
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱技术的小龙虾新鲜度快速检测研究
[王超1  , 刘言
, 刘言1, * , 夏珍珍2 , 王桥1 , 段烁1 ]
, 刘言, 夏珍珍|
|


作者简介: 王 超, 1998年生,武汉轻工大学食品科学与工程学院硕士研究生 e-mail: 734100693@qq.com
小龙虾是近年来广受消费者欢迎的淡水产品, 相关产业迅猛发展, 产生巨大的经济利益。 小龙虾整虾及虾仁、 虾尾在运输过程中极易腐败变质, 产生有害物质。 如果不能对小龙虾新鲜度进行及时检测, 任由腐败小龙虾进入食品流通环节, 极易酿成食品安全事故, 危害消费者生命安全, 对整个产业链造成不良影响。 挥发性盐基氮(TVBN)是衡量水产品新鲜度的主要指标, 也可以用于衡量小龙虾的新鲜度, 但传统的挥发性盐基氮检测方法存在步骤复杂、 检测时间长和化学试剂污染的等问题, 无法满足小龙虾庞大产业链的检测需求。 近红外光谱技术是一种快速、 无损、 环境友好的分析技术, 在食品分析领域中已有较为广泛的应用。 本研究基于近红外光谱分析技术(NIR), 结合化学计量学方法提出一种小龙虾新鲜度的快速检测方法。 使用偏最小二乘算法(PLS)建立小龙虾虾尾挥发性盐基氮定量分析模型。 为了提高模型的预测能力, 使用多元散射校正(MSC)、 标准正态变换(SNV)、 连续小波变换(CWT)和1阶导数(1st)法对光谱进行预处理, 扣除光谱背景; 使用蒙特卡洛-无信息消除(MC-UVE)和随机检测(RT)算法进行波长筛选, 选择光谱中有效变量。 结果显示, 光谱预处理和波长筛选技术能够有效提高模型的预测能力。 其中, 经过1阶导数和蒙特卡洛-无信息变量消除法组合优化处理之后的光谱所建立的偏最小二乘模型与其他模型相比具有更好的预测能力, 对于预测集样品, 其预测均方根误差和相关系数可达1.626和0.950, 能够实现对小龙虾新鲜度的快速、 准确检测。
Crayfish is one of the most popular freshwater products in China. The industrial chain of crayfish has rapidly developed and produced gorgeous economic benefits. Easy to be putrid during the logistics transportation, the freshness of crayfish and related products must be monitored and has paid much attention in recent years. If the putrid crayfish cannot be detected in time, food safety accidents may happen, and the whole industrial chain of crayfish would be destroyed. The total volatile basic nitrogen (TVBN) is the common index of freshness for aquatic products and can be used to evaluate the freshness of crayfish. The traditional analytical methods for TVBN are accurate but complex, time-consuming and environmentally hazardous. Developing novel, fast and stable methods are inevitable for the freshness evaluation of crayfish with large scale. Near-infrared spectroscopy (NIR) is a fast, non-destructive and environmentally friendly analytical technique widely used in many fields. In this study, a method for monitoring the freshness of crayfish by near-infrared spectroscopy combined with chemometrics was proposed. The TVBN were adopted as the freshness index and the quantitative models were built by partial least squares (PLS). The spectral pretreatment and variable selection methods were adopted to improve the models further. For the edible part of the crayfish, reasonable validation results can be obtained by using the optimized models. The combination of 1st and (MC-UVE) seems to have the better optimization results. For total volatile basic nitrogen (TVBN), the root means square error of prediction (RMSEP) and correlation coefficient ( r) of the crayfish tails were 1.626 and 0.950.
小龙虾(Procambarus clarkii)是一种原产于北美的淡水鳌虾, 最早于20世纪30年代引入中国。 随着人们生活水平的提高, 小龙虾因其营养丰富、 味道鲜美、 易于加工等特点成为深受消费者喜爱的水产品。 近年来小龙虾产业发展迅速, 形成了相当规模的产业集群。 中国小龙虾产业发展报告(2021)显示, 2020年小龙虾产业总产值高达3 448.46亿元, 养殖总面积达到2 184.63万亩, 养殖总产量达到239.37万吨。 其中, 长江中下游的湖北、 安徽、 湖南、 江苏、 江西5个省占据绝对主导地位, 养殖总产量218.69万吨, 占全国小龙虾养殖总产量的91.36%。 2020年, 我国共有小龙虾规模以上(年加工量100 t以上)加工企业123家, 总加工量约为88.07万吨, 年加工总产值约为480.07亿元。 按地域分布, 大量加工企业仍然主要集中在湖北、 安徽、 湖南、 江苏、 江西5个传统小龙虾养殖主产省。 其中仅湖北省, 规模以上加工企业就超过50家, 加工量超过60万吨, 占全国规模以上加工企业总加工量的近70%。 由于产地和加工地较为集中, 小龙虾及相关初级加工产品(虾尾、 虾仁)在送达加工企业或消费者餐桌之前往往需要经历较长时间的物流运输过程。 作为甲壳类生物, 小龙虾极易腐烂变质, 产生有害物质。 如果不能及时对小龙虾的新鲜度进行检测而引发食品安全事故, 将会对消费者的生命安全和整个小龙虾产业链产生毁灭性的影响。 因此, 必须对小龙虾的新鲜度进行全面监控, 维护消费者的利益, 保障小龙虾产业安全健康发展。
挥发性盐基氮(total volatile basic nitrogen, TVBN)一般指动物性食品由于酶和细菌的作用, 在腐败过程中, 使蛋白质分解而产生氨以及胺类等碱性含氮物质, 是衡量水产品新鲜度的主要指标。 现行的国家标准(GB5009.228— 2016)采用半微量定氮法、 自动凯氏定氮法和微量扩散法进行检测, 能够对小龙虾中的挥发性盐基氮进行准确定量, 但存在着操作繁琐、 有机试剂污染、 耗时较长等问题。 小龙虾产业高速发展, 规模迅速扩张, 传统国标方法的已不能满足庞大产业的检测需求, 必须针对性地开发新型分析检测技术。 近红外光谱分析技术是一种结合了近红外光谱、 化学计量学、 计算机科学等多学科的光谱检测技术, 具有快速、 无损、 高效、 环境友好等优点[1]。 近红外光谱是780~2 526 nm的电磁辐射, 包含了包括碳氢、 碳氧、 氢氧、 氮氢等基团在内的丰富化学键信息, 但也存在谱带重合严重、 吸收强度弱、 背景高等问题。 需要借助化学计量学方法, 通过建立分析模型从光谱中提取有效信息, 实现定性定量分析。 常见的建模方法包括偏最小二乘(partialleast squares, PLS)、 支持向量机(support vector machine, SVM)、 人工神经网络(artificial neural network, ANN)等。 在某些实际应用中, 样品的光谱中包含大量无关信息, 使得光谱的整体背景偏高, 利用原始光谱直接建模往往难以得到较好的分析结果。 需要使用光谱预处理、 波长筛选等技术对光谱进行处理, 通过扣除光谱背景、 选择有效波长等方法来提升模型的分析能力。 光谱预处理技术能够有效扣除原始光谱中的背景, 提高光谱分辨率, 为后续建模工作打下基础, 常见的光谱预处理方法包括多元散射校正(multiplicative scatter correction, MSC)、 标准正态变换(standard normal variate, SNV)、 连续小波变换(continuous wavelet transform, CWT)和1阶导数(1st derivative, 1st)等等。 波长筛选技术则能够从整段近红外光谱中提取出与建模高度相关的波长, 在提高模型解释能力、 降低冗余度的同时, 提升预测准确性。 常见的波长筛选方法包括无信息变量删除(uninformative variableelimination, UVE)、 蒙特卡罗-无信息变量删除(Monte Carlo-uninformative variable elimination, MCUVE)、 随机测试(randomization test, RT)、 竞争自适应重加权采样(competitive adaptive re-weighted sampling, CARS)等等[2, 3, 4]。 其中RT算法依靠打乱浓度矩阵与光谱矩阵之间的对应关系来考察变量在建模之中的稳定性, 通过扣除稳定性差的变量来实现波长筛选[2]; UVE和MCUVE方法主要通过多次采样建模来考察变量在建模过程中的稳定性, 借助淘汰稳定性差的变量实现波长选择[3]; 而CARS算法则以达尔文进化论的“ 适者生存” 为基本原则, 通过多次迭代计算淘汰无效波长点, 保留对于模型有利的波长点, 实现波长筛选[4]。
近红外光谱分析技术已经在各个领域之中得到广泛的应用[5, 6, 7]。 在食品分析领域之中, 已应用于对肉制品、 水果、 蔬菜、 鱼中蛋白质、 脂肪、 维生素、 有机酸、 糖分等相关参数的快速检测[8, 9, 10]。 在食品新鲜度检测领域, 也有相关的文献报道[11, 12]。 如Kucha等利用近红外光谱技术对猪肉中硫代巴比妥酸反应物进行快速检测, 实现猪肉新鲜度分析; 有研究采用近红外光谱技术实现对三文鱼中的挥发性盐基氮的快速检测; Xiong等[12]利用近红外光谱技术对生菜的新鲜度进行快速判别等。 而目前仍未发现基于近红外光谱分析技术检测小龙虾新鲜度的研究工作。 同时, 波长筛选技术能够有效提高近红外光谱模型的预测能力, 而食品新鲜度的相关研究之中该技术应用较少。 本研究以近红外光谱分析技术为基础建立小龙虾新鲜度快速检测方法。 利用偏最小二乘法建立小龙虾挥发性盐基氮定量分析模型, 同时对光谱进行预处理, 初步提升模型的预测能力。 使用波长筛选方法分从光谱中选择有效变量来进一步提升模型预测能力。 使用优化后的模型对小龙虾中挥发性盐基氮进行检测, 并与传统方法进行比较验证。
在本地养殖场购买鲜活小龙虾, 在实验室中模拟长途物流运输过程。 将小龙虾分成5批放置于水产塑料箱中, 分别在0, 4, 10, 20和30 ℃下保存。 每隔2 h收集小龙虾样品(优先收集受伤、 死亡、 活性低的个体), 采集小龙虾可食用部分(虾尾)用于后续分析。 整个过程持续48 h, 共采集120份样品, 其中0和4 ℃下分别采集到6个样品, 10和20 ℃下分别采集到48个样品, 30 ℃采集到12个样品。 将采集到的样品组成训练集, 用于建立定量分析模型。 同时, 分别在湖北、 安徽、 江苏和湖南的主要产区订购小龙虾, 通过传统的物流方式运输到实验室, 物流运输时间为1~2 d。 采集样品的可使用部分(虾尾)用于后续分析, 共采集60份样品组成预测集, 用于对定量分析模型进行验证。
使用GB5009.228— 2016中的自动凯氏定氮法对训练集和预测集样品中的挥发性盐基氮进行测定。 实验所用氧化镁、 硼酸、 盐酸、 甲基红指示剂、 溴甲酚绿指示剂和95%乙醇均购置于阿拉丁试剂公司。 表1中列出了检测结果的详细信息。 从表1中可以看到, 训练集样品挥发性盐基氮的浓度分布范围广于预测集样品挥发性盐基氮的浓度分布范围, 两个样品集合中样品挥发性盐基氮最高浓度均超过了鲜、 冻动物性水产卫生标准(GB2733— 2005)中规定的最高浓度[20 mg· (100 g)-1], 说明在实际运输过程中确实存在新鲜度不合格的风险。 训练集样品中不合格样品数量高达60个, 不合格率为50.0%, 说明高温环境不适合小龙虾保存; 预测集样品不合格率为33.3%, 明显低于训练集。 训练集和预测集样品挥发性盐基氮浓度的平均值与标准偏差均较为接近, 说明经过模拟运输过程产生的训练集样品基本能够覆盖不同运输距离的小龙虾物流运输状况。
| 表1 训练集、 预测集样品挥发性盐基氮检测结果 Table 1 Analysis results of TVBN in calibration and prediction set |
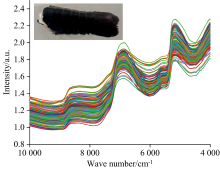
使用ThermoFisher公司的Antaris Ⅱ 型近红外光谱仪采集小龙虾可食用部分(虾尾)的漫反射光谱。 将小龙虾虾尾平铺置于石英培养皿上, 然后将培养皿放置在近红外光谱仪积分球配件的光斑上, 同时保证虾尾完全遮挡光斑, 采集虾尾的近红外光谱。 光谱波长范围为4 000~10 000 cm-1, 采集间隔1 cm-1, 每条光谱包含6 001个数据点。 扫描次数为64, 实验时环境温度为4 ℃, 仪器工作温度25 ℃。 虾尾的光谱图如图1所示。
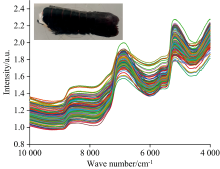 | 图1 小龙虾虾尾光谱Fig.1 Spectra of crayfish tails |
分别使用MSC, SNV, CWT和1st对训练集和预测集样品的光谱进行处理。 其中, CWT处理时选择Haar小波为小波基, 尺度系数为20; 1st处理时尺度系数为19。 使用偏最小二乘法, 利用训练集样品的原始光谱和不同预处理方法处理之后的光谱分别建立挥发性盐基氮定量分析模型, 建模过程中所需的模型因子数通过蒙特卡洛交叉验证法(Monte Carlo cross validation, MCCV)确定[13]。 为了对不同的模型进行验证, 使用留一交叉验证法(leave one out cross validation, LOOCV)计算训练集样品的挥发性盐基氮浓度, 然后与国标方法的分析结果进行比较, 计算预测浓度的交叉验证均方根误差(root mean square error of cross validation, RMSECV)和相关系数(R训练), 通过比较不同模型的RMSECV和R训练值确定最优的光谱预处理方法。 为进一步优化模型, 分别使用蒙特卡洛-无信息变量消除法和随机检测法[14]对最优光谱预处理方法处理之后的光谱进行波长筛选, 选择重要变量重新建立PLS定量分析模型。 再次使用留一交叉验证法计算训练集样品的挥发性盐基氮浓度, 同时计算预测结果的RMSECV和R训练值对不同模型进行验证, 确定最优的光谱预处理和波长筛选方法组合。 在确定最优组合之后, 使用预测集光谱和最优化模型计算预测集样品中挥发性盐基氮含量, 并与国标方法的分析结果进行比较, 通过计算预测均方根误差(root mean square error of prediction, RMSEP)和相关系数(R预测)评价模型实际预测能力。 所有建模及计算过程均在个人电脑上使用Matlab 2020a完成。
有研究表明光谱预处理技术可以有效扣除光谱中的背景信息, 使用经光谱预处理技术处理之后的光谱建模可以有效提高模型的预测能力。 本研究使用四种常见的光谱预处理技术对分别对原始光谱进行处理, 并使用处理之后的光谱建立PLS模型, 使用留一交叉验证法计算训练集样品的挥发性盐基氮浓度, 然后与国标方法的分析结果进行比较, 结果如表2所示。 从表2可以看到, 光谱预处理方法可以显著提高模型的预测能力。 原始光谱建立PLS模型预测结果的RMSECV值为4.138, R训练仅为0.776, 而原始光谱经过MSC和SNV处理之后, 对应光谱建立PLS模型预测结果的RMSECV值下降到2.363和2.576, R训练提升到0.933和0.920。 如果使用小波变换和1阶导数对光谱进行处理, 可以得到更好的结果, 对应PLS模型预测结果的RMSECV值可以下降到1.709和1.712, R训练提升到0.965。 经小波变换和1阶导数处理之后光谱所建立PLS模型预测结果的RMSECV值和R训练优于经MSC和SNV方法处理之后光谱所建立PLS模型预测结果的RMSECV值和R训练。 而小波变换和1阶导数两种方法处理光谱之后对于模型预测能力的提升效果接近。 因此, 选择使用小波变换和1阶导数优化之后的光谱进行波长筛选, 做进一步优化。
| 表2 不同光谱预处理方法处理光谱建立 PLS模型的预测结果 Table 2 Prediction results of PLS models optimized by different spectral preprocessing methods |
为了进一步提高模型的预测能力, 使用MC-UVE和RT算法分别对经过小波变换和1阶导数处理之后的光谱进行波长筛选, 不同光谱的筛选结果如图2(a)和(b)所示。 从图中可以看到, 经过筛选之后的光谱呈现高度集中的趋势, 对于经小波变换处理后的光谱, 从图2(a)中可以看到, 两种波长筛选方法所处理得到的变量较为相似, 大部分变量集中在5 300, 7 200, 7 600~7 700和8 800 cm-1四个区域, 少部分使用RT算法选择的变量位于4 600 cm-1。 根据Jerry Workman所著的《Practical Guide to Interpretive Near-Infrared Spectroscopy》, 位于5 300 cm-1附近的波段属于N— H伸缩振动和弯曲振动的组合频吸收峰; 7 200和7 600~7 700 cm-1两个波段分别属于伯酰胺和伯芳胺中N— H的2ν 反对称吸收峰; 8 800 cm-1波段属于N— H溶液中3ν 反对称吸收峰; 4 600 cm-1波段属于N— H反对称振动和NH2摇摆振动的组合频吸收峰。 可以看到, 筛选得到的波长均与胺基基团相关, 相较于使用全波长建立的定量模型, 筛选后的波长所建立的模型具有更好的解释能力。 对于经过1阶导数处理之后的光谱, 图2(b)中大部分经两种方法筛选得到的光谱与图2(a)中的区域相似, 不同之处仅在于MC-UVE算法未筛选出波长范围5 300 cm-1的变量, 而筛选出了波长范围4 600 cm-1处的变量。
 | 图2 不同光谱波长筛选结果 (a): 小波变换; (b): 1阶导数Fig.2 Selected variables by using MC-UVE and RT methods for the spectra preprocessed (a): WT; (b): 1st |
使用筛选出的波长重新建立PLS模型, 利用留一交叉验证法计算训练集样品挥发性盐基氮浓度, 同时计算RMSECV值和R训练对新模型进行验证, 结果列于表3。 比较表2与表3中数据可以看出, 波长筛选可以进一步提升模型的预测能力。 对于经过小波变换处理之后的光谱, 表2中经全波段光谱所建立PLS模型预测结果的RMSECV值为1.709, R训练为0.965, 当使用MC-UVE算法选择其中318个有效变量重新建立PLS模型之后, 模型预测结果的RMSECV值降低至1.525, R训练提升至0.973。 如果使用RT算法选择其中235个有效变量建立PLS模型, 则对应模型预测结果的RMSECV值降至1.529, R训练升至0.972, 提升幅度与经MC-UVE算法选择之后的变量所建立的PLS模型类似。 对于经过1阶导数处理之后的光谱, 两种波长筛选同样获得了提升模型预测能力的效果。 综合来看, 1阶导数和MC-UVE的组合略微优于其他3种组合, 具有相对较低的RMSECV值(1.464)和较高的R训练值(0.975)。
| 表3 不同光谱预处理方法结合波长筛选方法 处理光谱建立PLS模型的预测结果 Table 3 Prediction results of PLS models optimized by spectral preprocessing method coupled with wavelength selection method |
为了验证不同PLS模型的实际预测效果, 使用PLS模型结合预测集样品光谱计算对应样品中挥发性盐基氮含量, 并与标准方法计算得到的参考值进行比较, 不同模型的计算结果分别列于表2和表3之中。 通过比较可以发现, 表2和表3中RMSECV值和RMSEP值、 R训练和R预测的差值较小, 大部分RMSECV值小于对应的RMSEP值, 而R训练值大于对应R预测值, 说明模型不存在过拟合的风险。 同时, 与训练集的结果类似, 在对实际样品的预测之中, 光谱预处理和波长筛选技术有效提高了模型的预测能力。 在表2中, 原始光谱所建立的PLS模型预测结果的RMSEP值高达3.299, R预测仅为0.779; 当使用WT和1st对光谱进行处理之后, 对应光谱所建立PLS模型预测结果的RMSEP值降低至1.944和1.984, R预测值提升至0.931和0.929。 MSC和SNV两种方法处理光谱同样可以提升模型的预测能力, 但提升幅度不如前两种方法明显。 表3中可见, MC-UVE和RT两种波长筛选技术可以进一步提升模型的预测能力。 与训练集结果类似, 使用MC-UVE方法从经过1st处理之后的光谱中选择得到269个变量, 利用这269个变量建立PLS模型的预测结果可以将RMSEP值进一步降低至1.626, R预测值提高到0.950, 优于其他组合的预测结果。
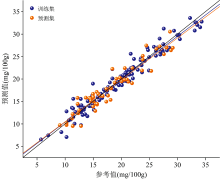
为了更直观地说明优化后模型的预测能力, 图3中画出了使用最优方法组合(1st+MC-UVE)处理光谱之后建立PLS模型对训练集和预测集样品中挥发性盐基氮含量的计算结果散点图。 从图3中可以看出, 大部分训练集(深蓝)和预测集(橙)样品沿对角线(黑线)均匀分布, PLS模型计算得到的挥发性盐基氮含量和使用国标方法检测得到的挥发性盐基氮含量之间的差异较小, 且差异与浓度大小无明显的关系。 分别使用训练集样品和预测集样品计算拟合直线(深蓝线和橙线), 可以发现两条直线与对角线的重合度较好, 偏差值较小。 研究结果表明该PLS模型对于实际样品有较好能预测能力, 能够用于相关样品中挥发性盐基氮的快速检测。
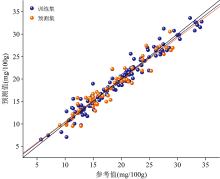 | 图3 优化后PLS模型的预测结果Fig.3 Prediction results obtained by the optimized PLS model |
提出了一种基于近红外光谱技术结合化学计量法方法的小龙虾新鲜度快速检测技术。 使用PLS算法建立基于虾尾近红外光谱的挥发性盐基氮定量分析模型, 利用光谱预处理和波长筛选技术对模型进行优化, 提高模型预测能力。 研究发现, 先使用1st方法处理光谱, 然后使用MC-UVE方法筛选变量之后建立的PLS模型具有相对较好的预测能力。 使用该模型对实际样品中得挥发性盐基氮值进行计算, 预测结果的RMSEP值和R预测值分别为1.626和0.950。 结果表明, 该方法有一定的实际应用价值, 可以用于小龙虾新鲜度的快速检测。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|