{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
绝缘子污秽高光谱检测的特征波长筛选方法比较
[李加加1  , 王相峰
, 王相峰1 , 黄飞林1 , 刘勇1 , 姚轩2 , 杨辉2 , 程宏波2, * ]
, 王相峰]
|
|


作者简介: 李加加, 1987年生,中铁电气化铁路运营管理有限公司工程师 e-mail: 550941565@qq.com
表面污秽会影响绝缘子的绝缘性能, 给电力系统带来危害。 现行检测方法需要停电取样, 操作繁琐且费时费力, 高光谱分析可以实现非接触式不停电检测, 在绝缘子污秽检测中具有较好的应用潜力。 为降低绝缘子表面污秽高光谱检测的数据处理量, 提高绝缘子高光谱数据分类识别的准确率, 依据现行人工试验样本制备标准, 制作了盐密度0.22 mg·cm-2、 灰密度0.1 mg·cm-2和盐密度0.3 mg·cm-2、 灰密度0.1 mg·cm-2的两种不同污秽等级的绝缘子人工污秽样本各3个。 对不同污秽等级的绝缘子样本进行高光谱采样, 在每个样品上选取15个区域提取区域光谱数据, 共得到90组光谱数据, 选取训练集样本63个, 测试集样本27个。 利用竞争性自适应重加权算法(CARS)、 连续投影算法(SPA)、 无信息变量消除法(UVE)对绝缘子高光谱数据的特征波长进行筛选, 搭建支持向量机分类模型, 利用多元散射校正(MSC)、 标准正态变化(SNV)、 一阶导数、 去卷积法、 移动平均滤波、 基线校正、 归一化、 小波变换方法对光谱数据进行预处理, 利用测试的样本数据进行了分类试验, 对比了不同预处理方法与特征波长筛选方法组合后的分类效果。 试验表明预处理后的数据可以提高分类识别的准确率, 经预处理后识别准确率最低为51.85%, 最高可达96%, 高于未经处理情况下的40.74%。 特征筛选可以降低原始光谱数据的维度, SPA是三种方法中筛选效率最高的, 平均筛选率可达3.56%。 筛选后可提高分类识别的准确率, 原始数据经CARS筛选后分类识别的准确率可由40.74%提升到74.07%。 对光谱数据进行预处理辅以特征波长筛选, 可大大提升污秽绝缘子分类识别的准确率, MSC-CARS、 SNV-CARS、 MSC-UVE、 归一化-UVE组合处理后的分类识别准确率都可达到100%, CARS、 SPA、 UVE结合8种预处理后测试集平均分类准确率分别为87.05%、 86.25%、 83.47%, 表明预处理与特征筛选结合后对于改善数据质量、 提高模型性能具有重要作用。 光谱数据经过预处理和特征波长筛可以有效降低原始数据维数, 简化模型复杂度, 提高绝缘子污秽分类识别准确度。
The surface pollution will affect the insulator's insulation ability and harm the power system. The current detection method requires power outage sampling, which is tedious and time-consuming. Hyperspectral analysis can realize non-contact non-power outage detection and has good potential for application in insulator pollution detection. In order to reduce the data processing amount of insulator surface pollution hyperspectral detection and improve the accuracy of insulator hyperspectral data classification and identification, according to the current manual test sample preparation standards, Three artificial pollution samples of insulators with salt density of 0.22 milligrams per square centimeter, ash density of 0.1 milligrams per square centimeter and salt density of 0.3 milligrams per square centimeter and ash density of 0.1 milligrams per square centimeter were made.Hyperspectral sampling was carried out on insulator samples of different pollution levels. 15 regions were selected on each sample to extract regional spectral data, and a total of 90 groups of spectral data were obtained. 63 training set samples and 27 test set samples were selected. Competitive adaptive reweighted sampling (CARS) Algorithm, Successive Projections Algorithm (SPA and Uninformation Variables Elimination (UVE) were used to screen the characteristic wavelengths of insulator hyperspectral data and build a support vector machine classification model. Multivariate scattering correction (MSC), standard normal variation (SNV), first order derivative, deconvolution, moving average filtering, baseline correction, normalization, and wavelet transform were used to preprocess the spectral data. The classification experiments were carried out using the tested sample data, and the classification effects of different pretreatment methods and feature wavelength screening methods were compared. The experimental results show that the pre-treated data can improve classification recognition accuracy, and the pre-treated data's recognition accuracy can reach a low of 51.85% and a high of 96%, higher than the 40.74% in the untreated condition. Feature screening can reduce the dimensionality of the original spectral data, and SPA is the most efficient of the three methods, with an average screening rate of 3.56%. After screening, the accuracy of classification recognition can be improved, and the accuracy of classification recognition of original data can be increased from 40.74% to 74.07% after CARS screening. Pretreatment of spectral data combined with feature wavelength screening can greatly improve the classification and identification accuracy of dirty insulators. The classification and identification accuracy of MSC-CARS, SNV-CARS, MSC-UVE, and normalized UVE can reach 100% after combined processing. The average classification accuracy of CARS, SPA, and UVE combined with 8 preprocessed test sets was 87.05%, 86.25%, and 83.47%, respectively, indicating that the combination of preprocessing and feature screening plays an important role in improving data quality and model performance. These preprocessing and characteristic wavelength screening methods of spectral data can effectively reduce the original data dimension and simplify the model complexity, which can play an important role in improving the accuracy of insulator pollution classification and recognition.
绝缘子是电力系统中重要的绝缘设备, 在输电线路和变电所中应用广泛。 由于受恶劣环境和电场强度的影响, 绝缘子表面会吸附空气中的粉尘颗粒, 导致污秽物积聚, 在潮湿天气下, 污秽物中的可溶性盐会溶解于水中, 形成导电通路, 影响绝缘子的绝缘性能, 降低电力系统的放电阈值, 增加设备击穿风险[1, 2]。
绝缘子污秽检测方法包括等值盐密法、 泄露电流法、 表面污层电导率法等[3, 4, 5]。 这些方法需要专业人员操作, 步骤繁琐, 且需对工作的绝缘子进行取样, 由于绝缘子悬挂于高处, 数量多且不易拆卸, 检测效率低、 单个检测时间长[6]。 因此, 绝缘子污秽等级的快速检测技术显得尤为重要。 近年来, 许多学者利用红外热成像法[7]和紫外成像法[8]检测绝缘子污秽程度。 这两种方法分别反映了绝缘子的发热特征和放电特征, 在提高检测效率和实现非接触式检测方面有所贡献, 但均易受到电磁干扰影响, 存在难以表征复杂特征的问题。 何洪英等[9]采集不同湿度条件下绝缘子污秽图像, 搭建径向基概率神经网络模型对不同湿度条件下绝缘子污秽等级进行划分。 金立军等[10]提出红外与紫外图像信息决策级融合的污秽等级状态识别方法。
高光谱检测作为一种新型的检测技术, 在绝缘子非接触、 不停电检测中具有较为明显优势。 高光谱检测技术相较于传统检测方法, 具有更高的效率和更低的成本, 且具有非接触检测的优势, 它能够在紫外至中红外范围内对目标进行成像, 涵盖数百个连续光谱波段, 显著提高了分辨率, 可形成连续的光谱曲线, 同时获取目标物的空间信息和比红外热成像、 紫外成像更为全面的光谱数据。 高光谱检测具有图像和光谱数据分析的双重优势, 在绝缘子污秽检测领域展现出巨大的潜力。 张血琴等[11]采用高光谱可见光波段信息, 基于深度学习算法搭建检测复合绝缘子表面老化程度评估模型。 文志科等[12]采集不同运行状态下硅胶绝缘子高光谱图像, 建立样本光谱库, 利用贝叶斯分类模型检测复合绝缘子运行状态。 这些试验都验证了高光谱检测在绝缘子表面污秽检测中的可行性。 但由于绝缘子污秽等级检测涉及的高光谱数据维度高, 其中包含了一些与污秽检测无关的光谱信息, 这不仅增加了建模计算的复杂度, 还可能影响模型的表现。 因此有必要进行特征波段的筛选, 以降低光谱数据的维度, 提高数据处理的速度及模型的泛化能力[13]。
本工作采用高光谱检测方法获取绝缘子污秽的光谱数据, 旨在探究光谱数据特征波长筛选的方法。 比较了竞争性自适应重加权算法、 连续投影算法和无信息变量消除法三种方法在筛选特征波长方面的表现进行对比; 对不同特征筛选方法所建立的污秽等级分类模型进行比较和分析, 评估其性能。 最终选择表现最佳的特征提取方法用于后续建模, 确保检测模型的精确性和有效性。
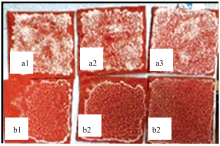
依据GB/T22707— 2008《直流系统用高压绝缘子的人工污秽试验》[14]标准规定制备试验样本, 选用与绝缘子材质相同的红色硅橡胶片(5 cm× 5 cm)作为人工污秽样本的基材, 选用氯化钠和高岭土混合制作污秽物溶液。 称取0.55 g氯化钠和0.25 g高岭土、 0.75 g氯化钠和0.25 g高岭土两组配比, 分别溶解于500 mL蒸馏水中, 形成两种不同浓度的氯化钠混合溶液, 充分搅拌后, 将5 mL氯化钠混合液均匀涂刷在每个人工试验胶片表面, 并在自然环境下晾干, 得到盐密度0.22 mg· cm-2、 灰密度0.1 mg· cm-2和盐密度0.3 mg· cm-2、 灰密度0.1 mg· cm-2的两组污秽绝缘子样片如图1所示, 上面三个样本(a组)的盐密度为0.3 mg· cm-2, 下面(b组)三个样本的盐密度为0.22 mg· cm-2。
 | 图1 人工污秽样品Fig.1 Artificial contamination samples |
a组、 b组样品共6个, 在每个样品上选取15个大小相等区域提取区域光谱数据, 共得到90组光谱数据。 按照7∶ 3的比例划分训练集与测试集, 选取训练集样本63个, 测试集样本27个。
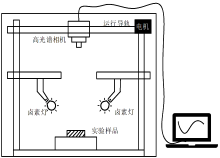
高光谱检测数据采集原理如图2所示。 采集系统平台包含高光谱相机(FS-13), 光谱波长范围400~1 000 nm(可见光/近红外); 50 W卤素灯2个, 波长范围400~1 000 nm(可见光/近红外), 用于提供均匀稳定的光源; 放置样品的暗箱可隔离外部光源和环境干扰; 反射率为1的标准校正白板; 导轨平台由电机驱动使高光谱相机在导轨上匀速移动。 计算机用于储存光谱数据和后续处理和分析。
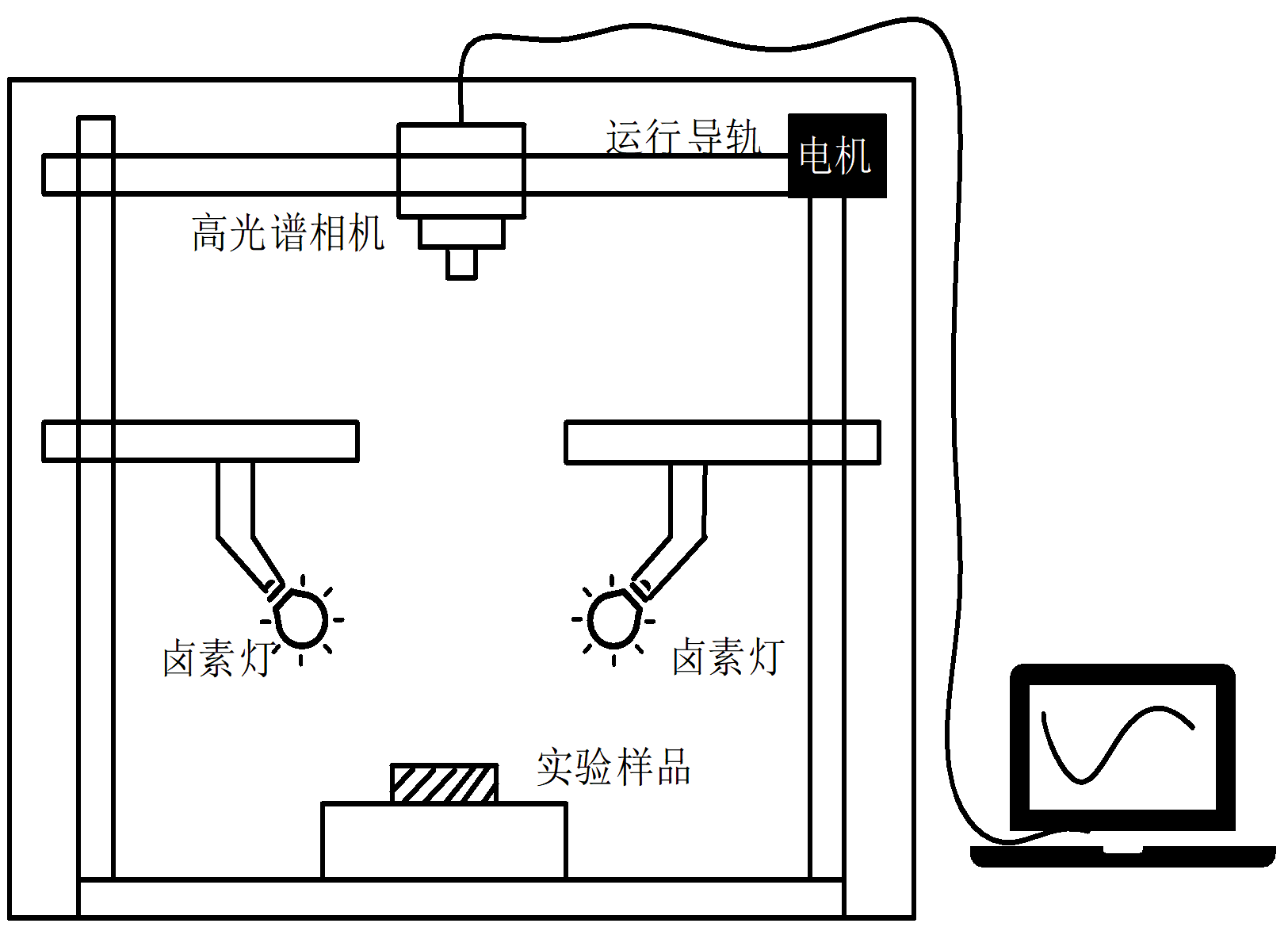 | 图2 高光谱采集系统Fig.2 Hyperspectral acquisition system |
为了使样本图像不变形并获得清晰的高光谱数据, 调节高光谱相机合适的曝光时间以及导轨的移动速度至38.5 mm· s-1。 高光谱相机拍摄角度与运行导轨呈90° 。
外界环境噪声及仪器内部暗电流的干扰会影响光谱数据的准确性, 需将采集的数据进行黑白校正。
通过使用标准校正白板获得反射率为100%的全白标定数据, 高光谱相机盖住后采集的数据作为全黑标定数据, 对采集到的这些数据进行黑白校正处理
式(1)中, RD是经黑白校正处理后的光谱数据; RS是实验采集到的原始光谱数据; RB是全黑标定光谱数据; RW是全白标定光谱数据。
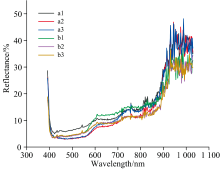
光线经过被测物表面时不仅会发生反射, 还会有部分光线发生折射, 为减少光谱数据的丢失, 还需对其进行散射校正, 图3为每个人工污秽样本的原始光谱图。
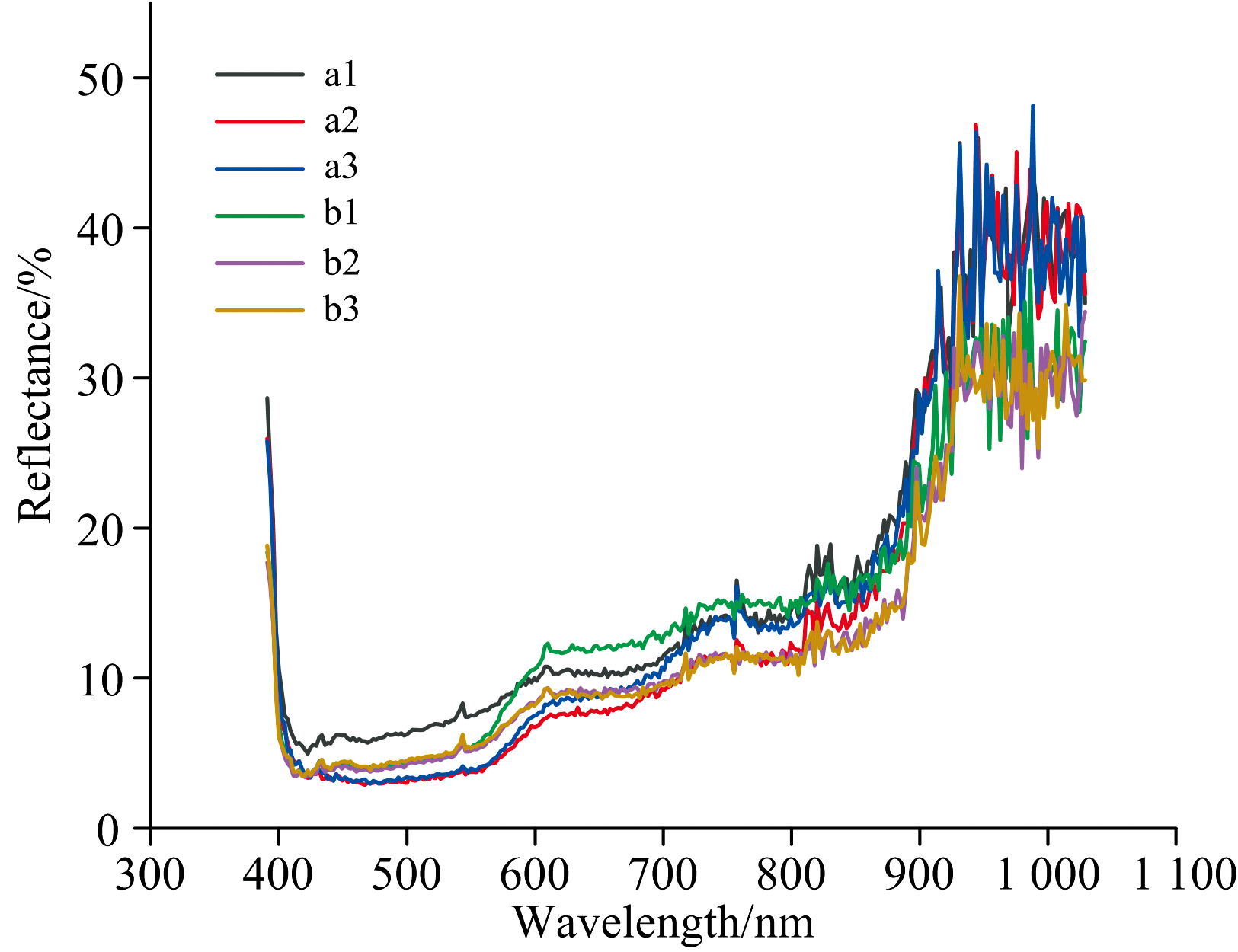 | 图3 6个人工污秽样本原始光谱图Fig.3 Original spectra of samples |
1.4.1 竞争性自适应重加权算法
竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)是一种用于高光谱数据特征波长筛选的方法, 用于对高维数据进行降维, 并剔除不重要的波段, 这一方法是通过模拟生物进化中的选择机制, 根据实际情况自适应地对光谱波段进行重加权和筛选, 逐步剔除冗余和不重要的波段, 这使得CARS算法特别适用于信息冗余和多重共线性问题的数据。 CARS算法的基本原理和步骤:
(1)蒙特卡洛采样: 在初始采样阶段, 每次随机从校正集中选择一部分数据用于构建训练集, 其余样本数据作为预测集建立偏最小二乘模型(PLS)。 提前设定蒙特卡洛的采样的次数, 计算采样过程中偏最小二乘模型中回归系数的绝对值权重:
式(2)中, |bi|为第i个变量的回归系数绝对值; wi为第i个变量的回归系数绝对值权重; p为每次采样中剩余的变量数;
(2)自适应加权采样: 采用指数衰减函数(exponentially decreasing function, EDF)剔除PLS模型中回归系数的绝对值权重相对较小的点, 运行中保留变量的比例为:
式(3)中, g与β 为常数系数; 其决定条件为: 第一次运行时, r1=1; 第N次运行时, rN=
(3)交互验证: 通过计算交叉验证均方根误差(RMSECV), CARS算法经过多次采样后, 得到N个最佳特征波长组合, 最终选择均方根误差值最小的波长组合的子集作为特征波长。
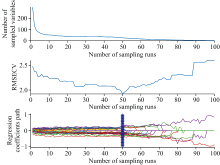
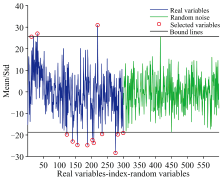
图4为利用CARS算法筛选绝缘子表面污秽特征波长的运行结果。 实验中设置100次蒙特卡洛采样并结合偏最小二乘法回归, 以确定CARS的最佳主成分数, 筛选前期, 随着采样次数的增加, 筛选出的变量数量显著减少; 而在筛选后期, 尽管采样次数继续增加, 筛选的变量数量基本保持不变。 最终, 通过最小交叉验证均方根误差值来确定最终筛选的波长数量为29个。
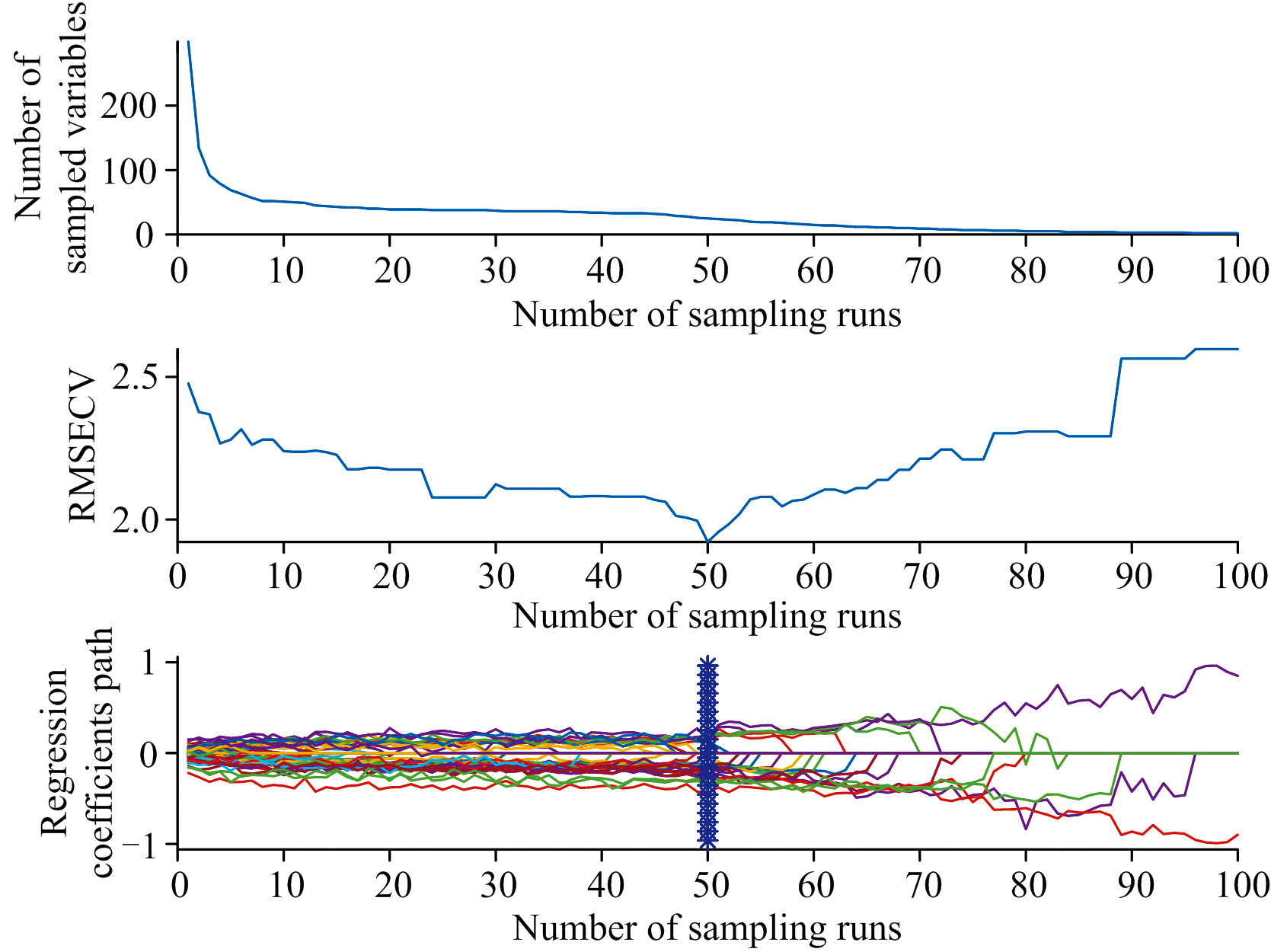 | 图4 CARS选取Fig.4 Process of CARS selection |
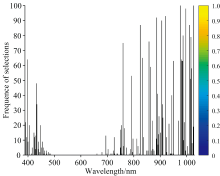
图5所示为变量被选频率图, 频率越高的波长, 表明其作为特征波长的概率越大, 结果显示: 频率较多集中在780~950 nm之间。
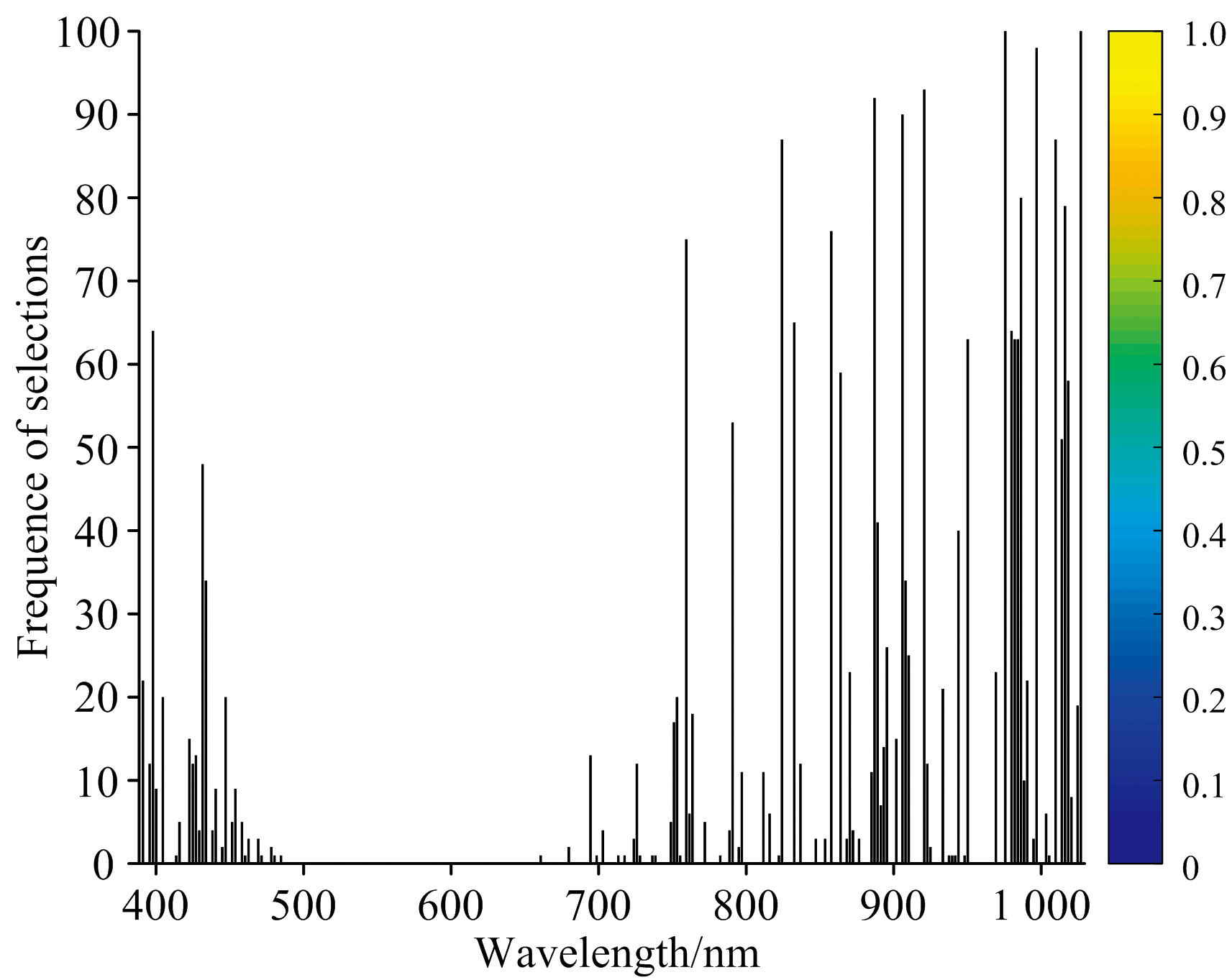 | 图5 变量被选频率图Fig.5 Frequency of variable selections |
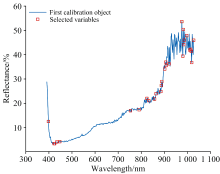
图6展示了筛选的结果, 特征波长共计29个, 由于低于400 nm和高于1 000 nm处的波长可信度较差, 需要进行剔除, 最后剩下23个, 分别为: 422.6、 424.84、 433.77、 447.13、 753.15、 790.79、 824.23、 832.59、 857.7、 863.98、 884.94、 887.04、 889.13、 901.73、 905.94、 908.04、 920.67、 975.64、 979.89、 982.01、 984.14、 986.27和996.92 nm。
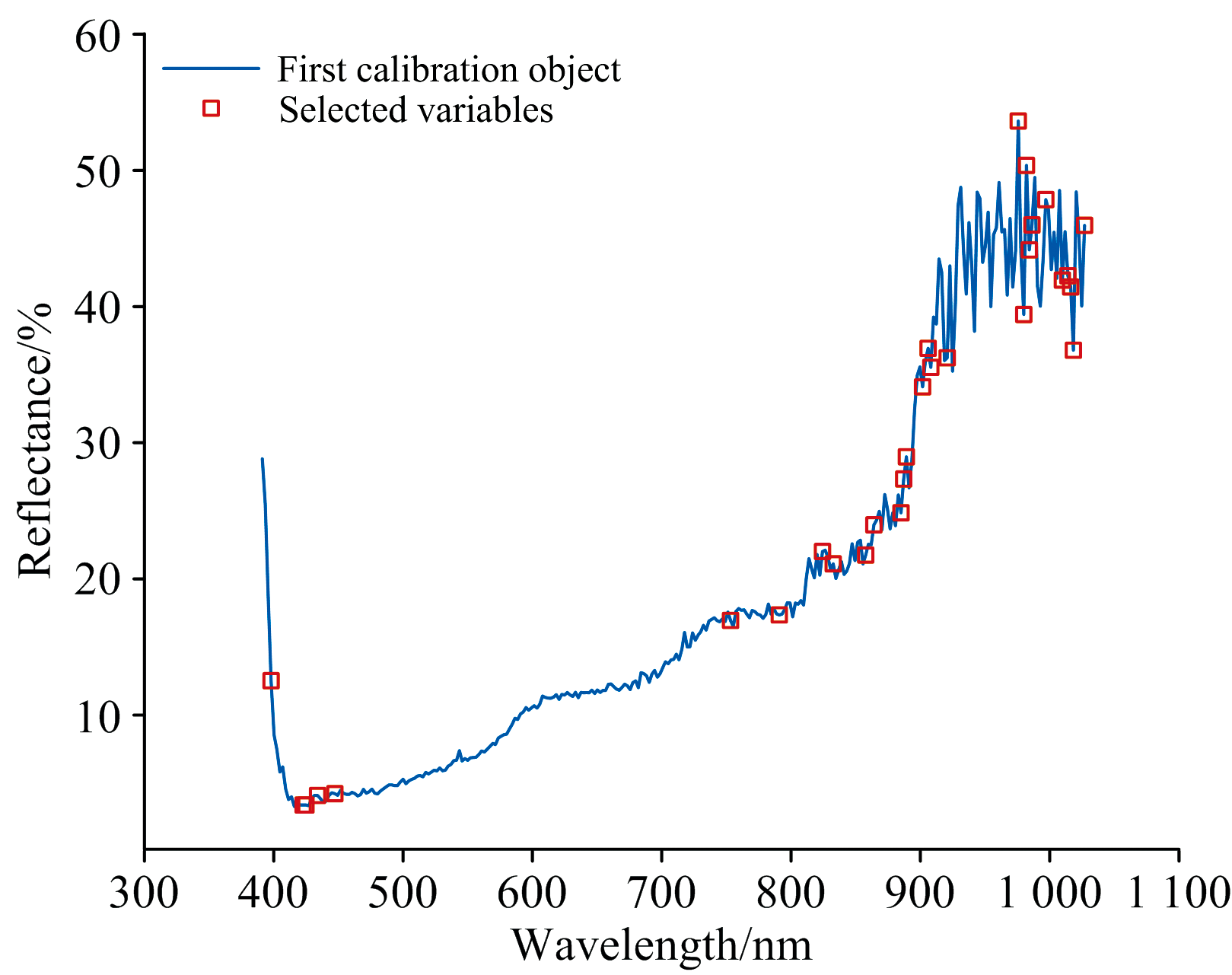 | 图6 CARS波长选取的波长结果Fig.6 Distribution of selected wavelength by CARS |
1.4.2 连续投影算法
连续投影算法(successive projections algorithm, SPA)旨在从成百上千个光谱变量中精确地筛选出最具代表性的变量, 以此来降低变量之间的共线性, 有效地减少数据的重叠和冗余, 并通过多元回归分析评估这些变量的预测效果。 具体步骤如下:
(1)将初始迭代向量定义为xi(0), 光谱数据矩阵为Z列, 包括N个变量。
(2)从建模集中随机抽取一列光谱矩阵, 将这一列记为第j列, 同时将第j列赋值给xj, 记为xi(0);
(3)将未被选中的列向量的集合记为H, 即:
(4)计算出剩余的所有未被选择的列向量的投影集合, 记为Qxj, 即:
(5)提取最大投影向量的光谱波长:
(6)假定xj=Qxj, j∈ H。
(7)n=n+1, 若n小于N, 重新回到步骤(3)循环计算。
通过计算提取的变量{xi(n)=0, …, N-1}, 经过多次循环, 可以获得对应的每次循环中的i(0)和N, 再利用多元回归(MLR)模型分析, 以及计算均方根误差(RMSEP), 当均方根误差达到最低时, 对应的i(0)和N即为最佳解。
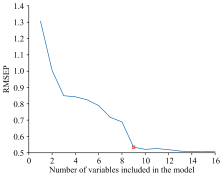
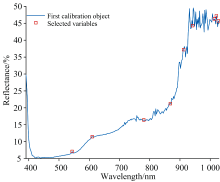
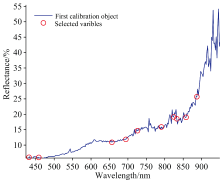
经SPA运行后的结果如图7所示, 展示了各波长的RMSEP值, 波长子集的RMSEP值接近最小值时, 共筛选出6个波长, 如图8所示, 分别为543.44、 609.90、 780.34、 868.17、 912.25和941.76 nm, 从图中展示的结果看, 筛选后的波长都集中于900 nm以上, 但处于波峰波谷处的波长居多。
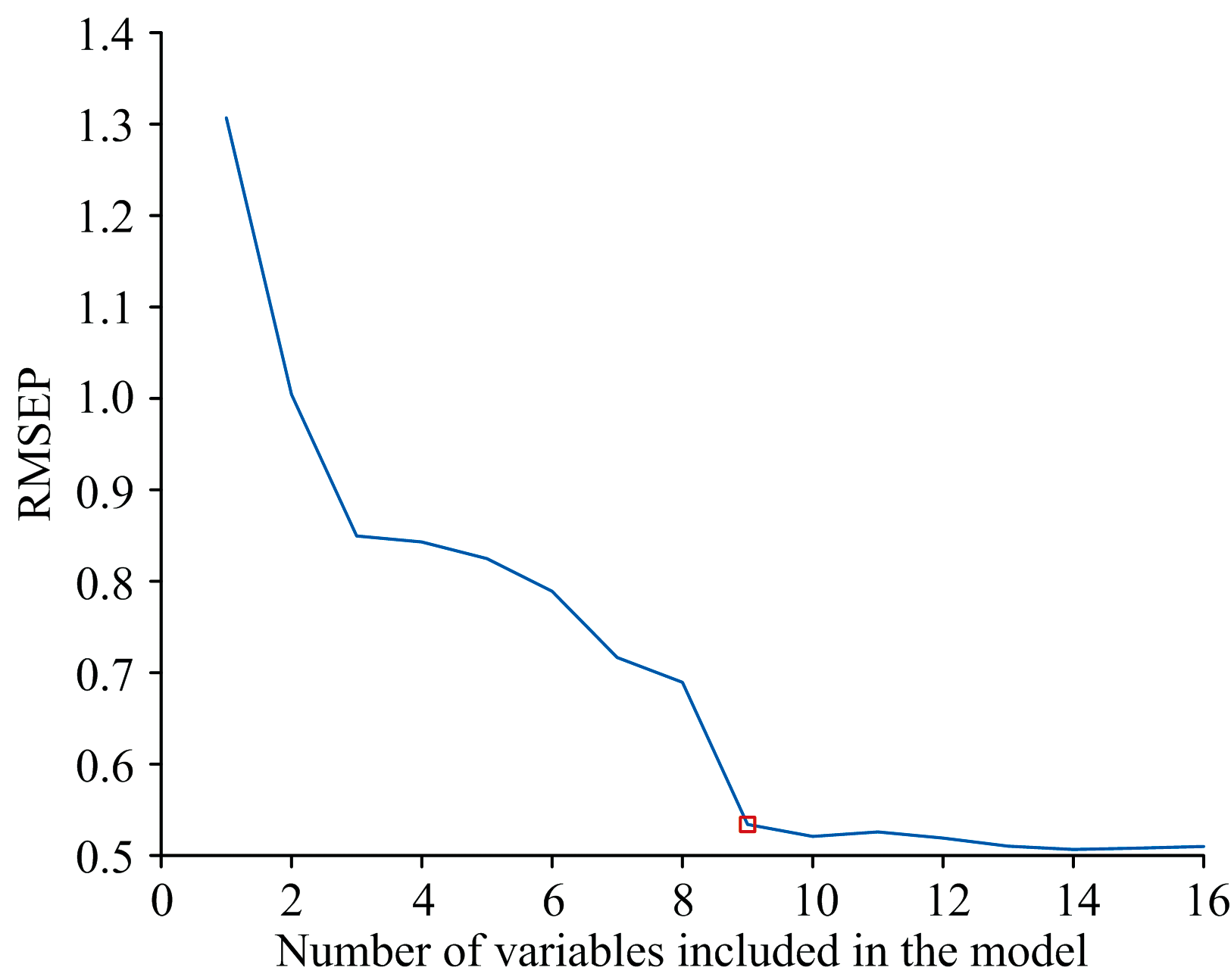 | 图7 SPA选取波长的RMSEP值Fig.7 RMSEP value of SPA wavelength selection |
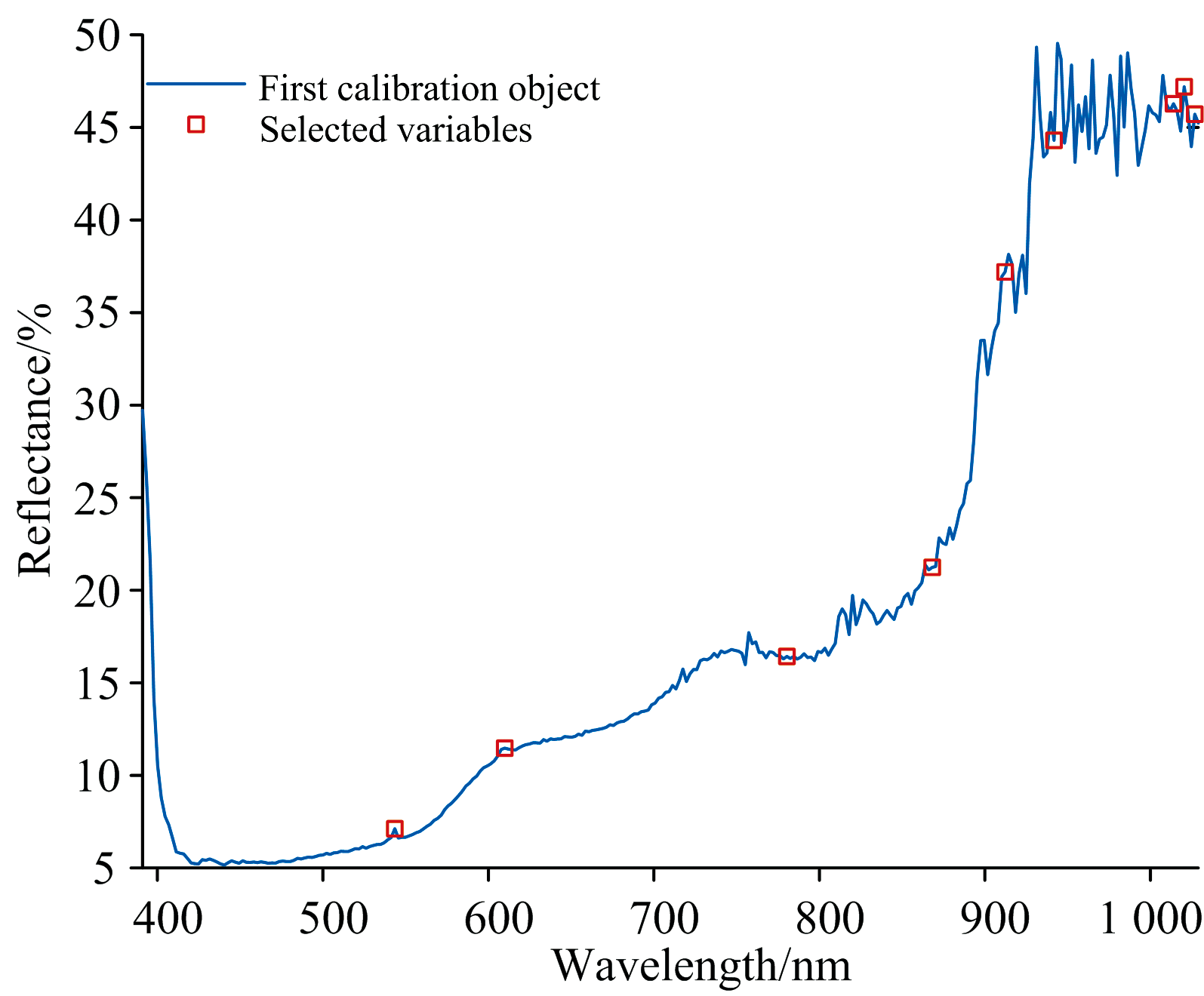 | 图8 SPA选取的波长结果Fig.8 Wavelengths selected by SPA |
1.4.3 无信息变量消除法
无信息变量消除法(uninformation variables elimination, UVE)可以有效地筛选出对建模贡献最小的波长变量, 从而确保模型的准确性和可靠性。 选择具有有效表征的特征波长, 被剔除的波长变量称为无信息变量。 UVE算法基于偏最小二乘法(PLS), 可减少变量的数量, 降低模型复杂性。 具体步骤如下:
(1)假设有n个样本, 其中Tn× q=[t1, …, tq]为自变量矩阵, ti=
(2)定义噪声矩阵Yn× m, 构建新的n× (2q)维变量混合光谱矩阵TYn× (2q)=[T, Y];
(3)对TYn× (2q)与yn× 1进行PLS留一交叉验证;
(4)从样本中移除第i个样本, 对剩下样本进行偏最小二乘建模, 得到1× (2q)维回归系数向量ci=[ci1, …, ci(2q)]; 重复上述步骤, 进行n次偏最小二乘回归, 确保每个样本都被移除一次, 最终得到系数矩阵
式(9)中, aj=
(5)通过计算aj系数向量中元素W(aj)的标准差和均值M(aj), 可得到一个稳定值aj可表示为
为了剔除异常值和极端噪声, 尽可能确保大多数数据都能保留下来, 增强稳定性与鲁棒性, 将阈值Cthreshold设置为噪声变量稳定值绝对值的第99百分位数, 并根据该阈值剔除光谱变量, 可以获得更加准确的有效光谱变量。
UVE算法处理后的结果如图9、 图10所示, 图9为UVE中阈值判断图, 图中上下两黑色水平轴代表变量的阈值, 阈值之间的区域表示被剔除的无关信息变量, 而超出阈值的部分则为筛选出来的有效波长, 可用于后续建模。 图10显示了筛选出的结果, 特征波长共13个, 考虑到低于400 nm和高于1 000 nm处的波长可信度较差, 需要进行剔除, 最后剩下12个, 分别为: 431.54、 458.21、 656.54、 694.46、 725.94、 790.79、 824.23、 832.59、 857.70、 887.04、 975.64和990.52 nm。
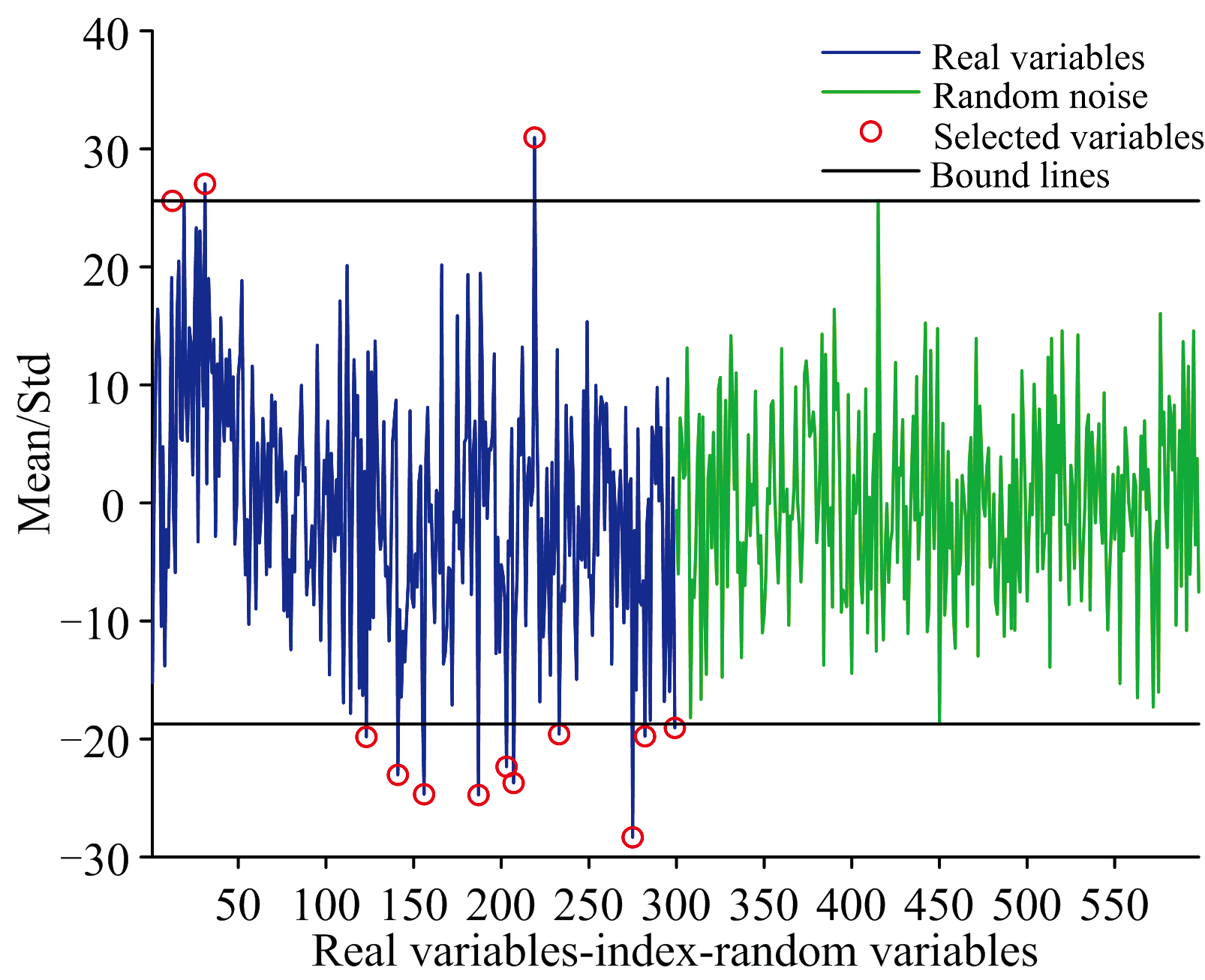 | 图9 UVE阈值判断图Fig.9 UVE threshold determination diagram |
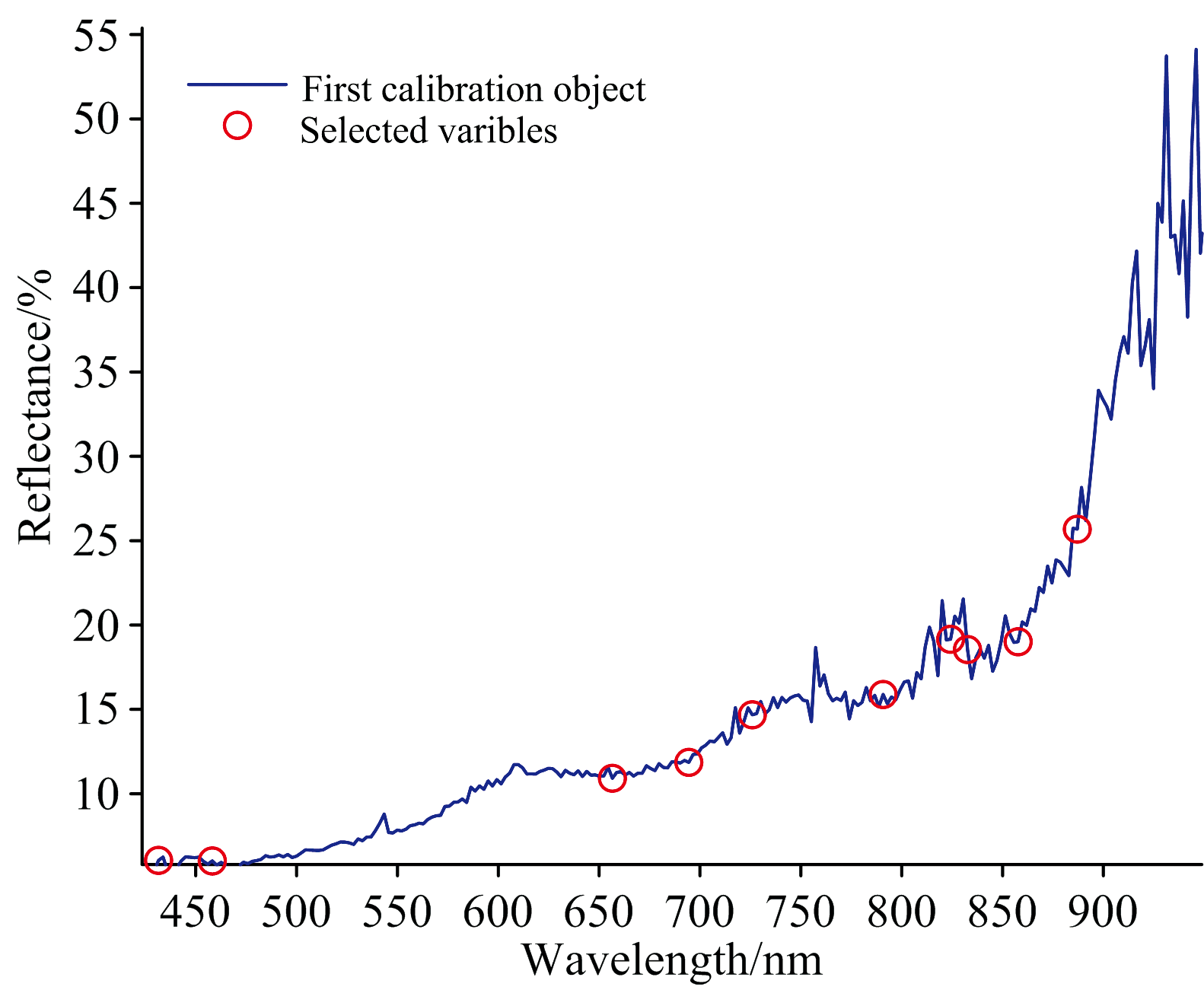 | 图10 UVE筛选的特征波长结果Fig.10 Characteristic wavelengths extracted by UVE |
为验证不同筛选方法的效果, 考虑8种不同的预处理方法, 分别与CARS、 SPA和UVE结合进行特征波段筛选, 搭建支持向量机SVM分类模型进行绝缘子污秽等级的划分。 表1列出了不同预处理方法与筛选方法组合进行分类的结果。
| 表1 具体测试结果 Table 1 Specific test results |
从表1可以看出: 光谱数据经过预处理后建模分类的准确率明显高于采用原始数据分类的准确率, 经过预处理后再进行筛选所得的特征波长个数明显减少, 但分类的准确率并未受到影响。 不同的预处理方法分类效果存在着明显差异。
2.2.1 特征波长筛选结果的对比
在三种特征筛选方法中, SPA和UVE两种方法的筛选效果较好, SPA筛选所得的特征波长数目最少, 最高效情况下可以从300个波长中筛选出5个特征波长; 且SPA针对各种预处理方法的筛选效率都是最高的, 平均筛选率为3.56%, UVE的平均筛选率为6.11%, CARS的平均筛选率为6.89%。 UVE方法的整体筛选效果要好于CARS方法, 但对于部分预处理方法, 如标准正态变化、 基线校正和小波变换3种预处理方法, UVE的筛选效果略差于CARS。
2.2.2 分类效果对比
从表中可以看到, 采用经过预处理后的光谱数据进行识别分类, 其准确率要高于采用未处理数据进行识别的准确率。 光谱数据经过预处理后, 在不经筛选的情况下, 其识别准确率最低可以达到51.85%, 高于未经处理不筛选情况下的40.74%。 采用标准正态变化处理后的数据, 在不经筛选情况下进行识别的准确率可达到96%。
采用未经预处理的原始数据, 经过特征筛选后再进行分类识别的准确率也能得到较大提升, 其中原始数据经CARS筛选后再进行分类的准确率可达到74.07%。
光谱数据经过预处理再加上特征筛选后进行分类识别, 其准确率会进一步提高, MSC-CARS、 SNV-CARS、 MSC-UVE、 归一化-UVE处理后的测试集准确率均可达到100%; CARS、 SPA、 UVE结合8种预处理后测试集平均分类准确率分别为87.05%、 86.25%、 83.47%。 预处理方法与特征筛选方法结合后, 模型性能得到显著提升, 表明预处理与特征筛选结合对于改善数据质量、 提高模型性能具有重要作用。
高光谱中蕴含有从可见光到近红外的详细光谱高维信息, 直接采用原始数据进行分析, 数据处理工作量大, 分类识别准确率不高。 采用预处理后的数据可以提高分类识别的准确率, 其中标准正态变化可以使得分类识别准确率提高到96%。 特征筛选方法可以降低原始光谱数据的维度, 并提高分类识别的准确率, 利用原始数据采用CARS筛选后分类识别的准确率提升较多。 对光谱数据进行预处理后筛选特征波长再进行分类识别, 其准确率会大大提升, MSC-CARS、 SNV-CARS、 MSC-SPA、 MSC-UVE、 归一化-UVE处理后的分类识别准确率可达到100%, 显示出光谱数据预处理和特征波长筛选能够有效降低原始数据维数, 简化模型复杂度, 并提高运行速度和模型准确度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|