


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱技术的蛋白粉掺假检测研究
[李斌 , 殷海, 张烽, 崔惠桢, 欧阳爱国
, 殷海, 张烽, 崔惠桢, 欧阳爱国* ]
, 殷海, 张烽, 崔惠桢, 欧阳爱国]
|
|


作者简介: 李斌, 1989年生,华东交通大学智能机电创新研究院讲师 e-mail: libingioe@126.com
蛋白粉是健身者必备的营养补剂, 市场需求在不断增加, 一些不法商家为了谋取利益, 在蛋白粉中加入廉价的粉末售卖。 传统的蛋白粉掺杂的检测方法费时、 费力, 操作复杂, 且成本昂贵。 高光谱技术具有易于操作、 在不损害实验样本的情况下可快速检测等优点, 因此, 提出使用高光谱技术以实现蛋白粉掺假检测。 在蛋白粉中分别加入质量百分数5%~60%, 浓度间隔5%的三类掺假物(玉米粉、 大米粉和小麦粉), 并采集所有样本的光谱信息。 在对蛋白粉中的玉米粉、 大米粉和小麦粉三类掺假物进行定性判别时, 首先分别采用卷积平滑(SG)、 标准化(Normalize)、 多元散射校正法(MSC)、 基线校正(Baseline)和标准正态变换(SNV)的预处理方法对光谱数据进行处理, 然后建立基于主成分回归(PCR)、 反向传播神经网络(BPNN)和随机森林(RF)的模型, 其中基于全波段光谱MSC预处理方法下建立的RF模型最优, 其整体准确率达到了100%, 其对应的RP和RMSEP分别为0.997 9和0.018 9。 在对蛋白粉中不同掺假物浓度进行定量分析时, 对三类掺假样本的光谱分别进行SG, Normalize, MSC, Baseline和SNV的预处理, 并建立LSSVM模型; 比较不同预处理方法下的各模型之间的性能, 在蛋白粉中掺玉米粉、 大米粉和小麦粉的LSSVM预测模型最佳预处理方法分别是无、 Baseline和Normalize, 然后, 采用连续投影算法(SPA)和竞争性自适应重加权算法(CARS)对其筛选, 并建立LSSVM模型, 三类掺假样本的SPA-LSSVM模型对应的RP为0.989 0, 0.986 0和0.997 9, CARS-LSSVM模型对应的RP为0.991 0, 0.994 6和0.999 1, 故三类掺假样本的CARS-LSSVM模型预测效果更佳。 研究表明: 高光谱技术可以实现对蛋白粉掺假的定性、 定量的检测, 并且操作简单、 检测快速和无损。
Protein powder is an essential nutritional supplement for bodybuilders, and the market demand is increasing. Some unscrupulous businessmen are adding cheap powder to protein powder for sale to profit. The traditional protein powder adulteration detection method is time-consuming, laborious, complicated and expensive. Hyperspectral technology has the advantages of easy operation and rapid detection without damaging the experimental sample. Therefore, this paper proposes the use of hyperspectral technology to achieve protein powder adulteration detection. In the experiments, three types of adulterants (corn flour, rice flour and wheat flour) with 5%~60% mass percentages and 5% concentration interval were added to the protein powder, and the spectral information of all samples was collected. In the qualitative discrimination of the three types of adulterants (corn flour, rice flour and wheat flour) in the protein powder, the spectral data were firstly processed using the pre-processing methods of convolutional smoothing (SG), normalization (Normalize), multiple scattering correction (MSC), baseline correction (Baseline) and standard normal transformation (SNV), and then the spectral data were established based on principal component regression ( PCR), backpropagation neural network (BPNN), and random forest (RF) models, among which the RF model built under the MSC preprocessing method based on full-band spectra is the best, and its overall accuracy reaches 100%. Its correspondingRP and RMSEP are 0.997 9 and 0.018 9, respectively. In the quantitative analysis of different adulterant concentrations in protein powder, the spectra of the three types of adulterated samples were pretreated with SG, Normalize, MSC, Baseline and SNV, respectively, and LSSVM models were established. The performance between the models under different pretreatment methods was compared. The best LSSVM prediction models were used for corn flour, rice flour and wheat flour adulterated in protein powder preprocessing methods were None, Baseline and Normalize, and then, the continuous projection algorithm (SPA) and competitive adaptive reweighting algorithm (CARS) were used to screen them and build LSSVM models. The RP corresponding to the SPA-LSSVM models for the three types of adulterated samples were 0.989 0, 0.986 0 and 0.997 9, and theRP of the CARS- LSSVM model corresponds toRP of 0.991 0, 0.994 6 and 0.999 1, so the CARS-LSSVM model for the three types of adulterated samples has a better prediction. Research shows that hyperspectral technology can achieve qualitative and quantitative detection of protein powder adulteration and simple operation, rapid and non-destructive detection.
在经济利益的驱使下, 食品掺假屡见不鲜, 并已成为全球性的挑战。 从简单加工到复杂制作, 都有可能出现食品掺假。 食品掺假会产生一系列的问题, 例如降低食品营养成分、 食物中毒或引起过敏, 从而会影响消费者的健康, 甚至会对消费者产生致命的后果。 蛋白粉是最基本的营养补剂, 也是健身的必备物品, 对于每个健身者来说都不可或缺。 蛋白粉不仅能在健身后提供必要的蛋白质, 而且所提供的能量能让肌肉加速恢复和增长。 目前, 蛋白粉的市场需求量在不断增加, 但是, 有些蛋白粉生产商家为了降低生产成本, 会以颜色相近且价格低廉的其他粉末作为掺假物质添加到蛋白粉中。 这样不仅会大大损害消费者的权益, 而且对正规生产商家蛋白粉的生产和销售产生威胁。
目前, 蛋白粉掺假检测大多采用化学方法检测, 这些方法既有长处也存在短处[1]。 例如, 免疫分析法是利用毒物与标记毒物竞争性结合抗体检测毒物的方法, 虽然成本较低, 但是不耐高温, 无法在高温环境中进行检测[2]; 生物传感器法具有检测速度快、 成本低等优点, 但在生物响应方面, 需进一步加强其稳定性[3]; 气相色谱法检测灵敏度极高, 但是对固体样品、 部分无机样品不适用[4]; 液相色谱法具有常温操作, 不受样品挥发度和热稳定性的限制等优点, 但是检测仪器昂贵[5]。 虽然这些方法检测精度高, 但是是有损检测[6, 7]。 目前亟需探索一种易于操作, 并且在不损害实验样本的情况下实现快速检测的蛋白粉掺假检测方法。
高光谱技术具有操作简单, 且能够快速、 无损检测等优点, 被广泛应用于食品掺假方面的检测, 如Ropodi等利用高光谱技术检测将不同比例的猪肉掺入牛肉中并进行有效区分[8]。 Wu等采用高光谱技术研究了在虾中进行明胶掺假, 并验证了其检测的可靠性与准确性[9]。 Shun等基于高光谱图像的特征光谱信息有效判别出了东北长粒香大米掺入了不同比例的江苏溧水大米[10]。 Shun等利用高光谱技术对牛肉丸中掺入猪肉和鸡肉进行检测, 然后采用不同的预处理方法处理光谱数据, 并联用四种筛选波长的方法后建立PLS模型, 表明了高光谱技术可以实现牛肉丸中掺假含量的预测[11]。
上述研究表明了高光谱技术在检测食品掺假上具有可行性, 然而在多种已有的对蛋白粉掺假的检测方法中, 高光谱技术未被提及。 本研究采用高光谱技术对蛋白粉掺假进行定性、 定量检测, 以期能为蛋白粉安全品质监控提供一定的帮助。
实验所用的蛋白粉和掺假物(玉米粉、 大米粉和小麦粉)均从大型超市购买, 总共制备了四类样品, 分别是: 第一类是纯蛋白粉样品, 第二类是蛋白粉掺了玉米粉的样品, 第三类是蛋白粉掺了大米粉的样品和第四类是蛋白粉掺了小麦粉的样品。 掺假样品一共配置288个样品, 质量百分数5%~60%, 浓度间隔5%, 其浓度和样本数量的详细信息如表1所示, 以及纯蛋白粉样品96个, 故共制备了384个样品。 采用配有50 mL聚丙烯离心管的旋涡混合器对每个实验样本进行混合处理; 为了使得每种掺假样品能够在蛋白粉中均匀分布, 机器工作时间设定为1 min。 然后, 用液压机在10 MPa的压力下压1 min, 制备样品压片, 压片的形状为圆饼形, 直径为13 mm, 厚度为0.8~1.1 mm。 将这样制备好的样品放在贴有标签的袋子里, 并将其密封。
| 表1 三类掺假样品的质量百分数及样本数量 Table 1 Mass percentages and the number of three types of adulterated samples |
1.2.1 高光谱成像系统
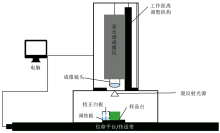
实验数据采集用盖亚(GaiaSorter)高光谱分选仪, 其组成结构示意图如图1所示。 系统硬件的组成主要包括成像光谱仪、 四盏卤素灯(20 W)、 位移平台和步进电机。 软件主要采用SpectralView。
 | 图1 高光谱成像系统Fig.1 Hyperspectral imaging system |
1.2.2 高光谱成像数据采集与标定
在图像采集之前, 为了减少基线漂移, 需要打开系统预热30 min。 设置的参数如表2所示。 操作步骤: (1) 将压成圆饼状的样品放在位移平台上; (2) 打开位移平台, 并点击保存按钮采集高光谱数据; (3) 利用计算机软件记录数据, 最终形成一个包含了影像信息和光谱信息的三维数据立方体。
| 表2 高光谱系统具体参数设置 Table 2 Specific parameter settings of hyperspectral system |
由于摄像头中存在暗电流, 会对实验数据产生影响, 为了减少这种影响, 需要对采集到的原始图像进行黑白版校正[12]。 校正公式如式(1)所示。
式(1)中, R, R0, B和W分别为校正后的图像、 原始图像、 黑色参考和白色参考。
1.3.1 光谱数据提取
感兴趣区域(ROI)面积为100像素× 100像素, 是采用ENVI4.5软件提取的, 该区域内的光谱反射率的平均值为样本的光谱数据。 利用高光谱成像系统采集到的信息不能够直接应用于建模, 因为其包含了一些对于实验分析造成影响的信息和噪声。 在建立模型之前, 为减少噪声等对实验结果产生不好的影响[13], 采用卷积平滑(SG)、 标准化(Normalize)、 多元散射校正法(MSC)、 基线校正(Baseline)和标准正态变换(SNV)对数据进行处理[14], 然后, 建立不同预处理方法处理后的模型, 对比模型性能, 为后续的数据处理选出最佳的预处理方法。
1.3.2 特征波长的选取
全波段光谱数据量非常庞大, 可能会包含一些无关信息和重复信息, 这些无用信息不仅会降低模型的运算速度, 甚至会降低模型的准确性。 因此, 进行特征提取以简化模型、 提升模型效率非常必要。 筛选特征波长的方法多种多样, 如竞争性自适应重加权算法(CARS)、 连续投影算法(SPA)等[15]。 在不同掺假物浓度的定量分析中采用了SPA和CARS算法, 然后分别建立最小二乘支持向量机(LSSVM)模型。
2.1.1 所有样品的光谱特征
从图2(a)中可知, 掺入玉米粉、 大米粉和小麦粉的样品光谱曲线趋势有很大的共同性, 并且大部分样品的光谱相重叠, 通过肉眼根本无法区分出样品掺入了何种掺假物, 但是从图2(b)中可以看出, 蛋白粉中掺入20%质量分数的掺假物, 光谱曲线还是存在明显的区别, 所以在样本数量较大时, 需要通过对数据进行处理, 以提高检测不同掺假物的建模精度。
 | 图2 蛋白粉中掺假不同物质的光谱曲线 (a): 所有样品原始光谱曲线; (b): 20%质量分数掺假光谱曲线Fig.2 Spectral curves of protein powders adulterated with different substances (a): Original spectra of all samples; (b): Spectra of protein powders adulterated by 20% other powders |
2.1.2 光谱数据处理
运用Kennard-stone(KS)算法, 将384个样本按照3:1的比例的分成训练集和预测集, 即训练集有288个样本数据, 预测集有96个样本数据。 光谱曲线中既包含有用信息, 也包含一些噪声等无用信息, 为了减少无用信息对后续建模精度产生影响, 需要对光谱数据进行预处理。 本研究采用的算法包括SG, Normalize, MSC, Baseline和SNV。
为了找出性能较优的预测模型, 将各种预处理后的全波段光谱建立三种预测模型, 分别是主成分回归(PCR)模型、 反向传播神经网络(BPNN)模型和随机森林(RF)模型, 然后比较它们在各小类上的准确率以及整体的准确率, 最后得出一个能够预测不同掺假物的最优判别模型。
2.1.3 全波段模型效果评价
从表3中可知: 基于原始全波段光谱建立的PCR, BPNN和RF模型整体准确性都没有达到100%。 全波段光谱经过各种预处理方法处理后, 建立主成分回归(PCR)模型, 除预处理Baseline建立的模型外, 其他模型相比于原始光谱建立的模型, 精度都得到了一定的提高, 精度提高最大的预处理算法是MSC, 模型总共判断错误8例, 分别是掺假物为玉米粉4例和掺假物为小麦粉4例, 整体准确性为97.9%, 模型的判别效果较优。 经过各种预处理方法后的全波段光谱建立的BPNN模型, 虽然在小类的准确率达到了100%, 但在整体准确率上却没有超过70.0%, 其模型的判别效果较差。 相比于以上两种模型, RF模型整体准确率都达到了94.0%以上, 甚至在MSC预处理方法下建立的模型, 其整体准确率达到了100%, 其对应的RP和RMSEP分别为0.997 9和0.018 9。 故对于预测蛋白粉中不同掺假物的最优判别模型是MSC-RF模型。
| 表3 基于原始及预处理全波段光谱的三种模型下准确率对比 Table 3 Comparison of accuracy rates of the three models based on the original and preprocessed full-band spectra |
2.2.1 不同掺假浓度的平均光谱特征
图3中的三幅图分别为掺有不同掺假物的蛋白粉样本平均光谱曲线, 从图中可知, 蛋白粉中掺假物含量不同的样本, 虽光谱曲线趋势较为接近, 但其反射率却存在一定的差别。 纵观三幅图可知, 只要蛋白粉中掺入了一定的掺假物, 其反射率必会下降。 但是掺假量按照一定梯度增加, 反射率却没有表现出相应的规律, 即反射率没有一直随着掺假量的增加而增加或降低。 因此, 需要对数据进一步处理来提高检测不同掺假浓度的建模精度。
 | 图3 三类掺假样本的各浓度平均光谱曲线 (a), (b)和(c)分别代表掺有玉米粉、 大米粉和小麦粉的蛋白粉样本平均光谱曲线Fig.3 The average spectra of three types of adulterated samples with different blend rations (a), (b), (c) represent the average spectral curves of protein powder samples mixed with corn flour, rice flour and wheat flour, respectively |
2.2.2 光谱数据处理
为了定量分析蛋白粉中掺假物的含量, 运用Kennard-stone(KS)算法, 将每类的104条蛋白粉掺假光谱按照3:1的比例分成训练集和预测集, 即训练集有78个样本数据, 预测集有26个样本数据。 然后, 分别基于原始光谱和SG, Normalize, MSC, Baseline和SNV建立了LSSVM(RBF_kernel)模型。 比较模型的预测结果, 选出最好的光谱预处理。
2.2.3 全波段LSSVM(RBF_kernel)模型效果评价
表4是采用原始全波段光谱以及各种预处理方法处理过的数据作为LSSVM(RBF_kernel)模型输入值后的结果。 比较表中的结果可知, 基于原始全波段光谱建立的掺假物为玉米粉的模型精度最高, RMSEP为0.017 8, RP为0.996 1, 其对应的γ =4 464 077.790 8, σ 2=921.039 0; 掺假物为大米粉的模型精度最高的预处理方法是Baseline, RMSEP为0.018 4, RP为0.996 1, 其对应的γ =54 097.003 8, σ 2=2 042.103 4; 掺假物为小麦粉的模型精度最高的预处理方法是Normalize, RMSEP为0.013 8, RP为0.997 8, 其对应的γ =149 529.038 6, σ 2=802.730 2。
| 表4 基于原始及预处理全波段光谱的LSSVM(RBF_kernel)模型预测结果 Table 4 The prediction results of the LSSVM (RBF_kernel) models based on the original and preprocessed full-band spectra |
2.2.4 特征波长的选择
为了简化模型和提高模型的检测速度, 需要从全波段光谱中挑选出具有代表性的特征波长, 因此选用SPA和CARS两种方法去筛选, 然后分别使用筛选出的特征波长建立模型。
使用SPA方法分别对三类掺假样本的光谱进行波段筛选, 特征波长的数量范围将其设置为1~40, 最后SPA筛选出三类掺假样本的特征波长数量为12, 10和13。 使用CARS方法筛选时, 将采样次数设置为100次, 最终筛选出三类掺假样本的特征波长变量分别为33, 41和47, 两种方法筛选出的波长如表5所示。
| 表5 两种波段筛选方法下筛选的结果 Table 5 Screening results of two band screening methods |
2.2.5 特征波长LSSVM(RBF_kernel)的结果
利用SPA和CARS这两种方法获取三类掺假物样本光谱的特征波长, 然后分别建立SPA-LSSVM和CARS-LSSVM简化模型, 结果如表6所示。 可以看出, 三类掺假样本的SPA-LSSVM模型对应的RP为0.989 0, 0.986 0和0.997 9, CARS-LSSVM模型对应的RP为0.991 0, 0.994 6和0.999 1。 而从表4中可知掺假物为玉米粉、 大米粉和小麦粉的样本对应最佳的LSSVM模型的RP分别为0.996 1, 0.996 1和0.997 8。 综上所述, 基于全波段光谱建立的模型与基于特征波长建立的模型, 其性能相差无几, 掺假物为小麦粉的样本基于特征波长建立的CARS-LSSVM模型性能要优于基于全波段光谱建立的LSSVM模型。 并且由于特征波长筛选会大大降低波长的数量, 使得模型的运算时间会大幅度缩减, 效率更高, 所以总体上会更适合在线检测的要求。 同时, 从RP和RMSEP方面对比两种波长筛选方法建模后的预测效果, 从表6中可知, 三类掺假样本的CARS-LSSVM模型的RP均高于三类掺假样本的SPA-LSSVM模型, RMSEP均低于三类掺假样本的SPA-LSSVM模型, 所以蛋白粉中掺玉米粉、 大米粉和小麦粉的LSSVM 预测模型所对应的最佳特征波长筛选方法均为CARS。 图4(a), (b)和(c)分别是CARS-LSSVM蛋白粉掺玉米粉、 大米粉和小麦粉含量预测模型的散点图。
| 表6 基于不同特征波长筛选方法的蛋白粉中掺假物含量的LSSVM(RBF_kernel)模型预测结果 Table 6 Prediction results of adulterant content in protein powder using LSSVM (RBF_kernel) models based on different characteristic wavelength screening methods |
 | 图4 CARS-LSSVM三类掺假样本的预测模型散点图 (a), (b), (c)分别代表蛋白粉掺玉米粉、 大米粉和小麦粉的预测模型散点图Fig.4 Scatter plots of prediction models of three types of adulterated samples by using CARS-LSSVM (a), (b), (c) are the scatter plots of prediction models for the protein powder mixed with corn flour, rice flour and wheat flour, represent |
通过高光谱技术对蛋白粉中的玉米粉、 大米粉和小麦粉三类掺假物进行了定性、 定量检测分析。 首先, 对样本的光谱数据进行预处理, 预处理方法包括SG, Normalize, MSC, Baseline和SNV, 然后, 将原始和预处理后的光谱分别建立PCR, BPNN和RF模型, 比较模型之间的正确率, 得出全波段光谱在MSC预处理方法下建立的RF模型最优, 其整体准确率达到了100%。 再对蛋白粉中不同掺假物浓度进行定量分析。 首先, 利用原始全波段光谱和预处理后的全波段光谱建立LSSVM预测模型, 比较模型性能, 得出蛋白粉中掺玉米粉、 大米粉和小麦粉的LSSVM预测模型最佳预处理方法分别是无、 Baseline和Normalize, 然后, 在SPA和CARS这两种特征波长筛选方法中, 蛋白粉中掺玉米粉、 大米粉和小麦粉的LSSVM预测模型所对应的最佳特征波长筛选方法均为CARS, 筛选出的特征波长的数量分别为26, 41和47, 与之对应的RP和RMSEP分别为0.991 0和0.025 3, 0.994 6和0.022 7, 0.999 1和0.008 8。 研究表明, 高光谱技术可快速、 准确、 无损对蛋白粉掺假进行定性、 定量检测, 为进一步运用高光谱技术开展蛋白粉安全品质快速检测提供理论和实验参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|