

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于特征选择与机器学习的富硒茶叶硒含量高光谱估测
[文竹1  , 郭松
, 郭松1 , 舒田1 , 赵龙才2, 3 ]
, 郭松|
|


作者简介: 文 竹, 1978年生,贵州省农业科技信息研究所副研究馆员 e-mail: 360159928@qq.com
硒元素是富硒茶体内的重要养分指标之一, 其含量决定了富硒茶的经济和营养价值。 高光谱遥感反演技术具有无损、 实时和快速监测的特点, 以贵州省开阳县南贡河茶园富硒茶硒含量和相应冠层非成像高光谱数据作为源数据, 采用Savitzky-Golay二阶平滑滤波预处理原始光谱并基于一阶导数变换以及连续统去除变换挖掘原始光谱数据潜力, 利用波段穷举组合以及多种特征选择算法获取建模自变量, 通过不同算法构建多个茶叶硒含量反演模型。 结果表明: (1)光谱变换与光谱指数的结合可增强原始光谱反演茶叶硒含量的能力。 (2)SPA总体优于UVE; 连续统去除变换光谱优于原始光谱和一阶导数光谱。 (3)多因素模型精度优于单因素模型, 多因素模型中ELMR性能最佳; 所有模型中连续统去除光谱下的SPA-ELMR模型精度最高, 该模型建模决定系数( R2)及归一化均方根误差(nRMSE)分别为0.689、 18.869%, 相应验证 R2与nRMSE分别为0.627、 20.429%。 探讨了特定生育期下茶叶硒含量与其冠层高光谱反射率的响应关系, 构建了精度适宜的茶叶硒含量单因素反演模型及多因素反演模型, 为茶叶硒含量的快速、 无损监测提供了理论基础, 也为茶园的数字化建设提供了一定技术支持。
Selenium is one of the important nutrient indices in selenium-rich tea, and its content determines the economic and nutritional value of selenium-rich tea. Hyperspectral remote sensing inversion technology has the characteristics of non-destructive, real-time, and rapid monitoring. This study utilizes the selenium content in selenium-rich tea from the Nangong River tea garden in Kaiyang County, Guizhou Province, and corresponding canopy non-imaging hyperspectral data as source data. The Savitzky-Golay second-order smoothing filter was used to preprocess the primary spectrum, and the potential of the primary spectral data was explored through first-order derivative transformation and continuum removal transformation. The independent variables for the modeling were obtained using a band elimination combination and various feature selection algorithms. Multiple inversion models of selenium content in tea were constructed using different algorithms. The results showed that: (1) the combination of spectral transformation and spectral index could enhance the ability of retrieving selenium content from the primary spectrum. (2) SPA was better than UVE overall; Continuum removal spectrum was superior to the primary spectrum and the first derivative spectrum. (3) The accuracy of the multi-factor model was better than that of the factor model, and the performance of ELMR in the multi-factor model was the best. Among all the models, the SPA-ELMR model under the continuum removal spectrum had the highest accuracy. The coefficient of determination ( R2) and normalized root mean square error (nRMSE) of this model were 0.689 and 18.869%, respectively, and the corresponding verification R2 and nRMSE were 0.627 and 20.429%, respectively. In this study, the response relationship between selenium content in tea and spectral reflectance at specific growth stages was discussed. A single-factor inversion model and a multi-factor inversion model with appropriate accuracy were constructed, providing a theoretical basis for the rapid and non-destructive monitoring of selenium content in tea. Also, they provided some technical support for the digital construction of tea gardens.
硒是人体必不可少的重要微量元素, 其功效包括增强人体免疫力、 预防心脑血管疾病、 辅助血糖调节以及抗氧化等[1]; 饮富硒茶是人体补硒的主要方式之一, 硒元素可与茶树中活性成分形成良好协同作用, 提升营养价值的同时还易于人体吸收[2]。 叶片硒含量实时监测是富硒茶种植业中的一大重难点, 富硒茶中硒含量过少会导致补硒功效较差、 含量过多亦会使人体中毒。 传统的茶叶硒含量检测为人工实地取样, 经由室内实验室(如色谱法)测定[3], 但此类方法不仅效率低下、 成本高昂, 难以普及于大尺度下茶园监测, 且对样品本身会造成不可逆的损害, 因此迫切需要一种可在茶园大面积使用的叶片硒含量无损监测技术。 随着农业大数据领域的不断推测出新, 高光谱遥感波段多而窄且数据量丰富的特点为解决以上问题提供了新途径, 该技术基本原理为挖掘训练样本反演参数与光谱反射率之间的内在隐形知识并将其模型化, 后续再基于该模型计算未知样本反演参数[4]。
目前, 在高光谱遥感技术反演茶叶生理生化参数方面, 已有一定研究。 Tu等[5]基于茶园无人机高光谱影像提取其冠层归一化光谱, 结合偏最小二乘回归反演茶叶多酚和氨基酸含量, 二者反演模型相关系数分别达0.58和0.62。 Sonobe等[6]采用随机森林、 支持向量机、 深度信念网络以及核极限学习机四种机器学习算法探究高光谱数据估算遮荫条件下茶叶叶绿素含量的能力, 其中核极限学习机模型性能最佳, 其均方根误差为(8.94± 3.05) μ g· cm-2。 杨宝华等[7]从茶叶空间维以及光谱维提取叶片多酚含量敏感信息, 以纹理数据和特征波段作为输入变量构建多个反演模型, 所有模型中支持向量回归精度最高, 建模集和验证集决定系数分别高达0.933和0.823。 Kang[8]等将商品肥和有机肥作为长势变量因子, 研究不同肥料条件下高光谱数据反演芽茶儿茶素的潜力, 结果表明商品肥和有机肥下的儿茶素偏最小二乘模型决定系数均在0.7以上且两类模型具有较强的可交叉性。 He等[9]由茶园冠层成像高光谱数据提取叶绿素光谱指数以及叶面积光谱指数, 利用简单线性和非线性函数解释冠层光谱与茶叶产量的关系, 发现曲率函数及分段线性函数精度最高, 相应均方根误差低至124.602 g。 Ren等[10]提出一种结合特征选择与机器学习的近红外茶叶灰分反演策略, 其中以区间变量迭代空间收缩法和支持向量机组合预测能力最好, 相对预测偏差达5.59。 Jiang等[11]为反演茶叶冠层氮素及生物量, 以微分以及小波分析等预处理算法提炼高光谱反射率中的敏感信息, 构建的各类模型决定系数介于0.35~0.76。 综上所述, 当前高光谱遥感反演茶叶理化参数的研究已较为成熟, 反演的理化参数包括叶绿素、 多酚、 生物量等, 建模方式从传统回归向机器学习延申, 数据源亦由地面到低空、 由单源向多源扩展。 然而, 尚未出现有关高光谱技术反演茶叶硒含量的报道。
贵州省开阳县作为我国主要富硒区之一, 富硒茶已成为当地重要的经济及文化组成。 以该地区富硒茶为研究对象, 探究高光谱遥感数据反演叶片硒含量的能力, 为该项研究空白积累有效知识的同时也为地区数字农业发展提供理论基础。
研究区位于贵州省开阳县龙岗镇南贡河茶园(107.018 889° E, 26.804 722° N), 地貌上属黔中高原区, 气候类型为亚热带季风性湿润气候, 地区平均海拔1 000 m, 年均降水和平均气温分别为1 100 mm和14 ℃, 全年无霜期超过300 d, 茶园所在地土壤类型为黄壤, 质地疏松, 养分肥沃, PH呈酸性, 适宜于茶树生长。 研究区茶品种为“ 福鼎大白” , 树龄十年。 供试肥料选择含硒型氨基酸水溶肥, 施肥方式为叶面喷施, 设四个硒水平, 依次为T0-0 mg· L-1、 T1-2.5 mg· L-1、 T2-5 mg· L-1、 T3-10 mg· L-1, 其中T0为喷清水对照, 其余处理采用清水稀释至相应浓度后喷施。 试验开展于2024年7月12日(晴天)下午14:00, 喷施液体量以茶叶表面布满小水珠但不滴水为宜, 单个处理喷施4垄, 每垄划定10个采样小区(1.4 m× 1.5 m), 各小区中间设置1个采样点, 共160个采样点, 小区及采样点设置如图1。
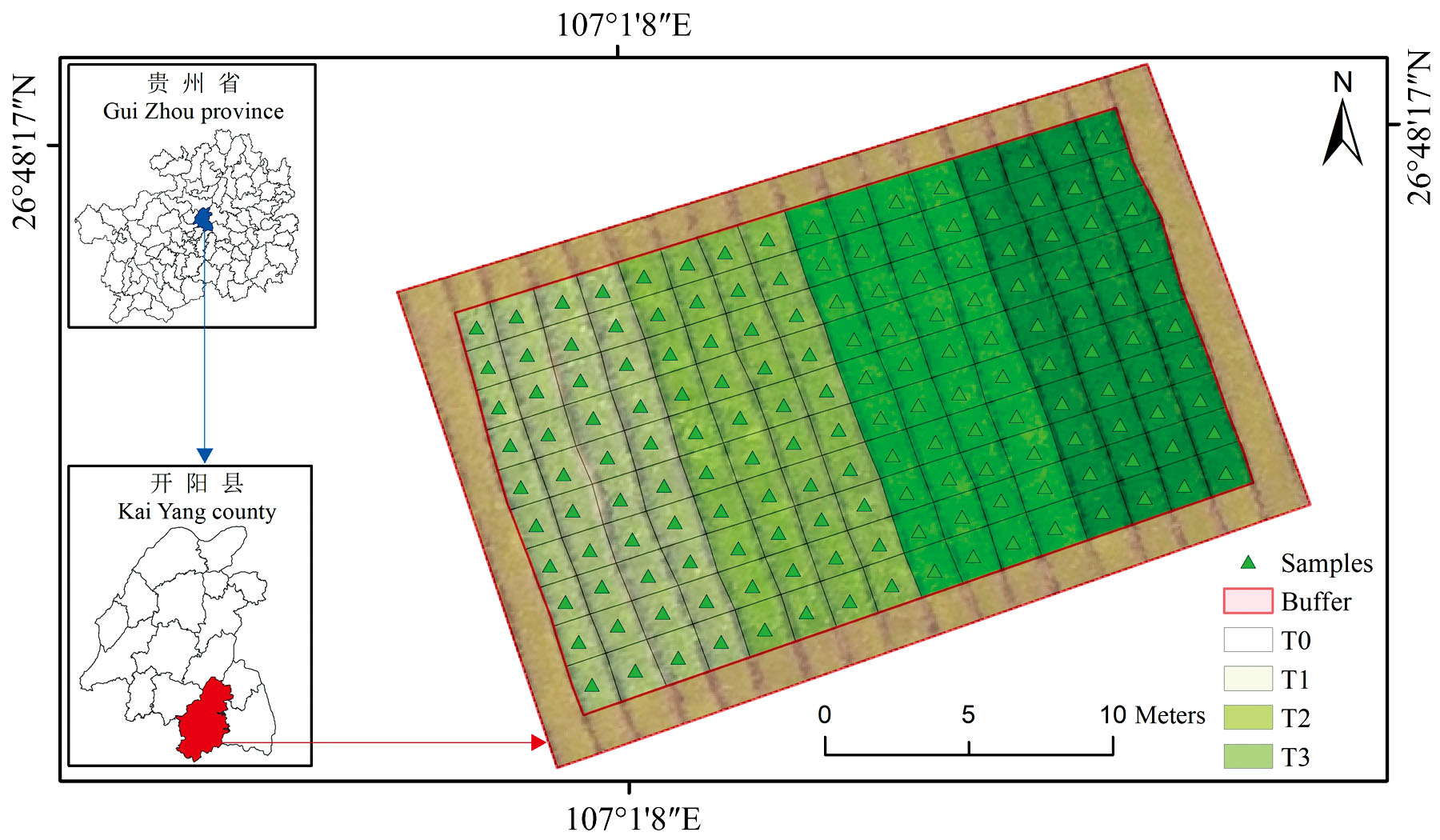 | 图1 研究区地理位置Fig.1 Geographical location of the study area |
1.2.1 高光谱数据测定
茶叶冠层高光谱数据通过ASDField Spec3便携式地物光谱仪(美国, ASD公司)获取, 该仪器成像范围350~2 500 nm, 采样间隔1 nm, 其在350~1 000及1 000~2 500 nm范围的光谱分辨率分别为1.38、 2 nm。 根据当地农户生产经验, 于施肥后15 d左右晴朗天气下12:00— 15:00采集数据, 此时太阳辐射充足, 高度角较大, 茶叶正处于当地第三次采摘期, 采集过程中传感器探头始终垂直向下且与茶叶冠层距离保持在30~50 cm。 为确保数据科学性与准确性, 每隔15 min 校正1次白板。 各采样点重复获取10条光谱曲线, 取平均作为该样点代表光谱曲线。
1.2.2 硒含量(Se)测定
光谱数据获取后迅速于各小区采集长势良好且无明显病虫害的冠层叶片, 单个小区采集不少于200 g, 采样位置与光谱数据测定位置一致。 茶叶鲜样置于烘箱前先擦拭其表面灰尘, 再以120 ℃杀青30 min, 80 ℃烘至恒重, 随后研磨成粉。 茶叶硒含量的测定通过硒快速检测仪(型号JPYZ FAST-100)(中国, 苏州硒谷科技有限公司)实现, 该仪器操作简单, 仅需将粉状样品装入测定管中基于其内置工作曲线即可测定样品硒含量。
高光谱数据采集过程中由于设备暗电流等原因会引入随机噪声, 因此在The Unscrambler X 10.4中对原始光谱采用Savitzky-Golay二阶平滑滤波以弱化其影响, 同时为进一步挖掘高光谱数据反演茶叶硒含量的潜力, 在ENVI 5.3中对扩展原始光谱(primary spectrum, PS)到一阶导数光谱(first derivative spectrum, FDS)和连续统去除光谱(continuum removal spectrum, CRS), 结果如图2。 相较于原始光谱, 一阶导数变换主要放大原始光谱中反射率突变的位置, 如红边; 连续统去除变换主要凸出原始光谱中吸收谷和反射峰, 如绿峰、 红谷等。
 | 图2 不同类型光谱Fig.2 Different types of spectra |
在Excel 2021 中以升序规则对茶叶硒含量排序, 按照3:1的比例分层抽样划分建模集与验证集。 划分结果如表1, 可见建模集、 验证集以及总体的各项统计特征差别不大, 说明样本划分较为合理; 各样本类别下变异系数均大于80%, 属高度变异, 表明数据跨度明显, 代表性较强。
| 表1 建模集与验证集统计特征 Table 1 Statistical characteristics of modeling set and validation set |
将基于波段排列组合的方式构建差值光谱指数(difference spectral index, DSI)、 比值光谱指数(ratio spectral index, RSI)以及归一化光谱指数(normalized spectral index, NDSI)作为单因素模型建模参数, 单因素模型包括线性函数、 幂函数、 对数函数以及指数函数, 通过连续投影算法(successive projections algorithm, SPA)以及无信息变量消除法(uniformative variable elimination, UVE)提取多因素模型建模参数, 多因素模型包括多元线性回归(multiple linear regression, MLR), 支持向量回归(support vector regression, SVR)以及极限学习机回归(extreme learning machine regression, ELMR)。 所有模型的构建均在Matlab 2018a中完成。 其中多元线性回归考虑多个自变量线性贡献的建模方式, 支持向量回归通过定义超平面来描述自变量对响应变量的影响[12], 极限学习机则采用模拟人类神经元处理问题的方式, 基于输入层、 输出层以及中间层拟合自变量到响应变量[13]。
各模型精度由决定系数(R2)和归一化均方根误差(normalized root mean square error, nRMSE)共同评价, 其中R2越接近1, nRMSE越小, 代表模型精度越好。 二者计算方式如式(1)和式(2), 式n中为样本数量, xi、
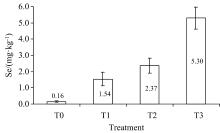
如图3, 不同硒肥处理下茶叶硒含量不同, 随着硒肥处理浓度的升高, 茶叶硒含量平均值和误差棒均升高。 其中T3处理下茶叶硒含量最高, 达5.30 mg· kg-1, T0最低, 为0.16 mg· kg-1, 其余处理介于二者之间。
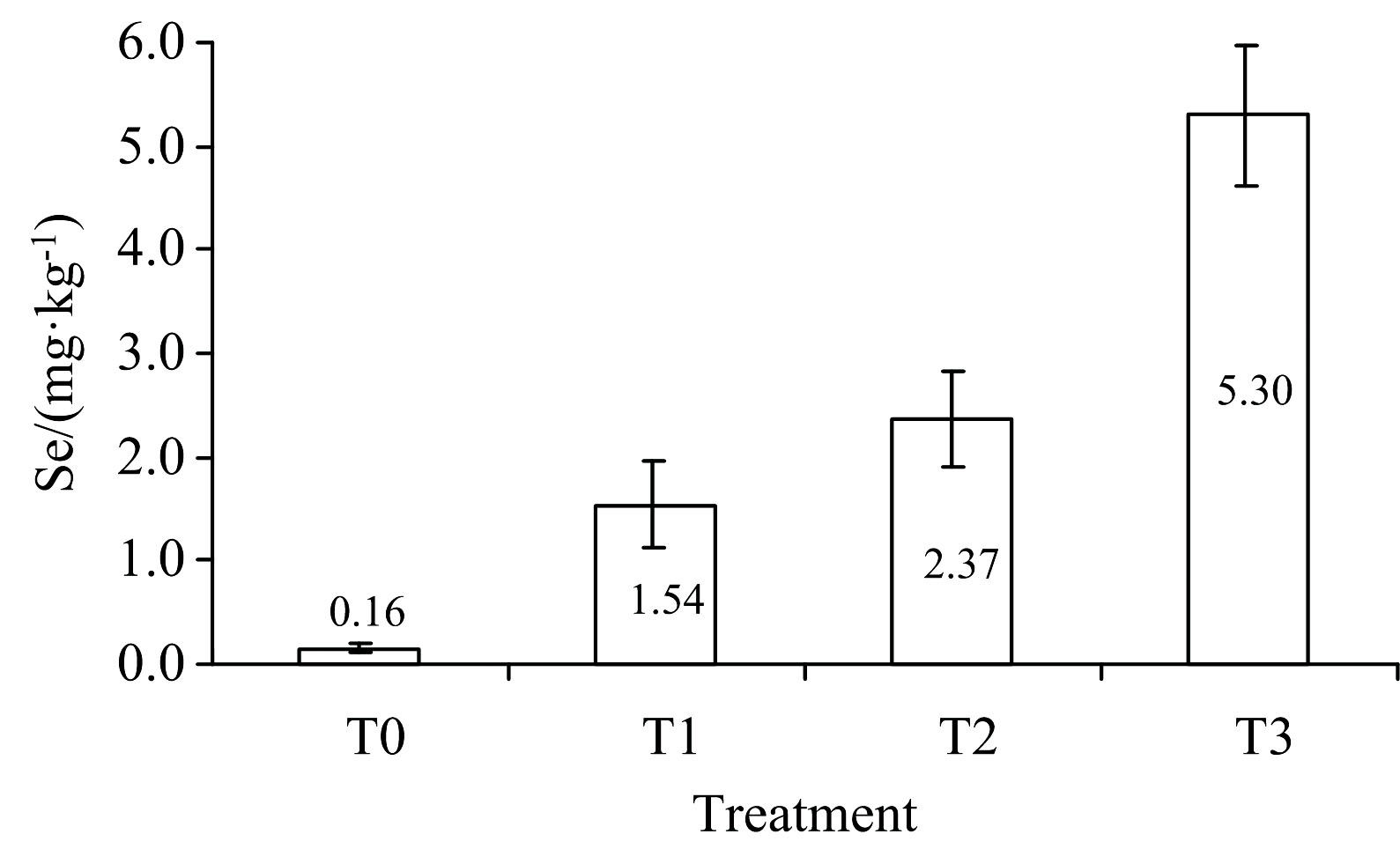 | 图3 不同硒肥处理下茶叶硒含量特征Fig.3 Characteristics of selenium content in tea under different selenium fertilizer treatments |
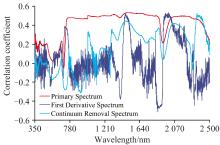
计算不同类型光谱在各波长处的值与茶叶硒含量相关系数, 形成图4。 从曲线平滑度看, 原始光谱平滑度最好, 350~2 500 nm范围基本无噪声, 其次为连续统去除光谱, 仅在1 300~2 300 nm区域曲线噪声较小, 一阶导数光谱最差, 350~2 500 nm区域无平滑曲线; 从相关系数看, 原始光谱相关系数绝对值较大的波段数量最多、 连续统去除光谱与一阶导数光谱相对较少, 三者相关性最好的波长及其系数值分别为: (1 501, 0.532)、 (1 989, 0.532)、 (2 342, 0.522)。
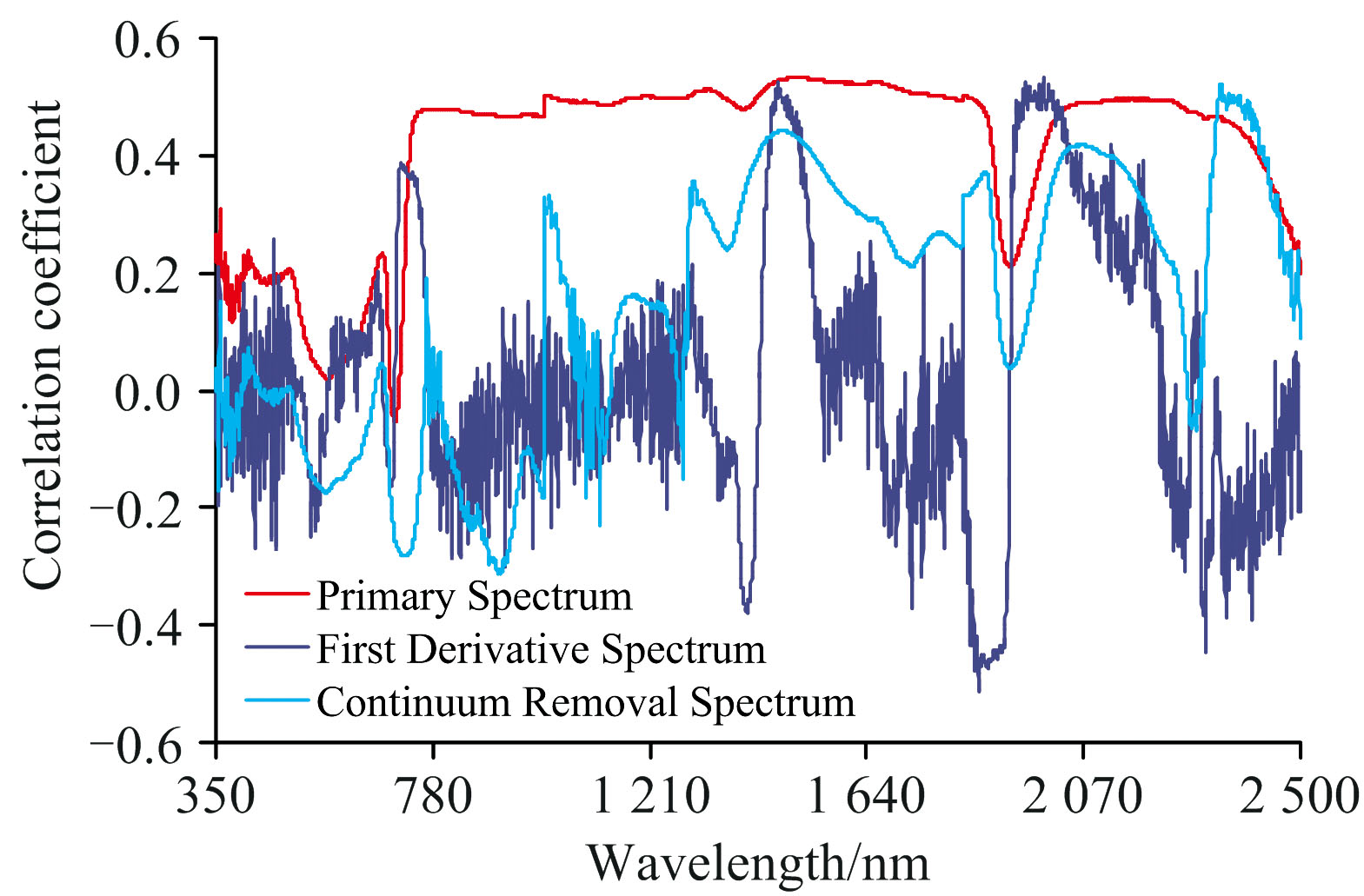 | 图4 不同类型光谱值与茶叶硒含量相关性Fig.4 The correlation between different spectral data and selenium content of tea leaves |
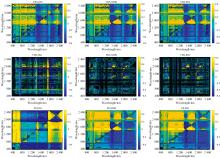
根据波段反射率排列组合方式构建光谱指数, 形成各类光谱指数与茶叶硒含量相关系数热图(图5), 可见不同类型光谱下, RSI与NDSI相关系数分布规律一致, DSI与二者不同, 原始光谱与连续统去除光谱中相关系数较大的区域集中性较强, 该特点在一阶导数光谱中较差; 选择不同热图中相关系数绝对值最大的波段组合作为可选光谱指数, 如表2, 可见入选的波段多分布在1 500和2 300 nm附近, 从相关系数看, 原始光谱、 一阶导数光谱以及连续统去除光谱中相关性最强的光谱指数分别为RSI、 DSI、 DSI, 相应相关系数为-0.549、 -0.614、 -0.591, 均达到极显著水平。
 | 图5 不同光谱指数与茶叶硒含量相关系数热图Fig.5 Hot maps of correlation coefficients between selenium content in tea leaves and different spectral indices |
| 表2 可选光谱指数及其相关性 Table 2 Optional spectral index and their correlation |
连续投影算法(SPA)与无变量信息消除算法(UVE)均为特征选择算法, 前者通过不断加入投影长度最小的新变量来构成目标自变量矩阵, 后者基于原始自变量矩阵对响应矩阵的相关系数统计特征来剔除自变量矩阵中的无关变量。 各类型光谱下SPA与UVE选择的建模参数如表3, 整体上SPA与UVE降维效果均较好, 选择的波段个数介于7~30个, 降维率在98%以上; 从光谱类型看, 连续统去除光谱中被选择的波段个数最少, 其次为原始光谱, 最次为一阶导数光谱, 从波段位置看, 各类光谱中SPA与UVE所选择的波段中心波长集中于1 100、 1 500和2 300 nm。
| 表3 连续投影与无信息变量消除降维 Table 3 The successive projections algorithm and uniformative variable elimination dimensionality reduction |
2.5.1 单因素模型及精度比较
以表2中最优光谱指数为自变量构建单因素模型, 结果如表4。 可见茶叶硒含量与光谱指数之间包含线性和非线性关系, 所有单因素模型精度由低到高分别为原始光谱、 连续统去除光谱、 一阶导数光谱, 其中原始光谱和连续统去除光谱模型精度规律一致, 均表现为建模精度较好而验证精度较差, 不适宜于实际应用; 一阶导数光谱模型精度最好, 建模和验证R2分别为0.473以及0.446, 相应nRMSE为31.401%和32.124%, 当使用单因素模型反演茶叶硒含量时, 应优先考虑此模型。
| 表4 茶叶硒含量单因素反演模型 Table 4 Single factor inversion models of selenium content of tea leaves |
2.5.2 传统多因素模型及精度比较
茶叶硒含量与光谱反射率的响应关系不仅仅局限在单个波段, 因此采用多元线性回归(MLR)拟合多波段信息与硒含量的关系, 其中自变量为表2中各特征, 响应变量为茶叶硒含量, 结果如表5。 可见, 相较于单因素模型, MLR模型精度整体上更高, 过拟合现象并不明显; 从降维算法看, 各类型光谱下均为基于SPA构建的MLR模型更优, 从光谱类型看, 连续统去除光谱下反演模型精度最高, 原始光谱次之、 一阶导数光谱最差; 所有传统多因素模型中连续统去除光谱下的SPA-MLR模型为最优模型, 其建模和验证精度分别为(0.652, 22.615%)、 (0.588, 24.313)。
| 表5 茶叶硒含量多元线性回归模型 Table 5 Multiple linear regression models of selenium content of tea leaves |
2.5.3 机器学习回归多因素模型及精度比较
单因素模型与传统多因素模型结果显示, 茶叶硒含量与其冠层光谱反射率之间的关系为“ 一对多” 和“ 线性复杂” , 因此, 使用拟合能力更强的机器学习算法定量表达二者内在联系, 算法包括支持向量回归和极限学习机回归。 为节约计算成本, 支持向量回归与极限学习机回归分别使用网格法以及麻雀搜索算法寻优, 其中网格法采用等差穷举的方式尽可能的列出不同参数的排列组合, 各组合不断循环以获得较优结果; 麻雀搜索算法通过模拟麻雀种群的捕食以及反捕食行为以促使算法朝着R2增大而nRMSE减小的方向运行[14]。 研究中支持向量回归核函数为径向基函数, Epsilon统一设定为特征数倒数, 其网格法寻优参数为惩罚系数C与Gamma系数, 二者寻优区间分别为[0.1, 10]、 [0.01, 1]; 麻雀搜索算法中隐含层数目为特征数个数, 麻雀种群数量为特征数的10倍。
机器学习回归结果如表6。 对比表5中的MLR模型, 除SVR中一阶导数光谱下的UVE、 SPA以及原始光谱下的UVE模型仅建模精度有所增强外, 其余反演模型建模与验证精度均得到提升, SVR各模型建模R2提升0.015~0.040, nRMSE下降1.460%~2.317%, ELMR各模型建模及验证R2分别上升0.032~0.053、 0.001~0.039, 相应nRMSE降低范围为2.109%~4.871%以及1.257%~3.884%, 可见SVR与ELMR均可构建较好的反演模型; 从模型精度看, SVR与ELMR各模型精度规律与MLR模型一致, 均为连续统去除光谱最好、 原始光谱次之、 一阶导数光谱最差, 同种回归算法和光谱类型下, 均为SPA优于UVE; 对比SVR和ELMR, ELMR下的各类模型精度均好于SVR, 各模型建模和验证R2最高分别提升0.023和0.067, 说明ELMR在定量表达茶叶硒含量与光谱反射关系方面具有较强优势; 总体上所有机器学习回归模型中的最优模型为连续统去除光谱下基于连续投影算法降维的ELMR模型, 该模型精度较高, 无明显过拟合与欠拟合现象, 其建模和验证R2为0.689、 0.627, 相应nRMSE分别低至18.869%和20.429%。
| 表6 茶叶硒含量机器学习回归模型 Table 6 Machine learning regression models of selenium content of tea leaves |
不同理化性质地物在光谱曲线上的差异是遥感量化相应参数的数学基础[15]。 本工作中茶叶硒含量在原始光谱、 一阶导数光谱以及连续统去除光谱下的特征波段分别位于1 501、 1 989以及2 342 nm, 与Tian[16]等的研究结果相似, 光谱变换可有效挖掘原始光谱数据潜力并改变特征波段位置; 特征选择是解决高光谱数据冗余的有效手段之一, SPA与UVE降维效果均较好, 但由于算法策略和样本数量偏少等原因, 不同类型光谱下多因素模型建模参数大多为相邻波长, 因此, 后续的研究应着重于算法的改进、 不同特征选择算法的联合、 波段折叠以及基于相邻波段的特征波段积分研究。
研究中多因素模型优于单因素模型、 机器学习模型强于传统回归, 该规律与Chen[17, 18]等的研究结果一致, 从模型精度看, 连续统去除光谱下多因素模型好于其他类型光谱, 原因在于茶叶硒含量差异主要体现在高光谱曲线上的吸收峰和反射谷, 而连续统变换方式放大了该特征, 因此特征选择算法所筛选得到的建模参数多于其余类型光谱, 故而相应模型精度亦会更高; 从变量冗余看, 建模自变量增多是导致模型精度较高的次要贡献, 而主要贡献在于光谱变换改变了原始光谱曲线物理意义; 受制于生育期和数据源有限, 本研究构建的各类模型是否适用于其他生育期和品种还有待测试, 同时, 为扩展模型适用性, 茶叶硒含量的空-天-地一体化遥感估测模型开发应是下一步研究的重点之一。
基于ASD Field Spec3地物光谱仪采集富硒茶冠层高光谱数据, 采用Savitzky-Golay二阶平滑滤波预处理原始光谱并基于一阶导数变换以及连续统去除变换派生原始光谱, 分别以光谱数据和地面实测茶叶硒含量(Se)作为解释变量和响应变量, 利用波段穷举组合以及特征选择获取建模自变量并基于不同算法构建多个茶叶硒含量遥感反演模型。 结果表明, 光谱变换可增强光谱指数与茶叶硒含量相关性; 在特征选择方面, 连续投影(SPA)总体上优于无变量信息消除(UVE), 连续统去除变换光谱好于原始光谱和一阶导数光谱; 在反演模型方面, 多因素模型精度优于单因素模型, 多因素模型中以极限学习机回归(ELMR)性能最佳, 所有模型中连续统去除光谱下的SPA-ELMR模型精度最高, 该模型建模R2与nRMSE分别为0.689、 18.869%, 相应验证R2与nRMSE分别为0.627、 20.429%。 探讨了特定生育期下茶叶硒含量与其冠层高光谱反射率的定量关系, 构建了精度适宜的茶叶硒含量反演模型。 该研究为后续茶叶硒含量敏感波段划分以及空-天-地一体化遥感大模型构建提供了一定理论参考, 也为智慧茶园建设提供了技术支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|