
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
柴油十六烷值近红外系统受控下数据质量目标的优化
[李颖1  , 潘志强
, 潘志强2 , 王斗文3, * ]
, 潘志强]
|
|


作者简介: 李 颖,女, 1976年生,大连产品质量检验检测研究院有限公司高级工程师 e-mail: 819818501@qq.com
柴油十六烷值近红外(NIR-CN)系统测试的数据质量目标(DQO)建模优化, 目前尚未见到成熟的研究成果。 为减轻匹配错误的综合基体效应和避免单水平无法控制的β风险, 本工作利用美国瓦克夏(Waukesha)十六烷值机数据进行比对。 经与幂律、 二次线性组合和斜率弧度的统计比较, 认为最大似然估计戴明回归(DR)的偏倚修正属于最佳合理拟合模型。 DR建模来自水平下加权中心平方和(CSS)二维数据的变量迭代, 其建立在随机变量独立同分布(i.i.d)假设检验的前提条件, 非视相关系数为模型拟合优劣的判断依据, 而是通过失拟效应和Anderson-Darling(AD)拟合优度检验。 这种检验能有效避免自相关函数(ACF)的累积冲击和交互干扰, 最大限度弥补控制图主观臆断趋势分析的目测不足。 研究结果表明, DR模型更符合NIR系统的DQO稳健性和实际情况。 NIR系统以往仅局限于CN单一水平讨论, 现扩展到多个水平的变异研究。 不同决策导致不同不确定度, 错误决策会遭致额外的成本损失。 随时间推移在风险与成本统一的原则下难免会出现CSS的重新选择, 只要后续测试满足NIR系统所设定的DQO随机扰动, 将使用条件产生的风险控制在所论证的CSS范围内即可。
The DQO modeling for the NIR-CN system has not yet seen mature research results, in which comparison with data from the Waukesha CN engine was conducted to alleviate the composite matrix effect of matching error and the uncontrollable β risk at a single level. Compared to the power function, quadratic linear combination, and slope radian angles, the DR bias correction model's maximum likelihood estimate is found to be the best-fitting line. The DR modeling, which was derived from the variable iteration of two-dimensional data weighted by the CSS, was established under the premise of the i.i.d. assumption. Consequently, the correlation coefficient cannot be regarded as the criterion for judging the model, but rather through the lack of fit and the AD goodness-of-fit test. This test can effectively mitigate the cumulative impact and interaction interference of ACF, and maximize compensation for the limitations of subjective trend analysis in control charts. The research results indicate that the DR model aligns more closely with the DQO robustness and the actual situation of the NIR system. The NIR system was previously limited to a single CN level discussion; now it has been expanded to study variations at multiple levels. Different decisions lead to different uncertainties, and wrong decisions will incur additional cost losses. Under the uniform principle of risk and cost, the variation of CN over time will inevitably lead to the choice of CSS. As long as the DQO set by the NIR system is subsequently met, the risk arising from the use conditions can be controlled within the demonstrated CSS range.
在柴油CN测试中, NIR系统(常规方法, 以下简称X法)是一种多元过程的关联模型测试, 常被用来替代笨重且昂贵的Waukesha十六烷值机操作(参考方法, 以下简称Y法)[1]。 在承担柴油调和的CN检验市场中, 在节能降费、 提质增效与风险的折中权衡, X法起到了不可忽视的重要作用。
基于Y法对X法的确认, 两种方法的测试原理完全不同。 无需努力评估两者分析技术的近似程度, 而是寻找其结果之间的一致性。 为降低人为偏性的实验方案设计需斟酌可用资源的分配, 双总体配对的分割水平采用, 能减少外界条件变化所产生的不同影响。 这种类似于随机处理的完全区组设计会涵盖更多变异源, 有助于总体误差之间的相互独立和偏离监控。
协同试验和能力验证非误差控制的有效方式, 重复性(r)太理想而再现性(R)过于保守, 本工作利用X法系统受控下的室内再现性(intermediate limit, R'), 最大限度覆盖时间和空间的广义重复, 以获得更多信息来推断总体[2, 3, 4, 5]。 X法和Y法之间的关联性不等于因果关系, 而是受制于某些隐藏的混杂影响因素所致, 尤其是当产生基质和交互效应作用时, 很难将其排除掉, 极易导致X法和Y法两者间拟合模型的失败。 然而, 当下某些学者一味地视相关系数为模型拟合优劣的判断依据, 可否将其理解为是一种仅可参考的商榷思路。
本工作根据汇集X法和Y法的CN数据集, 经坐标变换后论证, 幂律、 二次线性组合和斜率弧度统计均无法完成数据的自相关分析和偏倚修正。 经审慎的比较和思考, X法的DQO优化可考虑DR模型的CSS处理, 这种处理属于多单元等概率的分割水平时序设计, 最大限度代表已知或潜在变异源的预期总变异, 有助于较大范围内有价值的推断和预测、 以及现行系统的改进和风险控制。
NIR-CN测试系统研究的前提条件是, 满足线性可加模型的随机化设计、 以及避免交互作用产生的相关性趋势。 这种i.i.d状态的判断依然困扰目前的研究者。 当下频繁采用主观臆断的目测分析, 实属非纯粹意义上的假设检验。 为达到i.i.d的受控状态, 本工作利用AD拟合优度的检验[6, 7, 8, 9], 为解消假设的风险预控、 优化组合的有效决策和随机化处理提供了更合理的估计。
当采用DR回归模型进行偏倚修正时, 各种处理随区组不同容易质疑交互作用, 此时的NIR-CN系统必须实施AD检验, 以判断机遇的解消假设是否成立。
NIR-CN系统受控下的DQO靠不确定度度量。 为避免不确定度分析产生错误的结论, 不能仅停留在单水平估计的局限认知, 而是依靠多水平变异监控来支撑。 在坚持质量效益与客户需求一致性的原则下, 合理的不确定度宜为特定水平下给出最小成本的理想估计。
本工作针对某X法系统的CN长期测试中, 自实验室信息管理系统LIMS随机抽取了6人次提交的4水平样数据对结果(X法和Y法各自提交独立结果)。 见表1和表2。
| 表1 某X法与Y法的CN数据对变换 Table 1 CN data pair transformation of X method and Y method |
| 表2 交互效应检查与幂律建模 Table 2 Interaction checking and power modeling |
表1分别给出重复性标准差(sr)和室内再现性标准差(sR')。 避免sR'/sr之比出现水平依赖性, 利用sR'的对数关系寻找变换参数, 使得其效益化符合最佳加权拟合预测的估计。 变换后的数据集必须通过式(1)的AD拟合优度检验, 式(1)中, AD分为ADs(判断正态性和分辨力)和ADMR(判断独立性), ADMR计算有移动极差(MR)[10], pi为结果的累积正态概率。
表1中有, sR'/sr模型有p(斜率)< 0.05, 因无数据丢失可不必对sr变换。 但sR'具不等自由度的效应, 可寻找其最佳的变换估计参数。 变换值近似有
表2为交互效应分析和系统性能建模, 按式(2)— 式(4)计算。 s'2(单元间方差)见式(2), 其中的a=X+Y, n=2, S为每个样品所得结果的总数, P为参加人次。
R'2见式(3), 其中, β=
R'(原结果)见式(4), 其中
表2的F比值结果确保了交互作用影响减至最小。 根据式(2)— 式(4)求得R'(XY)=2.48
通过交互效应的评价建立了方法间的性能R'(XY)=0.26
基于表1的数据集, 表3给出了二次线性组合和斜率弧度的统计拟合。
| 表3 二次线性组合与斜率弧度的检查 Table 3 Check of quadratic linear combinations and slope radian |
表3的二次函数尽管接收AD的解消假设, 但回归参数对Y影响不大。
表3中的斜率弧度计算见式(5)和式(6)。
式(5)和式(6)中, β为斜率; SXX、 SYY和SXY分别为X法和Y法的数据偏差平方和、 以及两个变量协方差。
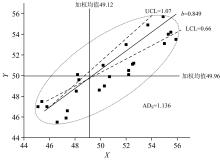
为验证方法间斜率的等效结果, 利用坐标旋转变换的弧度法, 通过正交最小二乘线性关系的角度盘, 将数据反变换为原尺度。 表3利用式(5)和式(6)求得, b(斜率)=0.849和a(截距)=7.446; ϕ=0.117 3; θ(弧度角)=0.702 6(与0.785 4有差异)。 由此求得上限和下限有LCL(θ)=0.585和UCL(θ)=0.820, 进而给出LCL(β)=0.66和UCL(β)=1.07。 接受(0.75-1.33)斜率等效假设, 但AD评价该模型系统失控。
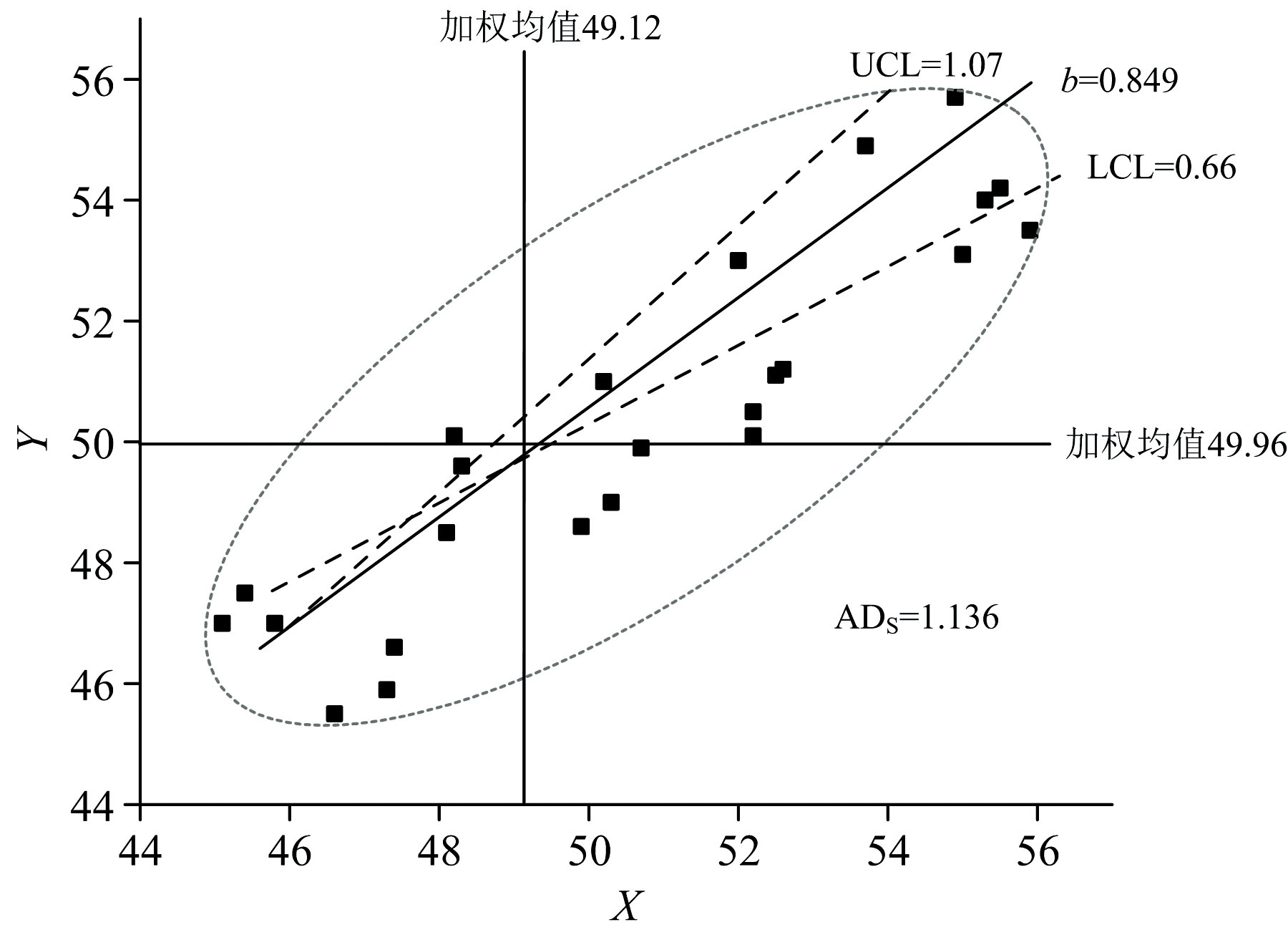 | 图1 方法间斜率正交回归的弧度检查Fig.1 The radian check of slope orthogonal regression between different methods |
1.3.1 CSS的理解
在柴油过程流体的CN分析中存在太多的变量, 确保测试系统的i.i.d状态不是一件容易的事情。 毕竟X法属于非标系统, 最佳的办法是同时估计X和Y的误差, 找准残差变量间的函数关系f(x), 考察实际X与理论Y的符合程度, 确立X法实时测量的一致性和可靠性。 见图2。
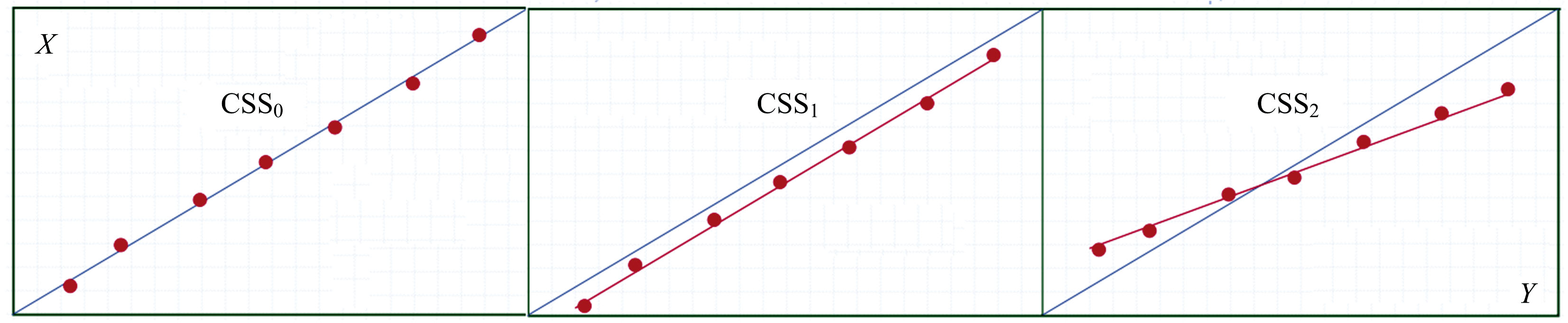 | 图2 方法间CSS拟合Fig.2 CSS fits between different methods |
图2的解释有如下说明:
无偏函数有
常数函数有
鉴于CN的0特性值无物理意义, 故未纳入比例函数的CSS拟合。
线性函数检验是否符合随机变量
1.3.2 DR模型的有效性评价
自LIMS系统在45-56(CN)水平范围内, 前一个阶段按时间序列随机抽取了X法和Y法水平下20个数据对结果, 见表4。
| 表4 两个阶段数据对的CSS评价与选择 Table 4 CSS evaluation and selection of data pairs for two phases |
表4中的解消假设为CSS0, 而更多的是备择假设。 通过加权迭代的函数权重推导, 进行数学变换和线性修匀的平滑逼近。 方法间CSS残差加权回归量化的选择计算有如式(7)和式(8)判断公式。
式(7)的F为失拟效应检查, 可通过F单侧备择假设判断; 式(8)中若t2接受备择假设则选CSS2, 反之看CSS1。 若t1绝原假设选择CSS1, 反之用CSS2。
式(9)的ε为所选CSS模型的系列残差; w为所选CSS模型的加权值;
在表4中, 前一个阶段按时序抽取的20个数据对, 利用功效0.90的双单侧区间Δ偏倚检查, 发现超出业内设定的± 3, 方法间需建立偏倚修正。 因式(8)的计算有t2=1.28和t1=0.50, 均小于t临, 则选择Y=0.83X-0.22的拟合, 且CSS2=19.27< χ2=28.9。
但由式(7)得知F=0.95< 3.55, 表明Y=0.83X-0.22无法改进X法和Y法的一致性。 更严重的是, 由式(1)和式(9)给出ADs=1.607和ADMR=2.732, 完全拒绝系统具有良好的正态性、 分辨力和独立性假设。
在表4第一阶段数据集的基础上, 后续跟进增加了10对时序数据, 形成第二阶段的30个数据对。
尽管表中的Z(X)标准评分有
表4中的CSS2最终求得b=0.570 3, a=-0.071。 由式(7)和式(8)得知, F=4.76> 3.34, t2=3.08> 2.05, 即利用Y=0.57X-0.07(CSS2=39.4< χ2=41.3), 可以改进X法和Y法之间的预期一致性。
由式(1)和式(9)给出ADs=0.564和ADMR=0.658, 表明95%概率下方法间残差系统的良好正态性、 分辨力和独立性假设成立。
DR模型的性能评价见式(10)
其中的R'(XY)为方法间共享的室内再现性; b为所选CSS模型的斜率。
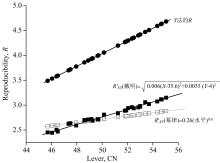
表4有模型s(X)=0.66+0.07(X-45)和s(Y)=1.23+0.03(Y-45)。 根据式(10), 两个模型经合并整理后有R'(XY)=
Y法规定的R[1](括号内为CN值)有: 40(2.8), 44(3.3), 48(3.8), 52(4.3)和56(4.8), 见图3。
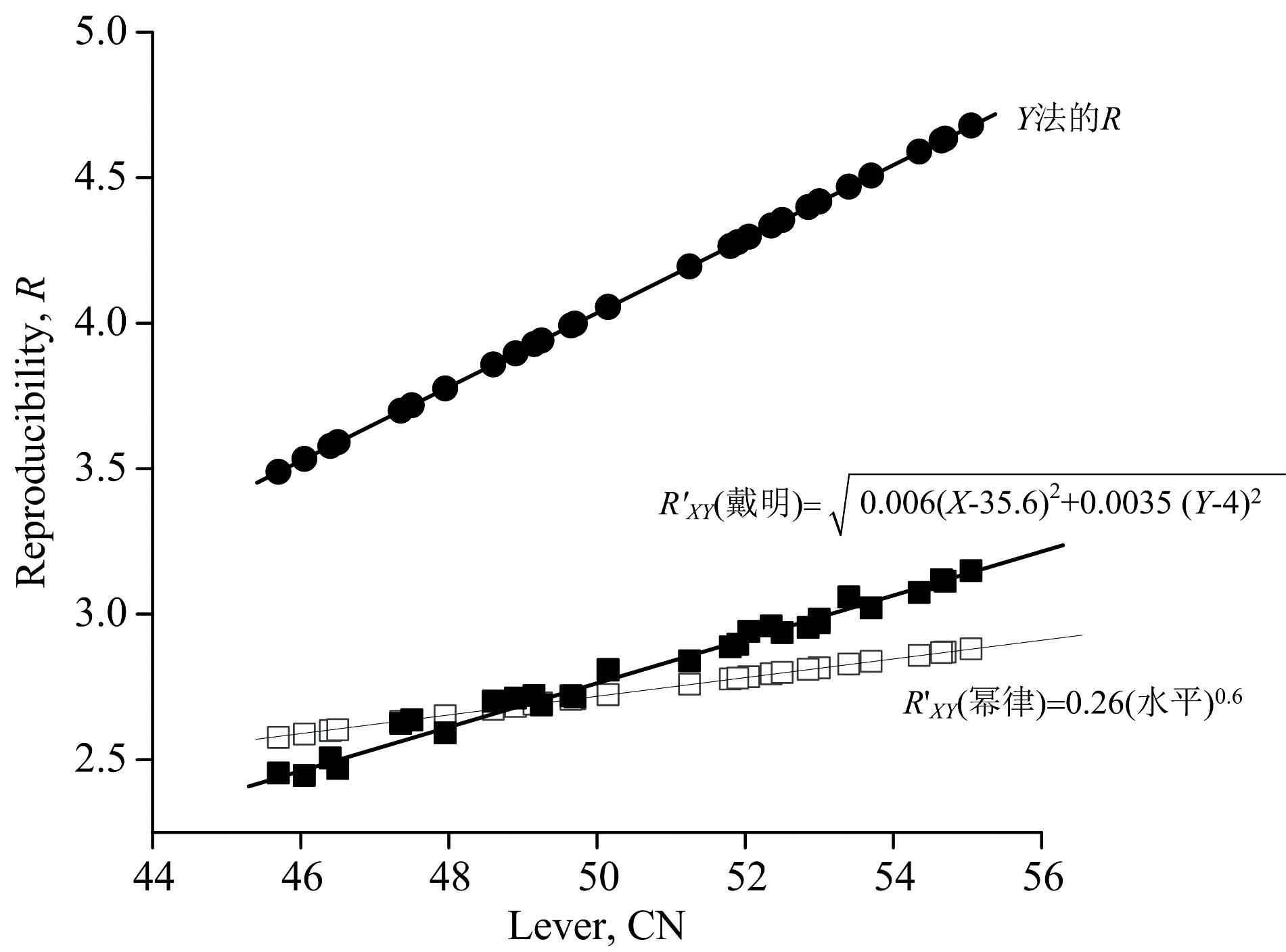 | 图3 幂律和DR模型受控下45-56(CN)水平测试的DQO性能比较Fig.3 Comparison of DQO performance on 45-56 (CN) testing from power and DR model in control |
图3中给出R'(XY)=0.26
数据集变换后需要做单变量广义极值学生化偏差GESD技术检查, 这种检查是一种四分位数回归分析的多离群值测算法。 GESD首先明确疑似离群值数的上限, 通过比较每个数据点标准化残差与预测阈值之间的偏差, 来予以识别异常值。
离群值的检测算法有多种手段和方法, 例如有曼德尔的h和k统计量、 数值方法、 何克伦(Cochran)和格拉布斯(Grubbs)检验等。 因解释离群点的意义经常发生多义性, 且现实情况下数据集相互掩盖的异常值不止一个, 则本工作建议在X法和Y法的离群值检验中, 采用掩蔽现象具有较好抵抗能力的GESD检测技术为宜。
不同于Grubbs和Cochran两端极值剔除的检验, GESD在错误概率0.01的决策准则下能同时识别出多个异常值, 该检查信息量大, 可防止数据被过度甄别处理。
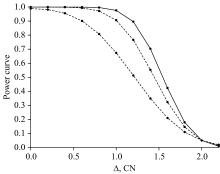
表4中第一阶段的数据对样本量为n=20, 第二阶段的数据对样本量为n=30, 样本量的设计可通过检出功率曲线来判断[11]。
图4的检出功率曲线表明, 第二阶段的30批次样品量设计具有其合理性(n=30为收益递减的可接受点, 以低成本投入争取DQO优化的高效益)。 图中所示, 输入变量的消费者风险0.05, 对称限± 2, 样品设计2和Z(α)=1.645。 样本量设计目标90%不应太低, 其中检出功效1-β 承担了接收错误的风险。 图中的三条曲线从左至右分别表示n=10(折线)、 n=20(折线)和n=30(实线)的样本量, 并在点(2, 0.05)相交。 这些曲线处于柴油45-56(CN)的NIR测试范围, 功效曲线越右移, 越容易接受Δ(绝对差)的等效检验。
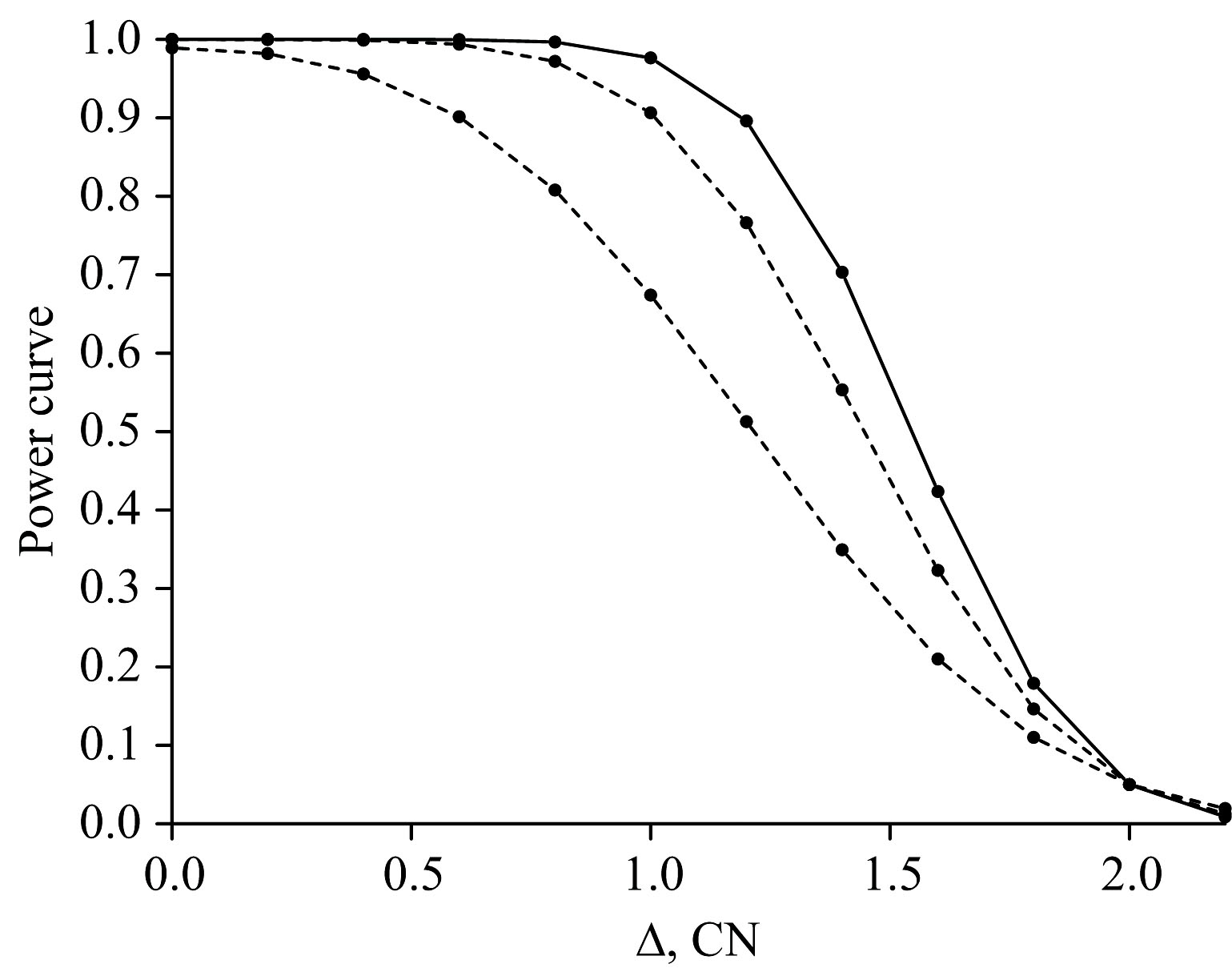 | 图4 不同功效曲线下的样本量选择Fig.4 Sample size selection for different power curves |
图4的观察时间和成本、 输出对异常的响应速度(过程动态)以及对反应不及时的后果, 这些都是考虑采样的实际因素。 采样频率过高也会导致连续子群间的自相关性。 所以, 应根据两种风险和错误决策成本的可接受水平, 来做权衡。 显然, 第一阶段的Δ取n=20功效是勉强的, 而第二阶段共有n=30则大于90%, 说明取Δ的实验失败风险小于10%。
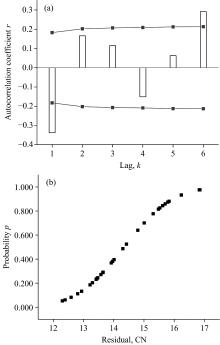
X法和Y法的系统已接受i.i.d状态下正态性和独立性的解消假设, 可不必按数学模型传播法(bottom-up)的思路来评定每个水平的变异。 配合休哈特管控图的ACF目测分析[见图5(a)], 本工作更关注式(1)重尾分布修正的二次统计量ADMR检验[见图5(b)]。
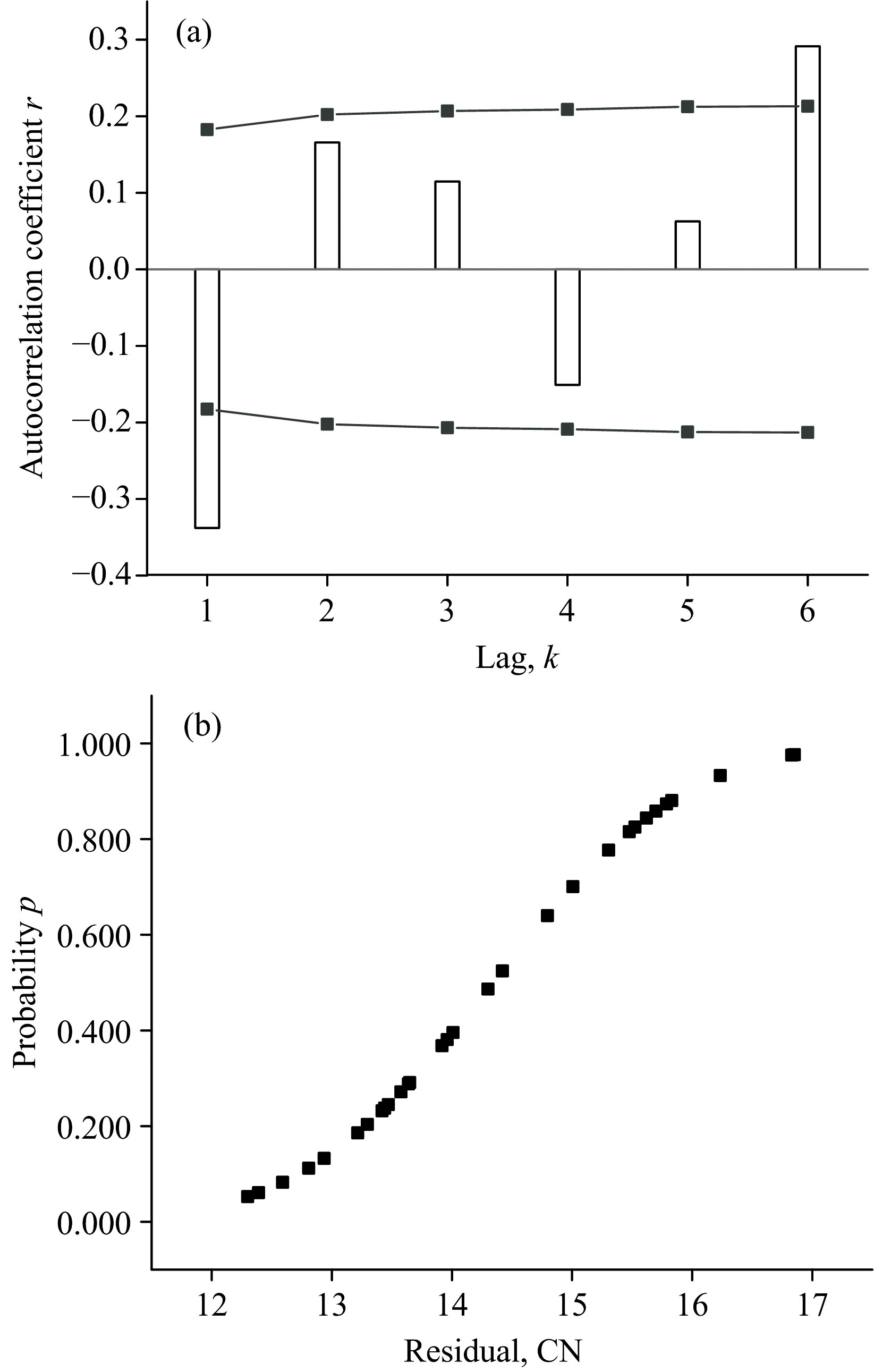 | 图5 方法间系列残差的自相关趋势分析 (a): 阶滞后序列的ACF图; (b): ADMR检查的概率图Fig.5 Autocorrelation trend analysis of series residuals between methods (a): ACF of the lagged sequence; (b): Probability of the ADMR check |
有别于均值分布趋于正态的连续性, 独立性指一个随机变量的发生对另一个随机变量不存在影响, 可利用图5(a)做目测分析。 图中6个时滞数值(括号内为各自的上下控制限): -0.337 8(± 0.182 6)、 0.165 7(± 0.202 3)、 0.114 7(± 0.206 8)、 -0.151 0(± 0.208 9)、 0.062 6(± 0.212 5)和0.291 4(± 0.213 1)。 这些因受到累积冲击效应的干扰或交互所增加的不稳定性, 非通过校准给予消除, 且任何变换不能形成平稳时序, 导致性能无法确定。
随机过程的数字特征中存在ACF函数, 刻划两个不同时刻之间的线性依从关系。 即系列残差t1和t2的线性依从仅与(t2-t1)有关, ACF为单变量(t2-t1)的函数。 这种随时间推移呈现一致向下或向上的变异趋势, 解释为变量与自身、 或前后数值之间的相关, 在数学上表明各时刻的变量相互独立(依赖于随机变量在时间上分布)。 期望时序来自独立白噪声过程、 以及随滞后的增加而结果接近于0(以往间隔对当前影响不大)。 若协方差不等于0, 可调整样本结果的抽取次数不要过于靠近而产生趋势, 导致残差在时序中产生自相关。
图5的ACF图发现不同滞后阶数出现不一致的现象(期望各时间步骤之间的相关性随时间增加而减少趋于消失)。 根据以往判断似乎存在一种趋势, 表明解释变量随着滞后阶数的增加而增大(第一滞后超限)。 ACF的主观目测分析能否确定为平稳无趋势尚待敲定。
为配合ACF的作图分析, 本工作建议直接采用MR逐次差分(递差)消除短期波动的ADMR检验来发现问题。 图5(b)有配合分析ADMR=0.658, 表明在没有确凿的物理证据下, 可以保留数据对的函数样本集拟合, 断定分布滞后回归模型中相邻观测值的随机扰动得到保障。
ADMR检验的累积分布函数线性化[见图5(b)], 取决于原假设的统计函数值是否落入α错误率下拒绝域内, 见式(1)。 α阈值来自经验累积分布函数Fn(x)与原假设F0(x)两者间的差异, 权函数在分布F0两端取大值。 所选分布拟合与非参数阶梯函数之间区域的度量, 视为AD统计量的平方距离。 通过递推计算求得分布函数的线性化。 根据大量现场数据集的试验而确定的临界分别有0.752(95%概率)和1.032(99%概率)。 表4的数据集即利用这种递推来度量随机样本与理论PDF的兼容性, 其统计有ADs=0.564和ADMR=0.658, 表明没有理由拒绝系统呈正态、 独立和响应适宜的统计假设。
不稳定性是NIR-CN系统测试的常见问题。 例如, 部件的老化、 数据分辨力、 软件程序和环境变量的变化等, 造成任意t时刻数据受到所有随机冲击的累积影响增大。 所以, ADs和ADMR的拟合优度检验不可忽视。
针对预测和依赖变量模型, 其决定系数仅做比较而言, 不能作为模型度量的判断准则。 当两个变量均存在误差时, 采用幂律、 二阶与斜率函数的拟合需审慎。
DR回归模型同时涉及到X和Y的两者误差[R'(XY)], 能正确发现二维数据集的最佳拟合。 NIR-CN系统所设定的DQO目标是否合理, 非取决于DR模型的决定系数度量, 而是建立在i.i.d随机受控前提条件下。 所以说, NIR-CN测试系统的DR建模是通过严谨的CSS偏倚修正和AD拟合优度检验完成的。 其中, 为避免两类风险和有限信息可能导致模糊推理的非随机性, 尤其注意ACF的滞后目测和时序的ADMR递归计算(见图5), 这种AD检查描述了尾部频率阶跃函数权重在累积经验分布下的符合程度。
DR回归模型提出的R'(XY)=
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|