
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向可见光谱图像的跨模态双通道伪装目标检测方法
[程玉虎 , 吴世佳, 王浩宇, 王雪松
, 吴世佳, 王浩宇, 王雪松* ]
, 吴世佳, 王浩宇, 王雪松]
|
|


作者简介: 程玉虎, 1973年生,中国矿业大学信息与控制工程学院教授 e-mail: chengyuhu@163.com
面向可见光谱图像的伪装目标检测任务旨在利用可见光谱信息检测和周围环境具有视觉一致性的伪装目标。 这种视觉一致性导致的目标边界区分难和辨识性特征学习难等问题, 限制了现有目标检测方法在伪装目标检测任务中的有效性。 为此, 本文提出一种跨模态动态协同双通道网络(CDCDN), 探索了全局-局部多层次视觉感知和视觉-语言模型(VLM)在伪装目标检测中的应用潜力。 具体而言, 首先, 针对目标边界区分难, 设计了动态协同双通道模块, 通过双通道将检测过程解耦为全局信息定位和局部特征细化, 从多层次的视觉角度进行针对性的检测和优化。 在此基础上构建了动态信息协同及融合机制, 通过全局门控约束与局部感知校正实现了全局与局部信息的相互补充和校正, 从而增强了目标检测模型在目标边界模糊场景中的空间捕获能力。 其次, 针对辨识性特征学习难, 设计了跨模态场景对象匹配模块, 通过引入VLM来建立视觉和语言模态的跨模态交互, 增强了目标与背景在特征空间中的差异性, 从而提升了目标检测模型在缺乏辨识性特征场景中的语义区分能力。 在MHCD2022和COD10K两个数据集上分别评估了mAP@0.5、 mAP@0.5:0.95和mAP@0.75指标。 CDCDN在MHCD2022数据集上分别达到67.6%、 42.6%和48.4%, 在COD10K数据集上分别达到67.9%、 40.6%和41.0%。 与五种主流的目标检测方法Faster R-CNN、 DETR、 Lite-DETR、 YOLOv5、 YOLOv10相比, CDCDN在三个指标上均取得了最优的检测精度。 荒地、 草地、 树林和雪地四种常见伪装场景的可视化检测结果进一步验证了CDCDN具有良好的场景适应性。 在消融实验中, 逐步消融CDCDN中的关键组件, 以系统地评估其贡献, 结果显示各个关键组件都有助于模型检测性能的提升。 综合实验结果表明, CDCDN可准确检测和周围环境具有高度视觉一致性的伪装目标, 为伪装目标检测提供了一种新的解决方案。
The camouflaged object detection (COD) task for visible-spectrum images aims to utilize visible-spectrum information to detect camouflaged objects that are visually consistent with their surrounding environment. This visual consistency poses challenges such as difficulty in distinguishing object boundaries and learning discriminative features, which limit the effectiveness of existing object detection methods for COD. A Cross-modal Dynamic Collaborative Dual-channel Network (CDCDN) is proposed to explore the potential of global-local multi-level visual perception and visual-language models in COD. First, to address the challenge of distinguishing object boundaries, a dynamic, collaborative, dual-channel module is designed. Through the dual channels, the detection process is decoupled into global information localizationand local feature refinement, enabling object detection and optimization from a multi-level visual perspective. A dynamic information collaboration and fusion mechanism is established, through which global and local information are mutually complemented and corrected by global gating constraints and local perception correction. The spatial capture capability of the model is enhanced in scenarios with blurred object boundaries. To address the difficulty in learning discriminative features, a cross-modal scene-object matching module is designed. By incorporating a pre-trained VLM, this module establishes cross-modal interactions between the visual and language modalities, thereby enhancing the distinction between objects and backgrounds in the feature space and improving the model's semantic discrimination in scenes with limited discriminative features. CDCDN is evaluated on the MHCD2022 and COD10K datasets using the mAP@0.5, mAP@0.5:0.95, and mAP@0.75 metrics. CDCDN achieves scores of 67.6%, 42.6%, 48.4% on the MHCD2022 dataset, and 67.9%, 40.6%, 41.0% on the COD10K dataset, respectively. Compared to five mainstream object detection methods, including Faster R-CNN, DETR, Lite-DETR, YOLOv5, and YOLOv10, CDCDN achieves the best detection accuracy across all three metrics.Visualization of detection results in four common camouflaged scenes -barren land, grassland, woodland, and snowfield -demonstrates the adaptability of CDCDN to various scenes. In an ablation study, the key components of CDCDN are incrementally removed to systematically evaluate their contributions, with results showing that each component significantly enhances the model's detection performance. Comprehensive experimental results indicate that CDCDN can accurately detect camouflaged objects with high visual consistency to their surroundings, providing a novel solution for COD.
随着现代科技的飞速发展, 复杂环境下伪装目标检测的重要性日益凸显[1]。 在自然场景中, 目标通过运用自然或人工材料, 使其视觉特征与周边环境高度融合[2], 例如变色的动物和身穿迷彩服的人员。 这种融合导致目标在可见光谱图像中与背景几乎无法区分, 大大增加了常规光学侦察设备的识别难度[3]。 因此, 要实现在复杂背景下基于可见光谱信息精准识别伪装目标, 发展伪装目标检测技术就显得尤为关键[4]。
现有伪装目标检测方法通常对伪装目标进行像素级检测[5, 6, 7]。 Cong等[8]引入频率感知网络, 通过频域内的差异检测伪装目标。 Khan等[9]通过特征分离和调制模块区分前景和背景特征, 并使用上下文精炼模块增强了不同空间尺度上的特征表示。 像素级检测方法可以精确反映目标的形态轮廓信息[10], 但往往伴随较高的计算代价和内存开销, 限制了其在低资源设备上的部署和应用。 为解决该问题, 一个直观的解决方案是对伪装目标进行目标级检测。 现有的目标级检测的方法主要划分为两类: 基于锚点的检测器和无锚点的检测器。 前者分为以YOLO系列[11]为代表的单阶段检测器和以Faster R-CNN[12]为代表的多阶段检测器。 后者摒弃了锚点框的设计, 直接预测目标的位置和形状, 例如CornerNet[13]和DETR[14]。 然而, 传统的目标检测方法大多是为非伪装场景设计的[15], 其有效性高度依赖于目标和周围环境的可区分性。 需要指出的是, 在伪装目标检测任务中, 由于伪装目标和环境在纹理、 颜色上的高度视觉一致性使得传统的目标检测方法面临了以下挑战: 目标边界区分难和辨识性特征学习难。 这些挑战限制了现有方法在复杂伪装场景中的有效性。
具体而言, 首先, 导致目标边界区分难的主要原因是伪装目标与背景在视觉上的高度相似。 目标通常通过与背景相似的纹理、 颜色、 形状等视觉元素进行伪装, 例如, 章鱼会通过改变皮肤的纹理与周围的环境融合, 目标的边界在视觉上几乎“ 消失” 。 在现有方法中, 目标的边界信息通常是基于图像中的梯度变化或显著区域提取的。 但是, 伪装目标由于与背景的一致性, 导致这种梯度变化变得模糊甚至不存在。 以基于传统卷积神经网络的目标检测为例, 尽管其在提取局部特征上具有一定的优势, 但在伪装场景中, 局部特征往往不足以提供足够的空间信息来精确区分目标与背景。 其次, 辨识性特征学习难主要体现在伪装目标的语义属性上。 伪装通过改变目标的外观, 使其与周围环境的语义内容高度一致, 这使得传统的基于显著特征的学习方法难以有效提取具有辨识度的特征。 例如, 伪装的变色龙与周围的树叶相似, 语义上都表现为“ 植物” , 伪装士兵的服装和周围的植物在语义上都表达为“ 自然环境” 。 这使得模型在进行语义理解时将其视为背景而非目标, 导致了即使目标与背景有细微差异, 也容易被模型忽略或误判。
针对目标边界区分难, 本文提出了动态协同双通道模块。 通过双通道解耦全局与局部信息, 从多层次视觉角度对伪装目标进行针对性检测。 全局通道通过多头注意力识别宏观位置, 局部通道利用多尺度卷积提取边缘轮廓。 同时提出了动态信息协同及融合机制, 融入到全局通道和局部通道, 从而实现全局特征与局部特征动态地相互补充和校正。 最后进行通道融合, 通过全局上下文信息和局部细节的结合, 提升对目标轮廓的辨识精度。 针对辨识性特征学习难, 设计了跨模态场景对象匹配模块。 通过使用预训练的视觉-语言模型(vision language model, VLM), 结合文本描述生成文本特征并利用跨模态匹配交互, 将场景和对象更丰富的语义信息引入视觉特征中, 从而有效增强目标与背景在特征空间中的差异性。
综上所述, 工作可总结为:
(1)提出了跨模态动态协同双通道网络。 将全局-局部多层次视觉感知和VLM引入到伪装目标检测中, 通过解耦动态协同和跨模态交互, 增强了模型对复杂环境中伪装目标的识别能力。
(2)提出了动态协同双通道模块。 通过将检测任务解耦为全局信息定位和局部特征细化, 结合动态信息协同与融合机制, 实现了全局与局部信息的有效配合, 从而增强了模型在伪装目标场景中的空间捕获能力与细节识别能力。
(3)提出了跨模态场景对象匹配模块。 通过将场景和目标以文本描述的形式进行建模, 并融合视觉与文本的跨模态信息, 充分利用语义信息进行目标与环境的匹配, 使得伪装目标在场景中的辨识度得到显著提升。
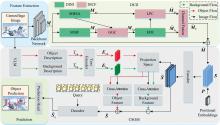
图1给出了跨模态动态协同双通道网络(cross-modal dynamic collaborative dual-channel network, CDCDN)的结构框图, 主要包括: 主干网络、 动态协同双通道模块(dynamic collaborative dual-channel module, DCD)、 跨模态场景对象匹配模块(cross-modal scene object matching module, CSOM)、 预测头四个关键组件。 结合图1, 接下来详细阐述CDCDN的工作流程。
 | 图1 CDCDN框架图Fig.1 Framework of CDCDN |
首先, 将伪装图像输入到主干网络中进行特征提取, 得到伪装图像的多尺度特征图。
接着, 将多尺度特征图输入到动态协同双通道模块。 动态协同双通道模块分为双通道解耦检测(dual-channel decoupling detection, DDD)和动态信息协同及融合(dynamic information collaboration and fusion, DICF)。 DDD中全局通道主要包括多头自注意力(multi-head self-attention, MHSA)、 局部通道包括多尺度信息融合(multi-scale information fusion, MSIF)和边缘特征细化(edge feature refinement, EFR), 通过DDD将特征图解耦成全局信息定位和局部特征细化。 引入DICF, 通过全局门控约束(global gating constraint, GGC)以及局部感知校正(local perception correction, LPC)对全局通道和局部通道进行动态信息协同, 之后进行通道融合(channel fusion), 得到融合特征并和特征图进行残差连接, 获得最终的增强特征图。
然后, 将增强特征图和伪装图像输入给跨模态场景对象匹配模块。 将增强特征图转化成特征序列, 并注入位置编码输入编码器中, 得到特征增强序列。 同时, 利用VLM分别得到关于伪装图像的背景描述和目标描述, 再通过文字编码之后得到对应的文字特征。 将特征增强序列和文字特征输入到投影空间, 再分别进行跨模态匹配交互, 得到跨模态特征序列。 将跨模态特征序列得到的查询和跨模态特征序列输入解码器得到最终的跨模态查询序列。
最后, 将跨模态查询序列输入预测头, 获得目标的位置预测和类别预测, 完成伪装目标检测任务。
伪装目标检测中的核心挑战在于目标与背景在视觉特征上的高度一致性。 为应对这一挑战, 提出了双通道解耦检测。 各尺度特征图分别进入全局信息定位通道和局部边缘细化通道, 核心目标是将伪装目标的检测过程解耦为全局信息定位和局部特征细化, 从多层次的视觉角度对伪装目标进行针对性的检测和优化。
在伪装目标检测中, 伪装目标往往与背景具有高度的视觉相似性, 因此仅依靠局部特征很难有效区分目标与背景。 全局信息定位通道通过引入多头自注意力机制来捕捉伪装目标与环境之间的宏观特征, 从而增强模型对全局上下文的理解。 将图像输入主干网络, 得到特征图M∈ Rc× h× w, 其中: c表示通道数量, h和w分别表示特征图的长和宽。 具体见图2, 全局中心检测通道主要通过以下几个步骤进行:
输入M并将其展平成二维序列并进行转置, 再对特征图应用层归一化, 用于注意力机制计算
式(1)中, RS(· )表示重塑, PM(· )表示转置, LN(· )表示层标准化。
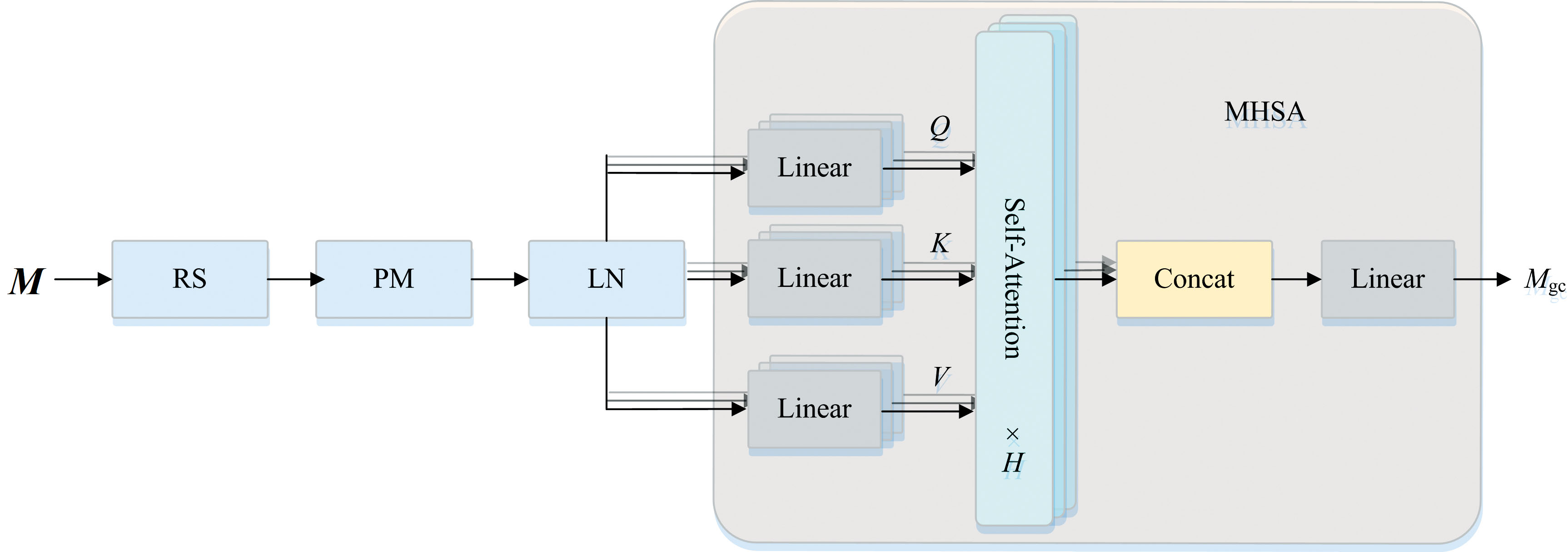 | 图2 全局信息定位通道Fig.2 Global information localization channel |
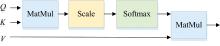
分别输入到MHSA中, 通过图3多个独立的自注意力头并行执行计算每个输入位置与其他所有输入位置之间的相似度。 最后, 将所有头的输出进行拼接, 得到全局输出特征Mgc
式(2)中, Wq, Wk, Wv∈
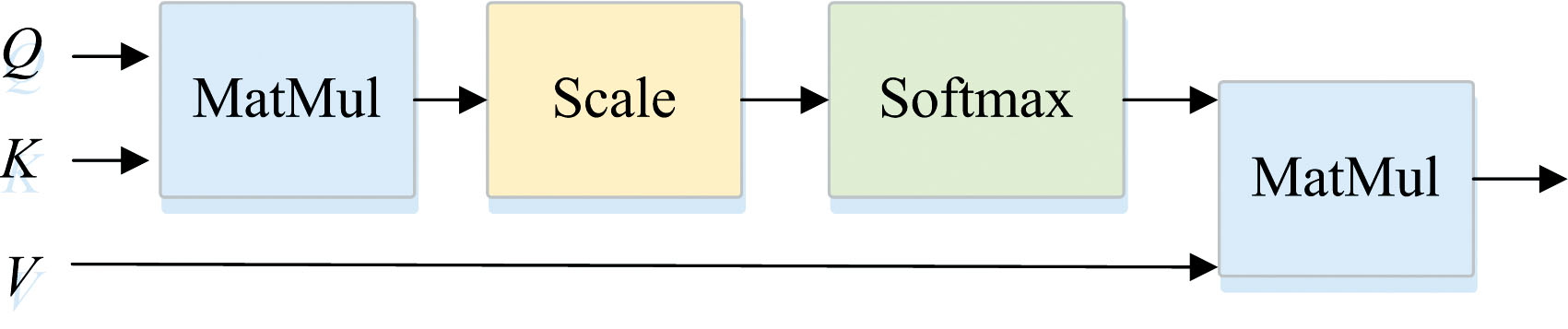 | 图3 自注意力头Fig.3 Self-attention head |
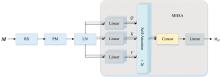
局部边缘检测通道通过MSIF模块和EFR模块细化伪装目标的边缘特征, 提升模型的细粒度感知能力, 见图4。
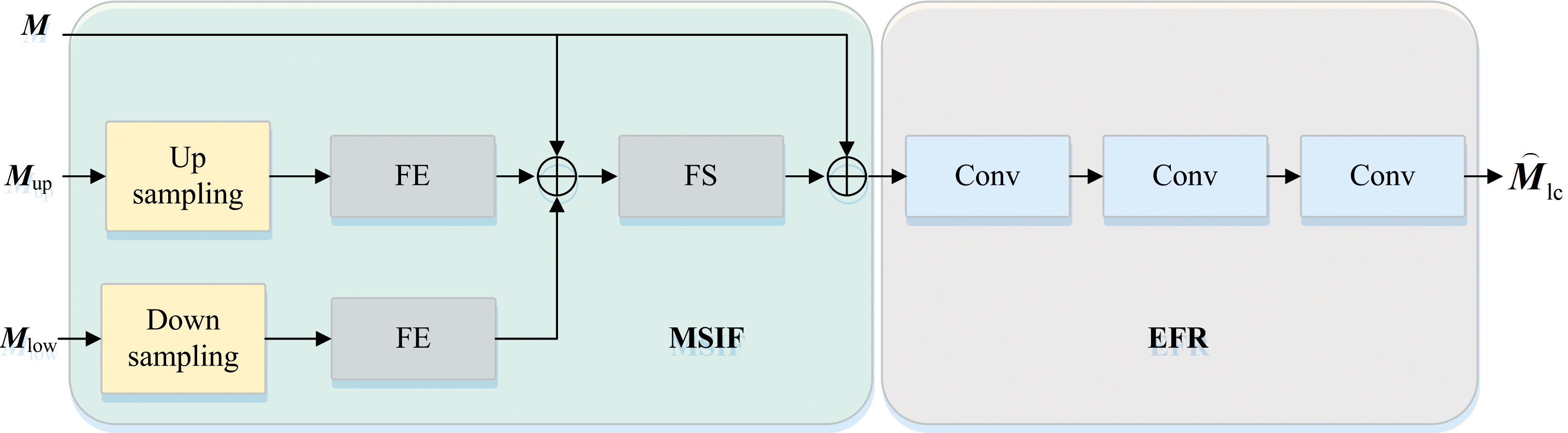 | 图4 局部边缘检测通道Fig.4 Local edge detection channel |
具体来说, 将当前尺度的特征M和上下尺度的特征Mup、 Mlow同时输入MSIF模块中进行插值, 以对齐其空间分辨率。 若输入来自高尺度特征图Mup, 通过双线性插值将其上采样至与中间尺度特征M的分辨率一致, 得到
每个尺度的特征进入特征增强模块FE(· ), 特征增强模块由卷积、 归一化和激活函数组成, 能够有效提取和细化目标的边缘和纹理信息
将所有尺度的特征与中间尺度特征M进行融合, 得到初步的融合特征
式(4)中, FS(· )表示多尺度融合操作。 进一步, 将融合特征与中间尺度的特征再次进行残差连接, 以增强特征表示能力, 得到局部通道特征Mlc。
输入到EFR模块, 得到最终的边缘细化特征
式(5)中, EFR(· )包含三层3× 3的卷积。 通过多层卷积, 逐步增强输入特征中的边缘信息, 提取目标物体的边界细节, 提升目标检测的细粒度感知能力。
如果对目标与背景使用不同的处理方式, 会引发全局与局部特征之间的“ 特征分歧” 。 全局特征和局部特征在捕捉目标时存在层次差异, 全局特征关注整体形状和背景, 局部特征关注边缘、 纹理等细节。 直接融合可能导致全局特征掩盖局部细节, 而局部特征因缺乏上下文而难以定位目标。 为此, 设计了一种动态信息协同机制, 用于对全局通道与局部通道的特征进行互补与增强, 并在得到解耦的特征之后进行通道信息融合。
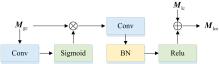
动态信息协同主要包括GGC与LPC。 当获取到Mgc时, 先通过GGC进行控制, 再进行后续操作, 见图5。
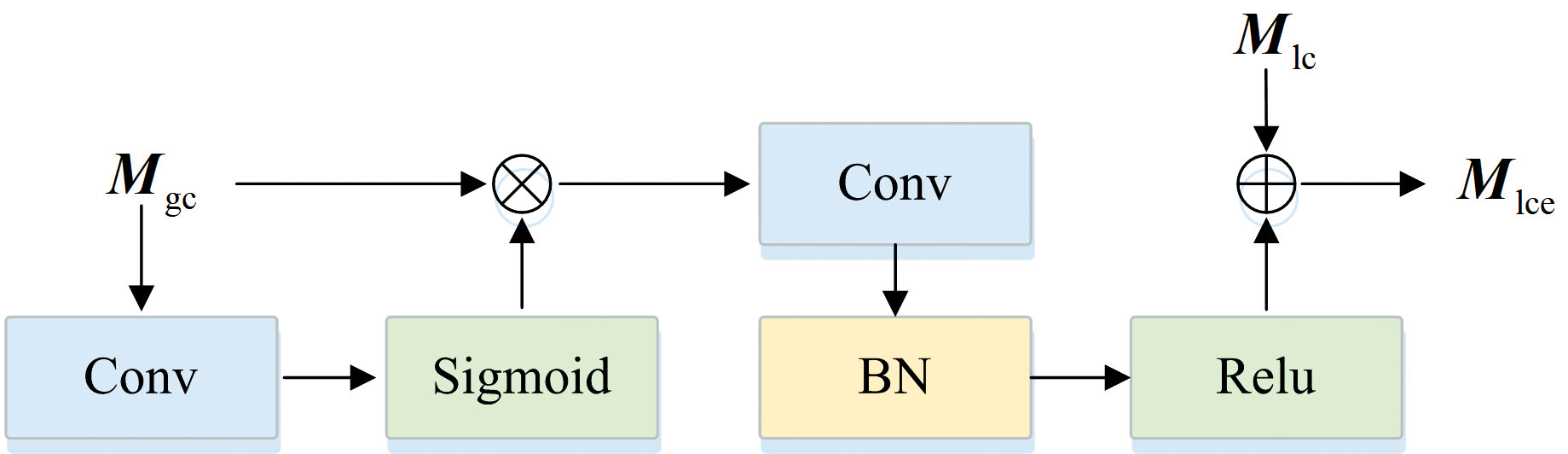 | 图5 全局门控约束Fig.5 Global gating constraint |
这种门控机制是基于一个由全局门控网络产生的权重矩阵来实现的。 这个权重矩阵的作用是动态调整全局特征对局部特征的作用程度, 从而使得全局特征经过门控处理后能够更加适应局部特征的需求, 具体如式(6)
式(6)中, σ表示Sigmoid激活函数, * 表示卷积操作, Wgate为门控卷积核, ☉表示逐元素乘积操作。 接下来, 将门控后的全局特征通过操作CG(· )进行增强, 具体操作包括卷积、 归一化和Relu函数激活, 之后与局部特征Mlc相加, 得到增强的局部特征
这样可以避免全局信息对细节特征的过度干扰, 同时保证全局信息能够为局部特征提供必要的上下文支持。
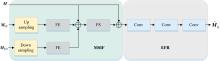
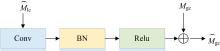
当得到Mlce后, 继续进行局部通道的后续处理。 将得到的
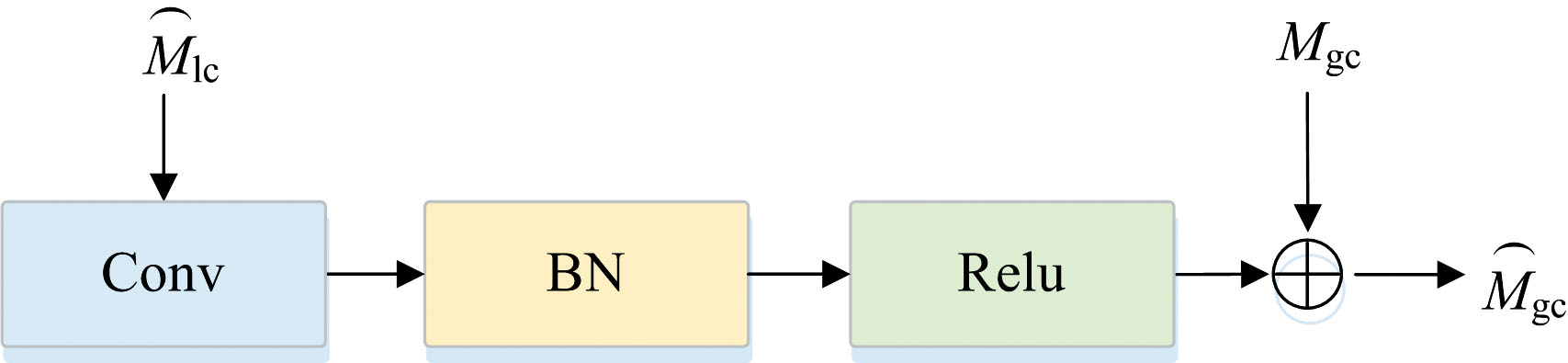 | 图6 局部感知校正Fig.6 Local perception correction |
局部校正信号CL(
通过卷积和批归一化等操作, 调整全局特征以更准确地反映局部信息, 从而提高特征表达的一致性。
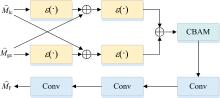
在得到双通道解耦的特征后, 为了匹配双通道特征, 进行动态通道融合, 见图7。
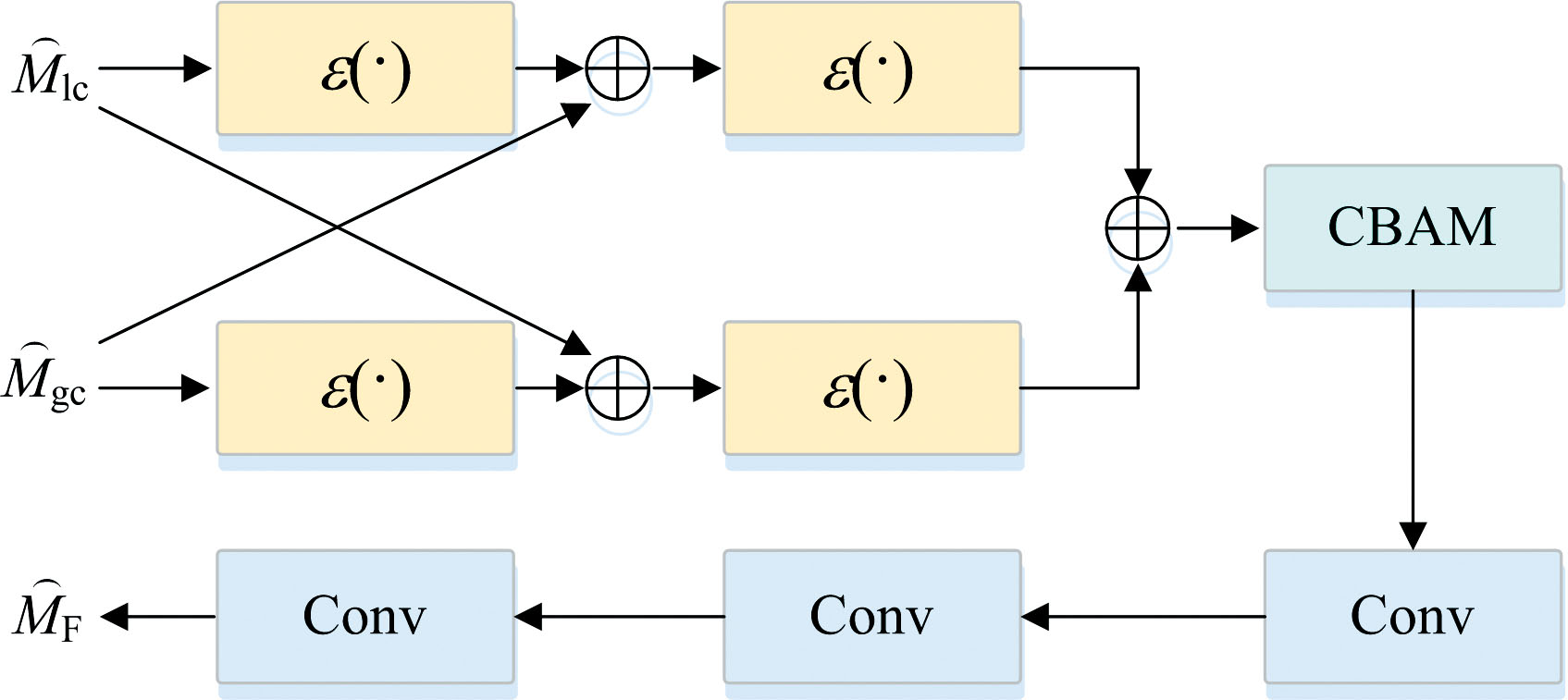 | 图7 通道融合Fig.7 Channel fusion |
对于解耦得到的
式(9)中, ε(· )表示适应性增强模块, 强化关键区域的表达。 将
融合后的特征图经过三层连续的卷积操作C1(· )、 C2(· )、 C3(· )提取更深层次的融合特征
在通道融合完成后, 和输入的特征图M进行残差连接, 最终输出用于后续伪装目标检测的增强特征图
为打破伪装目标与背景的语义相似性, 仅依赖图像特征难以提供足够的语义信息来分离二者。 为此提出了跨模态场景对象匹配, 利用VLM通过预训练生成的文本特征, 引入更具语义深度的信息来打破视觉上的局限。 具体操作如下:
为了捕获图像特征的空间依赖关系, 将
与此同时, 针对伪装图像I, 将I输入到VLM中获取目标和背景对应的文本描述
VLM采用BLIP2 (bootstrapping language-image pre-training)[17]来生成图像中背景与目标的语义描述。 对于背景描述, 输入图像并配以查询语句Tqb“ What is the environment in the picture?” , 对于目标描述, 则输入特定提示Tqo“ What is the camouflaged object in the picture?” 以引导模型聚焦于潜在目标区域。 VLM的流程为
图像I首先通过冻结的ViT编码器提取视觉特征, 并与可学习的查询Qs进行交叉注意力计算。 随后将得到的视觉特征与经过BERT编码过后的查询语句进行向量拼接, 并通过自注意力机制进一步融合。 接着融合特征与线性投影权重Wp相乘分别得到联合特征Zbg、 Zob。 然后将联合特征输入到语言模型的L层解码器中。 为更清晰描述, 下面仅使用Zbg作为数据输入
式(15)中, CATT(· )为因果自注意力, FFN(· )为前馈网络,
式(16)中, Wz为一个将隐藏状态映射到词表空间的输出权重矩阵, bz为偏置项, |D|为词表大小。 对P中前k个词的概率进行归一化, 根据结果筛选出生成词wt。 重复上述过程直到生成终止符, 得到最终的背景文本描述Tbg。 Zob也通过相同过程得到目标文本描述Tob。
通过文本编码器TE(· )分别生成背景文字特征Ebg和目标文字特征Eob, 即
为减少模态间差异, 将特征增强序列
将投影后的图像特征序列分别与背景和目标文字特征通过交叉注意力机制进行场景对象匹配得到背景特征
最后, 将
通过将场景和对象的语义描述与视觉特征结合, 能够更好地捕捉目标和背景的潜在差异, 增强伪装目标的可分性。 这一跨模态方法不仅使伪装目标更加凸显, 还通过整合更为精准的语言语义, 重新定义了伪装检测的维度, 从而有效解决视觉特征相似性导致的检测瓶颈。
该部分旨在对跨模态查询序列进行目标的类别预测和位置预测, 并通过精细化的预测和优化策略, 增强模型在复杂场景下对目标检测和识别的性能。
具体而言, 将跨模态查询序列
式(21)中, Lcls(
实验使用了两个公开的可见光伪装目标检测数据集:
MHCD2022数据集[15]包含3000张可见光谱图像, 涵盖人(Person)、 坦克(Tank)、 飞机(Aeroplane)、 军用车辆(Military Vehicle)和军舰(Warship)五个目标类别。 这些图像来自多个真实世界场景, 包含丛林、 沙漠、 雪地、 城镇和海洋等多种场景。 MHCD2022数据集旨在识别在复杂背景中肉眼难以察觉的可见光伪装对象。 在实验过程中, 选取了2 400 张图像作为训练样本, 另外600张用于测试。
COD10K数据集[5]包含10000张可见光谱图像, 拥有78种类别的数据, 涵盖了多种自然环境下的伪装目标, 目标包括水生、 飞行、 两栖和陆生动物, 环境包括森林、 雪地、 草原、 天空、 海水等。 在实验中, 筛选出COD10K数据集中5 066 张包含伪装物的图片作为训练和测试数据, 按照3 040张训练样本和2 026张测试样本的比例进行划分。
在模型的数据预处理阶段, 实施了多种数据增强策略, 包括图像反转、 随机旋转、 随机裁剪以及随机调整图片大小, 使模型能够学习到更加泛化的特征表示。 实验硬件配置为3.80 GHz的英特尔酷睿i7-12700KF处理器、 64 GB内存和RTX 2080Ti GPU。 软件环境基于PyTorch深度学习框架搭建, 网络架构采用ImageNet预训练的ResNet-50作为骨干网络。 训练过程设置为100个epoch, 使用AdamW优化器进行参数优化, 学习率设置为0.000 1。 模型性能评估遵循COCO标准, 主要计算mAP@0.5、 mAP@0.5:0.95和mAP@0.75三个关键性能指标。
在MHCD2022数据集上对CDCDN涉及的多个关键参数进行了实验, 主要包括: 注意力头数(Heads), 编码器层数(EN), 解码器层数(DN), 以及权重因子λ1、 λ2和λ3, 实验结果见表1。
| 表1 关键参数性能影响 Table 1 Impact of key performance parameters |
对于Heads, 当采用4头注意力时, 模型的mAP@0.5为62.4%, 这表明较少的注意力头较难充分捕捉伪装目标的多维度特征。 将头数增加到8个时, 性能提升至67.6%, 此时模型能有效综合全局及局部信息。 然而, 当增加到16头时, 性能反而下降至62.0%, 这是由于过量的注意力头引入了过多的噪声交互, 反而降低了特征的判别性[18]。
对于EN和DN层数, 5层结构的mAP@0.5仅为51.1%, 较浅的网络不能充分学习伪装目标与复杂背景之间的特征关系。 当层数增加到6层时, 性能得到较好的提升, 此深度能够有效建模多尺度特征和长程依赖关系[14]。 然而, 7层结构的性能下降至55.6%, 这是由于网络过深导致引入了过多的冗余信息。
对于权重因子, 当边界框损失权重为5、 分类损失和GIoU损失的权重为2时能够平衡分类和回归任务, 此时mAP@0.5达到最高。 当边界框权重过高时, 模型过度关注位置优化而忽视语义特征, 例如(1, 7, 3)组合性能降至56.6%。 多个权重组合都能达到65%左右的性能, 说明模型对权重配置有一定鲁棒性。 但是, 只有(2, 5, 2)组合能突破67%, 表明该配置更适合协调伪装检测中分类和定位的联合优化。
将CDCDN和Faster R-CNN[12]、 DETR[14]、 Lite-DETR[19]、 YOLOv5[20]、 YOLOv10[21]作比较。 实验结果如表2所示。
| 表2 MHCD2022和COD10K数据集上的检测性能 Table 2 Detection performances on the MHCD2022 and COD10K datasets |
CDCDN在三个评估指标上均优于其他对比方法。 在精度指标mAP@0.5上, 较最新的YOLOv10和Lite-DETR也有一定的优势。 这一结果表明, CDCDN通过引入跨模态语义信息能够更好地帮助模型区分伪装目标与背景, 提升检测的整体准确率。 在精度指标mAP@0.5:0.95上, CDCDN在两个数据集上相比于Faster R-CNN、 DETR和YOLOv5等经典检测器都有较好提升, 表明在处理复杂伪装目标检测任务时, CDCDN较传统目标检测能够有效分离全局和局部特征。 并通过动态信息协同确保全局和局部特征之间的有效交互, 减少了信息干扰。 CDCDN在mAP@0.75精度上的表现也较为出色。 这说明CDCDN不仅能够检测到伪装目标, 还能够在目标边界精细化上表现出色, 特别是在高精度要求的场景下仍能准确检测目标并进行定位。
取数据集中出现频率最高的四种场景进行比较展示, 如图8所示。 在四种场景中人员都穿着与环境具有较高相似度的作战服, 导致对目标的检测变得困难。 在荒地场景中, Faster R-CNN、 Lite-DETR、 YOLOv5和CDCDN模型能够识别伪装目标的大致位置。 与标签标注图相比, CDCDN在定位和置信度方面表现最佳, 且定位误差最小。 对于草地场景, 六种模型均能检测出伪装目标的大致位置, 但除了Lite-DETR和CDCDN外, 其他模型均存在较大误差或误检的情况。 在树林场景中, CDCDN相较于其他模型定位较好, 置信度较高。 在雪地场景中, YOLOv5和v10未能检测到伪装目标, 而Faster R-CNN和DETR则出现了较多的误检, Lite-DETR也存在漏检的情况, 而CDCDN能够较好地检测到伪装目标。
 | 图8 不同方法检测结果对比 (a): Faster R-CNN; (b): DETR; (c): Lite-DETR; (d): YOLOv5; (e): YOLOv10; (f): CDCDN; (g): 真实图Fig.8 Comparison of detection results of different methods (a): Faster R-CNN; (b): DETR; (c): Lite-DETR; (d): YOLOv5; (e): YOLOv10; (f): CDCDN; (g): Ground truth |
为评估模型在实际应用中的性能表现, CDCDN及对比模型的计算效率分析结果如表3所示。 CDCDN的模型参数量为57.1 M, FLOPs为168.7 G, 这些指标在对比模型中处于中等水平。 在推理速度方面, CDCDN达到22.8 FPS, 能够满足日常应用需求, 但与主流实时检测器YOLOv5和YOLOv10相比仍存在差距。 经分析, CDCDN的计算效率瓶颈主要集中于跨模态场景对象匹配模块。 具体而言, 该模块需要通过VLM对输入图像进行编码和解码并生成背景及目标的文本描述, 同时执行视觉-文本特征的交叉注意力匹配机制。 这些处理步骤增加了计算开销, 从而影响了模型的整体推理速度。
| 表3 模型参数量、 FLOPs及推理速度 Table 3 Parameters, FLOPs, FPS of models |
针对模型当前的性能瓶颈, 提出后续的优化策略:
(1)文本特征预存机制。 当前模型的CSOM依赖实时文本生成, 导致额外的计算负担。 为解决这一问题, 拟建立高频场景文本描述及特征预存系统, 将动态生成过程转化为高效的检索匹配任务。 在训练阶段构建场景文本特征库, 预先计算并存储文本特征嵌入; 在推理阶段, 模型只需提取输入图像的视觉特征, 即可通过特征库检索快速获取匹配结果。
(2)模型蒸馏优化。 考虑到当前CSOM模块依赖VLM, 推理速度较慢, 计划开发基于知识蒸馏的轻量化学生模型。 通过特征表示对齐等蒸馏策略, 在保持模型性能的前提下降低计算复杂度。 同时结合精简的模型架构设计和量化训练技术, 进一步提升整体计算效率。
为系统验证CDCDN中各个组件的有效性, 对DDD、 DICF以及CSOM进行了消融实验, 构建多个基线模型, 见表4。 下面是各个基线模型的具体构建原则:
Baseline-A: 该模型作为基础版本, 只进行单通道特征提取方法得到查询序列, 并基于此完成目标检测任务。
| 表4 基线模型 Table 4 Baseline models |
Baseline-B: 在A模型基础上, 添加DDD。 将任务解耦成全局信息定位与局部边缘细化, 在得到全局和局部特征后, 通过逐元素相加的方式进行特征融合。
Baseline-C: 在B模型基础上, 加入DICF, 实现全局与局部信息交互融合。
CDCDN: 完整模型, 在C模型基础上集成CSOM, 引入VLM生成文本信息并结合图像信息来进行跨模型信息交互。
消融实验结果如表5所示, 可以看出:
| 表5 消融实验 Table 5 Ablation experiment |
(1)相较于Baseline-A, Baseline-B在两个数据集上的检测性能均得到了提升。 在MHCD2022数据集上, DDD模块的引入使mAP@0.5从61.9%提升至64.5%, mAP@0.75从41.5%提升至43.0%, 这一提升验证了DDD模块解耦设计的有效性。 模块中的全局信息定位通道通过多头自注意力模块帮助模型在复杂背景中更好地定位伪装目标的宏观位置, 局部边缘细化通道增强了模型对伪装目标边缘的辨识能力。
(2)相较于Baseline-B, Baseline-C的检测性能也均有一定的提升。 在MHCD2022数据集上的mAP@0.5提升至66.7%, mAP@0.75提升至44.0%。 性能的提升主要归功于DICF的有效引入, 首先, 全局门控约束机制实现了全局特征对局部特征的动态调制; 其次, 局部特征校正机制确保了局部细节信息能够有效地反馈至全局特征; 最后, 通道融合进一步通过自适应增强来提升全局定位与局部细化的融合效果。
(3)相较于Baseline-C, CDCDN的检测性能达到最佳。 这一提升主要得益于新增的CSOM模块, 该模块能够利用VLM生成文本语义特征, 将场景和对象描述信息与视觉特征进行深度匹配, 从而有效增强了模型对伪装目标的场景适应能力。
在MHCD2022数据集上, CDCDN相较于Baseline-A在mAP@0.5、 mAP@0.5:0.95和mAP@0.75上分别提升了5.7%、 2.1%和6.9%; 在COD10K数据集上, 相应指标也分别实现了4.1%、 4.0%和5.4%的提升。 这些实验结果证实了CDCDN中各个功能模块的有效性, 各模块之间的协同工作使得模型在伪装目标检测任务中达到了当前最优的性能水平。
针对伪装目标检测存在的视觉一致性带来的目标边界区分难和辨识性特征学习难等问题, 提出了一种跨模态动态协同双通道网络(CDCDN)。 首先, 设计了动态协同双通道模块, 全局通道侧重于捕获目标的宏观信息, 局部通道则专注于边缘的精细化表征, 二者通过动态信息协同及融合机制实现特征互补, 有效解决目标边界区分难的问题。 其次, 设计了跨模态场景对象匹配模块, 通过将图像特征与VLM生成语义描述进行跨模态融合, 在特征空间构建判别性更强的联合表征, 从而解决辨识性特征学习难的问题。 CDCDN在MHCD2022和COD10K数据集上的实验均达到了最高的检测精度, 为伪装目标检测提供了一种新的有效方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|