

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
InvertResNet: 基于深度学习和近红外光谱的药品定性分析方法
[黄天宇1  , 杨辉华
, 杨辉华1, 2 , 李灵巧1, * ]
, 杨辉华]
|
|


作者简介: 黄天宇, 2000年生, 桂林电子科技大学计算机与信息安全学院硕士研究生 e-mail: huangtianyuu@163.com
分类或定性分析是药品溯源、 真伪鉴别的关键技术。 然而在实际应用中常面临近红外光谱数据的非线性特征、 样本量不足、 数据噪声干扰以及复杂的预处理过程等技术挑战。 传统机器学习方法难以充分捕捉光谱数据中的深层次信息, 导致分类性能有限。 随着深度学习技术的迅速发展, 其自动特征提取和处理能力为近红外光谱数据分析提供了新的解决途径。 本研究提出一种名为InvertResNet的卷积神经网络: 该方法首先将一维光谱数据转换为二维伪图像, 并在转换过程中采用双线性插值法对数据进行填充, 以确保二维化后的光谱数据完整性; InvertResNet在经典卷积神经网络(CNN)框架基础上, 引入倒残差结构, 通过先扩展后压缩特征维度, 优化了模型的深度和宽度, 在保持轻量级特性的同时, 有效抑制了噪声干扰, 并提升了特征提取和表达能力。 该方法采用二维转换不仅解决了数据长度不足的问题, 还保留了光谱数据的局部和全局空间相关性, 从而增强了模型对复杂模式和非线性信息的识别能力。 为全方位评估InvertResNet的性能, 利用草莓泥近红外光谱数据集对该方法展开初步验证, 结果显示其在草莓泥光谱数据处理中展现出良好适应性与初步有效性, 为后续深入研究筑牢根基。 此后, 研究重点转向公开的药品近红外光谱分类数据集。 在此数据集上, 将本方法与传统的偏最小二乘法(PLS)、 支持向量机(SVM)、 随机森林(RF)、 标准卷积神经网络(CNN)、 Swin-Transformer模型(SwinTR)、 GhostNetV2及基于Transformer架构的SpectraTr模型进行了对比测试。 结果表明, 在不同的训练样本比例下, InvertResNet均优于PLS等传统算法和标准CNN结构。 在低训练样本比例的情况下, InvertResNet实现了95.97%的分类准确率, 显著优于PLS-DA(79.39%)、 SVM(68.44%)、 RF(67.74%)、 CNN(91.94%)、 SwinTR(92.74%)和GhostNetV2(89.91%)。 随着训练样本的增加, InvertResNet的分类准确率进一步提高, 并在高比例训练样本条件下达到了100%, 相比于其他模型, 如CNN的98.39%、 SwinTR的98.38%和GhostNetV2的98.39%, 依然表现出明显的优势。 综上所述, InvertResNet通过其创新的倒残差结构和二维光谱数据变化及增强方法, 在药品近红外光谱分析中表现出色, 显著提升了分类准确率, 在近红外光谱分析领域的具有广阔的应用前景。
Classification or qualitative analysis is a key technique for drug traceability and authentication applications. However, in practical applications, we often face technical challenges such as the nonlinear characteristics of near-infrared spectral data, insufficient sample size, data noise interference, and complex preprocessing processes. Traditional machine learning methods cannot fully capture the deep information in spectral data, resulting in limited classification performance. With the rapid development of deep learning technology, its automatic feature extraction and processing capabilities provide a new solution for near-infrared spectral data analysis. In this study, a convolutional neural network named InvertResNet is proposed: the method first converts one-dimensional spectral data into two-dimensional pseudo-images and fills the data with bilinear interpolation during the conversion process to ensure the completeness of the two-dimensionalized spectral data; InvertResNet introduces an inverted residual structure based on the classical convolutional neural network (CNN) framework. By first expanding and then compressing the feature dimensions, the model's depth and width are optimized, effectively suppressing the noise interference and improving the feature extraction and expression capabilities while maintaining the lightweight characteristics. The method adopts a two-dimensional transformation that solves the problem of insufficient data length and preserves the spectral data's local and global spatial correlation, thus enhancing the model's ability to recognize complex patterns and nonlinear information. To evaluate the performance of InvertResNet, this study first utilizes the strawberry puree near-infrared spectral dataset to carry out a preliminary validation of the method, and the results show that it has demonstrated good adaptability and preliminary effectiveness in strawberry puree spectral data processing, which has laid a solid foundation for subsequent in-depth research. Thereafter, the research focus shifts to the publicly available near-infrared spectral classification dataset of pharmaceuticals. On this dataset, the method of this thesis was compared with the traditional partial least squares (PLS), support vector machine (SVM), random forest (RF), standard convolutional neural network (CNN), Swin-Transformer model (SwinTR), GhostNetV2, and SpectraTr model based on the Transformer architecture. Comparative test experiments were conducted. The results show that InvertResNet outperforms traditional algorithms such as PLS and standard CNN structures at different training sample ratios. At low training sample ratios, InvertResNet achieves a classification accuracy of 95.97%, which is significantly better than PLS-DA (79.39%), SVM (68.44%), RF (67.74%), CNN (91.94%), SwinTR (92.74%) and GhostNetV2 (89.91%). With the increase of training samples, the classification accuracy of InvertResNet further improves and reaches 100% under the condition of a high percentage of training samples, which still shows a clear advantage over other models, such as 98.39% for CNN, 98.38% for SwinTR and 98.39% for GhostNetV2. In summary, InvertResNet, with its innovative inverted residual structure and two-dimensional spectral data variation and enhancement method, performs well in the near-infrared spectral analysis of pharmaceuticals, significantly improves the classification accuracy, and has a broad application prospect in the field of near-infrared spectral analysis.
药品制造是一个高度复杂且严格监管的过程, 产品质量受制造商专业知识、 原材料质量、 生产环境及质量控制措施等多种因素影响[1, 2, 3, 4]。 不法分子使用低质量原材料或简化生产工艺生产假冒药品, 危害消费者健康并损害合法企业声誉[5, 6, 7]。 因此, 质量检测在药品监管中尤为重要[8]。 传统的化学分析方法过程复杂、 资源消耗大且具有破坏性[9], 相比之下, 近红外光谱具有无损、 快速和成本低效益高的优势[10], 已广泛应用于食品安全[11, 12, 13]、 农业[14]、 医药[15]和石油化工[16, 17]等领域。
NIR光谱分析以往主要依赖于传统机器学习方法, 如偏最小二乘法(PLS)、 支持向量机(SVM)和随机森林(RF), 这些方法在特征提取能力、 噪声敏感性和光谱重叠处理上存在局限, 且需要大量预处理和波长选择工作[18, 19, 20, 21]。 深度学习技术的迅速发展为NIR光谱数据分析提供了新的机遇, 通过自动特征提取和强大的模式识别能力, 显著提升了分类与定性分析的准确性和鲁棒性。 例如, Jacopo等[22]开发了一种浅层卷积神经网络(CNN)模型, 用一个公开可用的光谱数据集测试, 平均准确率达到86%, 显著优于PLS方法, 展示了CNN在近红外光谱分类任务中的潜力。 Jiang等[23]改进了ResNet模型, 并将其应用于烟叶产地识别, 模型准确率达到97%, 从而确认了深度网络在近红外光谱分析中的有效性。 在最近的一项研究中, Fu等[24]介绍了SpectraTr, 这是一种基于Transformer架构的新型深度学习模型, 用于药品光谱的定性分析, 突显了基于Transformer模型在光谱分析中的多样性和增强性能。 鉴于深度学习在图像处理中的成功, 预计其在NIR光谱分析中将进一步发展。 本研究提出了一种创新的卷积神经网络模型InvertResNet, 具有以下显著进步:
(1)倒残差结构: 引入倒残差块, 结合扩展因子和逐通道可分离卷积, 实现高效特征提取, 同时减少计算负担和参数数量, 提升计算效率和模型性能。
(2)光谱数据的二维重塑: 将一维光谱数据转换为二维伪图像, 增强模型对空间相关性、 复杂模式和非线性信息的捕捉能力, 提高分类准确性和鲁棒性, 特别适用于大规模近红外(NIR)光谱数据分析。
这些创新显著提升了InvertResNet在NIR光谱药品表征中的性能。 应用在公开药品数据集上, 模型达到了100%的准确率, 远超传统机器学习算法。
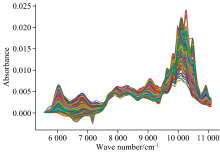
分别对数据集A和B进行了定性建模分析, 数据集A由生物技术与生物科学研究理事会[25]提供, 共包含983个样本, 均为草莓及其他多种水果果泥的光谱数据。 样本类别清晰划分为两类, 一类为草莓果泥样本, 另一类涵盖了掺假草莓果泥以及树莓、 苹果等单一或混合果泥样本。 每条光谱波长范围为900~1 800 nm, 间隔4 nm, 共有235个数据点。 原始光谱数据分别如图1所示。 引入该数据集, 主要是为了初步验证所提算法的有效性, 为后续更为深入的研究奠定基础。
 | 图1 数据集A的光谱Fig.1 Spectra of dataset A |
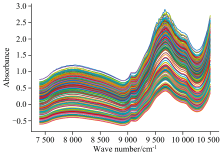
数据集B来自哥本哈根大学, 其中包含310个波数范围为7 400~10 507 cm-1的药品样本, 共404个数据点, 该数据集依据药片所包含的活性物质浓度与剂量差异, 将药品样本清晰划分为四类。 原始光谱数据如图2所示。 可以从http://www.models.life.ku.dk/Tablets 获取。
 | 图2 数据集B的光谱Fig.2 Spectra of dataset B |
1.2.1 光谱数据二维化
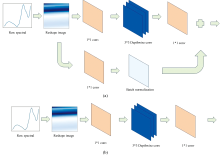
深度学习擅长识别二维图像中的模式, 因此将一维光谱数据转换为二维伪图像, 以更有效地捕捉和分析空间相关性。 基于CNN提取空间特征的能力, 此转换保留了数据的局部和全局关系, 使CNN能够捕捉梯度、 边缘和纹理等模式, 并通过分层特征提取识别高层次抽象特征, 增强对复杂模式的解释能力。
二维伪图像引入空间不变性, 提高特征对偏移或轻微失真的鲁棒性, 适用于变异性光谱数据分析。 此外, 该方法可无缝集成到现有深度学习框架中, 便于数据增强和迁移学习, 提升分析效率。 实验中, 采用双线性插值法填充不足的一维光谱数据, 确保连续性后重塑为二维矩阵, 如图3所示。
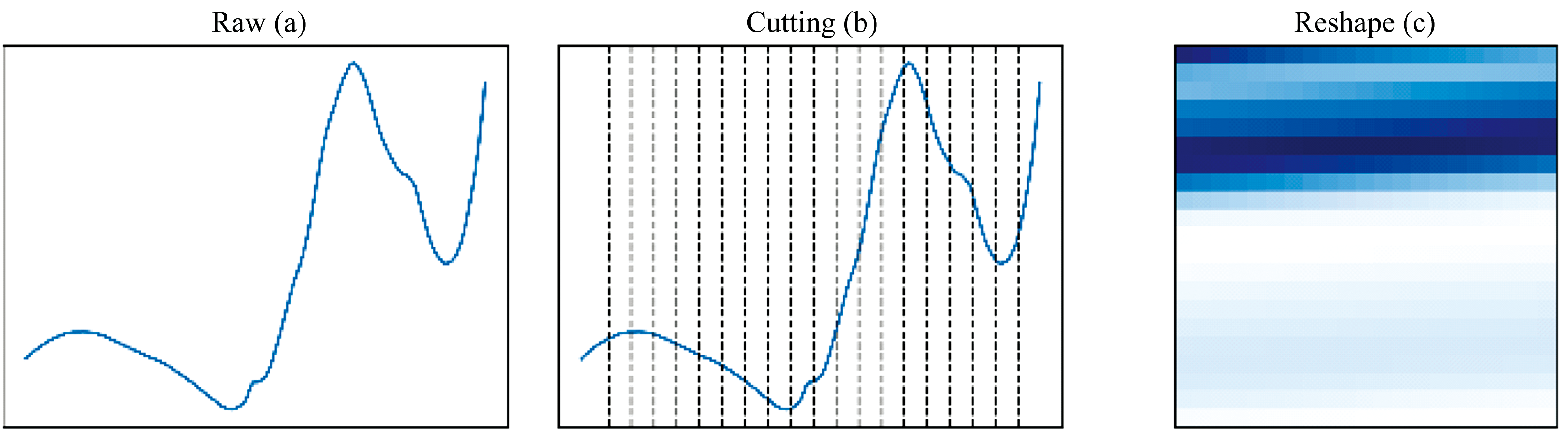 | 图3 将近红外光谱序列重构为二维图像 (a): 原始近红外光谱; (b): 切割后的结果; (c): 数据重组后生成的图像Fig.3 Reconstruction of NIR spectral sequences into 2D images (a): Raw NIR spectral; (b): The result after cutting; (c): The image generated after data reorganization |
该方法首先验证光谱数据的长度是否足以重塑为目标二维矩阵(如20× 20), 若数据长度不足, 则采用双线性插值法填充缺失值。 在插值过程中, 选择最邻近的四个数据点进行加权平均, 以保证数据的平滑性和连续性。 对于每个缺失值, 通过计算周围数据点的加权平均值进行填充, 从而提高插值过程的准确性。 接下来, 对光谱数据进行修剪, 若数据点数超过目标矩阵需求, 则对数据进行修剪, 若不足, 则通过插值进行补充, 以确保数据完整且特征不变。 最后, 将经过修剪或插值处理得到的一维数据重塑为二维矩阵, 便于CNN等模型进行处理。
为了验证将一维光谱数据转换为二维格式的有效性, 我们在数据集A上进行了实验, 比较了在一维和二维数据表示上训练的模型的性能。 表1总结的结果清楚地表明, 对光谱数据进行二维重塑可显著提高分类准确率。
| 表1 光谱数据二维重塑前后的模型准确率比较 Table 1 Comparison of model accuracies before and after two-dimensional reshaping of spectral data |
实验结果表明, 将一维光谱数据转换为二维伪图像格式显著提高了模型的分类准确率, 验证了空间信息在光谱数据分析中的关键作用。 具体而言, 在相同的训练样本比例下, 将数据从一维转换为二维后, 测试集的准确率有所提高。 例如, 在训练集样本为248、 测试集样本为62的情况下, 二维数据的准确率分别为CNN模型的92.37%和InvertResNet模型的95.19%, 相比于一维数据训练时的90.20%和94.06%, 分别提高了2.17%和1.13%。 这表明, 二维数据重塑不仅帮助模型更好地理解数据的内在结构, 还提升了其在测试集上的泛化能力, 尤其是在样本较少时, 二维数据的表示能够更有效地减轻数据稀缺带来的负面影响。 此外, 实验还验证了在不同训练样本比例下, 数据维度对模型表现的稳定性和可靠性的影响。 当训练集和测试集的比例发生变化时, 二维数据的优势依然明显。 在训练集为62、 测试集为248的情况下, 二维数据训练的模型依然能够保持较高的准确率(CNN为92.37%, InvertResNet为95.19%), 且准确率较一维数据训练时有所提高。 这进一步表明, 二维数据在不同样本规模下能够提高模型的鲁棒性和稳定性, 尤其是在训练样本较少的情况下, 二维数据增强了模型对光谱数据的理解, 从而提升了分类效果。
1.2.2 使用Kennard-Stone算法的数据划分方法
数据泄漏是机器学习中的关键问题, 指在模型训练中使用了训练集之外的信息, 导致性能评估过于乐观且泛化能力下降。 为防止数据泄漏并确保模型评估的稳健性, 必须以保持数据完整性和多样性的方式划分训练集和测试集[26]。 Kennard-Stone算法通过迭代选择具有最大欧氏距离的样本, 确保训练集覆盖整个特征空间, 提升多样性和代表性, 从而有效降低数据泄漏的风险[27]。
要实现Kennard-Stone算法, 首先要计算数据集中所有样本对之间的欧氏距离, 形成距离矩阵D。 其数学表达如式(1)
式(1)中, xi和 xj分别是样本i和j的特征向量。 距离矩阵D表示所有样本之间的成对距离。
接下来, 算法会找出一对距离最大的样本。 这两个样本被设定为训练集中的初始样本。 可以表示为
式(2)中, i* 、 j* 是根据距离矩阵D得出的数据集中相距最远的两个样本的指数。
这一步将确定训练集中的两个初始样本, 以确保数据集特征空间的广泛初始覆盖。
选定的样本指数m将以这两个指数进行初始化
该算法通过迭代选择额外的样本来进行。 对于每个后续样本, 都会选择与已选样本距离最小的样本。 这样可以确保新样本尽可能远离当前选定的样本集。 迭代选择标准为
式(4)和式(5)中, di, min计算的是从任何候选样本i(尚未被选中)到任何已被选中并包含在样本集m中的样本k的最小距离。
这一措施可确保下一个要选取的样本尽可能远离当前选取的样本集, 从而最大限度地提高覆盖率和多样性。
其中, i* 是下一个要选取的样本的索引, 选取时要使其与已选取的样本集m的最小距离di, min最大化。
这种选择标准会不断迭代, 每次向集合m中添加一个样本, 直到达到所需的样本数量或充分覆盖整个数据集。
通过上述步骤, Kennard-Stone算法确保训练集和测试集的独立性, 最大化特征空间的覆盖率和多样性, 减少测试集与训练集的重叠, 从而有效降低数据泄漏的风险。 所有实验结果均基于测试集得出。
1.2.3 InvertResNet
倒残差块在本文的网络架构中起着核心作用。 InvertResNet的卷积块由倒残差块、 批归一化(BN)层和激活层组成。 每个倒残差块的输入首先通过一个1× 1卷积层(扩展层)来增加特征图的深度, 其计算公式为
式(6)中, E(x)是扩展层的输出, We是1* 1卷积核的权重矩阵, be是偏置项, * 表示卷积操作, x是输入特征图。
随后, 一个3× 3深度可分离卷积块(3× 3 DW Conv Block)处理扩展后的特征图。 深度可分离卷积由两部分组成: 第一部分是深度卷积, 对每个输入通道分别应用滤波器; 第二部分是1× 1逐点卷积, 用于合并深度卷积生成的特征图。 这个过程可以表示为
式(7)和式(8)中, D(x)是深度卷积的输出, P(D(x))是逐点卷积后的输出, Wd是深度卷积的权重, Wp是1* 1卷积核的权重, bP是逐点卷积的偏置项。
接下来, 批量归一化(BN)层用于对特征图进行正则化, 批量归一化层加快了训练速度, 并通过每个特征图的输出提高了性能, 其计算公式如式(9)
式(9)中, x是特征图的输入, μ 是批次内特征的平均值, σ 2是特征的方差, ε 是一个很小的数, 以避免除以零, γ 和β 分别是用于缩放和平移归一化数据的可学习参数。
倒残差块的末端是一个1× 1卷积层, 称为投影层, 用于降低特征图的维度, 使其与反转残差块的输出维度相匹配。 投影层的计算公式如式(10)
式(10)中, P(x)是投影层的输出, Wp是1* 1卷积核的权重, bP是偏置项, * 表示卷积操作, x是输入特征图。
在步长为1的倒残差块的两个变体中, 倒残差块都包含一个快捷连接, 可以将输入直接添加到投影层的输出。 快捷连接的计算公式如式(11)
式(11)中, F(x)是快捷连接的输出, x是输入特征图, P(x)是投影层的输出。
快捷连接帮助网络学习恒等映射, 减少梯度消失, 提升信息流。 在步长为2时, 由于特征图尺寸减半, 快捷连接被忽略, 倒残差块用于降低特征图尺寸、 减少计算量并扩大感受野。 倒残差块的设计平衡了模型的复杂性与效率, 使网络在保持轻量级的同时表现出良好性能, 特别适用于计算资源有限的移动和边缘设备。 其网络结构如图4所示。
 | 图4 倒残差块 (a): Stride=1(with shortcut); (b): Stride=2(no shortcut)Fig.4 Inverted residual block (a): Stride=1(with shortcut); (b): Stride=2(no shortcut) |
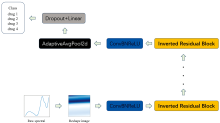
InvertResNet架构经过精心设计, 实现了高性能与计算效率的平衡, 适用于移动和边缘计算环境。 网络由初始卷积层、 多个倒残差块、 逐通道可分离卷积及全连接层组成。 每个倒残差块包含扩展层和逐通道可分离卷积, 后者分为逐通道卷积和逐点卷积。 所有卷积层后均应用批量归一化和ReLU6激活函数, 以加速训练并提升稳定性。
网络末端设有自适应平均池化层和dropout层, 以减少特征维度并防止过拟合, 最终通过全连接层输出分类结果。 倒残差块中的捷径连接有效缓解了梯度消失问题, 确保信息流畅传递。 整体设计使InvertResNet在处理高维数据时既高效又轻量, 即便在计算资源有限的情况下, 也能保持稳健的性能。
图5和表2概括了InvertResNet架构的详细结构。
 | 图5 InvertResNet结构示意图Fig.5 InvertResNet |
| 表2 InvertResNet网络的详细结构 Table 2 Detailed structure of the InvertResNet architecture |
AdaptiveAvgPool2d层的使用减少了空间维度, 通过减少参数数量使模型更加高效。 Dropout+Linear层进一步帮助防止过度拟合, 确保模型能够很好地泛化到新数据。
为了全面评估模型的性能, 采用了准确率(Accuracy)、 精确率(Precision)、 召回率(Recall)和F1指数(F1-Score)四个指标, 定义如式(12)— 式(15)
其中, TP、 TN、 FP、 FN分别表示真阳性、 真阴性、 假阳性和假阴性。
模型训练采用交叉熵损失函数, 其数学表达式为
式(16)中, N是训练集中样本的总数, M是类别的总数, yi, C是一个二进制指示器(0或1), 表示样本i是否属于类别C, 而
InvertResNet模型使用Python3.8和PyTorch2.0.1实现, 实验在配备NVIDIA GeForce RTX 3060 GPU和Intel i5 12400F CPU的工作站上进行。 为确保公平比较, 所有模型的超参数设置一致, 均采用交叉熵损失和Adam优化器。 训练过程中引入了学习率衰减策略(若10个epoch内损失不减则将学习率减半)及提前停止策略(若30个epoch内损失不减则终止训练)。 所有模型的超参数如表3所示。
| 表3 本研究中所有模型的超参数 Table 3 The hyperparameters of all models in this study |
本次实验聚焦于草莓及其他多种水果果泥的近红外光谱数据, 旨在实现精准预测, 并与其他基准方法展开全面且深入的比较分析。 在实验前期数据处理阶段, 为确保样本分布的合理性与代表性, 采用了分层随机抽样策略, 将数据集按照80%与20%的比例精准划分为训练集与测试集。 所有光谱数据均经过标准预处理流程以保证特征一致性。 所有模型均在该标准化数据集上进行训练和评估, 保持测试条件一致。 InverResNet与CNN模型的预测性能如表4所示。
| 表4 InvertResNet和CNN在草莓数据集上的预测结果(%) Table 4 Prediction results of InvertResNet and CNN on strawberry dataset (%) |
表4的结果显示, InverResNet的各项评估指标表现出色, 准确率(Acc)、 精确率(Precision)、 召回率(Recall)以及F1-Score均高达97.97%, 展现出对草莓及其他多种水果果泥光谱数据预测的卓越性能与高度稳定性。 相比之下, CNN模型的预测性能稍逊一筹, 虽然准确率达到96.45%, 精确率为96.63%, 召回率为96.45%, F1-Score为96.40%, 但在整体性能上与InverResNet存在一定差距。 这一结果充分表明, 针对该特定水果果泥近红外光谱数据的预测任务, InverResNet相较于CNN 等基准方法具有更为显著的优势, 能够为相关领域的研究与应用提供更为精准可靠的预测结果。
鉴于近红外光谱数据获取成本普遍偏高, 致使数据量相对有限, 为深入探究模型在不同数据规模下的性能表现, 设计了本次实验, 将数据集按照0.8~0.2的比例随机抽取数据, 构建不同比例的训练集与测试集进行实验, 以预测的准确率作为关键评估标准, 将InvertResNet与其他基准模型进行对比, 结果如表5所示。
| 表5 不同模型在不同训练样本比例设置下的测试集准确率(%) Table 5 Test set accuracies (%) of different models under different training sample ratio settings |
通过对表5结果的深入分析可知, 在不同训练样本比例设置下, 深度学习模型CNN与InvertResNet 的预测准确率显著优于传统的化学计量学方法, 如PLS_DA和SVM。 且在训练样本数量减少的情况下, 模型性能仍表现出较高水平。 在训练集样本数为788, InvertResNet模型达到了98.21%的预测准确率。 当训练集规模进一步减少至196时, 模型仍保持了95.57%的准确率, 相较于CNN模型在同等条件下的表现更为出色。 这充分彰显了InvertResNet模型在处理小样本近红外光谱数据分类任务时, 具备更强的适应性与稳定性。
2.2.1 对比实验
旨在评估InvertResNet模型在利用近红外(NIR)光谱鉴别药物化合物方面的能力。 为此, 我们将InvertResNet与传统机器学习方法、 标准卷积神经网络[28](CNN)、 Swin-Transformer[29](SwinTR)、 GhostNetV2[30]和SpectraTr[24]。 所使用的NIR光谱药物数据集经过归一化和预处理, 以确保一致性。 所有模型均在该标准化数据集上进行训练和评估, 保持测试条件一致。 表6详细列出了对比实验的结果。
| 表6 光谱数据上各种分类模型的评价指标(%) Table 6 Evaluation metrics for various classification models on spectroscopic data (%) |
InvertResNet模型在所有评估指标上表现卓越, 准确率达到100%, 显著优于传统机器学习方法(PLS-DA、 SVM、 RF)、 标准CNN和Swin Transformer。
InvertResNet采用深度可分离卷积技术, 显著减少模型参数数量并增强特征提取能力。 实验结果表明, InvertResNet在近红外(NIR)光谱药品识别任务中表现卓越, 图6(a)显示其在训练初期迅速达到100%的准确率, 图6(b)则显示其训练损失快速下降并稳定于低水平。
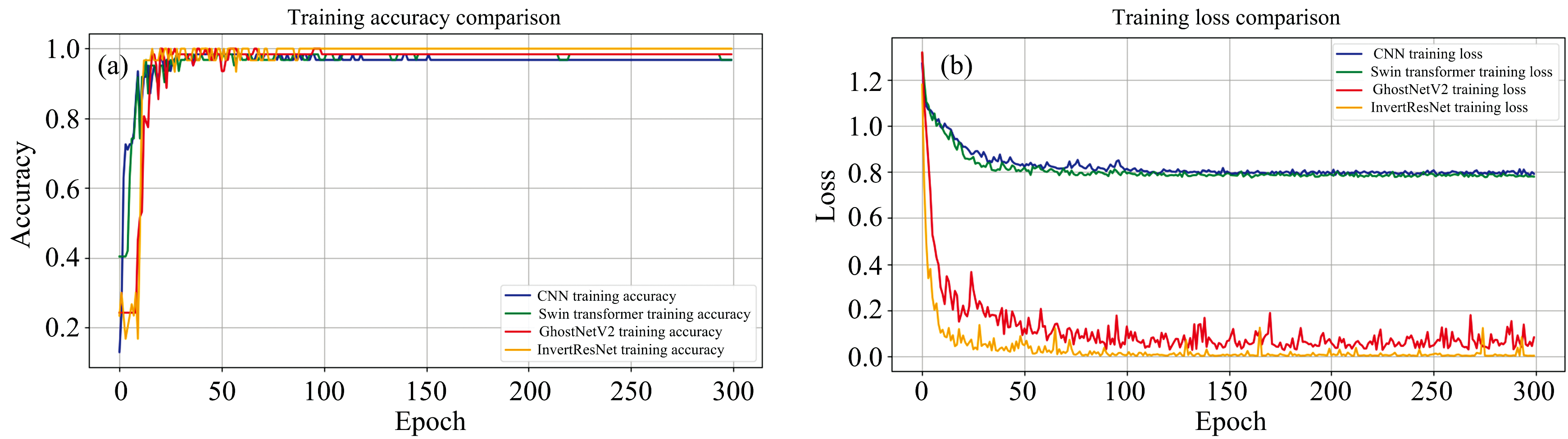 | 图6 训练集的准确率和损失值 (a): 准确率; (b): 损失值Fig.6 Accuracy and loss value of training set (a): Accuracy; (b): Loss value |
这些结果凸显了InvertResNet在NIR光谱数据分析和药品识别任务中的卓越能力, 验证了二维表示光谱数据在深度学习模型中的优势。
2.2.2 模型在测试集上的性能
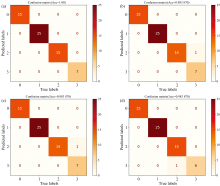
混淆矩阵是分类任务中重要的可视化工具, 用于展示实际类别与预测类别的对应关系。 图7比较了InvertResNet、 CNN、 Swin-Transformer和GhostNetV2模型的分类性能。 InvertResNet的混淆矩阵显示所有样本均被准确分类, 达到100%的准确率。 相比之下, CNN、 Swin-Transformer和GhostNetV2虽然在大多数类别上表现良好, 但在部分类别仍有误分类。 对比结果凸显了InvertResNet在分类任务中的卓越性能和优异的泛化能力。
 | 图7 InvertResNet (a)、 CNN (b)、 Swin-Transformer (c)和GhostNetV2 (d)测试集混淆矩阵Fig.7 Confusion matrices for test sets of InvertResNet (a), CNN (b), Swin-Transformer (c) and GhostNetV2 (d) |
2.2.3 不同训练样本比例设置下的模型性能
面对近红外(NIR)光谱数据收集的实际挑战, 这一过程通常既艰难又昂贵。 本研究旨在评估不同训练样本比例下模型在测试集上的性能, 探讨在样本有限的情况下, 机器学习和深度学习模型在药品光谱数据分类中的表现。 训练集来源于公开的药品光谱数据集, 样本比例从0.2到0.8不等, 比较了InvertResNet、 传统机器学习方法、 经典卷积神经网络(CNN)及Swin-Transformer模型。 通过这种方法, 研究揭示了各模型在数据稀缺环境下的鲁棒性和有效性。 准确率作为主要评估指标, 实验结果详见表7。
| 表7 不同训练样本比例设置下的测试集准确率 Table 7 Test set accuracy with different training sample ratio settings (%) |
实验结果显示, InvertResNet在所有训练样本比例下均优于传统基线模型, 且所有结果均基于测试集。 特别是在训练样本比例为0.6时, InvertResNet在测试集上达到了100%的准确率, 显著超越基线模型。
在样本量极小(62/248)的情况下, PLS-DA、 SVM和RF在测试集上的准确率分别79.39%、 68.44%和67.74%, 而InvertResNet达到95.97%。 即使在较低样本比例下, 经典CNN和Swin-Transformer分别实现了91.94%和92.74%的准确率, 仍略逊于InvertResNet。 GhostNetV2在高样本比例下表现良好, 但在低比例下未达到InvertResNet的水平。
综上, InvertResNet在不同样本比例下展现出卓越的分类能力和鲁棒性, 尤其在高样本比例下实现了完美的准确率, 证明其在数据有限环境中的强大判别能力。
2.2.4 低训练样本比例设置下模型的测试性能
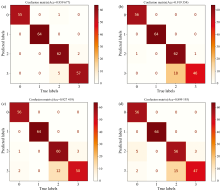
为了评估模型在有限数据下的泛化能力, 采用训练集与测试集2∶ 8的比例, 比较了InvertResNet、 传统机器学习方法、 经典CNN、 Swin-Transformer及GhostNetV2的性能。 结果显示, InvertResNet在所有训练样本比例下均优于其他模型, 尤其在样本比例0.6时达到了100%的测试准确率。 图8的混淆矩阵显示, InvertResNet几乎无误分类, 而其他模型在某些类别上存在明显错误。 综上, InvertResNet在不同训练样本比例下展现出卓越的分类能力和鲁棒性, 证明其在数据有限环境中的强大判别能力。
 | 图8 在低训练样本比例设置下InvertResNet (a)、 CNN (b)、 Swin-Transformer (c)和GhostNetV2 (d)模型测试集的混淆矩阵Fig.8 Confusion matrices for test sets of InvertResNet (a), CNN (b), Swin-Transformer (c) and GhostNetV2 (d) at a low training sample ratio setting |
提出了一种基于深度学习的近红外光谱定性分析方法— — InvertResNet, 该方法通过将一维光谱数据转换为二维伪图像, 并结合双线性插值进行数据扩增, 保留了数据特征并增强了模型对复杂模式和非线性信息的识别能力。 同时, 网络结构优化引入倒残差模块, 提升了特征提取效率和鲁棒性。 首先利用草莓泥近红外光谱数据集对InvertResNet方法进行了初步验证。 实验结果显示, 该方法在草莓泥光谱数据处理中展现出良好的适应性与初步的有效性, 为后续深入研究奠定了坚实基础。 在此之后, 研究重点聚焦于公开的近红外光谱药品分类数据集。 在该数据集上的实验结果表明, InvertResNet的表现优于传统的偏最小二乘判别分析(PLS-DA)、 支持向量机(SVM)、 随机森林(RF)、 卷积神经网络(CNN)以及Swin-Transformer模型和GhostNetV2模型。 该InvertResNet的成功表明提出的伪图像转换、 数据增强和网络结构优化等创新, 有效提升了准确率和鲁棒性, 在近红外光谱领域应用前景广阔。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|