
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于光谱-空间特征的黄茶多酚含量估算模型
[杨宝华1  , 高远
, 高远1 , 王梦玄1 , 齐麟1 , 宁井铭2 ]
, 高远|
|


作者简介: 杨宝华, 女, 1974年生, 安徽农业大学信息与计算机学院副教授 e-mail: ybh@ahau.edu.cn
茶多酚是黄茶中的重要成分之一, 具有保健和药用功效。 准确估测茶多酚含量对茶叶品质鉴定和定量分析具有重要的意义。 学者们已经利用电子鼻、 电子舌、 高光谱和近红外技术开展了茶多酚的估测研究, 取得了良好的效果。 然而, 由于缺乏空间特征, 难以满足黄茶内外品质综合判断的要求。 随着高光谱成像系统的发展, 尽管基于灰度共生矩阵的茶叶成分估测已经被证实取得较好的效果, 但在实际应用中仍然存在一些障碍。 一方面, 分辨率较低时, 图像的纹理特征不会有显著差异, 并且少数特征无法充分地解译高光谱图像, 从而导致模型估测效果较差。 另一方面, 分辨率较高时, 特征的增加会导致模型更复杂。 因此, 在保留高光谱图像原始信息的前提下, 有必要进一步挖掘高光谱图像的潜在特征, 尤其是纹理的细节部分。 因此, 提出了一种融合光谱和空间特征的模型来提高茶多酚估测的准确性。 首先, 利用连续小波变换提取光谱信息的小波系数; 其次, 根据不同尺度的小波系数能量优选小波系数特征, 分别是第4尺度的959和1 561 nm, 第5尺度的1 321, 1 520和1 540 nm, 以及第6尺度的1 202和1 228 nm; 再者, 基于小波系数能量之和优选2个特征波长, 分别是1 102和1 309 nm; 然后, 根据特征波长对应的高光谱图像分别提取灰度共生矩阵和小波纹理。 最后, 分别利用小波系数特征、 灰度共生矩阵、 小波纹理和他们的组合构建黄茶多酚含量的估测模型。 通过对五种黄茶的分析和验证, 比较基于不同特征的不同模型估测效果, 包括偏最小二乘回归、 支持向量回归和随机森林方法。 结果表明, 融合小波系数特征, 共生矩阵和小波纹理的支持向量回归模型效果最佳, 校正集的 R2为0.933 0, 验证集的 R2为0.823 8。 因此, 所提出的模型能有效的提高茶多酚含量的预测精度, 为预测茶叶的其他成分提供了技术基础。
Tea polyphenols (TP) is one of the important ingredients of yellow tea, which has health and medicinal effects. Moreover, accurate estimation of tea polyphenol content is of great significance for tea quality identification and quantitative analysis. Previous scholars have used E-nose, E-tongue, hyperspectral and near-infrared techniques to conduct research on the estimation of tea polyphenols, and they have achieved good results. However, due to the lack of spatial characteristics, it is difficult to meet the accuracy requirements for the comprehensive judgment of the internal and external quality of tea. With the development of hyperspectral imaging system (HIS), although the estimation of tea texture based on the gray level co-occurrence matrix (GLCM) has made progress, there are still some obstacles in practical application. On the one hand, if the resolution is low, there will be no significant difference in the texture features of the image, and fewer features will not be able to fully interpret the image, resulting in lower model accuracy. On the other hand, if the resolution is high, the increase of features will make the model more complicated. Therefore, on the premise of retaining the original information of the hyperspectral image, it is necessary to explore further the potential features of hyperspectral images, especially the details of the texture. Consequently, a method of combining spectral and spatial features is proposed to improve the accuracy of tea polyphenol estimation. First, the wavelet coefficients are extracted using continuous wavelet transform based on the spectral information obtained from the hyperspectral image. Second, the wavelet coefficient features are extracted based on the wavelet coefficients, including 959 and 1 561 nm at the 4th scale, 1 321, 1 520 and 1 540 nm at the 5th scale, and 1 202 and 1 228 nm at the 6th scale. Furthermore, two characteristic wavelengths are preferred based on the sum of the energy of wavelet coefficients, which are 1 102 and 1 309 nm, respectively. Then, the gray level co-occurrence matrix and wavelet texture are extracted according to the hyperspectral image corresponding to the characteristic wavelength. Finally, the wavelet coefficient features, co-occurrence matrix, wavelet texture, and their combinations were used to construct an estimation model for the content of polyphenols in yellow tea. By comparing different regression methods based on different characteristics, including partial least squares regression (PLSR), support vector regression (SVR), and random forest (RF), five types of yellow tea were analyzed and verified. The experimental results show that SVR model based on the fusion of wavelet coefficient features, co-occurrence matrix texture, and wavelet texture achieves the best results with R2 of 0.933 0 for calibration set and 0.823 8 for the validation set. Therefore, the proposed model can effectively improve the prediction accuracy of tea polyphenol content, which also provide a technical basis for predicting other components of tea.
黄茶是一种微发酵茶叶, 因其独特的风味和品质而受到消费者的喜爱。 有研究表明香气是影响茶叶风味和品质的重要因子[1], 茶多酚(tea polyphenols, TP)又是决定茶叶香气的主要成分。 因此, 检测茶多酚含量是评价黄茶品质的关键。 然而, 传统检测茶多酚含量大部分通过化学方法, 由于实验繁琐导致茶叶的功能难以深入挖掘, 因此快速、 准确估测茶多酚含量, 对黄茶品质鉴定和定量分析具有重要意义。
目前, 随着光谱仪器和数据处理技术的发展, 利用光谱检测茶叶中茶多酚含量的相关研究较为广泛。 Ren等对不同产地的红茶进行识别, 结果表明近红外光谱可以快速确定红茶的茶多酚含量[2]。 Dutta等对印度茶进行分析, 结果表明光谱可以准确估测茶多酚含量[3]。 Hazarika等对新鲜茶叶进行检测, 结果表明近红外反射(NIR)光谱可以快速估算新鲜茶叶中的茶多酚含量[4]。 然而, 由于近红外光谱缺乏空间信息, 从而限制了茶多酚的深入研究。
高光谱成像技术因具有同时获取被测物的空间信息和光谱信息的优势, 已经成功被用于检测茶叶的主要成分。 Tu根据茶叶的高光谱图像分析光谱特征, 预测茶多酚含量[5]。 Yang利用高光谱成像系统预测黄茶的氨基酸成分[6]。 Sohara利用高光谱图像估测绿茶中儿茶素浓度[7]。 尽管高光谱图像已经成功用于估测茶叶成分, 由于缺乏有效的空间信息和光谱信息导致估测模型的精确度不高。 蔡庆空等提出基于光谱信息和空间信息的模型用于茶叶分类[8], 证明了融合特征的有效性。 因此, 有必要融合空间-光谱特征, 提高茶多酚含量的检测能力。
小波变换由于具有多分辨率分析的优势而被广泛应用, 在高光谱特征提取中, 小波变换不仅表示多尺度多分辨率的轮廓信息, 而且能够提取更多的细节特征信息, Li等结合小波变换和灰度共生矩阵(gray level co-occurrence matrix, GLCM)从多光谱图像中提取特征并估计茶叶色素, 取得了良好的效果[9]。 但是, 很少有关于黄茶高光谱图像的小波变换的相关研究报道。 因此, 本研究利用小波变换提出一种融合光谱和空间特征的茶多酚含量估测模型, 克服光谱特征的易饱和性, 为黄茶的品质检测提供技术支持。
从当地市场购买五种来自不同产地的黄茶作为实验材料, 包括平阳黄汤(浙江省平阳县产)、 莫干黄芽(浙江省德清县产)、 霍山黄芽(安徽省霍山县产)、 蒙顶黄芽(四川省蒙顶山产)、 君山银针(湖南岳阳产), 这五种茶是中国著名的黄茶, 用锡箔袋包装成50 g· 袋-1, 避光低温贮藏。
试验用的高光谱图像采集系统包括光谱成像仪(Imspector V17E, Spectral Imaging Ltd., Oulu, Finland)、 CCD相机(IPX-2M30, ImperxInc., Boca Raton, FL, USA), 2个150 W的卤素灯(3900, Illumination Technologies Inc., New York, USA), 数据采集暗箱, 反射式线性光道管和电控位移平台(MTS120, 北京光学仪器厂, 中国)以及图像采集和分析软件(Spectral Image Software, Isuzu Optics Corp., Taiwan, China)组成。 反射光源的四个4个卤钨灯均匀分布在暗箱内的环形支架上, 光源照射方向与竖直方向呈45° 。
1.2.1 数据采集
实验在暗室中进行, 每个品种选取20个样本, 分别称取(20± 0.5) g黄茶样品均匀平铺在规格为ϕ 9 cm× 1 cm 黑色的培养皿中, 共得到100组大小为636× 814× 508的高光谱数据, 波长范围是908~1 735 nm。 曝光时间和物镜的高度为2 ms和28 cm, 移动平台的输送速度为8.0 mm· s-1。 其中光谱成像仪的光谱分辨率为5 nm。 为了消除暗电流的影响, 原始获得的高光谱图像进行校正。 选择高光谱图像中间50× 50像素范围为感兴趣区域(region of interest, ROI), 提取ROI所有像素的光谱值, 计算其平均值作为这个样本的光谱值。 茶多酚含量依据GB/T 31740.2— 2015标准进行测定。
1.2.2 空间特征获取
连续小波变换(continuous wavelet transform, CWT)是高光谱信息中弱特征提取的重要技术手段, 它可以将光谱信号分解成不同频率的子信号, 有效利用光谱信息的整体结构特征, 提取光谱信号中隐藏的弱信息。 用高光谱系统扫描五种黄茶, 获取100个样品的高光谱图像, 从感兴趣的区域提取黄茶的反射率, 并利用连续小波变换将其变换到不同尺度下的小波系数。 同时, 利用小波系数能量之和筛选敏感波长。
设Xi为CWT处理光谱后的小波系数, i代表不同的尺度因子(i=21, 22, 23, …), 则小波系数能量为各尺度下小波系数的平方, 设Ei为小波系数能量, S代表小波系数能量之和[10]。
小波变换对图像进行不同尺度的分解, 从而获得不同层次的轮廓信息和细节信息。 通常, 一幅图像经过一次小波变换后产生3个高频子带图像, 包括HL、 LH和HH, 分别表示水平高频分量、 垂直高频分量和对角线高频分量, 反映图像信号水平方向、 垂直方向与对角线方向边缘、 轮廓和纹理。 按照式(3)— 式(7), 利用小波系数计算的统计值作为小波纹理特征, 包括能量(energy)和熵(entropy)。
其中, ∧ =
灰度共生矩阵是一种有效的纹理分析的统计技术, 本研究通过二阶概率统计滤波的方式提取特征波长对应的高光谱图像的纹理特征[11], 包括平均值(mean)、 方差(variance)、 协同性(homogeneity)、 对比度(contrast)、 相异性(dissimilarity)、 熵(entropy)、 角二阶矩(angular second moment)和相关性(correlation)。
1.2.3 回归算法
偏最小二乘回归(partial least squares regression, PLSR)已成为非常流行的预测方法[12], PLSR结合了主成分分析和多元回归的功能, 通过大量原始描述到少量潜在变量的线性过渡, 从而提供了可预测性方面的最佳线性模型。 支持向量回归(support vector regression, SVR)的原理[13]是将原本复杂的低维非线性回归问题利用映射关系转化为高维空间的线性回归。 随机森林(random forest, RF)是一种回归树技术, 通过集成学习的思想将多棵树集成的一种算法, 它使用引导程序聚合和预测变量的随机化来实现高度的预测准确性[14]。
1.2.4 模型评价
为了使建立的模型具有普适性, 在试验中将数据按照7:3划分为校正集和验证集。 使用决定系数(coefficient of determination, R2)和均方根误差(root mean squared error, RMSE)作为模型精度的评价指标[6]。 所有利用回归技术构建模型、 验证和评估均使用基于Windows 10的MATLAB R2017b(The MathWorks Inc., Natick, MA, USA)进行。
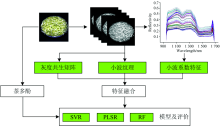
利用小波变换技术提高黄茶的茶多酚估测效果, 具体数据处理流程如图1所示。 通过对黄茶高光谱图像的多尺度小波系数特征的分析, 进一步提取光谱特征和空间特征, 包括小波系数特征、 灰度共生矩阵和小波纹理, 基于融合的光谱-空间特征构建黄茶多酚含量的偏最小二乘回归(PLSR)、 支持向量回归(SVR)和随机森林(RF)估测模型。
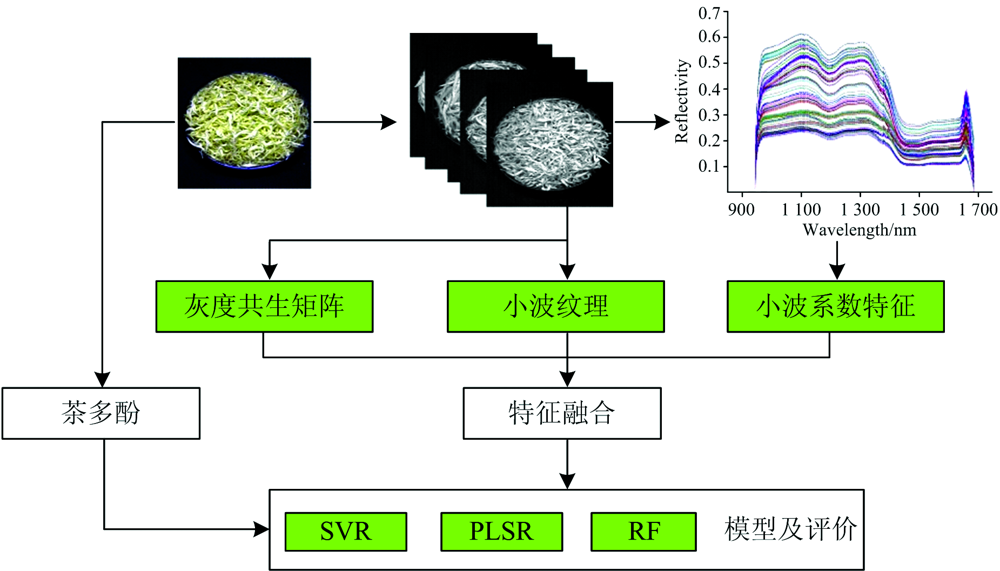 | 图1 数据处理流程Fig.1 Data processing flow |
2.2.1 光谱数据获取
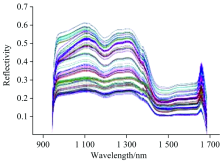
图2所示为不同样本的光谱曲线, 由图2看出不同品种的黄茶反映的光谱曲线趋势是一致的, 大部分反射率都在0.2~0.6之间。 另外, 在波长1 102和1 139 nm处反射率有较大幅度的增大; 在波长1 450~1 650 nm处各品种样本的反射率相对平稳。 由于外界条件的影响, 如光线强弱、 氧气浓度和仪器的误差等, 光谱曲线首尾两端比较杂乱。 因此, 为了提高模型的稳定性和精准性, 删除光谱数据中908~943和1 689~1 735 nm 的波段, 保留943~1 689 nm作为后续分析。
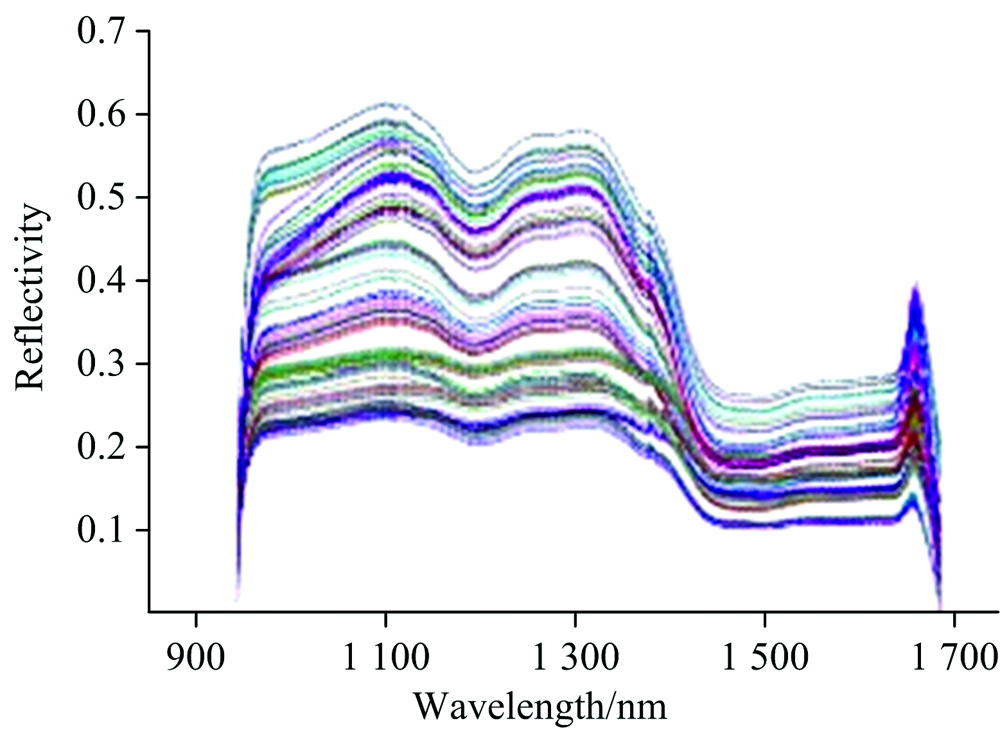 | 图2 黄茶样本的光谱响应曲线Fig.2 Spectra of yellow tea sample |
2.2.2 小波系数特征提取
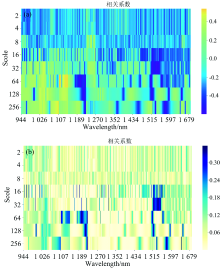
为了揭示所收集的光谱与黄茶茶多酚含量的相关性, 利用连续小波变换分析每个尺度光谱信息的潜在预测能力, 选取Daubechies函数作为小波基函数, 对黄茶样本的高光谱反射率进行小波分解, 分解的尺度根据经验值预先设置为8个尺度, 分别为21, 22, 23, 24, 25, 26, 27和28。 将变换后的8个尺度的小波系数与茶多酚含量进行相关性分析, 相关系数的热力图如图3所示, 各尺度小波系数与黄茶茶多酚含量的相关系数具有较大的差异, 总体变化趋势是先增加后减小, 尤其是, 第6尺度的相关系数热力图表明整体相关性达到最大。 分解尺度在7~8之间时, 相关系数呈下降趋势。 因此, 不同尺度的小波系数反映光谱信息的不同特征, 低尺度系数反映小波变换可以平滑噪声, 高尺度系数反映原始光谱的特定基团的吸收特征和茶叶的空间结构变化。
 | 图3 不同尺度的相关系数图 (a): 小波系数与茶多酚的相关分析; (b): 小波系数能量与茶多酚的相关分析Fig.3 Correlation coefficients of different scales (a): Correlation analysis between wavelet coefficient and tea polyphenols; (b): Correlation analysis between wavelet coefficient energy and tea polyphenols |
为了突出小波系数特征, 将小波系数能量与茶多酚进行相关分析, 结果如图3(b)所示, 相关性较高的波段集中在第4尺度的959和1 561 nm, 第5尺度的1 321, 1 520和1 540 nm, 以及第6尺度的1 202和1 228 nm, 一共7个小波系数特征。
2.3.1 敏感波长优选
由于小波变换后的能量仍然与原始光谱信号的能量保持一致, 通过式(2)计算不同品种茶叶样本不同尺度的小波系数能量之和, 再取平均值作为该品种黄茶的小波能量特征, 发现不同品种的黄茶对应的小波系数能量之和在947~1 696 nm范围内变化规律一致, 其小波系数能量之和按照从大到小依次为平阳黄汤、 莫干黄芽、 霍山黄芽、 蒙顶和君山银针。 实际上, 光谱反射率会随着物质含量的变化而变化, 并且茶多酚的光谱吸收特性主要由分子中的O— H和C— H等基本化学键的倍频和合频引起的[15]。 在1 006~1 102 nm附近, 茶多酚中O— H键拉伸, 在二级倍频区附近强烈振动, 所以吸收能力逐渐增强。 另外, 由于CH2基团的影响, 茶多酚在1 309 nm附近反射能力开始增加, 因此, 选取1 102和1 309 nm作为茶多酚含量的敏感波长。
2.3.2 灰度共生矩提取
利用ENVI从1 102和1 309 nm的灰度图像, 分别提取灰度共生矩阵作为纹理特征。 利用灰度共生矩阵分别与茶多酚进行相关分析, 结果如图4(a)所示, 由图可知很多纹理特征之间的相关系数较高, 为了避免特征间的共线性, 针对16个灰度共生矩阵特征进行主成分分析, 结果如图4(b)所示, 当提取前三个主成分时KMO (Kaiser-Meyer-Olkin)检验统计量为0.674, 累计贡献率达到97.52%, 因此, 选取共生矩阵特征的前三个主成分作为新的特征向量。
 | 图4 灰度共生矩阵的提取及优选 (a): 不同尺度的小波系数与茶多酚的相关系数; (b): 灰度共生矩阵的主成分分析Fig.4 Extraction and optimization of gray level co-occurrence matrix (a): Correlation coefficients of wavelet coefficients and tea polyphenols at different scales; (b): Principal component analysis of gray co-occurrence matrix |
2.3.3 小波纹理特征提取
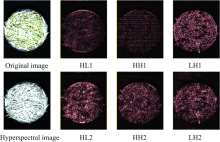
通过对特征波长的高光谱图像进行小波分解, 获取的结果作为黄茶样本的小波纹理特征。 针对1 102和1 309 nm对应的高光谱图像进行二层小波分解, 如图5所示, HL1, LH1和HH1分别表示小波分解的水平方向、 垂直方向和对角方向的第一层高频子图, HL2, LH2和HH2分别表示第二层高频子图。 特征高光谱图像的第一层小波子图表示轮廓纹理, 第二层表示细节纹理。 同一种茶叶对应的不同特征高光谱图, 它们的小波纹理是有区别的, 而且, 不同品种茶叶的小波纹理也不相同, 尤其第二层的高频子图的区别比较明显, 体现不同样本之间茶多酚含量的区别。 因此, 通过小波分解获得的多尺度信息表明黄茶光谱-空间的总体一致性和细节差异性。
 | 图5 高光谱图像的小波分解结果Fig.5 Wavelet decomposition results of hyperspectral images |
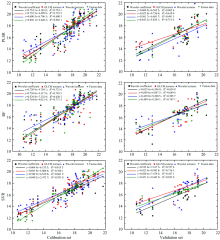
为了进一步评估小波变换对估测模型的影响, 将小波系数特征、 小波纹理、 优选的灰度共生矩阵及融合所有特征分别作为模型输入的变量, 模型的主要参数通过调试设置为最优参数, PLSR模型的主成分个数为5, SVR模型的核函数为RBF, 惩罚参数C为15, 随机森林的子树为1 000棵。 构建偏最小二乘法回归(PLSR)、 支持向量回归(SVR)和随机森林(RF)模型, 结果如图6所示, 从图6中发现基于不同特征的三种回归模型都取得良好的预测效果。 SVR模型比PLSR模型和RF模型的结果都有所改善, 其中, 基于小波系数的SVR模型分别提高7.5%和11.5%, 基于GLCM纹理的SVR模型分别提高3.2%和7.4%, 基于小波纹理的SVR模型分别提高9.2%和6.2%, 基于融合所有特征的SVR模型分别提高8.2%和17.3%。 可见, SVR的估测效果最好。 另外, 校正集模型是经过多次参数寻优的结果, 测试集模型的数据是随机的, 因此校正集模型的精度要高于验证集模型, 但二者的预测效果是一致的。
从图6中还可以看出, 同一个模型中基于不同特征的预测效果存在一定的差异, 尤其是, 基于融合特征比基于小波系数、 GLCM和小波纹理的估测效果更出色。 其中, 基于融合特征的PLSR模型提高11.9%, 14%和29.8%, 基于融合特征的SVR模型提高12.5%, 18.5%和29%, 基于融合特征的RF模型提高6.4%, 8.8%和19.6%。 因此, 融合小波系数特征、 小波纹理和灰度共生矩阵可以有效提高估测模型的精度。
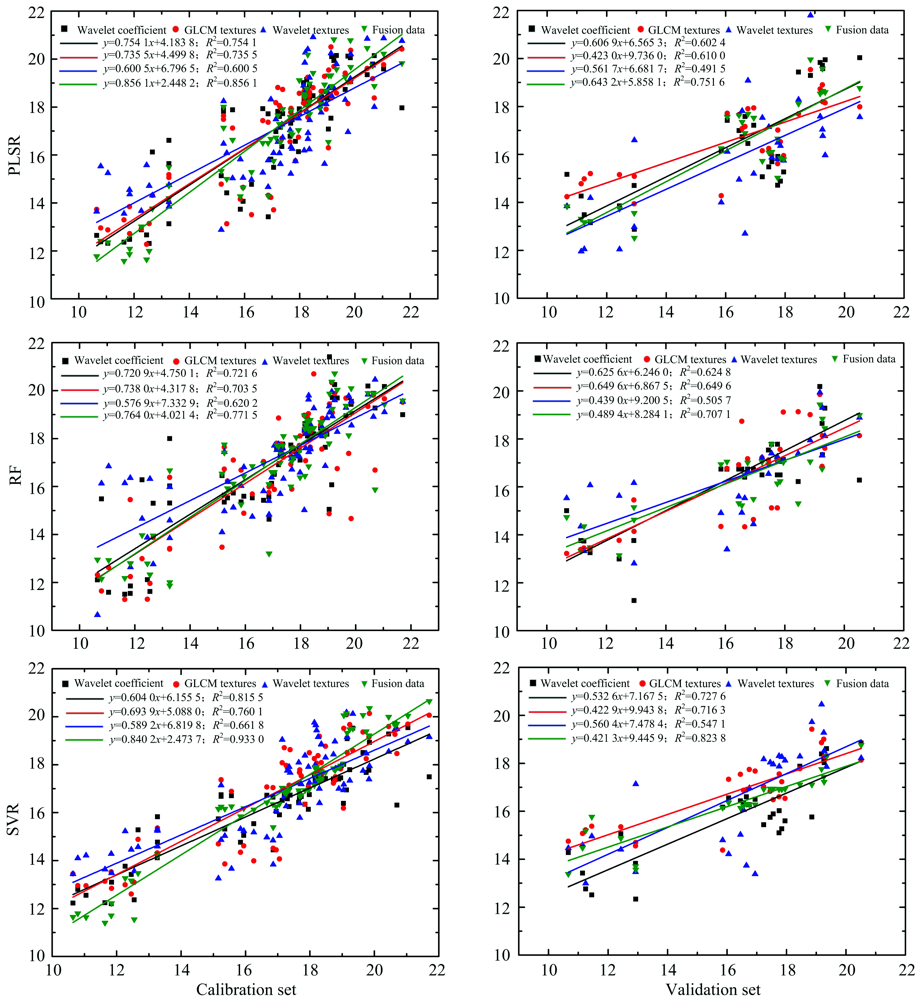 | 图6 不同模型的估测结果对比Fig.6 Comparison of estimation results of different models |
针对5个品种100个样本的黄茶近红外高光谱图像, 首先从感兴趣区域提取黄茶的反射光谱, 通过连续小波变换将其转化为不同尺度的小波系数。 然后, 从小波系数能量获得小波系数特征和特征波长, 分别从特征波长对应的高光谱图像中获得GLCM和小波纹理。 最后, 基于小波系数特征、 小波纹理、 优选的灰度共生矩阵及融合特征, 分别构建PLSR, SVR及RF的茶多酚预测模型。 主要结论如下:
(1)通过小波变换提取黄茶高光谱图像的小波系数特征和小波纹理, 说明小波变换具有提取和表达空间特征和光谱特征的能力。
(2)基于融合小波系数、 GLCM及小波纹理的模型比基于单一特征的模型精度高, 说明基于融合光谱-空间特征比单一的光谱特征或者空间特征的估测效果更有效。
(3)基于融合多特征的SVR模型估测效果在三种模型中表现最好, 决定系数达到0.933, 比PLSR和RF模型的精度提高8.2%和17.3%。
因此, 基于光谱-空间特征的估算模型。 可以快速、 准确地预测黄茶中茶多酚含量。 下一步研究将利用其他品种的茶叶进行模型验证, 提高模型的普适性, 为茶叶的无损检测提供参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|