



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱图像结合一维卷积神经网络的玉米大斑病早期识别
[路阳1, *  , 顾福谦
, 顾福谦1 , 谷英楠2, * , 许思源1 , 王鹏3, 4 ]
, 顾福谦, 许思源|
|


作者简介: 路 阳, 1976年生, 黑龙江八一农垦大学信息与电气工程学院教授 e-mail: luyanga@sina.com
大斑病在全球各大玉米产区都有出现, 降低了玉米的品质和产量。 该病害多在病斑明显时识别, 难以及时防治。 本文提出一维卷积神经网络(1DCNN)高光谱模型, 实现早期识别。 以玉米大斑病为研究对象, 手动接种大斑病后, 选取吐丝期的玉米叶片进行试验, 此时期刚显现病斑特征, 但无法通过视觉属性观察看出是何种病害。 首先采用SOC710E光谱仪采集高光谱图像, 通过选取感兴趣区域获得玉米叶片的健康和大斑病两种光谱数据。 使用SG卷积平滑、 多元散射校正(MSC)、 标准正态变换(SNV)和去趋势算法(DT)等四种光谱预处理方法, 以去除光谱数据中的噪声。 分别使用随机森林(RF)和K最近邻(KNN)两种监督学习算法, 以准确率作为评价指标, 对高光谱图像进行识别。 结果表明, MSC为优选的预处理方法, 两种模型预测准确率分别为88.13%和86.26%。 然后采用竞争性自适应重加权算法对玉米叶片光谱数据进行特征波长提取, 从原始的260个波长中优选出48个特征波长。 最后建立一维卷积深度学习模型进行分类, 识别准确率达到99.61%, 相较于传统分类模型KNN、 RF、 偏最小二乘判别分析(PLS-DA)、 反向传播神经网络(BP)、 支持向量机(SVM), 提出的模型识别准确率分别提高了5.94%、 6.88%、 6.48%、 8.27%、 12.12%。 高光谱技术结合深度学习模型可以更有效识别玉米大斑病, 为实现玉米病害早期识别提供了一种新的思路和方法。
Northern corn leaf blight (NCLB) occurs in major maize-producing regions globally, leading to a reduction in both maize quality and yield. Disease identification typically occurs when lesions are more obvious, making it challenging to prevent and control the disease promptly. This study proposes a one-dimensional convolutional neural network (1DCNN) model for early disease detection using hyperspectral imaging. In this research, NCLB was selected as the target disease. After manual inoculation, maize leaves at the silking stage were used for experiments, when lesions had just begun to appear, but the disease could not yet be visually identified. First, hyperspectral images were captured using the SOC710E spectrometer, and spectral data of both healthy and NCLB-infected maize leaves were obtained by selecting regions of interest. Four spectral preprocessing methods Savitzky-Golay smoothing (SG), multiplicative scatter correction (MSC), standard normal variate transformation (SNV), and detrending (DT) were applied to remove noise from the spectral data. Supervised learning algorithms, random forest (RF) and K-nearest neighbors (KNN), were employed for hyperspectral image classification, with accuracy as the evaluation metric. The results indicated that MSC was the optimal preprocessing method, achieving prediction accuracies of 88.13% and 86.26% for the RF and KNN models, respectively. Next, a competitive adaptive reweighted sampling (CARS) algorithm was applied to extract characteristic wavenumbers from the maize leaf spectral data, reducing the original 260 wavenumbers to 48 selected features. Finally, a 1DCNN deep learning model was developed for classification, achieving an accuracy of 99.61%. Compared with traditional classification models such as KNN, RF, partial least squares discriminant analysis (PLS-DA), backpropagation neural network (BP), and support vector machines (SVM), the proposed model improved recognition accuracy by 5.94%, 6.88%, 6.48%, 8.27%, 12.12%, respectively. These findings demonstrate that combining hyperspectral technology with deep learning models provides a new approach and method for early detection of maize diseases, enhancing the accuracy and timeliness of disease recognition.
玉米是中国三大谷物之一, 在全国范围内被广泛种植[1]。 玉米大斑病是全球各个玉米主产区普遍存在的叶部病害之一。 近年来, 国内玉米大斑病发生严重, 通常会导致玉米产量在发病年份减少约20%, 严重时甚至会减产一半以上。 因此, 迫切需要一种能够提前预测玉米病害, 并及时采取有效防治措施的方法。
对于传统的病害识别, 大多依赖于视觉属性[2], 出现病害特征后, 立即采取喷洒农药等措施来进行病害防治, 如果再进行理化检测和人工调查, 费时、 费力, 不能及时掌控病害发展情况, 错过最佳防治时机, 造成重大损失。 因此, 玉米病害发生初期进行诊断具有重要科学意义。 随着深度学习算法和高光谱成像技术的不断进步, 越来越多的学者开始利用高光谱图像信息和深度学习技术来识别农作物病害[3], 这种方法既准确又高效。 在玉米病害识别方面, 国内外众多学者已经取得了一些研究成果。 沈艳艳[4]等提出一种基于高光谱技术实现玉米典型叶部病害种类识别及其烈度分类的方法, 病害种类识别模型最优精度达95.06%, Macro F1达0.94。 Bai[5]等使用基于强化学习的响应时间分析和共线性诊断来挖掘敏感特征和重要特征。 结果表明, 集成叶绿素含量、 植被指数和波形特征的模型比仅使用光谱特征的模型显示出更高的精度, 最大差异为7.81%。 Liu[6]等建立了SVM、 BiLSTM和DBO-BiLSTM三种模型来区分玉米和大豆病害。 对比分析表明, 在玉米和大豆病害分类中, 基于CARS提取方法的DBO-BiLSTM模型表现出最高的分类准确率, 在测试集上达到98.7%。 Cen[7]等提出了一种基于一些最佳光谱特征的番茄BW检测模型, 在识别叶子青枯病的总体准确率上达到90.7%。 梁万杰[8]等基于ResNet50深度学习模型, 对其结构进行优化。 模型对油菜菌核病发病早期的识别准确率达到了88.66%。 王圆圆[9]等为了实现水稻病虫害的早期识别, 在经典的YOLOv4模型基础上, 提出了YOLOv4-tiny轻量化模型, 平均准确率可以达到81.79%。 当前国内外普遍都是以传统的机器学习方法为主[10, 11], 识别率不高, 且大多无法实现早期诊断, 或是直接建立三维卷积模型, 过程比较繁琐。 因此, 针对上述问题, 借助深度学习和高光谱技术, 实现精准且快速地在早期预测玉米大斑病, 是迫切需要解决的问题[12]。
本文提出一种基于高光谱图像技术的一维卷积神经网络, 对玉米大斑病进行早期检测, 在试验田通过手动接种大斑病菌后, 选取吐丝期叶片作为试验数据, 把采集到的高光谱图像数据预处理, 再通过手动选取感兴趣区域(ROI)得到玉米叶片高光谱数据, 采取多元散射校正(multiplicative scatter correction, MSC)作为预处理方法, 选取竞争性自适应重加权采样算法(competitive adaptive reweighted sampling, CARS)作为提取特征波长的方法, 并建立了深度学习模型, 识别准确率达到了99.61%, 相比传统的机器学习分类算法如BP神经网络(backpropagation neural network, BP)[13]、 K最近邻算法(K-nearest neighbors, KNN)[14]、 偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)[15]、 随机森林(random forest, RF)[16]、 支持向量机(support vector machine, SVM)[17]都有所提高。 本文的方法可以为早期识别玉米大斑病提供有效依据。
试验选用的玉米品种为本实验室筛选的不同基因型玉米品种, 包括郑单958和先玉335(其中室内培养试验为郑单958和先玉335, 室外仅为先玉335), 种子发芽率≥ 90%。 玉米种子采用人工精确播种, 行距为70 cm。 试验设置喷施玉米大斑病菌孢子悬浮液和未喷施玉米大斑病菌孢子悬浮液共2个处理, 本试验采用随机区组(RCBD)设计, 设定种子密度为82 500株· hm-2, 每个处理包含6行, 每行长15 m, 宽0.7 m, 并进行3次重复试验。
研究所用菌株由黑龙江省农业科学院植物保护研究所玉米植物保护研究室提供, 于25 ℃黑暗培养10 d, 在PDA培养基中培养, 收集分生孢子, 制备孢子悬浮液。 孢子悬浮液制备过程: 将长势良好的菌块, 用加油0.1%吐温20的溶液洗涤, 2层纱布过滤, 用血球计数板将溶液配置成浓度为1× 105个孢子· mL-1的分生孢子悬浮液。 分别在玉米11~12叶期(大喇叭口期)向玉米叶片表面进行喷雾接种, 接种量控制在5~10 mL· 株-1, 以清水为对照。 及在玉米三叶一心时期(幼苗期)向玉米叶片表面进行喷雾接种, 接种量控制在1~3 mL· 株-1, 以清水为对照, 保持培养箱温度(25± 2) ℃, 白天光照12 h, 湿度> 90%。
2022年, 在哈尔滨市呼兰区试验园区(海拔130米)进行玉米试验。 选用的先玉335为感病品种, 生长周期127 d, 积温超过2 700 ℃, 种子发芽率≥ 90%。 玉米通过人工精准播种, 保持70 cm的行距, 定植日期为5月10日, 试验区与其他种植区物理隔离, 确保病害不传播。 试验期间, 田间管理得当, 清理病残体和杂草, 合理施肥, 进行中耕除草等。
试验中高光谱仪器为SOC710E便携式可见/近红外成像光谱仪(测量波段范围375~1 032 nm, 光谱采样间隔2.5 nm), 如图1所示。
 | 图1 高光谱成像系统Fig.1 Hyperspectral imaging system |
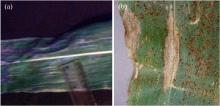
在玉米的生长过程中, 玉米大斑病的病斑在不同生长阶段表现出明显的差异。 特别是在成熟期, 病斑的特征非常明显, 容易被识别和诊断。 然而, 在吐丝期, 玉米植株的病斑表现则不明显, 仅能观察到一些初期的病斑, 且这些病斑的形态特征尚未完全显现, 难以通过肉眼准确区分和诊断病害类型。 如图2所示。
 | 图2 不同时期玉米叶片病斑特征 (a): 吐丝期; (b): 成熟期Fig.2 Characteristics of maize leaf lesions at different stages (a): Spinning stage; (b): Maturity stage |
将待测样本平铺, 尺子用于固定玉米叶片。 保证待测样本表面平整, 进行高光谱数据采集, 采用功率为150 W的钨丝石英卤素灯作为采集样本光源, 入射角度30° , 探头置于待测样本垂直上方, 视场角20° , 距离待测样本约40 cm(将叶片全部置于可视界面内), 每份待测样本采集光谱数据3次, 数据按顺序编号、 保存。 高光谱数据采集时, 在采集框中放置标准灰板, 以校正高光谱成像中的光照不均匀问题。 使用“ SRAnal710-E” 软件对原始高光谱图像进行处理, 并对玉米叶片的高光谱数据进行反射率转换, 以减少光照影响, 更准确地反映目标的光谱特性。
避开叶脉和叶片边缘, 通过选择有效的感兴趣区域, 然后计算该区域内所有像素点的光谱反射率平均值, 以此作为叶片样本的数据。 然后计算所有样本的光谱曲线的平均值± 标准差, 光谱曲线如图3所示。 其中健康叶片的光谱数据共316组, 接种大斑病菌的光谱数据共104组。 在整个波段范围内, 健康玉米叶片与受大斑病感染的叶片的反射光谱在光谱形态特征方面相似, 但反射率值存在明显差异。 整体上来看, 病害叶片在整个400~900 nm波段内的反射率普遍高于健康叶片。 其中500 nm处的反射率变化反映了叶绿素含量, 600 nm 处与叶片健康状况密切相关, 而750 nm附近的反射率则受细胞结构破坏影响, 表明其水分和组织结构发生了变化。
 | 图3 玉米叶片光谱曲线 (a): 健康; (b): 大斑病; (c): 健康和大斑病Fig.3 Spectral curve of corn leaves (a): Health; (b): Macroplaques; (c): Health and macroplaques |
光谱数据可能会受到仪器响应、 环境变化和样品特性或其他干扰的噪声影响, 影响建模和预测的精度。 因此, 为了提高数据的质量和建模性能, 本文采用四种较为常见预处理算法对玉米光谱数据进行预处理, 分别为SG卷积平滑、 多元散射校正、 标准正态变换和去趋势算法[18]。
MSC主要用于消除由于固体样品因颗粒大小不同、 颗粒形状差异等物理因素引起的散射影响。 MSC通过统计方法对玉米光谱因散射而引起的线性变化进行校正, 从而实现化学信息与散射信号分离。 其具体计算过程如下:
首先根据式(1)对采集到的光谱数据计算平均光谱, 然后对每个样品的光谱做最小二乘线性回归, 如式(2), 最后依据式(3)计算MSC处理后的每个光谱数据。
这些光谱预处理方法(SG卷积平滑、 MSC、 SNV、 DT)各自具有不同的数学原理和应用场景。 SG卷积平滑通过多项式拟合对光谱数据进行平滑, 去除高频噪声, 适用于信号中噪声较为明显的情况; MSC通过消除光谱数据中的散射效应, 减少基线漂移, 提高数据的一致性; SNV对光谱数据进行标准化处理, 去除仪器效应, 适合不同样本的比较; DT则通过计算导数来去除基线漂移, 并突出信号的微小变化。 因此, 这些预处理方法对结果的影响机理可以归结为: 去噪、 消除干扰、 标准化及增强微小特征的识别, 最终目标是提升数据的质量、 精度以及在后续分析中的可解释性。
本研究采用竞争性自适应重加权采样算法(CARS)进行特征选择。 CARS算法能够自适应地调整采样点的密度, 根据目标函数的局部特性动态选择采样点, 因此能更有效地探索目标函数的复杂结构[19]。
每次从玉米光谱数据校正集中选择80%的样本进入建模集进行模型训练, 其余样本作为测试集, 分别建立PLS模型。 首先根据式(4)计算每次对玉米叶片光谱数据进行处理时, 回归系数的绝对值权重。 设定|bi|为第i个变量回归系数的绝对值, 之后分别计算第i个变量回归系数的绝对值权重wi。
基于MC采样在第i次时建立PLS模型, 计算保留的玉米光谱特征点的比例Ri, 如式(5)所示。
当第N次(即最后一次采样)计算完成时, 保留波长点比例为2/n, 其中n是原始特征数。 可得常数μ 和常数k的计算公式如式(6)所示。
此时在N次采样结束之后, 会得到N组特征子集, 这些子集即为CARS算法选取的不同特征, 每一组子集都会对应一个RMSECV值, 通过寻找最小的RMSECV值, 选出相应的特征波长子集作为提取之后的特征。
卷积神经网络是一种专门用于处理图像、 声音和视频等多媒体数据的深度学习模型。 这种网络结构主要包括卷积层、 池化层和全连接层。 其中, 卷积层使用一组可训练的滤波器来扫描输入数据, 以捕捉各种特征, 如图像中的边缘、 角点和纹理。 这些卷积操作产生一系列称为特征图的输出。 接下来, 池化层通过减少特征图的大小来压缩数据和简化模型, 同时仍然保留关键的信息。 最终全连接层将这些提取出的特征整合, 并将它们映射到输出层, 以产生最终的预测或分类结果。 这种设计使CNN能够高效地从复杂的原始数据中学习并提取有用的信息[20]。 CNN工作原理如下。
输入层: 将输入的玉米叶片光谱曲线通过特征构造新的特征矩阵, 从而输入到网络中进行进一步特征提取并学习。
卷积层: 卷积层使用的是适合处理序列数据的一维卷积。 为了减少过拟合现象, 在每个卷积层后面引入BN层, 它可以加快网络的训练和收敛的速度, 防止梯度消失。 卷积操作如式(7)所示。
式(7)中, I是输入序列, K是卷积核, b是偏置项, O是输出序列。
池化层: 池化层的核心功能是下采样。 由于数据在经过多次卷积后, 其维度逐渐增加, 这会使网络训练难度加大, 甚至导致过拟合。 而池化层可以避免这种问题发生, 其可以通过对数据进行压缩来降低维度。 最大池化如式(8)所示。
式(8)中, s是池化的步长。
Dropout层: 为了减少参数量、 加快模型的训练速度并缓解过拟合现象, Dropout层的隐藏比例设置为0.5。
Dense层, 即全连接层, 在模型中起到“ 分类器” 的作用。 它将学到的“ 分布式特征表示” 映射到样本的标记空间, 分类公式如式(9)所示。
式(9)中, W是权重矩阵, b是偏置项, σ 是激活函数。
ReLU激活函数引入非线性到1D卷积网络, 如式(10)。
本研究需处理的玉米光谱数据为一维数据, 因此采用一维卷积神经网络(1DCNN)进行分析。
采用上述四种光谱预处理方法, 对原始的健康和大斑病玉米光谱数据进行分析。 这些方法的选择旨在有效地处理玉米叶片原始光谱中的噪声, 便于进行后续的进一步分析。
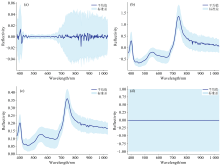
经过四种预处理方法得到的光谱曲线(平均值± 标准差)如图4所示。
 | 图4 不同预处理方法的结果 (a): DT; (b): MSC; (c): SG; (d): SNVFig.4 Results of different preprocessing methods (a): DT; (b): MSC; (c): SG; (d): SNV |
如图4所示, 经过DT处理后, 原始数据的噪声和冗余信息明显减少。 经过MSC处理之后, 离散数据明显减少, SG处理之后基线漂移问题得到一定的抑制, SNV处理进一步消除了散射效应, 提高了光谱数据的稳定性。 对光谱数据进行预处理之后, 在四种预处理结果的基础上分别建立KNN和RF模型, 模型识别准确率如表1所示。
| 表1 不同预处理建模分析的准确率(%) Table 1 Accuracy of different preprocessing modeling analyses (%) |
由表1可以看出, 经过MSC处理后模型识别准确率最高, 说明MSC处理后数据可以有效提高模型性能和精度。 对比四种预处理方法, 经MSC方法预处理后, 在RF和KNN两个模型中识别准确率分别提升了3.84%和6.89%。 经DT预处理与SNV预处理的效果不如原始数据。 因此, 确定MSC算法作为玉米叶片病害分类时, 优选的光谱预处理方法。
本研究采用CARS算法提取玉米光谱特征波长。 图5中(a)、 (b)和(c)分别表示在竞争性自适应重加权采样算法过程中, 260个变量数、 RMSECV值和变量回归系数路径的变化(本研究中设置MC采样次数为50次)。
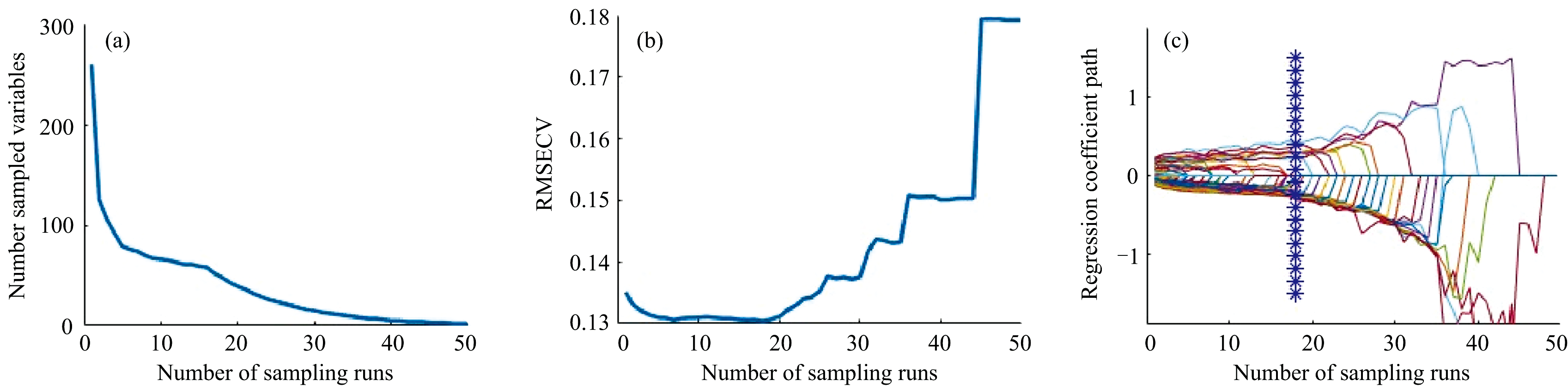 | 图5 CARS算法提取特征波长变量 (a): 迭代次数和变量的关系; (b): 不同的迭代次数的RMSECV值; (c): 变量PLS回归系数值Fig.5 CARS algorithm extracts feature wavelength variables (a): Iteration vs Variables; (b): RMSECV at different iteration; (c): PLS coefficients of variables |
图5(a)展示了采样次数与变量数量的关系, 采样次数在20次时, 下降趋势不再像当初明显, 并且有稳定的趋势。 图5(b)显示了交叉验证均方根误差随采样次数的变化, 初期误差较低, 后期随着采样次数增加, 误差上升。 图5(c)描绘了回归系数路径的变化, 随着采样次数增加, 部分变量的回归系数趋于稳定, 蓝色星号标记的特定位置可能为特征选择的关键节点。 总体而言, 合理的特征选择有助于在减少数据维度的同时保持关键信息, 从而提升模型稳定性和分类性能。
结果显示, 当采样次数为18次时, 所得均方根误差达到最小值。 此时选取的特征波长为48个。 这48个特征变量被认为是最具代表性和区分性的特征波段, 可以作为在后续建模处理中的特征指标。 具体结果如表2所示。
| 表2 CARS提取特征结果 Table 2 CARS feature extraction results |
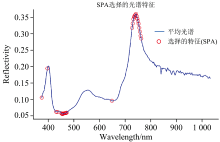
此外, 还建立了连续投影算法(successive projections algorithm, SPA)模型, 并从光谱数据中选择30个特征波长。 这些波长主要集中在反射率变化较大的区域, 如峰值和谷值附近。 所选特征具有较强代表性, 有助于减少冗余并提升建模识别能力和效率。 如图6所示。
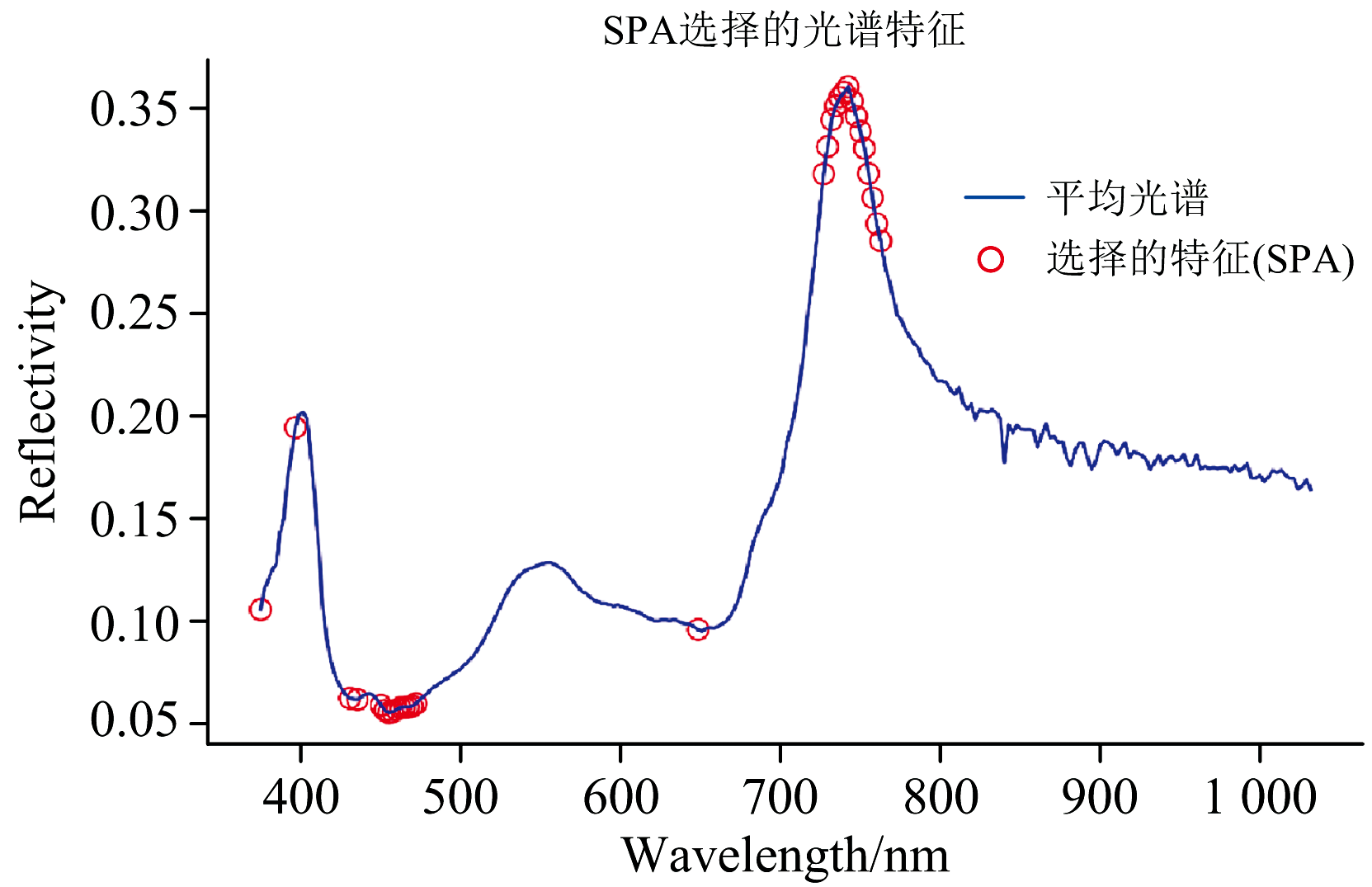 | 图6 SPA选择特征分布Fig.6 SPA selected features distribution |
对于CARS和SPA两种特征提取方法后的结果分别搭建RF模型, 准确率分别为92.73%和84.75%。 结果表明, CARS选取的特征更具代表性, 更能保留数据主要信息, 而SPA主要减少数据冗余, 但可能遗漏部分关键波长。 因此, CARS方法更适用于高光谱数据的特征提取。
2.3.1 基于CNN的玉米大斑病识别模型
本研究提出的模型如图7所示。
 | 图7 1DCNN网络结构模型图Fig.7 1DCNN network structure model diagram |
本研究构建的深度学习模型第一层为32个卷积核的卷积层, 使用ReLU激活函数。 数据通过窗口大小为2的一维最大池化层降维, 并通过丢弃率0.3的Dropout层防止过拟合。 第二层为64个卷积核的卷积层, 配备最大池化和Dropout层。 第三层为128个卷积核的卷积层, 继续采用最大池化和Dropout进行特征提炼。 特征提取后, 通过展平层将特征映射为一维向量, 并连接至64神经元的全连接层。 最终, 输出层为一个神经元的全连接层, 使用Sigmoid激活函数进行二分类预测。 该模型通过多层卷积与池化操作提取关键特征, 并利用Dropout机制降低过拟合风险, 确保模型稳定性和准确性。 模型的具体参数配置详见表3。
| 表3 1DCNN网络结构 Table 3 1DCNN network architecture |
2.3.2 网络模型训练及结果分析
本研究提出的1DCNN深度学习模型基于TensorFlow深度学习框架, 并采用Python编程语言进行开发。 实验中, 计算环境配置为Windows 10 64位操作系统, 配备NVIDIA GeForce GTX 1050 Ti(4GB显存)显卡。 软件环境包括Anaconda3(64位)、 CUDA 10、 Python 3.8以及TensorFlow-GPU 2.0, 确保了高效的计算性能和深度学习模型的优化训练。
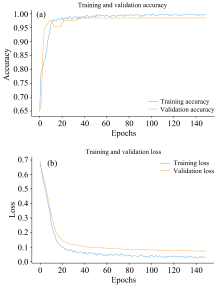
原始数据维度为420× 260, 经过特征选择后降维至420× 48。 数据按2∶ 1随机划分为训练集和测试集。 训练过程中, 使用Adam优化器优化模型参数, 提高模型稳定性, 学习率设定为0.001, 在训练初期可以保持较快的更新速度, 迭代次数设定为150次, 确保训练结束可以充分学习数据特征, 批处理大小设定为32。 每个epoch结束后进行一次验证, 记录训练集和验证集的准确率和损失值。 最终, 模型训练准确率为99.61%, 损失最小为0.03, 表现最佳。 训练和验证的准确率及损失值变化如图8所示。
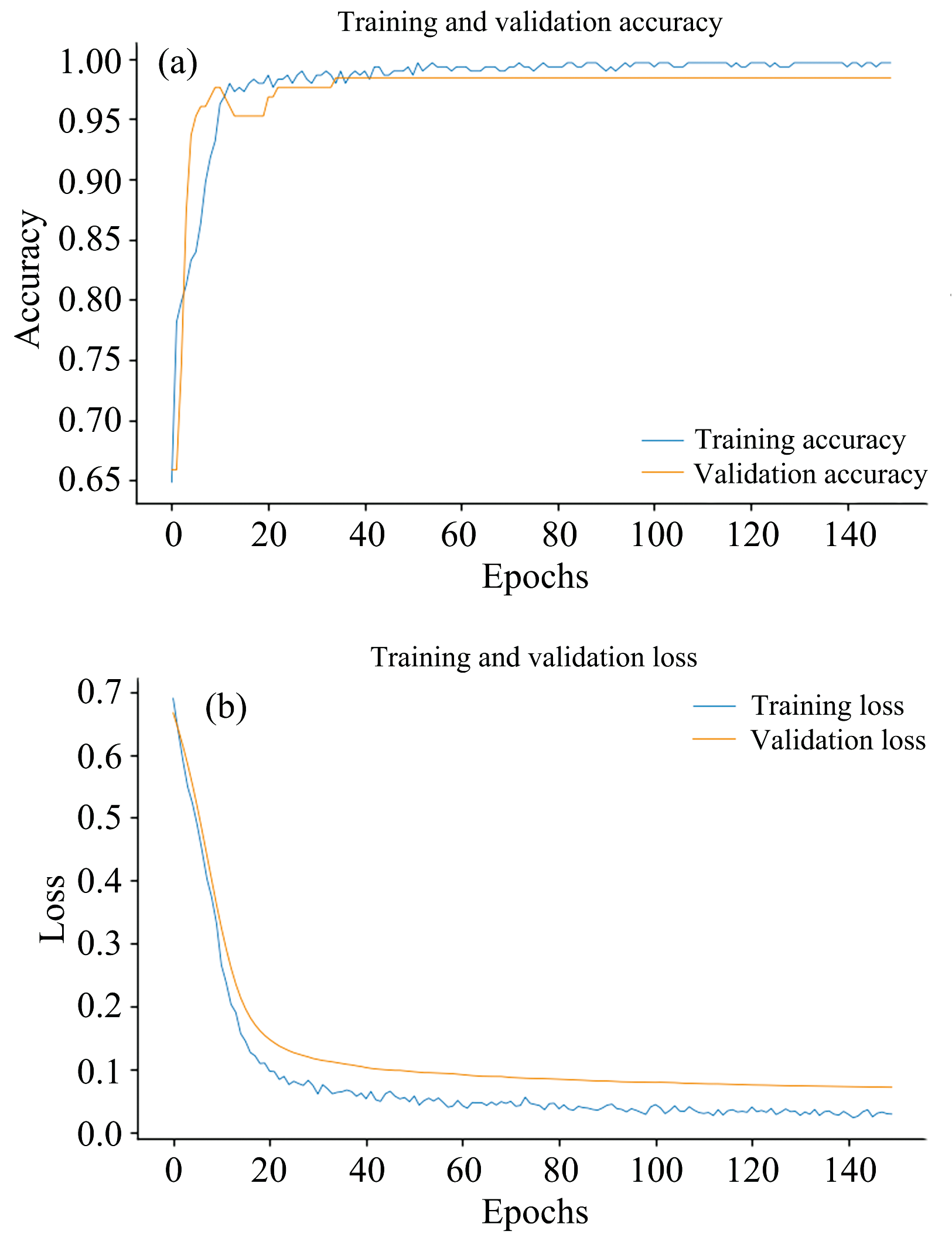 | 图8 准确率和损失值变化曲线图 (a): 准确率; (b): 损失值Fig.8 Accuracy and loss value variation curve (a): Accuracy; (b): Loss value |
1DCNN模型的样本训练集准确率曲线在训练次数为98次时, 曲线呈收敛趋势, 曲线准确率变换范围为0.65~0.99, 模型预测表现良好。 1DCNN模型的样本训练集损失函数在训练次数103次时, 曲线呈收敛趋势, 损失函数曲线变换范围为0.69~0.03。 模型的准确率已经达到99.61%。
2.3.3 模型结果与评价
为了全面评估本文提出的1DCNN模型在分类任务中的性能, 本研究在对玉米光谱数据进行分类时, 还应用BP神经网络、 KNN、 PLS-DA、 RF、 SVM等五种传统分类模型进行对比。 结果如图9所示。
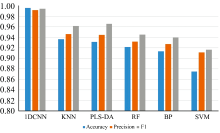
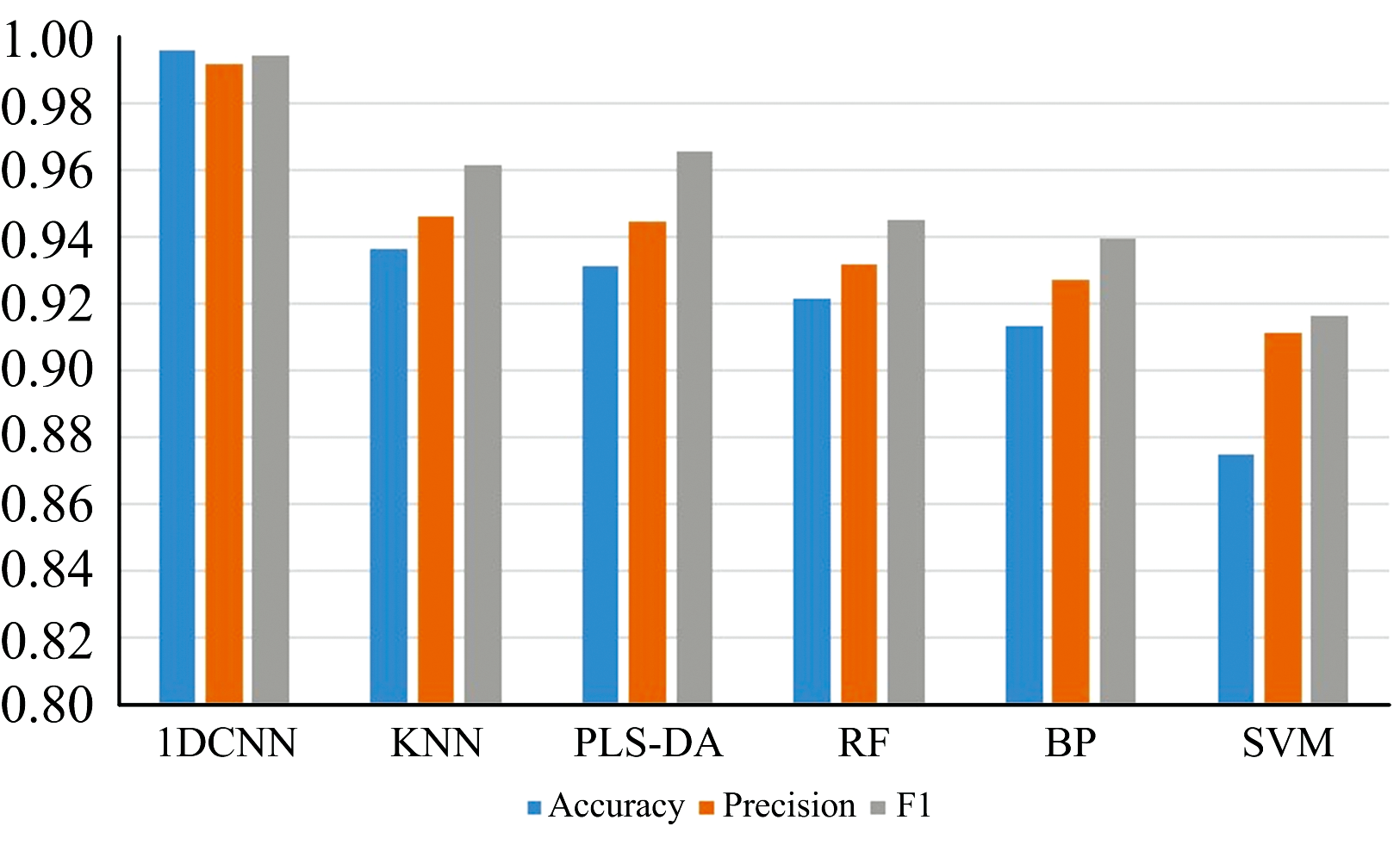 | 图9 各模型的准确率, 精确率和F1值Fig.9 Accuracy, Precision, and F1 value of each model |
结果显示, 1DCNN模型在处理序列数据时表现出了极高的准确性和稳定性, 其准确率达到了99.61%, 精确率为99.19%, F1分数高达99.46%, 远高于其他模型。 KNN模型适用于数据分布不规则的情况, 在分类任务中表现较为理想, 准确率为93.67%, 精确率为94.64%, F1分数为96.19%。 PLS-DA适用于处理具有高度相关性和多重共线性的高维数据, 可以在降低数据维度的同时保留最重要的信息, 其准确率为93.13%, 精确率为94.49%, F1分数为96.59%。 KNN和PLS-DA表现相对接近, 但在F1分数上 PLS-DA略胜一筹。 RF虽然适用于处理高维度数据, 但是对于非平衡数据集可能出现偏差, 其准确率为92.73%, 精确率为93.19%, F1分数为94.53%。 BP神经网络适用于处理复杂的非线性问题, 但是容易陷入局部最优解, 准确率为91.34%, 精确率为92.73%, F1分数为93.94%。 而SVM模型则适用于处理小样本数据, 对参数的选择较为敏感, 准确率为87.49%, 精确率为91.13%, F1分数为91.64%。
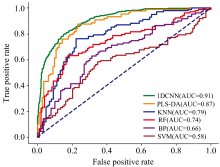
在模型评估过程中, 绘制了ROC曲线, 以直观地展示不同模型的表现。 ROC曲线展示了模型的正确识别样本比例与错误识别样本比例之间的关系, 从而帮助理解模型在不同操作点的权衡。 为了量化模型的表现, 还计算了AUC值(Area Under Curve)。 AUC值用于比较不同分类器的性能, 越接近1, 表示模型的分类性能越强。 ROC曲线如图10所示。
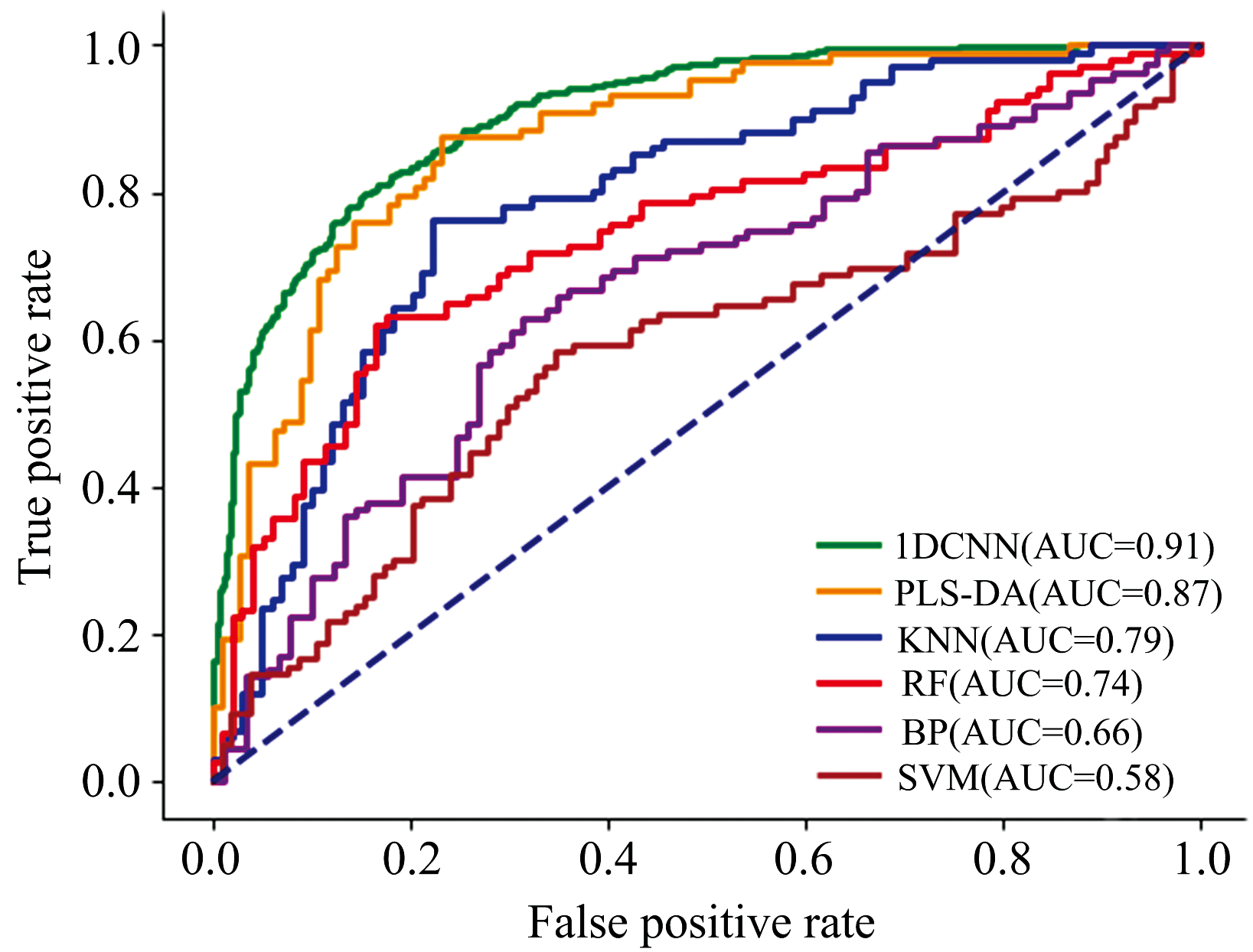 | 图10 不同模型的ROC曲线比较及AUC值评估Fig.10 Comparison of ROC curves and AUC values for different models |
可以看出, 1DCNN模型表现最佳, 其ROC曲线几乎接近左上角, AUC值为0.91, 说明该模型能够有效区分正负样本, 具备较强的分类能力。 PLS-DA(AUC=0.87)和KNN(AUC=0.79)也表现较好, 均能有效提高正样本识别率, 但其性能仍不如1DCNN。 RF(AUC=0.74)和BP(AUC=0.66)模型的性能较弱, 尤其是BP, 其分类能力远不及其他模型。 性能最弱模型是SVM(AUC=0.58), 其AUC值接近0.5, 1DCNN在区分正负样本方面表现极为出色, 能够有效提高分类准确率。
1DCNN通过多层卷积特征提取、 自适应权重学习和Dropout正则化技术, 提高了对微小变化的抵抗力, 降低了过拟合风险, 即使在噪声或特征偏移时仍能保持较高的分类性能。 池化层增强了特征提取的稳健性, 使模型能够忽略局部变化, 提取全局代表性特征, 提升了鲁棒性。 在泛化能力方面, 1DCNN能够有效识别高维特征中的关键信息, 减少冗余, 表现优异。 相比之下, KNN、 PLS-DA对数据分布依赖较大, SVM和BP神经网络对超参数敏感, 可能导致性能下降。 综上, 1DCNN在鲁棒性和泛化能力上优于传统模型, 适用于高光谱数据分类任务。
采用高光谱技术与一维卷积神经网络相结合的方法对玉米大斑病进行早期识别:
(1)本研究选取吐丝期玉米叶片作为试验数据, 获取健康玉米叶片与大斑病叶片的高光谱数据, 并采用多元散射校正方法对原始光谱曲线进行预处理, 以提高模型的稳定性和可靠性, 增强其泛化能力。
(2)对处理后的光谱数据, 采用CARS算法提取特征波段, 去除冗余变量, 降低模型复杂性。 从原始260个特征波长中优选48个特征波长, 精简率为82%, 有效降低了数据维度, 减少计算复杂性, 增强分类和识别能力。
(3)构建1DCNN深度学习模型对大斑病进行分类, 并与KNN、 SVM、 BP神经网络、 PLS-DA和RF五种机器学习模型进行比较。 结果表明, 本文构建的1DCNN模型的准确率高于传统学习模型, 准确率达到99.61%。
因此, 本研究构建的1DCNN模型是一种有效的玉米大斑病识别方法, 为玉米病害早期识别提供了一种新的研究思路和参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|