

{kind=link}
{kind=link}
CARS算法提取特征光谱建立荞麦叶片总黄酮与蛋白质近红外模型
[朱丽伟 , 杜千禧, 唐国红, 李洪有, 张晓娜, 陈庆富, 石桃雄
, 杜千禧, 唐国红, 李洪有, 张晓娜, 陈庆富, 石桃雄* ]
, 杜千禧, 唐国红, 李洪有, 张晓娜, 陈庆富, 石桃雄]
|
|


作者简介: 朱丽伟,女, 1985年生,贵州师范大学生命科学学院副教授 e-mail: liweib0401001@163.com
为满足荞麦品质鉴定和育种工作的需要, 采用竞争性自适应重加权采样算法(CARS)提取特征光谱, 结合定量偏最小二乘法对荞麦叶片总黄酮和蛋白质含量进行了快速测定研究。 首先利用Kennard-Stone(KS)算法划分训练集和测试集, 训练集总黄酮含量的平均值、 最大值和最小值含量分别是55.8、 92.5和28.1 mg·g-1, 测试集样品的平均值、 最大值和最小值含量分别是71.0、 99.8和31.5 mg·g-1。 训练集蛋白质含量的平均值、 最大值和最小值含量分别是169.6、 331.0和121.2 mg·g-1, 测试集样品蛋白质含量的平均值、 最大值和最小值含量分别是158.2、 183.0和129.1 mg·g-1。 然后分别使用归一化、 归一化+多元散射校正、 归一化+标准正太变换、 归一化+一阶导数、 归一化+二阶导数、 归一化+SG平滑滤波对波长在4 000~12 000 cm-1范围内光谱进行预处理, 再采用CARS算法提取特征波段, 最后利用偏最小二乘法建立预测模型。 通过对模型训练集决定系数( Rc)、 测试集决定系数( Rp)、 交叉验证均方根误差(RMSECV)、 测试集均方根误差(RMSEP)和剩余预测偏差(RPD)的综合分析, 得到可预测荞麦总黄酮和蛋白质的最佳模型。 其中3个总黄酮预测模型是可用的, 最佳的预测模型使用了1 102个波段中的46个特征波段, 所使用的预处理方法为归一化+一阶导数, 其模型的 Rc、 Rp、 RMSECV、 RMSEP和RPD分别为0.997、 0.933、 0.170、 0.829和2.893。 4个蛋白质预测模型是可用的, 其最佳的预测模型使用了42个特征波长, 所使用的预处理方法为归一化+二阶导数, 其模型的 Rc、 Rp、 RMSECV、 RMSEP、 RPD分别为0.998、 0.965、 0.202、 0.353和3.849。 结果表明, 将KS算法和CARS算法应用到近红外光谱模型的建立过程, 可以利用较少的样本建立可靠的预测模型, 满足对荞麦叶片总黄酮和蛋白质的快速测定, 为叶用荞麦育种工作提供有力的工具。
To meet the requirements of buckwheat quality determination and breeding work, the Competitive Adaptive Re-Weighted Sampling (CARS) algorithm was used in this study to extract the characteristic spectrum and combined with the quantitative partial least squares method to rapidly determine the total flavonoid and protein content in buckwheat leaves. First, the Kennard-Stone (KS) algorithm was used to split the training and test sets. The training set's average, maximum, and minimum total flavonoid contents were 55.8, 92.5 and 28.1 mg·g-1, respectively. The test set's average, maximum, and minimum total flavonoid contents were 71.0, 99.8 and 31.5 mg·g-1, respectively. The training set's average, maximum, and minimum protein contents were 169.6, 331.0 and 121.2 mg·g-1, respectively. The samples' average, maximum, and minimum protein contents in the test set are 158.2, 183.0 and 129.1 mg·g-1, respectively. Then use Normalization, Normalization + Multiplicative Scatter Correction (MSC), Normalization + Standard Normal Variate Transform (SNV), Normalization + First Derivative, Normalization + Second Order Derivative, Normalization + Savitzky-Golay Smoothing Filter (SG) to preprocess the spectrum in the wavelength range from 4 000 to 12 000 cm-1, then use CARS algorithm to extract the characteristic spectrum, and finally use the partial least squares method to build prediction models. Through a comprehensive analysis of the coefficient of determination of the training model ( Rc), the coefficient of determination of the test model ( Rp), the root mean square error of cross-validation (RMSECV), the root mean square error of the test model (RMSEP) and the residual predictive deviation (RPD), we obtain the best model for the prediction of total flavonoid and protein in buckwheat. Three available prediction models for total flavonoidswere constructed. The best prediction model used 46 characteristic wavenumber points out of 1102 wavenumber points. The preprocessing method used was normalization + first derivative. The model's Rc, Rp, RMSECV, RMSEP, and RPD were 0.997, 0.933, 0.170, 0.829 and 2.893, respectively. Four available protein prediction models were created, the best of which used 42 characteristic wavenumber points, and the preprocessing method used was normalization + second derivative. The model's Rc, Rp, RMSECV, RMSEP, and RPD are 0.998, 0.965, 0.202, 0.353 and 3.849, respectively. The results show that the application of the KS algorithm and CARS algorithm in building the near-infrared spectroscopy model requires fewer samples to build a reliable prediction model, enables the rapid determination of total flavonoids and protein of buckwheat leaves, and provides powerful tools for buckwheat breeding.
荞麦是蓼科荞麦属一年生草本植物, 有甜荞和苦荞两个主要栽培种, 因富含黄酮类物质具有很高的食用价值和医疗保健作用, 是重要的药食两用杂粮作物, 长期食用可降三高[1, 2]。 相比于主要谷物水稻、 小麦和玉米而言, 荞麦富含必需氨基酸组成平衡的蛋白质, 高含量的生物活性黄酮, 还有高含量的抗性淀粉[3]。 据统计, 我国“ 三高” 及糖尿病患者总数达到3亿多人, 营养与保健已成为人类的基本追求。 为满足人们的需求, 营养功能物质高含量(高蛋白、 高黄酮、 高抗性淀粉)荞麦品种选育已成为当前荞麦育种工作的热点。 育种工作中涉及大量样品中黄酮、 蛋白质等物质的测定, 因此黄酮和蛋白质含量的准确、 快速测定对于荞麦育种极其重要。 目前国内外对荞麦总黄酮和蛋白质的测定多采用传统的方法, 如使用液相色谱法测定黄酮的含量, 利用凯氏定氮法测定蛋白质含量, 这些方法有预处理复杂、 耗时长、 污染环境等缺点, 因此研究能简便快速、 无污染测定荞麦营养物质含量的方法具有重要的现实意义。
近红外光谱技术具有快速、 无污染、 检测方便等诸多优点, 目前, 在作物和食品质量评估中有很多应用[4, 5], 而在实际应用中, 仪器间的台间差、 外界环境的变化都会影响样品光谱的采集, 导致对某台仪器建立的分析校正模型难以适用于其他仪器[6]。 潘秀珍等[7]利用连翘叶的近红外光谱建立了多种成分含量的动态定量预测模型, 其中总黄酮模型的相关系数可达0.95, 满足连翘叶总黄酮快速测定的需求。 本课题组[8]前期利用200多份荞麦叶片的近红外全光谱建立了可快速预测金苦荞叶蛋白质含量的模型, 其最佳模型的决定系数均高于0.93。 在建立荞麦总黄酮模型时, 尝试不同的光谱预处理方法, 选择不同的光谱区间多次建模后, 其模型决定系数仍低于0.50。 越来越多的学者发现使用特征光谱建模, 其模型的预测效果更好。 Xiao等[9]分别利用分数阶导数和连续小波变换技术提取柑橘高光谱的特征光谱, 建立了可预测柑橘叶绿素含量的模型。 Zhang等[10]利用深度卷积生成对抗网络从猕猴桃和梨的多光谱中获取包含百个波长的水果特征光谱, 利用光谱对猕猴桃和梨的内部品质进行建模, 发现建模效果远优于基于全光谱的模型。 Deng等[11]使用多种算法筛选特征波长建立了快速预测黄精总多糖、 总黄酮和总皂苷的近红外模型。 为了提高建模效果, 本课题组[12]尝试使用特征光谱建立近红外模型, 使用变异系数为15.06的苦荞群体建立了测定苦荞籽粒总黄酮含量的近红外光谱, 其最优模型建模集和验证集的鉴别率大于0.94。 本工作利用傅里叶变换近红外漫反射光谱技术采集53份总黄酮和蛋白质含量差异较大的荞麦叶片的近红外光谱, 采用Kennard-Stone(KS)算法划分样本集, 再使用多种光谱预处理方法处理光谱后, 然后利用竞争性自适应重加权采样算法(competitive adaptive reweighted sampling, CARS)提取特征光谱, 最后结合偏最小二乘回归法建模, 成功构建荞麦叶片总黄酮和蛋白质的近红外分析模型, 为实现育种过程荞麦叶片总黄酮和蛋白质含量的快速检测提供帮助, 也为荞麦食品研发过程相关物质含量的测定提供参考。
实验用的材料为2023年春季采收的荞麦叶片。 为了得到更具代表性的样品, 采集了甜荞、 苦荞、 金苦荞和金荞等多种栽培荞麦的叶片, 共53份差异较显著的叶片样本。 采收的叶片先放于鼓风干燥机中杀青30 min(105 ℃), 然后将烘箱温度调至80 ℃, 烘24 h。 烘干后的叶片用高速粉碎机粉碎后过100目筛, 放于-80 ℃冰箱待用。
1.2.1 光谱采集
光谱采集所使用的仪器是德国布鲁克光谱仪器公司生产的MPA傅里叶变换近红外光谱仪, 分辨率设为4 cm-1, 扫描范围4 000~12 000 cm-1, 扫描次数64次。 采用漫反射扫描。 每份叶片样品充分混匀后分为3等份, 分别扫描光谱后单独存放, 建模使用3份样品的平均光谱。
1.2.2 蛋白质含量测定
样品中蛋白质含量测定参照国家标准《GB/T 5511— 2008谷物和豆类氮含量测定和粗蛋白含量计算凯氏定氮法》。
1.2.3 总黄酮含量测定
样品中总黄酮的含量测定参考本课题组前期探索的紫外分光光度法进行[12]。
1.2.4 数据分析与处理
使用Matlab R2023b进行数据集的划分、 光谱预处理、 特征波长的筛选以及模型的构建。 建立模型时, 首先采用KS算法将总样本分别按3:1和4:1划分为训练集和测试集。 再采用CARS算法进行特征波段的筛选。 然后分别采用归一化、 归一化+标准正太变换(standard normal variate transform, SNV)、 归一化+多元散射校正(multiplicative scatter correction, MSC)、 归一化+SG平滑滤波(Savitzky-Golay smoothing filter, SG)、 归一化+一阶导数(first derivative)和归一化+二阶导数(second derivative)预处理光谱, 最后利用偏最小二乘法进行模型的构建。 验证方法为留一交叉验证法, 以交叉验证均方根误差(cross-validationroot mean square error, RMSECV)、 测试集均方根误差(root mean square error of the test set, RMSEP)、 训练集决定系数(coefficient of determination of the training set, Rc)、 测试集决定系数(coefficient of determination of the test set, Rp)、 剩余预测偏差(residual deviation of prediction, RPD)来选择最佳模型[13]。
为了提高建模的准确率, 建模的第一步就是样本集的划分。 有学者采用随机的方法将样本集划分为训练集和测试集两组, 不过分注意两组数据集的比例[14, 15]。 也有学者认为若随机划分样品集使得某个子集过度偏向特定类型的样本, 会造成子集均衡性不足, 不如使用KS算法和SPXY(sample set partitioning based on joint x-y distance)算法等合理的划分数据集[16, 17]。 本研究在建立总黄酮的近红外模型时, 发现使用KS算法将训练集和测试集以4:1的比例划分时, 总体建模效果较好, 其中训练集样本的最小值、 最大值和平均值分别是28.1、 92.5和55.8 mg· g-1, 测试集样本的最小值、 最大值和平均值分别是31.5、 99.8和71.0 mg· g-1, 而建立蛋白质的近红外模型时, 发现训练集和测试集的样品比例为3: 1时效果更佳, 其中训练集样本的最小值、 最大值和平均值分别是121.2、 331.0和169.6 mg· g-1, 测试集样本的最小值、 最大值和平均值分别是129.1、 183.0和158.2 mg· g-1(表1)。
| 表1 建模时使用的训练集与测试集数据 Table 1 Sample data for the training and test sets used in modeling |
扫描固体样本的近红外光谱时, 由于光散射和有效路径长度的不同, 会导致扫描得到的光谱数据存在一些不需要的变量和噪音, 因此建模前需要对光谱进行预处理以提高建模效果[18]。 共使用了6种方法预处理近红外光谱后提取特征光谱建模。 为了突出信号, 消除数据中非相关变量的影响[19], 建模过程对所有光谱都使用了归一化处理。 利用CARS算法将全波光谱划分为1 102个波段, 分别筛选特征波长, 利用偏最小二乘法进行建模, 模型主成分数为12时效果较佳。 从表2可知, “ 归一化+MSC” 、 “ 归一化+SNV” 和“ 归一化+一阶导数” 预处理光谱后所建立的模型RPD均大于1.5, 因此这三个模型是可用的。 从6个模型的相关系数(Rc、 Rp)、 RMSECV和RMSEP可知, 经“ 归一化+一阶导数” 预处理光谱后所建立的模型效果最好, 图1(a)为此预测模型建模时训练集和测试集的真实值和预测值回归图, 其Rc和Rp均大于0.93。 建模过程, 光谱被分成1 102个波段, 图1(b)为最佳模型的46个特征波段在全光谱中的分布, 特征波段主要分布在8 900~12 000 cm-1范围内, 特征波段占总光谱的4.2%。 Yu等[17]从256个波段中筛选了33个特征光谱区段用于总黄酮模型的建设, 也取得很好的建模效果。
| 表2 光谱预处理方法对荞麦总黄酮近红外模型的影响 Table 2 Influence of pretreatment methods on total flavonoid modeling |
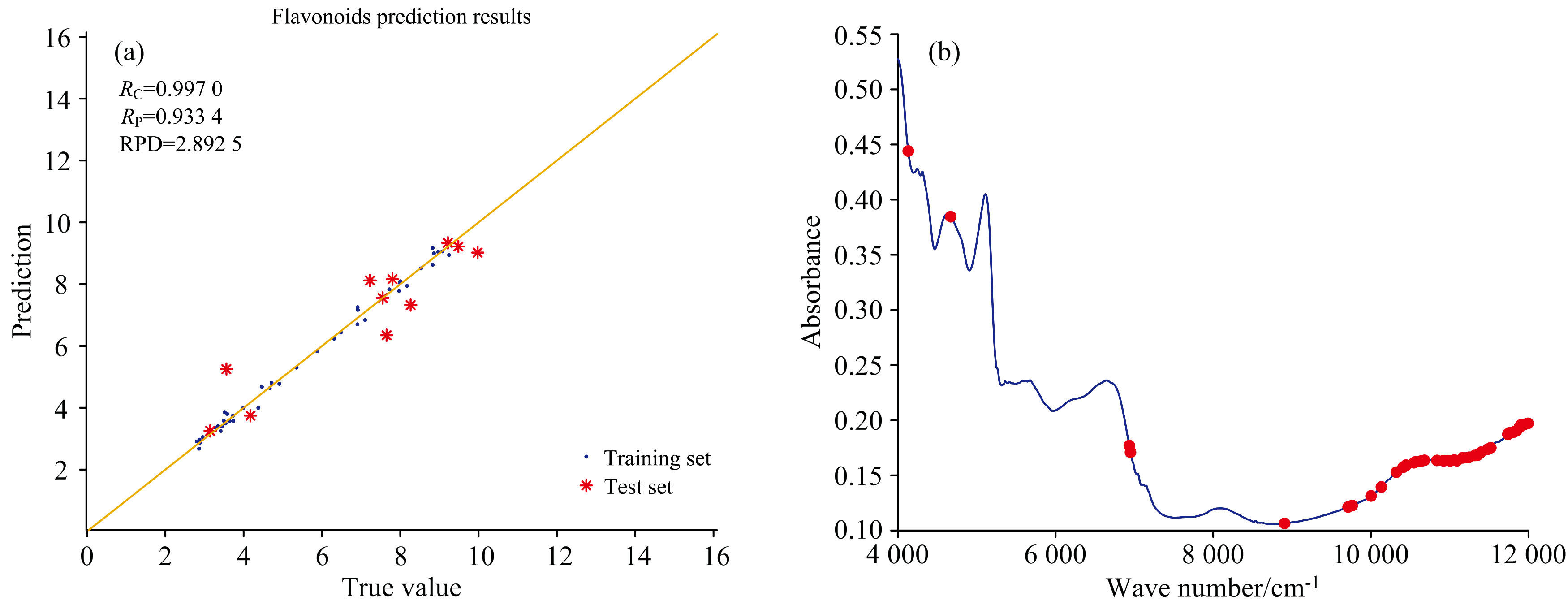 | 图1 (a)总黄酮真实值和预测值回归图; (b) 筛选的有效波长区段在原始光谱上的分布Fig.1 (a) Regression plot of true and predicted values of total flavonoid and (b) selection of characteristic wavelengths from the raw spectrum |
在建立蛋白质的近红外模型时, 使用不同的方法预处理光谱后, 利用CARS算法将全波长划分为1 102谱区, 分别筛选特征波长, 之后利用偏最小二乘法进行建模, 主成分数为12时所建立的模型最佳。 从表3可知, “ 归一化” 、 “ 归一化+MSC” 、 “ 归一化+一阶导数” 和“ 归一化+二阶导数” 预处理光谱后所建立的模型RPD均大于1.5, 因此这4个模型均是可用的。 从这4个模型的Rc、 Rp、 RMSECV和RMSEP可知, 经“ 归一化+二阶导数” 预处理光谱后所建立的模型效果最好, 其Rc和Rp均大于0.96, 从图2(a)可知此模型对未知样品的预测效果极好。 Yu等[17]从256个光谱区段中筛选了18个特征波段建立蛋白质模型, 使用了总光谱的7%。 前人的研究发现, 蛋白质的吸收波长波分布在10 987、 9 804、 6 623 cm-1等多个区域[20], 从图2(b)可知, 所建立最佳蛋白质预测模型, 从1 102个波段中筛选出42个特征光谱区段建模, 占总光谱的3.8%, 特征波段主要分布在4 000~7 000及9 800~12 000 cm-1范围内, 与前人的研究比较吻合。 相对于本课题组之前使用全波段光谱建模, 本次使用特征光谱所建立模型的Rc和Rp比之前分别提高0.06和0.02, 对未知样品的预测准确性有较大提高[6]。
| 表3 光谱预处理方法对荞麦蛋白质近红外模型的影响 Table 3 Influence of pretreatment methods on NIRS prediction results (protein) |
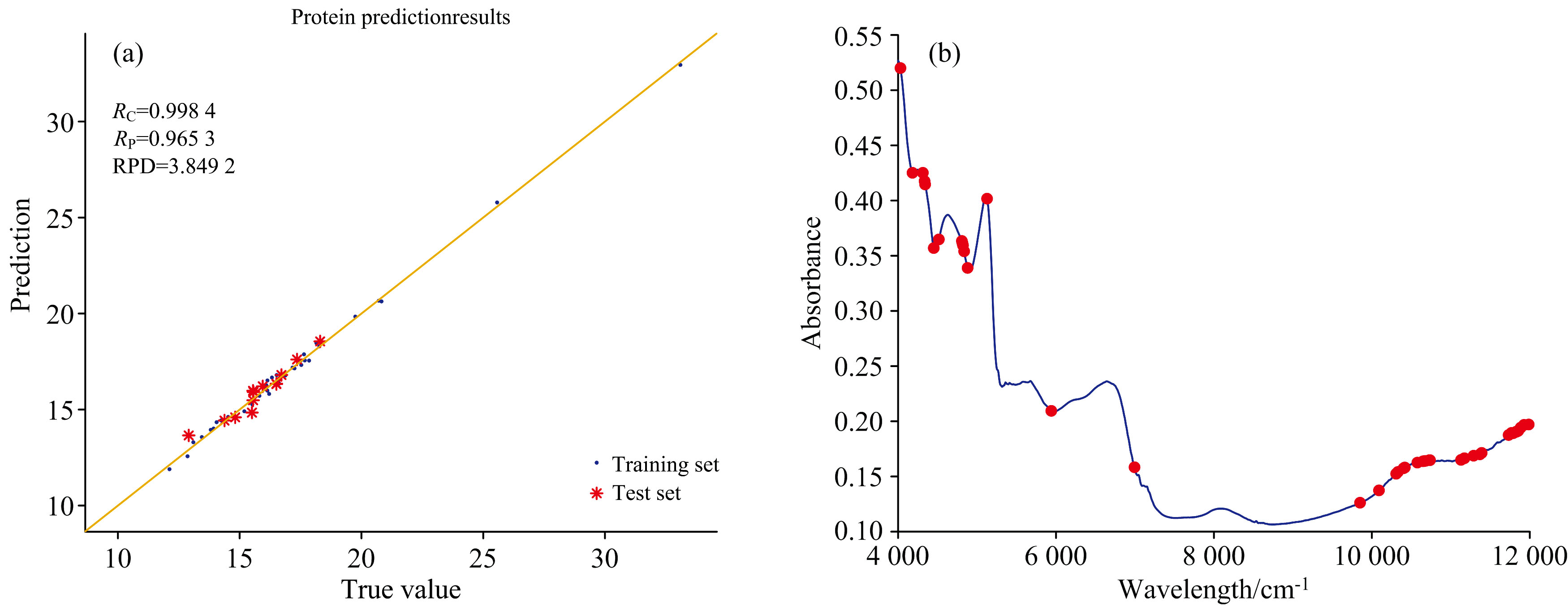 | 图2 (a)蛋白质真实值和预测值回归图; (b)筛选的有效波长区段在原始光谱上的分布Fig.2 (a) Regression plot of true and predicted values of protein and (b) selection of characteristic avelengths from the raw spectrum |
以53份具代表性的粉碎荞麦叶片为研究对象, 利用化学法测定其总黄酮和蛋白质含量, 利用KS算法划分样品集; 预处理光谱后, 用CARS算法提取样品的特征光谱, 再结合定量偏最小二乘法建立了荞麦叶片总黄酮和蛋白质的预测模型。 从模型的Rc、 Rp、 RMSECV、 RMSEP和RPD来看, 荞麦叶片中总黄酮和蛋白质含量都得到较好的预测效果。 总黄酮含量模型建设过程利用“ 归一化+一阶导数” 预处理光谱后, 再使用CARS算法从总光谱中选择了46个特征光谱区段, 主成分为12时, 其训练集和测试集的决定系数分别为0.997和0.933。 蛋白质含量模型建设过程利用“ 归一化+二阶导数” 预处理光谱后, 再使用CARS算法从总光谱中选择了42个特征光谱区段, 主成分为12时, 其训练集和测试集的决定系数分别为0.998和0.965。
理想的预测模型需要尽可能多且差异较大的样本。 本研究虽选用了差异较大的样本, 但整体样本量偏少, 为了使建立的模型应用更广泛, 课题组下一步拟仔细整理近年来收集自全球的荞麦种质资源, 筛选性状差异较显著的核心种质为建模材料, 进一步优化模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|