

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱和LOF的蛋清粉非定向掺杂鉴别研究
[祝志慧1, 2  , 李沃霖
, 李沃霖1 , 韩雨彤1 , 叶文杰1 , 金永涛1 , 王巧华1, 2 , 马美湖3 ]
, 李沃霖|
|


作者简介: 祝志慧,女, 1975年生,华中农业大学工学院副教授 e-mail: zzh@mail.hzau.edu.cn
蛋清粉的掺杂鉴别技术对保障蛋粉质量安全具有重要意义, 然而目前传统的生物分子检测方法存在操作复杂且耗时长的问题, 且针对蛋清粉的掺杂鉴别模型仍主要为定向鉴别模型, 其检测范围有限, 无法有效覆盖所有可能的掺杂物质, 亟需开发一种快速、 准确、 泛用的蛋清粉掺杂鉴别方法。 该研究引入近红外光谱检测技术, 构建了LOF非定向鉴别模型。 该模型是一种无监督单分类模型, 且在原模型基础上加入MSC预处理和CARS波长筛选处理, 提高模型提取光谱特征的能力, 减少噪声干扰, 降低模型计算量。 试验结果表明, LOF非定向鉴别模型针对掺杂蛋清粉的检测率可达到93.6%, 其准确率、 精确率、 召回率、 F1分数分别达到了93.6%、 95.5%、 93.6%、 94.5%, 针对掺杂浓度超过15%的蛋清粉, 可达到100%的检测率, 两种测试集的总准确率( AAR)均为93.6%, 平均检测时间( AATS)可达到0.001 1 s; 与其他非定向算法相比具有更高的精度, 且相比于传统的定向模型泛用性更强, 更适合应用于市面上掺杂种类繁杂的蛋清粉掺杂鉴别。 该研究可为后续开发针对蛋粉质量检测的便携式近红外光谱检测仪提供一定的科学基础。
Egg white powder adulteration identification technology is of great significance to ensure the quality and safety of egg powder, however, the traditional biomolecular detection methods are complicated and time-consuming, and the adulteration identification model for egg white powder is still mainly a directional identification model, which has a limited detection range and can not effectively cover all the possible adulterants, so it is urgently needed to develop a fast, accurate and generalized method for egg white powder adulteration identification. In this study, we introduced near-infrared spectroscopy detection technology and constructed a LOF non-directional identification model. The model is an unsupervised single classification model, and MSC preprocessing and CARS wavelength screening processing are added to the original model to enhance the model's ability to extract spectral features, reduce noise interference, and lower computational requirements. The experimental results show that the detection rate of the LOF non-directional identification model for adulterated egg white powder can reach 93.6%. Its accuracy, precision, recall, and F1 score reach 93.6%, 95.5%, 93.6%, and 94.5%, respectively. For egg white powder with an adulteration concentration of more than 15%, the total accuracy rate ( AAR) of both test sets reaches 100%, and the average detection time ( AATS) can be as low as 0.001 1 s. Compared to other non-directional algorithms, this algorithm has higher accuracy and is more generalizable than traditional directional models, making it more suitable for identifying egg white powder adulteration with a wide variety of adulteration types in the market. This study can provide a theoretical basis for the subsequent development of a portable near-infrared spectroscopy detector for detecting egg white powder quality.
鸡蛋粉产品包括全蛋粉、 蛋黄粉、 蛋清粉等[1]。 因其营养成分与人体需要相适宜, 具有高质量的蛋白质、 均衡的矿物质和维生素且便于携带, 成为鸡蛋的理想替代品[2, 3], 已广泛应用于食品生产、 化妆品工业及医疗制造等领域[4, 5]。 其中, 蛋清粉的蛋白质含量可高达80%, 同时具有低脂肪低碳水的特点, 特别适合发育期、 老年人或者是运动人群食用。 目前, 在蛋粉生产过程中部分企业掺入廉价的植物蛋白粉或者面粉等, 以次充好, 不但扰乱了蛋粉市场的秩序, 也给食品安全带来了极大隐患。 相较于全蛋粉和蛋黄粉, 蛋清粉蛋白质含量较高, 市面上价格较贵, 其掺杂情况更加严重。 因此, 研究蛋清粉掺杂鉴别技术, 对保障蛋粉质量安全具有重要意义。
目前, 关于蛋清粉的掺杂鉴别主要有感官识别法、 基于DNA分子与蛋白质分子检测的生物分子技术[6]和光谱检测技术。 其中, 前两种方法存在着主观性过强、 成本高、 操作复杂且耗时长的问题, 无法达到快速检测的要求。 近红外光谱(near-infrared spectroscopy, NIRS)检测技术已经广泛应用于粉末状食品的掺杂鉴别, 是一种快速、 无损的检测技术, 其原理为通过物质在近红外波段的吸收与散射特性, 来获取有机物中含氢基团(如C— H、 N— H、 O— H)的信息[7]。 课题组前期分别建立了基于PLS的高光谱全蛋粉掺假的无损检测模型[8]和基于集成学习的近红外光谱全蛋粉掺假鉴别模型[9], 其研究表明基于近红外光谱检测蛋粉掺杂是可行的。 但目前基于近红外光谱的食品掺杂鉴别, 其建模方式仍为定向鉴别模型, 仅可对特定的掺杂物质进行有效检测。 但市面上蛋清粉的掺杂物质众多, 定向鉴别模型可检测的掺杂种类有限, 无法有效覆盖所有可能的掺杂物质, 其检测范围有提升的空间。 面对蛋粉市场上繁多的未知掺杂物, 亟需开发一种快速、 准确、 泛用的检测方式。
近年来, 基于无监督学习的非定向检测方法在时序检测[10]、 故障诊断[11]、 异常检测[12]、 图像处理[13]等各个场景应用中取得了一定的成果。 针对光谱数据处理, 非定向检测方法在食品质量检测方面已有进展[14, 15]。 其中, 局部离群因子检测算法(local outlier factor, LOF)是一种基于密度的异常检测算法, 可应用于无监督单分类检测, 在工业领域的异常检测[16, 17]中得到了应用, 并取得了良好的效果。 由于LOF仅依靠正常样本, 可检测出多样的异常样本, 可以满足蛋清粉掺杂检测中覆盖所有可能的掺杂物质的需求, 且LOF能够准确识别局部异常值, 适合光谱部分波段数据异常的应用场景。 由于掺杂蛋清粉相对于真实蛋清粉, 其部分波段光谱数据会有异常变动, 故本研究拟应用LOF模型, 并基于近红外光谱数据对蛋清粉进行非定向掺杂鉴别。
为改善蛋清粉全近红外光谱信息复杂、 原数据存在较多噪声等问题, 在LOF基础上加入预处理及波长筛选处理, 提高模型对特征的敏感度, 减少全光谱噪声及无用波段对鉴别的干扰, 降低模型的计算量。 该模型鉴别的掺杂种类广泛, 对于不同类型的样本均实现了良好的判别效果, 可实现对蛋清粉的真伪进行快速、 准确的鉴别, 以期为开发针对蛋粉质量检测的便携式近红外光谱检测仪提供一定的理论基础。
使用来自安徽、 江苏、 湖北、 辽宁及吉林5个省的品牌纯蛋清粉为样本。 为了确保纯蛋清粉样本之间的差异性, 选择不同生产批次的纯蛋清粉样本。 每个省份提供600份样本, 最终有纯蛋清粉样本共3000份。 为验证样本的可信性, 参照“ 国家标准GB 5009.5— 2016 食品中蛋白质的测定” 中的凯氏定氮法测定蛋粉中的蛋白质含量, 参照“ 国家标准GB 5009.3— 2016 食品安全国家标准 食品中水分的测定” 中的直接干燥法计算水分含量, 每种品牌取2 g纯蛋清粉样本进行测定, 最终测得5种纯蛋清粉样本的蛋白质含量≥ 78.0%, 水分≤ 9.0%, 参照“ 国家标准GB/T 42237— 2022 蛋粉质量通则” 中的理化指标, 样本均处于质量标准内。
一般市面上蛋清粉的掺杂物分为两大类: 一类是常见的增量剂掺杂物(如淀粉), 此类掺杂物在形态上难以与纯蛋清粉区分, 可用于以次充好; 第二类是富氮类化合物(如三聚氰胺), 由于实际中通常使用凯氏定氮法来测量样本的蛋白质含量, 此类掺杂物可用以伪造高品质蛋清粉。 本研究的掺杂蛋清粉样本选择7种常见增量剂掺杂物与富氮类化合物, 包括淀粉、 大豆分离蛋白、 三聚氰胺、 尿素、 甘氨酸、 麦芽糊精和二氰酸。 其中前五种为蛋清粉常见掺杂物, 后两种为其余粉末状食品典型掺杂物。 蛋清粉的掺杂可分为单组分掺杂、 多组分掺杂, 其中多组分为二组分掺杂、 三组分掺杂。 掺杂的浓度含量为0.1%、 0.5%、 1%、 5%、 10%、 15%、 20%、 30%。 对于前五种蛋清粉常见掺杂物, 单组分中每种掺杂物168份, 共840份, 二组分360份, 三组分216份。 5种常见掺杂物分别制备纯掺杂物样本3份, 共15份, 最终制备的前五种掺杂蛋清粉样本共1431份。 对于后两种其余粉末状食品典型掺杂物, 单组分中每种掺杂物48份, 共96份, 二组分48份, 2种纯掺杂物样本6份, 共12份, 最终制备的后两种掺杂蛋清粉样本共156份。
对全部纯蛋清粉和掺杂物过孔径1 mm标准筛, 以确保样本颗粒大小均匀。 将掺杂后的蛋清粉分别置于搅拌机中搅拌2 min, 确保掺杂物颗粒均匀混杂在蛋清粉样本中。 将所有制备好的样本分别放入120 mm× 80 mm的样本袋内, 并置于4 ℃的冷藏箱中贮藏。
使用Antaris Ⅱ 型傅里叶近红外光谱分析仪(美国Thermo Scientific公司)漫反射方式采集光谱数据。 光谱数据采集范围为10 000~4 000 cm-1(1 000~2 500 nm), 光谱分辨率为3.85 cm-1, 扫描次数为32次。 环境温度为25 ℃, 每份样本重复扫描3次, 取其平均光谱作为样本的原始光谱数据, 使用Python 3.7.1软件对保存的光谱数据进行相应的数据分析处理。
由于训练集仅由纯蛋清粉样本组成, 将3 000份纯蛋清粉样品按照Kennard-Stone算法随机分割, 以2∶ 1的比例分为训练集和测试集。 测试集有A、 B两组, 其中测试集A由1 000 份纯蛋清粉样本与1 431份由前5种蛋清粉常见掺杂物的掺杂蛋清粉样本组成, 以验证模型的准确度; 测试集B为156份后两种其余典型掺杂物的掺杂蛋清粉样本, 以验证模型对未知掺杂物的检测性能。 为改善样本多样性不足而导致模型准确度较低的问题, 故采用合成少数类过采样技术(synthetic minority over-sampling technique, SMOTE)[18, 19], 对训练集进行数据扩充, 最终得到新训练集数据共4 000份, 测试集A共2 431份, 测试集B共156份, 样本的划分详细信息如表1所示。
| 表1 样本分组详情 Table 1 Details of sample grouping |
在光谱的采集过程中, 采集的光谱数据会存在大量的随机噪声, 为减少此类影响, 并突出光谱有用信息, 对光谱数据进行预处理。 分别选择归一化(normalize, NORM)、 均值中心化(centering, CT)、 标准正态变换(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)、 卷积平滑(savitzky golay, SG)和去趋势(detrending, DT)共6种方法进行光谱预处理; 比较不同的光谱预处理方法对建模效果的影响, 并选取其中效果最好的模型。
原始光谱数据存在着大量变量, 这些变量之间存在大量噪声及无效信息, 如果采用全光谱数据建立非定向鉴别模型, 不仅加大模型的运算量, 还会影响模型的精度。 故分别采用竞争性自适应重加权采样算法(competitive adaptive reweighted sampling, CARS)、 连续投影算法(successive projections algorithm, SPA)和非信息变量剔除算法(uninformative variables elimination, UVE)这三种算法进行光谱的特征波长提取, 并选取其中效果最好的方法进行建模。
LOF是一种基于密度的异常检测算法, 其同时考虑了数据集的局部和全局属性, 可以有效检测出局部区域内的离群点, 且数据集不需要预先标注, 可以直接应用于无标签的数据集, 适合无监督学习任务[20]。
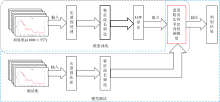
针对蛋清粉非定向掺杂鉴别, 将每一条光谱数据作为一个数据点, 其中纯蛋清粉光谱为正常点, 掺杂蛋清粉光谱为异常点, 在LOF算法的基础上加入光谱的预处理及波长筛选处理, 其模型训练和测试的流程如图1所示。 在模型训练时, 确定训练集的局部可达密度阈值, 建立非定向掺杂鉴别模型。 模型测试时, 光谱数据经过预处理及波长筛选后, 计算测试集中数据点的密度来筛选出异常点, 最终输出测试集的判别结果。
 | 图1 LOF模型流程图Fig.1 LOF model flowchart |
建立的模型为定性判别模型, 用于判断样本是否为真实蛋清粉。 从检测准确率、 检测精确度以及检测速度3个方面对模型进行评价。
(1)检测准确率指标: 针对模型性能, 分别以准确率(Accuracy)、 精确率(Precision)、 召回率(Recall)和F1分数(F1 score)来评估模型的综合性能。 针对测试结果有三个指标, 为假阳性率(false positive rate, FFPR), 对应误检率, 指的是纯蛋清粉被误判成掺杂样本的比例, 计算式如式(1)所示; 假阴性率(false negative rate, FFNR), 对应漏检率, 指的是掺杂蛋清粉误判成纯蛋清粉的比例, 计算式如式(2)所示; 总准确率(accuracy rate, AAR), 评估模型对样本的真伪鉴别能力, 计算式如(3)所示。
式(1)— 式(3)中, 将纯蛋清粉样本作为阴性样本, 掺杂蛋清粉样本作为阳性样本。 TP为真阳性数, 即掺杂蛋清粉被正确判断成掺杂样本的数量; FN为假阴性数, 即掺杂蛋清粉被错误判断成纯蛋清粉样本的数量; TN为真阴性数, 即纯蛋清粉被正确判断成纯蛋清粉样本的数量; FP为假阳性数, 即纯蛋清粉被错误判断成掺杂样本的数量。
(2)检测精确度指标: 最低检测限(lowest recognition concentration, LLRC), 即该掺杂种类可被完全检出时的最小掺杂浓度, 单位为百分比(%), 其计算式如式(4)所示, 其中x1— xn为该掺杂种类中漏检样品的掺杂浓度, 该指标可评价模型对掺杂样本的检测精确度。
(3)检测速度指标: 平均检测时间(average time spent, AATS), 即该模型在批量检测时每份样品的平均用时, 单位为秒(s), 该指标可评价模型对样本的检测效率。
2.1.1 纯蛋清粉与掺杂蛋清粉光谱分析
图2为样本的原始光谱图, 从图2(a)可知, 不同产地蛋清粉光谱图的变化趋势十分相似, 波峰、 波谷位置相同。 通过图2(a)和(b)可知, 纯蛋清粉与掺杂蛋清粉的原始光谱的变化趋势相似, 波峰、 波谷位置也十分相似, 吸光度随着波数的增加而逐渐减小。 纯蛋清粉与掺杂蛋清粉的光谱高度重叠, 无法仅通过光谱图进行鉴别, 需要通过相应的鉴别模型来提取有效信息, 实现对样本快速、 准确的鉴别。
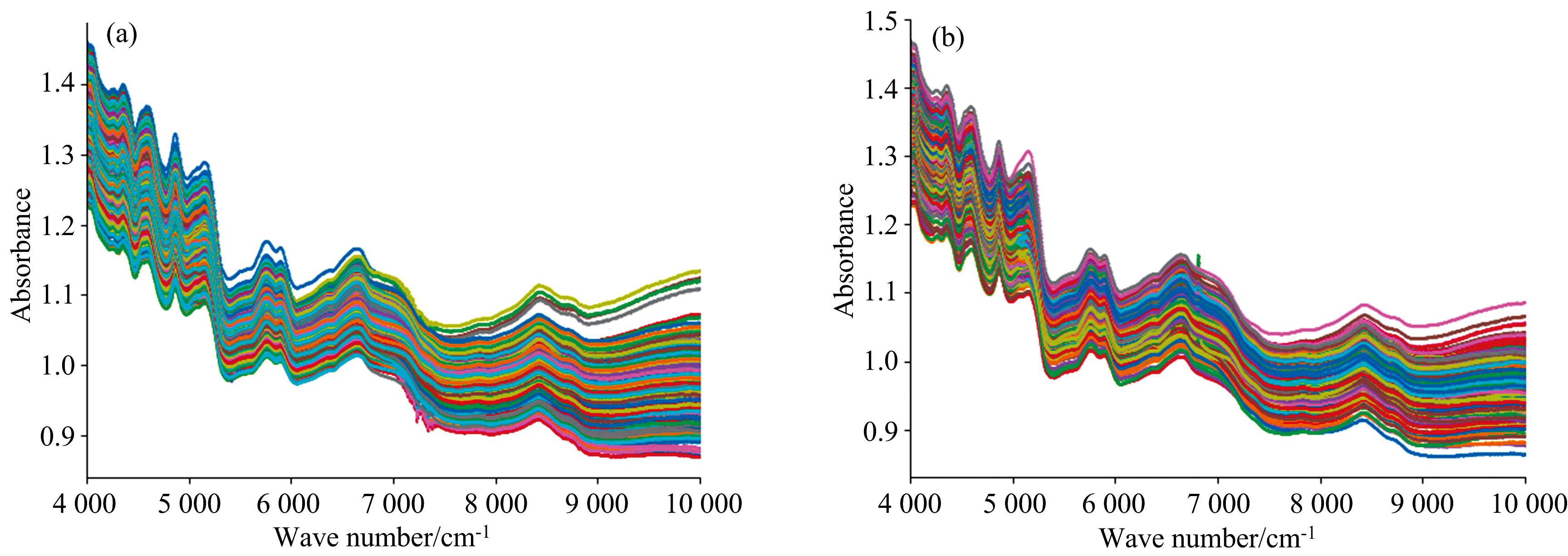 | 图2 样本原始光谱图 (a): 纯蛋清粉样本; (b): 掺杂样本Fig.2 Original spectra of samples (a): Egg white powder samples; (b): Adulterated samples |
2.1.2 不同掺杂种类蛋清粉光谱分析
5种掺杂物与纯蛋清粉的原光谱对比如图3(a)所示。 淀粉与大豆分离蛋白两种增量剂掺杂物在4 200~4 850与6 400~7 100 cm-1范围内吸光度大小区分明显; 三聚氰胺和尿素两种含氮类化合物相比于增量剂, 光谱图区分度更大, 在4 250~5 150和5 400~7 100 cm-1范围内吸光度大小区分明显; 对于甘氨酸, 在4 950~7 200 cm-1范围内吸光度变化趋势有很大的差异。 图3(b)— (d)中红框标出的光谱变化区间对应着该类掺杂物质的光谱变化特征, 通过对比可以得出以下结论: (1)掺杂物的种类及浓度决定了光谱变化的区间及程度, 其光谱变化直观表现了掺杂样本的种类及浓度特征; (2)多种掺杂物混合掺杂会导致光谱在多区间会发生变化, 且二组分和三组分掺杂变化的区间及程度为混合掺杂中每一种掺杂物质单独掺杂时各自产生光谱变化特征的叠加; (3)由于掺杂物所含的成分与蛋清粉不同, 掺杂导致蛋清粉样本的主要成分(C— H键、 N— H键和O— H键)发生了变化, 进而产生光谱畸变, 说明畸变波段存在着C— H键、 N— H键和O— H键倍频和合频的吸收峰, 这些官能团与蛋清粉的蛋白质、 水分等物质有紧密的联系。 这些结论为之后模型的建立、 训练及检测结果提供了理论依据。
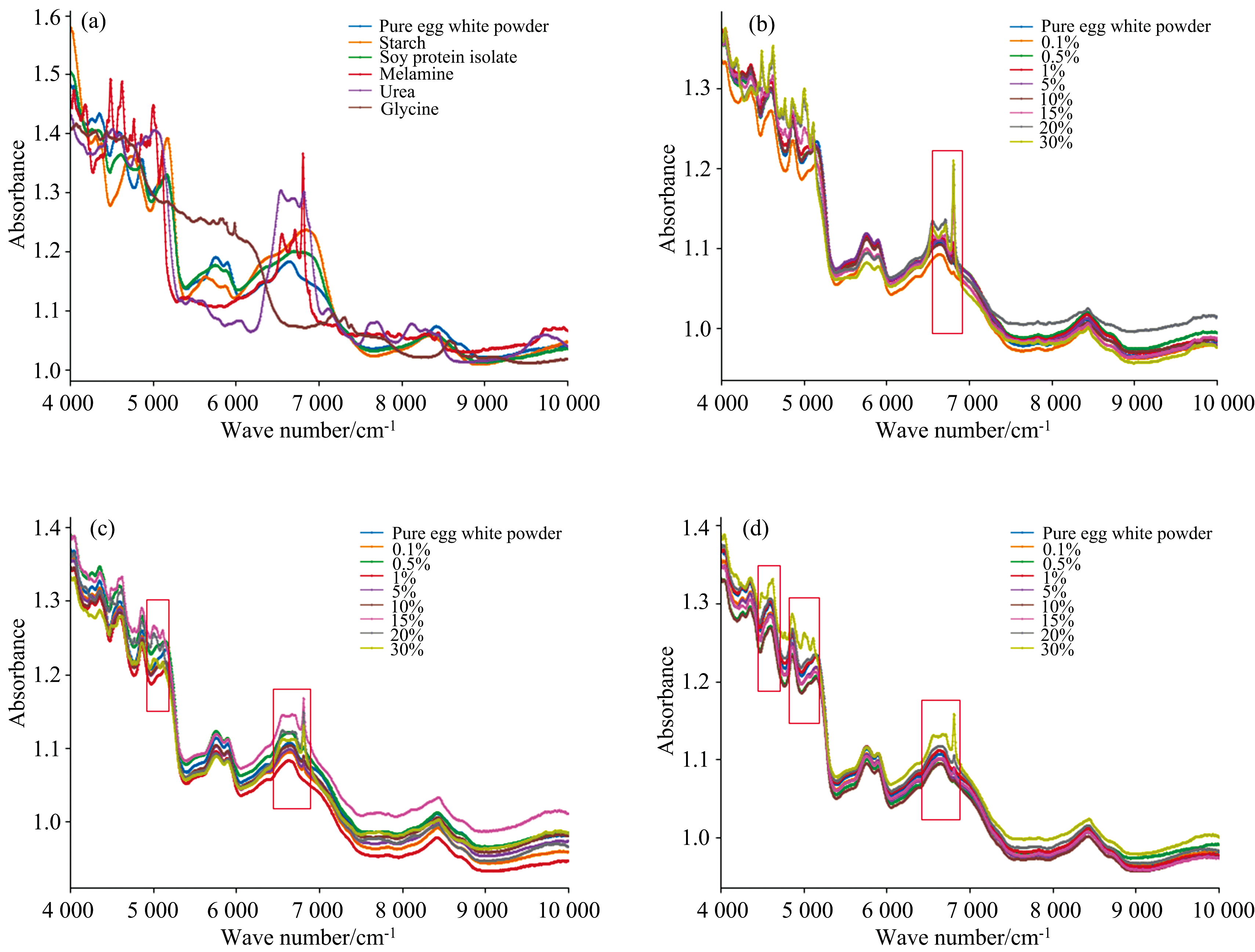 | 图3 不同掺杂种类及浓度蛋清粉光谱图 (a): 原始光谱; (b): 单组分掺杂; (c): 二组分掺杂; (d): 三组分掺杂Fig.3 Spectra of egg white powder with different types and concentrations of adulterants (a): Original spectra; (b): One-component; (c): Two-component; (d): Three-component |
2.2.1 光谱预处理
分别基于原始光谱数据与预处理后的光谱数据, 建立LOF非定向鉴别模型, 将测试集A作为测试集, 比较不同光谱预处理方法对模型鉴别结果的影响, 其结果如表2所示。 其中, 基于原始光谱数据建立的模型效果不够理想。 在6种光谱预处理方法中, MSC预处理方法的效果最优, 其准确率、 精确率、 召回率和F1分数分别达到了92.6%、 96.3%、 90.9%和93.5%, 相比于原始光谱和其他预处理方法均有提高。 故建模将采用MSC预处理方法对原光谱数据进行处理。
| 表2 不同预处理方法的鉴别结果 Table 2 Discrimination results of different preprocessing methods |
2.2.2 光谱特征波长筛选
分别基于CARS、 SPA、 UVE三种筛选方法, 对经过MSC预处理后的光谱数据进行光谱特征波长筛选。 在CARS中, 设定蒙特卡洛采样(迭代次数)为100次, CV交叉验证折数为10; 在SPA中, 输出的最大特征数量设定为60; 在UVE中, 设定CV交叉验证折数为10。
分别将光谱特征波长筛选后的数据输入至模型进行训练, 测试集也分别按照相同的预处理及特征波长筛选算法进行处理并测试, 最终模型测试结果如表3所示。 其中, 经过UVE和CARS处理后的数据, 最终的F1分数相比于未进行特征波长筛选的原数据有所提升。 经过SPA处理的F1分数相比于原数据有所降低, 是由于经过SPA处理后, 光谱的部分有效信息被筛选, 缺失了一部分真实蛋清粉相比于掺杂蛋清粉的光谱特征, 进而导致模型的性能降低。 经过CARS处理后的模型性能是最优的, 其准确率、 精确率、 召回率和F1分数分别达到了93.6%、 95.5%、 93.6%和94.5%, 相比于原数据模型, F1分数提高了1%。 CARS算法相比于UVE算法, 能更有效对原数据中的噪声及无用信息进行筛选排除, 且相比于SPA算法, 能在有效排除原数据噪声的同时, 保留更多的有效特征变量。
| 表3 不同光谱特征波长筛选方法的鉴别结果 Table 3 Discrimination results of different spectral feature wavelength selection methods |
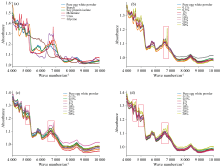
图4(a)为经过MSC预处理后的光谱, 图4(b)中光谱曲线上的红圈标注出了CARS算法筛选出的特征波段; 图4(c)为筛选后的光谱图。 由图4(b)可知, CARS筛选的特征波段主要分布在4 050~5 000、 5 100~5 600、 6 100~6 250、 6 820~7 150、 7 950~8 450和8 600~9 820 cm-1区域内, 加上分散在特征光谱区域的一些散点, 共计253个光谱变量。 这253个变量所在的波段区域与2.1中纯蛋清粉及掺杂蛋清粉的特征波段区域高度重合, 可说明CARS相比于其余筛选算法, 能更精确的保留有效特征变量。
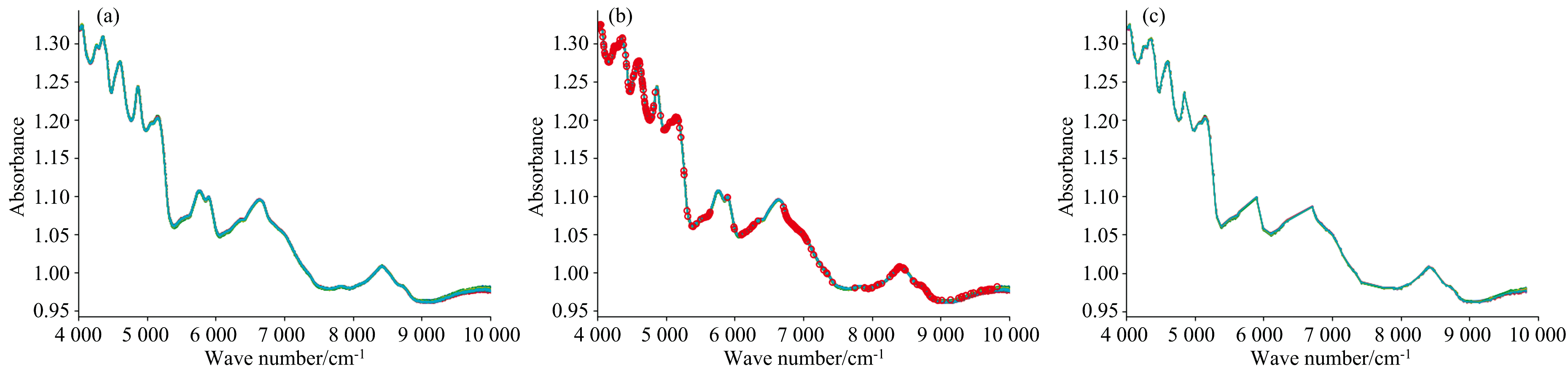 | 图4 CARS筛选后的光谱图 (a): MSC处理后光谱; (b): CARS特征波长筛选; (c): CARS筛选后光谱Fig.4 Spectra after CARS screening (a): MSC pretreated spectra; (b): CARS feature wavelength selection; (c): Spectra after CARS selection |
综上所述, CARS特征波长筛选方法能有效排除原数据中的噪声和无用信息, 提取真实蛋清粉光谱的特征变量, 能有效提升模型的精度, 减小模型的运算量, 故建模将采用CARS特征波长筛选方法对光谱数据进行处理。
2.2.3 LOF非定向鉴别模型测试结果
将光谱数据分别经过MSC光谱预处理及CARS光谱特征波长筛选后, 训练集输入至LOF非定向鉴别模型进行模型训练, 其中模型参数K设定为100。 模型训练完毕后, 分别将测试集A和测试集B输入至模型中进行测试。
表4为测试集A的不同掺杂浓度的真伪鉴别结果。 其中FFPR均为6.3%, 掺杂浓度高于15%的样本均无漏检, 其检测率为100%, 整个测试集A的AAR可达到93.6%。 通过2.1.2分析可得, 掺杂浓度越高的样本其光谱畸变越明显, 更容易被检测出其异常特征, 故对应的AAR会随着掺杂浓度的升高而提升。
| 表4 不同掺杂浓度的真伪鉴别结果 Table 4 Authenticity detection results for different adulterant concentrations |
具体的掺杂种类真伪鉴别结果如表5所示, 针对每种掺杂种类分别统计了在不同浓度下的误判数以及最低检测限。 其中, 单组分、 二组分、 三组分掺杂的LLRC最高均为15%, LLRC最低分别可达到5%、 0.1%、 0.1%。 通过2.1.2中的分析, 单组分中的三聚氰胺由于其光谱图特征最为明显, 在6 800 cm-1左右处有明显的波峰, 所以其LLRC相比其他掺杂物最低, 可达到5%; 对于多组分掺杂, 由于多组分掺杂光谱图的特征区域相比于单组分更多, 更容易被判定成异常点, 故该模型对于多组分掺杂有着更高的检测精度, LLRC最低可达到0.1%。
| 表5 不同掺杂种类的真伪鉴别结果及最低检测限 Table 5 Authenticity identification results and the minimum detectable limits for different types of adulterants |
测试集B的真伪鉴别结果如表6所示, 通过2.1.2分析, 由于富氮类化合物相比于增量剂, 光谱图区分度更大, 所以在单组分掺杂鉴别中, 二氰酸的鉴别效果更优, 其LLRC可达到0.5%, AAR可达到98.2%; 二组分由于光谱特征区段更广, 其LLRC可达到0.1%; 整个测试集B的AAR可达到93.6%, 与测试集A的准确率相比无明显差别, 这说明LOF非定向鉴别模型针对其他未知掺杂物也能保持良好的判别性能。
| 表6 测试集B的真伪鉴别结果及最低检测限 Table 6 Authentication results and minimum detection limits for test set B |
综上所述, 该模型在蛋清粉的真伪检测方面有良好的精确度, 对于单组分和多组分的混合掺杂均有较好的判别性能, 且该模型泛用性强, 针对其余未知掺杂物也能保持良好的检测性能。
为了比较LOF非定向鉴别模型与其他非定向算法的性能, 分别以孤立森林(isolation forest, IF)、 支持向量数据描述(support vector data description, SVDD)、 深度孤立森林(deep isolation forest, DIF)[21]三种无监督方法建立模型, 用相同的训练集和测试集A, 通过相同的MSC预处理方法以及CARS光谱特征波长筛选方法, 进行模型的训练及测试。 最终的试验结果如表7所示。 LOF相比于其他三种算法, 其准确率、 召回率、 F1分数均为最优。 其中SVDD的精确率为最优, 针对纯蛋清粉样本没有错检, 但SVDD在检测掺杂样本的准确率过低, 其综合模型性能不如LOF。 且LOF的检测速度最快, 其AATS可达到0.001 1 s, 满足了快速检测的要求。
| 表7 不同非定向鉴别模型的鉴别结果 Table 7 Discrimination results of different non-directional discrimination models |
为验证LOF非定向鉴别模型相比于定向鉴别模型对未知掺杂物的鉴别性能优势, 将LOF非定向鉴别模型与传统的支持向量机(support vector machine, SVM)和集成学习(ensemble learning, EL)定向鉴别模型进行比较, 分别运用测试集A和测试集B进行模型的性能测试。 最终结果如表8所示。 对于测试集A, 由于SVM和EL模型学习过测试集A中掺杂样本的掺杂种类, 其AAR相比于LOF模型更高。 但对于测试集B, 由于定向模型未学习过测试集B中的掺杂种类, 其FFNR大幅上升, 其AAR下降至66.0%和67.9%, 而LOF非定向鉴别模型在测试集A和测试集B中的AAR均能稳定至93%以上, 避免了由于未知掺杂物导致模型性能大幅下降的问题。
| 表8 非定向鉴别模型与定向鉴别模型的结果 Table 8 Results of the indirect discrimination models and the direct discrimination models |
综上所述, 相比于其他非定向模型, LOF模型的综合性能最优, 且相比于定向鉴别模型, 该模型针对未知掺杂物的鉴别效果更好且更稳定, 能有效鉴别的掺杂种类更广泛, 更适合应用于市面上掺杂种类繁杂的蛋清粉掺杂鉴别。
针对蛋清粉非定向掺杂鉴别问题, 提出了一种基于近红外光谱的LOF非定向鉴别模型, 实验结果显示MSC+CARS处理方法在模型的建立上具有优势。 最终LOF非定向鉴别模型针对掺杂蛋清粉的检测率可达到93.6%, 针对掺杂浓度超过15%的蛋清粉, 可达到100%的检测率, 对部分多组分掺杂种类, 其LLRC可达到0.1%, 针对测试集A与B的AAR均为93.6%, AATS可达到0.001 1 s。 该模型与其他非定向算法相比具有更优性能, 且相比于定向鉴别模型, 该模型可鉴别的掺杂种类更广泛, 更适合应用于市面上掺杂种类繁杂的蛋清粉掺杂鉴别上。 该研究可为后续开发针对蛋粉质量检测的便携式近红外光谱检测仪提供一定的科学基础。
为了使模型有更高的检测精度, 未来的研究可以尝试采集更多地区的蛋清粉样本, 提高模型的泛用性; 在机理成分上分析蛋清粉真实性特征, 进一步细分光谱特征波段; 优化模型结构, 尝试引入深度无监督学习算法, 以提高检测准确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|