

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于空谱增强变换的高光谱壁画图像修复
[张勉1  , 赵家昱
, 赵家昱1, * , 周晗2 , 廉玉生2 ]
, 赵家昱, 周晗|
|


作者简介: 张 勉,女, 1972年生,北京建筑大学智能科学与技术学院副教授 e-mail: zhangmian@bucea.edu.cn
壁画和彩绘的无损修复是建筑文化遗产保护和传承的重要课题和研究热点。 高光谱成像技术具有“图谱合一”的优势, 可同时获得图像目标的二维空间信息和一维光谱信息; 能在无接触、 无需独立样本的条件下, 对壁画和彩绘文物进行光谱数字典藏和无损分析, 已经成为文物数字典藏、 修复和分析的重要技术手段。 现有的RGB彩色壁画图像修复方法, 无法实现高光谱图像中多波段光谱信息的典藏、 修复和分析; 此外, 现有的基于卷积神经网络的深度生成式彩色壁画图像修复方法, 存在空间结构和光谱特征建模能力不足、 全局信息探索和建模能力弱等缺点, 严重影响图像的修复精度。 为解决以上问题, 本文提出一种基于空谱增强变换的高光谱壁画图像修复方法。 首先将待修复的高光谱壁画图像光谱降维, 转换为RGB彩色图像; 然后, 利用提出的基于空谱增强变换的生成对抗网络, 对该RGB彩色图像的空间和颜色信息进行修复; 提出的修复网络分为空间信息预修复网络(Spa-PIN)和空间-颜色信息修复网络(Spa-Color-IN), 结合空间注意力和光谱注意力模块(SAESA), 实现壁画图像的有效修复。 在空间信息结构重建阶段, 着重于壁画图像的基本形态与纹理重构; 在色彩修复阶段, 则进行空间注意力和光谱注意力的增强, 提高修复质量; 最后, 利用提出的聚类BPNN将修复的RGB图像升维重建, 得到修复的目标高光谱图像数据立方体。 本文提出的空谱增强变换注意力机制对图像特征进行空间坐标卷积融合和光谱立方体局部-全局注意力融合, 可同时关注图像全局和局部范围的空谱相关性, 增强空谱细节的修复能力。 公共数据集上的实验结果表明, 与当前的三种先进修复方法比, 本方法具有最优的定量指标和修复效果, 可有效、 准确地修复高光谱壁画彩绘图像, 为壁画和彩绘等建筑遗产的高精度典藏、 修复和分析提供新的先进技术手段。
The non-destructive murals inpainting and colored paintings are an important topic and research hotspot for protecting and inheriting architectural cultural heritage. Hyperspectral imaging technology can simultaneously obtain two-dimensional spatial information and one-dimensional spectral information of targets.It has become an important technical means for digital collection, restoration, and analysis of cultural relics to conduct spectral digital collection and non-destructive analysis of murals and painted cultural relics without contact and without independent samples. Existing RGB color mural inpainting methods can not realize the collection, restoration and analysis of multi band spectral information in hyperspectral images; In addition, the existing depth generating color mural inpainting methods based on convolutional neural network have shortcomings such as insufficient modeling ability of spatial structure and spectral characteristics, weak ability of global information exploration and modeling, which seriously affect the mural inpainting accuracy. In order to solve the above problems, this paper proposes a hyperspectral mural inpainting method based on the space spectrum enhancement Transformer. Firstly, the hyperspectral mural inpainting to be repaired is reduced in spectral dimension and converted into an RGB color image. Then, the space and color information of the RGB color image is repaired by using the proposed generation countermeasure network based on the space spectrum enhanced Transformer. The repair network proposed in this paper is divided into a spatial information pre-repair network (Spa-PIN) and a spatial color information repair network (Spa-Color-IN). The effective repair of mural images is achieved by combining a spatial attention and spectral attention module (SAESA). In the reconstruction phase of spatial information structure, the basic shape and texture reconstruction of mural inpainting are emphasized. In the phase of color restoration, spatial attention and spectral attention are enhanced to improve the quality of restoration. Finally, using the proposed clustering BPNN, the dimension of the repaired RGB image is upgraded and reconstructed, and the repaired target hyperspectral image data cube is obtained. The attention mechanism of the space spectrum enhancement Transformer proposed in this paper performs spatial coordinate convolution fusion and spectral cube local global attention fusion on image features, which can simultaneously model the spatial spectrum correlation of the image in the global and local ranges, and enhance the repair ability of spatial spectrum details. The experimental results on the public datasets show that, compared with the current three advanced restoration methods, the method proposed in this paper has the optimal quantitative indicators and mural inpainting effect. It can effectively and accurately restore hyperspectral mural inpainting and provide new advanced technical means for high-precision collection, restoration, and analysis of architectural heritage such as mural inpaintings.
壁画作为人类文明的“ 活化石” , 承载着丰富的历史信息和独特的艺术价值, 是研究古代社会生活、 宗教信仰、 审美观念不可或缺的实物资料。 然而, 由于受到自然侵蚀、 人为破坏以及环境变化等多种因素的影响, 壁画呈现出不同程度的污损和缺失。 壁画典藏和修复的研究, 旨在通过科学的方法和技术手段恢复壁画原貌, 确保这些历史文化遗产得以保存和延续[1, 2]。
高光谱成像技术具有“ 图谱合一” 的优势, 可同时获得目标的二维空间信息和一维光谱信息; 能在无接触、 无独立样本的条件下, 对壁画等彩绘文物进行光谱数字典藏和无损分析, 已经成为彩绘文物数字典藏、 修复和分析的重要技术手段, 在彩绘文物典藏和修复方面取得了重要进展[3, 4, 5, 6]。
在彩绘文物修复方面, 国内外学者和研究机构尝试基于深度学习的RGB彩色壁画图像修复, 并取得了初步研究成果。 2014年Goodfellow等[7]使用对抗生成网络进行图像修复, 通过预训练模型学习图像的先验分布, 再通过判别器和生成器的博弈过程来优化修复结果。 2015年, Radford等[8]提出了无监督的深度卷积生成网络(DCGANs), 利用学习到的图像特征, 指导图像生成; 但其GAN的判别器和生成器很难同时收敛。 为了解决这个问题, Arjovsky等[9]在2017年提出了WassersteinGAN(WGAN)的网络结构, 但因其局部卷积造成了掩膜信息完全依赖于最后一层特征图的缺点, 而导致网络模型无法确定像素点是否在受损区域内, 最终影响修复精度。 Yu等[10]在2019年提出了基于门控卷积的GAN网络(SN-PatchGAN), 门控卷积可以从输入的数据中学习出相应的像素点的门控值和位置信息, 从而有条件的提取特征, 减少了无效像素的干扰; 但其门控卷积无法显示空谱特征间的相关性, 也影响了修复精度。
2020年Lugmayr等[11]提出了一种基于Diffusion的图像修复方法, 利用其提出的DDPM模型对待修复图像的缺失部分进行生成, 再引入重采样机制以进一步提升修复效果; 在扩散降噪算法基础上, 在一定步长内做n次重复扩散降噪过程, 逐步迭代以提高图像语义的连贯性; 但无法有效的修复图像的细节和复杂纹理。 2020年Li等[12]提出了一种名为“ 递归特征推理” 的网络模型(recurrent feature reasoning), 用于图像填充任务。 该模型主要由一个递归特征推理模块和一个知识一致注意力模块组成。 递归特征推理模块通过反复推断空洞边界并利用其作为进一步推断的线索。 其每次循环推理采用递归加权求和的方式来进行未知区域的生成; 但无法有效地重建图像的空间结构。
2022年Li等[13]提出了一种基于卷积UNet的GAN的壁画图像修复方法, 使用卷积U-Net网络作为生成器对敦煌壁画进行了修复。 2023年Deng等[14]提出了双分支structure-guided two-branch(SGTB)模型的GAN图像修复算法。 2024年Xu等[1]提出了一种基于扩散模型的生成对抗网络, 该方法分为两个阶段: 第一阶段使用基于卷积UNet网络结构的裂缝检测方法提取受损区域, 并使用基本扩散模型进行初步修复; 第二阶段使用Canny边缘检测算法提取壁画的边缘信息, 并将边缘信息与裂缝检测结果结合起来生成带边缘信息的掩模, 然后使用边缘结构恢复的扩散模型进一步修复壁画。 这一方法也没有对图像空间信息相关性进行建模, 导致其修复效果欠佳。
2017年Vaswani等提出了一种新的转换网络[15], 在图像特征提取和重建方面展现出显著优势[16, 17, 18], 其核心在于能够通过自注意力机制精确地捕获图像中的空谱信息关联性, 并建模全局上下文信息, 从而有效地建模并增强图像的空谱相关性。 因此, 与现有方法[19, 20, 21, 22]相比, 能够更准确、 更细致地提取和重建图像特征。 而现有的基于卷积的深度学习的修复方法无法建模全局信息, 也没有进行空间结构和空谱特征相关性的建模和重构, 这将严重影响图像的修复精度。
综上所述, 现有的壁画图像修复研究仅针对RGB彩色图像开展, 并不适用于高光谱图像的修复, 无法实现壁画的高光谱信息典藏、 修复和分析; 此外, 现有的基于卷积神经网络的深度生成式彩色壁画图像修复方法受限于卷积网络无法建模全局信息的缺点, 其网络结构也存在空间结构和空谱特征相关性的建模能力不足等缺点, 严重影响图像的修复精度。
为解决以上问题, 我们提出一种基于空谱增强变换的高光谱壁画图像修复方法。 首先, 将待修复的高光谱壁画图像数据立方体转换为RGB彩色图像; 然后利用提出的基于空谱增强变换的生成对抗网络, 对该RGB彩色图像进行修复; 最终利用提出的聚类backpropagation neural network(BPNN)将修复的RGB图像重建, 得到修复的目标光谱图像数据立方体。
主要创新点有:
(1)提出一种高光谱壁画图像降维转换至RGB颜色空间进行空间信息和颜色修复, 并利用聚类BPNN进行高光谱重建的生成式高光谱图像修复方法, 克服了现有壁画修复方法无法实现高光谱图像修复的问题。
(2)提出了一种基于空谱增强转换的生成对抗修复网络, 以克服现有方法中空间结构细节修复能力不足、 无法同时建模图像的全局-局部和空间-光谱相关性等缺点。 具体而言, 在空间信息生成器中提出基于空间注意力增强的U-Net结构, 即基于空间信息预修复网络(spatial pre-inpainting network, Spa-PIN), 以增强空间细节的恢复能力; 在颜色信息生成器中提出空谱增强的转换机制, 即空间-颜色信息修复网络(spatial-colorful inpainting network, Spa-Color-IN), 以同时建模图像的全局-局部范围的空谱相关性, 增强空谱细节的修复能力。
(3)以待修复的RGB图像及其相对应的高光谱图像为训练数据集, 构建了重建目标高光谱图像的聚类BPNN网络, 实现了壁画高光谱图像修复。
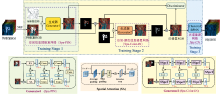
本文提出的生成式壁画高光谱图像修复框架及网络结构如图1所示。 首先, 利用彩色相机的光谱灵敏度函数(spectral response function, SRF), 将待修复的高光谱壁画图像数据立方体转换为RGB彩色图像; 然后, 利用提出的基于空谱增强转换的生成对抗网络, 对该RGB彩色图像进行修复; 最后, 用聚类BPNN将修复的RGB图像重建, 得到修复的目标光谱图像数据立方体。
 | 图1 生成式壁画高光谱图像修复框架及网络结构Fig.1 Generative mural hyperspectral image restoration frame and network structure |
基于空谱增强转换的生成对抗网络由基于空间信息预修复网络Spa-PIN的生成器Generator1、 空间-颜色信息修复网络Spa-Color-IN的生成器Generator2和鉴别器Discriminator组成。 在第一训练阶段(Training Stage 1), 生成器Generator1的网络Spa-PIN和鉴别器Discriminator构成的生成对抗网络预修复壁画RGB图像的空间信息; 在第二训练阶段(Training Stage 2), 生成器Generator2的网络Spa-Color-IN和鉴别器Discriminator构成的生成对抗网络继续精细化修复壁画RGB图像空间和颜色信息。 此外, 以待修复的RGB彩色壁画图像及其对应的高光谱图像分别为输入和输出训练数据集, 训练构建的聚类BPNN网络, 建立RGB数据向高光谱数据的高精度聚类映射关系, 实现已修复RGB彩色图像向高光谱图像的映射重建, 并得到最终的目标高光谱图像HSI。
在Generator1中, 为了增强空间细节的修复能力, 提出了基于空间注意力(spatial attention, SA)增强的U形Spa-PIN预修复网络。 在Generator2中, 为了有效利用第一阶段的修复结果, 并充分建模图像全局-局部范围上的空谱相关性, 增强空谱细节的修复能力, 提出了基于空谱增强注意力(spatio-spectral transform, SSpeT)的Spa-Color-IN网络。 此外, 利用提出的聚类BPNN将修复的RGB图像升维重建得到修复的目标HSI高光谱图像数据立方体, 实现了壁画的高光谱图像的高精度修复。
生成式壁画高光谱图像修复框架及网络结构如图1所示, 在Generator1中, Spa-PIN网络是由SA增强的U-net结构, 包括编码器、 解码器和Bottleneck。 Spa-PIN的具体结构如图1左下角所示。 在编码器中, 由于浅层特征包含丰富的纹理细节, 因此提出的SA模块被用于编码器的浅层特征提取, 随后在空间维度上使用3× 3卷积层进行层次特征编码。 同样, 在解码器中最后一层使用SA模块进一步重建空间纹理细节。 SA模块的引入, 增强了空间特征纹理细节的修复能力。
具体来说, 在Spa-PIN中, 将待修复RGB I∈ RH× W× 3与线条图L∈ RH× W× 1在通道维度拼接得到初始化的输入X0∈ RH× W× C。 然后, 为了强调纹理细节, X0经过SA进行纹理细节增强, 随后经过步长为2的卷积层进行下采样, 它可以将空间维度缩小1/2, 通道维度扩充为原来的2倍。 随后, 特征经过两个3× 3卷积层, 每个卷积层后都有一个下采样层。 编码器的第i级特征记为Xi∈
在SA模块中, 对输入的特征进行平均池化、 最大池化, 并经过3× 3的卷积, 生成具有空间纹理细节权重的空间注意力图; 该空间注意力图与输入的特征相乘后得到强调纹理细节的空间特征。 具体来说空间注意力模块通过使用两个池化操作, 聚合特征图的通道信息, 生成两个2D图:
SA可以强调和细化重要的纹理细节特征, 抑制信息量较小的无用特征, 有利于进一步提高修复精度。
在Generator2中, 本文提出的Spa-Color-IN网络的核心是SAESA模块, 因它可以同时建模和学习空间全局相关性和光谱全局-局部相关性, 其整体架构如图1右下角所示。 Spa-Color-INt采用U-Net结构, 由以SAESA为核心的编码器、 Bottleneck和解码器组成。 具体来说, 首先, Spa-PIN输出的预修复RGB Y∈ RH× W× 3彩色图像和待修复区域的掩码Mask M∈ RH× W× 1在通道维度进行拼接得到初始输入H0∈ RH× W× C。 随后, 为了在H0上进行不同尺度的特征编码, X0依次经过3个SAESA模块; 每个SAESA模块后都有一个Down模块, Down模块是一个步长为4的卷积层, 可缩小空间大小为原来的1/2并使通道加倍。 编码器的第i级特征记为Xi∈
在判别器(Discriminator)中, 使用70× 70 PatchGAN架构, 来判别大小为70× 70的重叠图像块是否真实。 该判别器结构有5个模块组成, 每个模块包含一个Norm, 一个卷积核大小为4的卷积层以及一个LeakyRelu激活函数。 前三个模块的卷积层步长为2, 后两个模块的卷积层步长为1。
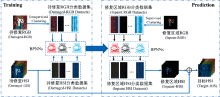
利用提出的聚类BPNN进行修复区域的RGB颜色向高光谱数据的映射, 并最终实现壁画的高光谱图像修复。 所提出的聚类BPNN原理框架, 如图2所示。 在RGB颜色空间中, 对待修复的RGB图像的像素颜色值进行Mean-shift无监督聚类[24], 在每一个类内, 建立一个以RGB图像像素的RGB颜色值为输入, 对应的HSI图像高光谱数据为输出的反向传播神经网络BPNN。 在训练过程中, 以每一类内的待修复RGB及其对应的待修复HSI高光谱为训练数据集, 训练属于此类的BPNN。 在预测过程中, 首先将对抗生成网络输出的修复区域RGB图像的每一个像素进行监督聚类, 其聚类中心与训练过程中待修复图像的聚类中心相同; 然后以像素所属类的BPNN进行对应的高光谱数据预测, 得到修复区域的HSI; 并与待修复HSI相加后, 可得目标HSI。 对RGB图像的颜色和对应的高光谱进行聚类映射, 有利于BPNN网络训练收敛, 并提高网络映射精度。
 | 图2 基于聚类BPNN的高光谱HSI图像重建原理框架Fig.2 The principle framework of hyperspectral HSI image reconstruction based on clustering BPNN |
本文所提出的BPNN输入和输出神经元数量分别等于RGB图像颜色通道数和高光谱HSI的光谱通道数, 其隐层以2层神经元数量为64的全连接层构成, 两个全连接层的中间以Sigmoid函数进行激活。
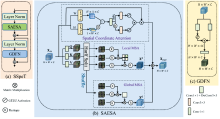
在Spa-Color-IN网络中, 通过SSpeT模块同时建模和学习全局和局部范围的空谱相关性。 如图3(a)所示, SSpeT由两个归一化层(LN), 一个Spatial attention enhanced spectral attention(SAESA)[图3(b)]和门控深度可分离卷积前馈网络Gated-Dconv feed-forward network(GDFN)[图3(c)]组成。
 | 图3 空间注意力增强的光谱转换注意力机制基本结构Fig.3 Basic structure of attention mechanism in spectral Transform for spatial attention enhancement |
在SEASA网络中包括两个分支, 第一个分支我们通过spatial coordinate attention(SCA)网络对输入特征进行H和W尺度的空间卷积, 提取图像的空间特征, 通过残差连接将其与原输入特征融合, 实现对图像的空间相关性建模。 SCA首先将特征图分别沿H方向和W方向空间维度做平均池化操作, 来获取空间两个子维度的全局信息, 两个子维度获得的张量在通道维度进行拼接, 再经过1× 1卷积来进行两个子维度的全局信息融合, 获得全面的空间全局信息。 随后, 将两个子维度得到的张量在通道维度进行拆分, 分别经过1× 3和3× 1的不对称卷积进行信息整合之后, 相乘得到空间全局注意力信息, 简单来说, SCA可以总结如式(2)— 式(4)
其中, F∈ RH× W× C表示输入特征, R表示重塑张量形状, , MH和MW分别表示H, W维度得到的中间注意力图, σ 表示Sigmoid函数, C13和C31分别表示1× 3卷积和3× 1卷积, MH∈ RH× W× C表示最终输出的空间注意力图。
另一个分支, 先对输入特征线性映射转换为查询Q、 键K、 值V。 再利用Half Split将Q、 K、 V划分为若干非重叠窗口。 通过Shuffle将其再分为局部Local MSA和全局Global MSA两路。 通过局部MSA建模局部尺度上的上下文信息, 并通过全局MSA建模长程依赖关系。
将输入记为Xin∈
将Q、 K、 V 沿通道维度分为两等份, 分别为
其中Ql, Kl, Vl∈
局部分支的Ql, Kl, Vl被分割为大小为M× M的非重叠窗口。 然后它们被重塑为
每个头的维度为dh=
其中$P_{l}^{i} \in R^{M^{2} \times M^{2}}$为可学习参数,用于端入位置信息。非局部分支的$Q_{nl} , K_{nl} , V_{nl} \in R^{H \times \hat{W} \times \frac{C}{2}}$首先被划分为大小为$M \times M$非重㔊窗口。然后它们的形状从$R^{\frac{H \hat{W}}{M^{2}} \times M^{2} \times \frac{C}{2}}$转换为$R^{M^{2} \times \frac{H \hat{W}}{M^{2}} \times \frac{C}{2}}$来打乱标记的位置并建立跨窗口体赖关系。$Q_{nl} , K_{nl} , V_{nl}$分别分成了$h$个头
全局MSA由每个头计算为
其中$P_{nl}^{i} \in R^{\frac{H \hat{W}}{M^{2}} \times \frac{H \hat{W}}{M^{2}}}$为可学习参数, 用于橄入位置信息。随后$A_{n l}^{i} \in R^{M^{2} \times \frac{H \hat{W}}{M^{2}} \times d_{h}}$, 通过转置转换为形状为$R^{M^{2} \times \frac{H \hat{W}}{M^{2}} \times d_{h}}$的张量实现像素重组, 进一步建模非局部相关性。 然后, 根据 式(4)中局部分支的输出和式(6)中非局部分支的输出融合两个分支的结果
式(11)中, $W_{l}^{i}$和$W_{n l}^{i}$属于可学习参数。我们通过重新排列方程(7)的结果来获得输出$X_{o u t} \in R^{H \times \hat{W} \times C}$将各部分输出融合后作为该网络结构的输出。
最后将从SAESA网络中得到的两个分支的空间信息与局部-全局光谱信息进行融合。
本文提出的生成式高光谱壁画修复网络的损失函数由两部分组成: 生成器损失和判别器损失。 判别器损失衡量判别器判断的结果是否符合事实[7]; 生成器损失中的对抗性损失衡量了生成的图片与真实图片之间的接近程度。 在两个损失函数之间进行平衡时, 最终图像会逐渐接近真实图像。 在我们的网络中, 生成器损失(LGenerator)由感知损失[25]、 L1损失和直方图损失[26]组成, 如式(7)所示
感知损失(LGram)旨在实现图像的整体重建, 而L1损失(L1)用于颜色校正, 直方图损失(LHistogram)用于调整颜色分布并避免歧义。
在第一阶段, 我们只训练结构重建网络。 这一阶段的目标是从草图和损坏图像中生成一个基本结果。 由于直方图损失的时间复杂度和空间复杂度都很高, 在第一阶段不采用直方图损失。 在第二阶段的训练中, 感知损失、 L1损失和直方图损失同时用于两个生成器。
我们使用的实验环境为: intel(R) Xeon(R) Platinum8168 CPU @2.70GHz; Nvidia RTX 4090。 使用了参考文献[13]中提供的壁画数据集, 其中包含525幅真实壁画和1189幅复制品及其对应的线稿图。 同时, 使用了参考文献[27]中发布的公共遮挡数据集作为掩码, 以生成待修复的壁画图像。
修复算法的训练过程被分为两部分, 后者生成器依赖于前者生成器的输出, 不可避免地会出现累积误差。 因此, 在早期阶段, 对第二个生成器进行训练是没有意义的。 我们采用了两个阶段的训练策略: 首先独立训练Spa-PIN, 经过8个周期的训练, Generator1和D达到收敛, Generator1开始生成包含边缘图结构信息的结构良好的画作; 然后在第二阶段加入Spa-Color-IN进行训练。 由于判别器已经很好地训练好了, 因此在它的指导下Generator2可以快速收敛。
第一阶段训练步数为4 000步, 第二阶段为6 000步, 鉴别器D和生成器G的学习率设置为0.000 1和0.000 01。 在第一阶段训练中, epoch和batch size分别设置为8和32; 在第二阶段训练中, 分别设置为8和8。
BPNN[28, 29]由训练阶段和预测阶段组成。 在训练阶段, 使用基于聚类的BP神经网络从待修复RGB学习待修复RGB-HIS的映射函数。 在RGB和HSI中, 具有相同坐标的两个对应像素形成一个RGB-HSI对。 然后, 使用无监督聚类将待修复RGB分成不同的簇。 无监督聚类中的簇数没有预先定义, 每个簇中的RGB数据点单独生成一个待修复RGB分类数据集, 根据RGB-HSI对生成相应的RGB到光谱图像的数据集。 我们为每个簇建立了一个BP神经网络来学习RGB-HSI映射函数。 每个簇的待修复RGB分类数据集用于训练该簇的BP神经网络。
在利用训练好的BPNN进行预测阶段, 根据上文提到的无监督聚类的得到的聚类中心, 通过有监督聚类将修复区域的RGB像素归到这些聚类中心所在的类中, 并获得修复区域分类RGB数据集。 使用训练好的BP神经网络, 将修复RGB分类数据集映射到修复HIS分类数据集中, 并与待修复HIS未受损区域进行拼接, 最终得到修复完成的HSI。
实验结果的评价指标为光谱夹角(SAM)、 峰值信噪比(PSNR)、 结构相似度(SSIM)[17, 18]; SAM越小代表修复光谱质量越好, PSNR和SSIM越高代表越好的空间保真度。 三种RGB图像修复方法(包括Guided-diffusion[11]、 RFR[12]和LDGPI[13])被用作比较算法。 Guided-diffusion也采用了注意力机制, 但本文提出的方法新增了对于图像光谱和空间信息相关性的建模; RFR和LDGPI使用卷积提取图像特征; 这种卷积操作虽然能够有效地提取图像的一些基础特征, 但在处理复杂的图像纹理和色彩信息时存在一定局限性。 本方法使用空谱联合局部-全局注意力机制对图像的纹理和色彩特征进行提取, 不仅可以关注到图像中局部区域的纹理细节, 还能从全局视角把握图像的整体色彩分布和结构特征。
为了更加直观的对比, 用壁画数据集[13]训练这些模型, 并进行测试。 测试结果的定量指标如表1所示。
| 表1 不同修复算法的定量指标 Table 1 Quantitative indexes of different repair algorithms |
在峰值信噪比(PSNR)方面, 本方法取得了显著优势, 达到43.656, 远高于RFR的30.617、 LDGPI的40.266以及Guided-diffusion的41.391。 得益于空谱联合的局部-全局注意力机制, 本方法在抑制图像噪声、 提升图像质量方面表现卓越, 能够更为精准地恢复图像原始信息, 使修复后的图像与原始图像在像素层面的差异降至更低水平, 从而确保图像具有更高的清晰度与保真度。
结构相似性(SSIM)指标上, 本方法的 SSIM 值最高, 达到0.996, 表明其在修复过程中能够出色地保持图像的结构完整性与一致性, 最大程度地保留了图像的原有结构特征。 相比之下, Guided-diffusion仅建模光谱全局相关性, 取得了次优结果。 而基于卷积的方法, LDGPI的SSIM值分别为0.994和0.993; 而RFR的SSIM值仅为0.932, 相对较低, 反映出其在图像纹理结构复原方面的能力较差, 这可能源于卷积神经网络对全局信息的建模能力不足, 修复后的图像可能会出现一定程度的结构变形。
对于光谱夹角图(SAM), 本方法为0.326, 显著优于其他三种方法。 这表明本方法在处理图像光谱信息方面具有显著优势, 能够精准地恢复图像的光谱特征。 LDGPI的SAM值为0.426, Guided-diffusion的SAM值为0.446, 二者在光谱信息处理上虽有一定效果, 但与所提方法相比仍存在差距; 而RFR的SAM值高达1.357, 说明其在光谱信息恢复方面存在较大缺陷, 修复后的图像色彩可能会出现严重偏差, 无法准确还原图像的光谱色彩信息。
此外, 我们随机选择了410和680 nm两个波段, 并对它们的修复结果进行定性比较。 410 nm波段不同算法的图像修复结果及误差热力图如图4所示, 680 nm波段的结果如图5所示。
 | 图4 410 nm波段不同算法的图像修复结果及误差热力图 (a): 410 nm波段不同算法的图像修复结果; (b): 410 nm波段误差热力图Fig.4 Image inpainting results and error heat maps of different algorithms in 410 nm waveband (a): Image inpainting results of different algorithms in 410 nm waveband; (b): Error heatmaps in the 410 nm waveband |
 | 图5 680 nm波段不同算法的图像修复结果及误差热力图 (a): 680 nm波段不同算法的图像修复结果; (b): 680 nm波段误差热力图Fig.5 Image inpainting results and error heat maps of different algorithms in 680 nm waveband (a): Image inpainting results of different algorithms in 680 nm waveband; (b): Error heatmaps in the 680 nm waveband |
由图4和图5可知, 本方法可以有效修复空间细节, 并产生了最小的误差热力图。 其次是LDGPI和Guided-diffusion, 它们在图像纹理细节处的热力图误差较大; RFR产生了棋盘状伪影, 无法有效修复图像结构。
从破损区域的形状复杂程度来看, 本方法在面积较小, 分散的破损区域中能获得较小的误差值, 对于面积较大较为连续的破损区域, 误差值偏高; 但整体效果优于对比算法, 并且修复结果符合图像语义; 对比算法中, 除RFR外, 其他两种算法获得了较好的结果。 也就是说, 通过预测全局噪声分布的Guided-diffusion算法与加入空间注意力的双生成式对抗网络的LDGPI算法产生较好的修复结果; 而本方法提出了局部和全局尺度上的空谱注意力机制, 取得了最优的修复结果。
提出了一种基于空谱注意力增强转换的壁画光谱图像修复网络。 通过双对抗生成网络结构, 对由高光谱转换成RGB图像的壁画图像进行了先结构、 后色彩的修复流程。 在色彩修复阶段我们融合了空间注意力和光谱的局部-全局注意力, 对空间和光谱相关性进行了建模, 大幅提高了壁画图像的修复质量。 并利用聚类BPNN将修复的RGB图像重建得到修复的目标光谱图像数据立方体。 通过上述策略, 本方法在修复图像的准确性和结构相似度方面有显著提高。 实验结果表明, 与现有的先进壁画图像修复方法相比, 本方法在定量指标和修复效果上达到最优, 可更有效、 准确地修复壁画图像, 为壁画和彩绘等建筑遗产的高精度典藏、 修复和分析提供了新的方案。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|