





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多任务卷积神经网络的红外与可见光多分辨率图像融合
[朱雯青1, 2, 3  , 张宁
, 张宁1, 2, 3 , 李争1, 2, 3, * , 刘鹏1, 3 , 汤心溢1, 3 ]
, 张宁, 刘鹏|
|


作者简介: 朱雯青,女, 1994年生,中国科学院上海技术物理研究所博士研究生 e-mail: fyzhuwenqing@163.com
红外与可见光图像融合一直是图像领域研究的热点, 融合技术能弥补单一传感器的不足, 为图像理解与分析提供良好的成像基础。 因生产工艺以及成本的限制, 红外探测器的分辨率远低于可见光探测器, 并在一定程度上因源图像分辨率的差异阻碍了实际应用。 针对红外与可见光图像分辨率不一致的问题, 提出了用于红外图像超分辨率重建与融合的多任务卷积网络框架, 应用于多分辨率图像融合。 在网络结构方面, 首先设计了双通道网络分别提取红外与可见光特征, 使算法不受源图像分辨率的限制; 其次提出了特征上采样模块, 先用双线性插值方法增加像素个数, 再通过多层感知器精细化拟合像素平滑空间与高频空间的映射关系, 无需重新训练模型即可实现任意尺度的红外图像上采样; 接着将线性注意力引入网络, 学习特征空间位置间的非线性关系, 抑制无关信息并增强网络对全局信息的表达。 在损失函数方面, 提出了梯度损失, 保留红外与可见光图像中绝对值较大的滤波器响应值, 并计算该值与重建的融合图像响应值的Frobenius范数, 无需理想的融合图像作为真值监督网络学习就能生成融合图像; 此外, 在梯度损失、 像素损失的共同作用下对多任务模型进行优化, 可以同时重建融合图像和高分辨率红外图像。 算法在RoadScene数据集上进行训练, 与其他4种相关算法在TNO数据集上进行对比, 主观性能上该方法可以输入任意分辨率的源图像, 融合图像红外目标突出、 可见光细节纹理丰富, 在源图像分辨率相差较大时能重建特征清晰的高分辨率红外图像, 模型泛化性能强; 客观性能上在信息熵、 差异相关性总量、 空间频率等多个评价指标上表现优异, 结果表明重建的融合图像信息丰富、 信息转化率高、 清晰度高, 验证了算法的有效性。
Infrared and visible image fusion have always been a research hotspot in the image field. Fusion technology can compensate for a single sensor's deficiency and provide good imaging pandation for image understanding and analysis. Due to the limitation of production technology and cost, the resolution of infrared detectors is much lower than that of visible detectors, which prevents practical usage to a great extent. A multi-task convolutional neural network framework combining infrared super-resolution and image fusion tasks is proposed, which is applied to the infrared and visible multi-resolution image fusion. In terms of network structure, firstly, a dual-channel network is designed to extract infrared and visible features respectively, so that the resolution of each source image does not limit the proposed algorithm. Secondly, the feature up-sampling block is proposed, using the bilinear interpolation method to increase the number of pixels. Then the mapping relationship between pixel smooth space and high-frequency space is refined via a multilayer perceptron. Therefore, the infrared images can be presented on an arbitrary scale, where the training tasks are not provided. Furthermore, the linear self-attention mechanism is introduced into the network to learn the nonlinear relationship between feature space positions, suppress irrelevant information and enhance global information expression. In terms of the loss function, the gradient loss is proposed to retain the filter response with larger absolute values in the infrared and visible images and calculate the Frobenius norm between the value and the response value of the reconstructed fusion image. Thus, fusion images can be generated without ideal images as ground truth supervising network learning. Finally, the fused and high-resolution infrared images can be reconstructed simultaneously by optimizing the multi-task model under the combined action of gradient loss and pixel loss. The proposed approach is trained on the RoadScene dataset and compared with the other four related algorithms on the TNO dataset. In terms of subjective performance, the proposed method can input source images with the arbitrary resolution, and fusion images have prominent infrared targets and rich visible details. When the resolution of source images is quite different, the proposed method can still reconstruct high-resolution infrared images with clear features and has robust generalization. The objective performance is excellent in multiple evaluation metrics such as entropy, the sum of the correlations of differences and spatial frequency. Experimental results demonstrate that fusion images have a large amount of information, high information conversion rate and high clarity, which verifies the effectiveness of the proposed method.
随着传感器技术的发展, 单一传感器已经满足不了日益发展的需求。 图像融合技术能够结合不同图像传感器的优势对目标特征进行表达, 从而获得增强目标特性的效果。 红外与可见光图像融合技术一直是图像融合领域的研究热点之一, 红外探测器能在低光照、 恶劣天气条件下描述热目标, 目标显著性强却纹理细节信息少, 可见光图像分辨率高、 符合人眼视觉感受但是容易受到光照天气的影响。 图像融合技术将红外与可见光波段的信息以适宜的策略进行有效信息, 广泛应用在多光谱遥感分析、 军事探测等领域。
国内外有较多学者从事红外与可见光图像融合算法的研究, 提出了基于引导滤波[1]、 稀疏表示[2]、 脉冲耦合神经网络[3]等融合算法。 同时深度学习在图像融合领域也取得了较大进展, 如Liu等提出了一种基于孪生卷积网络的图像融合算法[4], Ma等首次提出了基于生成对抗网络的端到端图像融合算法[5], Li等提出了基于空间通道注意力机制的卷积网络融合算法[6]等。 但是大部分算法都只适用于红外图像与可见光图像分辨率一致的情况下。 在实际应用中, 因硬件工艺、 成本的限制, 红外探测器的分辨率远低于可见光探测器, 但是从硬件上提升红外探测器分辨率的成本很高。 一般思路是将低分辨率红外图像用超分辨重建方法得到高分辨率的红外图像, 再与高分辨率可见光图像进行图像融合, 这类方法的缺点是超分与融合任务中重复提取特征, 算法复杂度比较高。 针对这个问题, Ma等[7]提出了基于双判别器条件生成对抗网络的多分辨率图像融合算法(DDcGAN), 生成器企图生成真实的融合图像欺骗两个判别器, 双判别器分别区分融合图像和源图像之间的结构差异, 并利用了反卷积层学习高低分辨率之间的映射关系, 但该方法的缺点在于输入的图像尺度受到限制, 一个模型只能适应一种尺度, 当源图像的尺度改变时需要重新训练模型。 Li等提出了基于元学习的红外与可见光图像融合算法[8], 采用卷积网络分别提取源图像的特征, 并用元上采样模块根据实际需求实现任意分辨率的上采样, 然而该方法在源图像倍数相差较大时噪声较大, 纹理细节缺失严重。
针对以上问题, 提出了基于多任务学习的卷积神经网络框架, 用于红外与可见光多分辨率图像融合。 将超分辨思想引入融合问题中, 先采用双通道卷积网络分别提取源图像的特征, 再采用特征上采样模块对红外图像特征进行超分辨率重建, 接着通过线性注意力机制学习特征空间位置的非线性关系, 提升网络对全局信息的提取, 同时提出了梯度损失函数, 无需理想的融合图像进行监督训练, 并且模型不受源图像分辨率比例关系的限制, 一个模型就能实现任意分辨率的图像融合。
1.1.1 总体框架
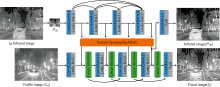
在红外与可见光图像的分辨率不一致的情况下进行图像融合, 首先需要有效提取源图像的重要信息, 再提高红外特征的分辨率, 同时与可见光特征进行有效融合, 最后重建出高分辨率的融合图像。 研究中设计了多任务卷积神经网络, 整个模型由两个子网络组成, 分别用于红外图像超分辨率重建和图像融合两个任务, 模型框架如图1所示。
 | 图1 模型框架图Fig.1 Architecture of the model |
红外图像超分辨率重建部分网络分为特征提取、 特征上采样两个过程。 特征提取层由4组3× 3卷积层、 leaky ReLU激活函数组成, 为了防止梯度消失, 使用了残差结构, 用短连接将上一层的输出传递到下一层输出, 同时将前4层提取的红外特征输入特征上采样模块, 输出特征的大小为可见光图像分辨率, 最后将上采样后的红外特征用3× 3卷积层、 Tanh激活函数映射到[-1, 1]区间得到超分辨率后的红外图像
1.1.2 特征上采样模块
广义上的空间域超分辨率重建方法包括三个类别: 基于插值、 基于重建和基于学习的重建方法。 其中最早提出的是基于插值的重建方法, 这种方法理论简单、 易于实现, 包括双线性插值、 双立方插值等。 超分辨重建是一个病态问题, 难点在于上采样过程, 一般上采样层有亚像素卷积层、 反卷积层[9]等方法。 亚像素卷积层是将若干个特征图的像素重新排列成一个新的特征图, 例如, 在放大倍数为r的网络中, 假设特征图尺寸为r2× H× W, 亚像素卷积层会将该特征图重新排列成1× rH× rW的高分辨率特征图, 从而达到上采样的效果。 反卷积层是通过转置后的转换矩阵与特征图进行卷积操作, 从而将低维特征映射到高维特征。 但是这些上采样方法只能实现单一倍数的上采样, 任意尺度上采样一直是超分领域的难点。
为了能够生成任意分辨率的红外超分图像, 研究中设计了特征上采样模块, 结构如图2所示。 首先用双线性插值方法按照平滑性假设增加像素个数, 初步计算得到高分辨率红外特征, 实现特征高宽与可见光特征相同, 然后利用多层感知器(multilayer perceptron, MLP)学习平滑特征与真实高分辨率特征间的非线性关系, 多层感知器由4层参数为[256, 256, 256, 64]的全连接层组成, 在每层全连接层后用ReLU激活函数防止网络退化, 增强网络非线性。 令双线性插值后得到的特征图为F0, 每层隐藏层按照式(1)不断迭代传播信息
式(1)中, Fl-1和Fl分别表示第l-1、 l层的特征, Wl和bl分别表示第l层的权重与偏置, fl表示ReLU激活函数。
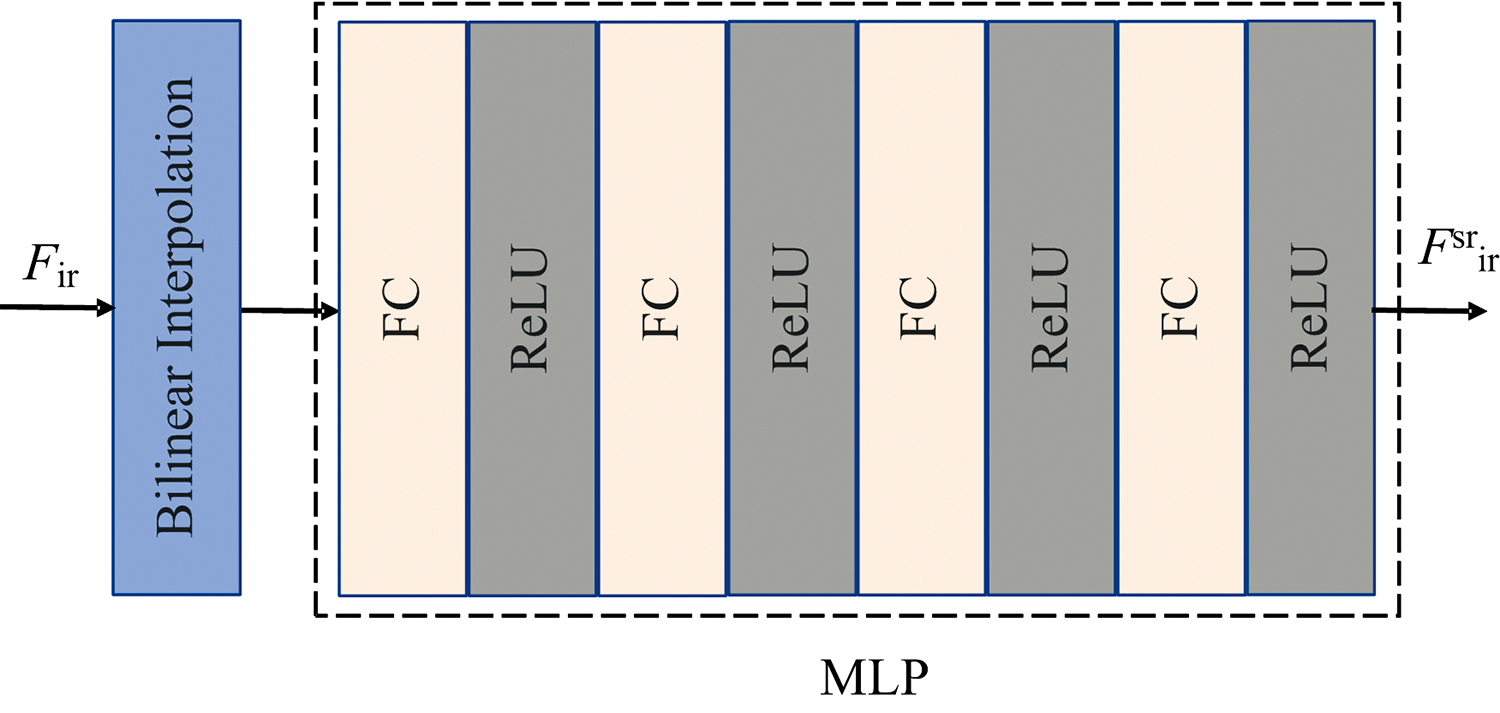 | 图2 特征上采样模块结构示意图Fig.2 Architecture of feature up-sampling block |
1.1.3 线性注意力模块
传统卷积网络的感受野受到卷积核大小以及网络深度的限制, 难以学习到全局信息。 自注意力这一概念最早应用在自然语言处理领域, 是一种计算单个序列不同位置的关联来表达序列的注意机制, 可以将全局信息引入网络中, 增加感受野。 自注意力机制通过测量查询向量元素与每个关键向量元素之间的相似度来选择相关信息, 输出向量是由相似度得分加权值向量的总和, 如果相似度高就能从值向量中提取相关信息。 令输入的序列为x, 分别用投影矩阵Wq∈ RF× D, Wk∈ RF× D, Wv∈ RF× M将x映射为查询向量Q、 关键向量K、 值向量V, x的自注意力计算公式如式(2)所示。
式(2)中, D为列向量的维度, softmax激活函数作用在QKT上。 假设将Q和K的长度表示为N, 同时设它们的特征维度为D, Q和K的点积引入了计算成本, 并且计算复杂度随输入序列的长度呈二次方增长[O(N2)], 在提取尺寸较大的图像全局信息时对计算资源要求很高。
本工作引入了线性注意力机制, 能在提取全局相关信息的同时减少计算成本, 模块结构如图3所示。 先将红外与可见光特征在通道维度相加以后得到特征fin, 特征大小为[B, H, W, C], 分别用矩阵Wq∈ RC× D, Wk∈ RC× D, Wv∈ RC× D将fin映射为尺寸为[B, H, W, D]的Q, K, V。 自注意力中最重要的是计算Q和K之间的关系, 可以由式(3)表示。
原始自注意力机制中的相似性是由内积计算得到的, Linear Transformer通过用替代核函数sim(Q, K)=ϕ (Q)ϕ (K)T的方法代替原始注意力层中使用的指数核, 将自注意力的计算复杂度降低到O(N), 计算方法如式(4)所示。
然后用激活函数ϕ (x)增强特征Q和K的非线性表达能力得到ϕ (Q)∈ RB× H× W× D, ϕ (K)∈ RB× H× W× D, 计算特征图中每个位置与其他位置特征的相似性权重V'i, 并与fin相加得到fout。
 | 图3 线性注意力结构图Fig.3 Architecture of linear attention |
图像融合是一个无监督问题, 损失函数决定了多分辨率图像的融合效果。 本工作需要同时对超分辨率重建和图像融合任务进行优化来提高模型的学习能力, 因此设计了多任务损失函数, 模型损失函数由梯度损失Lgradient和像素损失Lpixel组成。
理想的融合图像既能包含可见光的细节纹理信息, 又能突出红外热目标。 一般图像边缘越清晰, 图像信息越丰富, 清晰度越高。 为了保留源图像中的特征并将其融合在一张图像上, 需要保留红外与可见光图像中的灰度变化趋势, 实现互补信息的融合。 采用高斯拉普拉斯算子LoG分别计算可见光图像IVis、 红外图像IIR和生成的融合图像If的响应值, 保留红外与可见光图像中梯度变化较大处的响应值, 并计算该值与融合图像响应值的Frobenius范数, 如式(5)和式(6)所示。
其中, ∇
像素损失Lpixel用来优化真实高分辨率与超分辨重建的红外图像间灰度值分布差异, 如式(7)所示。
式(7)中, IIR表示真实红外图像,
像素损失Lpixel与梯度损失Lgradient共同组成了本模型的损失函数Ltotal对网络进行训练, 并引进参数λ 平衡Lpixel和Lgradient对模型的作用, 如式(8)所示。
本文在RoadScene数据集进行模型训练, 该数据集从FLIR数据集中选取了221对红外与可见光图像进行图像增强、 配准等预处理。 在RoadScenes数据集中随机抽取了200对图像作为训练集, 为了测试模型泛化性能并且更直观地与其他算法进行对比, 从TNO数据集中选取20对图像作为测试集。 在训练模型前, 先将训练集用水平翻转、 垂直翻转与90° 旋转等方法进行数据增强, 并每隔12像素将图像裁剪成64× 64大小, 扩充训练集防止模型过拟合。 然后将高分辨率红外图像作为真值IIR(ground truth), 将IIR进行4倍双三次下采样后得到低分辨率红外图像
本研究中网络使用的卷积大小均为3× 3, 通道数为64, 损失函数中的λ 为500, 使用参数β 1=0.9, β 2=0.999的Adam[10]算法进行优化, 整个模型训练的epoch数为10, 批量大小为32, 学习率设为10-4。 模型使用了Tensorflow框架, 训练环境为NVIDIA 1080 Ti GPU。 本算法与ASR[2], HMSD_GF[11], FusionGAN[5], MLF[8]算法在TNO测试集上进行了对比, 其中ASR、 HMSD_GF为传统算法, FusionGAN、 MLF为基于深度学习的算法。 除了对算法进行主观评价以外, 还使用了信息熵(entropy, EN)、 差异相关性总量(sum of the correlations of differences, SCD)[12]、 标准差(standard deviation, SD)、 平均梯度(average gradient, AG)[13]和空间频率(spatial frequency, SF)[14]五个客观评价指标进行图像客观质量评价, 指标值越大表示成像效果越佳。
为了证明所提出方法的有效性, 设置了5种不同尺度的源图像分辨率, 如表1所示。 将原始红外图像使用不同尺度因子的双三次插值计算低分辨率红外图像, 可见光图像分辨率不变, 输出的红外图像、 融合图像的目标分辨率与可见光图像分辨率相同。 例如, Setting #2表示要融合的红外和可见光图像的长、 宽分别是原始图像的1/2和1倍, 即可见光图像分辨率是红外图像的2倍。 红外图像与可见光图像分辨率之间的比例关系是相对的, 因此在改变输入分辨率的同时固定融合图像分辨率与可见光图像分辨率相同的策略是合理的。
| 表1 不同尺度的源图像分辨率设置 Table 1 Source image resolution settings of different scales |
考虑到ASR, HMSD_GF, FusionGAN三种算法只能实现相同分辨率的图像融合, 在测试时这三种方法输入的红外图像是按照表1所示的尺度关系将低分辨率红外图像用双三次插值算法模拟计算得到的, 可见光图像的分辨率不变。 5种算法在TNO数据集“ men in front of house” 图像对上的效果如图4所示。 从图4可得, ASR算法的融合图像较为平滑, 边缘较为模糊, 降低了红外目标的显著性; HMSD_GF算法生成的图像在大块平滑区域出现不必要的纹理变化, 红外目标边界不清晰, 随着红外图像质量的下降, 融合算法效果也受到了影响; FusionGAN 算法生成的融合图像分布趋近于红外图像, 丢失了大量可见光细节特征; MLF算法没有将指示牌等互补信息融合到图像中, 并且在低倍数下生成的图像较为平滑, 在源图像分辨率相差4倍及以上时引入了大量噪声, 细节丢失严重, 边缘出现扭曲。 本算法能够实现不同分辨率的图像融合, 既能突出红外目标, 又能较好保留可见光的细节纹理信息, 并且当红外图像分辨率是可见光图像的1/4、 1/6时, 图像边缘锐化, 有提升对比度的效果。 同时, 本方法无需重新训练模型就能生成任意尺度的红外上采样图像, 在“ man_in_doorway” 图像上的测试结果如图5所示, 与双三次插值方法相比, 在放大6倍时依旧能保持良好的红外目标边缘, 与真值(groundtruth)相比有一定的增强效果。
 | 图4 不同分辨率“ men in front of house” 图像上不同方法的融合结果 从上至下分别为: Settings 1— 5任务下的实验结果, 从左到右分别为ASR, HMSD_GF, FusionGAN, MLF和本计算结果Fig.4 Fusion results of different methods on the “ men in front of house” example with five settings From top to bottom: the results on the tasks of Settings 1— 5; From left to right: the results generated by ASR, HMSD_GF, FusionGAN, MLF and our method, respectively |
 | 图5 在“ man_in_doorway” 不同尺度上采样的视觉比较Fig.5 The visual comparison on the “ man_in_doorway” up-sampling with different scale factors |
研究中抽取了TNO数据集的20对图像进行图像客观质量评价, 结果如表2所示。 setting #1— 5任务中本算法在EN, SCD和SD指标上的表现最好, 在SF指标上本算法在setting#2— 5任务中表现最优, 在AG指标上本算法在setting#3和setting#4任务中表现突出, 其他任务中与HMSD_GF算法接近, 并且随着红外图像分辨率的降低, 本算法优势越明显。 综合来看, 本算法重建的融合图像信息量丰富、 边缘清晰, 纹理细节保留较为完整, 视觉效果较好, 在红外与可见光图像分辨率相差较大时依旧能保持良好的成像质量。 而且本模型在分布差异较大的RoadScene和TNO数据集上分别进行训练与测试, 图像质量的主客观评价结果优异, 说明本模型的泛化能力较强。
| 表2 不同图像融合方法在TNO数据集上的客观评价结果 Table 2 Objective evaluation results of different image fusion methods on the TNO dataset |
为了验证线性注意力和特征上采样模块的作用, 设计了消融实验, 在保证网络参数与损失函数不变的情况下, 去除网络部分结构在相同训练集上重新训练模型, 在setting#4任务的TNO数据集“ soldiers_with_jeep” 图像对上测试结果如图6所示, 其中图6(a)和(b)分别是可见光和4倍放大显示的红外图像。 在保证其他不变的情况下只去除了线性注意力模块, 模型测试结果如图6(c)所示, 保留特征上采样模块中的双线性插值层, 只去除多层感知器, 模型测试效果如图6(d)所示, 本文模型结果如图6(e)所示。 对比可知, 线性注意力可以起到抑制噪声、 伪影等无关信息的作用, 图像表达的视觉感受更佳; 多层感知器能够更精细地学习高低分辨率之间的非线性映射关系, 使得图像边缘更为清晰, 局部对比度更高。
 | 图6 线性注意力和特征上采样模块的有效性验证 (a): 可见光图像; (b): 4倍放大显示的红外图像; (c): 无线性注意力的模型效果; (d): 无多层感知器模型效果; (e): 本算法效果Fig.6 Effectiveness validation of the linear attention block and the feature up-sampling block (a): The Visible image; (b): The infrared image displayed at 4× magnification; (c): The model result without linear attention; (d): The model result without multilayer perceptron; (e): The result of our method |
为了验证本文提出的损失函数对模型的影响, 在保证网络结构和训练参数不变的情况下改变损失函数重新对模型进行训练: (a)L=Lgradient; (b)L=λ Lpixcel, (c)本方法结果, 在setting#4任务“ soldier_behind_smoke2” 上的测试结果如图7所示。 第一行的IVis为可见光图像,
 | 图7 各部分损失函数对模型的作用Fig.7 The effect of each part of the loss function on the model |
针对在实际应用场景下红外与可见光图像分辨率相差较大的问题, 本文提出了多任务卷积神经网络框架, 应用于红外与可见光多分辨率图像融合。 首先本文将超分辨率重建与融合任务相结合, 提出了特征上采样模块, 实现任意倍数的红外图像超分辨率重建, 同时实现不同分辨率的红外与可见光图像融合。 其次引入了线性注意力机制学习特征间的非线性关系, 提升图像的视觉表达。 同时提出了一种梯度损失函数, 无需理想的融合图像进行监督就能有效融合源图像中的信息。 实验结果表明, 本文方法不受源图像分辨率比例关系的限制, 生成的融合图像能够较好地保留可见光的纹理并能突出红外目标, 并且图像信息丰富、 边缘清晰, 模型泛化能力较强, 实现了传感器互补的效果。 但是本文算法在红外图像分辨率与可见光图像相差倍数过多超出训练分布尺度时性能有限, 在高倍数下的融合效果仍需要研究, 通过改进网络结构、 训练方法后算法仍有提升空间。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|