


{kind=link}
{kind=link}
{kind=link}
基于高光谱成像的烟火药快速可视化识别方法
[李云鹏 , 王宏炜, 代雪晶, 武连全, 胡伟成, 张彦春]
, 王宏炜, 代雪晶, 武连全, 胡伟成, 张彦春]
, 王宏炜, 代雪晶, 武连全, 胡伟成, 张彦春]
|
|


作者简介: 李云鹏, 1988年生, 中国刑事警察学院副教授 e-mail: lypciomp@126.com
涉爆现场勘查工作中, 烟火药的快速探测和准确识别对重大突发爆炸案件的防控与快速处置起着至关重要的作用, 而当前对烟火药等爆炸物进行现场快速检测方法大多存在识别速度低、 可视化困难等问题。 鉴于此, 提出一种基于高光谱成像技术结合单类支持向量机(OCSVM)快速发现与识别烟火药的方法。 首先, 使用高光谱相机采集检材400~720 nm波段的高光谱数据, 运用主成分分析(PCA)对数据进行降维, 通过乘性散射校正(MSC)消除样本表面颗粒散射引起的基线偏移, 使用Savitzky-Golay(SG)平滑抑制高频噪声, 提升光谱信噪比。 其次, 为减少模型复杂度提高效率, 通过Kennnard-Stone(K-S)方法从光谱数据中选取代表性的烟火药样本作为数据集, 以4∶1的比例将其划分为训练集和测试集, 在此基础上建立OCSVM模型。 再次, 为验证模型对烟火药的识别能力, 使用相同的训练集建立孤立森林(iForest)、 自编码器(AE)模型, 对比三种模型对烟火药的识别能力。 最后, 将识别结果映射到检材的RGB图像中, 采取掩膜操作标记目标类像素得到识别图像, 实现烟火药的可视化识别效果。 结果表明, OCSVM方法对多种检材识别的总体精度高于0.95、 F1得分和AUC值超过0.8、 识别时间低于2 s, OCSVM在分类准确率、 运行速度、 F1得分和曲线下面积(AUC)等指标上的表现均优于孤立森林模型和自编码器模型。 在可视化识别方面, 经过映射和掩膜操作后得到基于OCSVM模型的识别图像可以较为准确的反映出烟火药在所有检材中的分布情况, 而基于孤立森林和自编码器模型的识别图像未能很好的反映烟火药在黄色纸和黑色涤纶布料上的分布。 研究表明, 本文提出的基于高光谱成像结合OCSVM的烟火药识别方法具有识别准确率高、 反应速度快、 泛化能力强的特点, 能够快速、 准确、 无损地识别检材中的烟火药。 其识别精度、 识别速度以及可视化效果可很好的适用于涉爆现场烟火药的快速发现与临场检测, 为现场勘查中烟火药的搜寻提供一种有效方法。
In the explosive scene investigation, the rapid detection and accurate identification of fireworks and explosives play a vital role in preventing, controlling, and rapidly disposing of major explosions. However, the current rapid detection methods for fireworks and explosives mostly have problems such as low recognition speed and difficulty in visualization. Because of this, this paper proposes a method based on hyperspectral imaging technology combined with one-class support vector machine (OCSVM) for rapid detection and recognition of fireworks. Firstly, the hyperspectral data of the sample in the 400~720 nm band were collected with a hyperspectral camera. Principal component analysis (PCA) was used to reduce the dimension of the data, multiplicative scattering correction (MSc) was used to eliminate the baseline offset caused by particle scattering on the sample surface, and Savitzky-Golay (SG) was used to smooth the high-frequency noise and improve the spectral signal-to-noise ratio. Secondly, to reduce the complexity of the model and improve the efficiency, the representative pyrotechnic samples were selected from the spectral data by Kennard stone (K-S) method as the data set, which was divided into the training set and the test set at the ratio of 4∶1. On this basis, the OCSVM model was established. Thirdly, to verify the recognition ability of the model to the pyrotechnic composition, the isolated forest (iforest) and self-encoder (AE) models were established using the same training set, and the recognition ability of the three models to the pyrotechnic composition was compared. Finally, the recognition result is mapped to the RGB image of the test material, and the recognition image is obtained by marking the target pixels with the operation of the mask to realize the visual recognition effect of the pyrotechnic composition. The results show that the overall accuracy of the OCSVM method is higher than 0.95, the F1 score and AUC value are more than 0.8, and the recognition time is less than 2 seconds. The performance of OCSVM in classification accuracy, running speed, F1 score, and AUC is better than that of the isolated forest and self-encoder models. In terms of visual recognition, the recognition image based on the OCSVM model after mapping and mask operation can more accurately reflect the distribution of smoke and powder in all samples. At the same time, the recognition image based on an isolated forest and a self-encoder model can not well reflect the distribution of smoke and powder on yellow paper and black polyester cloth. The research shows that the pyrotechnic identification method based on hyperspectral imaging combined with OCSVM proposed in this paper has the characteristics of high recognition accuracy, fast response speed, and strong generalization ability, and can quickly, accurately, and nondestructively identify pyrotechnics in the test material. Its recognition accuracy, recognition speed-, and visualization effect can be well applied to the rapid discovery and on-site detection of pyrotechnic and explosive at the explosion scene, and provide an effective method for searching for pyrotechnic and explosive in the scene investigation.
近年来, 涉爆案件在全国各地时有发生, 对人民群众的生命安全和社会稳定造成了极大的影响。 当前, 由于不法分子获取制式炸药难度大, 烟火药等非制式炸药因其获取方便、 成本低廉逐渐成为涉爆案件中最常见的炸药之一[1]。 因此, 快速发现并识别现场中的烟火药对涉爆现场勘查工作具有重要意义。 由于犯罪现场遗留的烟火药多为微量状态, 致使部分具有破坏性的检验方法在实际应用中受限, 而以光学检验方法为代表的无损检验方法更能适应实际环境。 当前, 烟火药的光学检验方法主要包括激光诱导击穿光谱[2]、 拉曼光谱[3]、 红外光谱[4]等。 激光诱导击穿光谱能够实现对烟火药的非破坏性识别, 红外、 拉曼光谱能够实现对烟火药高精度准确识别分类, 但这些方法不能实现识别结果的可视化, 使其难以应用于现场烟火药的发现与识别工作。 因此, 实现现场烟火药的快速可视化识别是当前法庭科学领域的研究热点。
与传统的光学检验方法相比, 高光谱成像技术因其具有光谱特征丰富、 非接触、 图谱合一等特点, 不仅能够实现对检材的无损检验, 而且拥有识别结果直观、 可视化[5]便捷的优点。 为此, 国内外学者就高光谱成像对爆炸物的可视化识别进行了研究, 展现了高光谱技术对爆炸物的识别能力。 Carvalho等[6]使用近红外高光谱成像结合交替最小二乘法实现了射击残留物的可视化识别, 其识别精度达到了72.2%。 Ortega-Ojeda等[7]利用CLS算法完成了目标物上射击残留物的可视化识别, 该方法对推进剂火药的识别精度达到96.6%, 但其对(512× 318× 238)大小的光谱数据预测时间超过十分钟。 Glomb等[8]使用了传统的RX算法和SVM算法实现了对射击残留物的检测。 El-Sharkawy等[9]通过高光谱相机收集每种测试爆炸材料的入射与反射光谱, 通过对反射光谱图像进行归一化并进行减法来实现对隐蔽爆炸物在对持距离上的识别。 Gasser等[10]使用高光谱拉曼成像结合随机决策森林分类算法在距离目标物15 m的位置实现了对人造铝基板上的痕量炸药的正确识别分类。 Kendziora等[11]利用主动红外反向散射高光谱成像结合卷积神经网络对痕量爆炸物进行了识别分类。 上述研究一方面主要着眼于射击残留物和制式爆炸物的可视化识别, 而对烟火药这类非制式爆炸物关注度不足。 另一方面, 上述研究侧重于对爆炸物的识别准确性而忽视算法识别速度在现场可视化识别中的重要性, 较低的识别速度限制了这些方法在现场勘查中的广泛应用。
针对当前研究对非制式爆炸物关注度不足和算法识别速度低的问题, 为实现现场勘查中对烟火药的快速可视化识别, 本工作使用K-S方法选取特征样本参与训练以降低算法复杂度; 使用PCA对待预测数据集进行降维以减少运算数据量; 使用OCSVM作为分类算法以实现小样本下烟火药的准确识别并进一步加快运行速度, 并与孤立森林、 自编码器算法进行对比; 最后通过将识别结果映射到原RGB图像上实现识别结果的快速可视化。 该方法在识别准确率和预测时间上做到了较好的平衡, 识别精度与速度均高于孤立森林、 自编码器, 同时具有较好的泛化能力, 能够较好地适应现场复杂多变的环境, 能够在一定程度上提高现场勘查工作中烟火药的搜索效率。
在涉爆现场, 烟火药的分布状态具有多样性。 为模拟现场环境的复杂性, 选取了三种承痕客体用于制作检材: 涤纶制黑色布料、 棉制黑色布料、 黄色纸。 用手指蘸取铁粉、 烟火药、 粉笔粉末后分别捺印在同种介质上的左上、 右上、 左下区域得到实验检材, 将区域标记为①、 ②、 ③。 三种检材如图1所示。
 | 图1 不同承痕客体上烟火药及其相似物 (a): 涤纶制黑色布料; (b): 棉制黑色布料; (c): 黄色纸Fig.1 Pyrotechnic compositions and its analogues on different bearing objects (a): Polyester black cloth; (b): Cotton black cloth; (c): Yellow paper |
为贴近非制式炸药的火药成分, 本工作使用的烟火药提取自白药类鞭炮, 属于爆响类烟火药, 主要成分为高氯酸钾、 铝粉、 镁铝合金粉和硫磺, 外光呈银白色颗粒状。 粉笔粉末提取自思进牌粉笔, 外观呈灰白色颗粒状。 铁粉为苏州远特新材料科技有限公司生产, 其平均粒径为1 μ m, 颗粒形貌为片形, 颜色呈黑色。
使用的高光谱相机型号为美国Cambridge Research & Instrumentation Inc(CRI)公司的Nuance Multispectral Imaging System。 该设备的液晶可调波长滤光镜(LCTF)波段范围为400~720 nm, 光谱分辨率为1 nm。 配备有科学级CCD数字相机, 具体参数为: 144万像素, 像元大小: 6.45 μ m。 使用的编程软件为python3.11, 模型的训练和测试以及对检材的识别使用CPU完成, 设备处理器为AMD Ryzen 5 5600H with Radeon Graphics主频3.30 GHz, 内存为16.0 GB。
使用高光谱相机以5 nm的采样间隔采集检材和纯烟火药样本在400~720 nm波段范围的光谱图像(1 392× 1 040), 每个检材和样本采集59张光谱图像。 为去除仪器噪声的干扰, 采集了相同环境光照下标准白板的数据和全黑标定数据, 以实现对数据进行黑白校正。 其校正公式为
式(1)中: R为校正后的数据; R0为原始数据; Rb为全黑标定数据; RW为全白标定数据。
由于现场烟火药附着的客体具有多样性, 为提高算法的泛化能力, 同时减少运算量, 采用单分类模型, 因此模型的训练集中只包含作为正样本的纯烟火药样本数据, 而不包含负样本。 具体预处理流程如下:
首先, 对采集的纯烟火药样本高光谱图像, 选取一个200× 200的矩形区域为感兴趣区域, 进行下一步处理。
其次, 由于烟火药颗粒大小、 分布不均匀, 对感兴趣数据采用SG平滑结合MSC以减少散射和噪声的影响。 SG卷积平滑是信号平滑算法中的一种, 通过局域多项式在移动窗口中对数据进行最小二乘拟合, 能在不改变光谱曲线原始形态的基础上将光谱曲线中的随机误差噪声滤除, 提高信噪比[12]; 多元散射校正是一种用于消除高光谱数据中散射效应的预处理方法。 它通过校正光谱数据中的加性和乘性散射效应, 使光谱数据更接近样品的真实化学信息。 MSC假设光谱的散射效应可以通过线性模型来描述, 并通过拟合参考光谱来校正每个样品的光谱[13]。
再次, 为减少训练样本、 降低算法复杂度, 使用K-S方法选取100个特征样本, 在此基础上使用PCA降维。 由于样本数据集的前5个主成分能够解释95%的总方差, 因此选择数据集的前5个主成分作为训练集的输入主成分。 K-S方法[14]是一种用于样本划分的算法, 通常用于将数据集划分为训练集和测试集。 其目标是通过选择具有代表性的样本, 使训练集和测试集在特征空间中均匀分布, 从而保证模型的泛化能力。 PCA[15]是一种常用的数据降维方法, 通过线性变换将高维数据投影到低维空间, 同时保留数据中的主要变异信息。 PCA通过找到数据中方差最大的方向, 将原始特征转换为新的正交特征, 从而实现降维。
为实现对烟火药的快速识别, 使用单分类算法建立烟火药识别模型。 常见的单分类算法主要有单类支持向量机、 孤立森林、 自编码器算法。 因此, 对比了基于这三种算法所建立的烟火药识别模型对检材的识别效果。
1.4.1 OCSVM模型设计
OCSVM[16]属于支持向量机的一种变体。 与传统的SVM用于分类或回归不同, OCSVM主要用于异常检测或无监督学习中的新奇点检测。 它试图从单类数据中学习该类的边界, 以识别出不属于这一类的新样本。 OCSVM的出发点是在变换后的特征空间中寻找到最优分离超平面, 使得正类样本和原点之间具有最大间隔。 OCSVM通过引入分离超平面和最大间隔的思想, 在变换后的特征空间中尽可能地使正类落于分离超平面的一侧, 而使原点与其他类别落于另一侧。
在构建OCSVM模型中, 将经过预处理后的纯烟火药高光谱数据集以4∶ 1的比例随机划分为训练集和测试集。 OCSVM中核函数的选择对算法性能影响显著, 为在高效率和高精准度之间找到平衡, 选择将径向基函数“ rbf” 作为核函数。 为达到最好的算法训练效果, 使用遗传算法来选择参数“ gamma” 和“ nu” 。 实验中遗传算法主要参数: 变异概率1%, 迭代次数20次, 种群个体数为50。
1.4.2 孤立森林模型设计
孤立森林[17]是一种基于随机树的异常检测算法, 它被广泛应用于识别数据集中的异常点。 其原理为异常值是少量且不同的观测值, 因此更易于识别。 孤立森林集成了孤立树, 在给定的数据点中隔离异常值孤立森林通过随机选择特征, 然后随机选择特征的分割值, 递归地生成数据集的分区。 和数据集中正常的点相比, 要隔离的异常值所需的随机分区更少, 因此异常值是树中路径更短的点, 路径长度是从根节点经过的边数。 在构建孤立森林模型中, 将经过预处理后的纯烟火药高光谱数据集以4∶ 1的比例随机划分为训练集和测试集。 并使用相同参数的遗传算法对孤立森林模型参数进行优化。
1.4.3 自编码器模型设计
自编码器[18]是一种特殊的人工神经网络, 它的目标是学习将输入数据重构为输出数据的方式。 自编码器的两个主要组成部分是编码器和解码器。 编码器将输入数据压缩成一个潜在的表示, 解码器从这个潜在表示重建出原始输入[19]。 编码器的核心在于学习一种数据的潜在表示, 在通常情况下这个潜在表示的维度要低于原始数据, 因此也被称为瓶颈层。 编码器将原始高维数据压缩成低维的潜在表示, 解码器则试图从这个潜在表示重建出原始输入。
本文使用三层自编码器, 包括输入层、 编码器和解码器。 该算法使用了ReLU作为编码器的激活函数, 解码器的最后一层使用Sigmoid激活函数, 以确保输出值在[0, 1]范围内, 与标准化后的输入数据一致。 算法通过Adam优化器进行训练, 学习率为0.001, 使用均方误差(MSE)作为损失函数。
使用总体精度(OA)、 F1分数、 AUC、 运行时间作为算法的评价标准。 总体精度是指分类正确的样本数占总样本数的比例。 它衡量的是算法在整个数据集上的正确分类能力。 其计算方式如式(2)所示
式(2)中, TPi为第i个类别的真正例; k为类别总数; N为总样本数。
F1分数同时兼顾了分类模型的准确率和召回率。 F1分数可以看作是模型准确率和召回率的一种加权平均, 它的最大值是1, 最小值是0, 值越大意味着模型越好。 其计算方式如式(3)所示
式(3)中, Precision为精确率, 即模型预测为正类的样本中, 实际为正类的比例。 Recall为召回率表示实际为正类的样本中, 模型预测为正类的比例其中精确率和召回率的计算公式如式(4)和式(5)所示。
式(4)和式(5)中: TP为真正例, 即模型正确预测为正类的样本数。 FP为假正例, 即模型错误预测为正类的样本数。 FN为假负例, 即模型错误预测为负类的样本数。
ROC曲线通过绘制真正类率(TPR)与假正类率(FPR)之间的关系来展示算法的分类能力。 AUC是接受者操作特性曲线(ROC)下方的面积表示算法区分正类和负类的能力。 AUC越大, 算法的分类性能越好。 尽管本工作使用的是单分类算法, 但通过对检材数据集添加目标标签和非目标标签的方式, 从而可以应用ROC曲线和AUC评价算法对烟火药识别的效果。
分别对烟火药在涤纶制布料、 棉制布料、 黄色纸三种承痕客体上的原始光谱曲线图进行了对比。 如图2所示, 涤纶制布料上的烟火药的光谱曲线与纯烟火药的光谱曲线尽管在总体走势上具有一定的相似性, 但其在550~690 nm上的差异较大。
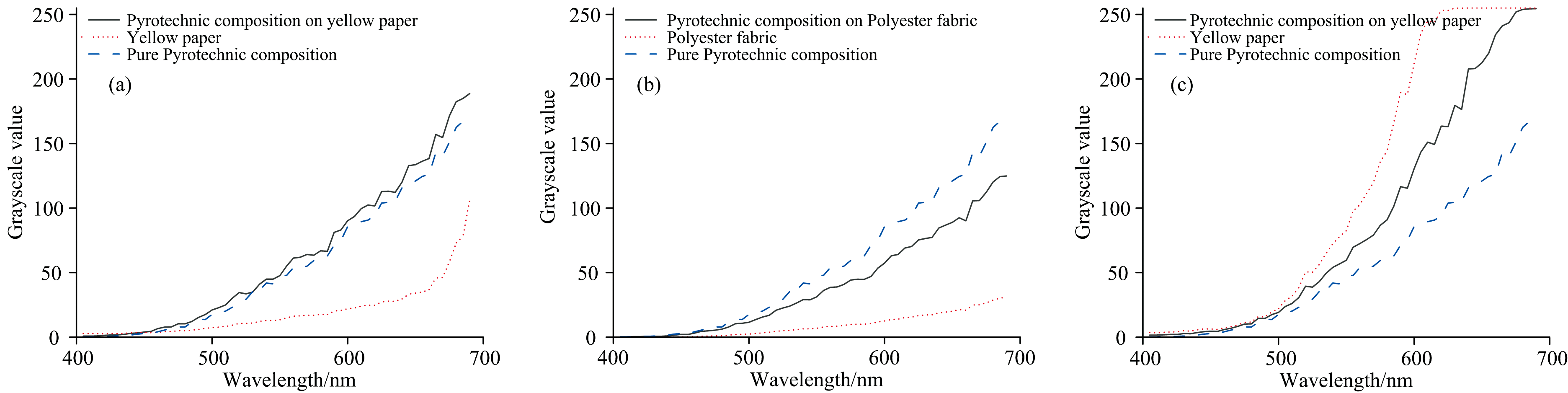 | 图2 烟火药在三种承痕客体上的原始光谱曲线图 (a): 涤纶制布料; (b): 棉制布料; (c): 黄色纸Fig.2 Original Spectral curves of pyrotechnic compositions on three types of trace bodies (a): Polyester black fabric; (b): Cotton black fabric; (c): Yellow paper |
如图2(a)所示, 黑色涤沦制布料上烟火药和纯烟火药的光谱曲线高度相似, 不仅形状一致而且在走势上具有较高的相似性。 如图2(b)所示, 尽管棉制布料上烟火药与纯烟火药的光谱曲线整体趋势相似, 但在550 nm以后, 反射光强度具有一定差异, 同时与承痕客体的光谱曲线保持了较大的差异。 如图2(c)所示, 黄色纸上烟火药的光谱曲线在550~690 nm 波段下与纯烟火药光谱曲线的差异性较大。 这是由于黄色纸在550~690 nm波段的光反射强烈, 影响了设备对烟火药数据的采集, 而其他两种承痕客体对光反射较弱, 对烟火药的采集影响较小。 上述内容表明, 不同的承痕客体对痕量物质的光谱曲线的影响不同。 因此, 在建立物证识别模型时需要重视模型的泛化能力, 避免过拟合对识别结果产生影响。
为测试三种算法训练的模型对实际检材的识别能力, 分别使用三种算法建立识别模型对三种检材进行识别。 表1为三种算法在识别不同检材时的总体精度、 F1分数、 AUC值和运行时间对比。 由表1可知, OCSVM对三种检材的总体精度均超过0.95, F1分数和AUC值均高于0.8, 具有较好的识别能力和泛化能力。 同时该方法的运行时间小于2 s, 能够在较短的时间完成识别任务。 孤立森林算法对涤纶制布料和棉制布料上烟火药识别效果较好, 总体精度高于0.9, F1分数和AUC值也相对较高, 而对黄色纸上烟火药的识别能力差, 总体精度只有0.429, F1分数和AUC值也相对较低, 该算法的运行时间为5~6 s。 自编码器算法对涤纶制布料和棉制布料上烟火药识别效果较好, 总体精度高于0.9, F1分数和AUC值也相对较高, 而对黄色纸上烟火药识别效果识别能力差, 总体精度只有0.267, F1分数和AUC值也相对较低, 该算法的运行时间高于60 s。
| 表1 三种算法对不同检材的识别精确率 Table 1 The recognition accuracies of three algorithms for different specimens |
对表1中三种算法各项评价指标分析可知, OCSVM算法各项模型的评价指标均高于孤立森林和自编码器算法。 自编码器算法作为一种常用的异常检测算法, 其识别模型的总体精度、 F1分数、 AUC高于孤立森林识别模型, 但其运行时长远高于孤立森林, 这是由于自编码器算法在建立模型时使用了迭代的方法, 增加了模型的复杂度, 降低了模型的识别速度。 而孤立森林采用分割的方法, 使其对非线性数据处理能力不足。 相较于其他两种算法, OCSVM直接从数据中学习决策边界, 降低了模型复杂度, 加快了模型的识别速度, 使用核函数捕捉复杂的模式, 使其可以有效地处理非线性的数据。 因此, 该算法相较于其他两种算法具有较好的识别准确率和较快的运行速度。 同时, 尽管OCSVM模型在识别黄色纸上烟火药时也出现了识别准确率降低的问题, 但相较其他算法其准确率下降的幅度较小, 这表明了该模型具有更好的泛化能力。 综上所述, OCSVM总体精度高于0.95具有最好的识别能力和识别时间低于2 s的最快运行速度, 基于OCSVM建立的模型的泛化能力也最强, 更能满足现场勘查工作的需求。
为获取直观的识别效果, 实现结果的可视化。 本文首先将模型输出的预测标签重塑为与原始高光谱图像相同的二维空间尺寸, 使每个像素点的预测标签与原始图像位置相对应。 然后基于预测标签创建二元掩膜矩阵, 将目标类像素标记为1, 非目标类像素标记为0。 最后将掩膜叠加到原始RGB图像上, 通过颜色映射使用红色高亮显示目标类区域, 并同时保持背景图像的可见性, 得到识别结果如图3所示。
 | 图3 三种算法的识别图像 (a), (b), (c): 自编码器对涤纶制布料、 棉制布料、 黄色纸上烟火药识别结果; (d), (e), (f): 孤立森林对涤纶制布料、 面制布料、 黄色纸上烟火药识别结果; (g), (h), (i): OCSVM对涤纶制布料、 面制布料、 黄色纸上烟火药识别结果Fig.3 Recognition images of three algorithms (a), (b), (c): Recognition results of AE for pyrotechnic compositions on polyester fabric, cotton fabric and yellow paper; (d), (e), (f): Identification results of pyrotechnic compositions on polyester fabric, cotton fabric and yellow paper using IF; (g), (h), (i): Recognition results of OCSVM for pyrotechnic compositions on polyester fabric, cotton fabric and yellow paper |
由图3可知, 对于涤纶制布料检材, 三种算法都能够实现对烟火药区域的正确识别。 对棉制布料上烟火药, OCSVM在正确识别烟火药区域的同时排除了烟火药相似物的干扰, 而其他两种算法尽管正确识别了烟火药区域但未能排除干扰。 对于黄色纸上烟火药, 只有OCSVM能够实现对烟火药区域的正确识别, 而其他两种算法都出现了大量的误识别, 无法完成寻找烟火药的任务。
通过PCA降维, K-S方法和单分类识别算法进行识别模型设计降低识别模型复杂度, 提出了一种基于OCSVM的高光谱烟火药的快速可视化识别方法。 该方法在识别准确率和预测时间上做到了较好的平衡, 不但能够实现在2 s内完成对检材的识别, 抑制烟火药相似物和承痕体的干扰, 并且对不同检材的识别准确率高于0.95, 能够快速、 便捷、 准确地识别出不同承痕客体上的烟火药。 而且, OCSVM算法与孤立森林和自编码器算法相比, 分类准确率、 运行速度、 F1得分和曲线下面积(AUC)等指标上的均表现更优。 相较于现有检验烟火药的方法, 该方法具有可视化便捷、 反应速度快、 泛化能力强的优点, 可以完成较复杂环境下烟火药的识别任务, 有效提高现场烟火药勘查工作的效率, 有着广阔的应用前景。 此外, 由于本工作使用可见光400~720 nm波段的光谱数据建立识别模型, 降低了对紫外或红外等特殊成像设备的需求。 后续工作中, 拟使用滤光片结合常规相机得到特征波段对应图像, 配合本文提出的算法建立模型, 实现以低成本硬件设备完成对烟火药的快速识别, 将更易于在一线实战单位广泛推广。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|