



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于改进E-DWT算法和深度学习模型的红小豆锈病诊断方法
[付强1  , 关海鸥
, 关海鸥1, * , 李嘉琪2 ]
, 关海鸥, 李嘉琪|
|


作者简介: 付 强, 1992年生,黑龙江八一农垦大学信息与电气工程学院讲师 e-mail: fuqiang41151003@126.com
红小豆锈病是一种由真菌引起的常见植物病害, 主要通过感染叶片影响光合作用, 导致作物产量显著下降。 本文提出了一种基于改进经验模态分解-小波变换(E-DWT)算法和深度学习模型的新型红小豆锈病诊断方法。 选用“宝清红”红小豆作为实验对象, 使用手持可见/近红外光谱仪对960例红小豆叶片进行为期10天的连续光谱数据采集, 获取波长范围为326~1 075 nm的红小豆叶片反射率数据。 首先, 采用改进的E-DWT算法对采集的光谱数据进行去噪处理。 该算法结合了经验模态分解(EMD)和小波阈值去噪技术, 能够在去除噪声的同时最大限度保留信号的有效信息。 通过对比RMSE和SNR指标确定了最佳的小波基函数(sym5)和分解层数(4层)。 为了进一步降低高维数据中的冗余信息, 采用连续投影算法(SPA)从750个初始波长中筛选出了12个具有代表性的特征波长, 实现了数据降维, 将特征波长数量减少了98.4%。 接着, 结合格拉姆角场(GAF)方法, 将一维波长序列转换为二维光谱图像, 增强了不同波段之间的相关性, 便于后续的模型训练。 在模型设计上, 采用了结合卷积神经网络(CNN)和卷积块注意力机制(CBAM)的深度学习模型。 CBAM模块通过引入通道和空间注意力机制, 能够有效区分光谱数据中不同特征波长和时间节点的权重, 使模型更加关注影响红小豆锈病识别的关键特征。 实验结果表明, 基于CBAM的CNN模型在训练集中的识别率为99.31%, 而在测试集中的识别率为98.33%, 召回率达到98.89%, 明显高于传统CNN模型的表现。 与现有的其他方法相比, 本文提出的模型在识别准确性、 稳定性以及训练收敛速度上均具有显著优势。 总体而言, 本文所提出的基于改进E-DWT算法与CBAM-CNN模型的红小豆锈病诊断方法, 不仅实现了高效、 精准的病害检测, 还为未来数据驱动型作物病害诊断系统的构建提供了理论依据与技术支持。
Adzuki bean rust is a common fungal disease that significantly reduces crop yield by infecting leaves and impairing photosynthesis. This paper proposes a novel diagnostic method for adzuki bean rust based on an improved Empirical Mode Decomposition-Wavelet Transform (E-DWT) algorithm and a deep learning model. Using “Baoqinghong” adzuki beans as the experimental material, 960 leaf spectral datasets were collected over 10 days using a handheld visible/near-infrared spectrometer, obtaining reflectance data in the wavelength range of 326~1 075 nm. First, the improved E-DWT algorithm was applied for spectral denoising. This algorithm combines Empirical Mode Decomposition (EMD) and wavelet threshold denoising technology to retain effective signal information while removing noise. The optimal wavelet basis function (sym5) and the number of decomposition layers (4 layers) were determined by comparing the RMSE and SNR indicators. To further reduce redundancy in high-dimensional data, the Successive Projections Algorithm (SPA) was employed to select 12 representative wavelengths from the initial 750 features, resulting in a 98.4% reduction in feature wavelength count. Next, the Gramian Angular Field (GAF) method was employed to convert the one-dimensional wavelength sequence into a two-dimensional spectral image, thereby enhancing correlations between different bands for subsequent model training. The designed deep learning model combines a Convolutional Neural Network (CNN) with a Convolutional Block Attention Module (CBAM). The CBAM module effectively discriminates the weights of different feature wavelengths and time nodes through channel and spatial attention mechanisms, enabling the model to focus on key features influencing adzuki bean rust identification. Experimental results show that the CBAM-CNN model achieved 99.31% accuracy in the training set, 98.33% accuracy in the test set, and 98.89% recall, significantly outperforming traditional CNN models. Compared to existing methods, the proposed model exhibits superior performance in terms of recognition accuracy, stability, and training convergence speed. Additionally, the model structure is more concise, which optimizes parameter adjustment and improves operability in practical applications. In conclusion, the proposed diagnostic method based on the improved E-DWT algorithm and CBAM-CNN model not only achieves efficient and precise disease detection but also provides a theoretical foundation and technical support for constructing data-driven crop disease diagnosis systems in the future.
红小豆是一种广泛种植的粮食作物[1], 生长周期短且具有极高的药用价值和经济价值。 红小豆锈病是其常见的病害之一, 锈病菌孢子会通过空气流动或雨水传播, 导致植株大范围感染, 从而严重影响作物的质量和产量[2]。 为了有效防治红小豆锈病, 通常采取预防为主的策略, 若能在病害初期及时识别并干预, 防治效果将显著提升[3]。 因此, 尽早准确识别染病植株, 不仅能够指导农户对患病植株进行精准施药, 还能有效提高药物的使用效率[4], 对红小豆作物产量的提高大有裨益。
传统的作物病害检测方法依赖于田间调查和实验室检测, 尽管这些方法可靠且准确, 但过程繁琐耗时, 且可能会对作物造成破坏, 难以满足现代农业高效防控的需求。 因此, 采用更加快速且无损的物理检测方法成为农业领域中常见的病虫害识别技术。 Meng等[5]利用反射光谱建立光谱病害指数, 实现玉米南方锈病轻度、 中度和重度3个等级的烈度分类。 Barthel等[6]利用光谱数据并结合多元统计方法实现了苹果黄化病的有效识别。 沈梦娇等[7]利用遗传算法与局部二值模式实现了基于图像纹理特征的辣椒早疫病潜育期识别模型。 随着人工智能技术的不断发展, 深度学习算法在病虫害检测[8]、 植物物种识别[9]及果蔬质量检测[10]等领域得到更加广泛的应用。
然而, 目前基于光谱信息的病害识别方法大多是将多时间节点的数据作为一个整体处理, 未能有效考虑到光谱信号的时序特性, 忽略了光谱突变时间节点在病害预测中的重要性。 这使得病害预测的准确性较低, 且存在时滞, 从而延误了病害干预的最佳时机。 为解决这一问题, 本研究以红小豆光谱数据为研究对象, 构建了基于改进E-DWT算法和深度学习模型的红小豆锈病识别模型。
“ 宝清红” 红小豆是中国北方寒冷地区主要栽培的品种之一, 其在生长过程中易感染锈病等病原菌, 导致产量下降。 作为研究对象的“ 宝清红” 红小豆在实验室条件下栽培, 温湿度自动记录仪每小时记录一次数据, 实验期间温度控制在23~28 ℃之间, 湿度保持40%~60%。 采用16 h光照/8 h黑暗的光周期, 白天自然光通过智能补光系统维持光照强度在2 000~2 500 Lux, 夜间保持黑暗环境。 样本生长期间保持通风。 用孢子悬浮液对部分样本进行病原菌接种。 接种后, 每隔24 h采集所有植株样本的光谱曲线, 并连续采集10 d, 最终接种病菌叶片全部出现明显的病症。 使用ASD公司生产的手持Field Spec UV/VNIR光谱仪采集红小豆叶片的光谱数据, 首先获取像元亮度值(DN值), 然后通过ViewSpecPro软件将其转换为光谱折射率。 共收集了960组红小豆叶片的光谱数据, 所有光谱数据均经过白平衡校准, 检测波长范围为326~1 075 nm, 实验场景见图1(a)和(b), 图1(c)— (f)分别展示染病、 健康样本实物及其典型原始光谱。
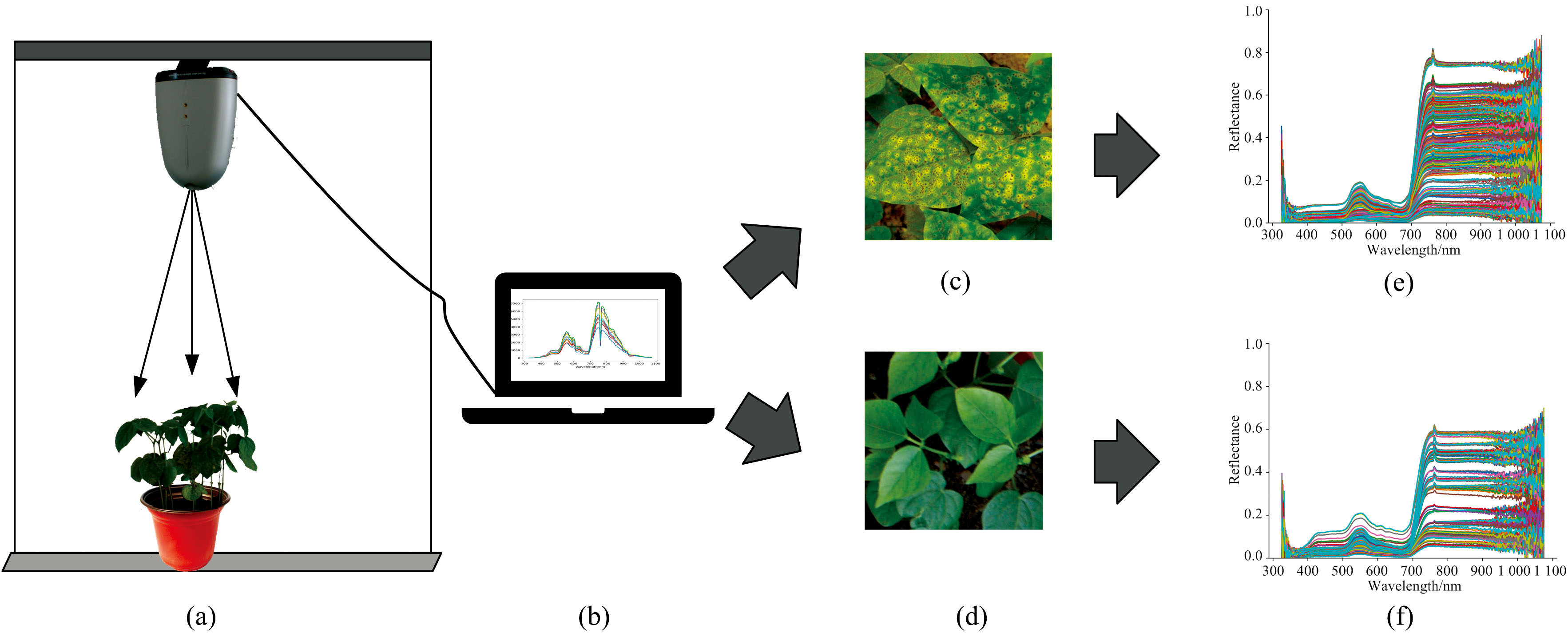 | 图1 光谱采集设备示意图 (a): 红小豆叶片光谱采集装置; (b): 外接电脑及内置软件; (c): 染病红小豆叶片样本; (d): 健康红小豆叶片样本; (e): 染病红小豆样本光谱曲线; (f): 健康红小豆样本光谱曲线Fig.1 The schematic diagram of the spectral acquisition device (a): Spectral collection device for adzuki bean leaves; (b): External computer and built-in software; (c): Samples of infected adzuki beans; (d): Samples of healthy adzuki beans; (e): Spectra of infected adzuki bean samples; (f): Spectra of healthy adzuki bean samples |
光谱数据采集过程中由于光照强度, 温度, 湿度等原因可能导致植物叶片的光谱特性发生变化, 从而引入噪声, 除此之外, 采集设备本身的性能、 精度和稳定性以及人工操作等原因也会产生噪声信号, 对后续的模型构建造成一定的影响, 因此本研究选择使用改进的E-DWT算法对采集的光谱数据进行降噪处理。 E-DWT算法是一种综合了经验模态分解和小波阈值技术的信号处理方法, 它将EMD的自适应频率提取能力与小波阈值的优秀降噪效果融合, 从而达到更高效地去除噪声的目的。 但传统的E-DWT算法没有对IMF分量进行优选, 造成原始信号完整性缺失等问题, 因此本工作选择余弦相似度指标将EMD分解的结果划分为信号主导的IMF分量和噪声主导的IMF分量, 并对噪声主导的IMF分量使用小波阈值方法进一步降噪处理, 在保留原始信号完整性的基础上实现更优的降噪效果。
对红小豆叶片光谱数据进行EMD分解, 生成一系列IMF分量和残差项, 每个IMF的幅值和频率不同, 利用低频分量重构光谱信号, 可以达到一定的降噪目的。 选择使用余弦相似度指标对IMF分量进行优化, 具体计算公式为
式(1)中, XIMF和Xorg分别表示IMF分量和原始信号。 计算各IMF分量与原始信号的余弦相似度, 结果如表1所示。 将各IMF分量余弦相似度的平均值0.100 1设为阈值, IMF5和IMF6的相似度分别为0.143 3和0.196 8, 显著高于阈值, 因此被认为是信号的主导分量, 而IMF1— IMF4的余弦相似度小于阈值, 被认为是噪声主导分量, 即信号中含有较多的噪声干扰。
| 表1 EMD分解后各IMF分量的余弦相似度 Table 1 IMF cosine similarity obtained by EMD decomposition |
传统的EMD去噪方法直接消除了所有以噪声为主的信号成分。 然而, 高频信号中也包含有效信号, 如果直接将其剔除, 会造成信号的缺失。 为了解决信号失真问题, 进一步采用小波分解对噪声主导的IMF分量进行去噪处理。
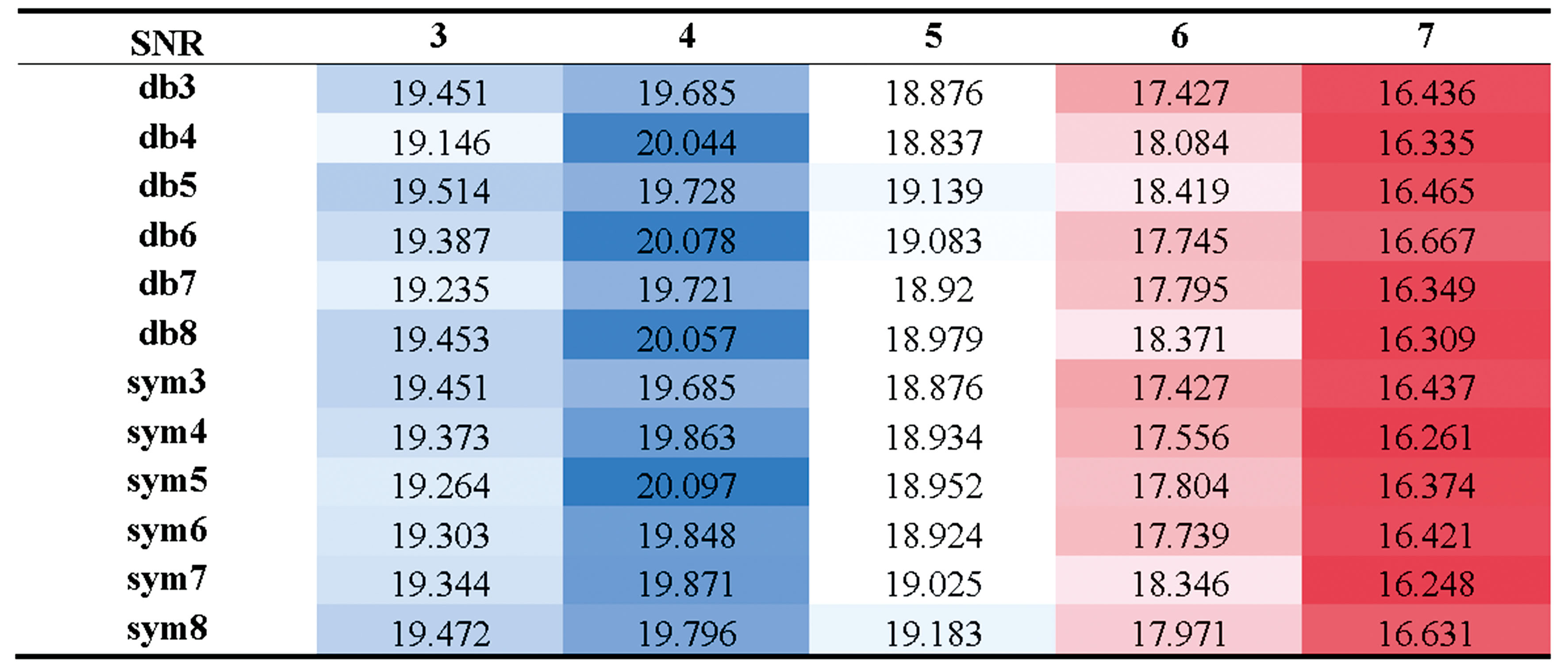
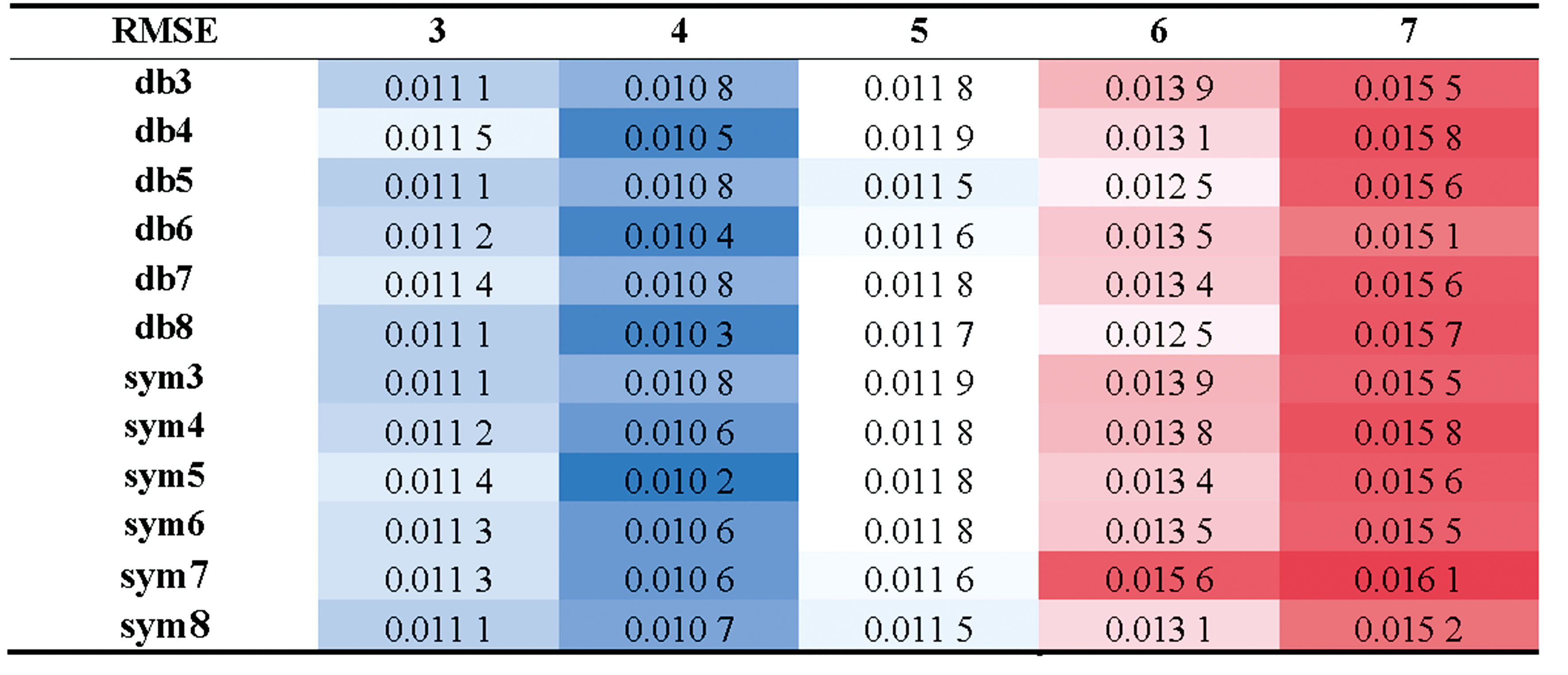
小波分解是一种将信号分解为不同频率的小波分量的方法, 在序列数据的噪声去除和有效信息提取方面具有独特的优势, 被广泛应用于非平稳信号的分析[11]。 影响降噪效果的因素主要包括小波基函数和小波分解层数的选择。 将基于信噪比(SNR)和均方根误差(RMSE)两个指标选取合适的超参数。 对比Symlet小波系(symN)和Daubechies(dbN)小波系在不同分解层数下的降噪效果, 结果如表2和表3所示。
| 表2 不同小波基函数在不同分解层的SNR Table 2 SNR of different wavelet groups at different decomposition layers |
| 表3 不同小波基函数在不同分解层的RMSE Table 3 RMSE of different wavelet groups at different decomposition layers |
在上述结果中, 蓝色单元格代表评价指标下的较优选择, 相反, 红色单元格代表评价指标下的较差选择。 对于dbN小波系, 信噪比指标的3个最优值分别为20.044、 20.057和20.078。 当小波基为db6, 小波分解层数为4时, SNR的最大值为20.078; 当小波基选取db8, 分解层数为4时, RMSE的最优值为0.010 3。 Symlet小波系在RMSE和SNR两种评价指标的变化趋势均呈现出一定的规律性, 即随着分解层数的增加, 整体效果先增大后减小, 在分解层数为4时达到最佳。 具体来说, 当小波基为sym5, 分解层数为4时, RMSE指标达到最优值, 该条件下的SNR指标也达到最优值20.097, 优于dbN小波系的结果。 因此, 采用sym5小波基函数并对信号进行4层分解。 Symlet小波作为近似对称的紧支撑小波, 其线性相位特性更适用于光谱信号处理。 对比表3可见sym5在4层分解时, 其频带划分与红小豆光谱噪声频段更匹配, 能更好分离高频噪声与有效信号。 而dbN小波的不对称性可能导致相位失真, 影响光谱特征保留。
分别使用EMD方法、 小波阈值去噪方法以及EMD-DWT方法对红小豆叶片光谱数据进行降噪处理, 各项指标如表4所示。 其中, RMSE为基于原始信号X与去噪信号
| 表4 三种降噪算法对比 Table 4 Comparison of the three denoising methods |
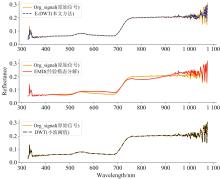
由表4可知, 基于小波阈值的去噪方法能够起到一定的去噪目的, 但整体效果不明显, SNR和RMSE不如E-DWT方法。 对于复杂信号, 单一的小波去噪方法不能充分提取信号的细节特征。 因此, 在小波阈值降噪的基础上引入EMD分解, 提供了一种多尺度分析方法, 可以从多个角度对信号进行分析处理, 进一步提高降噪的准确性和稳定性。 基于单一EMD分解的去噪方法虽然有效提高了信噪比, 但去除的IMF有效分量过多, 导致RMSE较小, 即去噪后的信号与原始信号差异过大, 造成信号失真, 影响后续建模过程。 三种方法对红小豆叶片光谱数据的去噪效果如图2所示。
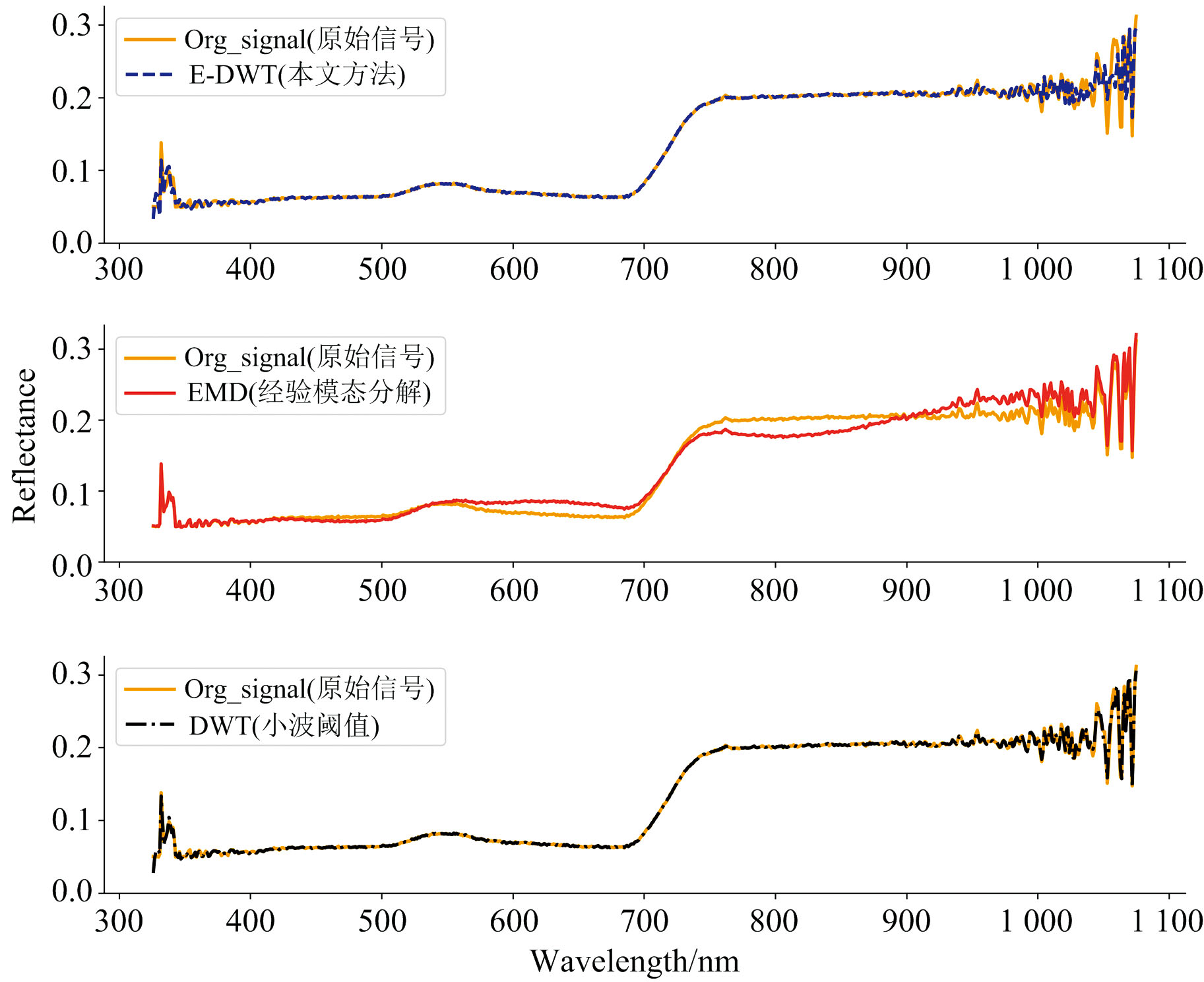 | 图2 不同算法降噪效果对比图Fig.2 Comparison of noise reduction effects |
采集的光谱数据覆盖326~1 075 nm波长范围, 特征维度高, 冗余信息多。 在光谱学领域, 常见的特征提取方法有主成分分析法(PCA)、 协同区间偏最小二乘法(SiPLS)、 连续投影算法(SPA)等[12]。 其中, 因SPA具有用时更短、 结果可重复、 且特征波长数可控的特性, 故选用SPA对红小豆叶片近红外光谱数据进行光谱特征波长的提取。 除此之外, 提取特征波长组成的波长向量难以表达各分量之间的相关性, 因此引入格拉姆角场理论将小波分解后的波长序列转换为极坐标系下的表示, 并进一步生产GASF矩阵, 从而转换为二维图像特征, 在保留了特征波长序列特性的基础上, 增加了各分量之间的相关性, 方便后续模型的构建。
连续投影算法是一种前向特征变量选择方法[13], 其利用向量的投影分析原理, 以选择含有最少冗余信息及最小共线性的变量组合。 为了确定SPA算法中需要提取的波长数N, 将经SPA算法提取后的特征波长矩阵和分类标签分别建立支持向量机(SVM)模型, 得到建模集交叉验证的准确率。 每个值对应一个不同的候选子集, 最大准确率值对应的N即为SPA算法的最优参数。
设定SPA算法的波长选择数目范围为2~30, 随着特征波长的不断增加, 模型的精度曲线呈现先上升后下降的趋势。 当N=12时, SVM的准确率达到最优值, 即选取12个特征波长。 与原始的750个特征波长相比, 此时的特征数量减少了98.4%, 简化效果明显。 具体而言, 对于采集的光谱数据, 其波长分别为: 326、 341、 360、 549、 688、 757、 951、 993、 1 011、 1 030、 1 049和1 075 nm。 如图3所示, 星号标记点为优选波长, 得到长度为12的一维光谱序列。
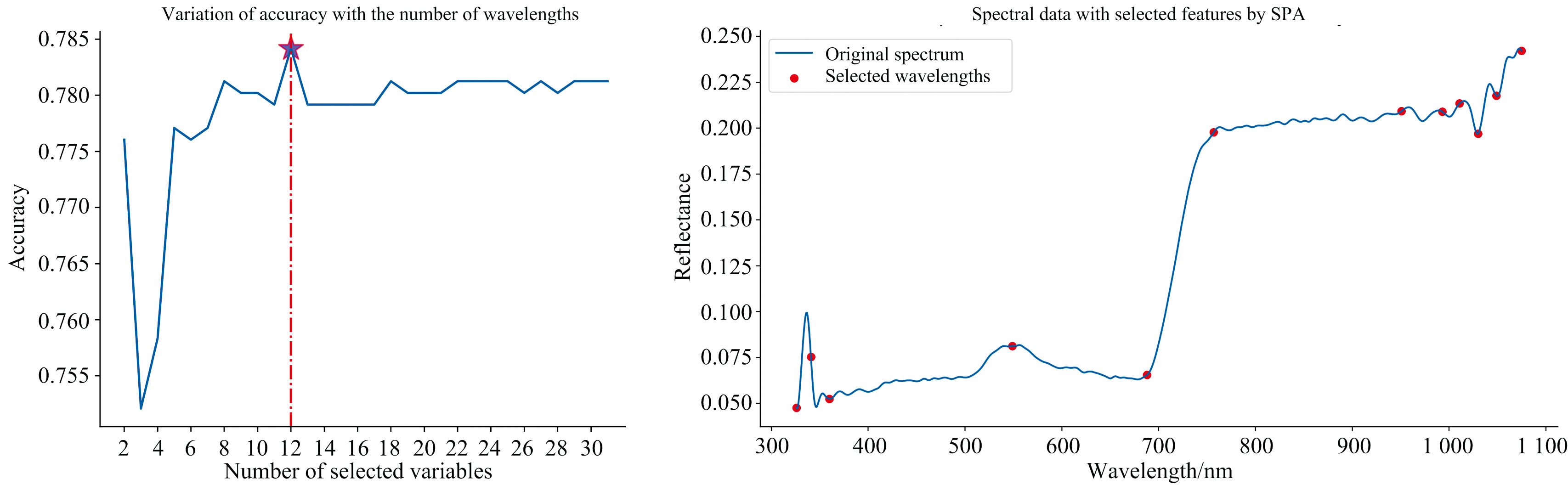 | 图3 SPA算法对红小豆叶片光谱数据进行特征提取Fig.3 SPA algorithm used to extract the features of adzuki bean leaf spectral data |
为了验证特征提取效果, 分别建立红小豆光谱数据的PCA-SVM模型和全波段-SVM模型, 并与SPA-SVM模型进行比较, 具体结果如表5所示。
| 表5 不同特征波长提取方法比较 Table 5 Comparison of several different feature wavelength extraction methods |
由表5可知, 同样选择SVM作为预测模型, 特征波长提取后的模型精度高于直接使用全波段数据。 采用SPA算法和PCA算法分别提取12个和6个特征波长。 虽然PCA算法的降维比率更大, 但PCA-SVM模型的准确率仅为73.13%, 而SPA-SVM的准确率为78.42%, 且过少的特征波数不利于后续模型的建立。 因此, 选择SPA作为红小豆叶片光谱特征波长的提取方法。 但SPA-SVM算法的准确率较低, 仍不能满足实际应用的要求。 这是因为该算法仅以一维光谱特征序列为研究对象进行建模, 不能充分多时段信息的有效融合。 因此, 有必要对特征进行进一步处理, 选择更合适的方法进行建模。
经SPA算法进行特征波长提取处理后, 形成一维特征序列, 该序列只能表示数据点的独立特征值, 而无法直接展示数据点之间的关系或结构, 因此引入格拉姆角场(Gramian Angular field, GAF)理论将特征序列转换为二维图像特征, 以捕获数据点之间的相似性和关联性, 从而提供更丰富的信息表示。
格拉姆角场是一种用于将时间序列编码为图像的方法[14], 具体过程如下。 对于一维波长序列特征{
将缩放后的序列数据{
根据式(4), 得到坐标点极坐标下的极径
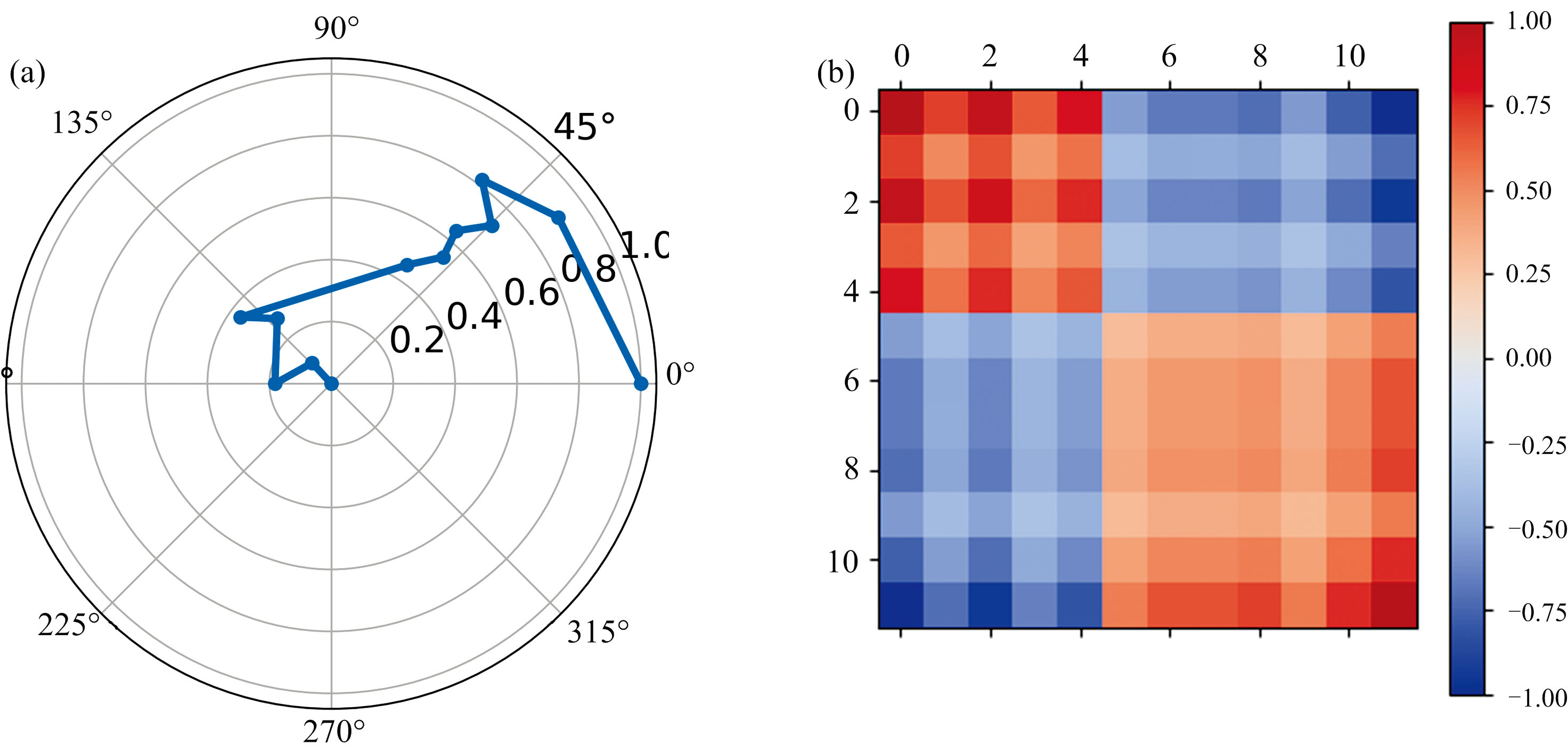 | 图4 基于格拉姆角场的特征向量变换 (a): 光谱矢量极坐标图; (b): GASF谱图Fig.4 Eigenvector transformations based on the GAF (a): Spectral vector polar map; (b): GASF spectrograms |
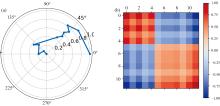
在保证光谱波长序列特性的基础上, 为了表示各数据点之间的相关性, 使用式(5)将极坐标变换为GASF谱图表示。
GASF谱图Gk中的每个元素取值为[-1, 1], 值越接近于1, 表示该像素点对应波长的折射率越高, 而越接近于-1, 则代表像素点对应波长的折射率越低, 绘制出二维谱图如图4(b)所示。 对于本研究中连续10天采集的光谱数据, 按照上述方法对波长进行优选后转换为GASF谱图, 那么每个样本则可以表示为具有10通道且大小为12× 12 的图像数据。 图5展示了染病植株随时间变化的二维谱图, 从图中可以发现染病植株的二维谱图随时间呈现出一定的特异性变化, 为后续早期红小豆锈病植株识别模型的建立提供了良好的数据支撑。
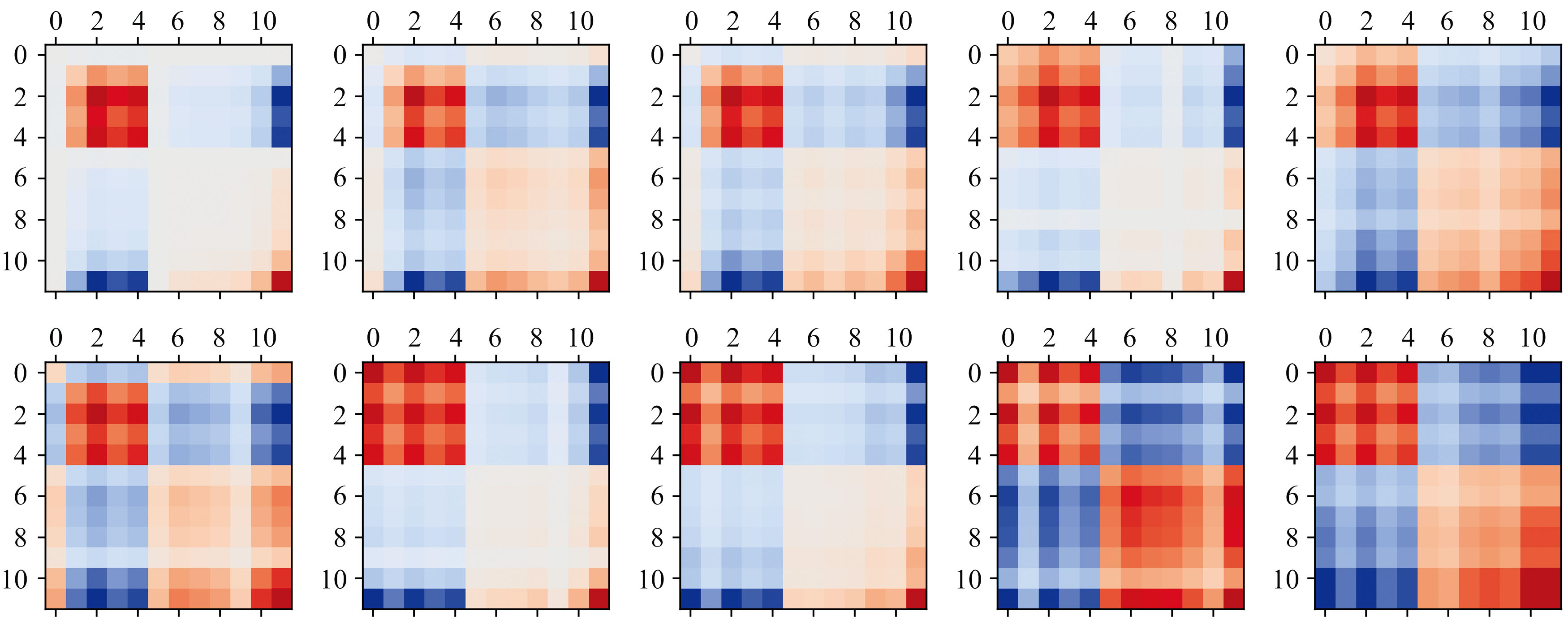 | 图5 染病植株随时间变化GASF谱图Fig.5 GASF spectra of infected plants changed with time |
卷积神经网络凭借其强大的特征提取和表达能力, 在计算机视觉任务中取得了很好的应用效果, 但传统的卷积神经网络模型对空间和通道维度信息分配相同权重, 没有对信息的重要性加以区分, 导致其容易遗漏关键性信息从而影响模型的预测能力。 因此, 本工作在传统多层卷积神经网络的基础上添加注意力机制, 使得模型更加关注引起光谱突变的特征波长以及时间节点, 从而达到早期识别感染锈病的红小豆植株样本的目的。
在传统卷积神经网络的基础上增加了CBAM模块, 具体模型结构如图6所示: 输入特征为预处理后尺寸为12× 12× 10的二维谱图, 首先采用16个3× 3的卷积核进行特征提取, 以降低参数, 增加特征表达层次, 再使用CBAM模块对通道及空间特征进行加权处理得到不同的空间语义算子并使用最大池化层以去除了无关信息的干扰, 从而使得模型更加关注光谱对数能量图的局部特征, 此时输出的特征图大小为6× 6× 16, 类似地, 再分别使用卷积层、 CBAM模块及最大池化层对上述的特征图进行处理, 最后经全连接层FC得到Softmax分类层的2个神经元, 对应本研究中红小豆样本是否感染锈病的预测结果。
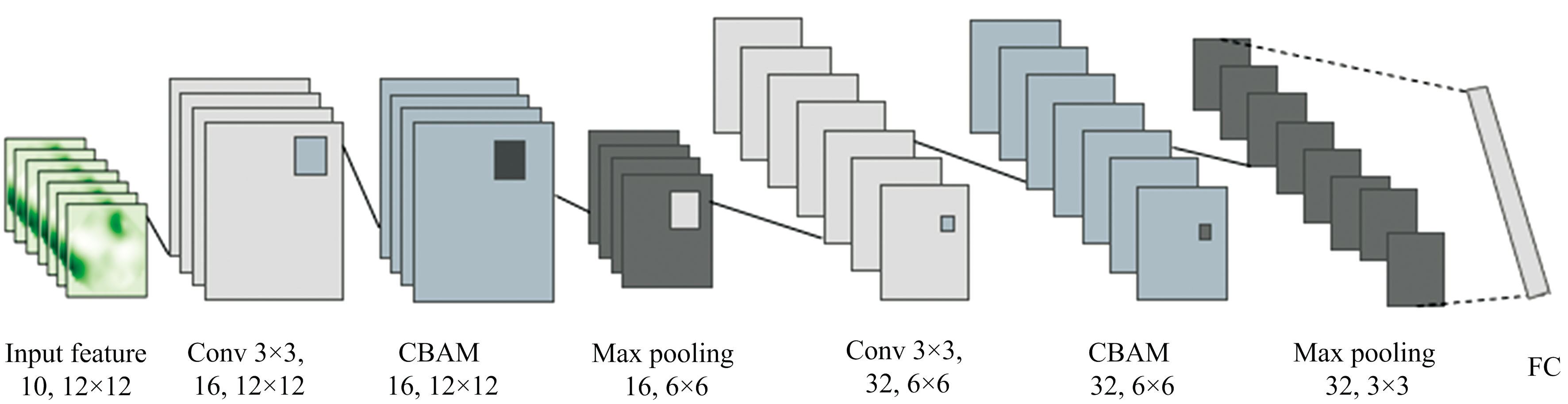 | 图6 网络结构图Fig.6 Network structure diagram |
基于开源深度学习框架PyTorch完成以CBAM-CNN模型为基础的红小豆锈病预测模型的构建。 计算机配置为Windows 11 64 bit操作系统, NVIDIA GeForce RTX 3060 Ti (12288MB); 软件环境为Anaconda3(64-bit), CUDA11.7, Python 3.9, PyTorch-GPU 2.0。 模型采用AdamW 优化器, 初始学习率0.001, 权重衰减0.000 1, 学习率衰减策略为每10轮乘以0.9。
共采集960例红小豆叶片光谱数据, 将染病植株视为正样本, 未染病植株视为负样本, 1和0分别作为正负样本的分类编码标签。 按照3:1的比例对数据集进行划分, 最终得到720组光谱数据作为训练集, 其中正样本270例, 负样本450例; 240组光谱数据作为测试集, 其中正样本90例, 负样本150例。
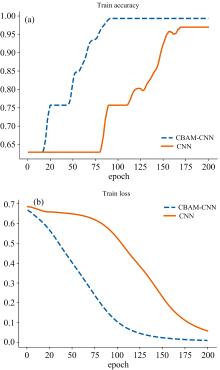
为检验CBAM模块的效果, 特进行消融实验, CBAM-CNN与CNN网络模型batch_size均取值为32, 训练次数为200, 采用ReLu激活函数并对数据进行批归一化处理。 最终训练集在CBAM-CNN模型以及传统CNN模型中的准确率分别为99.31%和96.53%, 损失值分别为0.009和0.056。 训练集在网络模型上训练200次的正确率及损失函数值的变化曲线图如图7所示。
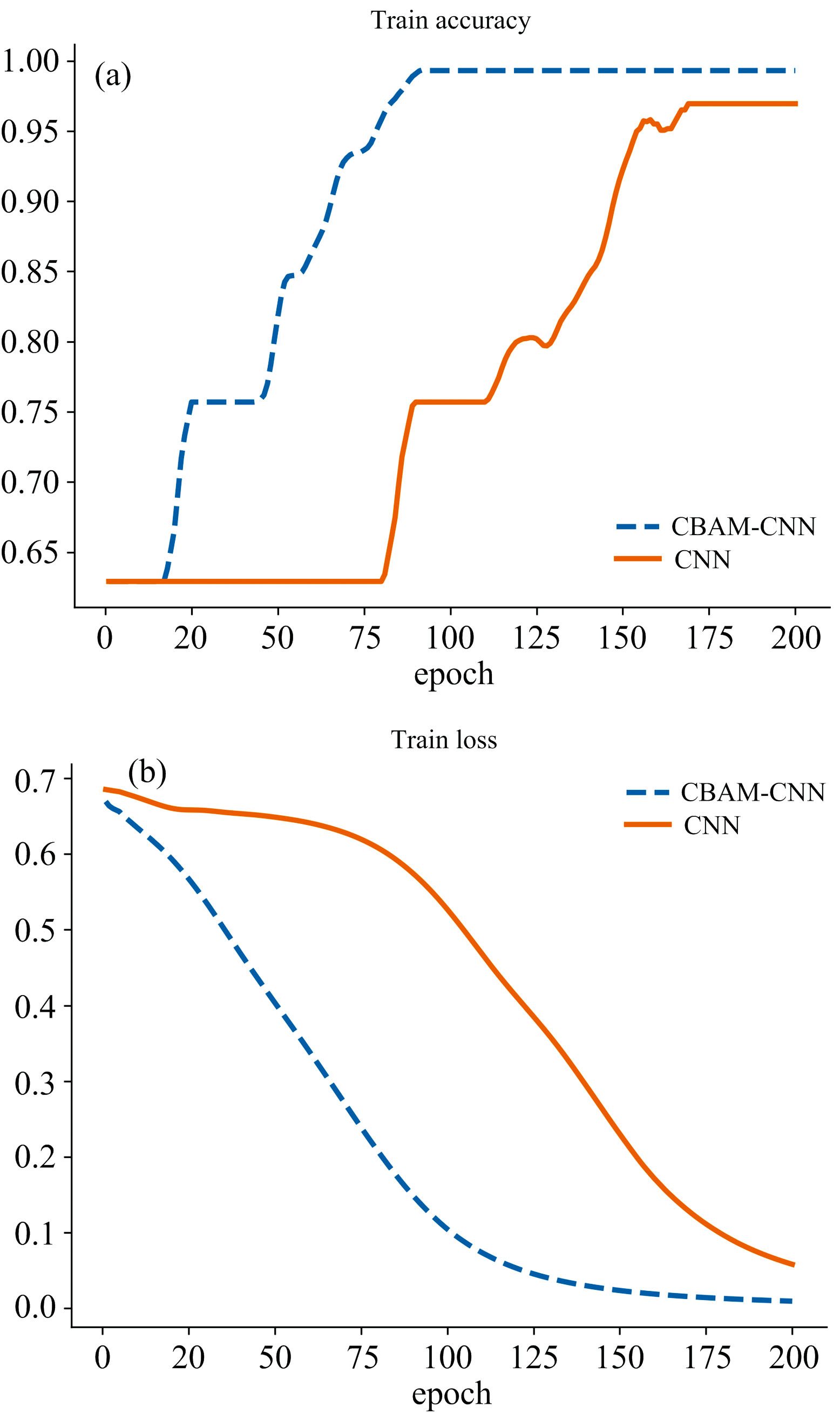 | 图7 训练集准确率和损失值变化曲线 (a): 训练集损失值; (b): 训练集准确率Fig.7 The accuracy and loss value change curves of the training set (a): Training set loss value; (b): Training set accuracy |
图7(a)中CBAM-CNN模型的准确率曲线变化范围为0.629 2~0.993 1, 变化幅度为0.363 9, 在迭代次数为18时开始收敛, CNN模型的准确率曲线变化范围为0.629 2~0.965 3, 变化幅度为0.336 1, 在迭代次数为80时开始收敛, 从2种模型在训练集上准确率的变化范围和收敛时的迭代次数来看, CBAM-CNN在训练集上的准确率收敛效果及收敛速度均明显优于CNN模型; 图7(b)中CBAM-CNN的损失值曲线变化范围为0.669 3~0.000 9, 变化幅度为0.668 4, 且迭代次数达130轮左右损失值便已稳定, CNN的损失值曲线变化范围为0.685 1~0.055 4, 变化幅度为0.629 7, 损失值在迭代次数为195轮左右时才趋于稳定。 综上所述, 相比于CNN模型, CBAM-CNN在训练集上的精确率、 损失值的收敛效果较好, 模型稳定性较高, 收敛速度更快。
通过图7中两种训练方式下训练集的效果进行对比分析, 加入注意力机制的CBAM-CNN可以更加高效地学习红小豆叶片病害区域特征, 更容易挖掘出引起光谱突变的特征波长和时间节点, 具有更好的特征学习能力和泛化能力。
为进一步评估上述模型的性能及分类能力, 将CBAM-CNN模型和CNN模型分别应用到测试集中, 两种模型的准确率分别为98.33%和95%。
从模型在测试集上的识别准确率分析, CBAM-CNN模型的对染病植株及未染病植株的识别准确率均高于CNN模型, 这是因为CBAM-CNN模型对输入特征的重要性加以区分, 使得网络减少了对区分病害种类无关区域的学习, 将更多的注意力作用于病害特征上, 可以更细致地提取病害特征, 提升卷积部分提取病害特征的能力。
| 表6 两种模型在测试集的表现 Table 6 Performances of two models on test sets |
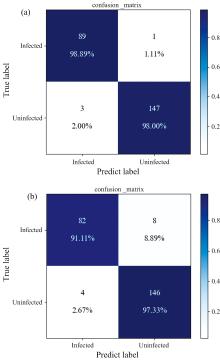
进一步使用混淆矩阵对2种网络模型在测试集上的表现进行对比, 统计结果如图8所示。
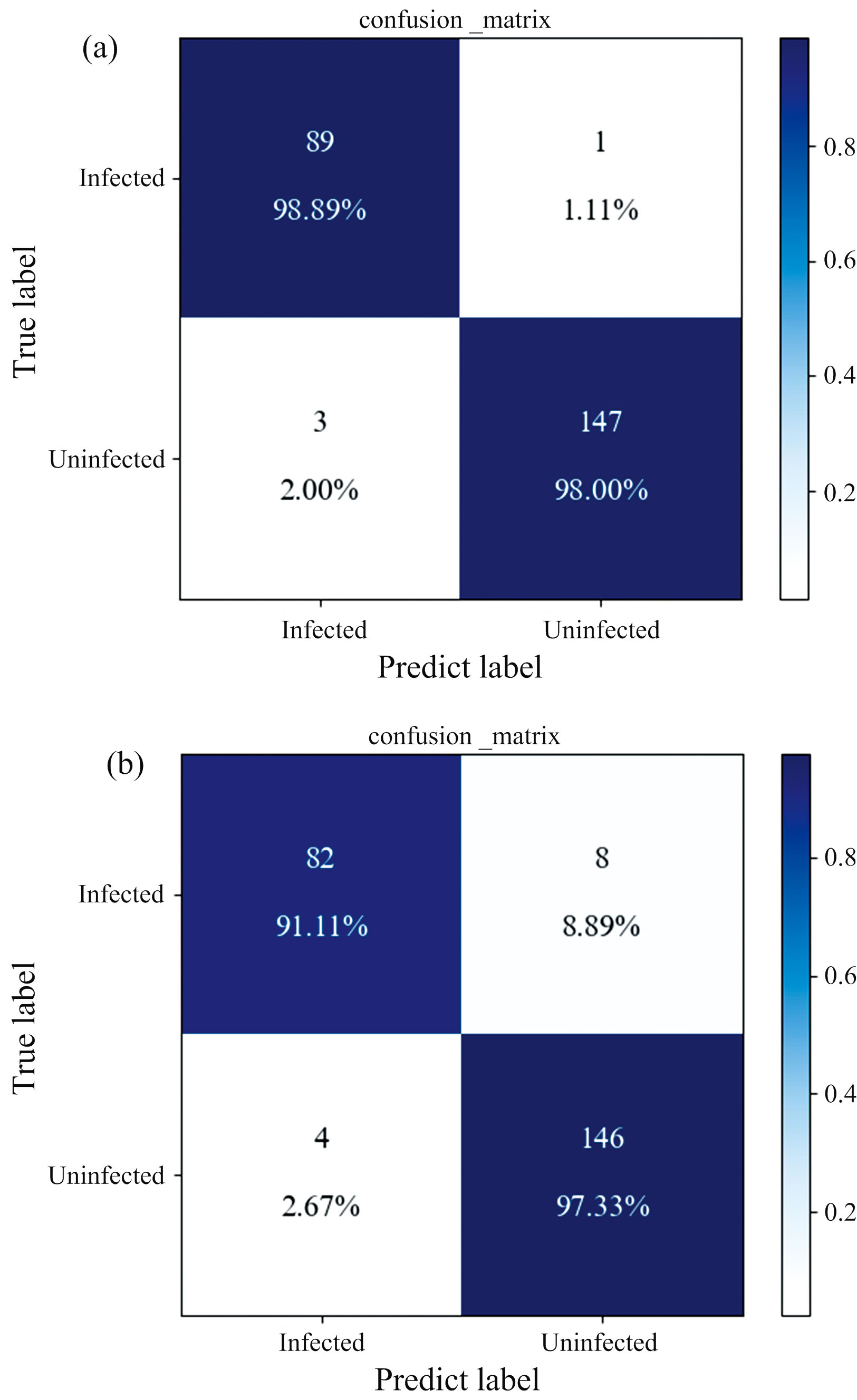 | 图8 CBAM-CNN (a)和CNN (b)模型的混淆矩阵Fig.8 Confusion matrices for CBAM-CNN model (a) and CNN model (b) |
图8混淆矩阵的结果表明, CBAM-CNN对染病样本和未染病样本的识别错误率分别为1.11%和2.00%, 相对于CNN模型的识别错误率分别降低了7.78%和0.67%, 说明CBAM-CNN模型在对两类样本的识别效果均优于CNN算法。
对于类别不均衡数据集, 准确率难以直接反映模型的预测性能。 本例中, 对于染病植株准确预测的重要程度要远高于未染病植株的准确预测, 因此增加精确率(Precision)、 召回率(Recall)和F1值作为评价指标。 分别计算CBAM- CNN和CNN模型的性能评价指标, 如表7所示。
| 表7 模型性能评价 Table 7 Model performance evaluation |
表7中列出了2种不同模型的对比结果。 相较于CNN模型, CBAM-CNN模型在精确率上提高了1.38%, 召回率提高了7.78%, F1的值也提高了0.046, 可见CBAM-CNN的3种性能评价指标均高于CNN网络, 尤其是召回率提升较多, 说明CBAM-CNN模型在注意力机制的作用下对染病样本的识别能力更强。
(1) 模型性能分析
提出了一种红小豆锈病快速无损识别方法, 仿真实验准确率达到98.33%, 召回率为98.89%, F1值达0.978, 在红小豆叶部锈病检测中取得了较好的效果。 与文献[15]使用的CARS+CNN模型相比, 本方法测试集对样本的识别准确率提升1.17%, 这是因为在建模之前, 本工作使用的光谱数据特征波长提取及序列变换方法增强了原始数据中有效信息的表达, 能够为后续模型的创建提供更加完备的数据基础。 与文献[16]使用的1D-CNN模型相比, 本文的CBAM-CNN模型精度提升了0.6%, 同时迭代轮次减少了82%, 这是因为CBAM模块使模型能够更加关注不同模态的重要信息, 增强对关键特征的表征能力和理解能力, 在保证模型性能的同时, 提高了建模效率。
(2) 局限性
该模型对于训练集和测试集数据的识别分别出现了5例和4例错误, 主要原因是部分样本在染病或者未染病的情况下未表现出明显的差异性, 其光谱曲线在549和757 nm特征波长处变异系数显著低于其他样本, 推测与病原菌侵染初期叶绿素降解不完全有关。 因此可以考虑在避免模型过拟合的前提下, 进一步改进基于注意力机制的网络学习算法, 并计划引入对抗训练机制增强模型对难例样本的鲁棒性。 除此之外, 数据预处理方法仍然需要进一步完善和改进, 在降噪环节, EMD分解方法可能在某些场景下会产生IMF分量模态混叠现象, 后续研究中考虑对EMD分解方法进行优化, 如使用EEMD、 CEMD、 RLMD等方法以解决模态混叠问题, 进一步提升去噪效果。 而在特征序列变换环节, 对于长时段的光谱序列, 可以考虑首先使用分段聚合近似的方法将序列进行压缩然后再进行向量变换处理, 以进一步提高算法的执行效率。
以红小豆叶片样本为实验对象, 对部分样本接种锈病病菌, 采集连续多日植株叶片光谱数据, 通过改进的E-DWT方法对光谱数据进行降噪处理, 对比分析了PCA和SPA方法对特征波长优选的性能指标, 最终选择SPA方法优选出12个有效波长, 为增加波长序列之间的相关性, 引入格拉姆角场法构建多通道GASF谱图, 最后建立CBAM-CNN网络模型, 实现了红小豆锈病识别准确、 快速、 高效的自动检测, 模型结构简单且自适应能力强有利于其实际应用和推广。
对于不同植物和病害种类, 可利用该模型所具有的强自动学习特性, 重新构建特定病种和植物的专用模型。 未来工作以本研究内容为基础, 增加研究的物种和病种, 面向复杂背景下的多种病害, 拓展本方法对植物病害检测范畴, 进一步利用深度学习模型的自适应性和植保专家先验知识相结合为红小豆栽培与精细管理提供可靠依据, 为农作物病害表型大数据的智能挖掘和解析提供理论基础和技术支撑。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|