
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于LSTM-TE模型的冬枣可溶性固形物含量高光谱估测
[刘傲然1, 2  , 孟惜
, 孟惜2 , 刘智国2 , 宋宇斐2, * , 赵雪曼2 , 智丹宁2 ]
, 孟惜, 赵雪曼|
|


作者简介: 刘傲然, 2001年生, 河北师范大学计算机与网络空间安全学院硕士研究生 e-mail: 347354547@qq.com
冬枣因其丰富的营养成分、 香甜的口感和优良的风味, 深受消费者的喜爱。 随着消费者对水果品质要求的提高, 可溶性固形物含量(SSC)作为衡量水果成熟度和口感质量的重要指标, 已成为水果品质评估中的关键因素。 因此, 实现冬枣SSC的高效、 无损预测具有重要的应用价值和实际意义。 提出一种融合长短时记忆网络(LSTM)与Transformer编码器的LSTM-TE模型, 旨在实现冬枣SSC的快速无损预测。 采集900个冬枣样本的高光谱数据并测定其SSC值, 结合多种光谱数据预处理方法[包括多元散射校正(MSC)、 矢量归一化(VN)、 Savitzky-Golay(SG)滤波、 一阶导数(D1)和二阶导数(D2)等]对数据进行处理, 通过PLSR、 SVR、 VGG16、 ResNet18、 LSTM五种模型系统比较了10种预处理组合的效果, 确定最优预处理方案为MSC-SG-D1。 在该预处理方法的基础上, 进一步构建了PLSR、 SVR、 VGG16、 ResNet18、 LSTM和LSTM-TE的多模型对比体系, 并对其在测试集上的性能进行了对比分析。 实验结果表明, LSTM-TE 模型在测试集上的决定系数为0.959 8, 均方根误差为1.269 0, 较传统机器学习模型PLSR ($R_{\mathrm{p}}^{2}$=0.817 3)提升17.4%, 较单一 LSTM模型($R_{\mathrm{p}}^{2}$=0.865 2)提升10.9%。 该模型通过LSTM的时序特征捕捉能力与Transformer编码器的全局依赖建模优势, 有效挖掘了高光谱数据中的非线性特征关系。 本研究为冬枣品质的在线检测与分级提供了新的技术方案, 对高光谱技术在精准农业中的应用具有重要参考价值。
Winter jujube is favored by consumers for its rich nutritional content, sweet taste, and excellent flavor. With the increasing demands of consumers for fruit quality, Soluble Solids Content (SSC) has become a key factor in fruit quality evaluation, serving as an important indicator for measuring fruit ripeness and taste quality. Therefore, efficient and non-destructive prediction of winter jujube SSC has significant practical value and importance. This paper proposes an LSTM-TE model, which integrates Long Short-Term Memory (LSTM) networks with a Transformer Encoder, aiming to achieve rapid and non-destructive prediction of winter jujube SSC. By collecting hyperspectral data from 900 winter jujube samples and determining their SSC values, multiple spectral data preprocessing methods (including Multivariate Scatter Correction (MSC), Vector Normalization (VN), Savitzky-Golay (SG) filtering, first derivative (D1), and second derivative (D2)) were applied to process the data. The effects of 10 preprocessing combinations were compared through five models: PLSR, SVR, VGG16, ResNet18, and LSTM, to determine the optimal preprocessing scheme, MSC-SG-D1. Based on this preprocessing method, a multi-model comparison system was further constructed, including PLSR, SVR, VGG16, ResNet18, LSTM, and LSTM-TE, and their performance was analyzed on the test set. Experimental results showed that the LSTM-TE model achieved a coefficient of determination of 0.959 8 and a root mean square error (RMSE) of 1.269 0 on the test set, an improvement of 17.4% compared to the traditional machine learning modelPLSR ($R_{\mathrm{p}}^{2}$=0.817 3) and 10.9% compared to the single LSTM model ($R_{\mathrm{p}}^{2}$=0.865 2). This model effectively explored the nonlinear feature relationships in hyperspectral data by capturing temporal features through LSTM and leveraging the global dependency modeling advantages of the Transformer encoder. This study provides a new technical solution for the online detection and grading of winter jujube quality, offering important reference value for applying hyperspectral technology in precision agriculture.
冬枣作为一种营养价值丰富的水果, 因其独特的风味以及丰富的维生素、 矿物质等营养成分, 在我国消费市场倍受青睐[1]。 对其品质的准确评估对于增强其市场竞争力至关重要。 可溶性固形物含量(soluble solids content, SSC)作为衡量水果成熟度和口感质量的关键参数[2]。 不仅与冬枣的风味特性和甜度直接相关, 而且对冬枣的商业价值具有显著影响[3]。 传统的冬枣SSC测定方法主要依赖于化学分析或物理检测技术, 这些方法虽然在准确性上具有优势, 但也存在一些限制, 例如操作复杂性、 检测周期长以及可能对样品造成破坏等问题[4]。 因此, 开发一种既准确又高效的SSC测定方法, 对于快速评估冬枣品质和提升市场竞争力具有重要意义。
随着高光谱成像技术的发展, 基于高光谱数据的无损检测方法在农业领域得到更广泛的应用。 高光谱数据能够提供水果表面及内部的多维信息, 并通过分析光谱特征与水果品质之间的关系, 实现对水果品质的快速、 无损评估[5]。 在高光谱数据分析中, 传统的机器学习方法, 如支持向量机回归(SVR)、 偏最小二乘回归(PLSR)、 随机森林(RF)等已得到广泛应用。 Guo等[5]基于特征波长建立的苹果SSC的CARS-PLS预测模型, 预测集的R2=0.98, RMSE=0.327。 Kim等[6]获取柑橘的光谱图像后, 基于特征波长建立柑橘SSC的CARS-PLSR预测模型, 预测集的R2和RMSE分别为0.75和0.56。 Yang等[7]提出了一种基于高光谱图像融合信息深度特征的新鲜桃子SSC估计方法, 所构建的SAE-RF模型的预测效果R2=0.918 4, RMSE=0.669 3。 然而, 传统的机器学习方法往往依赖于手工特征提取, 选择特征波长的过程繁琐且需要大量的领域知识[8]。 此外, 传统机器学习模型在处理高维数据时容易出现过拟合现象, 尤其是在样本量较小或数据噪声较大的情况下。 尽管通过预处理方法能够在一定程度上提高预测精度, 但由于这些方法仅限于对数据进行线性或局部处理, 无法完全捕捉高光谱数据中的复杂非线性特征[9]。 因此, 开发能够自动进行特征提取的高精度估算模型显得尤为重要, 这将有助于提高模型的泛化能力和预测精度, 同时减少人为因素的局限性与不确定性影响[7]。
近年来, 深度学习方法逐渐成为解决高光谱数据分析中的关键技术[10]。 深度学习方法能够通过端到端的训练过程, 自动提取和学习数据中的深层特征, 消除人工特征选择的瓶颈, 提高模型的预测能力和适应性。 Sun等[11]提出了一种预测橙色SSC的颜色校正1D-CNN模型, 与PLSR模型和常规1D-CNN模型相比, 最佳色彩校正模型的RMSEP分别降低了36.4%和16.1%。 Yu等[12]提出了一种基于全连通神经网络的SAE-FNN模型并成功预测了库尔勒香梨的可溶性固形物含量, 验证集的R2和RMSE分别达到了0.921和0.22%。 Qi等[13]将Transformer的注意力机制与卷积神经网络结合建立CNN-Transformer模型预测樱桃番茄的可溶性固形物含量, 验证集的R2为0.87。 上述工作展示了深度学习在水果品质预测中的巨大潜力。 然而, 目前基于深度学习预测水果可溶性固形物含量(SSC)的研究仍然相对较少, 且精度尚未达到理想水平, 尤其是对于冬枣等水果的SSC预测仍处于探索阶段。 已有研究表明, LSTM模型能够有效捕捉高光谱数据中的时序特征[14], 但是在处理长序列数据时存在一定的局限性, 随着序列长度的增加, 信息传递过程中会出现梯度消失或梯度爆炸的问题。 而Transformer模型则通过其注意力机制增强了对长程依赖关系的建模能力[15]。 因此, 融合LSTM和Transformer的混合模型在处理高光谱数据时, 能够更好地挖掘非线性特征, 提高预测的准确性。 基于这种思路, 设计了一种融合LSTM和Transformer编码器的深度学习模型, 用于预测冬枣的可溶性固形物含量(SSC), 该方法在处理高光谱数据时能够同时捕捉时序特征和全局信息, 具有较强的预测能力。
实验数据所涉及的冬枣样本采自中国山东省滨州市沾化区下洼镇(37.7° N, 117.9° E), 该地区属暖温带季风气候, 多年平均气温12 ℃, 年平均降水量575.5 mm。 此地土壤肥力优良, 水源供给充裕, 且土壤pH值处于适宜冬枣生长的范围。 该地优越的自然条件为冬枣的生长提供了极为有利的基础。 样本采集于2024年9月至2024年10月期间开展, 采集四个不同成熟期的冬枣样本共900个, 部分样本示例如图1所示。 将采集到的冬枣样本洗净后擦干分别装入自封袋中冷藏保存(0~5 ℃)。 使用彩谱科技有限公司生产的FIGSPEC FS-13高光谱相机成像系统采集冬枣样本光谱数据, 系统示意图如图2所示。
 | 图1 冬枣样本示例Fig.1 An example of a winter jujube sample |
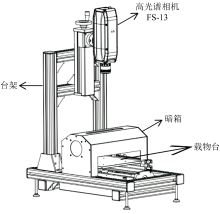
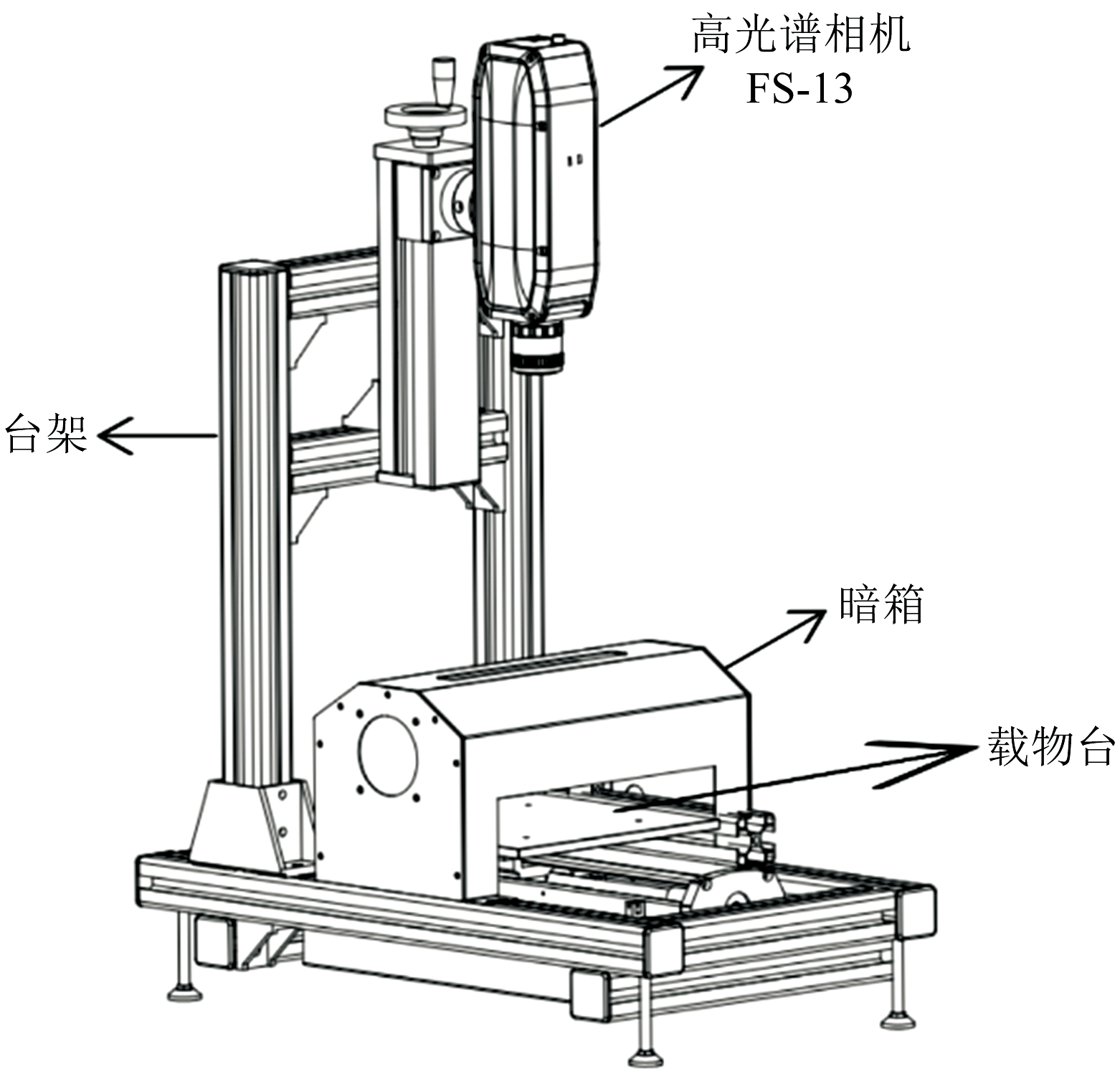 | 图2 FIGSPEC FS-13高光谱相机成像系统Fig.2 FIGSPEC FS-13 hyperspectral camera imaging system |
该系统配备了相机台架、 步进电机载物台以及包含8个卤素光源的暗箱。 相机采集范围为390~1 000 nm, 光谱分辨率为2.5 nm, 采样间隔为2 nm, 共计300个波段。 将每个样本放置于台架的载物台上实现扫描式拍照成像, 相机垂直于样本上方20 cm。 设备所提供的暗箱内部两面各置有4个卤素灯作为唯一光源, 与样本呈45° 角, 以消除光照不匀对实验带来的影响。 为确保实验准确性, 仪器预热5 min后进行白板标定。 将冬枣样本放置在载物台上进行光谱数据采集, 为保证实验的稳定性, 在每个冬枣“ 赤道” 附近选取5个采样点, 依次进行光谱采集。 通过FS-13高光谱相机成像系统配套光谱数据采集软件FigSpec记录每个样本的实验数据, 取5个采样点的光谱算数平均值作为每个冬枣样本的光谱数据。 为提高光谱测量的精度、 增强信噪比, 将所有样本的光谱数据剔除掉噪声较大的首尾波段(390~400和980~1 000 nm), 波长范围为400.46~979.62 nm的数据用于分析。
冬枣样本SSC的测定采用日本ATAGO爱拓PAL-1数字式糖度计折射仪, 量程为Brix0.0~53.0%, 精度可达Brix± 0.2%。 该折光仪具有温度补偿功能, 能够自动补偿每次测量时不同环境温度产生的误差, 建议取样量0.3 mL以上, 测量时间约3 s。 测定前先将折光仪调零校准, 利用便携式不锈钢手动榨汁器取得冬枣果肉的汁液, 过滤后用带有刻度的吸管吸取3 mL滴定于折射仪棱镜表面, 为保证测定的准确性, 静止3 s后再读数, 每个样本进行3次读数计算平均值, 以保证实验数据的稳定性。 所测得的样本SSC如表1所示。 为更好表征样本分布, 提高模型稳定性[16], 采用SPXY[17]方法进行数据集划分, 训练集样本720个, 测试集样本180个。
| 表1 冬枣SSC数据统计 Table 1 SSC statistics of winter jujube |
由于光谱数据在采集过程中不可避免地受到多种因素干扰, 为去除噪声、 减少干扰、 改善信号特征从而对光谱数据进行预处理, 以期提升原始光谱数据的质量和可用性, 为后续的分析和建模提供更准确、 更可靠的数据基础。
对所采集的光谱数据进行了多元散射校正(multiplicative scatter correction, MSC), 矢量归一化(vector normalization, VN), SG滤波(savitzk-golay, SG), 一阶导数(first derivative, D1)、 二阶导数(second derivative, D2)等预处理方法及多种预处理方法随机组合的操作。 基于预处理后的光谱数据建立冬枣SSC的传统算法预测模型和深度学习预测模型, 以确定最佳的光谱预处理方法。
与传统算法相比, 长短期记忆网络(LSTM)在处理时序数据时能够有效捕捉长期依赖关系, 特别适用于处理具有时间序列特征的高光谱数据。 LSTM 通过其特殊的门控机制(输入门、 遗忘门和输出门)能够有效地处理长序列数据, 避免了传统循环神经网络(RNN)中常见的梯度消失问题[18]。 另一方面, Transformer网络通过其独特的自注意力机制, 在全局信息的捕捉和并行处理方面表现出显著的优势[15]。 在本工作中, 基于LSTM的模型框架引入了Transformer的编码层结构, 以便有效融合两者的优势, 提升序列建立能力和全局信息捕获的效率。 Transformer编码层的核心思想是通过自注意力机制来建立序列中各个位置之间的依赖关系, 而不依赖于传统的递归结构, 这使得Transformer在处理长序列时展现出更好的并行处理能力和长程依赖捕捉能力。
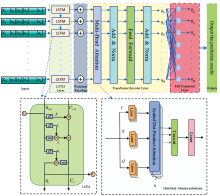
由于LSTM和Transformer均为深度学习方法, 它们在特征提取和数据处理方面展现出强大的能力, 能够自动从数据中提取关键特征。 因此, 结合LSTM与Transformer编码器模型, 可以利用LSTM在时间序列上的建模能力和Transformer在捕捉全局信息上的优势, 进一步提升冬枣SSC高光谱预测的准确性。 所设计LSTM-TE模型结构如图3 所示。
 | 图3 LSTM-TE网络结构Fig.3 LSTM-TE network structure |
LSTM-TE模型采用经过预处理的光谱数据作为输入, 以预测冬枣样本的可溶性固形物含量(SSC)作为输出。 为减少模型过拟合, 模型中引入了Dropout层, 能够在训练过程中随机丢弃一部分神经元的输出, 从而降低模型对训练数据的依赖, 增强其泛化能力。 为提高模型在异常值附近的鲁棒性。 选择SmoothL1Loss作为损失函数, 模型的学习率设定为0.005, 优化器选用Adam对模型其他相关参数进行优化。
以决定系数(R2), 均方根误差(RMSE)作为不同预测模型的评价指标。 其中
式(1)和式(2)中, n为样本数, yi为第i个样本的实际值,
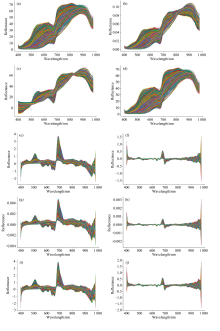
原始光谱数据通过上述预处理方法及它们的多种随机组合的处理结果如图4所示。 随后, 基于预处理后的光谱数据, 分别建立PLSR、 SVR、 VGG16、 ResNet18和LSTM五种模型, 并从模型的决定系数(R2)、 均方根误差(RMSE)来评估各预处理方法的效果, 以确定最佳的预处理方法。
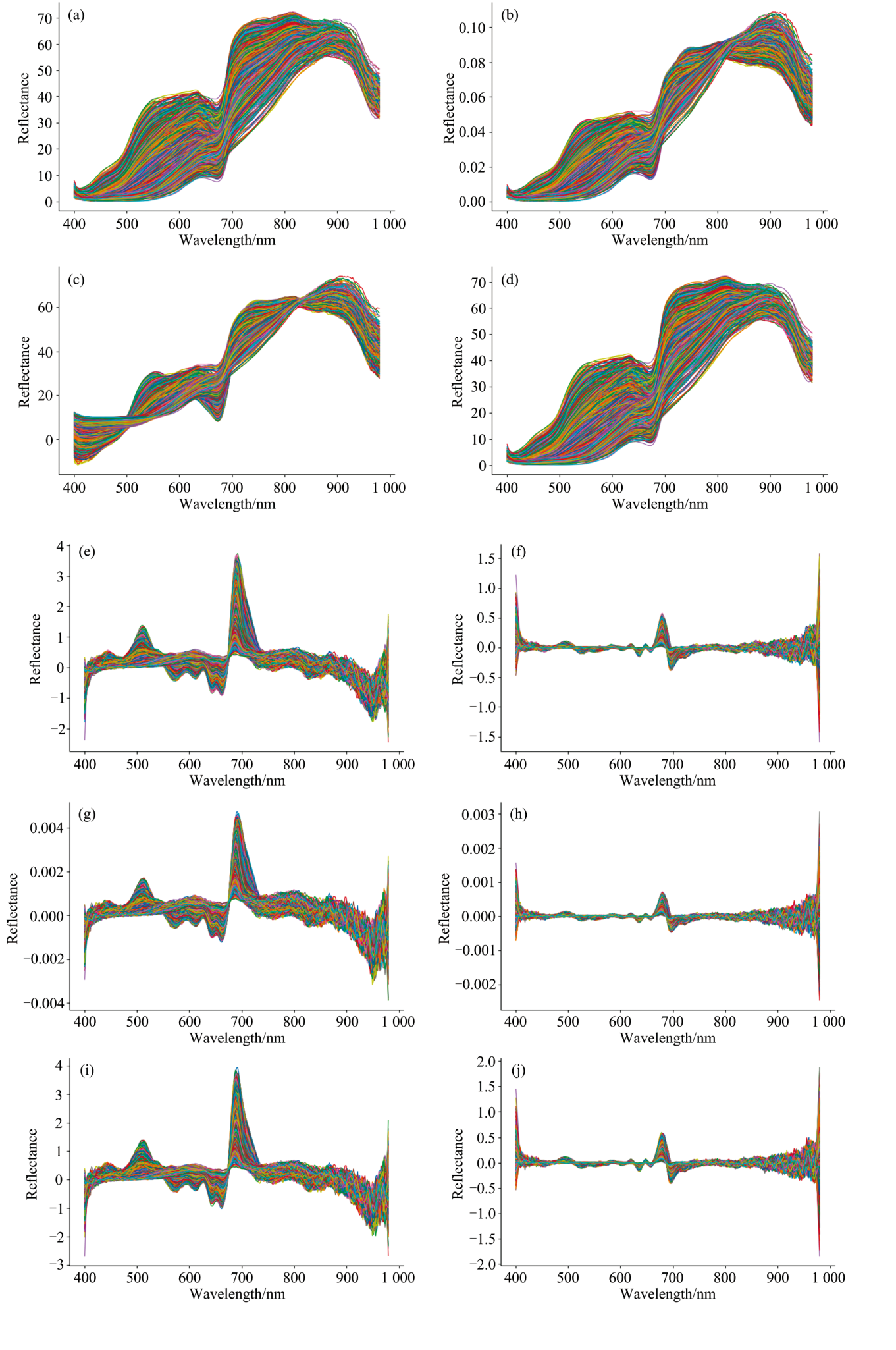 | 图4 光谱预处理结果 (a): 原始光谱; (b): VN; (c): MSC; (d): SG; (e): SG-D1; (f): SG-D2; (g): VN-SG-D1; (h): VN-SG-D2; (i): MSC-SG-D1; (j): MSC-SG-D2Fig.4 Spectral preprocessing results (a): Original; (b): VN; (c): MSC; (d): SG; (e): SG-D1; (f): SG-D2; (g): VN-SG-D1; (h): VN-SG-D2; (i): MSC-SG-D1; (j): MSC-SG-D2 |
2.1.1 传统算法模型验证
为系统评估不同预处理方法对传统模型性能的影响, 本研究基于PLSR与SVR两类机器学习算法, 对10种预处理方法的建模效果进行对比。 具体结果如表2所示。
| 表2 光谱预处理方法PLSR、 SVR建模结果 Table 2 Modeling results of PLSR and SVR using different spectral preprocessing methods |
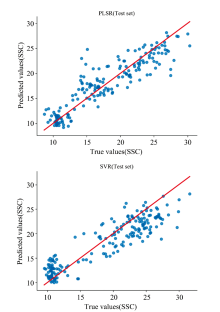
结果显示, 不同预处理方法对PLSR和SVR模型的建模效果存在明显影响。 在PLSR模型中, MSC-SG-D1的组合预处理方法在测试集上的
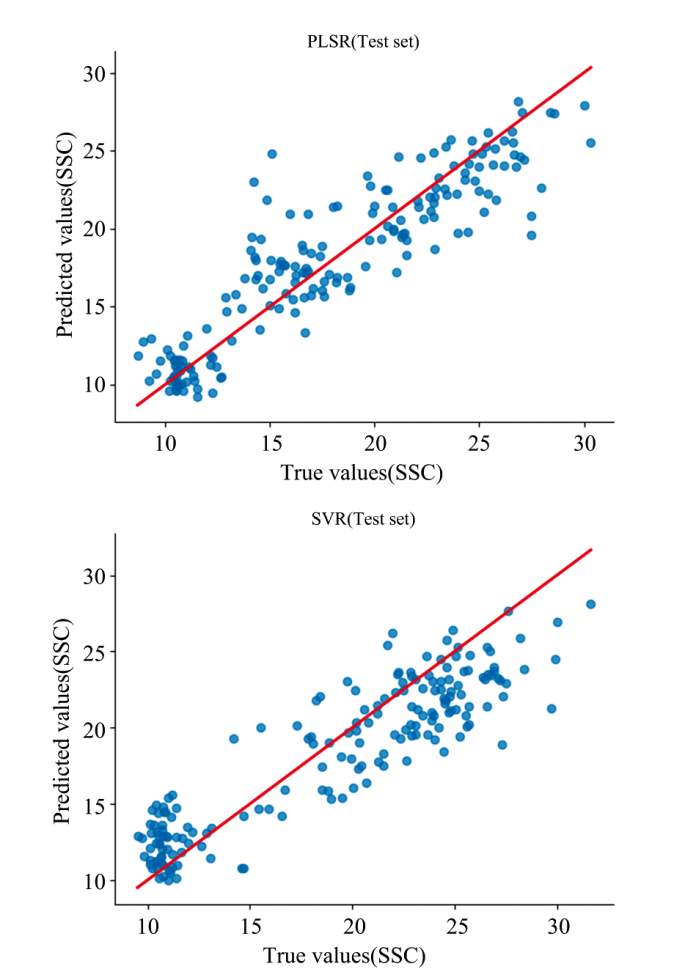 | 图5 MSC-SG-D1预处理后的PLSR、 SVR建模结果Fig.5 Modeling results of PLSR and SVR after MSC-SG-D1 preprocessing |
2.1.2 深度学习模型验证
为进一步探索深度学习模型在光谱数据建模中的表现, 基于三种深度学习模型(VGG16、 ResNet18和LSTM)对不同光谱预处理方法的效果进行评估。 通过对训练集和测试集的的决定系数(R2)、 均方根误差(RMSE)进行对比, 分析不同预处理方法对深度学习模型建模性能的影响。 具体结果如表3所示。
| 表3 光谱预处理方法VGG16、 Resnet18、 LSTM建模结果 Table 3 Modeling results of VGG16, ResNet18, and LSTM using spectral preprocessing methods |
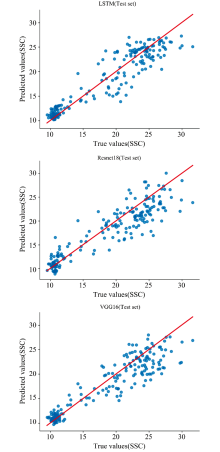
结果显示, 在VGG16模型中, MSC-SG-D1的组合预处理方法在测试集上的
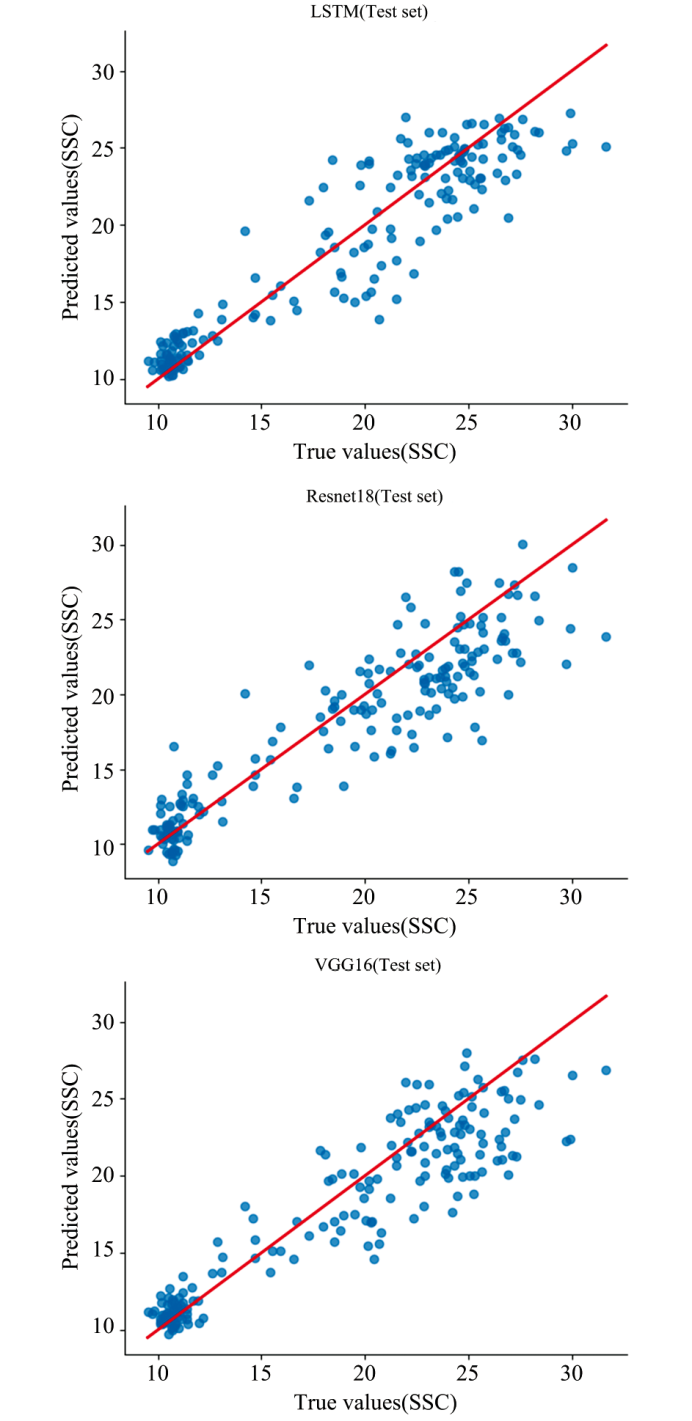 | 图6 MSC-SG-D1预处理后的VGG16、 Resnet18、 LSTM建模结果Fig.6 Modeling results of VGG16, ResNet18, and LSTM after MSC-SG-D1 preprocessing |
综合传统算法模型和深度学习模型的表现, 我们选取MSC-SG-D1为最终预处理方法。 以有效分离光谱数据中的散射光成分, 消除由不同散射水平引起的基线漂移和平移现象。 首先采用MSC方法处理光谱数据, 从而增强光谱与数据之间的相关性。 为保持光谱的主要特征和趋势, 进一步采用SG平滑处理光谱数据, 从而保持光谱的主要特征和趋势。 提高后续建模的稳定性和精度。 最后为去除由MSC和SG处理后可能残存的基线漂移和背景噪声, 同时增强光谱的细节特征。 选取一阶导数进一步处理光谱数据, 使得模型能够更准确地捕捉到与目标成分相关的光谱特征。 结果表明, 该预处理策略显著增强了模型的预测精度和稳定性。 实验结果证实, 光谱预处理能够显著增强模型的预测精度, 并且多种预处理方法的组合能够进一步提升模型的预测精度和稳定性。
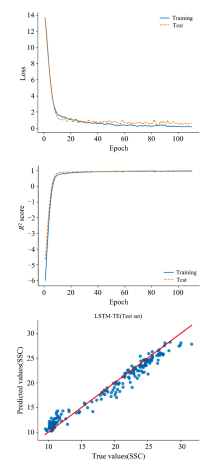
在确认预处理方法后, 采用LSTM-TE方法进行冬枣可溶性固形物预测模型的建立, 由于深度学习方法强大的特征提取能力和高效的数据处理能力, 免除了人工特征提取。 其中经预处理后的光谱数据为自变量, SSC为因变量。 建立LSTM-TE预测模型, 采取PLSR、 SVR、 VGG16、 ResNet18、 LSTM等主流方法建模进行对比实验。 模型性能对比如表4所示。 LSTM-TE模型预测结果如图7所示。
| 表4 不同预测模型训练结果对比 Table 4 Comparison of training results of different prediction models |
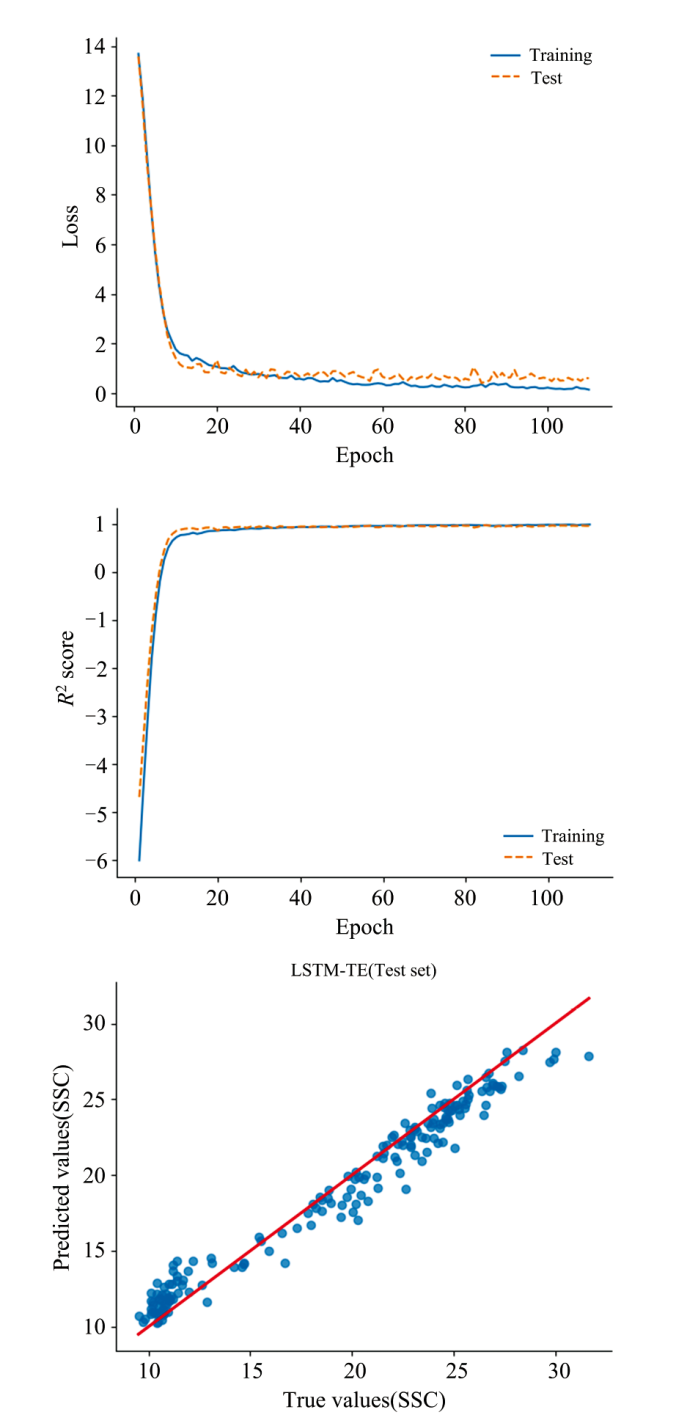 | 图7 LSTM-TE模型预测结果Fig.7 Prediction results of LSTM-TE model |
结果表明, 深度学习方法普遍优于机器学习方法, 可能是由于深度学习能够更好地捕捉数据中的复杂非线性关系和特征, 从而提高模型的预测能力和泛化能力。 在深度学习方法中, 本文所提出的LSTM-TE模型的
基于LSTM-TE模型的冬枣可溶性固形物含量预测, 通过将采集到的900个冬枣样本进行光谱数据采集与SSC检测, 随后对光谱数据预处理后建立SSC预测模型以实现冬枣SSC的快速无损预测。 实验结果表明:
通过对原始光谱数据进行多种单一及组合预处理方法的操作, 基于PLSR、 SVR、 VGG16、 ResNet18和LSTM五种模型进行建模和性能评估, MSC-SG-D1的组合预处理方法在不同建模方法(传统机器学习模型与深度学习模型)中均取得了最佳的性能, 与原始光谱数据相比, 拟合效果有所提升, 且优于其他预处理方法。 本文提出的一种融合Transformer编码层和LSTM网络结构的LSTM-TE冬枣SSC预测模型, 其在测试集上的
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|