
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于K-means-CNN的复杂牌号混合合金样品分类研究
[马耀安1  , 黄裕婷
, 黄裕婷1 , 张健豪1 , 曲东明1 , 扈蓓蓓2 , 刘碧野2 , 杨光1 , 孙慧慧1, * ]
, 黄裕婷]
|
|


作者简介: 马耀安, 2002年生,吉林大学仪器科学与电气工程学院本科生 e-mail: mayaoan0709@163.com
激光诱导击穿光谱(LIBS)技术通过超短脉冲激光聚焦样品表面形成等离子体, 进而对等离子体发射光谱进行分析, 从而确定样品的物质成分及含量, 是一种具有制样简单, 非接触测量, 现场适应能力强, 分析速度快的高效元素分析方法。 使用LIBS技术进行元素分析, 成分分类识别是研究的关键方向, 目前LIBS技术主要应用于岩石矿产检测, 环境监测, 化学品识别相关领域, 而对多种成分复杂牌号混合合金分类问题研究较少。 常用高性能精确分类算法通常对计算资源要求高, 难以搭载在要求便携性, 小型化的LIBS系统中。 MPL-T-1064激光器产生脉冲激光, 通过前置镜组调制光路, 激发Al, Fe, Cu多种牌号合金的混合样品采集数据。 使用主成分分析方法(PCA)对数据进行预处理, 输入K均值聚类算法(K-means), 卷积神经网络(CNN)模型中进行分类。 使用K-means无法对复杂牌号合金进行精细分类, 但在大类区分工作中准确率达到99.97%。 CNN可以对复杂牌号合金进行精细分类, 准确率达99.15%, 但对计算资源要求相对较高。 针对上述问题, 设计了一种融合算法, 使用K-means算法处理混合合金光谱数据, 对相同种类不同牌号的样品进行粗分类, 将一次分类后的数据输入CNN模型进行精细分类, 在Al, Fe, Cu十种牌号样品的混合合金光谱中分类准确率达到99.35%, 在5折交叉验证中准确率达99.52%, 验证了算法在分类准确的同时具有较好的泛化能力。 融合算法分类准确率相比K-means算法提高了39.65%, 运行速度相比CNN算法加快21.94%。 为多种成分复杂牌号混合合金分类问题提供了高效, 快速, 准确的方法。 为更加轻量化, 便携化的LIBS系统发展方向提供了新的思路。
, HUANG Yu-ting
Laser-induced breakdown spectroscopy (LIBS) is a highly efficient elemental analysis method with simple sample preparation, non-contact measurement, strong field adaptability, and fast analysis speed by focusing an ultra short pulse of laser light on the surface of the sample to form a plasma, and then analyzing the emission spectrum of the plasma to determine the material composition and content of the sample. Using LIBS technology for elemental analysis, component classification, and identification is the key direction of the research. At present, LIBS technology is mainly used in rock and mineral detection, environmental monitoring, chemical identification, and related fields, while less research is conducted on the classification of mixed alloys with multiple components and complex grades. The commonly used high-performance, accurate classification algorithms usually require high computational resources and are difficult to mount on portable and miniaturized LIBS systems. A mixed sample of various grades of AL, FE, and CU alloys was excited by an MPL-T-1064 laser with a modulated optical path through a front mirror set to collect data. Data were preprocessed using Principal Component Analysis (PCA) and then input into the K-means clustering algorithm (K-means), a Convolutional Neural Network (CNN) model for classification. The K-means is unable to classify complex alloy grades finely, but has an accuracy of 99.97% in the work of large class differentiation.CNN can classify complex alloy grades finely with an accuracy of 99.15%, but it has a relatively high demand on computational resources. Aiming at the above problems, a fusion algorithm is designed to use the K-means algorithm to process the mixed alloy spectral data. It coarsely classifies samples of the same kind but different grades. Then, the data after the first-stage classificationis input into the CNN model to carry out fine classification. The accuracy of classification in the mixed alloy spectra of ten kinds of samples of grades of AL, FE, CU reaches 99.35%, and the accuracy in the 5-fold cross-validation reaches 99.52%, which verifies that the algorithm has better generalization ability while classifying accurately. The classification accuracy of the fusion algorithm is 39.65% higher than that of the K-means algorithm, and the running speed is 21.94% faster than that of the CNN algorithm. It provides an efficient, fast, and accurate method for the classification of mixed alloys with multiple compositions and complex grades. It provides a new idea for developing a more lightweight and portable LIBS system.
近年来, 铝合金因其轻质性、 耐腐蚀性、 低密度、 高强度和易于加工成型的优点而得到广泛应用, 在航空航天、 交通运输、 军事、 电子等领域发挥着重要的作用[1, 2]。 作为第二大工业金属, 约三分之一来自废料的回收利用, 且再生铝的能源消耗量、 残留物和温室气体排放量远低于原铝生产, 因此再生铝更有利于实现碳中和目标和可持续发展[3, 4]。 但在铝合金的回收过程中, 尤其是大规模的工业废弃物, 铝合金经常与其他合金混杂在一起, 其中以铁合金、 铜合金居多, 增加了后续分选提纯过程的难度和人力成本, 所以建立一种铝合金的高效分类方法, 既可以提高回收效率又可以降低处理成本, 十分具有经济效益和应用价值。
激光诱导击穿光谱(laser-induced breakdown spectroscopy, LIBS)是一种基于等离子体发射光谱的光学分析技术, 等离子体由激光雾化一小部分样品表面产生[5]。 相比于需要较长检测时间和复杂样品制备且大多数具有破坏性的传统分析技术, LIBS具有快速、 灵敏、 无损和多元素分析的优势, 需要最少或不需要样品制备, 可以进行现场快速检测, 在合金准确分析和分类中广泛应用[6, 7, 8, 9, 10]。 近年来许多学者将LIBS与机器学习算法相结合对样品进行分类识别。 Aberkane等[11]分别结合了人工神经网络(artificial neural network, ANN), K近邻算法(K-nearest neighbors, KNN)和支持向量机(support vector machine, SVM)算法对锌合金进行分类比较, 其中SVM对锌合金LIBS光谱的分类效果最好; 周中寒等[12]采用光纤激光器LIBS技术, 结合主成分分析(principal component analysis, PCA)和SVM算法, 对6种牌号铝合金样品按牌号进行分类, 平均预测准确率达99.83%; 刘佳等[13]对于单脉冲LIBS光谱信号, 分别建立多维高斯概率密度分布判别函数, 实现了对三个系列铝合金样品的连续分类检测; Campanella等[14]结合“ 模糊” 的ANN, 加快分析过程并考虑LIBS光谱中包含的潜在非线性, 有效区分不同牌号的铝合金; 李晨阳等[15]结合基于密度的聚类算法(DBSCAN)及K均值聚类算法(K-means clustering algorithm, K-means)将钨合金的LIBS数据分成三簇, 进行样品标签未知情况下的快速聚类分析。
传统激光源常用单脉冲激光器, 因其体积大重量沉, 并不适用于现场快速检测。 而随着技术的进步, 现代社会在实地考察中常常使用更小、 更轻、 更便于携带的高重频脉冲激光器和小型嵌入式系统, 以实现现场实时快速检测。 而小型便携式系统的中央处理器难以处理数据计算量复杂的算法, 因此需要构建一种计算量小且快速的分类方法。
K-means算法无需监督学习计算量小, 在高维数, 数据量庞大的数据中表现较差; 卷积神经网络(convolutional neural network, CNN)在复杂牌号混合合金分类任务中表现较好, 但计算量过大, 小型嵌入式系统的性能不满足其需求。 因此, 本文提出了K-means-CNN混合分类算法, 利用K-means聚类对光谱特性差异较大的铝合金、 铜合金和铁合金样本进行大类区分, 将铜合金和铁合金剔除, 然后利用CNN对光谱特性差异较小的铝合金进行进一步的分类。 K-means-CNN输入数据通过PCA进行预处理降维, 首先降低了数据的复杂度。 相比于单一算法, K-means-CNN混合分类算法计算量大幅度减小, 分类速度有效提升, 可应用于小型便携式系统。 并且K-means-CNN混合分类算法效率高, 分类结果稳定性强, 适用于实地考察中现场实时检测的应用场合。
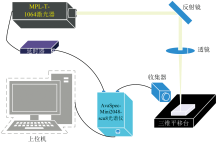
实验装置如图1所示, 将待测样品放置于Zolix薄型三维平移台上, 由MPL-T-1064激光器产生重复频率为9.96 kHz, 波长为1 064 nm, 脉冲宽度为10 ns, 脉冲能量为100 μJ的激光激发样品, 激光经反射镜改变光路在竖直平面通过嵌入在CP35笼板中的LA1131-YAG透镜垂直聚焦在被测样品表面, 微调滑台移Z轴高度对准等离子体接收光谱信息, 光谱数据经由光纤传输至AvaSpec-Mini2048-scu8光谱仪, 并将数据发送到PC进行后续处理。 激光器的时序控制使用长春纽斯派克光电科技有限公司高精度多通道时序控制器, 三维平移台使用本团队开发的SC300软件进行控制。
 | 图1 采样平台示意图Fig.1 Sampling platform diagram |
根据国标GB/T 1173— 1995规定, 实验样品Al样品牌号为2A12, 4032, 5052, 5083, 6061, 6063, 6262。 根据国标GB/T 340— 76规定, Cu样品牌号为H70。 根据国标GB/T 17616— 2013规定, Fe样品牌号为304, 316。 根据国标GB/T 3190— 2020, GB/T 20878— 2007, GB/T 5231— 2012得到上述样品主要成分如表1所示。
| 表1 样品主要化学元素成分含量 Table 1 The content of main chemical elements in the sample |
采集激光诱导击穿光谱数据的实验环境为标准大气压强和室温(25 ℃)环境, 通过透镜组搭建聚焦光路和通过光纤收集信息, 将样品放置在三自由度平台上, 控制激光器将激光照射在样品表面激发样品产生等离子体, 利用光谱仪收集等离子体信息并上位机中形成光谱图像, 将光谱数据记录在Excel表格中。 实验过程中, 由于激光烧蚀样品形成坑洞导致同一烧蚀点不能长时间收集数据, 故控制平台以0.3 mm· s-1的速度定向移动获取足够的数据。
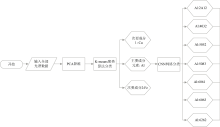
构建了一种K-means-CNN的融合算法, 并将数据使用PCA进行预处理, 对10种混合合金的光谱数据进行分类, 最后进行交叉验证测试算法的泛化能力。 PCA是使用线性变换将高维数据转换到低维空间, 同时保留数据中的主要变异信息的数学方法。 K-means聚类算法是基于样本点距离均值的一种无监督学习方法。 CNN是一种常用的人工神经网络。 使用PCA方法保留原始数据2 048个维度中方差解释率最高的三维。 方差解释率表征了该维度数据表征整体数据集特性的能力, 方差解释率越大, 该维度数据越能够表征整体数据集的特性。 将四维数据导入K-means算法进行分类, 对混合合金数据进行粗分类后得到Al, Fe, Cu的大类分类结果, 将Al数据投入CNN网络进行进一步分类, 实现了从复杂牌号混合合金中对特定种类合金进行分类的工作。 混合算法模型如图2所示。
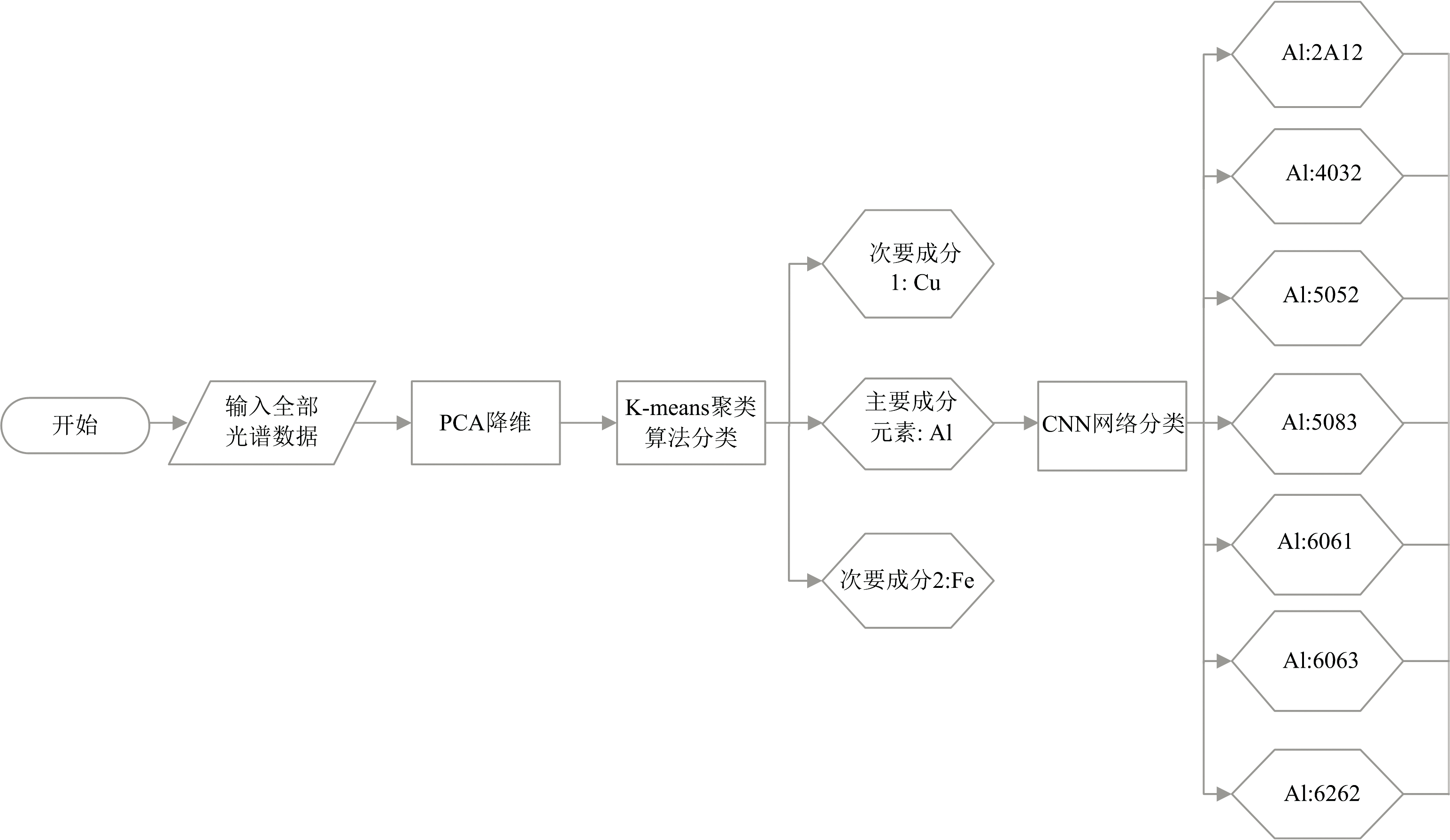 | 图2 混合算法模型Fig.2 Hybrid algorithm model |
CNN是一类包含卷积运算且具有深度结构的前馈神经网络, 是深度学习的代表算法之一。 采用卷积神经网络对7种铝合金进行监督分类, 每种合金样品获得300组光谱数据, 共获得2 100组光谱数据, 每组数据具有2 048个特征分量, 并且每类样品对应一个标签。 首先划分训练集和测试集, 将每种合金样品的前250组光谱数据, 即总共1 750组光谱数据划分为训练集; 将每种合金样品的后50组光谱数据, 即总共350组光谱数据划分为测试集。 训练集用于构建CNN模型, 测试集用于评估模型性能, 验证分类结果的准确性, 并进行多次交叉验证。
交叉验证是机器学习中评估模型泛化能力的重要方法, K折交叉验证是最常用的一种交叉验证方法。 它将原始数据集分成K个子集, 每次选择其中一个子集作为测试集, 其余K-1个子集作为训练集, 然后分别在这K个子集上进行训练和测试, 最终将K次测试结果的平均值作为模型的性能评估指标。 本文采用5折交叉验证并评估算法的泛化能力。
实验中将数据分别输入K-means算法和单一CNN模型中对十种样品直接进行分类, 记录分类结果和运行时间。 再使用构建的K-means-CNN的融合算法对十种样品进行分类, 对结果进行综合对比分析。
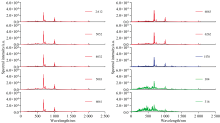
采用运动采样方法得到光谱数据, 每种元素采样300组, 每组数据维度为2 048, 故数据集总量为3 000× 2 048。 将采样获取的十种混合合金光谱数据绘制图像, 结果如图3所示。 如图3可知, 不同牌号混合合金光谱图像大类之间差异明显, 但小类之间差异较小, 难以进行直观区分。
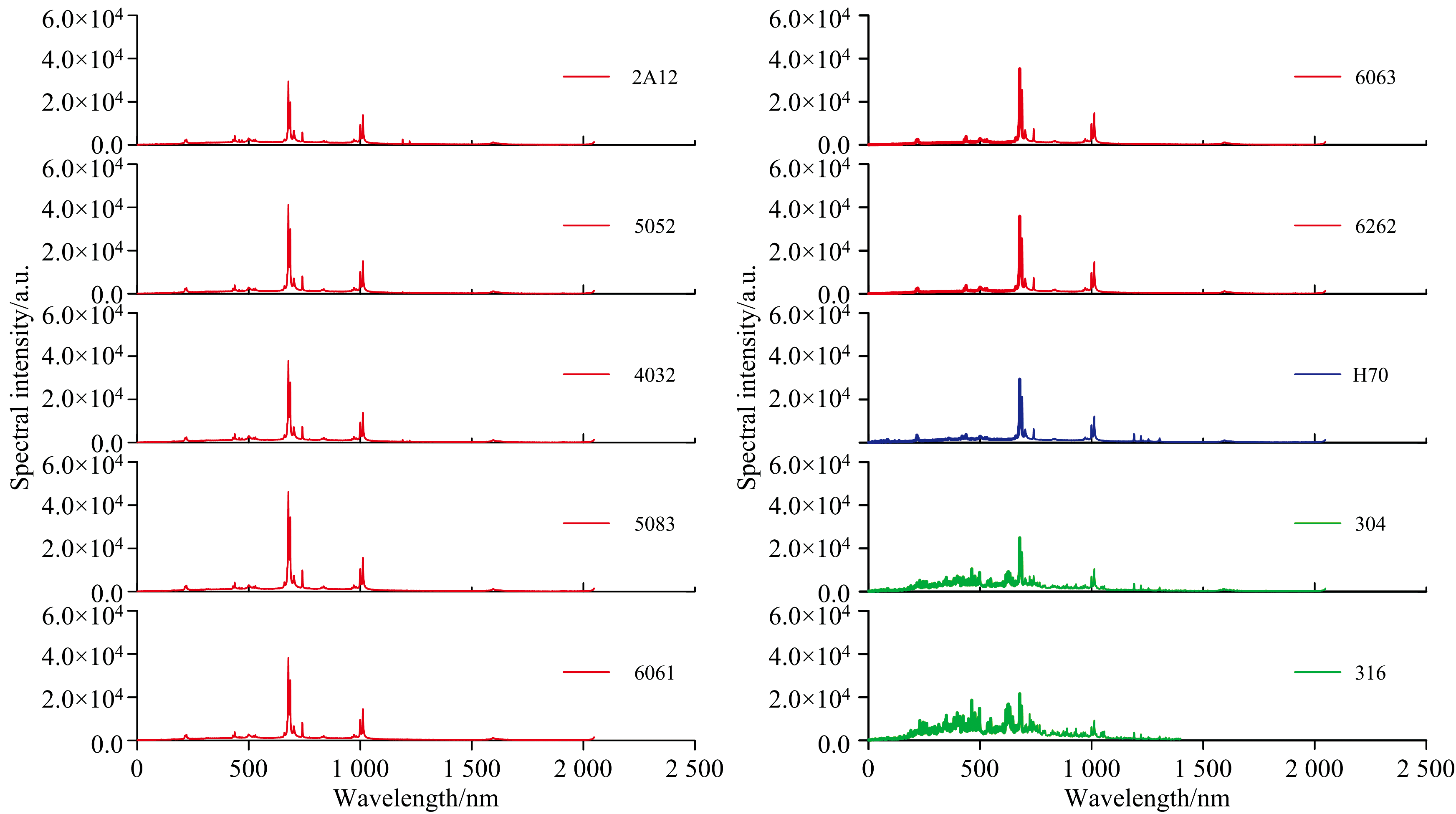 | 图3 合金光谱图像Fig.3 Alloy spectral image |
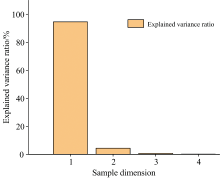
为了找到样品数据中的主要成分, 采用K-means算法对数据集进行初步分类。 在K-means算法的使用过程中发现, 由于数据维度为2 048, 数据维度过大, 直接采用原始数据集分类结果明显不准确。 故采用PCA技术对数据进行降维。 其中方差解释率如图4所示。
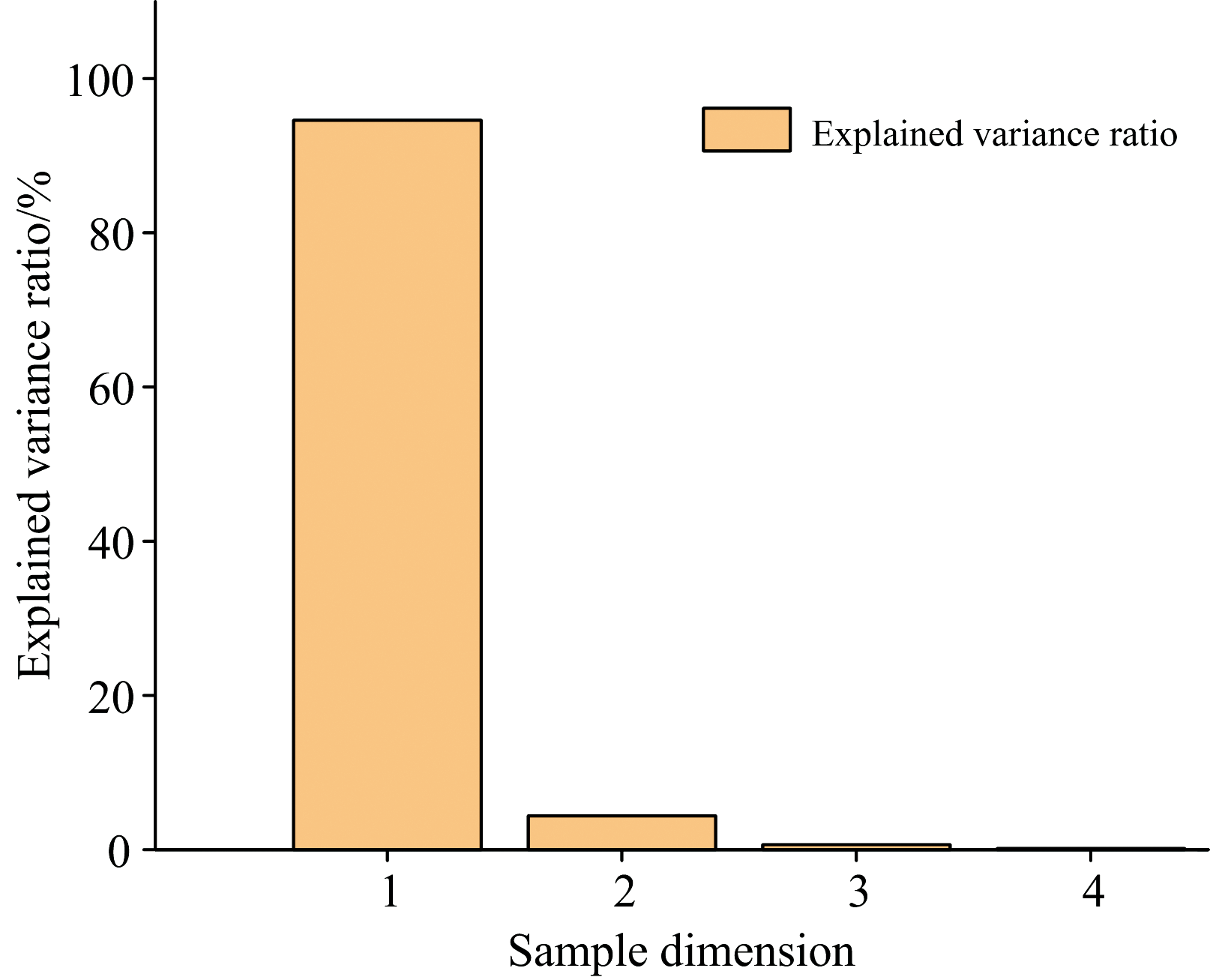 | 图4 PCA方差解释率Fig.4 PCA variance interpretation rate |
由图4知, 前三个维度的方差解释率远大于剩余的维度。 一般而言, 方差解释率在85%~95%之间则可以认为主成分以及解释了大部分数据的方差, 则可以选择保留对应的主成分。 故认为第一个维度开始的信息可以表征原始数据集2 048个维度的特征。 实验过程中, 分别采用前两个, 前三个维度和前四个维度的数据进行测试, 经验证得出结论, 使用前三个维度和前四个维度的数据均可以准确区分出目标合金。 而在使用前两个维度进行测试时, 出现了明显的分类不准确问题, 为在保证分类准确率的前提下降低运算量, 采用前三个维度的数据进行后续工作。 将前三个维度的数据分类结果输入K-means算法中并绘制混淆矩阵, 结果如图5所示。
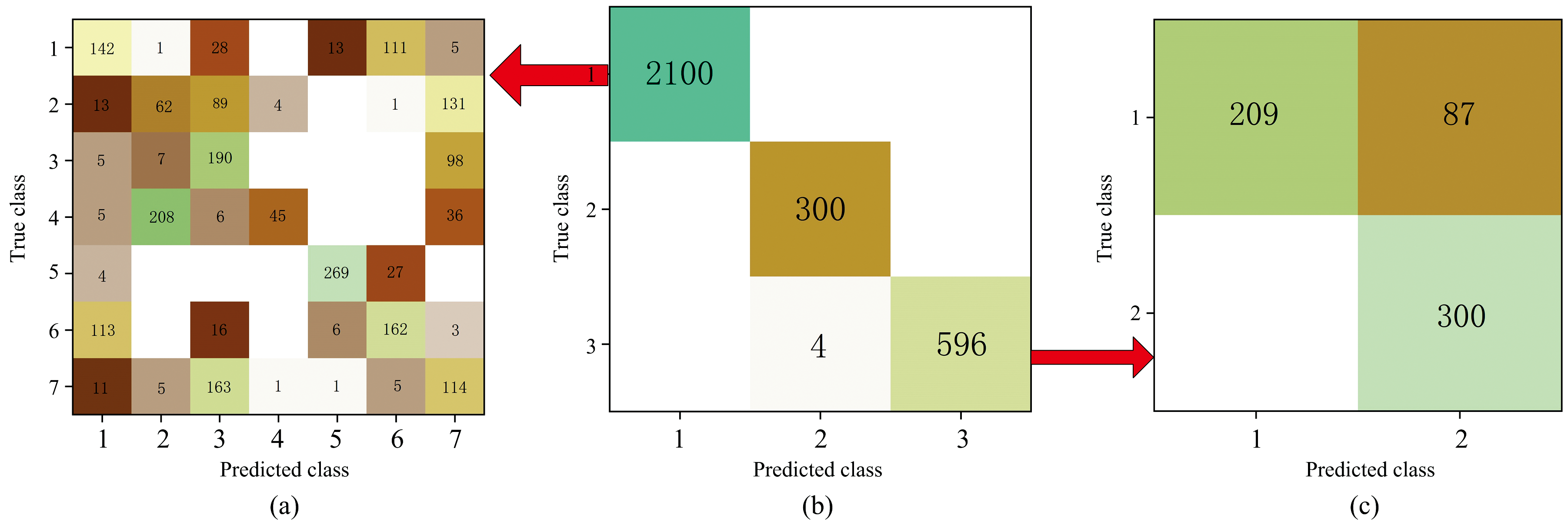 | 图5 PCA-K-means结果混淆矩阵Fig.5 PCA-K-means result confusion matrix |
图5(a, c)表明使用单一K-means算法对七种不同牌号的铝合金、 两种不同牌号的铁合金细分类效果很差, 综合分类准确率仅有59.87%。 在大类相同, 牌号不同的七种铝合金样品中分类准确率下滑到46.86%, 可见单一K-means算法不足以进行复杂牌号混合合金样品的精细分类工作, 但是对三种大类不同元素的粗分类准确率达到了99.97%, 如图5(b)所示。 并且在11th Gen Intel Core i5-1135G7上的运行时间仅为单一CNN模型执行时间的2.28%。
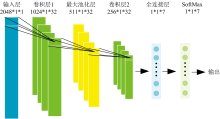
根据光谱的基本物理特性, 不同元素由于其内部电子结构的不同, 它们所产生的光谱的谱线位置亦有所差异, 合金样品中每个元素的含量不同, 其对应波长的谱线强度与之成正比, 根据铝合金光谱数据的特性, 本文构造了一个CNN模型对其进行分类, 由1个输入层, 2个卷积层, 1个最大池化层, 1个全连接层和1个输出层构成, 其结构示意图如图6所示。
 | 图6 卷积神经网络结构Fig.6 Convolutional neural network structure |
在实验过程中, 收集到的合金样品的光谱在不同波段的谱线强度差异过大, 每组数据都具有较大的动态范围, 会因为数值相差悬殊而导致计算过程中出现精度损失。 因此, 需要对算法的输入数据进行归一化处理, 将所有波段的谱线强度调整在[0, 1]范围内, 突出强度相对弱化的波段的贡献, 使CNN算法能够聚焦于所有波段的重要特征信息, 避免因特征尺度差异导致算法训练和预测的性能受到影响。
归一化后的光谱数据作为输入, 输入矩阵的尺寸为2 048× 1。 两个卷积层的参数设置相同, 卷积核尺寸为4× 1, 卷积核个数为32, 步长为2× 1。 为了加速模型收敛并提高计算效率, 选择Relu函数作为激活函数来处理卷积后的结果。 最大池化层在两个卷积层之间用来降低数据的维度并保留数据最重要的特征, 其尺寸为4× 1, 步长为2× 1。 全连接层将前面提取到的7个特征进行整合, 连接在一起组成一个一维数组。 为了处理多分类任务, 输出层损失函数选择Softmax函数, 将输出归一化到(0, 1)内转换成一个概率分布问题, 输出分类标签。
采用Adam梯度下降算法来构建神经网络模型, 硬件环境CPU型号为11th Gen Intel Core i5-1135G7。 为了增强模型的泛化能力, 减轻过拟合, 每次训练打乱训练集, 设置最大训练次数为200, 初始学习率设为0.001, 学习率下降因子设为0.1, 设置每经过50轮训练学习率就下降为原来的10%。 选择训练集的 10%作为批处理样本来更新模型参数, 则批处理样本数目设为175。
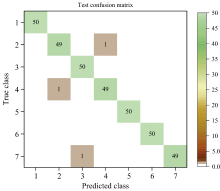
因为每轮训练会打乱输入的训练集, 所以每次训练构建的模型略有不同, 导致对测试集的分类结果不同, 分类准确率也不同。 因此对CNN模型进行重复训练50次, 得出训练集分类的平均准确率为100%, 测试集分类的平均准确率为99.074 3%。 而混合模型分类的综合平均准确率为99.3520%, 其输出混淆矩阵如图7。
 | 图7 CNN输出混淆矩阵Fig.7 CNN outputs the confusion matrix |
对CNN分类出现误判的原因进行分析, 可能的原因如下:
(1)虽然样品匀速移动, 但激光仍会烧蚀样品表面, 导致产生等离子体的聚焦光路发生微小变动, 使同一样品不同时刻收集到的光谱强度在小范围内波动, 加大了分类的难度。
(2)光谱数据维度高, 每组数据具有较大的动态范围, 算法难以聚焦于所有波段的重要信息, 可能会忽略强度较弱波段中的可以区分类别的重要特征。
为了更好地评估CNN算法在铝合金分类问题上的泛化能力以及模型的稳健性, 本文选用5折交叉验证去评估该模型的性能。 将数据集随机等分为五个互斥子集, 每个子集中均含有420个数据。 对于每个子集: 将该子集作为测试集, 其余四个子集作为训练集, 将训练集和测试集均代入与之前配置参数均相同的CNN模型中。 经过五次迭代后, 将每次训练后得出的模型准确率取平均作为5折交叉验证的结果, 并计算五次迭代训练结果中模型测试集分类的准确率的方差。 最终运行得出训练集分类的平均准确率为100%, 测试集分类的平均准确率为99.523 8%, 方差为0.028 3。 该模型在五折交叉验证中的结果准确率高, 方差小, 证明该模型具有很强的泛化能力和稳健性。
为了验证混合模型的优越性, 将其与单一CNN模型进行对比。 两种模型对10种合金样品分类50次的准确率分布如表2所示。 单一CNN模型重复训练50次, 得到对10种合金样品的平均分类准确率为99.152 0%。 而混合模型的综合平均准确率为99.352 0%, 高于单一CNN模型的平均准确率, 说明混合模型相比于传统单一模型分类效果更佳。 进一步比较两种模型分类结果的稳定性, 混合模型分类50次的准确率的标准差小于单一CNN模型, 说明混合模型分类的准确率在不同数值出现的离散程度小, 分类结果的稳定性和可靠性强于单一CNN模型。 在相同条件下, 以对10种合金样品分类50次为一组, 两种模型分别执行了两组并进行比较,
| 表2 两种模型对10种合金样品分类50次的准确率分布 Table 2 Accuracy distribution of classification of 10 alloy samples for 50 times by two models |
单一CNN模型的平均准确率不同, 分别为99.148 0%和99.248 0%, 而混合模型的平均准确率相同都为99.352 0%。
由此可见, 混合模型分类结果的稳定性更强。 并且由于混合模型中使用K-means算法进行初步分类, 确保分类准确的同时替代了CNN的部分功能, 由于K-means算法本身计算量较小, 结构简单的特性, 算法整体对处理器性能的要求进一步降低。
以上实验结果证明, 与传统的单一CNN模型相比, K-means-CNN混合模型对于复杂牌号混合合金样品分类的平均分类准确率更高, 分类结果的稳定性更强, 随机性更小。 且混合模型先采用K-means进行大类区分, 再采用CNN进一步对7种铝合金样品进行细分类, 相较于单一CNN模型直接对10种合金样品进行分类, 节省了对铜合金和铁合金细分类的计算机资源, 从而节省了21.94%的运行时间, 可以搭载在更轻量级的CPU中使用, 从而应用在嵌入式, 便携式LIBS系统中。
在当前激光器轻量化, 便携化的要求下进行合金分类时需要更多的关注数据量, 运算效率等问题, 单一CNN模型往往需要高性能的处理器, 便携化的小型系统通常不能满足算法的性能要求。 本文设计的K-means-CNN模型, 针对复杂牌号混合合金样品分类的问题进行了有效的解决。 在主要成分为Al, 次要成分为Fe, Cu的多牌号混合合金中, 正确的提取了主要元素Al, 对样品分类的平均准确度达到99.352 0%, 并进行了5折交叉验证, 准确率达到99.523 8%, 证明了模型的泛化能力。 同时运行时间提升了21.94%, 因此, 通过实验验证了该混合算法模型相对单一CNN模型可以在降低运算量的同时实现对多种牌号混合合金快速, 准确的分类, 更适用于当前轻量化, 便携化的LIBS系统。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|