




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
改进潜在低秩和反锐化掩模的红外与可见光图像融合
[冯准若1  , 李云红
, 李云红1, * , 陈伟重1 , 苏雪平1 , 陈锦妮1 , 李嘉鹏1 , 刘欢1 , 李仕博2 ]
, 李云红, 陈伟重|
|


作者简介: 冯准若, 2001年生,西安工程大学电子信息学院硕士研究生 e-mail: 15339007860@163.com
针对低光场景下红外与可见光图像融合中存在的图像显著性信息提取不全和细节弱化等问题, 提出了一种改进潜在低秩和反锐化掩模的红外与可见光图像融合算法。 首先, 将红外与可见光图像进行分块和向量化操作, 并将其输入到潜在低秩(LatLRR)模型中, 利用互逆重构操作从红外图像中提取出低秩分量, 从可见光图像中提取出基本显著分量; 其次, 将基本显著分量通过引入各向异性扩散的反锐化掩模滤波(ADUSM)进行逐项差分运算, 进一步分解为深层显著细节分量和多层次细节特征; 然后, 对低秩分量采用视觉显著性图规则进行融合, 确保显著性目标在融合图像中得到更好的保留和增强, 对深层显著细节分量采用局部平方熵最大化进行融合, 通过设定最大活动性系数, 最大程度保留深层显著性细节分量, 提升融合图像的整体质量和视觉丰富性。 对多层次细节特征采用最大空间频率的加权平均策略进行融合, 自适应不同图像的多层次细节特征, 提高整体图像的视觉清晰度和对比度。 最后, 将本方法与Bayesian、 Wavelet、 LatLRR、 MSVD和MDLatLRR算法在TNO和M3FD数据集上进行对比分析, 实验结果表明, 本算法相比于传统的潜在低秩算法, 平均梯度、 信息熵、 标准差和空间频率指标分别提高了31%、 2.1%、 4.4%和34%, 综合主观评价和客观评价分析, 本方法生成融合图像不仅具有丰富的纹理细节和清晰的显著性目标, 且与多种方法相比具有明显的优势, 有效解决了低光环境下图像显著性信息提取不全的问题, 具有较强的泛化能力, 充分验证了改进潜在低秩和各向异性扩散的反锐化掩模滤波结合在红外与可见光图像融合领域的有效性和可行性, 对红外与可见光图像融合的发展及应用具有重要的科学价值。
, LI Yun-hong, CHEN Wei-zhongTo address the challenges of incomplete salient information extraction and detail degradation in infrared and visible light image fusion under low-light conditions, we propose an enhanced fusion algorithm that integrates Latent Low-Rank Representation (LatLRR) with Anisotropic Diffusion-Based Unsharp Mask(ADUSM). Initially, we apply block-wise segmentation and vectorization to the infrared and visible images, subsequently inputting them into the LatLRR model. Through an inverse reconstruction operation, we extract low-rank components from the infrared images and obtain basic salient components from the visible images. Next, the basic salient components undergo processing with ADUSM for pixel-wise differencing, allowing for further decomposition into deep salient detail components and multi-level detail features. Subsequently, the low-rank components are fused utilizing a visual saliency map rule, which enhances the retention and visibility of salient targets in the resultant fused image. For the deep salient detail components, we employ local entropy maximization for fusion, establishing a maximum activity coefficient to preserve the deep salient details effectively, thereby improving the overall quality and visual richness of the fused image. The multi-level detail features are fused using a weighted average strategy based on maximum spatial frequency, which adapts to the multi-level detail features of the input images, thus enhancing the overall clarity and contrast. Finally, we conduct a comparative analysis of our proposed method against Bayesian, Wavelet, LatLRR, MSVD, and MDLatLRR algorithms using the TNO and M3FD datasets. Experimental results demonstrate that our algorithm significantly outperforms traditional low-rank algorithms in average gradient methods, achieving enhancements of 31%, 2.1%, 4.4%, and 34% in average gradient, information entropy, standard deviation, and spatial frequency metrics. Comprehensive subjective and objective evaluations indicate that the fused images produced by our method not only exhibit rich texture details and clear salient targets but also present substantial advantages over various competing methods. This study effectively addresses the issue of incomplete salient information extraction in low-light environments, exhibiting robust generalization capabilities. The integration of improved Latent Low-Rank and ADUSM filtering is demonstrated to be both effective and feasible in the realm of infrared and visible light image fusion, offering significant scientific contributions to the advancement and application of this technology.
多模态图像融合是将同场景不同视觉采集设备获取的视觉信息进行融合的技术。 红外图像通过热辐射反映目标物体信息, 图像中目标相较画面背景突出, 但其纹理、 细节特征弱, 而可见光图像对比度高, 纹理、 细节等外观信息丰富, 二者对于同一场景画面信息的描述具有较好互补性[1]。 因此, 通过图像融合技术实现二者融合, 可获得对场景及目标信息描述更全面清晰的单一图像, 目前该技术在民用安防、 军事及工业检测等领域广泛应用[2]。
在计算机视觉领域, 图像融合通常用于不同传感器、 不同时间点图像融合, 以获得更全面、 清晰的信息[3, 4]。 图像融合历时几十年发展, 主要包括三类: 基于像素融合、 基于特征融合和基于深度学习融合。 基于像素融合的方法用像素级操作, 将两种图像融合, 虽较为直接, 但可能会导致融合图像中细节和信息的丢失; 基于特征融合的方法则通常以图像特征提取融合为主, 保存图像细节和信息, 得出符合人们需求的图像; 基于深度学习的图像融合方法借助于神经网络, 能够自动学习图像中的特征和关联性, 达到较好的融合效果, 但需要海量数据图像实现融合[5]。 其中, 基于特征融合的方法具有灵活性, 因此研究应用最为广泛。
基于特征融合的方法实质是用多尺度分解将空间上重叠特征在尺度上充分分离, 根据每个子图像的特点来设计适宜的融合规则, 从而得到符合人们视觉感知的图像。 但受到源图像清晰度和分解融合方法缺陷的影响, 大部分的变换方法存在细节提取能力不足, 源图像信息保留不全的问题。 Zhao等[6]提出了一种基于贝叶斯的红外与可见光图像融合的模型, 取得了较好的融合效果, 提高了目标自动检测与识别系统的可靠性, 但图像纹理细节仍有较大丢失。 Liu等[7]提出了利用潜在低秩(latent low-rank representation, LatLRR)进行特征提取, 虽取得了较好的效果, 但LatLRR模型解决方法并不唯一, 泛化能力差。 Li等[8]提出了一种新型的基于MDLatLRR的图像多层分解方法, 通过有效的分解方法, 提取任意数量的输入图像的多级特征, 虽具有良好的融合效果, 但对比度损失较大, 细节丢失多。 Naidu[9]提出了一种基于MSVD的多分辨率奇异值分解的新型图像融合技术, 该算法的性能与小波结果相似, 可适用于实时场景, 但它的基向量取决于数据集, 具有一定局限性。 Ma等[10]利用视觉显著图来合并基础层, 提出一种优化的加权最小二乘法来融合细节层, 有效避免对比度损失, 但是伪影较为严重。 李云红等[11]提出了一种基于非采样金字塔滤波与潜在低秩表示分解的红外与可见光图像融合算法, 融合结果图像极大保留了红外特征信息, 取得了较好的效果, 但未考虑低光环境下的信息退化问题。
针对以上方法存在的不足, 充分考虑源图像在低光环境下的信息退化问题, 提出一种改进潜在低秩和反锐化掩模滤波的红外与可见光图像融合方法。 该方法有效地保持了边缘等重要信息的完整性, 在减小噪声的同时最大程度的防止了细节信息的丢失, 并且最大限度地保留了源图像显著性细节特征、 显著性目标和结构信息。
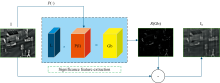
2010, Liu等[12]提出了潜在低秩表示理论。 通过假设图像的表示具有低秩性质, 通过优化算法或者矩阵分解重构出高质量图像, 对图像处理中去噪和图像融合有着重要的作用, LatLRR的数学模型由式(1)和式(2)表示。
式(1)和式(2)中, γ > 0是平衡系数, ‖ · ‖ * 代表核范数, ‖ · ‖ 1是l1范数, X代表图像, Z代表低秩系数, L代表显著性系数, E代表稀疏噪声部分, XZ代表全局结构, LX代表局部结构, 图1为LatLRR分解框架。 P(· )算子通过大小为n× n的滑动窗口将输入的图像I划分为多个图像子块P(I), 与显著性系数矩阵L结合之后, 得到细节矩阵Gb, 随后将细节矩阵重构为细节图像R(Gb), 最后分解出低秩图像Ia。
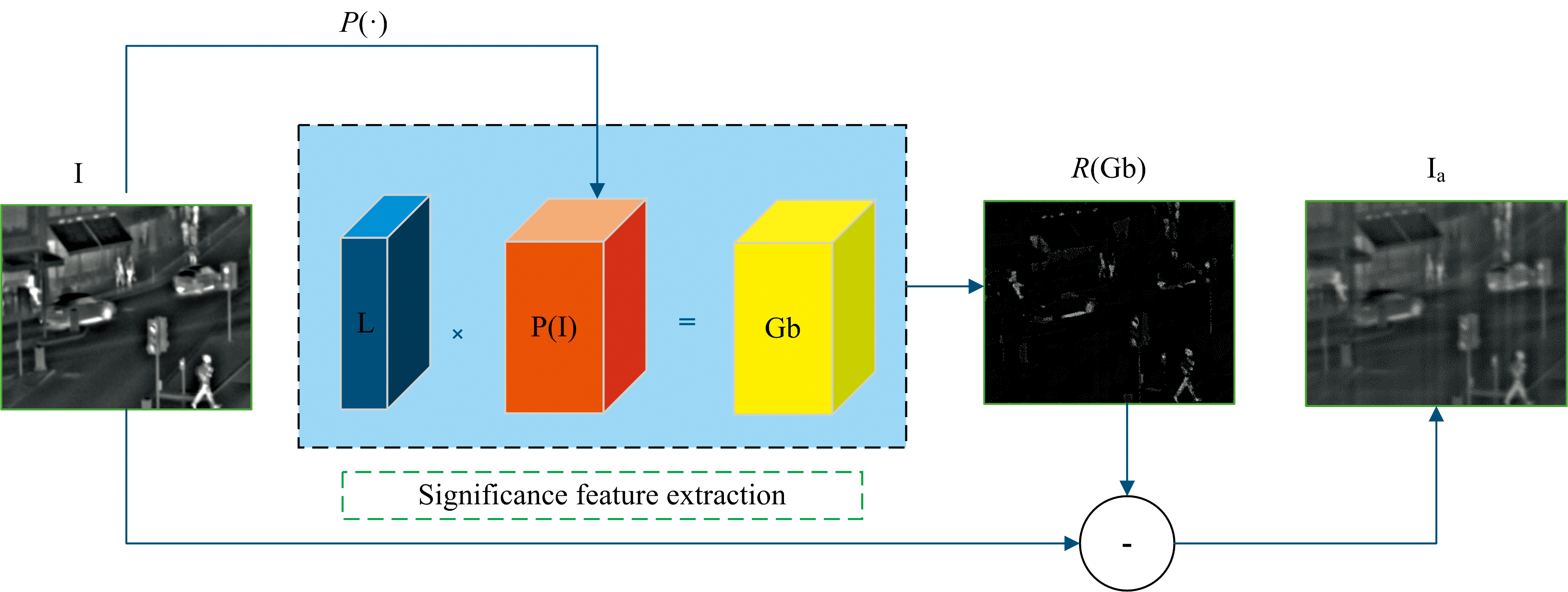 | 图1 LatLRR分解框架Fig.1 LatLRR decomposition framework |
Zohair Al-Ameen[13]在2020年首次提出了各向异性扩散的反锐化掩模滤波, 并将其用于数字图形增强。 各向异性扩散擅长于通过局部亮度调整来去除噪声和平滑图像, 在有效抑制噪声的同时保留图像细节。 反锐化掩模滤波是一种边缘和细节增强技术, 主要是通过强调原始图像和模糊图像之间的对比度来突出边缘和细节。 这两种方法的融合有利于在保持图像细节的同时平滑图像, 在图像增强和降噪方面起到了显著的作用。 从最近邻差值开始, 计算4个最近邻差值, 用等式(3)表示。 通过差异检测保留图像的高频成分后, 利用等式(4)计算四个传导算子来衰减每个方向上的高频成分, 用等式(5)来调节平滑程度。 最后利用散度对整个图像进行平滑, 散度可以通过等式(6)计算得到。
其中, Ii, j是每次迭代时的平滑图像i, j是图像坐标。 ∇k分别表示检测到的东、 西、 北、 南数值的差异, gk为传导算子, f(i, j)为输入的图像, Z是一个控制平滑程度的标量(Z> 1), σ 为标准差, QI, J为最终迭代输出图像。
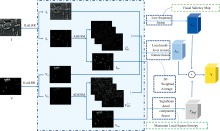
本文提出的融合方法框架如图2所示。 首先, 利用改进潜在低秩算法ILatLRR从红外图像I, 中提取低秩分量Ia和基本显著分量Ib, 从可见光图像V中提取低秩分量Va和基本显著分量Vb; 其次, 引入基于各向异性扩散的反锐化掩模滤波(anisotropic diffusion-based unsharp mask filter, ADUSM), 将基本显著分量Ib和Vb进行逐项差分运算, 分解为深层显著性细节分量和多层次细节特征分量
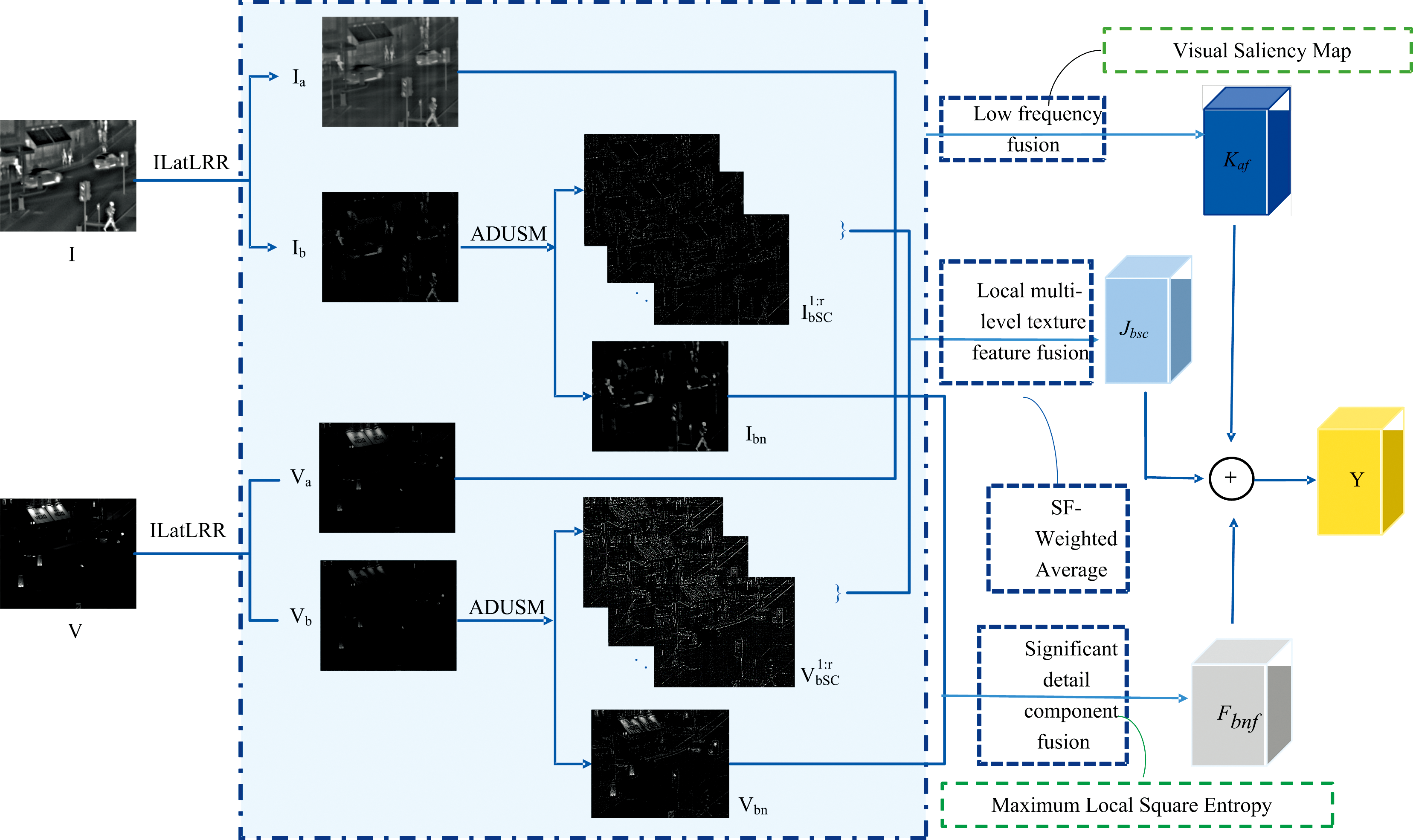 | 图2 算法框架Fig.2 Algorithm framework |
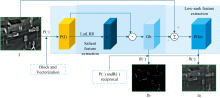
LatLRR只能提取显著特征分量, 而忽略主成分信息。 在此提出一种改进潜在低秩ILatLRR算法, 在显著性特征提取之前加入图像分块及向量化操作, 通过互逆图像重构操作对低秩信息提取, 最终在实现红外图像分解的同时保留主成分信息, 图3为ILatLRR分解框架。
 | 图3 ILatLRR分解框架Fig.3 ILatLRR decomposition framework |
在ILatRR分解结构中, Ia为红外光图的低秩部分, Ib为红外光图的基础显著性信息部分, 由式(7)和式(8)可得。 Gb为Ib图像的矩阵化操作, Ib=R(Gb), R(· )算子和P(· )算子互为逆操作, 且Gb=P(Ib)。 同样的, 可见光图像低秩部分和基础显著性信息部分提取步骤与上述相同。
各向异性扩散可去除图像噪声并平滑图像, 对图像局部进行亮度调整, 平滑图像中的噪声并保护图像的细节。 而非锐化掩模滤波是一种增强图像边缘和细节的方法, 主要通过提取原始图像与模糊版本之间的差异来增强图像边缘和细节, 二者结合起来不仅可保留源图像细节, 还可以对图像进行平滑处理, 对图像增强和去噪起到了很大的作用。
本算法通过将各向异性扩散和反非锐化掩模滤波结合对红外与可见光的基础显著性分量Ib和Vb进行深层次信息提取, 获得红外与可见光深层显著性细节分量Ibn和Vbn, 同时构造一种图像分解结构, 提取多级细节特征信息
2.3.1 低秩部分融合
传统平均融合规则无法最大程度地保留图像当中的低频信息[14]。 本方法采取视觉显著性图VSM的方式对低秩部分进行融合, 可将低频信息突显出来, 极大程度的保留了源图像的低频部分, 对任意图像S, 其像素Sp的视觉显著性图的过程可定义为式(12)。
式(12)中, N表示S的像素总数, K(p)为低秩分量, 规范化后取值在[0, 1]之间。 KIa(p)和Kva(p)分别表示为输入的红外图像和可见光图像的低秩分量, 利用式(12)计算可得到对应的图像视觉显著图, 而红外及可见光低秩分量Ia、 Va的融合结果可通过式(13)得到。
式(13)中, Kaf为低秩融合图像, Wb为权重, 且Wb=0.5+
2.3.2 多层次细节特征分量融合
经ADUSM分解后, 通过式(9)— 式(11)逐项差值完成对红外多层次细节特征分量
式(14)中: a, b, …, n分别表示第1, 2, …, r级经加权平均融合后的多层次细节特征
其中SF表示空间频率, 用于反映图像在空间域上的整体活跃度。 RF为空间行频率, CF为空间列频率。
2.3.3 深层显著性细节信息融合
深层显著性细节分量Ibn与Vbn采用局部平方熵最大法进行融合, Ibn与Vbn的局部平方熵系数可由式(19)和式(20)得到。
式中:
式(21)中:$F_{b}^{I}(x, y)$和$F_{b}^{V}(x, y)$为$I_{b n}$与$V_{b n}$在位置$(x, y)$处的活动度量系数。最终,深层显著性细节分量的融合$F_{b n f}$由式(22)完成。
2.3.4 图像重构
将低秩分量Kaf、 多层次细节特征分量JbSC和深层显著性细节分量Fbnf, 进行叠加得到最终融合图像Y, 具体如式(23)所示。
为了验证算法的可行性和有效性, 通过经典的数据集TNO[15]和公开数据集M3FD[16]进行验证, 图4为不同数据集上的源图示例。
 | 图4 两组数据集的源图像示例 (a): TNO数据集示例; (b): M3FD数据集示例Fig.4 Examples of source images of two datasets (a): Example image of TNO dataset; (b): Example image of M3FD datasets |
采用MATLAB R2021b, Windows10操作, CPUi5-11260H, 处理器NVIDIA GeForce MX250, 内存16 GB。 图像经过不同层次的分解, 会产生不同数量、 包含不同信息的基础层和细节层, 这将直接影响红外与可见光图像融合的结果。 因此, 对逐项差值的ADUSM分解层的最优层数的选取进行了实验, 具体如图5所示。
 | 图5 不同分解层次的实验结果Fig.5 Qualitative experimental results of different decomposition levels |
为便于观察, 绿色框区域为原始图像(黄色框区域)放大后的细节图。 随着分解层的增加, 图像的亮度有较为明显的提升, 更易观察图中的一些细节信息。 分解层L为2时产生的融合图像明显优于分解层L为1时, 当分解层L为3时图像融合图像在感官上有所提升, 当分解层L大于3后, 融合图像视觉感官上差距不会太大。
表1是不同分解层的定量实验结果。 随着分解层的增加, AG、 EN、 SD、 SF、 VIF指标的值逐渐增大再减少, 说明分解层次的增加在图像融合信息丰富性、 对比度、 视觉效果方面有一定的作用。 此外, 分解层L为1和3时, SCD指标均达到了最优值, 但对比L为1和3整体指标的优越性, L为1时, 只有SCD这一个指标的值优, 故综合考虑主客观评价, 将ADUSM的分解层L设置为3。
| 表1 不同分解层的定量评价指标 Table 1 Quantitative evaluation indexes for different decomposition layers |
为了评估融合性能, 选取了5种主流的融合方法进行定性比较, 包括Bayesian[17], Wavelet[18], LatLRR[19], MSVD[9]和MDLatLRR[20]。
图6(a)是不同算法在TNO数据集上的可视化结果。 为了更清楚对比, 选取图像中的关键区域(红色框区域)进行放大展示, 放大后图像为绿色框区域。 对比LatLRR和MDLatLRR两种算法, 这两种算法生成的图像色块亮度太大。 而本算法生成的图像在保留可见光源图的纹理特征方面表现得相对全面, 很大程度上消除了高亮色块带来的感官上的不适, 使得整个画面更加自然和舒适。 Bayesian方法生成的图像, 整体亮度是所有比较图像中最低的, 这种图形的细节信息几乎难以察觉。 而Wavelet、 MSVD图像遭受严重的红外背景干扰, 无法展示充足的纹理细节。 而本算法得益于图像分解和融合模块的改进与创新, 生成的融合图像具有清晰的显著性目标和丰富的纹理细节, 呈现出良好的视觉感知。
 | 图6 定性比较结果 (a): TNO数据集的定性比较结果; (b): M3FD数据集的定性比较结果 A: 可见光图; B: 红外光图; C: Bayesian; D: Wavelet; E: LatLRR; F: MSVD; G: MDLatLRR; H: OursFig.6 Qualitative comparison result (a): Qualitative comparison results for TNO dataset; (b): Qualitative comparison results for M3FD dataset A: Visible image; B: Infrared image; C: Bayesian; D: Wavelet; E: LatLRR; F: MSVD; G: MDLatLRR; H: Ours |
后在M3FD数据集上进行了泛化实验。 图6(b)是不同算法在M3FD数据集上的可视化结果。 为了更清楚对比, 选取图像中的关键区域(绿色框区域)进行放大展示, 放大后图像为橙色框区域。 容易看到, 上述对比算法在低光场景下生成的融合结果存在不同程度的细节弱化和图像显著性信息提取不全的问题。 如可见光图像中的打伞的人、 天线、 情侣等细节在融合图像中无法被清晰地展示, 红外图像中行人、 树木等热目标的强度和边缘信息在融合图像中出现明显退化。 相比之下, 本方法有效地集成了源图像中的纹理细节和显著性目标。
为了更客观地评价融合效果, 采用平均梯度(AG)、 熵(EN)、 差异相关性(SCD)、 标准差(SD)、 空间频率(SF)和视觉信息保真度(VIF)融合指标对上述方法的融合质量进行客观评价。
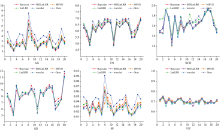
表2展示了TNO数据集可视化图6(a)中的4组经典图像的定量指标。 不难看出, 在IHR1、 IHR3和IHR4这三组数据中, 本算法在AG、 EN、 SCD和SF这四种评价指标上的表现均优于所对比的其他五种算法。 表3提供了TNO数据集上不同图像融合算法评价指标的平均值, 图7为TNO数据集指标折线图。 由各项指标可以看出, 本算法在这些定量评价指标上具有较好的结果。
| 表2 TNO中4组经典图像的定量比较结果 Table 2 Quantitative comparison results of 4 groups of classic images in TNO |
| 表3 TNO数据集融合图像的客观评价平均指标 Table 3 Average indexes of objective evaluation of fused images in TNO dataset |
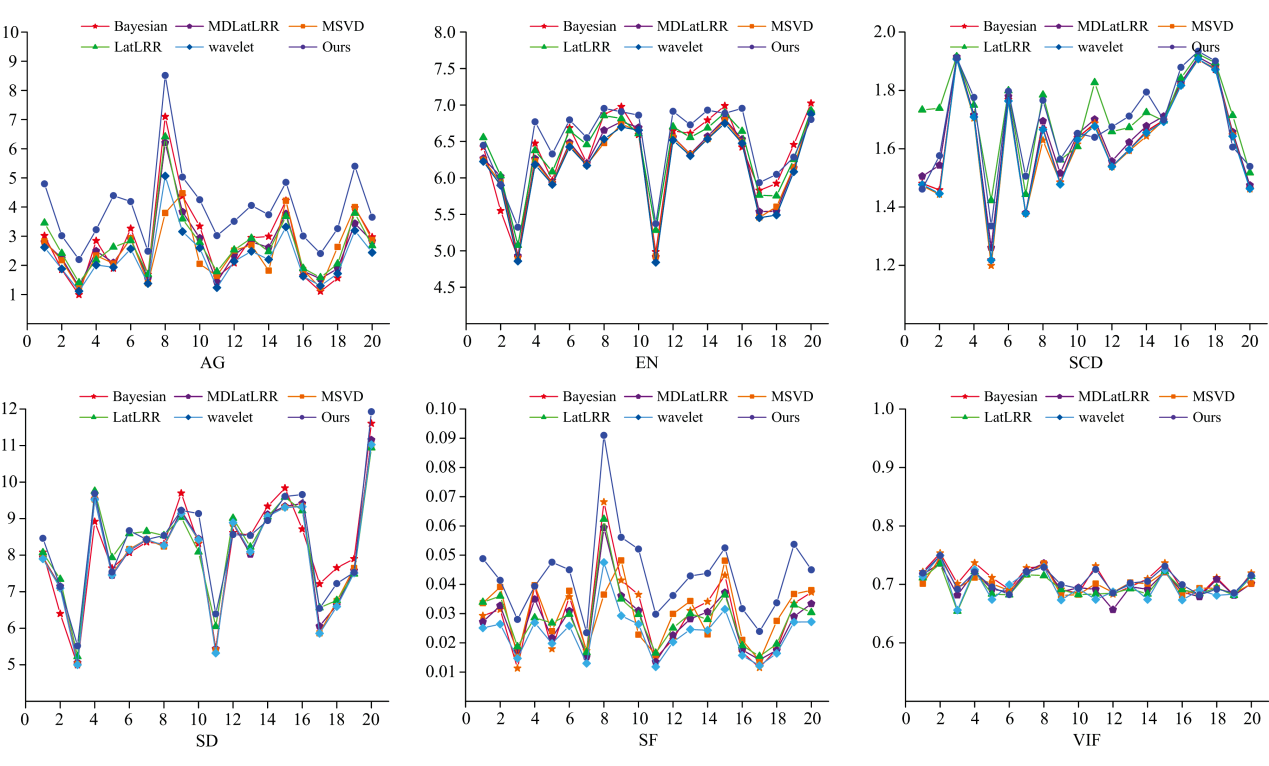 | 图7 TNO指标折线图Fig.7 TNO indicator line chart |
表4展示了M3FD数据集可视化图6(b)中的4组经典定量指标, 在IHR7和IHR8这二组数据中, 本算法在AG、 EN和VIF这3种评价指标上的表现均优于所对比的其他五种算法。 在IHR5和IHR6这两组数据中, 本算法在4种指标上均达到了最优值, 这表明生成的融合图像不仅从源图像中转移最多的信息, 且具有丰富的纹理细节和清晰的边缘特征, 能够应用于不同的场景, 泛化能力较强。 表5提供了M3FD数据集上不同图像融合算法评价指标的平均值, 图8为M3FD数据集上指标折线图。
| 表4 M3FD中4组经典图像的定量比较结果 Table 4 Quantitative comparison results of 4 groups of classic images in M3FD |
| 表5 M3FD数据集融合图像的客观评价平均指标 Table 5 Average indexes of objective evaluation of M3FD dataset fusion images |
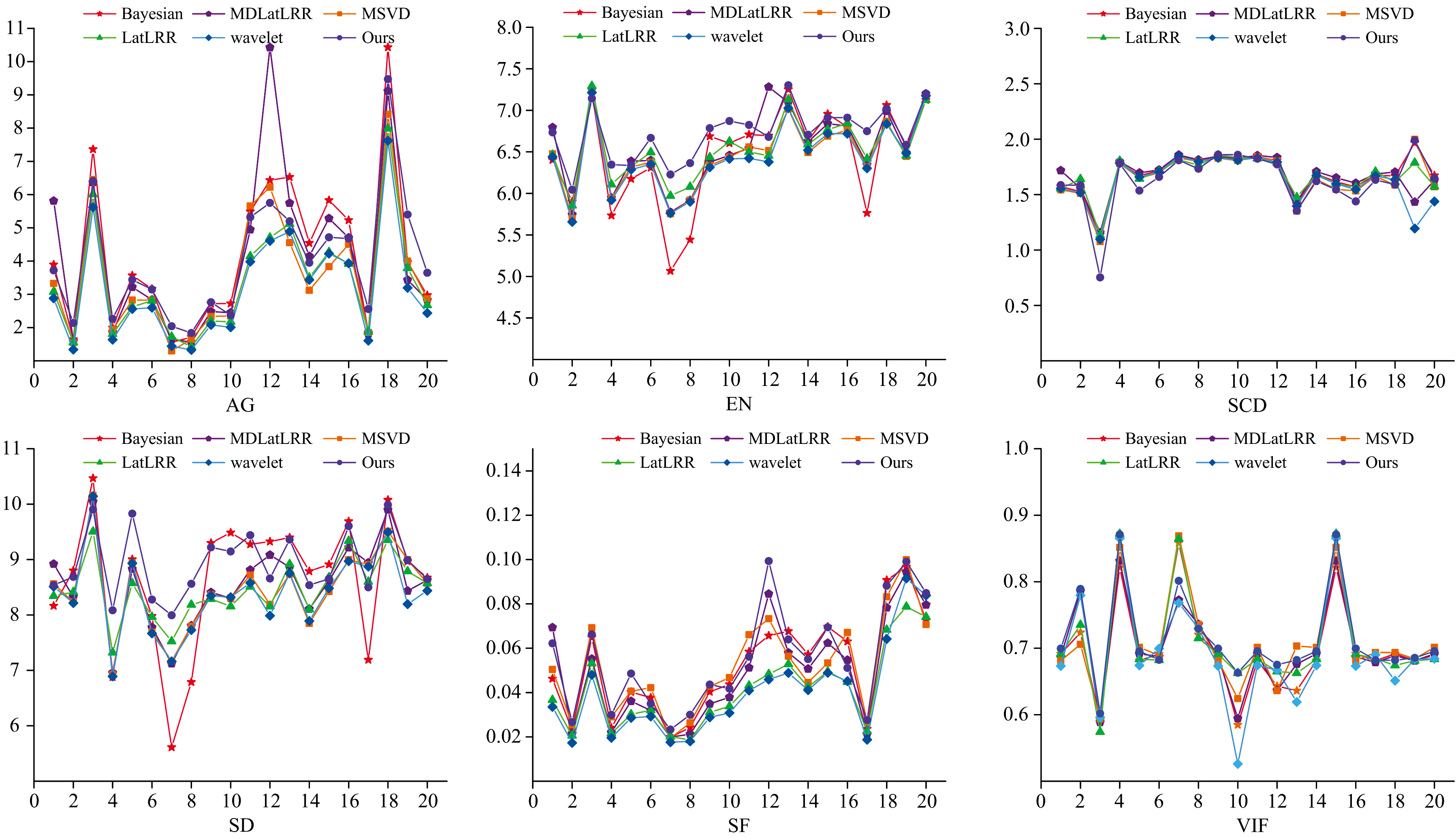 | 图8 M3FD指标折线图Fig.8 Line chart of M3FD index |
为了进一步评估方法的时效性, 在TNO和M3FD二个测试集上对比了不同方法的平均运行时间, 结果如表6所示。 本方法在平均运行时间上明显低于LatLRR、 Wavelet方法, 但略高于Bayesian、 MSVD和MDLatLRR方法, 综合考虑各种因素, 运行时间在允许范围内。
| 表6 在TNO数据集和M3FD数据集上的平均运行时间(单位: 秒) Table 6 Average time on the TNO and M3FD datasets(Unit: second) |
为验证所提模型的有效性, 分别对图像分解模块(模块A)、 局部平方熵最大法融合模块(模块B)、 空间频率最大的加权平均融合模块(模块C)进行消融实验。 为更清楚观察图像中细节, 选取图像中的关键区域(蓝色框区域)进行放大展示, 放大后区域为橙色框区域, 具体实验结果如图9所示。 没有模块A的stage1无法提供清晰的纹理细节; 没有模块B的stage2虽然结构相比于stage1清晰, 但还是未能在很大程度上保留源图形信息; 没有模块C的stage3热目标信息存在明显不足。 相比之下, 本文提出的stage4融合结果充分展示了清晰的目标信息和丰富的纹理细节。
 | 图9 消融实验定性比较结果Fig.9 Qualitative comparison of ablation experiments |
消融实验的定量比较结果如表7所示。 与stage4相比, stage1、 2、 3生成的融合图像在AG、 SCD、 SD、 SF、 VIF五个指标上均呈现不同的下降。 而在三个模块的协同作用下, stage4生成的融合图像在这五个指标上取得了最优的表现, 在EN上取得了次优表现。 综上, 消融实验的定性和定量比较结果均验证了本算法的有效性。
| 表7 TNO数据集和M3FD数据集40对图像上的消融实验定量比较结果 Table 7 Quantitative comparison of ablation experiments for 40 pairs of images between TNO dataset and M3FD dataset |
为提高在低光背景下红外与可见光图像融合图像质量, 提出改进潜在低秩和反锐化掩模的红外与可见光图像融合方法。 在融合前采用ILatLRR和ADUSM进行特征分解, 有效的保留了源图像的纹理细节特征。 在融合阶段, 利用视觉显著性图对低秩分量进行融合, 设计了一种基于空间频率最大的加权平均策略对多级细节特征进行融合, 增强了融合特征中关键信息的表达。 最后, 采用局部平方熵最大法对深层显著性细节进行融合, 确保显著性细节特征的有效集成。 改进潜在低秩和反锐化掩模的红外与可见光图像融合方法, 在AG、 EN、 SCD、 SD、 SF和VIF等客观评价指标上, 相比对比算法的整体均值分别提高了32.51%、 2.27%、 3.68%、 4.61%、 34.13%和1.53%。 实验结果充分证明了融合框架的优越性及模型的有效性。 在未来, 将深入研究融合任务与下游视觉任务的联动关系, 以推动融合技术在视觉领域的进一步应用与发展。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|