
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱结合支持向量机算法的砂岩岩性识别
[焦龙1  , 李莹
, 李莹1 , 仝容超2 , 王彩玲3 ]
, 李莹|
|


作者简介: 焦 龙, 1980年生,西安石油大学化学化工学院教授 e-mail: mop@xsyu.edu.cn
准确识别砂岩的岩性在资源勘探、 地质工程以及建筑材料研究等领域至关重要。 高光谱是近年来发展迅速的一种具有图谱合一、 信息量大、 分析速度快、 无损检测等优点的新兴分析手段, 克服了传统分析方法时间长、 程序复杂等问题。 支持向量机(SVM)方法具有强大的学习和泛化能力, 是一种快速、 准确的分析方法。 因此, 通过高光谱分析结合支持向量机建模建立了不同岩性砂岩的识别方法。 收集了4类不同岩性的砂岩样品, 采集其高光谱数据; 用标准正态变量变换(SNV)、 多元散射校正(MSC)、 Savitzky-Golay平滑方法分别对高光谱数据进行预处理; 之后分别采用偏最小二乘判别分析(PLSDA)和SVM方法建立分类模型。 在SVM模型中, 选择高斯核函数(RBF核)建立SVM分类模型, 用网格搜索法对SVM中的惩罚参数 C和核函数gamma参数进行优化, 确定 C的取值为(0.1、 1、 10、 100), 径向基函数gamma参数为(0.01、 0.1、 1、 10), 共形成16种参数组合, 分别建立分类模型, 最佳PLSDA和SVM模型的五折交叉验证分类准确率达到93.20%和96.40%。 建立的最佳MSC-PLSDA以及SNV-SVM模型均能较准确识别测试集样品, MSC-PLSDA模型的测试集分类准确率达到89.00%, 模型对应的 F1值均达到80%以上; MSC-SVM模型的测试集分类准确率达到96%, 模型对应的 F1值均达到90%以上, 其中泥质砂岩和细粒砂岩的识别准确度最高, F1值达到100%。 结果表明, 高光谱技术结合支持向量机方法是一种可靠的砂岩岩性识别分析方法, 且光谱预处理方法对识别准确度有显著的影响, 为砂岩岩性识别分析体系提供了一种新思路。
Accurate identification of sandstone lithology is crucial in resource exploration, geological engineering, and building material research. Hyperspectral is an emerging analytical method with the advantages of spectral integration, a large amount of information, fast analysis speed, and non-destructive testing. It overcomes the problems of long time and complex procedures of traditional analytical methods. The support vector machine (SVM) method has strong learning and generalization ability, and is a fast and accurate analysis method. Therefore, hyperspectral analysis combined with support vector machine modeling established the identification method of different lithological sandstones. Four types of sandstone samples with different lithologies were collected, and their hyperspectral data were collected. Hyperspectral data were preprocessed by standard normal variable transformation (SNV), multiple scattering correction (MSC), and Savitzky-Golay smoothing method (SG), respectively. After that, partial least squares discriminant analysis (PLS-DA) and SVM methods were used to establish classification models. In the SVM model, the Gaussian kernel function (RBF kernel) is selected to establish the SVM classification model. The grid search method optimizes the penalty parameter C and the kernel function gamma parameter in the SVM. The value of C is determined to be (0.1, 1, 10, 100), and the radial basis function gamma parameter is (0.01, 0.1, 1, 10). 16 parameter combinations are formed, and the classification models are established respectively. The five-fold cross-validation classification accuracy of the best PLSDA and SVM models reaches 93.20% and 96.40%. The best MSC-PLSDA and SNV-SVM models established can accurately identify the test set samples. The classification accuracy of the test set of the MSC-PLSDA model reaches 89.00%, and the corresponding F1 values reach more than 80%. The classification accuracy of the test set of the MSC-SVM model reaches 96%, and the corresponding F1 value of the model reaches more than 90%. Among them, the recognition accuracy of argillaceous and fine-grained sandstone is the highest, and the F1 value reaches 100%. The results show that hyperspectral technology combined with the support vector machine method is a reliable method for sandstone lithology identification and analysis, and the spectral preprocessing method has a significant impact on the identification accuracy, which provides a new idea for sandstone lithology identification and analysis systems.
识别砂岩岩性可以帮助了解地质沉积环境和储层特征, 是石油勘探和开发过程中的重要任务。 传统的的砂岩岩性识别方法是通过分析岩石的矿物成分结构和质地来确定其类别[1], 但当砂岩的矿物成分复杂且含量差异细微、 结构纹理呈现出高度的相似性、 质地受后期影响而发生显著改变时, 这些方法的识别结果常常不够准确[2]。 因此, 需要构建一种可靠、 准确的识别不同岩性砂岩的标准化方法。
近年来, 光谱分析结合机器学习算法在岩性识别分析领域得到了普遍运用。 Xu[3]等对砂岩在不同波段下的光谱特征, 包括可见光、 近红外和短波红外等波段进行了研究, 并将岩石图像和岩石元素数据深度融合, 实现了对石英岩和长石砂岩等岩性的分类识别, 所有岩性的平均FI值达到84.44%; Liu[4]等利用热红外高光谱技术采集不同岩性的热红外高光谱数据, 建立了随机森林(RF)、 支持向量机(support vector machine, SVM)和CNN等多种机器学习算法模型进行不同类别岩性的分类, 其中CNN模型性能最佳, 最高分类准确率达到了98.56%; Wang[5]等将卷积神经网络和长短期记忆网络相结合, 最终建立测井曲线与岩性类型之间的映射关系, 实现复杂岩层中各岩石的岩性的分类识别; Song[6]等系统对比了沉积岩、 变质岩、 热变质岩和煤岩的光谱特征, 揭示了不同类型岩石在光谱特征上的显著差异及其强弱关系, 为准确区分和识别不同类型岩石提供了理论依据和实践指导; Wang[7]等利用光谱匹配法对矿区岩性进行分类, 采用三种CNN模型进行特征提取和分类, 其中VGG-19模型的分类准确率最高, 达到87.3%, 得出研究区内花岗岩分布最广, 其次为闪长岩、 安山岩和石英岩。 然而, 关于高光谱技术应用于砂岩岩性分析的报告却鲜有报道。
高光谱是近年来迅速发展的一种具有图谱合一、 分辨率高、 信息量大、 分析速度快、 无损检测等优点的新兴分析手段[8, 9, 10], 现已被应用于识别花岗岩、 沉积岩、 变质岩等岩样[11, 12, 13]。 因此, 高光谱技术为砂岩岩性识别提供了可行方案。
支持向量机(support vector machine, SVM)具有训练速度快、 处理高维数据不易出现过拟合现象、 对噪声数据的鲁棒性、 以及具备处理非线性问题的能力等优点[14, 15], 已被广泛用于高光谱建模[16, 17]。
因此, 本工作旨在探索不同种类砂岩的高光谱识别方法。 采集四类不同岩性砂岩的高光谱, 对高光谱数据进行预处理, 以预处理后的光谱数据作为输入变量建立SVM分类模型对四类砂岩进行识别。
FieldSpec4型便携式地物光谱仪(ASD公司, 美国)。
四种砂岩样品均于陕西省西安市蓝田县灞河地区取心井钻取获得。 其中, 四类砂岩共计80个。 对选取的4类岩心进行切片打磨处理, 最终得到实验用样品。
将砂岩样品置于地物光谱仪的样品夹中进行高光谱采集。 首先, 将仪器预热30 min, 使用标准白板对其进行校正; 选择1 800~2 400 nm的波段进行砂岩样品的高光谱分析, 光谱分辨率为1 nm。 为保证光谱测量的准确性, 每个样品上取十个测量点, 将平行采集3次的平均光谱数据作为样品的光谱, 最终共获得800组光谱。
标准正态变量变换、 多元散射校正、 Savitzky-Golay平滑方法是近年来几种较常用的光谱预处理方法, 是增强光谱特征的有效手段[18, 19]。
标准正态变换(standard normal variate, SNV)通过对每个波长上的数据应用标准正态变换, 使其转换为符合标准正态分布(均值为0, 标准差为1)的数据[20]。 这有助于在分类任务中更好地区分不同的光谱特征。 如式(1)
式(1)中,
多元散射校正(multiplicative scatter correction, MSC)主要用于处理高光谱数据中由于散射效应引起的变化, 以提高数据的可解释性和分析精度[21]。
首先, 计算光谱数据的均值, 作为理想光谱
其次, 将每个样品的光谱数据对照标准光谱进行一元线性回归
最后, 进行多元散射校正后的光谱计算公式
式(4)中, R为n行m列光谱矩阵, 样本光谱数据总数为n, 波长个数为m;
SG平滑(Savizkg-Golag平滑, SG)是一种常用的多项式拟合方法, 它在每个滑动窗口内(通常为奇数个数据点)拟合一个低阶多项式来估计平滑后的值, 并在过程中调整多项式的阶数和窗口大小, 从而适应不同类型和频率的数据变化, 具有更好的保留信号特征和减少噪声的能力。
波长j经过平滑处理后的值
式(5)中, hk表示平滑系数, H为归一化因子, 其表达式为
1.4.1 偏最小二乘判别分析
偏最小二乘判别分析(partial least squares discriminant analysis, PLSDA)算法在众多领域中展现出了广泛的应用价值和优势, 尤其在处理线性可分的分类问题中尤为显著[22]。 因此, 首先使用该方法建立砂岩岩性识别模型。
PLSDA核心思想是寻找一组新的潜在变量, 最大化响应变量(类别标签)与预测变量之间的协方差。 通过迭代算法, PLSDA逐步提取出最优潜在变量并利用其建立一个判别模型, 用于对新的数据进行分类预测。 如式(7)
式(7)中, X是自变量矩阵(光谱数据矩阵), Y是因变量矩阵(类别矩阵), ω是初始化的与Y相关的权重向量。
1.4.2 支持向量机
支持向量机算法通过寻找最优超平面来进行分类或回归任务。 其性能受到核函数类型和参数设置的影响, 尤其是核尺度和框约束级别。 对于非线性分类问题, SVM通过使用核函数将输入的数据集映射到高维空间, 在空间中求解最优分类面得到决策函数, 从而得到全局最优解。 见式(8)和式(9)
式(8)和式(9)中: η为超平面斜率, 是一个n维向量, ξ为松弛变量, C为惩罚因子。
混淆矩阵[23](confusion matrix)是衡量分类模型准确度基础方法之一。
以二分类实验为例, 模型混淆矩阵如表1所示, 其中TP(true positive)表示模型预测正确的正例数量, FN(false negatives)表示模型预测错误的正例数量, FP(false positives)表示模型预测正确的负例数量, TN(true negatives)表示模型预测错误的负例数量。
| 表1 混淆矩阵 Table 1 Confusion matrix |
准确度(accuracy)和F1值是通常用于模型评估的指数。 准确度是指正确识别的样本数量与样本总数的比值, F1值从本质上衡量了模型在正类预测上的综合性能, 它的值介于0和1之间, 越接近1, 表示模型具有更高的性能。 计算公式如式(10)
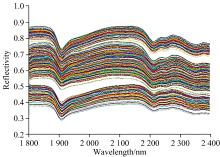
图1所示为四类砂岩样品的高光谱图。 通过对比可知, 不同岩样的高光谱存在差异。 这是由于不同岩性砂岩本身具有不同的化学组成, 导致光谱差异[24]。 但很难直接根据光谱区分不同岩性的砂岩样品。 因此, 需要采用机器学习方法对高光谱数据进行分析以识别不同岩性的岩样。
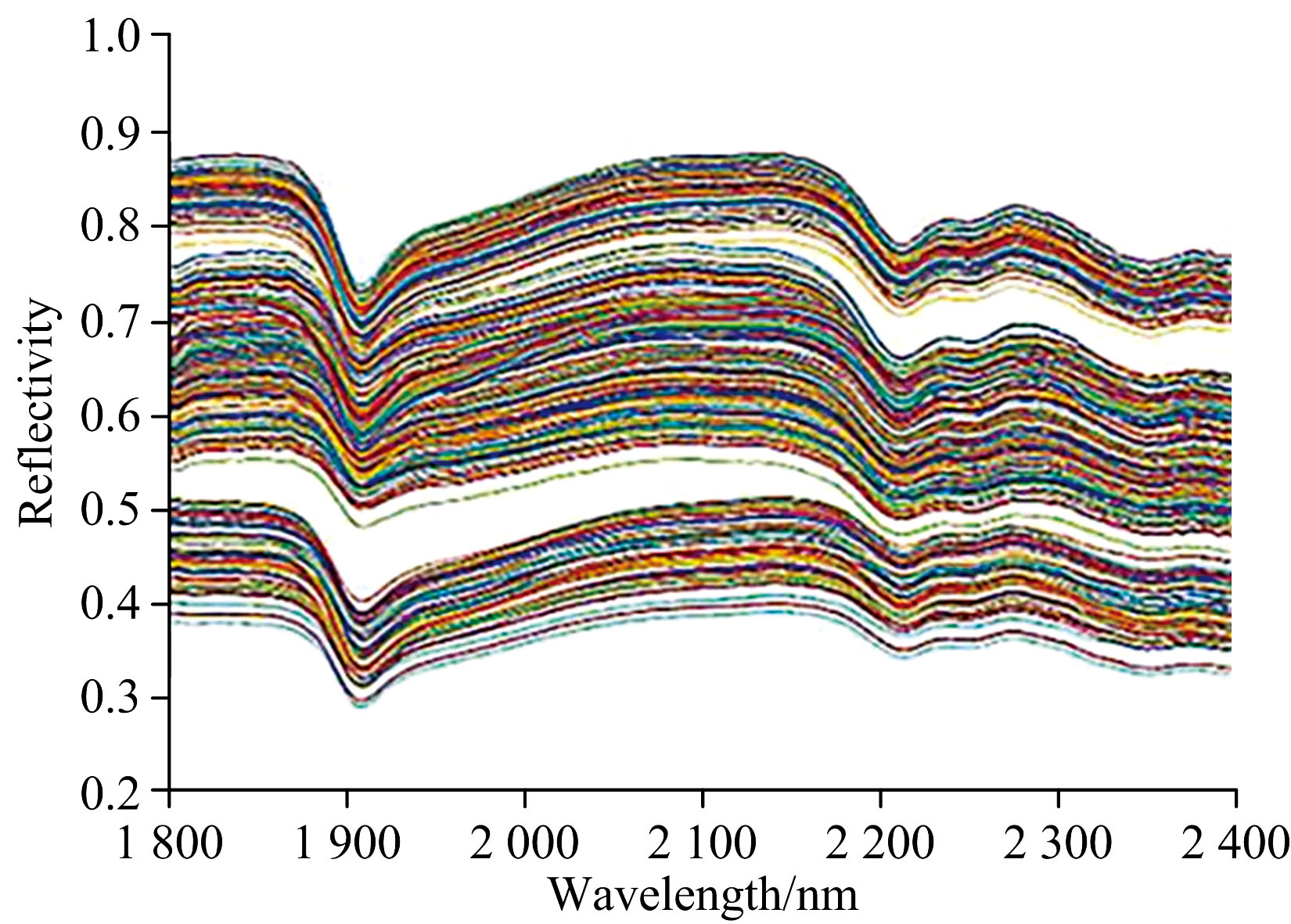 | 图1 四类砂岩样品的原始高光谱Fig.1 The Original hyperspectra of four types of sandstone samples |
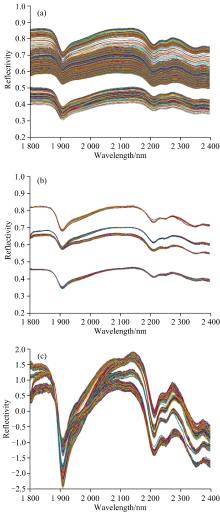
为了消除仪器噪声和随机因素的干扰, 对原始光谱分别进行SNV、 MSC和SG平滑预处理, 以降低噪声, 增强光谱响应, 提高模型准确度。 预处理后的高光谱反射率图如图2所示。
 | 图2 预处理后高光谱反射率图 (a): SG预处理; (b): MSC预处理; (c): SNV预处理Fig.2 Hyperspectral reflectance spectra of four types of sandstone after pretreatment (a): SG; (b): MSC; (c): SNV |
采取随机抽样的方法将数据分为600组光谱的训练集和200组光谱的测试集。 将不同预处理后的砂岩数据分别作为输入变量, 采用SVM算法和PLSDA算法建立砂岩岩性识别模型。 在SVM模型中, 通过调整惩罚参数C和核函数gamma参数从而使模型达到最佳的分类效果。 选择高斯核函数(RBF核)建立SVM分类模型, 用网格搜索法对SVM的惩罚参数C和核函数gamma参数进行优化, 以提高分类的准确性和可靠性。 步骤如下:
选择不同的惩罚参数C(0.1、 1、 10、 100)和径向基函数gamma参数(0.01、 0.1、 1、 10), 共形成16个组合。 采用16个参数组合分别建立SVM模型, 进行五折交叉验证, 以确定最佳参数组合。
分类模型中不同参数组合对应的五折交叉验证结果如图3 所示, 可知在SNV-SVM模型中当C=10且gamma=0.1时, 验证集的准确率最高。
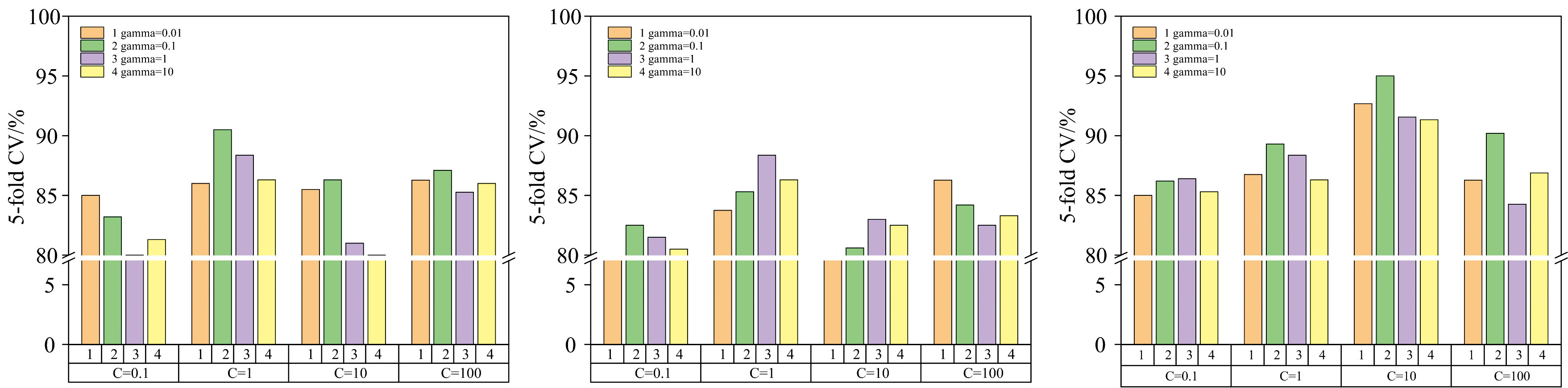 | 图3 SVM模型中不同超参数组合对应的五折交叉验证结果 (a): MSC-SVM; (b): SNV-SVM; (c): SG-SVMFig.3 5-fold cross validation results corresponding to different parameter combinations in SVM models (a): MSC-SVM; (b): SNV-SVM; (c): SG-SVM |
不同预处理方法结合PLSDA和SVM的模型识别准确率结果如表2所示。 从表2可以看出, MSC-PLSDA和SNV-SVM的识别效果较好, 验证集准确率分别达到93.20%、 96.40%。
| 表2 不同分类模型的识别准确率 Table 2 The recognition accuracies of different classification models |
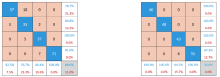
采用建立的PLSDA模型和SVM模型对测试集样品进行分类, 所得分类结果的混淆矩阵和F1值结果见图4及表3。 可知两模型对四类砂岩都取得了较好的识别结果。 SNV-SVM模型的识别准确度更高, 达到了96.0%, 此时模型对应的F1值均达到90%以上。 其中, 泥质砂岩和细粒砂岩的识别准确度最高, F1值达到100%。
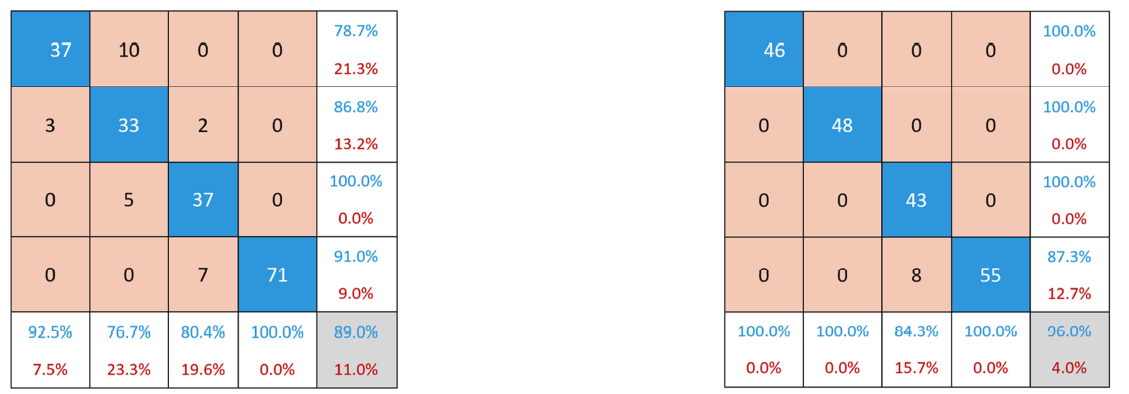 | 图4 (a)MSC-PLSDA模型测试集混淆矩阵; (b) SNV-SVM模型测试集混淆矩阵Fig.4 (a) MSC-PLSDA model test set confusion matrix; (b) SNV-SVM model test set confusion matrix |
| 表3 模型中不同砂岩类别对应的F1值 Table 3 F1 values in the model corresponding to different sandstone types |
所建立的SVM模型比PLSDA模型准确度高, 这可能是由于PLSDA是一种线性方法, 虽然可以通过一些扩展来处理一定程度的非线性问题, 但在处理高度非线性数据时可能不如SVM有效, 且在小样本数据的分类问题中, SVM能够通过选择关键的支持向量来构建模型, 避免对所有数据点的过度拟合。
通过研究建立了不同岩性砂岩的高光谱识别方法。 首先对不同岩性砂岩样品进行高光谱数据采集, 通过SG平滑、 SNV、 MSC预处理, 分别建立PLSDA和SVM分类模型。 结果表明, 基于SNV-SVM模型识别效果最佳, 该模型测试集准确率达到了96%, 同时对各类砂岩对应的F1值也最高。
由此可见, 高光谱结合SVM算法应用于砂岩岩性识别具有良好的可行性, 这是一种简便、 准确、 高效的砂岩岩性识别新方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|