


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱数据和Stacking集成学习算法的金矿品位快速反演
[毛亚纯 , 夏安妮
, 夏安妮* , 曹旺, 刘晶, 文杰, 贺黎明, 陈煊赫]
, 夏安妮, 曹旺, 刘晶, 文杰, 贺黎明, 陈煊赫]
|
|


作者简介: 毛亚纯, 1966年生,东北大学资源与土木工程学院教授 e-mail: Maoyachun@Mail.neu.edu.cn
金矿资源具有重要的经济和金融价值, 不仅为国家提供了贵重的金属资源, 推动经济增长, 还在增强货币稳定性和国际金融市场中的避险能力方面具有现实意义。 然而, 当前矿山用于金矿品位测量的化学分析法尽管精确, 但存在耗时长、 成本高以及药剂污染等多种问题, 无法实现基于实时品位信息的矿石品位与选矿方法的自动化调整。 相比之下, 可见光-近红外光谱分析法因其高效、 绿色环保及原位测定等优势, 逐渐成为估算矿区金属品位的有效替代方法。 为此以中国辽宁省二道沟、 凌源和排山楼三个金矿为研究区, 共采集了389个金矿样本, 以SVC便携式地物光谱仪测试的高光谱数据和化学分析数据为数据源。 首先对原始光谱数据进行Savitzky-Golay平滑(SG)处理, 并分析金矿的光谱特征, 发现反射率与金品位具有一定相关性, 且在455 nm处具有金的吸收特征, 基于此, 利用主成分分析法(PCA)、 等距特征映射(ISOMAP)和局部线性嵌入(LLE)算法对原始光谱数据进行降维处理, 对应降维结果的维数分别为6, 5, 5。 最后基于随机森林(RF)、 极端随机树(ET)、 决策树(DT)、 梯度提升树(GBDT)和自适应增强(Adaboost)、 极端梯度提升树(XGBoost)和Stacking集成学习算法对降维后的数据建立了金品位预测模型。 研究结果表明, Stacking集成学习方法在各方面性能均优于单一模型, 其中LLE-Stacking组合模型的精度最高, 预测值与真实值的 R2为0.972, RPD为5.935, 平均相对误差为0.231。 利用本方法可以快速准确预测矿粉中金的品位, 相比于传统模型的品位反演精度有明显的提升, 为矿山金品位的快速、 原位测定提供了新的技术手段, 对金矿的高效开采具有重要意义。
The gold mining resource holds significant economic and financial value, providing precious metal resources for the country, driving economic growth, and enhancing currency stability and hedging capabilities in the international financial market. However, while precise, the current chemical analysis methods for measuring gold ore grades in mines face issues such as long processing times, high costs, and reagent pollution, hindering the automation of ore grade and beneficiation method adjustments based on real-time grade information. In contrast, due to its efficiency, eco-friendliness, and in-situ measurement advantages, visible-near infrared spectroscopy is gradually becoming an effective alternative for estimating metal grades in mining areas. First, the raw spectral data were processed using Savitzky-Golay (SG) smoothing to reduce noise, and the spectral characteristics of gold ores were analyzed. It was found that reflectance correlates with gold grade, and a gold absorption feature is present at 455 nm. Based on this finding, dimensionality reduction was performed on the raw spectral data using principal component analysis (PCA), isometric feature mapping (ISOMAP), and locally linear embedding (LLE), with the resulting dimensions reduced to 6, 5, and 5, respectively. Finally, prediction models for gold grade were established using random forest (RF), extremely randomized trees (ET), decision trees (DT), gradient boosting decision tree (GBDT), adaptive boosting (Adaboost), extreme gradient boosting (XGBoost), and stacking ensemble learning algorithms on the dimensionally reduced data.Results indicated that the Stacking ensemble learning method outperformed single models in all aspects. Among them, the LLE-Stacking combined model achieved the highest accuracy, with R2 of 0.972, RPD of 5.935, and an average relative error of 0.231 between predicted and actual values. The method proposed in this study allows for rapid and accurate predictions of gold content in ore, significantly improving the inversion accuracy compared to traditional models, providing new technological means for the rapid and in-situ measurement of gold grades in mines, and holding great significance for efficient gold extraction.
众所周知, 金矿因其战略重要性而备受瞩目。 现今, 国际金矿局势展现出产量稳步增长、 需求强劲且价格波动呈明显的态势[1]。 然而, 金矿的矿脉普遍狭窄且结构较为复杂, 导致矿岩界限难以快速准确识别。 传统的化学分析方法[2]在测定金矿品位时存在周期长、 效率低以及药剂污染等问题, 虽然测量的精度以及准确性很高, 但无法实现基于实时品位信息的矿石品位与选矿方法的自动化调整。 这不仅影响了金矿开采的效率和经济效益, 还增加了运输和选矿成本, 因而实现金矿品位的高效实时测定成为了当前亟待解决的关键问题。 与传统方法相比, 高光谱分析技术凭借其采样灵活、 快速无损、 检定周期短和操作简便等优势, 已成为估算矿区金属品位的有效手段之一[3, 4], 进而可以精细化矿脉的分布来实现矿石资源的高效利用。
随着高光谱定量反演技术的持续进步与成熟, 目前已被广泛应用于土壤有机质及重金属含量和矿区金属品位的高精度反演。 该技术通过获取样品的连续光谱信息实现定量分析, 但在实际应用中, 由于相邻波段间的高度相关性, 常导致数据的冗余度过高, 不仅增加了光谱解译的难度和复杂性, 还影响了反演建模的精确度。 鉴于此, 对可见光-近红外光谱数据进行预处理显得尤为重要, Li[5]等利用主成分分析法(principal component analysis, PCA)对采集的矽卡岩型铁矿石高光谱数据进行降维预处理, 而后利用随机森林和人工神经网络两种反演模型建立了矿样铁含量的反演模型, 结果表明经过降维后的反演精度明显优于未处理的数据, 其R2可达到0.99, 可以满足实时铁矿石品位测定的精度要求。 Wang[6]等将CARS和SPA两种特征提取方法组合应用于米拉多铜矿高光谱数据的预处理, 而后利用随机森林、 支持向量机和Stacking集成学习等多种模型建立了铜品位反演模型, 其R2可达到0.936, 有效减少了数据的冗余, 同时也证明了Stacking集成学习模型在在矿石品位反演方面的有效性。 这些方法不仅降低了高光谱数据的冗余, 显著解决了“ 维度灾难” 问题, 同时还有效增强了与重金属相关的弱光谱信息, 均不同程度的提高了建模精度。
现今, 机器学习已被广泛应用于矿区及土壤中稀有元素的品位反演。 举例来说, Xu[7]等提出的基于改进的麻雀搜索算法和批量归一化优化的可变神经元节点双隐层极限学习机, 已成功实现对鞍山式铁矿品位的准确预测, 其R2高达0.962, 且RMSE仅为1.358。 此外, Cui[8]等通过结合不同阶数的FOD光谱并采用偏最小二乘法, 成功构建了一个用于快速预测土壤中铜含量的定量反演模型, 进一步证实了高光谱技术在估算样品重金属浓度方面的可行性。 然而, 考虑到矿样中金品位较低且金属品位与光谱特征之间存在复杂的隐式函数映射关系, 传统的数学模型无法准确表征两者复杂的函数, 而单一的机器学习模型虽能建立复杂的线性或非线性函数, 但也可能存在过拟合、 泛化能力不足和鲁棒性低等问题。 为了克服这一难题, 引入了集成学习模型。 集成学习[9]通过构建和组合多个独立的模型来协同完成任务, 从而获得明显优于单个学习器的泛化性能。 经典的集成学习算法包括Bagging、 Boosting和Stacking等, 其中, Stacking是一种先进的集成学习技术, 旨在通过融合多个学习器的预测结果来显著提升整体的预测性能。 其核心思想在于构建一个双层结构, 第一层包含多个互不干扰且独立的预测模型, 第二层为元学习器, 实现多个模型预测结果的融合和优化, 从而形成一个更为准确和全面的预测。
目前, 集成学习算法已被广泛应用于土壤污染评估、 农业监测和化工分析等领域, 例如Tan[10]等利用CARS方法进行特征提取, 并结合集成学习技术对预测研究区内的砷、 铬、 铅和锌等多种重金属进行了反演建模。 结果显示, 相较于单一模型, 集成学习在各项精度指标上均有显著的提升, 其中R2值可提升0.2~0.4。 Lin[11]等则基于Stacked-AdaBoost集成学习技术, 对高光谱图像中的土壤铬、 铜和砷等重金属品位反演进行了深入的分析和建模, 有效提升了模型的预测能力, 为农业生态保护和工业污染控制提供了详细可靠的数据。 由此可见, Stacking不仅结合了各个模型的优点, 还有效地弥补了单一模型可能存在的局限性和不足, 有效提高了模型的泛化能力。 整个流程的设计确保了每个模型都能充分发挥其独特的优势, 并通过协同作用实现预测性能的最大化。
本工作以辽宁省内二道沟、 凌源和排山楼金矿三个研究区的389个金矿样品的可见光-近红外光谱数据为数据源, 首先利用SG平滑进行了光谱去噪, 然后利用PCA、 等距特征映射(isometric feature mapping, ISOMAP)和局部线性嵌入(locally linear embedding, LLE)三种降维算法对去噪后的数据进行降维, 最后基于Stacking集成学习建立研究区金矿品位的定量反演模型, 并进行精度评价。 研究结果表明, 基于LLE-Stacking组合算法建立的金矿品位反演模型具有良好的预测能力, 可以很好的满足金矿快速品位原位测定和精度需求, 该研究可为金矿品位测定提供有效的技术手段。
本实验选用中国辽宁省朝阳市凌源、 二道沟和阜新市排山楼三个研究区的金矿, 其类型主要为石英脉型和蚀变岩型。 其中, 凌源金矿的中心地理坐标为东经119° 3'57″, 北纬40° 42'34″, 金矿体类型主要为石英脉型和蚀变岩型, 其平均品位为5.45 g· t-1。 二道沟金矿的中心地理坐标为东经120° 20'30″, 北纬41° 57'02″, 该矿区的年产黄金可达370 kg以上。 排山楼金矿的中心地理坐标为东经121° 45'15″, 北纬41° 52'25″, 该矿区平均品位为4.5 g· t-1, 储量为32 000 kg。 本文研究区域的位置如图1所示。
 | 图1 三个研究区域位置分布概况图 (a): 二道沟; (b): 凌源; (c): 排山楼Fig.1 Location distribution maps of the three study areas (a): Erdaogou; (b): Lingyuan; (c): Paishanlou |
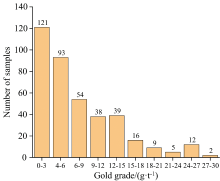
为了保障金矿样品品位分布的均匀性, 以分层抽样的方法在研究区域的不同位置采集了389个金矿样品, 样品的品位分布情况如表1所示, 样品品位的最大值为27.88 g· t-1, 最小值为0.10 g· t-1, 平均品位为7.20 g· t-1, 其中, 排山楼金矿的平均品位最高为9.10 g· t-1, 凌源金矿的平均品位最低为3.12 g· t-1, 品位具体的分布如图2所示。
| 表1 中国辽宁省内二道沟、 凌源和排山楼金矿三个研究区样品品位分布情况 Table 1 Grade distribution of samples from the three study areas of Erdaogou, Lingyuan and Paishanlou gold mines in Liaoning Province, China |
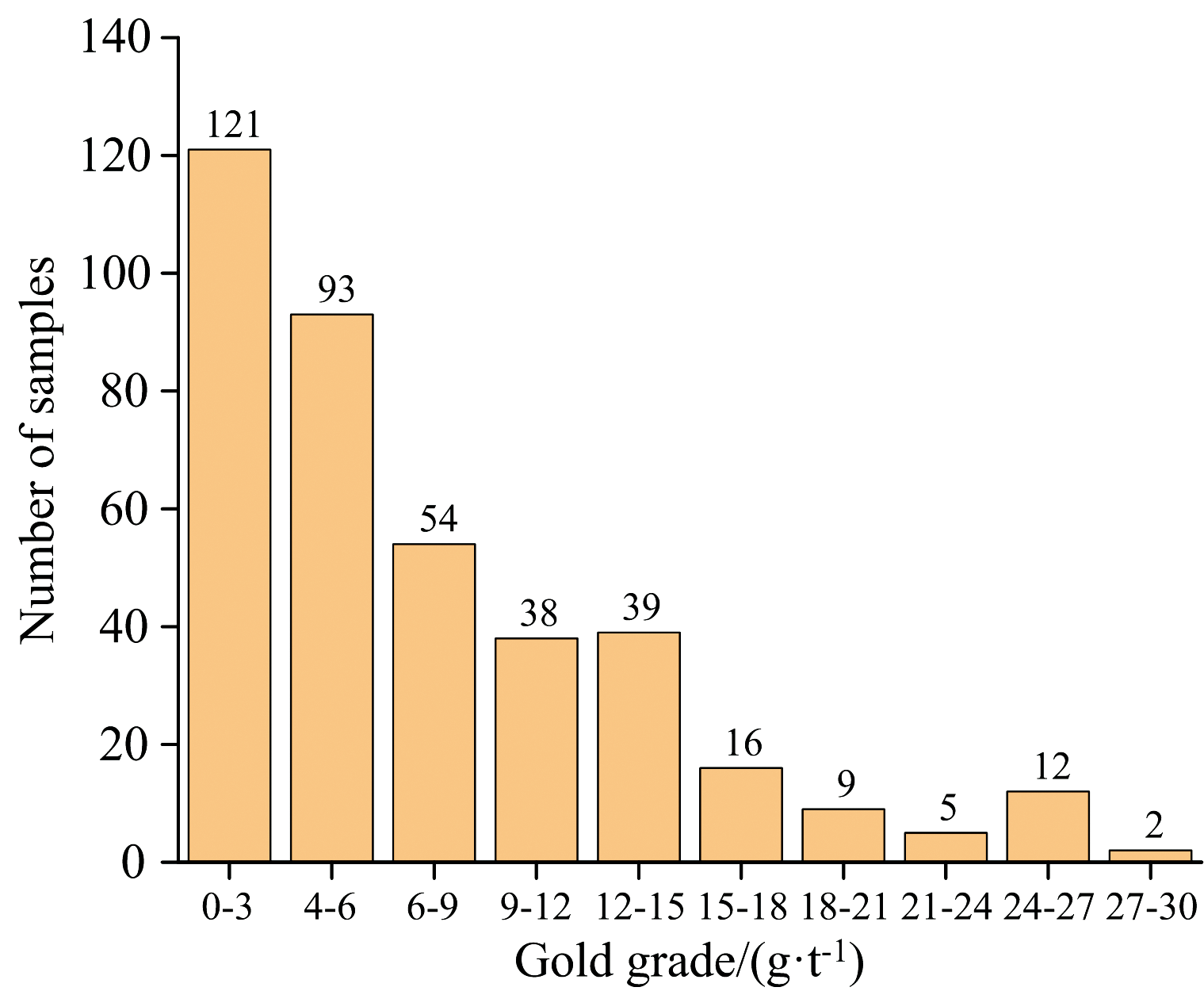 | 图2 金矿品位的具体分布图Fig.2 Specific distribution map of gold grades |
对采集的389个金矿样品进行杂物去除、 风干和过筛, 如图3(a)所示, 并分为两份装入带标签的塑料盒中等待使用, 其中一份样品利用化学分析法进行矿粉中金品位的测定, 另一份样品用于进行可见光-近红外光谱的测定, 样品的情况如图3(b)所示。 之后使用美国SVC HR-1024光谱仪对金矿样品进行光谱实验, 实验所用仪器如图3(c)所示, 其波段范围为350~2 500 nm, 共包含973个波段。 考虑到采样环境位于井下, 因此特别选择在封闭黑暗的实验室环境中进行测量, 以模拟井下条件来确保数据的准确性。 在测量的过程中, 严格控制光谱仪镜头垂直于样品表面以及样品观测面的水平。 为了保障仪器的稳定运行, 对光谱仪进行充分的预热, 并以卤素灯作为稳定光源, 在保持观测角度和距离不变的情况下进行测量。 并每隔10~15 min进行一次白板校正, 以及时消除或修正因光源变化可能引入的误差。 对每个金矿样品进行两次测量避免偶然误差, 并计算两组光谱数据的平均值作为样品的原始光谱曲线, 为后续深入分析奠定基础。
 | 图3 实验准备 (a): 过筛; (b): 装盒金矿样品展示; (c): 实验仪器Fig.3 Experimental preparation (a): Sieving; (b): Display of boxed gold ore samples; (c): Experimental apparatus |
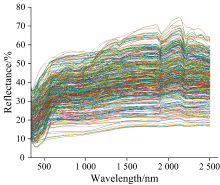
由于环境、 仪器的和人为因素存在噪声, 因此在深入数据分析与建模之前要进行预处理, 以此有效去除测量光谱中的噪声和异常数据, 减少对光谱分析的潜在影响。 经过多种预处理方法的对比研究表明[12], SG平滑可以有效去除信号中的噪声和杂散信号, 同时保留信号的峰形信息等主要特征, 且该方法计算速度快、 适应性强。 因此, 经过SG平滑处理后的数据在分析和解释上更具便捷性和准确性。 经过SG平滑后的光谱曲线如图4所示。
 | 图4 SG平滑后的光谱曲线图Fig.4 Spectral curves after SG smoothing |
测试的金矿样本的可见光-近红外光谱具有如下特征:
(1)测试样本的光谱反射率主要位于10%~70%间;
(2)在350~455 nm波段光谱曲线呈下降趋势, 在455~700 nm区间光谱曲线先呈现快速上升趋势, 于455 nm处出现细小波谷, 为金的敏感波段[13];
(3)经过统计发现在700~1 400 nm间光谱曲线出现差异呈现出两类变化趋势, 矿石品位小于3 g· t-1时, 变化较为平缓, 矿石品位大于3 g· t-1时, 呈现出较为快速的上升趋势, 在1 400 nm后两种变化趋势呈现一致性;
(4)在1 400~2 150 nm间光谱曲线呈现上升趋势, 测试样本在1 400和1 900 nm处呈现波谷特征, 并且此处的光谱曲线存在波动, 经分析后认为这种现象与采集的样品中含水有关[14]。
(5)2 150~2 500 nm波段间光亲曲线呈下降趋势, 于2 200 nm处出现较大的波谷, 是氢氧根离子的吸收特征。
可见光-近红外光谱中包含973个波段信息, 虽然光谱信息极其丰富, 但由于相邻波段间的高度相关性, 常导致数据冗余度过高, 利用全波段进行建模不仅增加了光谱解译的难度和复杂性, 还增加了建模时间和计算成本, 进而影响了反演建模的速度和精确度。 因此, 有必要进行数据降维以降低数据冗余, 削弱“ 维数灾难” 的影响, 并增强微弱的光谱信息。 为此, 本文采用PCA、 ISOMAP、 LLE三种降维算法对去噪后的光谱数据进行处理, 当累计贡献率达到99.5%以上即认为降维后的数据可用于定量反演建模。
2.1.1 主成分分析
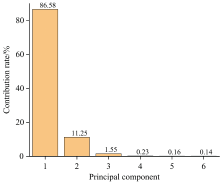
主成分分析算法(PCA)[5]是一种线性降维算法, 其核心原理是针对原始数据特征维数过高且冗余的问题, 基于线性变换提取主要特征, 即用提取后尽可能少的信息来代替原有的信息。 在转换过程中, PCA会保留数据集中对方差贡献最大的特征, 而忽略那些贡献较小的特征, 从而实现了数据的降维。 经处理后, 将原始数据从973维降至6维, 各维主成分所占贡献率如图5所示, 处理所用时间为1.719 s。
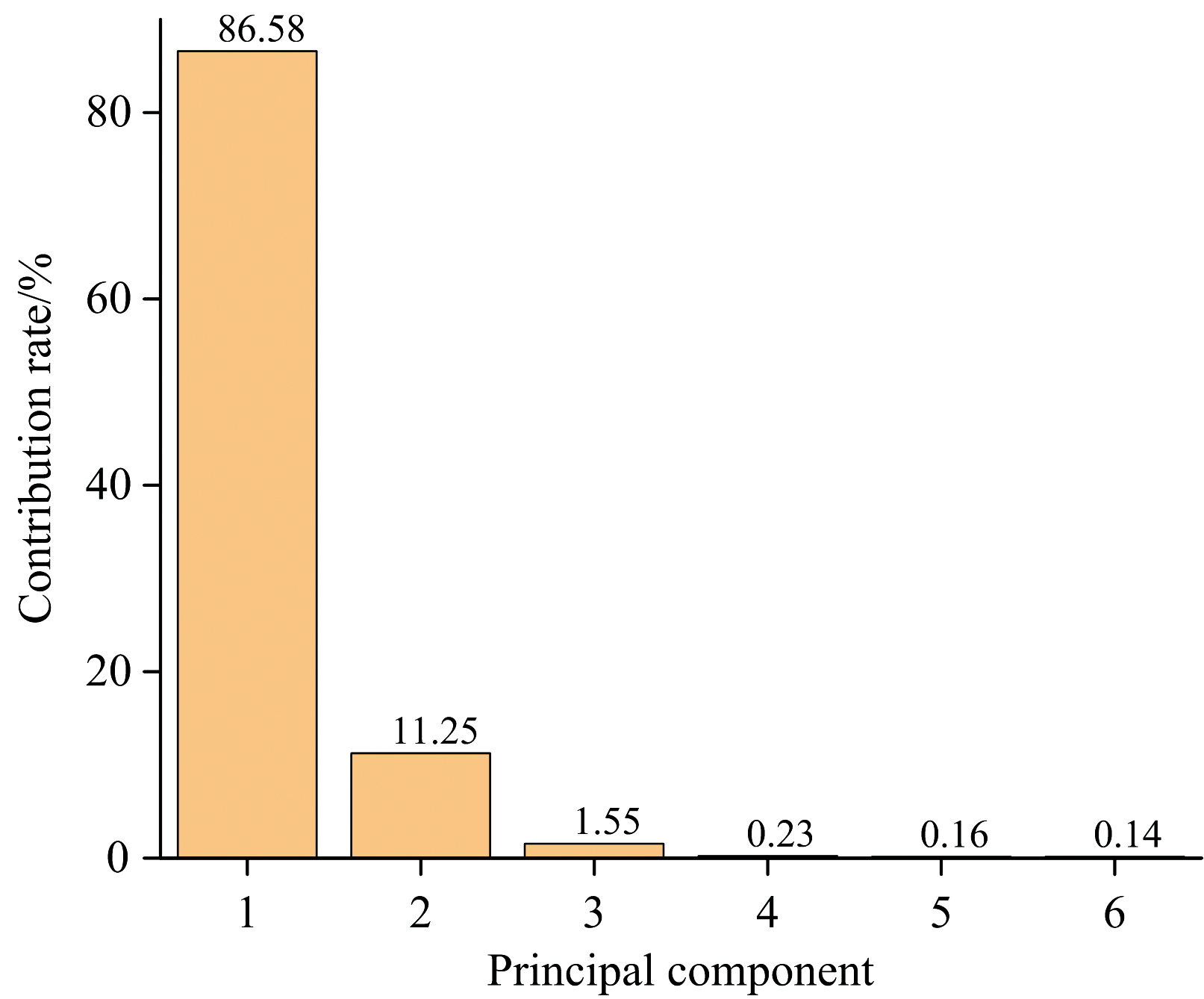 | 图5 主成分分析结果Fig.5 Principal component analysis results |
2.1.2 等距特征映射
等距特征映射算法(ISOMAP)[14]是一种无监督的非线性降维算法, 是一种典型的非迭代全局优化算法。 其核心思想在于通过保持数据点之间的等距关系来进行降维, 即使降维后的点两两之间的测地距离不变, 该算法关键在于数据点之间的距离用测地线距离来代替欧氏距离。 设置该算法的近邻点k的取值为1~100, 以极大似然法估计原始数据本征维度的结果为依据, 设置等距映射算法降维的维度为2~20维, 用最终的降维结果为数据源, 并以所建模型的精度为评价指标确定降维后的光谱数据为5维, 最邻近数为12, 处理所用时间为3.465 s。
2.1.3 局部线性嵌入
局部线性嵌入算法(LLE)[15]是一种非线性降维算法, 这一算法要求每一个数据点都可以由其近邻点的线性加权组合构造得到, 使得降维后的数据较好的保留原有的流形结构, 从而解决高维数据存在的数据冗余的问题。 设置该算法的近邻点k的取值为1~100, 并以欧氏距离寻找每个样本点的近邻点, 得到最终的降维结果。 并以所建模型的精度为评价指标确定降维维数, 确定最邻近数为12, 原始数据降维至5维, 处理所用时间为2.163 s。
Stacking[16, 17]是一种先进的集成学习技术, 其核心思想在于构建一个双层结构, 通过融合第一层中的多个基学习器的预测结果并输入到第二层元学习器中来显著提升整体的预测性能。 从而实现多个模型预测结果优化, 形成一个更为准确和全面的预测。
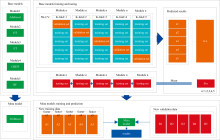
将389个金矿样本按3∶ 1的比例随机分为训练集和测试集, 其中, 训练集为291个, 测试集为98个。 将主成分分析法、 局部线性嵌入和等距特征映射三种降维算法处理后的结果作为输入数据, 以随机森林(random forest, RF)、 极端随机树(extremely randomized tree, ET)、 决策树(decision trees, DT)、 梯度提升树(gradient boosting decision tree, GBDT)和自适应增强(adaptive boosting, Adaboost)为第一层基学习器, 引入5折交叉验证训练第一层中的各个基学习器, 观察验证集的准确性来调整各个模型的参数以达到最优解, 并将各个基学习器的预测结果融合生成新的训练数据集, 输入到以极端梯度提升树(extreme gradient boosting, XGBoost)为第二层的元学习器中进行二次训练, 调节模型的整体参数进行训练与预测, 得到最终金矿品位的预测结果, 并以预测值与真实值的决定系数R2、 平均相对误差MRE、 平均绝对误差MAE、 均方根误差RMSE以及相对分析误差RPD共5个参数作为评桔指标来评估所建模型的精度。 具体的Stacking集成学习模型的实施流程如图6所示。 基于PCA、 ISOMAP、 LLE降维算法和各个模型组合建立的金矿品位反演模型的准确率如表2所示。
 | 图6 Stacking集成学习与训练过程Fig.6 Stacking integration learning and training process |
| 表2 经过PCA、 ISOMAP和LLE降维后的模型的预测准确率 Table 2 Prediction accuracy of the model after PCA, ISOMAP and LLE downscaling |
由表2可以看出, 利用PCA、 ISOMAP和LLE三种降维算法预处理后数据进行建模反演, 所有模型的评价指标均达到了准确率要求, 且不同的降维算法对模型的提升效果不同。 经过对比分析发现, 经过利用LLE降维算法处理后的高光谱数据所建模型得到的准确率总体上明显优于其他两种降维算法, 效果最好, 其中LLE-Stacking组合方法的准确率最高, R2为0.972, RMSE为0.991, RPD为5.935, MAE为0.655, MRE为0.231。 且Stacking集成学习模型的准确率明显优于单一模型的精度, 所有指标均得到了有效的提升。 同时, 绘制了基于Stacking模型的预测值与实测值的对比图, 如图7所示。
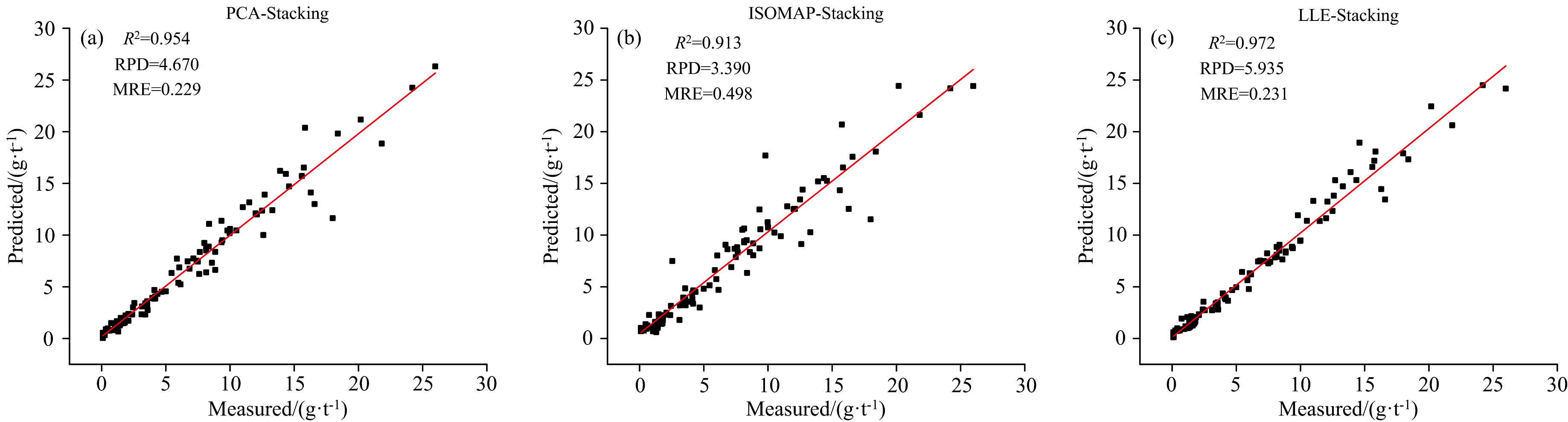 | 图7 Stacking真实值与预测值品位对比图 (a): PCA-Stacking; (b): ISOMAP-Stacking; (c): LLE-StackingFig.7 Comparison of actual and predicted grades using Stacking (a): PCA-Stacking; (b): ISOMAP-Stacking; (c): LLE-Stacking |
综上分析, LLE是一种典型的非线性降维算法, 能够使降维后的数据较好的保留原有的流形结构, 每一个数据点都可以由其近邻点的线性加权组合构造得到, 从而解决高维数据存在的数据冗余的问题。 而金矿高光谱数据中存在更多隐式的非线性特征, 因此相较于线性降维算法PCA可以对金矿的品位和光谱特征进行更为有效的降维和保留。 尽管LLE和ISOMAP都能显著降低数据的冗余度, 但LLE基于近邻重建权值保持不变理论来实现高维空间至低维空间的映射, 而ISOMAP算法在构建出测地距离矩阵后基于样本的成对相似性实现高维空间至低维空间的映射, 因此在处理金矿高光谱数据降维是, LLE能够更好地维持光谱数据的整体流形结构, 同时降低数据的冗余性。 因此经过对比分析发现LLE算法相较于其他两种算法更适用于金矿的高光谱数据降维。
Stacking克服了RF、 ET和XGBoost等单一模型的缺点和局限性, 减少单一模型可能存在的偏差和方差, 消除或降低数据的波动和噪声, 从而提高整体的预测性能, 降低过拟合的风险, 增强模型的鲁棒性。 选用XGBoost作为元学习器是因为该模型在金品位预测中展现了出色的能力, 有效抵消了高光谱数据的复杂性和非线性影响, 从而实现了更优的预测效果。 这一算法基于梯度提升方法, 对目标函数进行了二阶泰勒展开, 保留了更多关于目标函数的信息, 增强了模型的提升效果。 此外, XGBoost引入了正则化技术, 有效防止了过拟合, 并对数据中的噪声和异常值表现出一定的鲁棒性, 进一步提升了预测能力。 与其他单一模型相比, 集成学习不仅具备更全面的优势, 还表现出更高的实用性, 尤其在金矿品位反演建模中更为适用。 这种方法能够有效整合不同模型的特征, 提供更加精准和稳定的预测, 确保在实际应用中取得更优的效果。
针对基于可见光-近红外高光谱数据对中国辽宁省内二道沟、 凌源和排山楼金矿的品位反演建模问题进行了研究, 共利用三种降维算法进行了降维处理, 而后利用六种机器学习算法和集成学习算法分别建立了金矿的品位定量反演模型, 并评估了建模准确率, 得出以下结论:
(1)PCA、 ISOMAP和LLE三种降维算法均能有效降低金矿高光谱数据的冗余度, 并有效提升反演的计算速度和建模准确率, 三种算法最佳的降维维度分别为6, 5, 5。 其中, LLE降维算法对建模准确率提升最大, 可有效降低数据的冗余, 相比PCA和ISOMAP更适用于金矿高光谱数据降维预处理。
(2)基于Stacking集成学习建立的预测矿区金品位的模型的各项指标均优于单一模型。 其中, LLE-Stacking的R2最高为0.972, 相比于单一模型的最高(LLE-GBDT)R2提升了0.012, 相对分析误差RPD从4.986提升到5.935。 研究结果表明LLE-Stacking模型能够充分利用单一模型的优势, 建立的金矿的品位反演模型准确率更高、 稳定性更好, 更适用于金矿品位的反演。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|