
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱纯牛奶智能识别
[胡少文 , 黄浪鑫
, 黄浪鑫* , 余里辉, 吴志平, 李怀玉, 施炜利, 罗洪昱]
, 黄浪鑫, 余里辉, 吴志平, 李怀玉, 施炜利, 罗洪昱]
|
|


作者简介: 胡少文, 1987年生,江西省科技基础条件平台中心高级工程师 e-mail: 806814726@qq.com
为防止纯牛奶以次充好和优化纯牛奶检测手段, 提出了一种基于近红外光谱的纯牛奶智能识别方案。 首先, 采用傅里叶近红外光谱仪获取了同一品牌的不同纯牛奶在4 000~10 000 cm-1波段内的近红外光谱。 由于获取的近红外光谱信号数据相对冗余, 采用主成分分析算法对该波长范围内的近红外光谱信号数据进行特征信息的提取以提升纯牛奶的识别效率, 分别提取了贡献程度较大的四个主成分作为训练和测试样本数据。 随后, 采用BP-ANN算法(反向传播人工神经网络)对获取的样本数据进行初步训练和测试。 测试结果表明, 融合主成分分析的BP-ANN算法对纯牛奶分类识别效率不仅得到了提升, 而且准确率最优可达95%。 为进一步提升算法的识别准确率, 还添加了粒子群算法对BP-ANN中的权值和阈值参数进行优化, 另外, 还提出了一种新型动态递减的惯性权重因子函数, 用来优化粒子群算法中的惯性权重因子。 实验表明, 识别准确率可提高至100%。 因此, 基于近红外光谱的纯牛奶智能识别方案能够准确有效地实现纯牛奶种类鉴别。
To prevent the adulteration of pure milk and optimize the detection methods of pure milk, a recognition scheme for pure milk based on near-infrared spectroscopy is proposed in this paper. Firstly, a Fourier near-infrared spectrometer was adopted to obtain the near-infrared spectroscopy signals of different pure milk products from the same brand within the wavelength range of 4 000~10 000 cm-1. Since the obtained near-infrared spectroscopy signal data is relatively redundant, this paper utilized a principal component analysis algorithm to extract the feature information of the near-infrared spectroscopy signal data within this range to improve the recognition efficiency of pure milk. Four principal components with larger contributions were extracted to obtain the training and testing sample data. Then, the back propagation neural algorithm was employed for preliminary training and testing of the obtained sample data. The test results show that the BP neural network algorithm combined with principal component analysis improves recognition efficiency of pure milk and achieves an accuracy of up to 95%. To further improve the algorithm's accuracy, the particle swarm optimization algorithm was added to the proposed pure milk recognition scheme to optimize the weights and thresholds in the BP neural network. Additionally, a new dynamic decreasing inertia weight factor function was proposed in the particle swarm optimization algorithm for the inertia weight factor. Experiments show that the accuracy of the proposed intelligent recognition scheme for pure milk can be increased to 100%. Therefore, the intelligent recognition scheme for pure milk based on near-infrared spectroscopy can accurately and effectively identify the types of pure milk.
近年来, 食品安全问题屡见不鲜, 各类食品打假视频也越来越多, 究其原因有以下两点, 一是商家用低价低质量的商品假冒高价高质量的商品, 从中谋取暴利; 二是相关检测方法还不够先进, 如通过肉眼等方法检测校验, 导致很多假冒伪劣商品流入市场。 纯牛奶是我们日常生活中最重要的食品之一, 因它的营养价值非常丰富, 对人体的帮助良多, 因而成为日常生活中必备的一种商品。 首先, 纯牛奶中含有较高的蛋白质, 能够调节人体的神经系统并且有助于增强睡眠质量; 其次, 纯牛奶中的钙含量能够促进小孩的生长发育和预防老年人的骨质疏松。 但是在可食用奶制品领域, 发生过多次商家利用伪劣牛奶假冒真实牛奶的事件, 这无疑给食品安全带来了不良影响。 比如众所周知的“ 三鹿奶粉” 事件[1, 2], 商家为了谋取暴利, 对我国婴幼儿身体造成不可逆的损伤。 因此, 人们对牛奶的品质和选择更加警惕。 然而, 由于市场上纯牛奶多种多样, 不同种类的牛奶在价格和营养价值方面也有所差异, 然而消费者从外观和口感上很难区分。 为了避免假冒伪劣的纯牛奶进入市场, 同时让消费者能够正确辨别纯牛奶种类, 研究一种快速、 准确和无损的纯牛奶种类鉴别技术意义重大。
传统的鉴别牛奶的方法有感官法[3, 4]和化学检验方法[5, 6]。 因为不同种类的纯牛奶颜色相似, 从视觉、 嗅觉和味觉上判断难免会有较大的误差, 而化学检验方法需要对样品进行化学处理, 比如加入碳酸钠、 碳酸铵等, 容易破坏样本并且有一定的危险性。 迄今为止, 国内外学者已经采用多种不同方法对奶制品检测进行了研究。 Cao等[7]提出了使用液相色谱-四级杆/静电场轨道阱质谱法测定牛奶中的22种真菌霉素。 Wang等[8]研究了使用近红外透射光谱法对四种乳制品品种进行快速鉴别的方法, 预测达到了较好的识别率。 Brudzewski等[9]基于电子鼻技术通过半导体气体传感器检测不同牛奶挥发出来的气味, 对实验数据采用支持向量机(support vector machine, SVM)算法实现牛奶的分类识别。 随着研究人员的深入, 近些年近红外光谱技术已经在很多方面有应用[11, 12, 13, 14, 15, 16], 得益于其具有高效、 准确、 检测成本较低、 操作简单、 不需要对样品进行预处理、 无污染、 可多组分同时检测等优点, 可以有效避免传统检测方法的不足, 可为快速检测提供技术支撑, 实现在线监测分析。
国内外近红外光谱技术在牛奶检测中的研究近年来已有诸多成果。 例如, 卞希慧等[26]提出了一种基于高频和低频展开偏最小二乘判别分析(HLFUPLS-DA)的近红外光谱模式识别模型, 用于快速识别牛奶样本。 该方法通过经验模态分解(EMD)将光谱分解为不同频率成分, 再将高频和低频成分分别扩展为矩阵, 最终建立PLS-DA模型, 成功应用于不同品质牛奶样本的识别。 陈辉及其团队[27, 28, 29]在近红外光谱技术应用于牛奶检测领域也取得了显著成果。 2017年, 他们提出了一种基于近红外光谱和一类偏最小二乘法(OCPLS)分类器的检测方法, 用于快速筛查牛奶样本中的三聚氰胺掺假, 无需复杂预处理即可实现高灵敏度检测。 2018年, 团队进一步研究了近红外光谱结合基于互信息的变量选择和偏最小二乘法(PLS-DA或PLSR), 对不同品牌奶粉进行分类及蛋白质含量定量分析。 2021年, 他们又采用近红外光谱结合极值学习机的集成学习算法(EELM), 对不同品牌的液态奶进行分类, 结果表明该方法具有较高的分类准确率和鲁棒性。 Elainy Virginia dos Santos Pereira等[30]采用近红外光谱(NIR)技术结合偏最小二乘法(PLS)算法, 实现了山羊奶中掺假牛奶的识别以及脂肪和蛋白质含量的同时测定。 研究通过主成分分析(PCA)和偏最小二乘判别分析(PLS-DA)对掺假样本进行分类, 并通过区间偏最小二乘法(iPLS)和区间选择算法(iSPA-PLS)提高了模型的定量分析性能。 这些研究为牛奶品质检测和食品安全提供了高效、 准确的技术手段。
目前, 近红外光谱技术尽管已经用于乳制品检测中, 但是检测效果并不佳, 智能算法的快速发展有效弥补了这一缺点。 为此, 本工作提出一种基于近红外光谱的纯牛奶智能识别方案。 对同一品牌不同种类的纯牛奶样品进行多波段数据采集。 基于采集的数据, 通过不断优化和改进算法结构, 进一步提高了纯牛奶种类分类识别的准确度。 可以有效的检测出不同种类的牛奶, 能有效抑制牛奶以次充好。
根据Lambert-Beer定律: 溶液吸收或透过的光强是溶液中吸收物质浓度与光通过样品光程长的指数函数[17]。 即
由此推导出
式(2)中, I0为入射光强, I为出射光强, c为溶液浓度, b为光程长, ε 为消光系数。
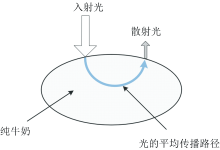
在实际应用中, 为了有效地获取样品的光谱信息, 需要选择合适的测量方法。 其中, 漫反射测样是一种特别适用于液体样品的测量技术。 光进入被测对象后被吸收、 散射, 被测对象中的成分对不同波长近红外光的吸引与散射强度不同。 漫反射测样原理如图1所示。
 | 图1 漫反射测样原理图Fig.1 Schematic diagram of diffuse reflectance measurement |
主成分分析(PCA)[18, 19]也称为主分量分析, 是一种通过降维方式来简化数据特征复杂度的方法, 即用少数几个代表性强的特征来代替原来的全部特征, 被选取的这几个特征要能够反映原来特征的大部分信息, 并且各个特征之间保持独立, 以避免出现重叠信息。 可以用式(3)表示, 即
式(3)中, X1, X2, …, Xp为原始变量(下标p表示变量的个数), F1, F2, …, Fk为新变量, 即主成分(下标k表示新变量的个数), upk为载荷系数。
采用监督型BP-ANN[20, 21, 22, 23]对不同种类的纯牛奶进行分类识别, 训练过程中通过梯度下降法自动调整网络中的权值和阈值, 最终目的是使网络的期望输出值和实际输出值的均方误差最小。
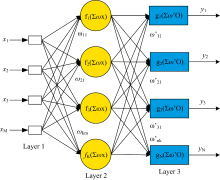
BP-ANN由3层网络构成, 如图2所示。 其中输入层有m(m=1, 2, …, M)个神经元, 给出p组输入的主成分数据为
 | 图2 BP-ANN网络结构Fig.2 Structure of BP-ANN network |
隐含层神经元传递函数采用Sigmoid函数, 输出层神经元传递函数采用线性函数。 即
BP-ANN隐含层的输出
式(5)中, wkm为输入层和隐含层之间的权值。
BP-ANN输出层的输出
式(6)中, wnk为隐含层与输出层之间的权值。
BP-ANN网络的实际输出为y(n)=
式(7)中,
另外, 通过构造上述BP-ANN网络, 在进行纯牛奶样本训练时, 采用误差反向传播算法对权值wkm和
式(8)中, $w_{k m}^{o l d}$和$w_{n k}^{o l d}$为调整前的权值,$w_{k m}^{n e w}$和$w_{n k}^{n e w}$为调整后的权值,$\eta$为学习率因子。
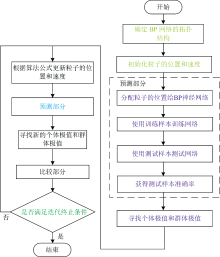
为了提高BP-ANN对不同纯牛奶分类识别准确率, 采用粒子群优化算法(partial swarm optimization, PSO)[24, 25]对BP-ANN的初始权值和阈值(ω nk和ω km)进行优化。 经PSO优化的BP-ANN算法流程框图如图3所示。
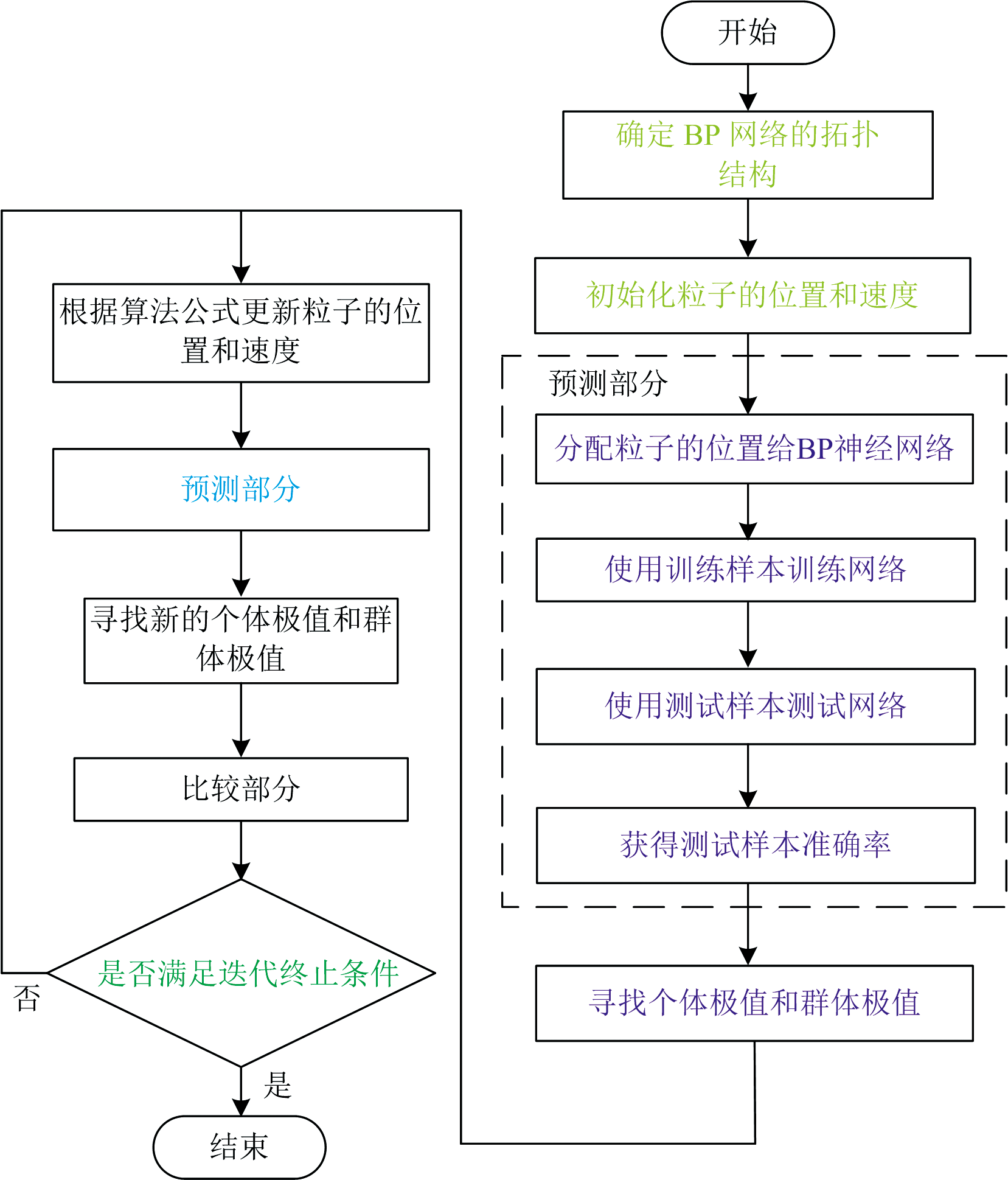 | 图3 PSO算法流程图Fig.3 Flow chart of PSO algorithm |
在PSO算法最优解的搜寻过程中, 需要对飞行速度和飞行方向按式(9)进行调节, 即
式(9)中, vi(n)为第i个粒子的初始速度, i=1, 2, …, M, M为总粒子个数; vi(n+1)为更新后的第i个粒子的速度。 ω 为惯性权重因子, 满足ω ∈ [0, 1]。 c1和c2为两个加速度因子, r1和r2为两个随机数, 它们满足(0, 1)的随机均匀分布。 xi(n)为粒子的初始方向, xi(n+1)为更新后的粒子方向。 Pi为局部最优粒子方向, Gi为全局最优粒子方向。 k为迭代次数索引。
实验设备使用美国的Antaris Ⅱ 傅里叶近红外光谱分析仪。 其分辨率为8 cm-1, 扫描次数为32次, 波长范围为4 000~10 000 cm-1, 光谱采样间隔为3.86 cm-1, 光谱数据以excel形式导出, 仿真平台为MATLAB 2022a。
实验中采用了从超市购买的伊利品牌下的四种不同的纯牛奶作为实验样品, 分别是纯牛奶, 金典纯牛奶, 金典有机纯牛奶, 脱脂纯牛奶, 如图4所示。 每种牛奶制备50组样本, 总样本数为200组。
 | 图4 实验样品 (a): 纯牛奶; (b): 金典纯牛奶; (c): 金典有机纯牛奶; (d): 脱脂纯牛奶Fig.4 Experimental samples (a): Pure milk; (b): JINDIAN pure milk; (c): JINDIAN organic pure milk; (d): Evaporated pure milk |
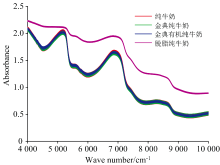
采用近红外光谱仪对四种不同纯牛奶进行了积分球漫反射光学检测。 实验中, 将一定量(约10 mL)的牛奶装入样品杯中, 然后置于积分球样品窗口中, 获取了全波段范围4 000~10 000 cm-1下的四种不同纯牛奶的吸光度谱如图5所示。
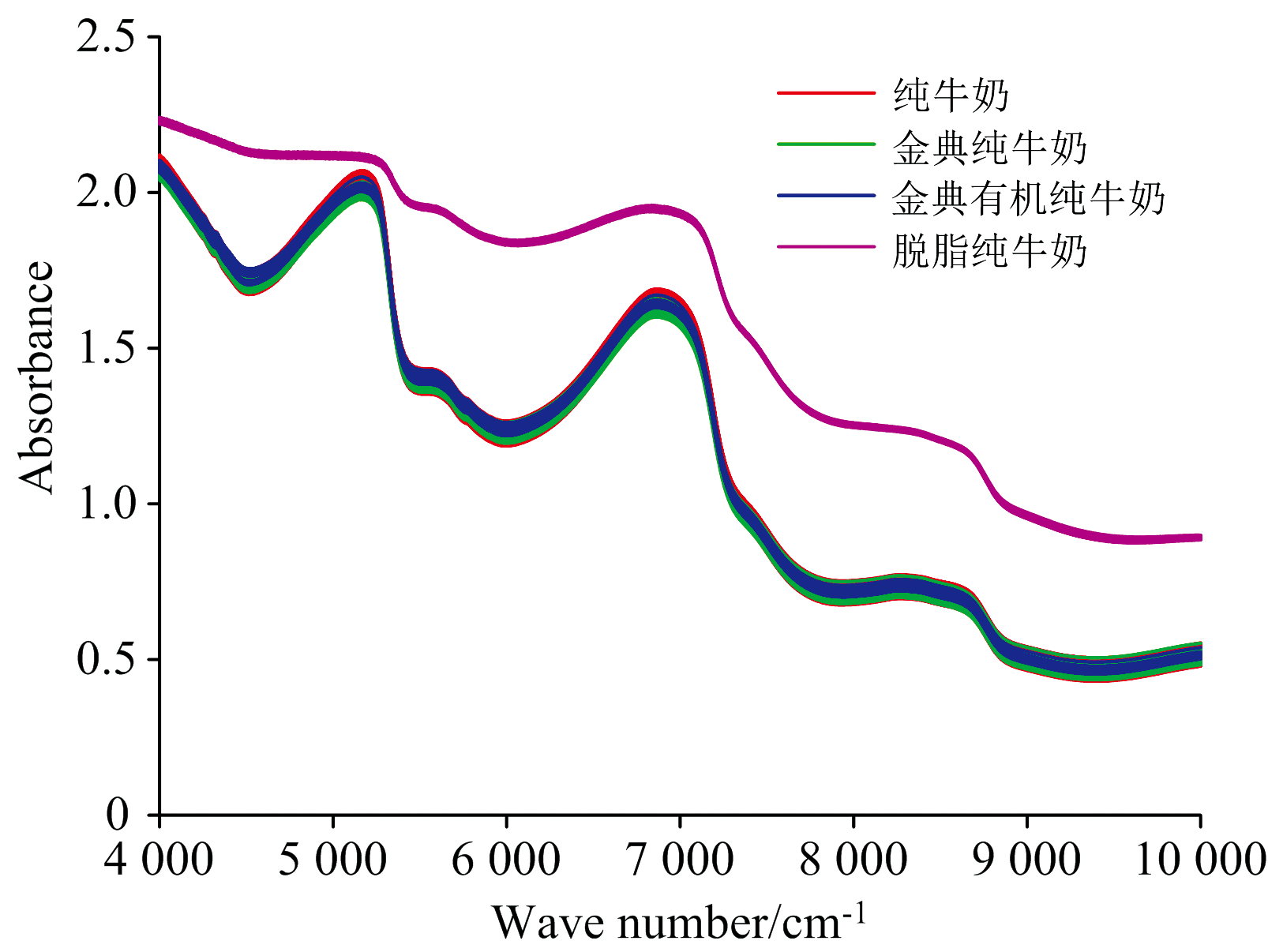 | 图5 4 000~10 000 cm-1不同纯牛奶的吸光度谱Fig.5 Absorbance spectra of different pure milk samples at 4 000~10 000 cm-1 |
从图5中可知, 纯牛奶, 金典纯牛奶和金典有机纯牛奶的光谱出现了严重的混叠现象, 肉眼难以区分, 但是脱脂纯牛奶的光谱与其他三种有明显的分隔, 从视觉上较好区分, 为了能够准确区分各种纯牛奶, 后面采用人工智能算法对光谱数据进行分析和处理。
3.2.1 基于PCA结果及分析
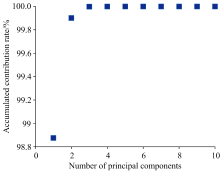
由于直接将全波段范围的各种奶样的光谱信号作为BP-ANN的输入样本, 容易造成网络结构模型复杂, 影响不同纯牛奶分类识别的准确率, 故采用PCA算法提取输入样本的主要特征成分。 为更好的反映全波段范围的光谱数据信息, 提取了累计贡献率大于95%以上的10个主成分, 如图6 所示。
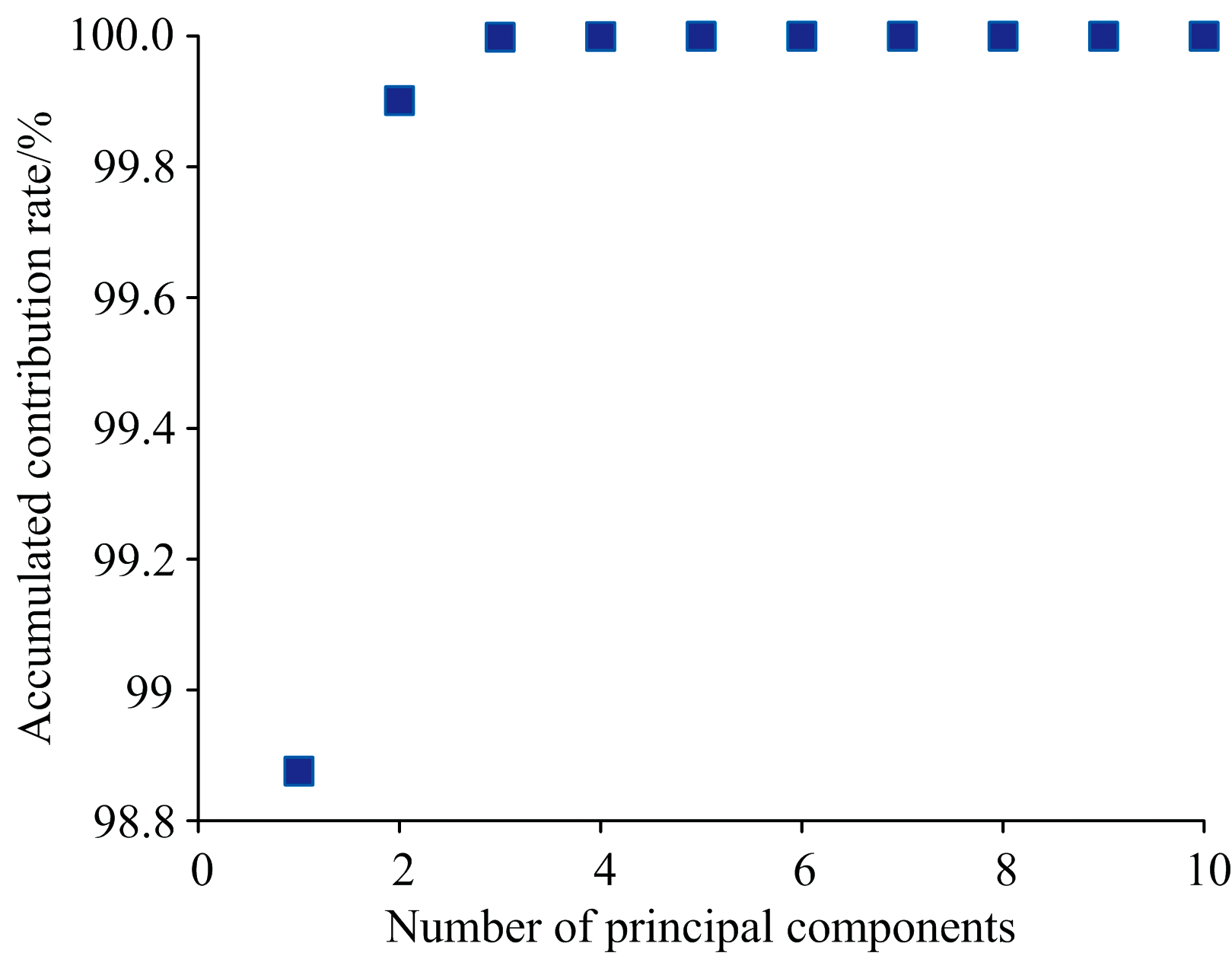 | 图6 主成分分析图Fig.6 Diagram of Principal component analysis |
从图6可知, 第一个主成分的累计贡献率约为99.91%, 随着主成分个数的增加, 累计贡献率在不断增大, 到第四个主成分的时候, 累计贡献率约为100%, 后面主成分再增加, 累计贡献率收敛。 因此, 选择4个主成分即可。
3.2.2 基于PCA-BPANN分类识别结果及分析
为了实现不同纯牛奶高准确率鉴别, 采用BP-ANN进行分类识别, 将选取的主成分特征作为输入样本, 并用数字1、 2、 3和4作为类别标签, 分别标记纯牛奶, 金典纯牛奶, 金典有机纯牛奶, 脱脂纯牛奶。 随机从四种牛奶中各选取40组样本进行训练和10组样本进行测试, 为了找到BP-ANN中最优的隐含层神经元个数从而提高对纯牛奶分类识别的准确率, 采用公式
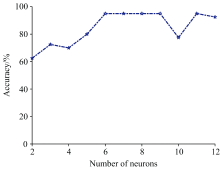
为了得到BP-ANN算法中最优隐含层神经元个数, 将选取的4个主成分下BP-ANN算法中隐含层神经元个数对不同纯牛奶分类识别的影响进行对比, 结果如图7所示。
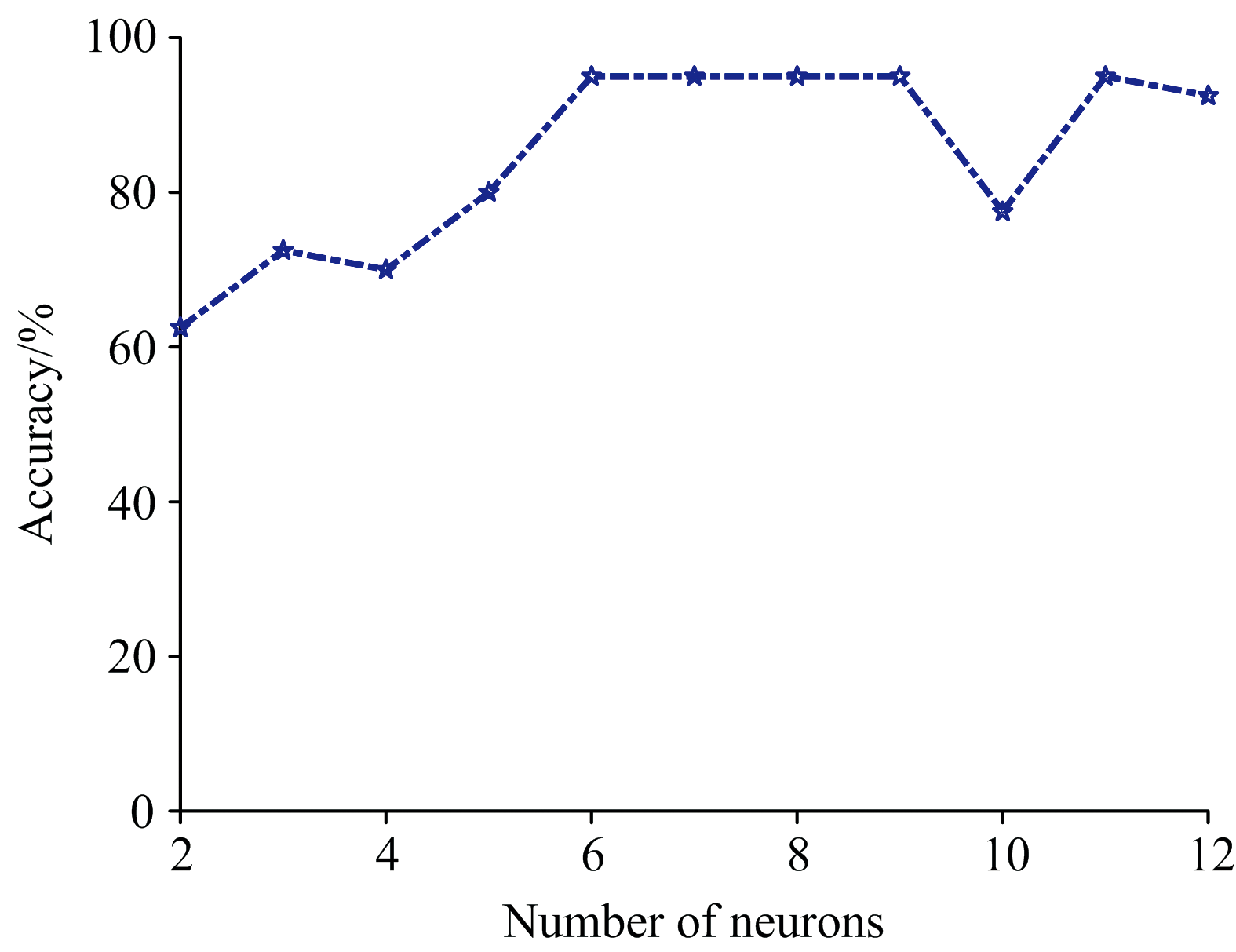 | 图7 4个主成分BP-ANN算法隐含层神经元个数对不同纯牛奶分类识别准确率结果对比Fig.7 Comparison of the accuracy of different pure milk classification and recognition based on the number of neurons in hidden layer for four principal component BP-ANN algorithm |
从图7可知, 对于4PC-BPANN(4个主成分), 其隐含层神经元为6时, 识别准确率最高, 保持在95%。
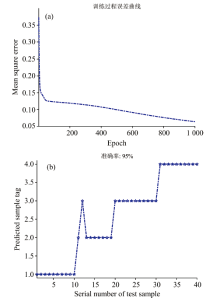
图8(a)给出了选取的4个主成分BP-ANN算法训练次数对纯牛奶识别均方误差的影响以及测试样本的预测结果。
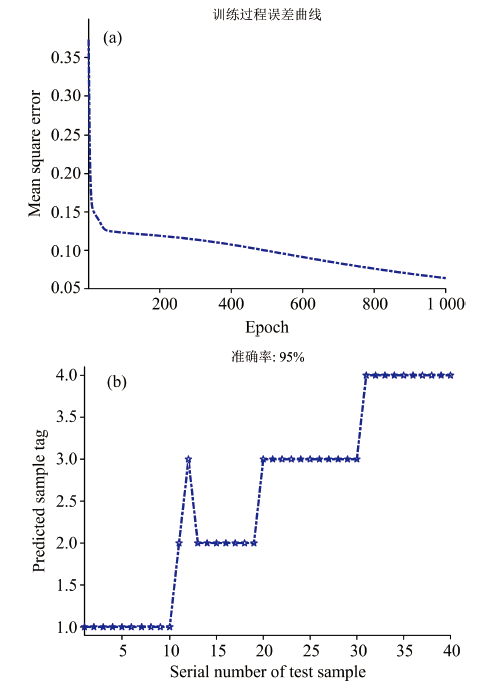 | 图8 4个主成分BP-ANN算法对不同种类牛奶的分类识别效果 (a): 训练次数对均方误差的影响; (b): 测试样本的预测结果Fig.8 Classification and recognition performance of different types of milk using four principal component BP-ANN algorithm (a): Effect of training times on mean square error; (b): Predicting results of test samples |
图8(b)给出了4个主成分的BP-ANN测试样本的预测结果, 从图中可知, 1组金典有机纯牛奶样本被错分成金典纯牛奶样本, 错误率为5%。
3.2.3 基于PSO-PCA-BPANN分类识别结果及分析
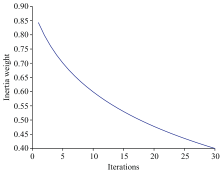
为了进一步提高对不同牛奶的分类准确度, 在4PC-BPANN的基础上, 采用PSO优化BP-ANN中的权值和阈值参数, 期间, 对PSO算法中惯性权重因子进行了优化, 因为惯性权重因子对PSO算法在预测牛奶性能上有重要的影响, 当ω 取值较大时, 全局搜索能力变强而局部搜索能力较弱, 当ω 取值较小时, 局部搜索能力变强而全局搜索能力较弱, 为了更好地平衡算法的全局搜索和局部搜索能力, 提出了一种新型动态递减的惯性权重因子函数。 即
式(10)中, k是当前迭代次数, Tmax是最大迭代次数, 在程序中Tmax设置为100, ω start是初始惯性权重, ω end是终止惯性权重, 在程序中ω start设置为0.9, ω end设置为0.4。 函数曲线如图9所示。
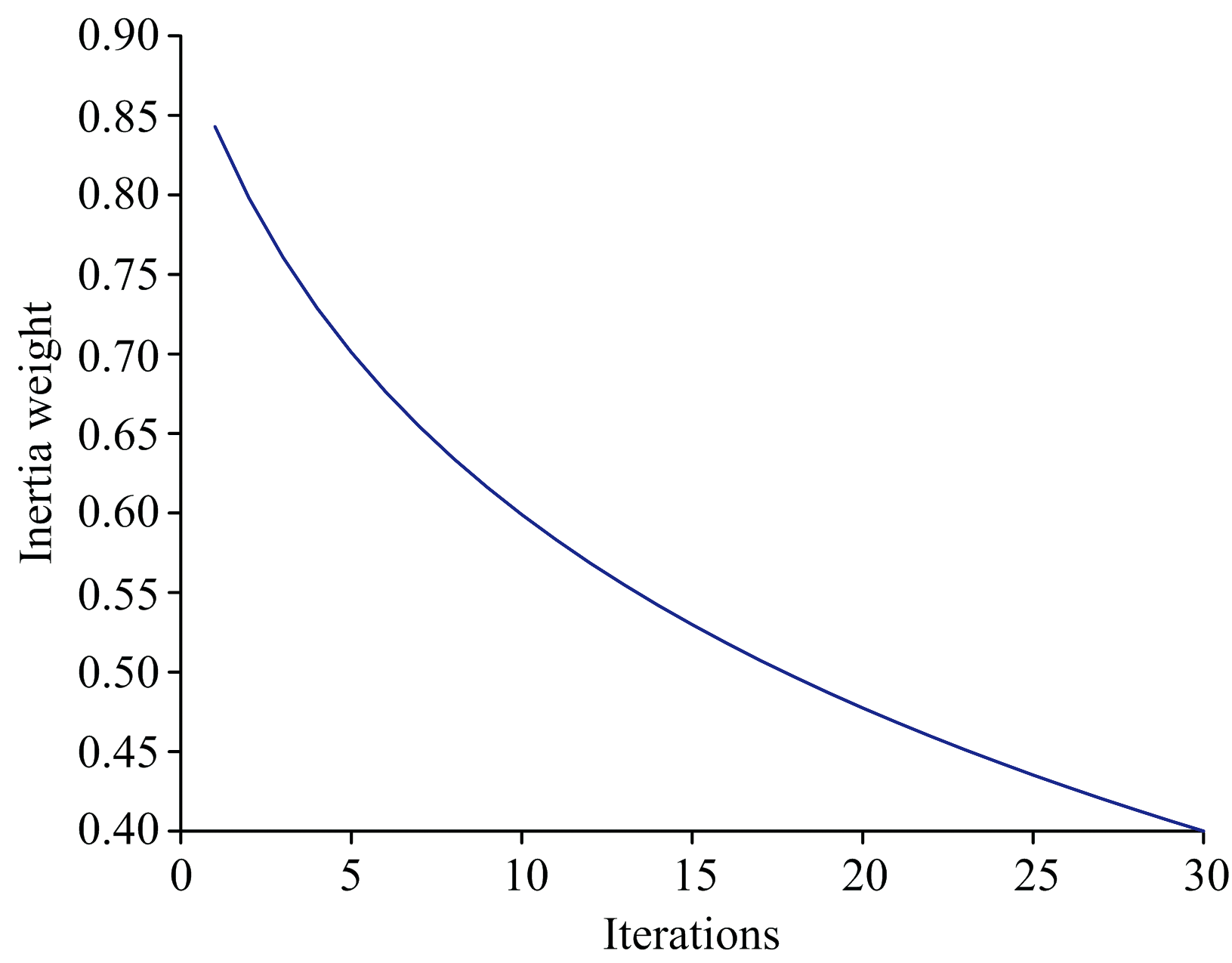 | 图9 动态惯性权重的函数曲线Fig.9 Function curve of dynamic inertia weight |
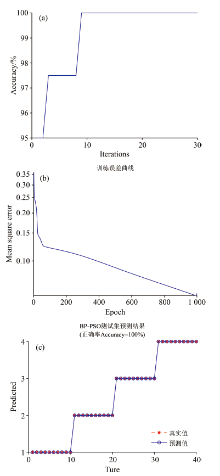
图10给出PSO-BPANN算法下迭代次数对准确率的影响, 训练次数对均方误差的影响以及测试样本的预测结果。
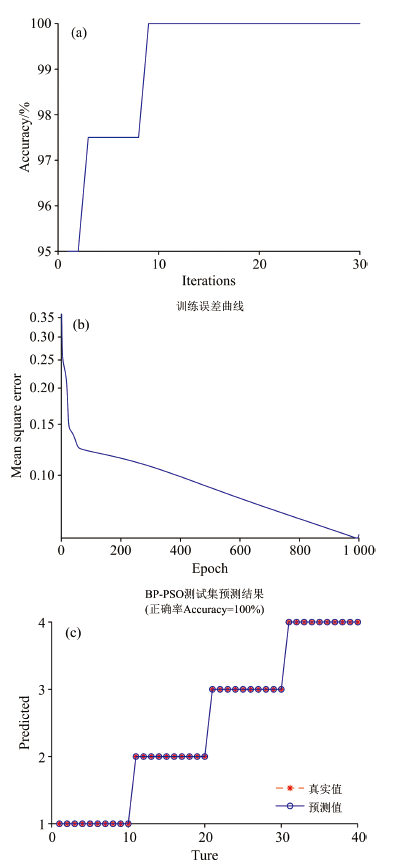 | 图10 PSO-BPANN算法下对不同种类牛奶的分类识别效果 (a): 迭代次数对准确率的影响; (b): 训练次数对均方误差的影响; (c): 测试样本的预测结果Fig.10 Classification and recognition results of different kinds of milk based on PSO-BPANN algorithm (a): Effect of iteration times on the accuracy; (b): Effect of epoch numbers on mean square error; (c): Predicting results of test samples |
从图10(a)中可知, 当迭代刚开始时, PSO-BPANN对不同牛奶的分类识别率为95%, 等于4PC-BPANN的识别率。 随着迭代次数的增加, PSO-BPANN对不同牛奶的分类识别率逐渐增大, 当迭代次数增加至5时, PSO-BPANN对不同牛奶的分类识别准确率达到最大值97.5%, 当迭代次数超过9时, 算法准确率始终保持在100%。
从图10(b)中可知, 随着训练次数增加, PSO-BPANN对不同牛奶识别均方误差呈指数形式减小, 且PSO-BPANN的均方误差小于4PC-BPANN算法。
在确定了PSO-BPANN算法的最优参数情况下, 对40组测试样本进行了预测, 测试结果如图10(c)所示。 从图中可知, PSO-BPANN算法对40组测试样本的分类识别准确率为100%。
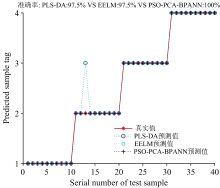
另外, 本文对PSO-PCA-BPANN模型的结果与PLS-DA(偏最小二乘判别分析)和EELM(极值学习机集成学习)的结果进行了对比分析。 如图11所示, PLS-DA和EELM模型的识别准确率均为97.5%。 在PLS-DA和EELM模型中, 有一个金典纯牛奶样本被误分类为金典有机纯牛奶。 相比之下, PSO-PCA-BPANN模型的分类准确率达到了100%, 表明该模型在鉴别分析中具有更高的准确性和鲁棒性。
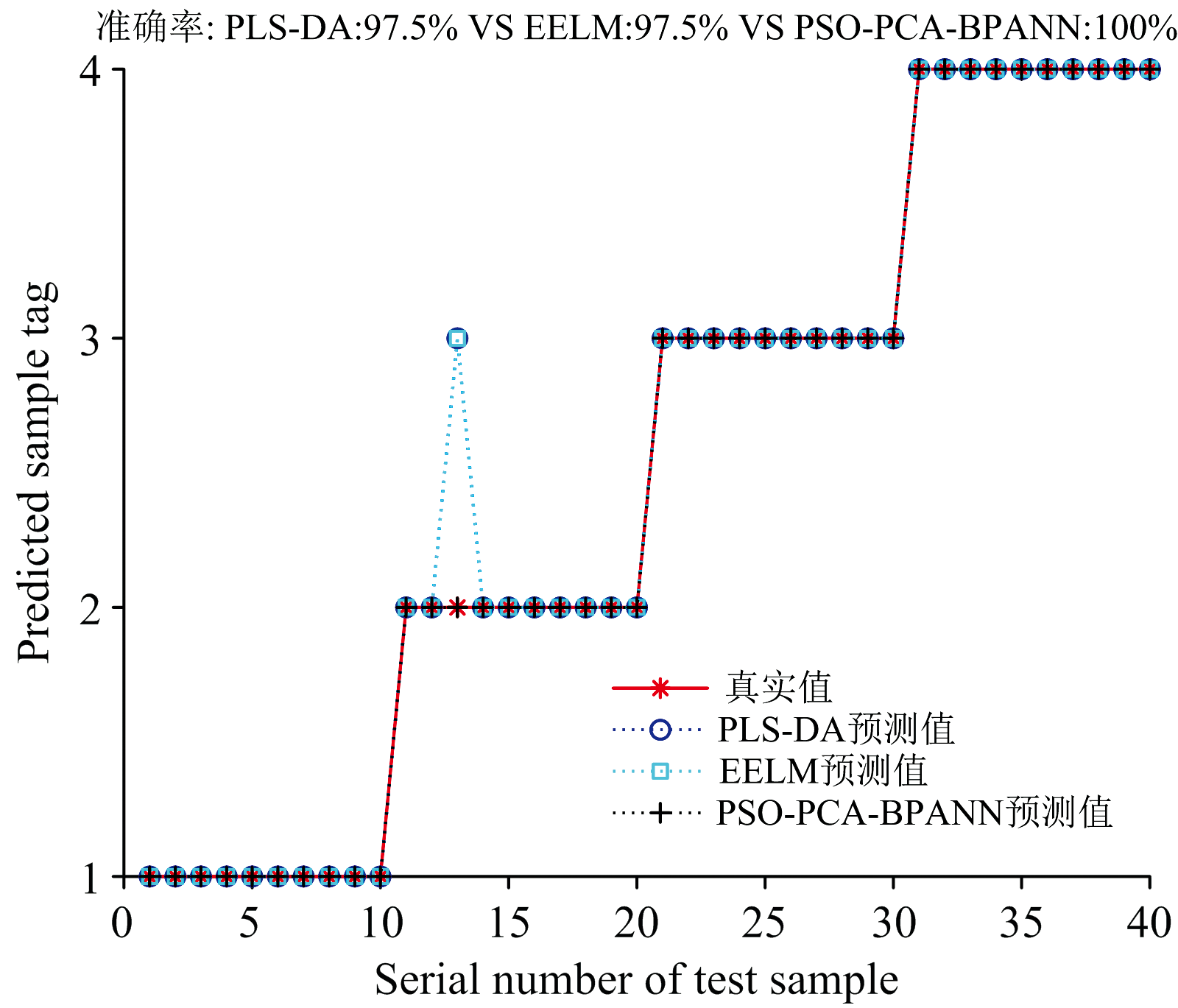 | 图11 不同模型之间的效果对比Fig.11 Comparison of effects between different models |
由于纯牛奶能够为人体提供丰富的营养成分, 所以纯牛奶品质的保证不言而喻, 开展不同纯牛奶的分类鉴别对保障食品安全和医疗卫生等方面至关重要。 利用近红外光谱技术结合PSO-PCA-BPANN智能算法实现了对不同纯牛奶的高准确度分类识别, 同时对牛奶样本未造成任何破坏, 可以实现无损检测。 将实验结果总结为以下几点:
(1) 采用傅里叶近红外光谱仪获取了四种不同纯牛奶的吸光度谱。 从中发现纯牛奶、 金典纯牛奶和金典有机纯牛奶的光谱发生了严重的混叠现象导致肉眼难以辨别。
(2) 为了实现不同纯牛奶的分类识别, 采用了PCA算法提取了全波段范围下光谱信号的主成分特征, 而后采用了BP-ANN算法对输入的主成分数据进行建模, 为了得到BP-ANN算法中最优的一组参数从而提高对纯牛奶分类识别的准确率。 期间, 调整了PCA-BPANN算法中隐含层神经元个数。 实验结果表明, 在4PC-BPANN融合算法下, 对不同种类的纯牛奶识别准确率为95%。
(3) 采用PSO优化BP-ANN中权值和阈值参数, 并提出了一种新型动态递减的惯性权重因子函数, 在PSO-BPANN算法下将准确率提高到100%。 因此, 近红外光谱技术联合PSO-PCA-BPANN算法在纯牛奶的分类识别方面有较好的应用价值。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|