{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于注意力机制的BiGRU土壤光谱全氮预测模型研究
[剧伟良1  , 杨玮
, 杨玮1, 2 , 宋亚美1 , 刘楠1 , 李浩1 , 李民赞1, 2, * ]
, 杨玮]
|
|


作者简介: 剧伟良, 1996年生,中国农业大学智慧农业系统集成研究教育部重点实验室硕士研究生 e-mail: s20223081703@cau.edu.cn
土壤全氮含量是评估土壤肥力的关键指标, 其精确测定对于提升农作物产量和品质具有重要意义。 运用近红外光谱分析技术预测土壤全氮含量已被证明是一种有效的解决方案。 由于土壤光谱数据具有高维性和复杂的时间序列性, 传统模型往往难以捕捉其中的关键信息, 从而影响预测结果的准确性。 为此基于600份土壤样本的近红外光谱(900~1 700 nm), 开展了土壤全氮(STN)含量光谱预测方法研究, 提出了一种基于注意力机制的双向门控循环单元模型(BiGRU-Attention)。 首先通过SG滤波和SNV预处理方法优化了光谱数据, 随后通过CARS特征筛选算法将光谱的波长数由198精简为30个关键特征波长, 剔除冗余信息, 降低了建模的复杂度。 BiGRU-Attention模型利用更新门和重置门有效控制信息流动, 使得模型忽略不重要的光谱数据, 并保留影响预测精度的关键信息。 通过结合双向GRU的双时序处理优势, 模型能够同时处理光谱序列的正向与反向输入, 从而增强模型对边缘数据的关注能力, 更全面地捕捉土壤光谱数据中的前后依赖关系。 此外, 模型通过注意力层的QKV矩阵计算每个部分的重要性, 并根据序列中的前后关联信息动态决定关注哪些特征, 通过计算注意力权重矩阵, 为每个输入数据分配权重, 生成更相关的上下文矩阵, 进而增强模型的预测精度。 实验结果表明, 与其他模型相比, BiGRU-Attention模型能更好地理解波段之间的相互关联, 在预测结果上表现更佳, 光谱数据在经过特征筛选后, 模型在测试数据集上的决定系数 R2达到了0.87, 均方根误差RMSE为0.20 g·kg-1, 表现出良好的预测性能。 该研究为土壤养分快速检测提供了技术支持, 为建立高精度的土壤全氮含量预测模型提供了方法与参考。
Soil total nitrogen (STN) content is a key indicator for evaluating soil fertility, and its accurate measurement is of great significance for improving crop yield and quality. Predicting soil total nitrogen content using near-infrared spectroscopy has been proven to be an effective solution. However, due to the high dimensionality and complex time series characteristics of soil spectral data, traditional models often struggle to capture critical information, affecting prediction accuracy. Hence, based on near-infrared spectra (900~1 700 nm) of 600 soil samples, the method for predicting soil total nitrogen (STN) content was investigated,and a Bidirectional Gated Recurrent Unit based on an Attention Mechanism (BiGRU-Attention) model was proposed. First, the spectral data quality was optimized using SG filtering and SNV preprocessing methods. Then, using the CARS feature selection algorithm, the wavelengths for modeling were reduced from 198 to 30, thereby removing redundant information and decreasing the complexity of the modeling process. The BiGRU-Attention model effectively manages the flow of information using update and reset gates and enables the model to disregard the unimportant spectral data and retain the key information, which impacts the prediction accuracy. By leveraging the dual temporal sequence processing advantages of bidirectional GRU, the model can simultaneously handle forward and backward inputs of spectral sequences, thereby enhancing its ability to focus on edge data and comprehensively capture the dependencies present in soil spectral data. Additionally, the model employs an attention layer to compute the importance of each segment using the QKV matrix and dynamically determines which features should be emphasized based on the sequential interdependencies. This process calculates attention weight matrices to assign weights to each input data point, generating a more relevant context matrix that improves the model's predictive accuracy. Experimental results show that the BiGRU-Attention model can better understand the correlation between bands and perform better in prediction than other models, with the spectral data achieving an R2 of 0.87 and an RMSE of 0.20 g·kg-1 on the test dataset after feature selection. This study provides technical support for rapid soil nutrient detection and offers a method and reference for establishing high-accuracy STN prediction models.
土壤全氮(soil total nitrogen, STN)是重要的土壤肥力指标, 其含量对植物的生长有着十分重要的影响[1, 2, 3, 4], 增加氮素供给可以促使作物产量提升, 过量施用则会抑制作物的正常生长[5]。 因此, 准确获取土壤全氮含量对于田间施肥具有重要的指导意义[6, 7]。 近红外光谱技术具有快速、 无损、 无污染等特点, 目前已被用于土壤有机质、 土壤全氮等土壤养分方面的预测研究[8, 9]。 近红外光谱技术结合前沿的算法和模型有助于构建精确、 快速的定量或定性的分析模型, 运用模型实现对物质含量或性质的快速预测[10]。
国内外许多有关土壤养分近红外光谱模型的研究中, 广泛应用了各种机器学习算法[11, 12, 13], 其中, 深度学习在处理序列信息和高维特征方面表现出更高的敏感性[14, 15]。 循环神经网络(recurrent neural network, RNN)及其高级变种, 例如长短期记忆网络(long short-term memory networks, LSTM)和门控循环单元(gate recurrent unit, GRU), 在处理时间序列或具有序列结构特性的数据方面展示了卓越的性能[16, 17, 18]。 这类模型能够有效捕捉序列内的长距离依赖关系, 因此在自然语言处理、 时间序列分析等领域得到了广泛应用, 在土壤养分光谱预测研究另域也取得了初步成果。 白子金[19]等开展了干旱土壤无机碳含量的光谱预测研究, 结合多种特征筛选算法进行特征筛选, 并对比了一维卷积神经网络、 二维卷积神经网络与长短期记忆网络等模型, 结果显示, 区间随机蛙跳算法结合长短期记忆网络组合模型的预测精度最高, 决定系数R2=0.93, 该研究表明深度学习结合变量筛选可以快速准确的实现土壤无机碳的定量预测。 王煜[20]等在对中国南疆土壤有机碳含量进行预测时, 采集了可见光与近红外光谱, 使用区间随机蛙跳算法等8种特征筛选算法进行特征筛选, 并对比了长短期记忆网络, 门控循环单元, 卷积神经网络等多种深度学习模型以及随机森林模型, 进行模型预测潜力的评估, 结果显示结合了特征筛选算法的长短期记忆网络取得了最好的预测效果, 为土壤光谱预测有机质提供了理论和技术指导。
在现有研究中, RNN模型由于存在梯度爆炸与梯度消失的问题, 在处理序列任务时效果较差。 LSTM模型虽然有较好的预测效果, 但相较于传统RNN模型, 增加了更多的门控结构, 在每个时间步都需要更多的计算, 使得LSTM模型在训练时的计算复杂度和时间成本较高; GRU模型相较于LSTM结构更简洁, 训练速度更快, 计算效率更高。 由于现有研究提出的时序模型GRU的信息流是单向的, 导致光谱序列中较早输入模型的光谱数据权重变得较小。 为了克服这个限制, 增加对序列中早期输入数据的关注, 本研究使用双向GRU机制(BiGRU)以更充分地获取光谱序列两端的信息。 BiGRU通过结合序列的前向和后向信息流, 增强模型对序列数据中长期依赖关系的捕捉能力, 使得模型拥有了更全面的光谱数据视角。 在土壤全氮模型预测任务中, 不同波长范围的反射率受全氮含量的影响程度不同, 波段之间存在着较多冗余信息, GRU模型在处理这些数据时可能难以识别关键特征的重要性, 为了解决这一问题, 应当考虑使用注意力机制来增强模型对关键信息的识别能力, 从而提升土壤全氮预测的准确性和效率。 本研究通过引入注意力机制, 对土壤光谱数据中的关键信息进行动态加权聚焦, 为不同波长的特征动态分配权重, 优先关注那些对预测全氮含量最重要的波长, 并减少冗余信息的干扰, 使模型能够重点关注关键的光谱特征, 进一步地提升模型的预测精度。
基于上庄实验站采集的600份土壤样本, 通过微型光谱仪与杜马斯定氮仪对样本的光谱反射率信息与全氮含量进行了系统采集。 通过应用光谱预处理和与CARS特征筛选方法, 进一步筛选出对预测任务具有较高相关性的光谱特征。 在此基础上, 提出注意力机制的双向门控循环单元模型(bidirectional gated recurrent unit based on attention mechanism, BiGRU-Attention)模型, 融合了双向GRU网络的综合信息处理能力和注意力机制的聚焦优势, 能有效捕捉土壤光谱数据中的复杂模式, 在精准识别关键特征方面表现良好, 为田间土壤氮素的精准预测提供了坚实的理论依据与技术支持。
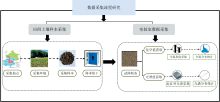
数据采集分为田间土壤样本采集与实验室数据采集, 采集流程如图1所示。
 | 图1 土壤样本数据采集流程示意图Fig.1 Schematic diagram of data collection process for soil sample |
1.1.1 土壤样本的采集与处理
试验点位于中国农业大学上庄实验站的玉米田(40.141 1° N, 116.189 4° E)长71 m, 宽24 m。 在试验田使用尿素进行梯度施肥, 划分3个区域分别进行不施肥、 半量施肥、 标准量施肥处理。 变量施肥七天后在试验田三个区域内横向每间隔1.5 m, 纵向每间隔1.5 m, 在作物主要根区的表层5~10 cm进行样本采集。 每区域采集200份, 共采集600份土壤样本, 在实验室环境下, 剔除样本中较大的颗粒与杂质, 分别放入塑料杯中编号, 将处理好的土壤样本放入烘箱中, 在控制的温度下(105 ℃)烘干至恒重。 为了支持后续田间设备的开发, 对烘干后的土壤样本进行了0.9 mm筛网过筛处理, 保留适中的颗粒度, 为后续光谱数据采集和定氮分析提供更加贴近田间实际的基础数据。
1.1.2 土壤近红外光谱的采集与预处理
使用深圳谱研互联科技有限公司的便携式光谱仪NIR-R210光谱仪采集光谱数据, 光谱波段范围为900~1 700 nm, 内置2.5 W卤素光源, 光学分辨率为10 nm, 全光谱的波长数为228(平均采样间隔约3.524 nm)。 与传统且配置复杂的分光光度计相比, NIR-R210仪器在光谱扫描精度上有一定降低, 但其提供了一种成本效益高、 空间体积小、 易于携带和集成的解决方案, 这使得后续在田间对土壤进行快速而准确的光谱分析成为可能。 考虑到光谱仪在900~950及1 650~1 700 nm的检测边缘范围信噪比较低, 试验数据仅保留波段为950~1 650 nm的数据(共198个波长)。
1.1.3 土壤全氮含量的测定
采用杜马斯定氮仪(荷兰SKALAR公司)测量样品全氮含量。 将处理好的土样称量0.5 g, 放入小坩埚中, 送入定氮仪的样品放置窗口进行燃烧测定, 使用SKALAR配套软件进行数据处理, 获取样本的对应全氮含量。
由于土壤样本采集的光谱数据量过大, 冗余信息较多, 因此需要引入特征筛选算法对数据进行降维, 减小建模所需的计算量和复杂度。 竞争自适应重加权算法(competitive adaptive reweighting sampling, CARS)是一种用于化学计量学和光谱分析的特征选择方法, 适合处理高维数据集并构建预测模型。 该算法从光谱数据中随机选取初始变量集来构建基础模型, 随后通过一个动态优化过程, 自适应地调整各个波长的权重。 在这个过程中, 算法评估每个波长对模型性能的贡献, 并据此调整其权重, 逐步过滤并突出那些对预测准确性更关键的波长。 该方法能够精确地识别并保留对提高模型预测性能至关重要的特征, 从而在复杂的数据环境中实现更为精确和可靠的分析结果。
算法初始化包括设定迭代次数为50次, PLSR模型的成分数为8, 和交叉验证的折数为10。 每次迭代将从特征集合中以指数衰减的方式减少特征数量, 初始保留特征数设定为数据特征总数的80%。 在每次迭代中, 基于特征对模型性能的贡献, 动态调整其权重。 在达到设定的迭代次数后, 使用迭代过程中RMSE最小的迭代结果作为最终筛选结果。
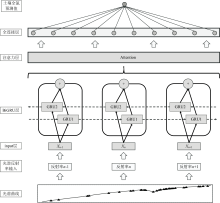
1.3.1 模型总体架构
在构建用于土壤全氮预测的模型时, 采用了基于注意力机制的双向门控循环单元(BiGRU-Attention)网络, 模型结构如图2所示。 土壤的光谱数据作为输入, 全氮预测值作为输出, 该模型利用两层双向GRU网络深入处理光谱序列信息, 有效捕获光谱数据中的前后文依赖关系, 并生成一系列隐状态向量。 这些向量经过拼接和整合, 形成一个综合的全局特征表示。 并进一步被送入一个精心设计的注意力层, 此层专注于评估并计算各向量中不同位置的重要性权重, 进而精准挑选出对预测任务至关重要的特征。 通过注意力层加工后的数据被展开为一维向量, 随后输入到一个全连接层网络, 进一步处理和分析数据, 最终输出对土壤全氮真值的精确预测。 通过集成BiGRU和注意力机制, 此模型结构不仅充分利用了光谱数据的前后关联信息, 还显著增强了模型对关键光谱特征的识别和处理能力, 从而显著提高了预测全氮含量的准确性和效率。
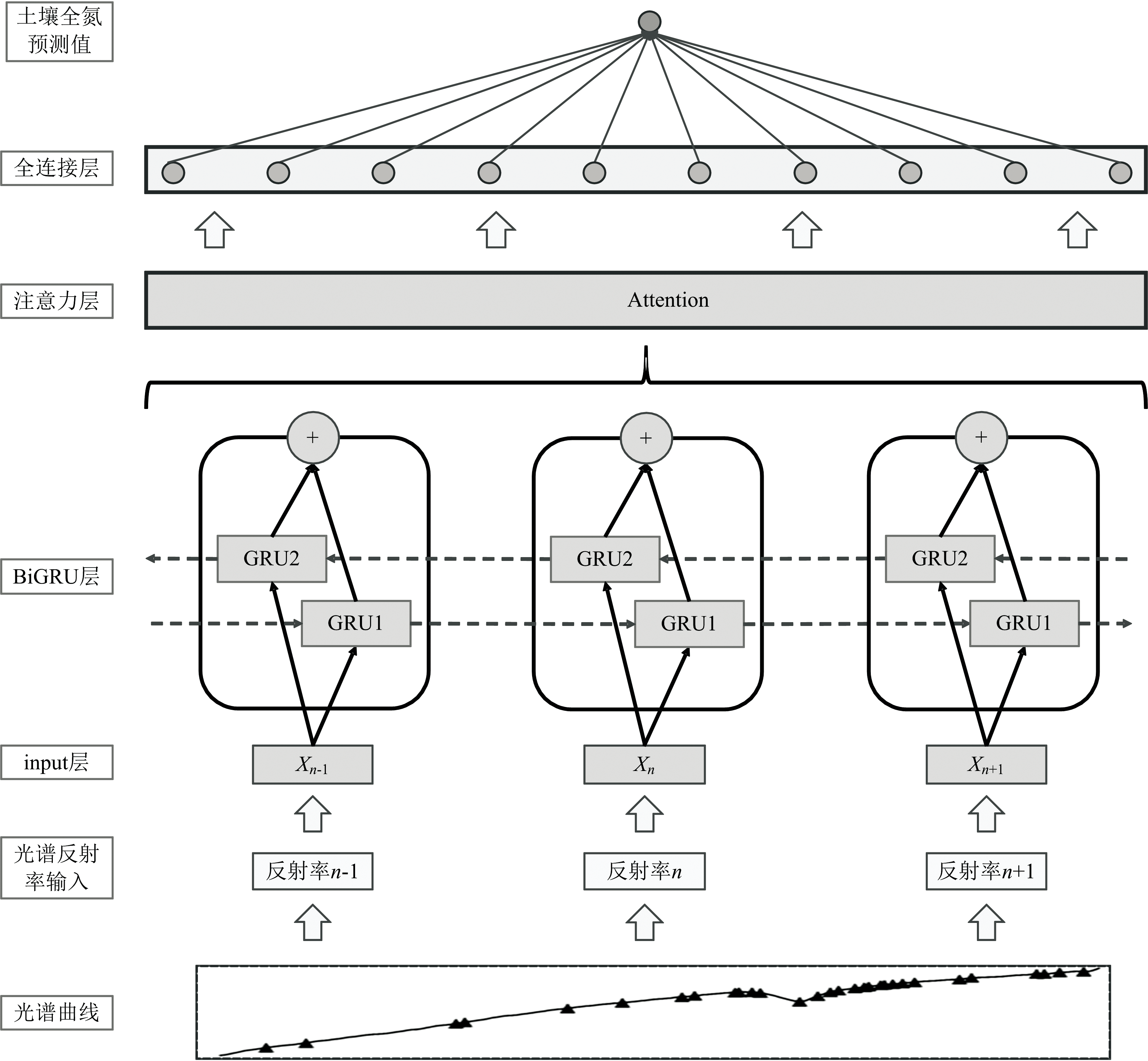 | 图2 基于注意力机制的双向门控循环单元(BiGRU-Attention)模型Fig.2 Bidirectional gated recurrent unit (BiGRU) model with attention mechanism |
1.3.2 双向门控循环单元模型构建
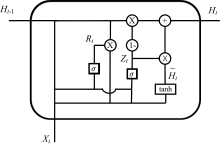
门控循环单元(GRU)是一种用于序列数据处理的神经网络结构, 它是循环神经网络(RNN)的一种变体, 目的是在处理长序列数据时, 面临的梯度消失或梯度爆炸问题。 GRU内部结构如图3所示, 它包含两个关键的门控机制, 即更新门和重置门。 在处理光谱数据时, 重置门的作用是决定是否需要“ 忘记” 或者忽略上一时刻的隐状态, 如在光谱反射率输入GRU门的过程中, 有一些并不重要的光谱数据进入了模型中, 在输出的隐向量中占据了不必要的位置, 那么可以使用重置门来帮助模型忽略这些信息, 重置门输出的值越接近0, 在计算候选隐状态时忽略的这些不必要的信息就越多; 更新门的作用是控制在每个时间步骤中保留多少之前的信息, 对于光谱数据来说, 如果序列点的光谱信息对某个化学成分的浓度(全氮含量)有重大影响, 更新门的使用会确保这些重要的历史信息被保留, 使模型能够综合这些数据进行更准确的预测, 更新门的输出值越接近1, 在计算当前时刻的隐状态时, 保留的上一时刻的信息就越多。
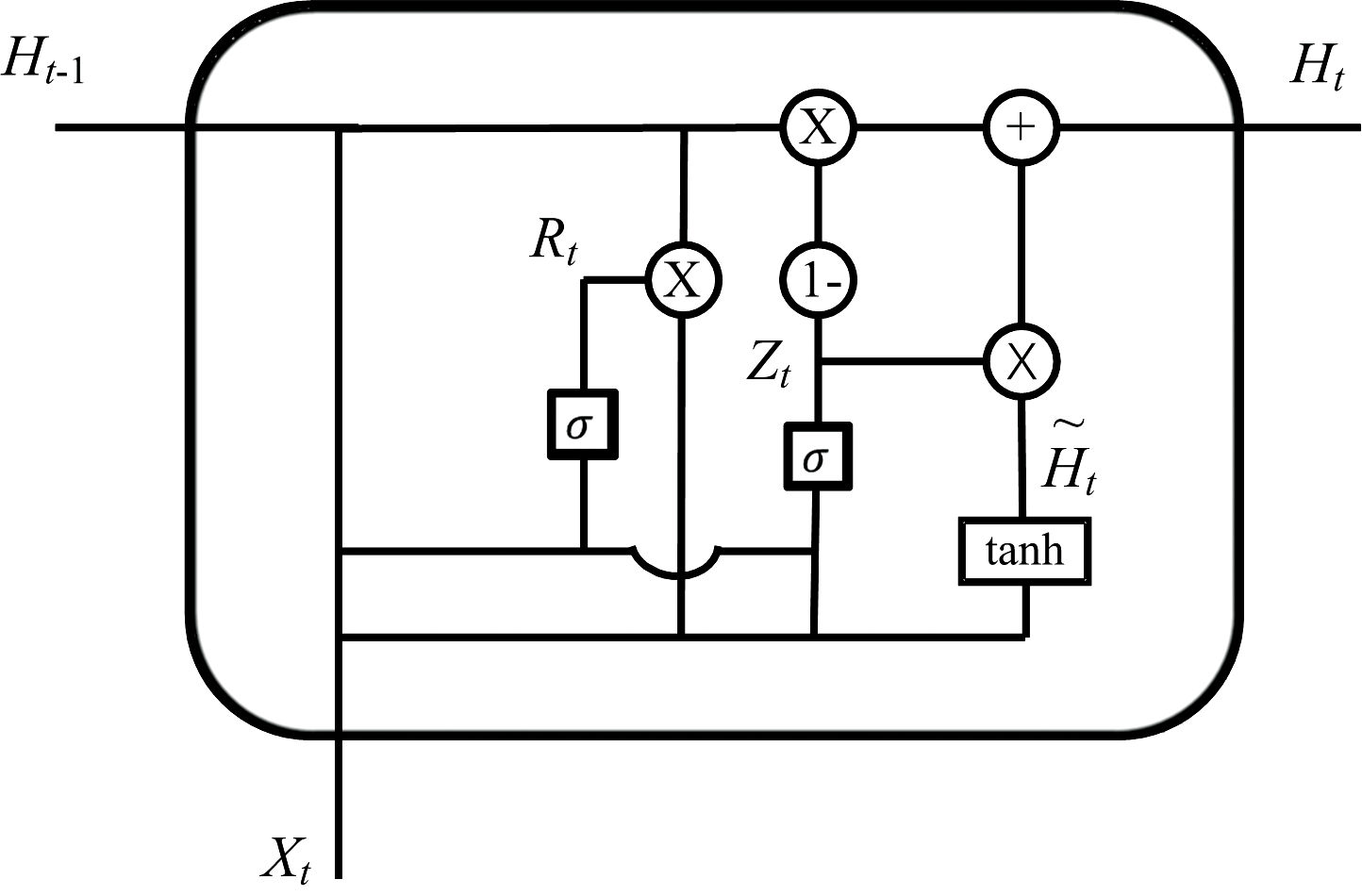 | 图3 GRU结构示意图Fig.3 Schematic diagram of GRU structure |
GRU主要数学公式如式(1)— 式(4)
其中, Rt为重置门, σ 为sigmod函数, Xt为当前输入, Wxr, Whr, br为重置门的权重矩阵和偏置参数, Ht-1为上一时刻隐藏状态; Zt为更新门, Wxz, Whz, bz为重置门的权重矩阵和偏置参数;
在门控循环单元的基础上进一步采用了双向门控循环单元(BiGRU)作为模型架构, 捕获序列数据中蕴含的时间依赖性及其双向上下文信息。 这一结构内包含两个GRU子层: 一个负责解析正向序列信息(从开始到结束的顺序), 另一个则处理反向序列信息(即从序列结束到开始的逆序), 将两个子层的输出结合为新向量, 这个新向量代表了光谱数据的高级抽象, 捕捉了输入数据中的关键特征。 BiGRU通过结合正向和反向两个GRU层, 能够深入学习并理解序列数据的前后信息, 显著增强模型对序列特征的把握和分析能力。
1.3.3 注意力机制引入
尽管BiGRU通过同时考虑过去和未来的信息以增强特征提取的能力, 但它仍有局限性, 特别是在处理长序列时, 即使模型能够从两个方向获取信息也依然面临信息稀释的问题, 与序列端口相距较远的信息可能难以对最终的输出产生显著影响。 通过引入注意力机制, 可以有效地弥补这一缺陷。
注意力机制通过对模型输入数据的不同部分动态分配权重, 有效地集中处理对当前任务至关重要的信息。 这种机制借鉴了人类的注意力聚焦行为, 在一定程度上提高了模型在处理大规模数据和复杂数据时的效率和准确性。 通过识别数据中的关键特征, 动态调整每个特征的重要性权重, 使模型更专注于对预测结果影响更大的信息, 使模型能够更准确地进行预测和决策。 在许多应用场景中[22, 23, 24, 25, 26], 注意力机制都表现出了卓越的灵活性和面对复杂数据的处理能力, 这种技术已逐渐成为推动深度学习发展的关键技术之一。
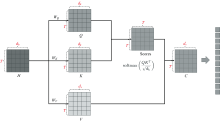
注意力机制模型如图4所示, 最左侧为隐向量矩阵H(由双向GRU的隐向量拼接而成), 通过可训练的权重矩阵WQ、 WK、 WV, 分别生成Query(查询)、 Key (键)和 Value(值)矩阵, Q矩阵与K矩阵计算匹配得分, 获得Scores矩阵, 此矩阵经过进一步的缩放与归一化处理, 获得权重矩阵W。 W矩阵与V矩阵做加权输出(W× V), 生成最右侧的上下文向量矩阵C。 这个输出矩阵综合了光谱输入信息且调整了数据不同位置的权重, 是注意力机制对输入数据的响应和解释, 通过这个矩阵, 模型动态地调整了数据处理的焦点, 优化信息的提取和利用。 该矩阵在模型中会进一步展平为一维, 并输入全连接层。
 | 图4 注意力(Attention)机制模型Fig.4 Attention mechanism model |
将600份样本按照80%和20%的比例随机分成训练集和测试集, 分别包含480份和120份样本。 模型首先在训练集上进行学习和调优, 随后使用独立的测试集来验证其预测性能, 确保评估结果能真实反映模型在未见数据上的表现。 在基于GRU的模型训练中, 对模型的超参数进行设置, 基于总样本量, 将模型批量大小设置为32, 为保证模型有效捕捉时序数据中的关键特征, 隐藏维度100(GRU中, 隐向量长度为100, BiGRU中, 隐向量长度为200), 使用Adam优化器进行梯度更新, 并将学习率设置为默认的0.001, 为保证模型充分训练并避免陷入过拟合, 最大训练迭代次数设置为300次。 该模型使用pytorch预测框架, 使用Nvidia GeForce RTX 3060 GPU进行计算与训练。
为了全面评估本研究提出的基于GRU的模型的性能, 选择了机器学习中的偏最小二乘回归(PLSR)作为参考模型。
通过将不同的GRU模型与PLSR模型进行比较, 来验证深度学习方法在处理复杂光谱数据时相对于传统机器学习方法的潜在优势。 评判指标为决定系数R2与均方根误差RMSE。 两个指标的计算公式如式(5)和式(6)所示。
对采集结果进行统计, 结果如表1所示。
| 表1 土壤TN含量成分统计摘要(g· kg-1) Table 1 Summary statistics of soil TN content (g· kg-1) |
分析显示, 土壤样本的全氮含量范围较广, 区间为0.96~2.98 g· kg-1。 平均全氮含量为1.84 g· kg-1, 标准差为0.54 g· kg-1, 结果表明样本间存在一定的差异性, 可以保证数据集的多样性和一致性, 对于后续的模型建模和训练十分有利。
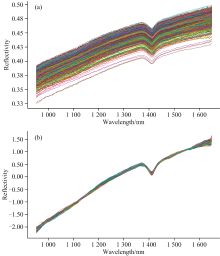
由于仪器自身性能限制以及外界环境噪声等因素, 所测光谱数据呈现锯齿状波动、 基线漂移等现象, 因此需要对光谱进行进一步预处理以改善其质量和可用性。 常用的预处理方法有Savitzky-Golay滤波(Savitzky-Golay filter, SG)和标准正态变量转换(standard normal variate, SNV)。 对NIR-R210的输出数据实施了SG和SNV的联合预处理。
经测试选择了3次多项式和大小为7的窗口来执行SG滤波, 优化了信号的平滑程度而不损失过多的细节信息。 接着, 为了进一步改善数据的质量并减少光谱仪结构带来的光散射效应, 使用了SNV做进一步处理。 通过对每个光谱进行标准化, 消除了路径长度差异和颗粒大小差异等因素引起的光谱变异, 从而使来自不同样本的光谱具有可比性。 经验证, 上述步骤对于提高分析结果的准确性和可重复性至关重要。
光谱预处理结果如图5所示。 预处理后的数据展示了更低的基线波动和更高的信噪比, 使得光谱数据更适合进行复杂成分的定量和定性分析。 此外, 预处理步骤的应用也为评估和比较不同样本之间的光谱差异提供了坚实的基础。
 | 图5 土壤样本光谱原始曲线与预处理结果 (a): 土壤样本原始光谱曲线; (b):土壤样本经过预处理的光谱曲线Fig.5 Original spectral curve and pretreatment results of soil samples (a): Original spectra of soil samples; (b): Spectra of soil samples after pretreatment |
CARS特征波长筛选算法在处理高维光谱数据中显示出卓越能力。 CARS算法通过自适应地调整特征的权重, 并逐步移除对模型贡献较小的特征, 从而聚焦于最具信息量的特征。 通过减少不必要的特征, CARS算法减轻了计算负担, 并提高了数据处理的速度。 此外, CARS算法提升了模型的解释性。 在光谱分析中, 能够清晰地识别和解释影响预测结果的关键特征是至关重要的。 通过CARS算法筛选出的特征, 不仅使模型变得更加精简, 而且使得模型的决策过程更加透明和可解释。
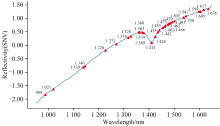
经过CARS算法处理后, 样本光谱的波长数由198个降低到30个特征波长, 特征波段主要集中在1 350~1 650 nm波段范围内, 全部特征波长分别是989, 1 021, 1 139, 1 146, 1 228, 1 271, 1 318, 1 328, 1 360, 1 363, 1 374, 1 380, 1 411, 1 426, 1 435, 1 442, 1 455, 1 463, 1 466, 1 475, 1 479, 1 485, 1 493, 1 502, 1 538, 1 547, 1 599, 1 605, 1 617和1 636 nm。 筛选后的特征波长标注如图6所示。
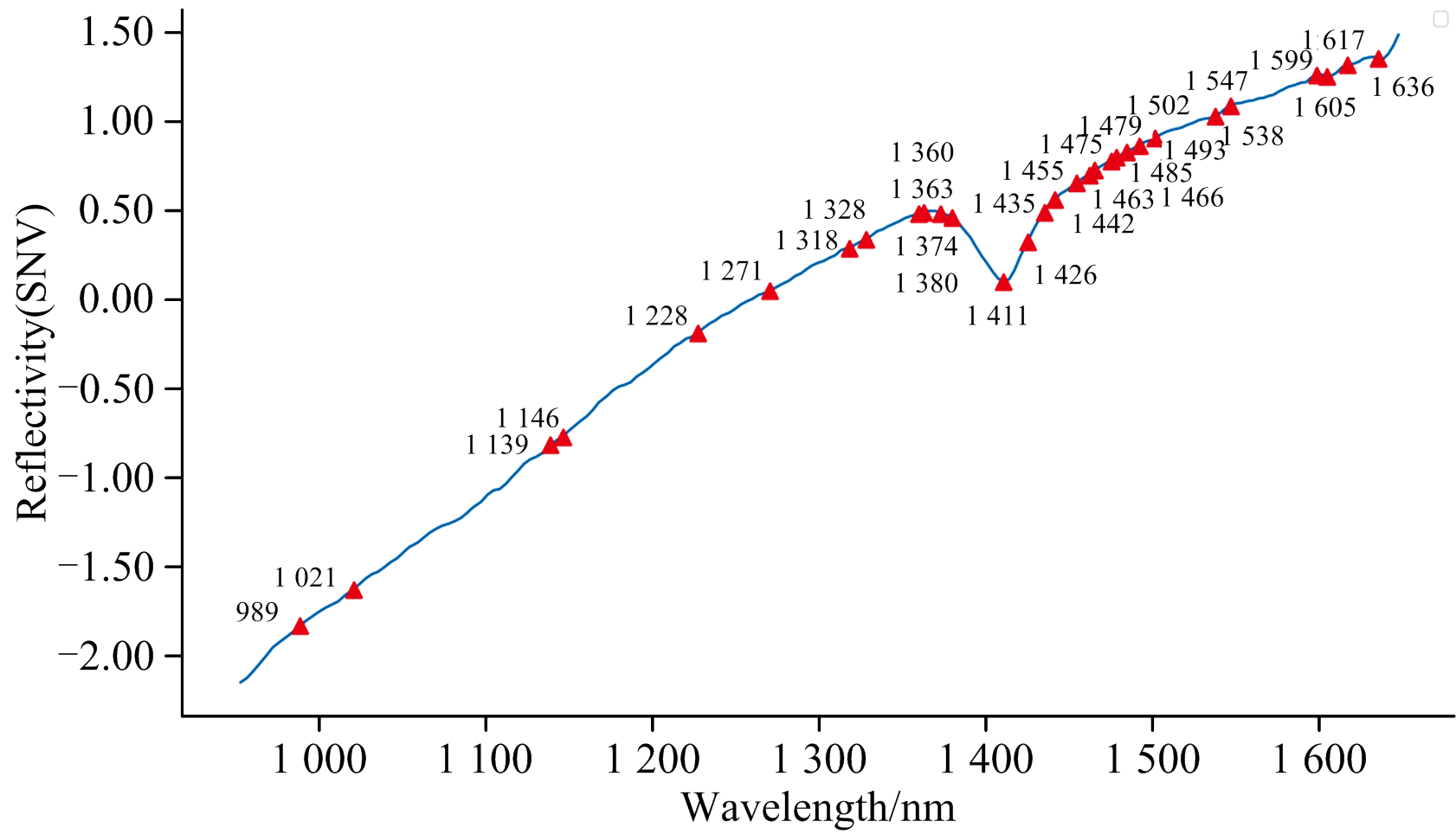 | 图6 特征波长标注Fig.6 Characteristic wavelength labeling |
查阅相关论文[27, 28], 1 420~1 569 nm为土壤中的主要含氮官能团(N— H、 C— N、 N— N)在近红外光谱区的特征吸收波段, 该波段土壤样本反射率与土壤全氮含量有着密切联系。 1 500 nm附近为N— H官能团的一级倍频区域, 该波段附近存在较多特征波。 这些官能团的存在使得即便是微小的化学成分差异也能在近红外光谱中转化为相对明显的光强变化, 从而让这些细微差别更容易被检测, 使得土壤中全氮含量的精确量化变得可行。
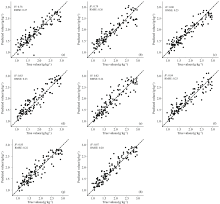
使用经过CARS筛选的数据集, 建立了基于注意力机制的双向门控循环单元模型(BiGRU-Attention), 并与全谱数据集(未特征筛选)进行对比。 同时为了对比BiGRU-Attention的效果, 针对经过CARS筛选的数据集和全谱数据集, 也建立其他3种模型作为对比: 偏最小二乘回归模型(PLSR)、 门控循环单元模型(GRU)和双向门控循环单元模型(BiGRU)。 建模结果对比如图7所示, 模型的预测结果如表2所示。 BiGRU-Attention模型的R2最高, RMSE也最小。
 | 图7 建模结果对比图 (a): 全谱-PLSR模型; (b): 全谱-GRU模型; (c): 全谱-BiGRU模型; (d): 全谱-BiGRU-Attention; (e): CARS-PLSR模型; (f): CARS-GRU模型; (g): CARS-BiGRU模型; (h): CARS-BiGRU-AttentionFig.7 Comparison of modeling results (a): Full-spectrum PLSR model; (b): Full-spectrum GRU model; (c): Full-spectrum BiGRU model; (d): Full-spectrum BiGRU-Attention model; (e): CARS-PLSR model; (f): CARS-GRU model; (g): CARS-BiGRU model; (h): CARS-BiGRU-Attention model |
| 表2 模型表现统计表 Table 2 Statistical table of model performance |
GRU模型重置门Rt的功能是决定在形成当前时刻的候选隐藏状态时, 上一时刻的隐藏状态Ht-1应保留多少信息, 这一机制对于光谱数据分析尤为重要, 因为它允许模型根据当前输入的重要性动态调整对历史光谱数据的依赖, 从而在预测土壤全氮含量时忽略那些不重要的过去光谱特征。 更新门Zt帮助模型决定在当前隐藏状态的形成中应维持多少之前的状态与增添多少新的光谱信息, 使模型能够及时更新其内部状态以反映最新的光谱输入。
BiGRU模型预测效果相较于GRU模型有进一步的提升, 这是因为双向门控循环单元模型通过同时利用过去和未来的信息来增强模型对时间序列(光谱反射率)数据的理解能力。 传统的单向门控循环单元模型仅从序列的开始到结束处理光谱数据, 在长序列中, 较早的光谱数据的影响力可能会在序列的后续处理中被逐渐“ 遗忘” , 这限制了模型捕捉长期依赖关系。 相比GRU模型, BiGRU模型设有两个独立的单元顺序: 一个正向单元从时间序列的起始端到结束端学习信息, 另一个反向单元则从时间序列的结束端到起始端学习信息。 这两个方向的信息在每个时间步上被合成, 使得每个数据点的分析都能利用到其前后文(光谱数据)的完整信息。 相比于单向门控循环单元模型, 双向的网络提供了更全面的数据解析能力, 取得了更好的预测效果, 这种双向处理进一步地提高了模型对边缘光谱数据点的关注, 更容易捕捉到输入的光谱数据中的长期非线性关系, 提升了预测的准确性和模型的泛化能力。
进一步地, 在基于注意力机制的双向门控循环单元模型(BiGRU-Attention)中, 每一个时间步的输出隐向量都作为注意力机制的输入。 这种设计相比于之前的BiGRU模型, 更全面地捕捉了光谱序列中各个时间步之间的依赖关系, 从而增强模型对重要特征的关注, 提高模型对关键信息的感知能力和整体预测的准确性。 通过查询(Q)、 键(K)、 值(V)矩阵, 注意力机制可以计算光谱序列中每个部分的重要性, 自适应地调整关注点, 这一机制非常适用于处理BiGRU模型所输出的多个隐向量, 发掘那些相隔较远的隐向量之间的重要联系。 通过引入QKV矩阵, 输出向量不再仅仅是原始隐向量的简单映射, 而是根据整个序列的上下文重新编码的结果, 这使得每个输出向量都在某种程度上反映了整个光谱序列的内容, 从而提供了一个更加全面的数据表示, 提升了模型对远距离关系的理解和处理能力。
相较于传统的机器学习模型以及LSTM、 GRU模型, BiGRU-Attention模型虽然增加了模型的复杂程度与计算开销, 添加了额外的模块, 并对样本的数据量提出了较高的要求, 但通过双向机制, 该模型提高了对边缘光谱数据的关注, 更容易捕捉输入到模型的长期非线性关系, 使得模型能够更全面地把握输入数据的时序依赖, 通过引入注意力机制, 模型可以基于整个序列的光谱数据进行计算, 发掘相隔较远的光谱数据之间的重要关联, 模型不仅关注局部的特征, 还能通过全局信息的关联性来改善预测效果, 为精准施肥提供科学依据。 进一步与微型光谱仪, 树莓派等便携式计算平台结合, 可以开发出高效、 实时的田间土壤养分检测系统, 结合农业传感器, 无人机, 卫星遥感等技术, 实现智能变量施肥, 最终提升农业生产的整体智能化水平。
此外, 当前研究未能充分考虑土壤有机质与pH值等因素对模型精度的影响, 且未采集不同区域, 不同类型与不同深度的土壤样本, 为进一步提高模型的适应性与精度, 在未来研究中应加强对这些因素的分析, 为模型提供更全面的数据支持, 提升其对不同特性的土壤的预测能力。
本研究以北京市上庄实验站土壤样本为研究对象, 对600份土壤样本的近红外波段的光谱进行分析, 采用了偏最小二乘回归模型、 门控循环单元模型、 双向门控循环单元模型和基于注意力机制的双向门控循环单元模型, 对土壤全氮含量进行了预测, 分析了特征筛选结合不同建模算法在预测土壤全氮含量任务中预测精度的差异性。 主要结论如下:
(1)通过结合使用SG滤波和SNV预处理, 相较于原始数据, 经过预处理的光谱数据更加的平滑和一致。 这种处理方式有效地减少了随机噪声和基线漂移, 增强了光谱信号的可信度, 使得重要的光谱特征更明显, 这对后续的特征筛选工作提供了更好的条件。
(2)通过CARS特征筛选算法, 将光谱的198个波长成功降低到30个特征波长, 使光谱波长输入量仅为原来的15%, 这种处理极大减轻了模型的复杂度和负载, 并取得了更好的预测精度。
(3)本研究提出的基于注意力机制的双向门控循环单元模型(BiGRU-Attention)在与其他模型对比时, 通过其双向接收数据的机制与注意力机制对关键特征的加权处理, 拥有更强的信息捕捉能力, 在测试集中R2为0.87, RMSE为0.20 g· kg-1, 取得了最优的预测效果, 展现了其在土壤全氮含量预测中的强大潜力, 为土壤全氮含量预测建模提供了一种新的研究思路。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|