

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多尺度空间-光谱特征提取的颜料高光谱图像分类方法
[汤斌1  , 罗希玲
, 罗希玲1 , 王建旭1 , 范文奇2, * , 孙玉宇1 , 刘家路2 , 唐欢2 , 赵雅3, * , 钟年丙1 ]
, 罗希玲, 孙玉宇, 钟年丙|
|


作者简介: 汤 斌, 1985年生, 重庆理工大学重庆市光纤传感与光电检测重点实验室副教授 e-mail: tangbin@cqut.edu.cn
颜料不仅赋予文物色彩和美感, 更承载着丰富的历史、 文化与技术信息, 因此对颜料的准确分类与识别是古代彩绘作品修复、 保护及学术研究的重要基础。 通过检测颜料的种类与化学成分, 不仅能帮助确定作品的创作年代、 地域特征及工艺风格, 还能为科学修复提供指导依据。 然而, 传统颜料分析受限于样品尺寸、 表面平整度, 且部分分析方法需要取样, 对文物造成不可逆损伤, 这使得古书画颜料的检测面临诸多挑战。 高光谱成像技术(HSI)凭借其无损检测、 广域扫描及获取完整光谱信息的优势, 成为文物颜料分析的重要工具。 HSI克服了样品表面不平整、 尺寸受限等问题, 能够从不同波段获取细致的光谱和空间信息, 帮助提取颜料的微观特征。 旨在利用HSI技术实现古书画颜料的精准分类与深度特征提取, 以应对复杂场景下的颜料检测挑战。 为此, 我们提出了一种多尺度空间-光谱特征融合的方法, 在分析过程中结合不同层次的信息: 利用光谱-空间注意力机制捕捉细节特征, 并通过视觉转换器(ViT)模型获取图像整体的高层语义信息, 从而增强对复杂颜料特征的表示能力和分类性能。 实验结果表明, 该方法在模拟画作样品上的分类性能显著优于传统和其他深度学习模型: 与支持向量机(SVM)相比, 分类精度提升了34.35%; 相较于HyBridSN与SSRN模型, 精度分别提高了8.93%和5.6%。 本方法不仅提升了颜料检测的准确性, 还为古书画的科学修复和价值保护提供了无损、 可靠的技术支持, 并为文物保护的智能化发展奠定了技术基础。
, LUO Xi-ling, SUN Yu-yu, ZHONG Nian-bingPigments not only endow cultural relics with color and aesthetic value but also carry rich historical, cultural, and technical information. Accurate classification and identification of pigments are essential for the restoration, preservation, and academic study of ancient painted artworks. Identifying the types and compositions of pigments helps determine the creation period, regional characteristics, and craftsmanship style, providing scientific guidance for restoration and cultural value research. However, traditional pigment analysis faces challenges due to limitations in sample size, surface flatness, and the destructive nature of some analytical methods, which may cause irreversible damage to the artifacts. Hyperspectral Imaging (HSI), with its non-destructive nature, wide-area scanning, and capability of capturing complete spectral information, has become a powerful tool for pigment detection. HSI overcomes the limitations imposed by uneven surfaces and small sample sizes, enabling the extraction of fine-grained spectral and spatial features from pigments. This study aims to utilize HSI for the precise classification and detailed feature extraction of ancient painting pigments, addressing challenges in complex scenarios. We propose a multi-scale spatial-spectral feature fusion method to integrate information at different levels. A spectral-spatial attention mechanism is employed to capture fine details. At the same time, the Vision Transformer (ViT) extracts high-level semantic information from the entire image, enhancing the representation of complex pigment features and improving classification performance. The experimental results show that the proposed method significantly outperforms traditional and other deep learning models in the classification of simulated painting samples: it improves classification accuracy by 34.35% compared to the Support Vector Machine (SVM) and by 8.93% and 5.6% compared to HyBridSN and Spectral-Spatial Residual Network (SSRN), respectively. This study not only improves the accuracy of pigment detection but also provides non-destructive, reliable technical support for the scientific restoration and cultural value preservation of ancient paintings, contributing to the intelligent development of cultural heritage conservation.
颜料是文物的重要组成部分, 不仅赋予了文物色彩和美感, 还承载着丰富的历史、 文化和技术信息。 国画颜料可以分为“ 石色” (矿物色)和“ 水色/草色” (植物色), 以及现代使用的化学原料合成的颜料, 即化学色[1]。 为了更好地保护和展现古书画的艺术价值, 通常需要对其进行颜色修复和复制工作。 当前, 虽然激光拉曼光谱、 X射线荧光等技术手段已广泛应用于古书画颜料类别的鉴定, 但由于受到样品尺寸、 表面平整度等因素的限制, 以及部分分析方法需要取样, 这使得古书画颜料的分析工作面临诸多挑战[2]。 高光谱成像技术(hyperspectral imaging, HSI)具有无损、 广域扫描、 获取完整光谱信息等优势, 能够精确分析古书画颜料, 且不受样品表面平整度和尺寸限制[3]。 这为颜料识别提供了一种高效且可靠的方法。
高光谱成像技术通过非侵入性方式, 快速获取样本的详细光谱信息及其空间分布特征, 并且具有高效性和快速采集数据的能力, 然而, 高光谱图像数据具有高维度和高复杂度, 传统的分析方法难以充分利用这雪丰富的信息。 因此, 使用深度学习技术来帮助分析高光谱数据变得尤为重要。 近年来, 许多研究团队在这一领域取得了显著进展: 青岛科技大学的张岩等[4]提出了一种基于卷积神经网络的三维卷积神经网络(3D-convolutional neural networks, 3D-CNN)结合卷积块注意力模型(convolutional block attention module, CBAM)的高光谱图像分类方法, 通过结合视觉注意力机制使得卷积神经网络可以更好地关注重要特征。 重庆师范大学的谭云飞等[5]提出了一种组合像素嵌入的双注意力高光谱图像分类的方法, 通过添加通道空间双注意力机制, 抑制冗余信息的干扰, 增强高光谱图像空间与光谱的特征权重。 Zhong[6]提出了一种基于图卷积中的半监督网络通过关注重要信息来学习空间相邻区域之间的重要性, 图像分类精度较传统算法有很大提升。 西安电子科技大学的钟佳平团队[7]构建了一种结合区域引导和双注意力机制的高光谱目标检测判别式学习网络RADN, 缓解了标记样本少的条件下不同类别相似度高和相同差异性大导致的背景和目标不易区分的问题。 然而, 由于高光谱图像数据具有高维度和高复杂度, 对其进行有效的特征提取和分类仍然存在一些问题, 如传统的卷积神经网络(convolutional neural networks, CNN)在高光谱图像分类中有一定应用, 但其连续的卷积和池化操作可能导致高维光谱特征的细节信息丢失, 影响分类性能; 单独依赖低层或高层特征的方法存在局限性: 低层特征虽然能够捕捉纹理和边缘等细节信息, 但可能缺乏对整体语义的理解; 而高层特征尽管能提供高级语义信息, 但可能忽视细节特征, 如图像中的小物体和微小变化。 因此, 本工作提出了一种基于多尺度空间-光谱特征提取的神经网络模型, 该模型旨在融合低层和高层特征, 以更全面地捕捉高光谱图像中的细节和全局信息, 从而提高对复杂高光谱数据的解析和分类能力。
提出的多尺度空间-光谱特征提取的神经网络模型, 用于对颜料高光谱图像进行分类。 通过空谱注意力机制提取低层信息, 并利用Vision Transformer模型提取高层语义信息, 实现了不同尺度特征的有效融合, 提升了对模拟画作颜料区域分类性能。 实验结果表明, 所提出的方法在颜料高光谱图像分类任务中表现优于传统方法, 验证了其有效性和优越性。
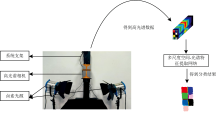
使用了莱森光学公司的iSpecHyper-VS1000高光谱相机进行数据采集。 该相机采用推扫式成像(push-broom imaging)原理, 通过样品与相机之间的相对运动逐行采集样品的光谱信息, 并在光谱和空间两个维度上生成三维数据立方体。 该相机的工作光谱范围为380~1 020 nm, 覆盖了从紫外到近红外区域, 适用于颜料等材料的光谱分析。 仪器包含300个光谱通道, 且光谱分辨率优于2.5 nm, 确保了细微光谱差异的捕捉。 横向扫描角度小于60° , 保证成像过程中视场范围内的光照均匀性。 系统采用300 W的卤素灯作为稳定的连续光源, 发射光谱涵盖了380~25 000 nm的宽光谱范围, 能够提供平滑的光谱输出, 避免了光谱间断。 高光谱图像采集系统如图1所示。
 | 图1 高光谱图像采集系统Fig.1 Hyperspectral image acquisition system |
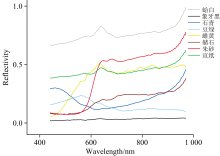
为了确保实验数据的多样性和准确性, 选取了矿物颜料中具有代表性的七种在唐宋时期的绘画作品中广泛应用的颜料, 包括朱砂、 雌黄、 蛤白、 象牙黑、 石青、 豆绿和深赭石, 所有颜料均来自北京岩彩天雅艺术中心。 并且由于文物本身具有极高的历史价值和不可再生性, 为确保实验过程中数据的可控性, 使用所选颜料绘制标准色块样本作为实验对象。 基底材料选用了棉料单宣纸, 该宣纸由中国宣纸股份公司生产的红星宣纸制成, 成分中含有40%的沙田稻草与60%的檀皮, 厚度约为90 μ m。 为增强颜料在宣纸表面的附着力, 选用了5%的牛皮胶水溶液作为粘合剂。 绘制过程主要分为三步, 首先将颜料在研钵中充分研磨, 使其颗粒均匀细化; 随后, 将研磨后的颜料与5%的牛皮胶溶液进行充分混合, 形成均匀的颜料浆液; 最后, 利用毛笔将混合后的颜料均匀涂覆于宣纸表面, 以获得稳定且可重复的实验样本如图2所示。 这些色块是使用特定的古代颜料按照不同的比例混合制作的, 模拟了实际古代书画中的颜料分布和混合情况[8]。 这种方式不仅保证了样品的真实性, 还使得采集到的高光谱数据能够更好地反映实际应用中的复杂情况, 采集到颜料光谱如图3所示。
 | 图2 模拟古代书画颜料的色块混合图Fig.2 Color block mixing chart simulating ancient painting pigments |
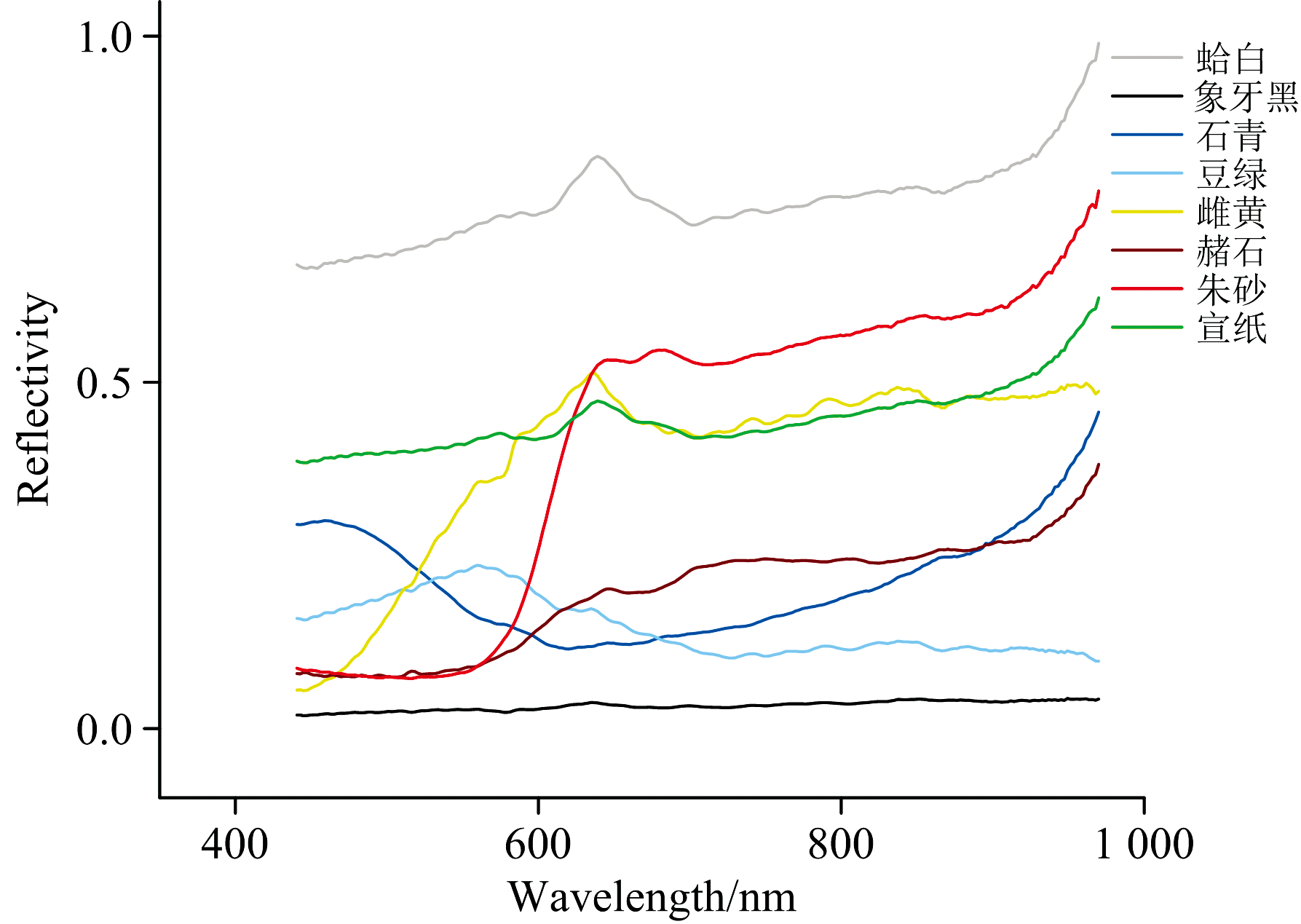 | 图3 颜料光谱曲线图Fig.3 Pigment spectral curves |
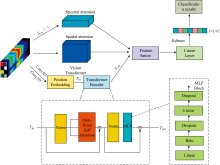
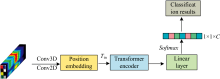
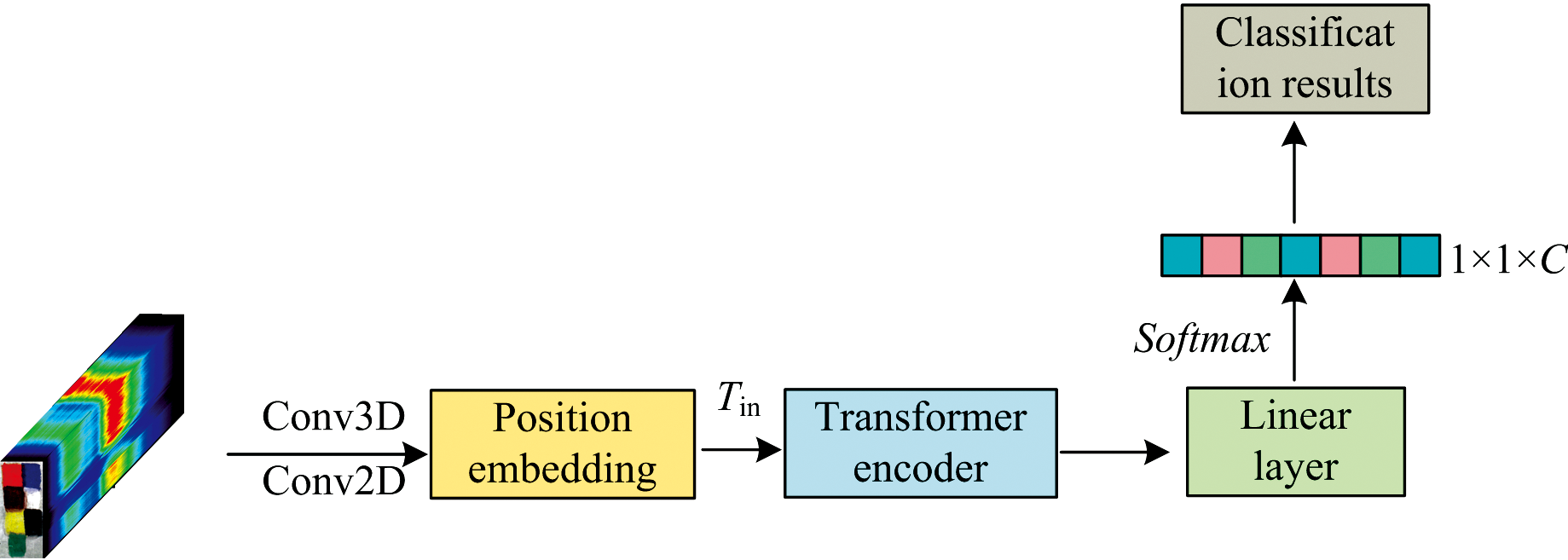
高光谱图像作为一个立方体式的数据, 其中包含了数百个连续波长下的波段图像, 其中每个波段都反映了物体在不同光谱范围内的反射特性。 通过这些波段信息, 可以精细地区分不同材料和物质的光谱特征。 对于这样的高光谱数据, 提出了一种多尺度特征提取网络, 网络结构如图4。
 | 图4 多尺度空间-光谱特征提取网络Fig.4 Multi-scale spatial-spectral feature extraction network |
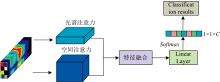
在本网络中, 输入的高光谱图像首先分别经过光谱注意力模块和空间注意力模块, 以提取光谱特征和空间特征[9]。 具体而言, 光谱注意力模块专注于分析各个波段的反射特性, 从而提取不同材料和物质的光谱特征; 而空间注意力模块则关注图像的几何结构和纹理信息, 捕捉像素之间的空间依赖关系。 此外, 网络通过卷积操作将输入的高光谱图像划分为小块(Tokens), 并使用位置编码(Position Embedding)对这些小块进行处理。 处理后的图像块再输入到Vision Transformer的Transformer Encoder中, 以提取高光谱图像的全局空间-光谱特征。
注意力机制的核心在于根据输入数据的相关性分配权重, 使模型能够专注于重要部分, 忽略无关信息, 从而更有效地提取有用信息。 对于高光谱图像数据, 光谱注意力模块突出光谱波段的特征, 而空间注意力模块强调分类像素周围的空间特征。 本文提出的方法利用注意力机制捕捉高光谱图像中的细节信息, 即光谱和空间特征, 以完成颜料高光谱图像的分类任务[10]。
这里, 采集到的高光谱数据输入为X∈ RH× W× B, 空间维度表示为(H, W), 其中H代表高光谱图像的高度, W代表宽度, B表示光谱的波段数。
然后通过最大池化和全局平均池化将高光谱图像中的每个像素点的波段信息提取出来形成一个1× 1× B的光谱特征向量
式(2)中, Xh, w表示位置(h, w)处的光谱特征向量。 然后将这些特征向量输入到一个多层感知机MLP(multi-layer perceptron)来提取高光谱图像中每个波段的权重, 然后将提取的特征经过Sigmoid激活函数即可得到光谱权重系数, 由于光谱特征中既包含了全局模式的信息(整体光谱趋势), 也可能存在局部波段的强响应(特定波段蕴含的关键信息)。 为捕捉这两类信息, 我们同时使用了平均池化(average pooling)和最大池化(max pooling), 平均池化用于提取整体光谱的平均趋势, 帮助模型关注全局性的光谱分布特征。 它可以平滑异常的波段响应, 保证模型不过分依赖局部的剧烈变化。 最大池化用于捕捉光谱中的局部强响应, 有助于模型在需要识别微小但关键的光谱特征时更加敏感。 从而达到突出包含重要信息的波段, 并抑制冗余或噪声波段的目的。 光谱注意力计算公式可以概括:
式(3)中, X为输出的高光谱图像, σ 为sigmoid激活函数, MSe是权重系数。
最后将计算得到的注意力权重对原始高光谱图像的每个波段进行加权求和, 从而增强关键光谱特征, 提高分类和识别性能。
式(4)中, Xh, w, i表示位置(h, w)处第i个波段的特征, MSe(X)是注意力权重。
在本研究中, 空间信息指的是画作中颜料在二维空间中的分布模式与局部结构特征。 每个像素的光谱信息不仅反映了局部颜料的成分, 还携带了空间邻域中颜色变化、 纹理以及颜料重叠等特征, 空间信息的引入有助于捕捉不同颜料之间的空间关系(如边界、 纹理和局部差异), 这些信息对于画作的颜料分类和复原具有重要意义。
与光谱注意力相似, 空间注意力机制通过分析高光谱图像中的空间特征来计算每个位置的权重, 从而突出包含重要信息的区域并抑制无关或噪声区域。 具体来说, 首先将高光谱图像在通道维度进行池化, 以此来压缩通道大小便于后面学习特征, 然后将全局池化和平均池化的结果, 维度为(H, W, 1), 按照通道拼接, 然后通过一个7× 7的卷积核来获取空间特征, 再经过Sigmoid激活函数即可得到每个位置的注意力权重, 最后将计算得到的注意力权重进对原始高光谱图像进行加权求和, 从而增强关键空间特征。 空间注意力计算公式可以概括为
式(5)中, X'表示高光谱徒像中加权的结果, f7× 7表示卷积核为7× 7的卷积层, σ 为sigmoid激活函数。
视觉转换器(vision transformer, ViT)是一种将Transformer模型应用于计算机视觉任务(如图像分类)的新颖方法。 ViT 的核心思想是将图像划分为小块(Tokens), 并利用自注意力机制处理这些小块, 以捕捉长距离依赖关系。 这使得 ViT 能够有效提取图像的全局特征, 从而提升对高光谱图像中复杂光谱和空间信息的理解与分类性能。 在高光谱图像处理中, 将ViT应用于特征提取可以充分发挥其强大的能力, 有助于捕获高光谱数据中的详细光谱和空间信息, 从而提高分类准确性, 增强对高光谱图像复杂空间和光谱关系的理解[11]。
为了适应ViT模型的输入要求, 将高光谱图像分成小块(Tokens)。 具体而言, 通过卷积操作实现图像分块, 并通过设置卷积核大小以及补偿参数来控制图像块的分辨率[12]。 图5展示了分块器(Tokenizer )模块的结构。
 | 图5 Tokenizer模块Fig.5 Tokenizer module |
经过嵌入层处理的序列化表示作为输入, 传入到编码器(Encoder)进行处理, 经过一系列Transformer编码器的处理后, 提取到全局特征用于后续的分类任务。 Transformer Encoder 如图6所示。
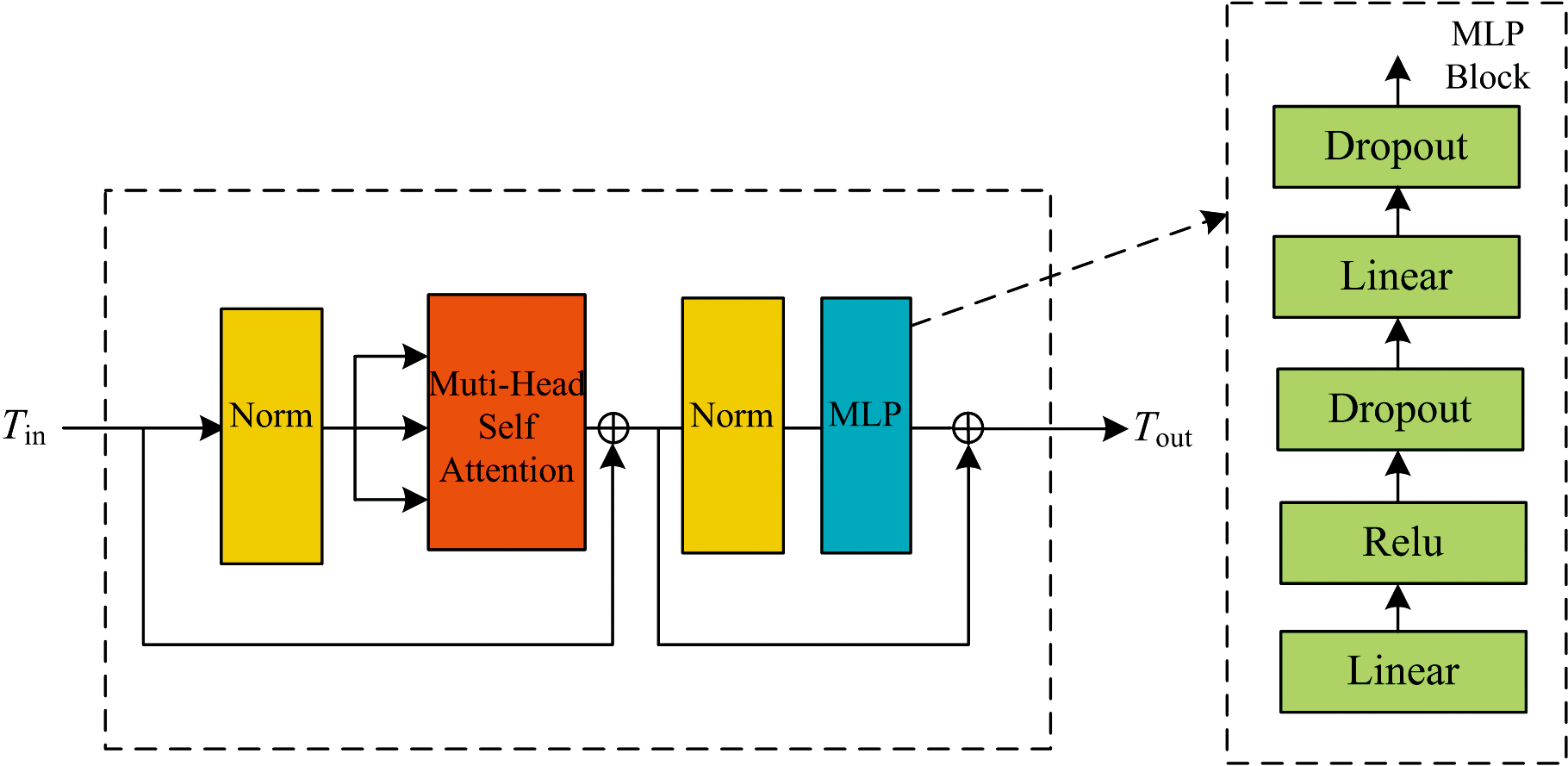 | 图6 Transformer编码器Fig.6 Transformer encoder |
在提取了多尺度的空间特征Fp、 光谱特征Fspe以及由ViT提取出的全局空间-光谱特征Fh之后, 如何有效地将这些特征融合成是提升模型分类性能的关键一步。 特征融合的核心目标在于结合这些不同维度的特征, 使模型能够更全面地理解高光谱图像的复杂结构, 从而更精准地进行颜料识别。 为实现这一目标, 采用了注意力加权融合的方法。 注意力机制通过动态地为不同特征分配权重, 确保最重要的特征在融合过程中得到充分表达, 进而增强模型的表现力[13]。
具体来说, 首先为每个特征生成查询Q(Query)、 键K(Key)和值V(Value)向量。 其中
WQ, WK, WV分别表示可学习的权重矩阵, F表示输入的特征。 然后, 通过计算查询和键向量的点积并对结果进行归一化, 得到各个特征的注意力权重α spe, α p, α h。 接下来, 利用这些权重对特征进行加权求和, 将不同特征融合为一个综合特征如式(9)所示。
这种加权融合方式不仅保证了各类特征的有效整合, 还通过动态权重分配强化了对关键信息的关注。
使用的高光谱图像数据集涵盖了多种模拟古代书画颜料的色块混合图。 图像光谱范围为380~1 020 nm具有300个通道, 分辨率为2.5 nm。 在数据预处理阶段, 对图像进行了反射率矫正、 噪声去除等处理, 以确保数据的准确性和一致性。 将得到的原始数据划分为两部分, 训练集和测试集, 比例设置为80%训练集, 20%测试集。 总计训练集样本数为22 560, 测试集样本数为5 640。
为了验证提出的基于多尺度空间-光谱特征提取的颜料高光谱图像分类算法, 所有算法模型均采用Python3.9编程语言采用Pycharm2022.3.3进行编程, 实验在CPU为Intel(R) Xeon(R) Platinum 8157 @2.30GHz, GPU为NVIDIA GeForce RTX 3090, RAM为24GB的个人计算机上进行。 实验中所有深度模型统一采用交叉熵损失函数(CrossEntropy Loss), Adam优化器, 随机梯度下降(stochastic gradient descent, SGD), 学习率为0.000 1, 训练轮次Epoch为200轮。
| 表1 数据集的类名和各个样本数 Table 1 Class names and sample counts of the dataset |
实验的定量评估方法采用总体精度OA(overall accuracy), 平均精度AA(average accuracy), 和Kappa系数K以及精确率(precision)、 F1得分作为综合评价指标[14]。 几种评价指标公式如下:
OA表示所有类别的正确预测样本数占总样本数的比例, 其计算公式如式(10)
AA即模型正确预测的样本数占总样本数的比例。 它衡量了模型对所有类别的整体预测准确性, 其计算公式如式(11)
Kappa系数, 是指一种对遥感图像的分类精度和误差矩阵进行评价的多元离散方法, 其计算公式如式(12)
式(12)中, p0表示表示观测精确性或一致性单元的比例, pe表示偶然性一致或期望的偶然一致的单元的比例
Recall是指争取预测的正样本数的占真是样本数的比值, 计算公式如式(14)
F1 score是精确率和召回率的调和平均值, 用于衡量模型在精确率和召回率之间的平衡能力, F1 score越高, 表明模型在这两个指标上表现越好。
其中, TP表示真正例的数目; FP表示负正例的舒服; FN表示假负例的数目。 TP、 FP、 FN均由分类结果混淆矩阵获得。
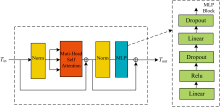
为了评估所提出模型中各模块对分类性能的贡献, 设计并实施了两组消融实验, 分别去除了光谱-空间注意力模块和Vision Transformer (ViT)模块, 并与完整模型进行对比。 以下是消融实验的具体设计与分析方法:
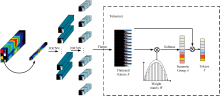
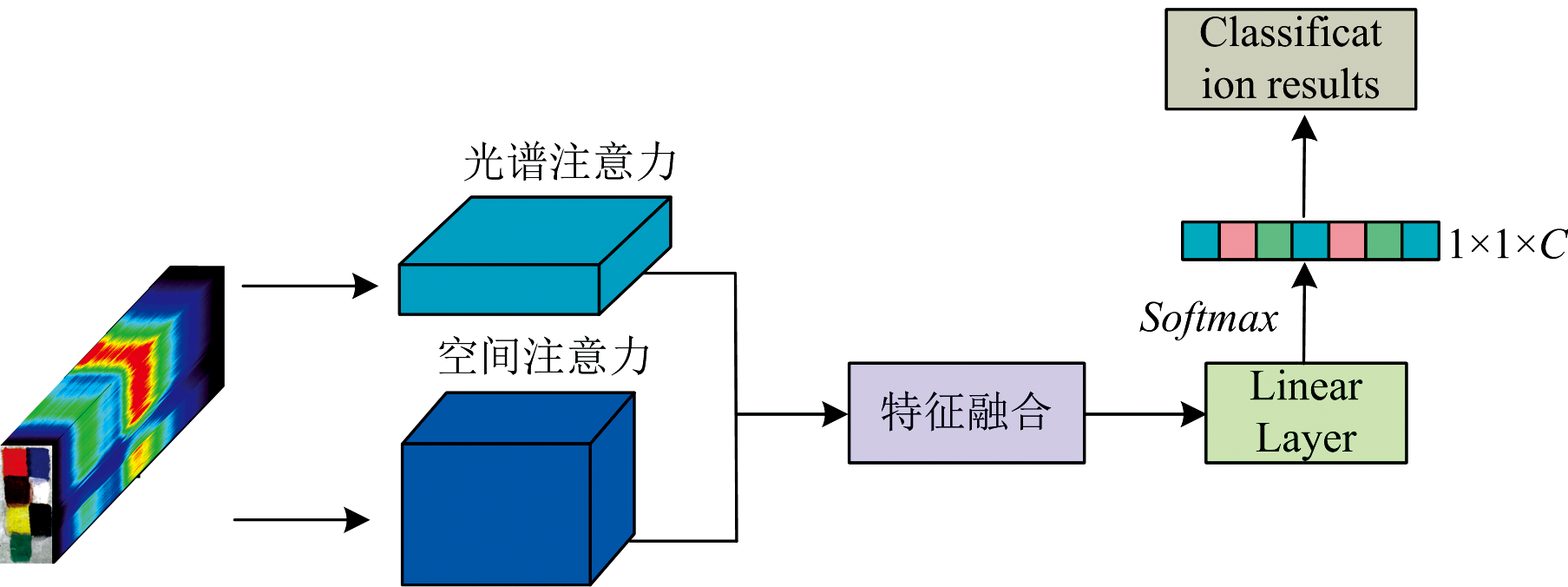
(1) 移除了模型中的光谱-空间注意力模块, 保持其他网络结构不变, 旨在评估该模块在低层光谱与空间特征提取中的作用。 通过去除该模块, 期望观察模型在捕捉高光谱图像细节信息和分类性能上的变化。 模块图如图7所示。
 | 图7 消融实验(去除注意力模块)Fig.7 Ablation study (removing attention module) |
(2) 设计了一个不包含ViT模块的网络, 仅使用基础卷积神经网络和光谱-空间注意力机制。 该实验旨在验证ViT的自注意力机制是否显著增强了模型的全局特征提取能力, 并提高了分类精度。 模块图如图8所示。
 | 图8 消融实验(去除ViT模块)Fig.8 Ablation study (removing ViT module) |
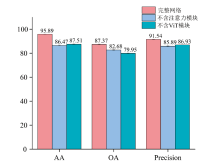
通过消融实验, 分别评估了去除光谱-空间注意力模块及Vision Transformer模块的网络在分类任务中的表现。 实验结果通过10次重复实验获得, 并以平均值± 标准差的形式报告。 表2和图9汇总了消融实验的关键评价指标, 包括平均准确率(AA)、 总体准确率(OA)和精度(Precision)。
| 表2 消融实验评价指标 Table 2 Metrics for ablation study |
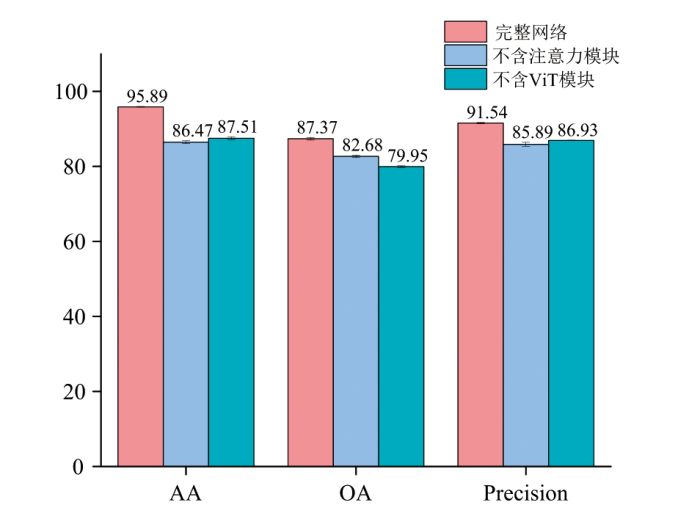 | 图9 消融实验评价指标对比图Fig.9 Comparison of metrics for ablation study |
从表2中可以看出, 去除光谱-空间注意力模块后, 模型的AA和OA分别下降至86.47%和82.68%, 这表明该模块对于增强模型在捕捉光谱和空间特征上的能力至关重要。 去除ViT模块后, AA和OA分别降至87.51%和79.95%, 这显示出ViT在全局特征提取方面的重要性。 Precision指标的下降进一步表明, 缺少这两个模块会显著影响分类精度, 导致分类错误率的增加。
这些结果表明, 在去除光谱-空间注意力模块后, 模型在低层特征提取和分类精度方面的性能显著下降。 表明光谱-空间注意力机制在增强有效波段和像素信息方面具有至关重要的作用。 缺乏这一模块会导致特征提取过程中关键信息的遗漏, 从而降低模型对高光谱图像细节的敏感度。 此外, 去除ViT后, 模型在全局特征捕捉和分类任务中的表现也显著下降。 ViT的自注意力机制对于捕捉图像中的长距离依赖关系和全局上下文信息至关重要。 去除ViT后, 模型失去了对全局特征的深度分析能力, 导致特征表示的不完整, 从而影响了分类精度。
将本文提出的基于多尺度空间-光谱特征提取的颜料高光谱图像分类算法与其他几种方法进行对比, 包括机器学习方法支持向量机(support vector machine, SVM)[15], 其中, SVM的参数选择了径向基函数(RBF)核, 这是处理复杂非线性数据分离的理想选择。 具体来说, 将核参数γ (gamma)设置为0.005, 将惩罚参数C设置为100。 较低的γ 值意味着每个训练点具有较广泛的影响, 从而产生更平滑的决策边界, 有利于泛化, 而较高的C值使得模型在训练数据上拟合更紧密, 以及两种深度学习方法SSRN[16]和HyBridSN[17]。 SSRN(spectral-spatial residual network)和HyBridSN都是当前高光谱图像分类任务中较为先进的模型。 这两个模型结合了光谱和空间特征的提取, 且都有一定的深度学习基础。 SSRN 是一个在光谱-空间特征融合方面表现突出的模型, 其通过残差机制来提高模型对信息的捕捉能力。 而HyBridSN同样结合了多层的深度学习结构和空间-光谱特征的提取, 二者是当前领域中解决类似问题的代表性方法。 为了确保实验的公平性, 所有网络均在相同的实验条件下进行了对比, 实验结果如表3和图10所示。 每个实验重复10次, 结果以平均值± 标准差表示。
| 表3 不同模型在数据集上的分类准确度 Table 3 Classification accuracies of different models on the dataset |
 | 图10 使用不同模型的数据集分类图 (a): 真实图; (b): SVM; (c): HyBridSN; (d): SSRN; (e): 多尺度特征提取网络Fig.10 Dataset classification chart using different models (a): Original; (b): SVM; (c): HyBridSN; (d): SSRN; (e): Multi-scale feature extraction network |
实验结果表明, 提出的基于多尺度空间-光谱特征提取的高光谱图像分类模型在多项评价指标上显著优于传统的机器学习模型SVM以及两种主流的深度学习模型HyBridSN和SSRN。 在总分类精度 (OA) 方面, 本模型达到了87.37%± 0.25%, 与HyBridSN的87.22%± 0.09%接近, 且明显高于SVM的56.95%± 0.21%和SSRN的85.55%± 0.20%, 说明其在整体分类任务中具备更强的性能表现。 平均分类精度 (AA) 指标上, 提出的模型以95.89%± 0.12%显著高于其他方法, 表明其在处理各类样本时更加均衡, 能够更好地应对高光谱数据中不同类别间的不平衡问题。 Kappa系数(K)为0.95, 较SVM的0.53和SSRN的0.83有大幅提升, 显示出模型在分类一致性方面的优势。 此外, 本模型的F1-score和Precision分别为0.89和91.54%± 0.17%, 不仅远超SVM的0.59和57.19%± 0.21%, 也优于SSRN的0.73和85.94%± 0.23%, 体现了在分类精确度和召回率方面的全面提升。
这些结果充分表明, 提出的多尺度空间-光谱特征提取方法在融合高光谱图像的多尺度空间信息与光谱特征方面具有显著优势, 能够在复杂的高光谱数据场景中有效提升分类性能。 相较于传统机器学习和其他深度学习方法, 该模型对高光谱图像中细微的光谱和空间差异有更强的捕捉能力, 在颜料类别识别任务中展现出卓越的鲁棒性和准确性。 这些特性使其在高光谱图像处理和文化遗产保护等领域具有重要的应用前景。
提出了一种结合空间-光谱注意力和Vision Transformer (ViT) 的颜料高光谱图像分类方法。 通过高光谱相机获取模拟画作的高光谱图像, 模型首先利用光谱-空间注意力模块提取低层次的细节信息, 再结合ViT提取深层语义特征。 随后, 这些多尺度特征被有效融合用于分类。 实验结果表明, 本文提出的模型在特征提取和分类性能上, 显著优于传统的支持向量机 (SVM) 方法, 并相较于现有的HyBridSN和SSRN模型也有明显提升。 具体而言, 训练集和测试集的分类准确率分别达到了98%和91.54%, 相较于SVM、 HyBridSN和SSRN, 分类精度分别提升了34.35%、 8.93%和5.6%。 与现有仅进行单一尺度特征提取的深度学习模型相比, 本研究的多尺度空间-光谱特征提取网络在特征提取的充分性和识别精度方面表现更为优异。 该网络有望在未来的文物保护工作中得到广泛应用, 特别是在基于高光谱图像的颜料识别和分类任务中, 为古代书画等文物的精细化修复与科学研究提供更加精准和高效的技术支持。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|