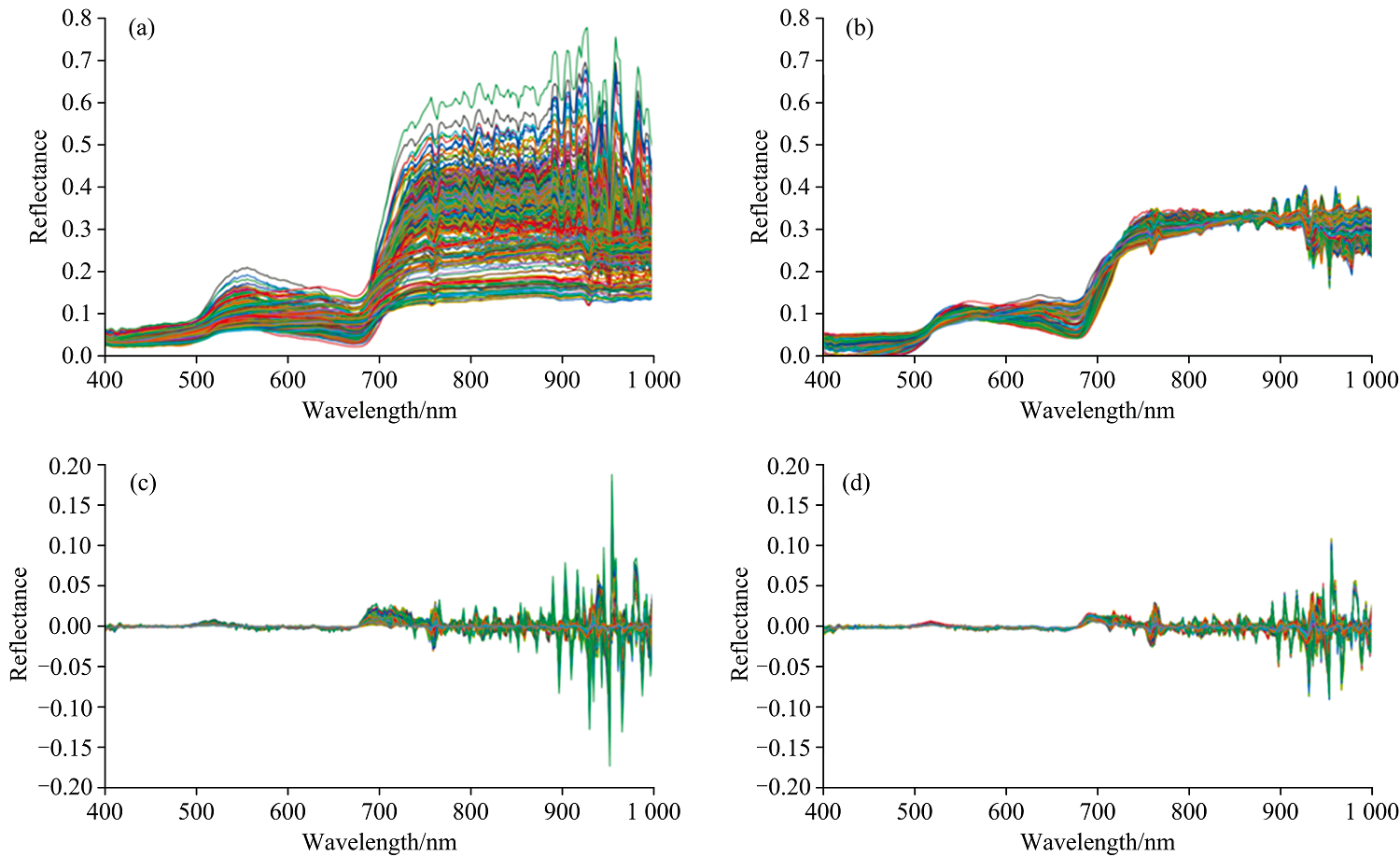 | 图2 高光谱反射光谱 |
由图2可以看出, 原始光谱在750~1 000 nm之间波动范围较大, 这种失真可能由大气颗粒物、 云层或其他环境因素引起, 导致光谱信号的衰减和畸变。 经过MSC处理后, 消除了大气散射成分, 750~1 000 nm的波动被压缩, 从而恢复出更接近于真实地表反射特性的光谱曲线。 这种方法对于高光谱遥感数据尤为重要, 因为它可以显著提高植被指数和其他光谱特征的准确性。 FD处理在识别光谱中微小但重要的变化时特别有用, 经过FD处理之后, 曲线在某些波段上存在较大的光谱波动, 突出了光谱中的变化趋势, 与原始光谱曲线相比, 具有强调光谱变化、 凸显峰值和谷底的特点, 使得后续的特征提取和分析更为敏感和准确, 有利于区分植被不同生理状态。 经过MSC+FD处理之后的曲线与原始曲线相比, 峰值和谷底的特征更加清晰, 两种方法同时处理能更清晰地突出光谱变化。
2.1.2 油菜角果平均光谱曲线
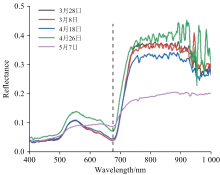
将5个采集日的55个小区的反射光谱求平均值, 得到每个采集日的油菜平均反射光谱, 原始的平均光谱曲线如图3所示。 可以看出, 第一个波峰出现在550 nm附近, 对应的是绿光; 在676 nm附近出现波谷, 对应的是红光; 在687~730 nm波段内, 前4个采集日的反射率陡然上升, 而后反射率不断波动; 在769 nm之后, 第5个采集日的反射率基本在0.18~0.20之间。
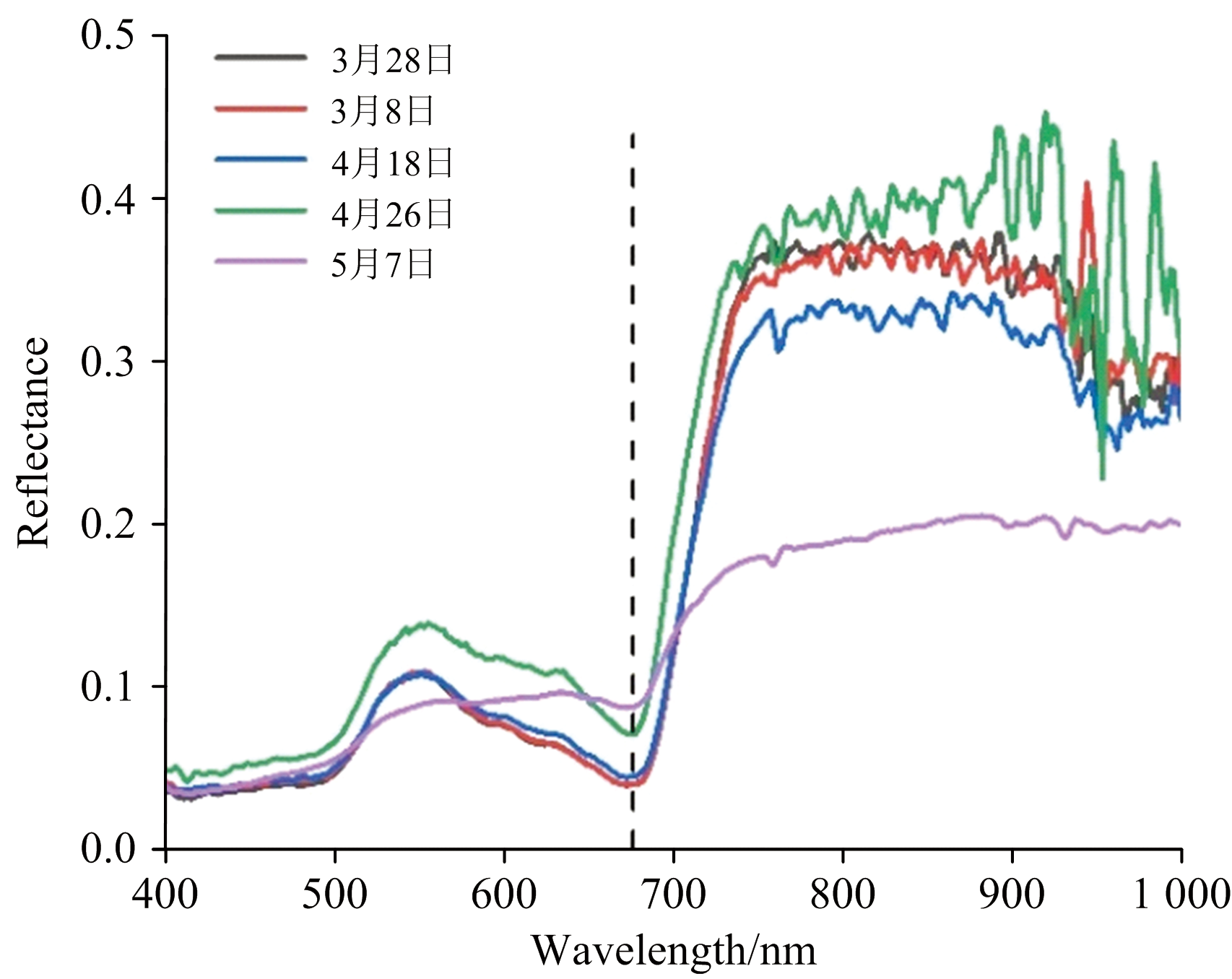 | 图3 油菜角果平均光谱曲线Fig.3 Average spectra of oilseed rape silique peel |
通常, 与叶绿素含量相关的波段包括蓝光区(440~470 nm)、 红光区(640~680 nm)、 红边区(680~750 nm)。 如图3所示, 红光区(676 nm)存在叶绿素的吸收峰, 并且随着油菜角果成熟, 含水量和叶绿素含量降低, 吸收峰上移。 这表明, 在油菜成熟的过程中, 油菜角果含水量和叶绿素含量经过一系列化学反应会转化为油菜籽粒的含油量[26]。
2.2.1 离散小波分解
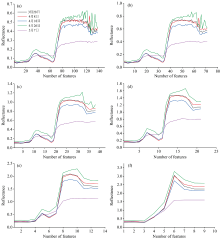
对5个采集日的55个小区的平均光谱曲线进行离散小波变换, 在降维过程中, 提取那些能够反映光谱数据主要趋势和结构信息的低频分量, 舍弃与噪声等信息关联更紧密的高频分量。 其中一个小区平均光谱曲线的离散小波变换后的低频变量曲线如图4所示, 随着分解层数的增加, 低频变量曲线的形状与原始曲线相比在细节上差异逐渐变大, 但从宏观上还是保留了整体趋势, 都保留了拐点处的特征。
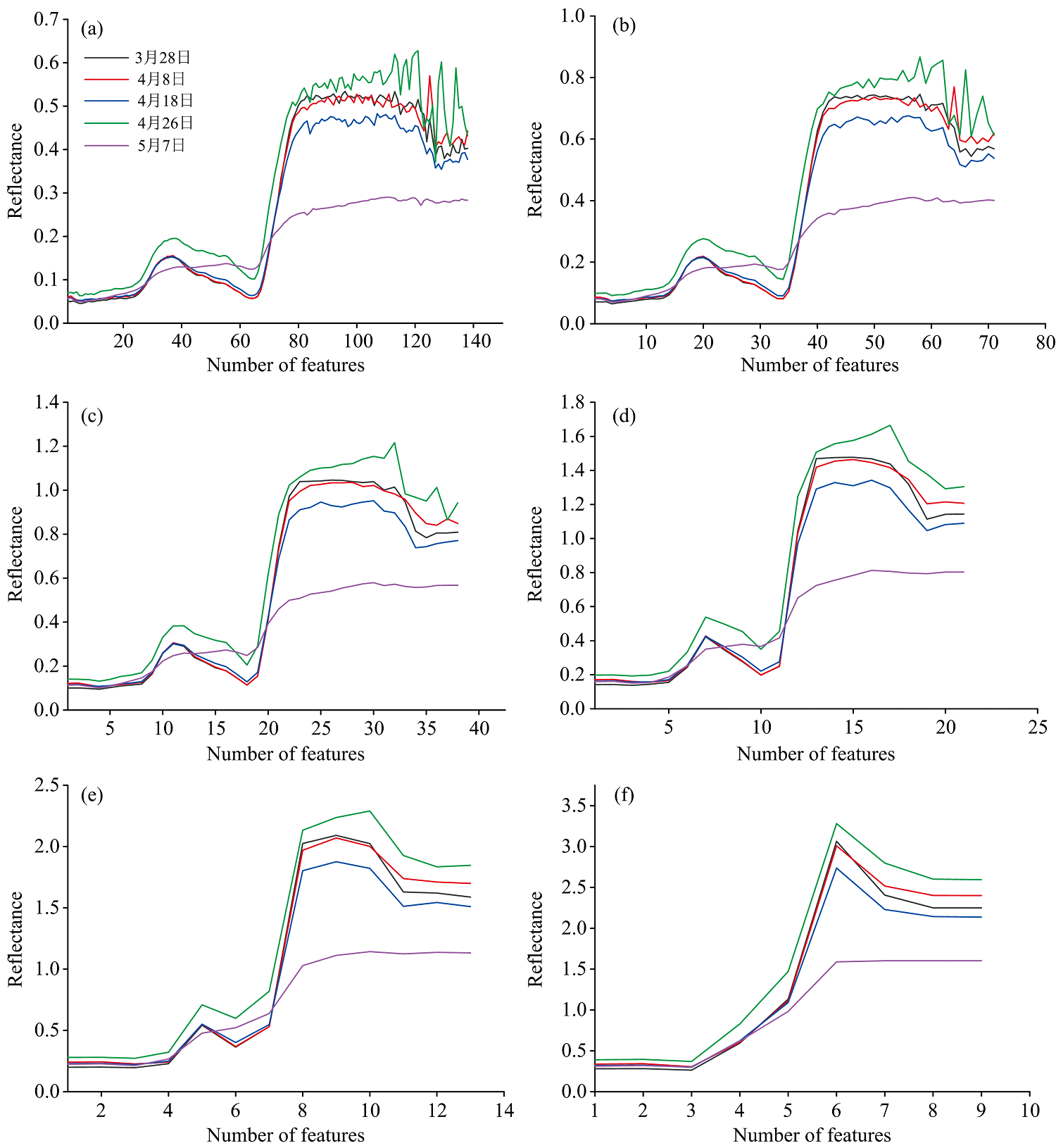 | 图4 基于coif1离散小波变换后的低频变量曲线 |
2.2.2 CARS+IRIV筛选
不同预处理方式下, 通过CARS、 IRIV和CARS+IRIV三种方法筛选得到的具体特征波长数量如表2所示。 从表中可以看出, 与原始的272个波段相比, 三种方法都明显降低了数据的冗余度。
| 表2 不同预处理方法选择的特征波长数量 Table 2 Characteristic wavelengths selected by using different pretreatment methods |
采用CARS方法进行全波段筛选时, 蒙特卡洛采样次数设置为200, 采样频率设置为0.8, 筛选阈值设置为0.8, PLS模型的主成分数设置为20, 主成分数设置较大是为了更好地获取数据的结构和特征。
对经MSC+FD处理后的数据进行IRIV特征波长筛选时, 在第4次迭代之前, 保留的变量数目迅速下降, 在第7次迭代之后, 变量数目保持不变, 为46, 然后进行反向消除无用的信息, 最终提取22个特征波长, 占全波段的8.09%。 虽然CARS对经过MSC+FD处理后的数据选择的特征波长数从272个分别减少到了35个, 但是CARS 选择的特征波长存在一些共线性问题。 在CARS选定的变量的基础上, 采用IRIV进一步去除冗余变量。 对MSC+FD-CARS数据共进行了3次迭代, 经过3次迭代后, IRIV 将变量数从35个减少到26个, 并在反向消除中消除了4个变量, 最后选出了22个特征波长, 占全波段的8.09%。 特征波段主要集中在红边区域(680~780 nm)和近红外波段(780~1 075 nm)。 红边区域的光谱反射率对水分有间接响应, 植物水分含量越低, 近红外波段反射率越高, 红边区域的光谱反射曲线会更陡峭。 近红外波段反射率则是对水分有直接响应, 是监测作物水分状况的重要波段。
2.2.3 纹理特征计算
油菜角果的含水率变化显著影响其物理结构, 其导致细胞膨胀或收缩, 进而改变表面纹理, 如光滑度和光泽。 这些结构变化通过高光谱图像的纹理特征如角二阶矩和相异性得以体现。 含水率同样影响光的反射、 吸收和透射特性, 改变光谱反射率, 这与纹理特征如对比度和协同性紧密相关。 随着油菜角果成熟, 含水率的变化伴随着叶绿素和脂质含量的变化, 影响其颜色, 这些变化通过纹理信息如熵和均值间接反映。 含水率变化还影响细胞大小和排列的均匀性, 这些空间分布特征通过相关性等纹理参数捕捉。 此外, 含水率的适应性变化也会在纹理特征中显现, 如方差和对比度。 高光谱图像所涵盖的不仅仅是光谱信息, 还包括对地面作物生长状况、 均匀性以及其他空间特征的空间纹理信息。 因此为了进一步提升含水率预测的准确度, 引入空间纹理信息。
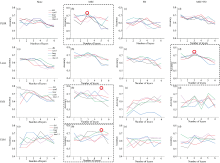
为了捕捉光谱中的细微变化, 将移动步长设为1和2, 选择的相对较小的窗口大小为5× 5和7× 7, 同时为了充分获取不同方向上的纹理变化特征, 设置0° 、 45° 、 90° 、 135° 这4个方向, 求得所有方向上的纹理特征参数取平均。 基于灰度共生矩阵计算的纹理特征通常是针对高光谱图像的单个波段进行的。 不同波段代表了不同的频谱信息, 反映的是地面作物对不同频率光波的吸收和散射特征。 图5(a)和(b)展示了414和585 nm处的纹理特征示意图, 可以看出不同波段在8个纹理特征上有明显的差异。 进一步将这8个纹理特征与含水率实测值进行多元回归, 如图5(c)所示, 角二阶矩贡献度最大, 其代表图像灰度的均匀分布程度, 当含水率减小, 表面纹理变粗糙, 像素对的灰度差异较大, 角二阶矩较小。
 | 图5 高光谱影像414 nm(a)、 585 nm(b)纹理特征示意图及贡献度分析(c)Fig.5 Schematic of texture features of hyperspectral image at 414 nm (a) and 585 nm(b), and Contribution analysis(c) |
采集的高光谱图像具有272个波段, 波长范围在400~1 000 nm之间, 通常, 与叶绿素含量相关的波段包括蓝光区(440~470 nm)、 红光区(640~680 nm)、 红边区(680~750 nm)。 根据2.1.2和2.2.2的结论, 选择基于CARS+IRIV方法筛选特征波段, 再叠加蓝光区、 红光区和红边区这三个区域, 最终计算450.242、 454.678、 459.114、 467.986、 640.998、 643.216、 678.705和689.796nm这8个波长的纹理特征。
2.3.1 基于光谱特征参量的油菜角果含水率预测模型
2.3.1.1 基于离散小波分解的模型预测
小波函数具有不唯一性, 不同的小波函数分析同一个问题会产生不同的效果。 本研究选用haar、 db1、 sym2、 coif1、 rbio1.3这5种小波函数分别对数据进行1~6层变换, 并用每层的低频变量作为因变量建立油菜角果含水率预测模型。
不同的预处理方式下建立PLSR、 Lasso、 SVR和ELM模型的预测效果如6所示。 建立的PLSR模型的准确率在0.520 7~0.722 7间, 其中经过MSC处理之后, 经过coif1小波基函数3层变换后准确率最高, 测试集的准确率为0.722 7。 建立Lasso模型的准确率在0.517 8~0.735 4之间, 其中经过MSC+FD处理之后, 经过haar小波基函数3层变换后准确率最高, 测试集的准确率为0.735 4。 建立SVR模型的准确率在0.407 8~0.777 4之间, 其中经过MSC处理之后, rbio1.3小波基函数5层变换后准确率最高, 测试集的准确率为0.777 4。 ELM模型的准确率在0.513 1~0.735 0之间, 其中经过MSC处理之后, coif1小波基函数5层变换后准确率最高, 测试集的准确率为0.735 0。 对比所有组合预测效果, 算法组合MSC-5-robi1-SVR预测效果最好。 研究结果表明, 经过预处理之后的模型均比未处理的数据建模效果更好, MSC方法的处理效果要优于FD处理, 这说明大气散射对高光谱数据的影响较大, 经过MSC处理后能够提高模型的准确性。
2.3.1.2 基于CARS+IRIV的模型预测
将通过预处理之后的数据, 分别用CARS, IRIV和CARS-IRIV这3种特征选择算法筛选的波段作为自变量, 油菜角果含水率实测值作为因变量, 分别建立了基于PLSR, Lasso, SVR和ELM的油菜角果含水率预测模型, 各模型测试集的决定系数如表3所示。
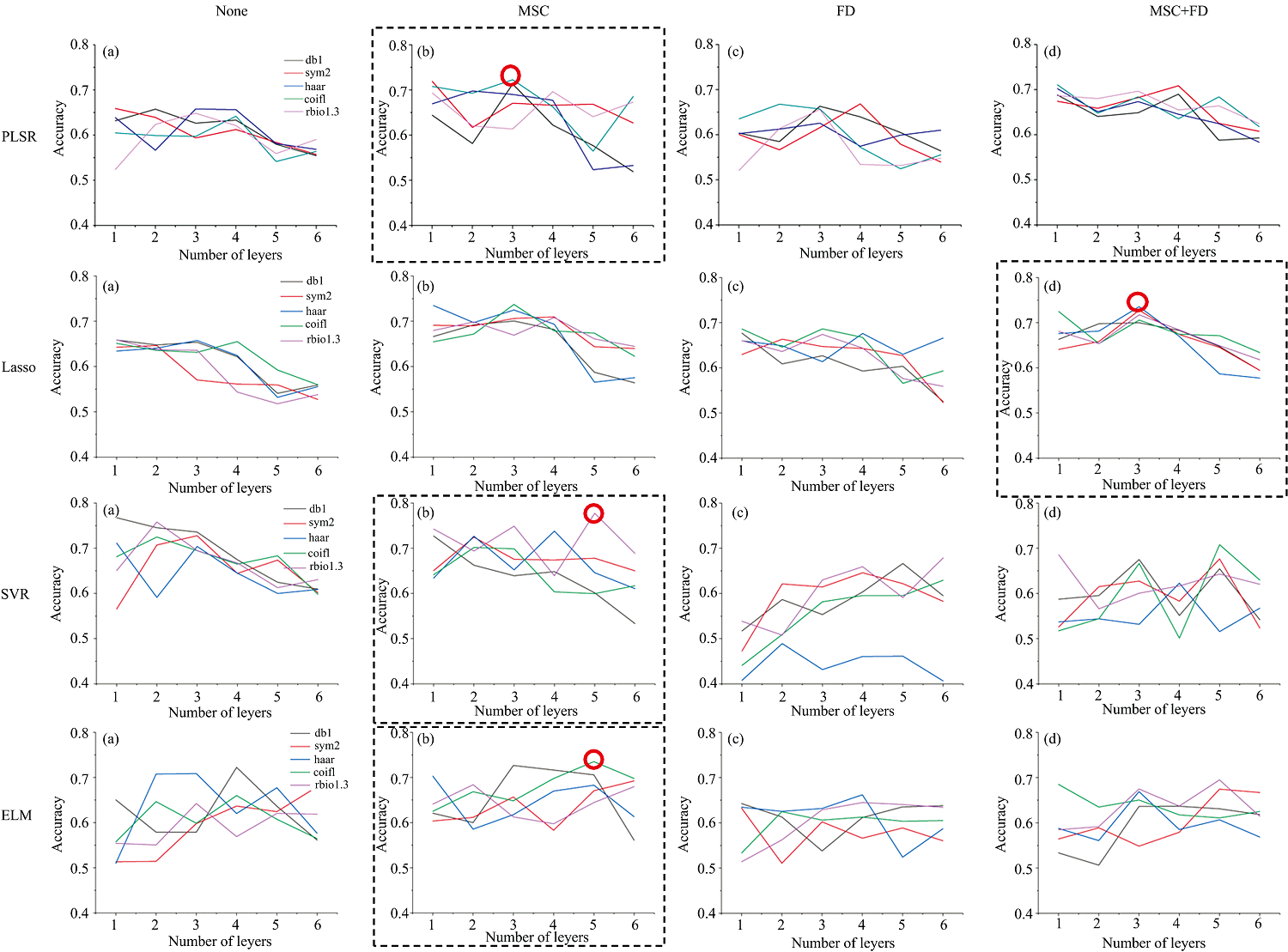 | 图6 基于None/MSC/FD/MSC+FD预处理DWT降维的PLSR、 Lasso、 SVR、 ELM模型总体精度Fig.6 Overall accuracies of PLSR, Lasso, SVR, ELM based on DWT after different preprocessing of None, MSC, FD, MSC+FD |
| 表3 不同算法的决定系数 Table 3 R2 of different algorithms |
由表3可以看出, PLSR模型预测效果最好的算法组合为MSC+FD-CARS-IRIV-PLSR, 测试集的R2为0.691 5, RMSE为0.069 1; Lasso模型预测效果最好的算法组合为MSC+FD-CARS-IRIV-Lasso, 测试集的R2为0.772 0, RMSE为0.060 9; SVR模型预测效果最好的算法组合为MSC-CARS-SVR, 测试集的R2为0.748 2, RMSE为0.066 4; ELM模型预测效果最好的算法组合为None-CARS-IRIV-ELM, 测试集的R2为0.645 0, RMSE为0.085 6。 在这4类模型中, 预测效果最好的算法组合为MSC+FD-CARS-IRIV-Lasso, 测试集的R2为0.772 0, RMSE为0.060 9。
2.3.2 基于图谱数据融合的油菜角果含水率预测模型
经过离散小波分析后建立的4种预测模型中, 选择2种模型预测效果最好的算法组合, 即MSC+FD-3-haar-Lasso的测试集为0.735 4, MSC-5-rbio1.3-SVR的测试集为0.777 4。 同样在经过预处理, CARS、 IRIV和CARS-IRIV这3种特征筛选后建立4种预测模型中, 选择2种预测效果最好的算法组合, MSC+FD-CARS-IRIV-Lasso测试集为0.772 0, MSC-CARS-SVR的测试集为0.748 2。 考虑对这4个模型引入空间纹理信息, 是否引入纹理信息的不同模型的预测效果如表4所示, 不同模型对应的残差分布图如图7所示, 横坐标为预测值, 纵坐标为观测值与预测值之间的差异, 即残差值。
| 表4 是否引入纹理信息的不同模型预测效果 Table 4 Predictive effects of different models with or without the introduction of texture information |
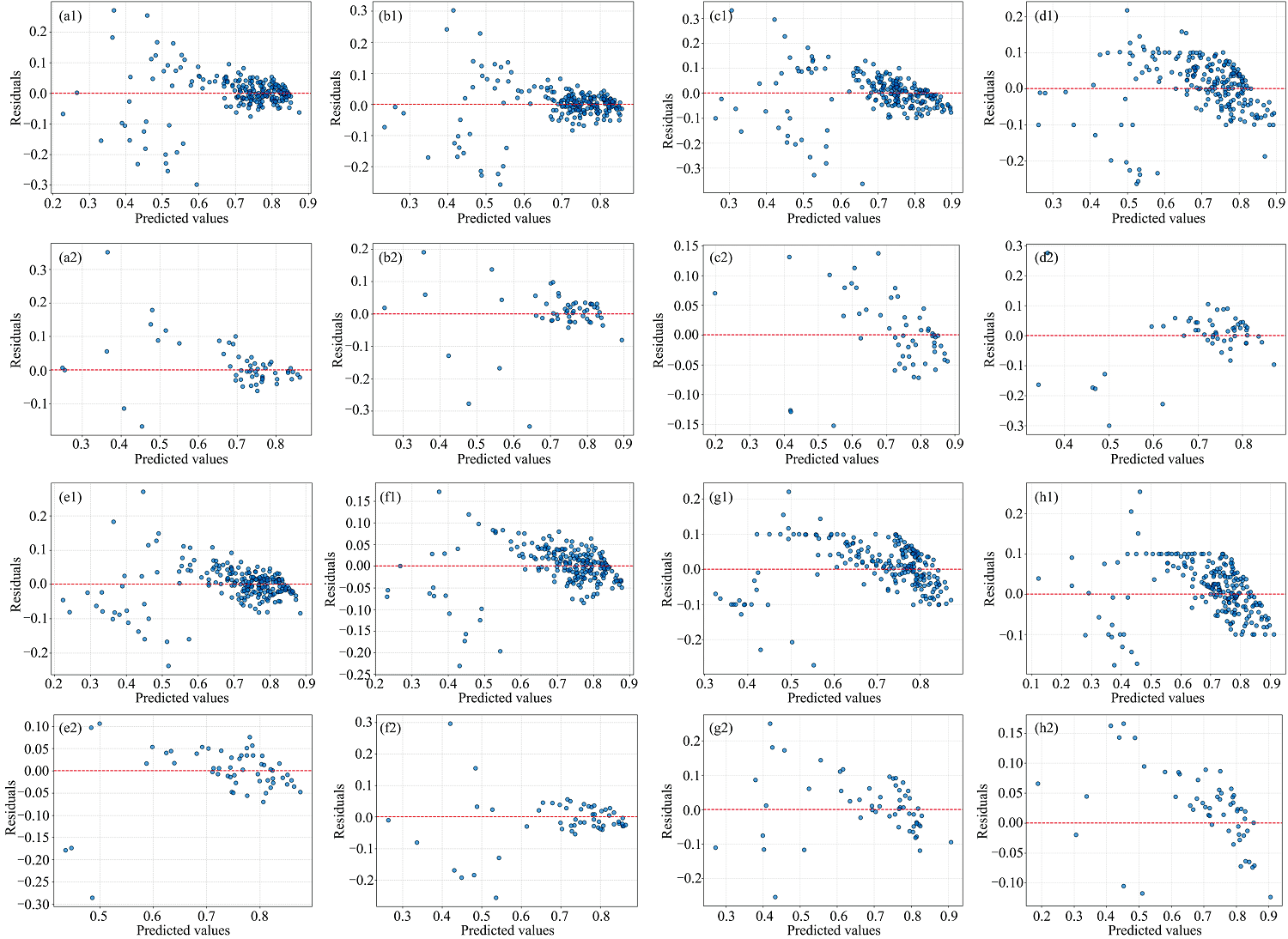 | 图7 是否引入纹理信息的不同模型的残差分布图 |
引入纹理信息之后, MSC+FD-3-haar-Lasso和MSC-5-rbio1.3-SVR这两个模型的训练集的R2和RMSE均增加, 测试集均减少, 对应的残差分布图如图7(b1)、 (b2)和(d1)、 (d2), 测试集(b2)和(d2)均有呈曲线变化的趋势, 说明模型可能未捕捉到数据的非线性关系。 分析可知, 经过离散小波分解后, 再引入空间纹理信息, 模型测试集准确率减少。 这是由于离散小波分解通过不同的小波基函数, 经过了一系列数学变换后保留下近似系数, 数据的物理意义发生了变化, 引入纹理参数后对经过离散小波变换后的数据产生了影响, 使得模型预测效果变差。 而建立MSC+FD-CARS-IRIV-Lasso模型和MSC-CARS-SVR模型时, 训练集和测试集的R2和RMSE均增加, 对应的残差分布图如图7(f1)、 (f2)和(h1)、 (h2), 残差均随机分布在0附近, 且没有明显的模式。 分析可知, 预处理之后的数据经过CARS、 IRIV和CARS-IRIV进行特征筛选后, 再引入空间纹理信息, 建立的预测模型的测试集准确率提升了。
实验结果进一步表明了纹理信息能够有效地弥补光谱反射率数据在空间维度信息的丢失。 高光谱数据通过数百个连续的窄波段捕捉地物的精细光谱特征, 能够反映物质的分子结构和化学成分, 如含水率、 植被的叶绿素含量等。 而空间纹理信息反映作物对象在空间分布上的结构特征, 如形状、 结构等。 叶片等相对平整的器官含水率预测相对成熟。 但油菜角果皮结构复杂(三维立体、 表面不平整、 内部有空腔、 含水率分布可能不均)、 体积小、 在冠层中分布密集且相互遮挡。 空间纹理信息引入, 量化角果表面的空间变异和结构细节(如皱纹、 凹凸), 这些结构与其失水过程和含水状态紧密相关; 另外, 空间纹理可以部分补偿单一像元光谱因角果形状、 朝向引起的变异, 减轻几何光学效应; 局部纹理变化可能指示了角果皮不同部位含水率的差异。 因此将光谱数据与空间纹理特征融合, 输入学习模型, 空间纹理信息通过补充光谱数据缺乏的结构化特征, 增强模型对地物空间分布规律的捕捉能力, 解决光谱歧义性问题, 提升特征表达能力, 提升回归精度和预测能力, 并增强模型对噪声和异常值的鲁棒性。
用大疆M600 Pro型无人机搭载Nano-Hyperspec高光谱仪, 应用于油菜角果含水率的预测。 主要研究结论如下:
(1)光谱预处理技术能够突出光谱中的一些隐藏信息, 对油菜光谱进行多元散射校正、 一阶求导数学变换后更加有利于提取光谱敏感信息。
(2)基于全波段数据, 经过预处理、 特征波段筛选后, 构建了PLSR、 Lasso、 SVR和ELM模型预测含水率。 对原始数据进行MSC+FD处理, 并采用CARS、 IRIV、 CARS-IRIV这3种特征波段筛选方法进行特征选择。 基于处理后的数据建立线性模型(PLSR、 Lasso)和非线性模型(SVR、 ELM)的油菜角果含水率预测模型。 预测效果最好的算法组合为MSC+FD-CARS-IRIV-Lasso, 测试集的R2为0.772 0。
(3)PLSR能够在样本数量较少的情况下获得理想的预测效果, PLSR通过降维提炼出最重要的信息, 适合处理高维数据。 SVR通过调整核函数和参数, 可以适应不同类型的数据分布, 适用于对模型泛化性能要求较高的情况。 SVR和PLSR因为能够有效处理高光谱数据的非线性关系和高维度问题, 通常在利用遥感高光谱数据预测植被含水率方面显示出较好的适用性, 而被较广泛的应用。 而此前, Lasso回归和ELM虽然在某些方面具有优势, 但在植被含水率预测方面的应用较少。 研究发现, Lasso回归通过L1正则化实现特征选择, 特别适用于特征数量多于样本数量的情况, 且Lasso回归能够产生稀疏模型, 有助于提高模型的解释性, 并取得较好的预测效果。 ELM以其快速训练而闻名, 因为它不需要迭代优化权重, 适用于大规模数据集和高维特征空间。 ELM的训练速度快, 但可能不如其他模型那样灵活, 因为它不进行权重的迭代优化, 对于非常复杂的非线性关系, ELM可能不如其他几个模型表现好。
(4)利用高光谱影像的图谱合一的特性, 在纯光谱模型的基础上, 引入空间纹理信息, 弥补在空间维度信息上的缺失。 与纯光谱模型对比, 基于特征参数、 植被指数和纹理信息建立的PLSR、 Lasso、 SVR和ELM模型在模型准确率均有所提升。 选择CARS、 IRIV和CARS-IRIV特征筛选方法进行降维后, 引入纹理信息之后, 能够在一定程度上提升预测模型的准确率。
本研究提出并实现了一种基于同源高光谱数据的深度特征融合框架。 不仅利用了高光谱数据丰富的光谱信息, 更创新性地从其空间维度提取了多尺度的纹理特征(如GLCM等), 并通过特征选择后拼接实现了光谱特征与空间纹理特征的深度协同与互补。 这种深度融合策略显著区别于以往仅依赖光谱信息或简单结合多源异质数据的研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|