




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三维荧光光谱结合2D-LDA的食用油掺假鉴别研究
[姜海洋1, 3  , 崔耀耀
, 崔耀耀2 , 贾彦国1, * , 谌志鹏3 ]
, 崔耀耀, 谌志鹏|
|


作者简介: 姜海洋, 1975年生, 燕山大学信息科学与工程学院博士研究生 e-mail: jianghy@tstc.edu.cn
食用油掺假行为严重威胁消费者的身体健康并扰乱社会市场秩序。 研究有效的食用油掺假鉴别方法对于构建安全、 可靠的食品供应链和提升消费者福祉具有重要意义。 以食用油中的香油为例开展食用油掺假鉴别方法研究。 通过芝麻香精与玉米油、 大豆油以及菜籽油三种食用油配制了3类掺假香油; 使用FLS920稳态荧光光谱仪采集了这3类掺假香油以及不同品牌香油共计45个实验样本的三维荧光光谱数据; 基于2D-LDA方法提取了实验样本的二维特征, 并以此为依据采用最近邻分类原理实现了掺假食用油的准确鉴别。 将所述方法与平行因子结合非线性判别分析(PARAFAC-QDA)、 多维偏最小二乘——判别分析(NPLS-DA)两种方法进行了对比。 结果表明, 2D-LDA方法能够有效提取掺假香油的二维特征。 这些特征能够使不同类别的实验样本在投影子空间中实现最大程度分离; 同时可使相同类别的实验样本在子空间中尽可能地紧密聚集, 进而使得样本在低维子空间中具有更好的可分性, 从而获得了100%的鉴别准确率。 而PARAFAC-QDA和NPLS-DA两种方法仅分别获得了85%和95%的鉴别准确率。 2D-LDA方法相比于这两种方法在食用油掺假鉴别特别是现场快速检测的实际应用中更具优势和潜力, 其鉴别过程与结果更加简捷和精确。 研究为现场食品安全监管提供了一种高效可行的新方案。
The adulteration of edible oil seriously threatens consumers' physical health and disrupts the social market order. Therefore, developing effective methods for identifying adulterated edible oil is crucial to establishing a safe and reliable food supply chain and enhancing consumer welfare. This article studies a method to identify adulterated edible oil using sesame oil as a case study. The study first formulated three types of contaminated sesame oil by adding sesame flavor, corn oil, soybean oil, and rapeseed oil. The FLS920 steady-state fluorescence spectrometer was then employed to collect 3D fluorescence spectrum data from 45 experimental samples, including these three types of contaminated sesame oil and different brands of pure sesame oil. Subsequently, two-dimensional features were extracted from the experimental samples using the 2D-LDA method. The principle of nearest-neighbor classification was applied to identify adulterated edible oils accurately. Moreover, the proposed method was compared with the PARAFAC-QDA and NPLS-DA methods. The results demonstrated that the 2D-LDA method effectively extracted two-dimensional features characterizing adulterated sesame oil. These features facilitated maximum separation of different classes of experimental samples in the projection subspace. Simultaneously, they allowed experimental samples of the same class to cluster closely in the subspace. The distinct characteristics of these features enhanced sample separability in the low-dimensional subspace, resulting in 100% identification accuracy. In contrast, the PARAFAC-QDA and NPLS-DA methods achieved 85% and 95% discrimination accuracies, respectively. Hence, the 2D-LDA method outperformed these two methods in identifying edible oil adulteration, offering a simpler and more accurate identification process and results. This study provides an efficient and feasible new solution for on-site food safety supervision.
香油是一种常用的食用油, 具有特殊的风味和营养价值[1, 2]。 一些不法商家为了牟取利益, 可能会向芝麻油中掺入廉价的、 甚至是有害物质的成分, 从而降低成本或改变产品的性质[3]。 这种行为对消费者的健康构成潜在威胁, 同时也扰乱了市场秩序。 准确鉴别掺假食用油有利于保障食品安全、 维护消费者权益与市场秩序、 促进行业健康发展以及建立品牌信誉和消费者信任。 开展掺假食用油鉴别研究对于构建安全、 可靠的食品供应链和提升消费者福祉具有重要意义。
掺假香油通常采用劣质油掺入色素和香精调制而成, 很难通过观察外观和气味进行鉴别。 目前主要通过特定技术检测食用油中的特殊成分如香料、 添加剂等, 以实现食用油掺假鉴别的目的。 荧光光谱技术以其高灵敏度、 非破坏性、 检测快速以及多组分同时分析等优势被广泛应用到食用油品质鉴别中[4, 5]。 潘钊等采用三维荧光光谱结合Tchebichef矩、 小波矩分别对食用油进行了分析, 实现对植物油掺假的简单、 快速鉴别[6, 7]。 吴希军等采用Zernike矩提取了食用油三维荧光光谱的形状特征, 并结合聚类分析和GRNN(广义回归神经网络)模型实现对植物油定性和定量分析。 孔德明等使用三维荧光光谱结合交替惩罚三线分解(APTLD)方法实现对食用油所含成分鉴别及其含量预测[8]。 这些研究成果在一定程度上为食用油掺假鉴别提供了理论参考和实验依据。
本工作以食用油中的香油为例开展了香油掺假鉴别研究。 通过芝麻香精与3种廉价食用油配制了3类掺假香油, 使用荧光光谱仪采集了掺假香油和不同品牌香油共计45个样本的三维荧光光谱数据, 基于2D-LDA方法实现了掺假香油的快速、 准确鉴别。 本研究思路与结果为食用油掺假鉴别提供了一种新途径, 也为相关部门及企业提供了参考依据。
实验选用芝麻香精(E1)配制掺假香油样本, 选择不同品牌的香油(S1— S14)、 玉米油(C1)、 大豆油(B1)以及菜籽油(R1)4类食用油作为实验样品。 掺假香油样本的配制过程: 采用移液枪量取一定体积的芝麻香精, 将其移至容量瓶中; 量取一定体积的玉米油同样移至该容量瓶中, 并将该容量瓶置于往复式振荡器上震荡以使芝麻香精和玉米油充分混合, 振荡频率和时间分别设置为100 r· min-1和1 h; 分别量取不同比例的芝麻香精和玉米油重复上述步骤, 共配制9个掺假样本。 使用大豆油及菜籽油分别与芝麻香精配制另外两类掺假样本, 最终共得到27个(3× 9)掺假香油样本, 实验样本详细信息如表1所示。
| 表1 实验样本详细信息 Table 1 Detailed information of experimental samples |
使用爱丁堡公司生产的FLS920稳态荧光光谱仪(精度: 0.1 nm)测量表1中实验样本的三维荧光光谱数据。 FLS920使用450 W的氙灯作为激发光源, 其信噪比为6 000∶ 1。 测量三维荧光光谱时设置仪器的激发波长扫描范围为250~550 nm, 步长为10 nm; 发射波长的扫描范围为260~750 nm, 步长为2 nm; 激发和发射狭缝宽度均为1.11 mm, 扫描的积分时间为0.1 s。
使用MATLAB R2016b (Windows 10操作系统)处理获得的三维荧光光谱数据。 为了有效评估方法性能, 将所有实验样本随机分成两类, 一类作为训练集样本共25个, 另一类作为测试集样本共20个。
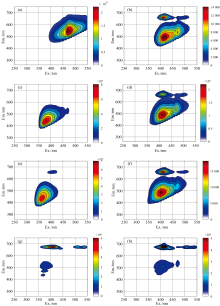
实验样本所获得的三维荧光光谱如图1所示。 其中, (a)香油S1, (b)芝麻香精E1, (c)玉米油C1, (d)掺假香油CE8, (e)大豆油B1, (f)掺假香油BE5, (g)菜籽油R1, (h)掺假香油RE5。 由图可知, 香油有一个位于激发/发射波长470/550 nm处的荧光峰; 芝麻香精则有四个荧光峰, 分别位于激发/发射波长为410/660、 420/494、 470/540以及500/660 nm位置; 玉米油的荧光峰集中在激发/发射波长380/440 nm处; 大豆油有两个荧光峰, 分别位于激发/发射波长为360/430和410/658 nm位置; 菜籽油有六个荧光峰, 分别位于激发/发射波长为410/676、 510/674、 540/676、 380/516、 370/470以及370/438 nm处, 这些区域产生的光谱主要归因于植物油中所含的饱和脂肪酸、 单不饱和脂肪酸、 双烯酸以及多烯酸等成分[9]。 可以看出, 芝麻香精与香油的主要荧光区域重叠, 因此由芝麻香精与其他食用油所构成的3类掺假香油也均与香油的主要荧光区域存在一定程度重叠。
二维线性判别分析(2-dimensional linear discriminant analysis, 2D-LDA)是一种经典的模式识别和统计分类方法[10]。 2D-LDA通过引入二维投影矩阵, 将数据从原始高维空间投影到一个二维子空间中, 使得在降低数据维度的同时保留了更多的判别信息, 进而有助于提高分类性能[11]。 2D-LDA的步骤和原理如下[12, 13]:
(1) 整理数据集及对应类别标签。 香油设定类别标签为1, 三类掺假香油设定类别标签分别为2、 3和4, 而每一个样本的三维荧光光谱数据矩阵X(m× n)包含真假香油所含不同成分的荧光特征, 其通过激发波长(m)和发射波长(n)处对应的相对荧光强度表征。
(2) 对于每个类别, 通过将X乘以投影矢量a(n× 1)计算该类别下所有样本的均值向量y(m× 1)
式(1)中, 均值向量y的第i分量yi由矩阵X的第i行mi与投影矢量a之间的标量积给出, 其表示该类别在特征空间中的中心位置。
通过类内散布矩阵SB计算每个类别内部的离散程度
式(2)中,
对于不同类别, 通过类间散布矩阵SW计算其类别之间的分离程度, 见式(5)
对于式(1)中的投影矢量a通过式(6)计算最佳投影矢量aopt, 见式(6)
如果SW是非奇异矩阵, 则aopt需满足以下条件
式(7)中, λ 是
选择一组正交约束的投影向量{a1, a2, …, ar}构建二维投影矩阵A, 并将该投影矩阵与三维荧光光谱数据X相乘得到特征矩阵Y(m× r), 最终将数据X投影到二维子空间中, 见式(8)。
最后, 基于最近邻分类原理对特征矩阵Y进行分类。 其中, 通过欧氏距离d(Ytest, Ytrain)评估测试集和训练集样本之间的相似性, 见式(9)
$d\left(Y_{\text {test }}, Y_{\text {train }}\right)=\sqrt{\operatorname{trace}\left[\left(Y_{\text {test }}-Y_{\text {train }}\right)^{\mathrm{T}}\left(Y_{\text {test }}-Y_{\text {train }}\right)\right]}$(9)
根据获得的欧式距离判断测试样本所属类别, 对于每一个训练样本所属的类别Cp可通过式(10)获得
2D-LDA通过线性变换将原始高维特征空间投影到了一个低维子空间, 使得不同类别样本在投影后的子空间中能够最大程度分离, 同时相同类别样本在子空间中尽可能地紧密聚集, 进而使样本在低维子空间中具有更好的可分性。 因此2D-LDA在处理高维数据和复杂分类问题时存在一定的优势。
采用2D-LDA方法香油与3类掺假香油训练集样本前3个特征向量如图2所示。 图2(a、 b、 c)分别是第一特征向量、 第二特征向量以及第三特征向量, 图中横坐标代表样本的发射波长, 纵坐标则代表所提取的相应发射波长处的特征值。 由图2看出, 同一类别样本的特征轮廓极为相似, 香油与3类掺假香油的特征轮廓则差异明显。 而3类掺假香油由于均含有芝麻香精导致其特征轮廓存在一定程度的相似, 但每一类掺假香油的特征强度也存在区别。
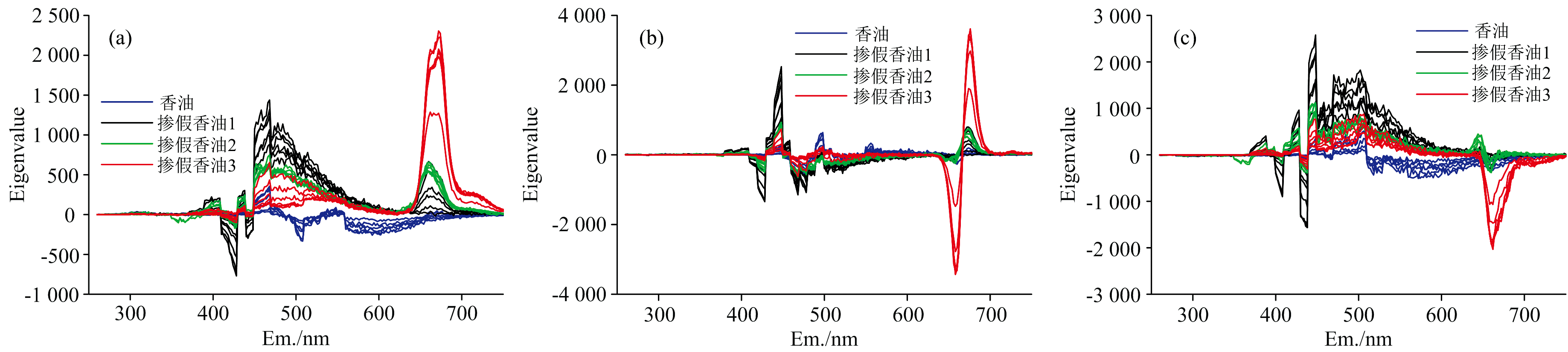 | 图2 训练样本提取的2D-LDA特征 (a): 第一特征向量; (b): 第二特征向量; (c): 第三特征向量Fig.2 2D-LDA features extracted from training samples (a): First eigenvector; (b): Second eigenvector; (c): Third eigenvector |
采用2D-LDA方法提取香油和3类掺假香油训练集样本的前3个特征向量。 计算测试集和训练集样本之间的欧氏距离, 并据此确定测试样本所属的类别, 实现香油掺假鉴别的目的。 其中测试集中第2个、 第9个、 第13个以及第17个样本与所有训练集样本之间的欧式距离分别如图3(a、 b、 c、 d)所示, 图中横坐标代表所有训练集样本, 纵坐标代表测试样本与训练集样本间的欧式距离, 红色实心圆点标记为最小欧式距离。
 | 图3 测试集样本的鉴定结果 (a): 第2测试样本与训练样本之欧式距离; (b): 第9测试样本与训练样本之欧式距离; (c): 第13测试样本与训练样本之欧式距离; (d): 第17测试样本与训练样本之欧式距离Fig.3 Identification result of the test samples (a): Euclidean disdance between the 2nd test sample and the training set samples; (b): Euclidean disdance between the 9th test sample and the training set samples; (c): Euclidean disdance between the 13th test sample and the training set samples; (d): Euclidean disdance between the 17th test sample and the training set samples |
由图3(a)可知第2个测试样本与训练集中前6个样本间的欧式距离均较小, 且与训练集中第5个样本(ID=5)具有最小欧式距离Min distance=1471.75, 训练集中前6个样本均为香油, 因此第2个测试样本被鉴别为香油; 同理, 第9个、 第13个以及第17个样本分别被鉴定为第1类、 第2类和第3类掺假香油。 由图3还可以看出测试样本与相同类别的训练集样本之间的欧式距离均较小, 与不同类别样本之间的欧式距离则较大, 表明2D-LDA方法所提取的二维特征能够有效地辨识香油类别。
为了比较2D-LDA方法在香油掺假鉴别中的优势, 使用了PARAFAC-QDA和NPLS-DA两种方法进一步分析了香油及掺假香油样本。 如图4(a)所示, 通过奇异值分解方法确定实验样本的PARAFAC因子数为9, 其中前3因子得分如图4(b)所示, 可以看出香油与第3类掺假香油的因子得分在空间上存在一定程度重叠, 而与其他两类掺假香油在空间上则能够有效区分。
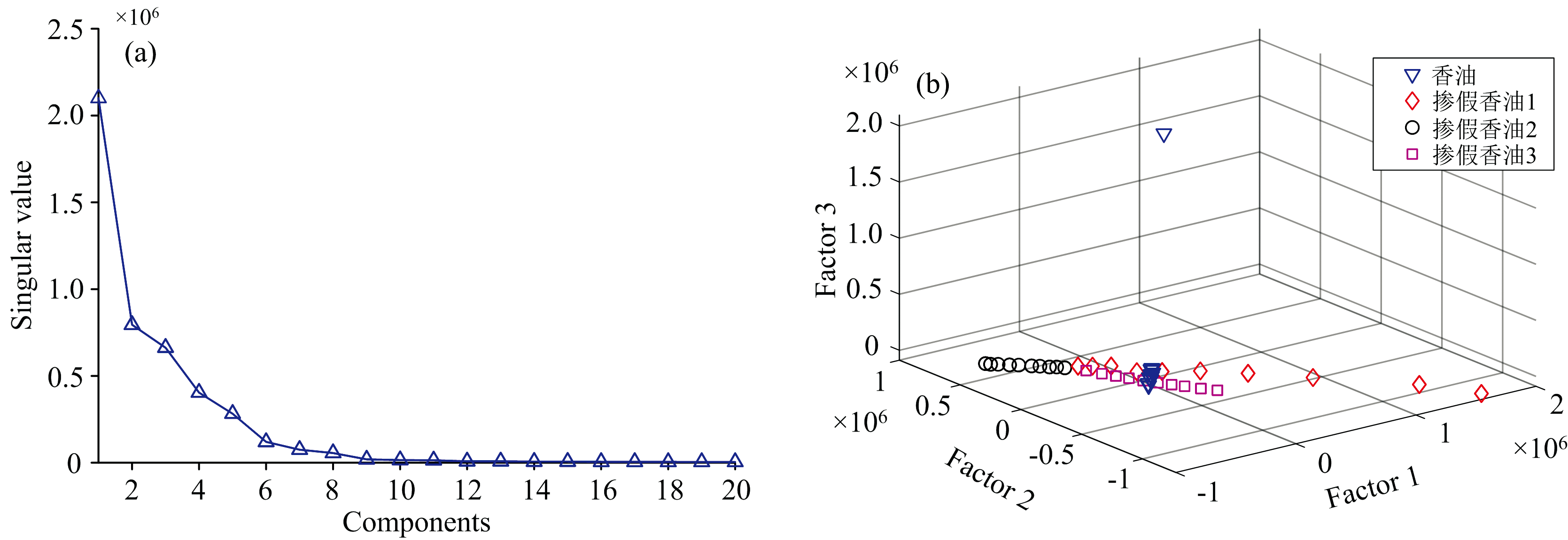 | 图4 实验样本的PARAFAC分析结果 (a): 奇异值与因子数关系曲线; (b): 前3因子得分图Fig.4 PARAFAC analysis results of experimental samples (a): Curve of relationship between singular values and number of factors; (b): Scatter plot of the top 3 factors |
如图5(a)所示, 实验样本的NPLS-DA潜在变量数通过交叉验证方法确定为9, 其中前三变量得分如图5(b)所示, 可以看出香油与三类掺假香油的因子得分在空间上均能够有效区分, 但第1类和第2类掺假香油因子得分却在空间存在一定程度重叠。
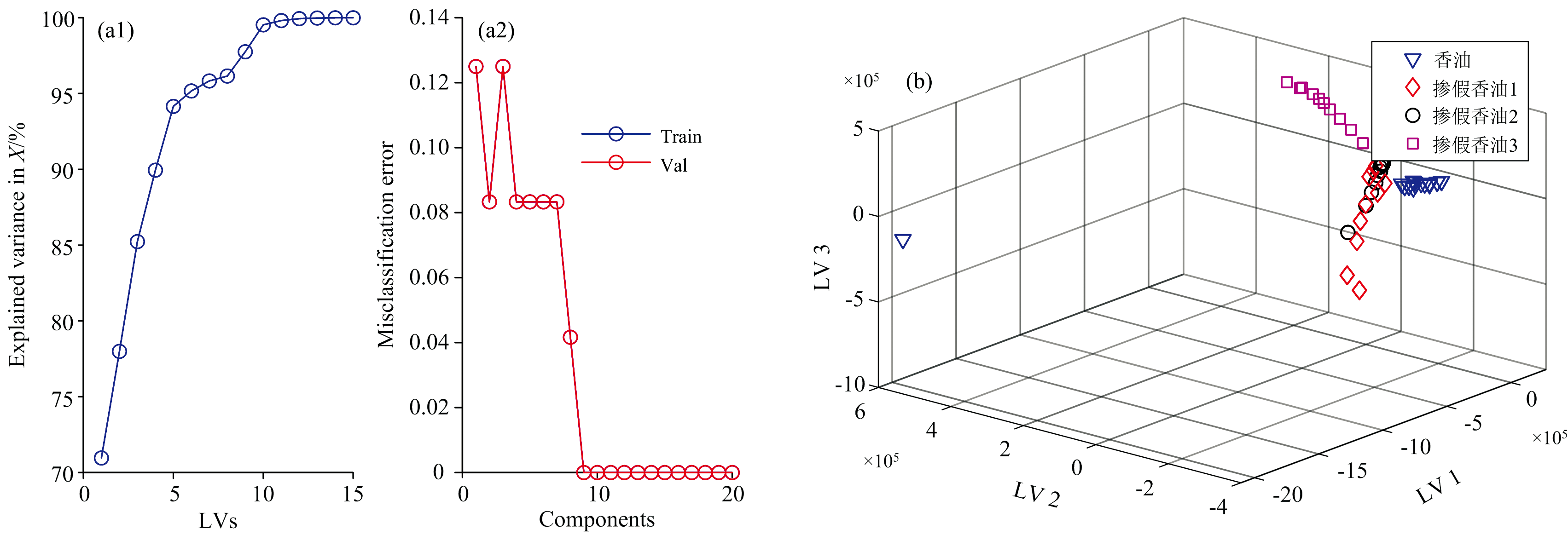 | 图5 实验样本的NPLS-DA分析结果 (a): 潜在变量数确定; (b): 前3变量得分图Fig.5 PARAFAC analysis results of experimental samples (a): Determining latent varibale count; (b): Scatter plot of the top 3 variables |
使用3种方法所获得的测试样本混淆矩阵如表2所示, 该表可以清楚的展示所有测试样本的鉴定结果, 其中被鉴定正确的测试集样本在表2使用粗体表示。 由表2可以看出, 使用2D-LDA方法时所有的测试样本类别均被鉴定为正确; 使用PARAFAC-QDA方法时有3个第3类掺假香油被鉴别为香油, 这与图4(b)所示结果一致; 而使用NPLS-DA方法时有1个第1类掺假香油被鉴定为第2类掺假香油, 其他全部鉴别为正确结果, 虽然不影响真假香油鉴别结果, 但由上述分析可知2D-LDA方法提取的特征分辨率更高, 对掺假香油的鉴别也更加准确。
| 表2 测试集样本获得的混淆矩阵 Table 2 Confusion matrix obtained for test set |
使用精确度、 灵敏度、 特异性以及准确率四个指标评价所述方法, 如表3所示。 2D-LDA方法获得了100%的正确率, 其表现最佳; NPLS-DA方法获得了95.0%的正确率, 其表现次之; 而PARAFAC-QDA模型获得了85.0%的正确率, 其表现最差。 每一种类型的实验样本具体评价结果可以从精确率、 灵敏度和特异性这三个评价指标获得, 是混淆矩阵的量化表现。 这些评价结果表明2D-LDA能够有效提取香油的分类特征, 因此能够获得更为精确的鉴别结果。
| 表3 不同鉴别方法的评价结果 Table 3 Evaluation results of different identification method |
准确鉴别掺假香油对保护消费者身体健康和维护社会市场秩序具有重要的现实意义。 采用2D-LDA、 PARAFAC-QDA及NPLS-DA三种方法分别分析了香油和掺假香油三维荧光光谱数据。 结果表明, 相比于PARAFAC-QDA和NPLS-DA两种方法, 2D-LDA方法可以更加有效地提取香油以及掺假香油的分类特征, 能够以100%的准确率鉴别香油和掺假香油。 相比于其他方法, 本方法在现场快速检测的实际需求中更具应用潜力, 为现场食品安全监管提供了一种高效可行的方案。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|