

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱成像技术结合深度学习的藕粉识别和掺假检测
[彭健恒1  , 胡新军
, 胡新军1, 2, * , 张嘉洪1 , 田建平1 , 陈满骄1 , 黄丹2 , 罗惠波2 ]
, 胡新军, 张嘉洪|
|


作者简介: 彭健恒, 2000年生,四川轻化工大学机械工程学院硕士研究生 e-mail: 1198751028@qq.com
藕粉营养价值高, 工艺复杂, 一些不法商家受到利益的驱使, 利用廉价的普通淀粉冒充藕粉或在藕粉中掺入普通淀粉。 传统的藕粉真伪检查方法耗时耗力, 具有破坏性。 高光谱成像技术凭借其快速、 无损且精确的优点在食品安全检测领域得到广泛应用。 因此, 为了准确区分藕粉和其他普通淀粉并识别掺假藕粉, 提出了一种高光谱成像技术结合深度学习的快速鉴别藕粉真伪的方法。 利用高光谱成像技术采集900~1 700 nm波段范围内的纯藕粉、 四种普通淀粉以及掺假淀粉的高光谱图像。 在纯藕粉和四种普通淀粉的高光谱图像中划分若干个感兴趣区域(ROI), 计算每个ROI的平均反射率作为构建分类模型的原始光谱数据。 去除掉原始光谱前后受噪音影响的异常波段, 保留了940~1 675 nm之间的443个波段。 接着通过孤立森林(IF)算法剔除掉光谱数据中的异常数据。 为提高模型训练效率, 采用竞争性自适应重加权算法(CARS)、 自助软收缩算法(BOSS)和通道注意力模块(CAMM)三种方法分别从443个波段中提取出45、 32和12个特征波长。 基于提取出的特征波长的光谱数据, 构建了偏最小二乘判别(PLS-DA)分类模型, 其中CAMM-PLS-DA模型识别效果最好, 测试集准确率达到了95.25%。 为了确定最佳分类模型, 基于CAMM提取不同特征波长数目下的光谱数据, 建立PLS-DA、 支持向量机(SVM)和卷积神经网络(CNN)分类模型, 其中CAMM-CNN模型的分类性能最好, 测试集准确率最高达到了99.69%。 为进一步检验CAMM-CNN模型对掺假藕粉的鉴别能力, 将掺假藕粉高光谱图像所有像素点的光谱数据输入到训练好的CAMM-CNN模型中进行判别, 从可视化图像看出, 模型成功识别出掺假藕粉中的多种普通淀粉。 研究结果表明, 高光谱成像技术结合深度学习方法可以有效地应用于藕粉的真伪鉴别, 这为打击藕粉掺假行为和保障藕粉安全提供了一种新的检测手段。
, HU Xin-jun, ZHANG Jia-hongLotus root starch is highly nutritious, and its production process is complex. Some unscrupulous businessmen, driven by profit, adulterate lotus root starch with cheaper common starch or mix common starch into lotus root starch. Traditional methods for authenticating lotus root starch are time-consuming, labor-intensive, and destructive. Hyperspectral imaging technology, with its advantages of rapid, non-destructive, and accurate, has been widely applied in food safety detection. Therefore, this study proposes a method for quickly distinguishing between lotus root starch and other common starches, as well as identifying adulterated lotus root starch, by combining hyperspectral imaging technology with deep learning. Hyperspectral images of pure lotus root starch, four types of common starches, and adulterated starches were collected in the wavelength range of 900~1 700 nm using hyperspectral imaging technology. Several regions of interest (ROI) were delineated in the hyperspectral images of pure lotus root starch and the four common starches, and the average reflectance of each ROI was calculated from the original spectral data to build classification models. Abnormal bands affected by noise at the beginning and end of the original spectra were removed, leaving 443 bands between 940 and 1 675 nm. Outliers in the spectral data were then eliminated using the Isolation Forest (IF) algorithm. To enhance model training efficiency, the Competitive Adaptive Reweighted Sampling (CARS), Bootstrapping Soft Shrinkage (BOSS), and Channel Attention Mechanism Module (CAMM) were employed to extract 45, 32, and 12 feature wavelengths from the 443 bands, respectively. Partial Least Squares Discriminant Analysis (PLS-DA) classification models were constructed based on the spectral data after feature wavelength extraction, with the CAMM-PLS-DA model showing the best recognition effect, achieving an accuracy of 95.25% in the test set. To determine the optimal classification model, PLS-DA, Support Vector Machine (SVM), and Convolutional Neural Network (CNN) classification models were established using spectral data with different numbers of feature wavelengths extracted by CAMM. The CAMM-CNN model exhibited the best classification performance, with a highest accuracy of 99.69% in the test set. To further verify the ability of the CAMM-CNN model to distinguish adulterated lotus root starch, the spectral data of all pixel points in the hyperspectral images of adulterated lotus root starch were input into the trained CAMM-CNN model for discrimination. Visualization images showed that the model successfully identified various types of common starches in the adulterated lotus root starch. The results indicate that the combination of hyperspectral imaging technology and deep learning methods can effectively be applied to the authentication of lotus root starch, providing a new detection approach to combat the adulteration of lotus root starch and ensure its safety.
藕粉是莲藕经过选藕、 清洗、 研磨、 过滤、 脱水、 干燥等一系列严苛的步骤制成的食品[1]。 它不仅含有丰富的蛋白质、 氨基酸、 还原糖等营养成分[2], 而且有益于治疗痢疾、 消化不良等疾病[3]。 藕粉的制作方式复杂, 产出率低, 市场价格是木薯淀粉、 红薯淀粉、 马铃薯淀粉、 玉米淀粉等普通淀粉的几十倍。 然而, 不良商家为获取高额利润, 利用廉价、 颜色相近的普通淀粉替代藕粉或在藕粉中掺入普通淀粉。 这种行为让消费者很难通过肉眼来区分, 极大地损害了消费者的利益。 因此, 为了保证藕粉的质量和维护市场秩序, 监管部门迫切需要一种能够快速、 无损检测出藕粉真伪的方法。
粉状食品中的掺假物可以使用高效液相色谱技术[4], 气相色谱-质谱法[5], 薄层色谱[6], 显微方法[7], 聚合酶链反应[8]等破坏性方法进行检测。 比如Wang等通过藕粉与硫酸亚铁的显色反应成功识别出掺假藕粉[9], 韩建勋等使用荧光聚合酶链反应法实现了对藕粉样品的掺假检测[10], Bai等基于液相色谱-质谱技术建立了对藕粉掺假的鉴定方法[11]。 虽然这些方法取得了良好的结果, 但它们需要专业的人员进行操作, 耗费了大量的时间和人力, 并且实验过程中使用的化学试剂对环境具有一定污染性。 这些原因都促使人们向更方便、 快捷的检测技术上探究[12]。 近年来, 随着光谱学的快速发展, 光谱技术在粉状食品真实性鉴别上的应用研究越来越多。 已有报道利用傅里叶变换中红外光谱鉴别掺入了马铃薯淀粉、 红薯淀粉的藕粉[13]; 也有研究人员利用近红外光谱识别掺入玉米粉、 地瓜粉和木薯粉的藕粉[14]; 这些研究都展现了光谱技术应用于检测藕粉中的普通淀粉的可行性。 然而, 傅里叶变换中红外和近红外光谱技术对样品制备的要求比较高, 且不能获取样品的空间信息, 更无法实现对掺假样品的可视化[15]。
高光谱成像(hyperspectral imaging, HSI)作为一种很有前景的光学技术被广泛应用于食品质量安全检测领域。 HSI将成像和光谱相结合, 可以同时获取样品的空间信息和光谱数据, 由此创建的高光谱图像, 每个像素都包含反映样品内部化学成分信息的光谱数据[16, 17]。 一些研究重点关注了HSI技术在粉状物质检测中的应用潜力。 Hashemi-Nasab等采用可见光和短波近红外高光谱成像技术检测出了姜黄粉中多种掺假物[18]; Khan等利用可见-近红外高光谱成像技术实现了辣椒粉和掺假辣椒粉的分类[19]; Faqeerzada等利用短波红外高光谱成像技术成功对杏仁粉和掺假杏仁粉进行分类[20]。 这些将HSI技术应用于粉状物质的检测都取得了不错的结果, 证明了高光谱成像技术应用于粉状物质检测的可行性。 然而, 这些研究还局限于对单一掺假物的辨别。 本研究不仅建立了能够快速区分藕粉与普通淀粉的高精度分类模型, 更进一步探究了HSI技术结合深度学习算法用于识别掺假藕粉中多种低浓度掺假物的能力, 弥补了传统机器学习方法在处理复杂数据和自动学习特征方面的不足, 拓展了HSI技术在藕粉面临复杂掺假情况下的应用前景。
藕粉来自湖北忆荷塘荷莲产业开发有限公司, 执行标准号 GB/T25733; 红薯淀粉、 木薯淀粉、 马铃薯淀粉、 玉米淀粉来自河北古松农副产品有限公司, 执行标准号GB/31637。
一台GaiaField-N17E-HR高光谱相机(光谱范围900~1 700 nm, 光谱分辨率5 nm, 波段数512个), 江苏双利合谱科技有限公司; 四个FSL卤素灯光源(功率55 W), 佛山电器照明股份有限公司; 一台ASUS计算机(配备高光谱数据采集软件SpecVIEW), 中国台湾华硕电脑股份有限公司; 一台BCE55I-10CN电子天平(测量精度0.01 mg), 北京赛多利斯仪器系统有限公司。
藕粉和四种普通淀粉各制备10个样品, 每个样品重量20 g, 一共50个纯淀粉样品。 对于掺假藕粉样品的制备, 通过将一种、 两种、 三种和四种不同掺假物(红薯淀粉、 木薯淀粉、 马铃薯淀粉、 玉米淀粉)掺入纯藕粉中, 依次制备了二元、 三元、 四元和五元混合掺假藕粉, 共四类掺假藕粉。 在每类掺假藕粉中, 每种掺假物的浓度有0.2%、 0.4%、 0.6%、 0.8%和1%共五个梯度。 因此, 每类掺假藕粉制备了5个样品, 每个样品重量20 g, 一共20个掺假样品。 掺假浓度可由式(1)得到
式(1)中: m1为掺假物的质量, m2为纯藕粉的质量。
为了确保每种掺杂物都能够均匀分布在藕粉中, 将准确称量配比后的掺假样品置于50 mL的聚丙烯离心管中, 用漩涡混合器震荡混合1 min。
高光谱成像系统如图1所示。 将样品置于直径10 cm, 高度2 cm的圆形玻璃培养皿中, 使用玻璃压板将表面压平, 保证表面的平展和充实。 然后放到距离高光谱成像仪镜头40 cm的采集平台中央处, 采集得到640× 666像素× 512波段的高光谱图像数据。 为获获取准确的高光谱图像数据, 提前设置好SpecVIEW软件的相关参数。 图像的R、 G、 B通道值分别设置为954.15、 927.55、 904.28 nm, 相机增益设置为2, 曝光时间设置为2 ms。
 | 图1 高光谱成像系统Fig.1 Hyperspectral imaging system |
由于相机中的暗电流和系统光源强度分布不均匀, 所采集的高光谱图像受大量噪声影响, 不能反映样品的真实情况。 因此, 需要采集白板和黑板图像对采集到的高光谱图像进行黑白校正, 用于降低相机噪声和光源强度不均匀对数据的影响, 获得相对稳定的光谱反射率[21]。 根据式(2)对原始图像进行黑白校正
式(2)中: Rc是校正后的高光谱图像, R0是校正前的高光谱图像, Rw为白色参考图像, Rd是黑色参考图像。
每张高光谱图像都包含样品和背景。 其中背景为无用信息, 因此, 采用大津阈值算法分割图像中的样品和背景, 分割出感兴趣区域(regions of interest, ROI)。 对于纯淀粉样品, 每份样品以像素点为单位, 随机划分40个圆形ROI, 每个ROI的半径为10个像素点。 通过计算ROI内所有像素的平均光谱值得到光谱曲线, 由此得到每类纯淀粉各400条光谱曲线。
提取出有效的光谱数据后, 需要对数据进行清洗, 剔除影响建模效果的异常数据[22]。 采用孤立森林(isolation forest, IF)算法剔除异常数据。 孤立森林是由众多的孤立树构成, 通过对光谱数据集中的样本进行连续的随机划分来构建这些孤立的树。 在这个过程中, 所有的样本都被反复分割, 直到它们都被归入某个孤立树的左侧或右侧, 最终形成了孤立森林。 然后, 根据每个样本在孤立森林中的路径长度计算相应异常得分。 最后, 通过设置异常得分阈值剔除异常样本。 根据多次调参实验, 将异常得分阈值设置为0.5。 剔除掉异常得分大于0.5的样本后, 模型的稳定性和准确性有显著提高, 证明在该阈值下, IF算法能够有效去除对建模效果有负面影响的异常样本。
光谱数据通常包含大量复杂和冗余的波段信息。 直接使用高维数据可能会导致计算量激增, 从而延长计算时间, 这会影响模型在实际检测应用中的运行效率[23]。 因此, 需要使用特征波长提取算法从全波长中提取出具有代表性、 稳定性和区分度的特征波长。
竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)的变量选择策略模仿了达尔文进化论的“ 适者生存” [24]。 其主要方法是以迭代竞争的方式依次选择一定数量的变量子集, 通过交叉验证选出交叉验证均方根误差(root mean-squared error of cross validation, RMSECV)最小值对应的子集, 即为筛选出的特征波长。
自助软收缩算法(bootstrapping soft shrinkage, BOSS)是一种基于变量空间的波段选择方法。 来源于加权自助抽样(weighted bootstrap sampling, WBS)和模型总体分析(model population analysis, MPA)的思想[25]。 变量的权重由回归系数(regression coefficients, RC)的绝对值确定。 根据权重利用WBS生成子模型, 利用MPA对子模型进行分析, 更新变量的权重。 优化过程遵循软收缩规则, 即不直接消除不重要的变量, 而是赋予较小的权重。 该算法多次迭代运行, 直到变量数量减少至1才终止。 最终, 选取RMSECV最小的最优变量集。
CAMM是通过引入通道注意力机制, 用来学习波段权重的深度学习神经网络模块[26]。 如图2所示, 将CAMM表示为一个函数g, 它以S个样本和b个光谱波段组成的全波段光谱向量集Ι ∈ RS× b为输入, 充分学习波段之间的非线性关系, 并产生一个非负波段权重张量w∈ R1× b, 其表达式为
式(3)中: Θ b表示CAMM中涉及的可训练参数。
 | 图2 CAMM特征提取流程图Fig.2 Feature extraction flowchart of CAMM |
为了保证学习到的权值的非负性, CAMM中使用Sigmoid函数作为输出层的激活, 其表达式为
此外, 为去掉一些无用波段的同时, 实现特征波段的稀疏分布, 增强模型的可解释性, 对波段权重施加了L1范数约束[27]。 得到的损失函数如式(5)
式(5)中, S为训练样本的个数, λ 是一个正则化系数。
上述方程采用自适应矩估计法(adaptive moment estimation, Adam)进行优化。 下一步, 根据学习到的稀疏波段权重, 通过对所有输入样本的波段权重求平均值来确定特征波段。 第j个波段的平均权重计算为
最后选择前C个平均权重最高的波段作为特征波段构成特征光谱向量子集
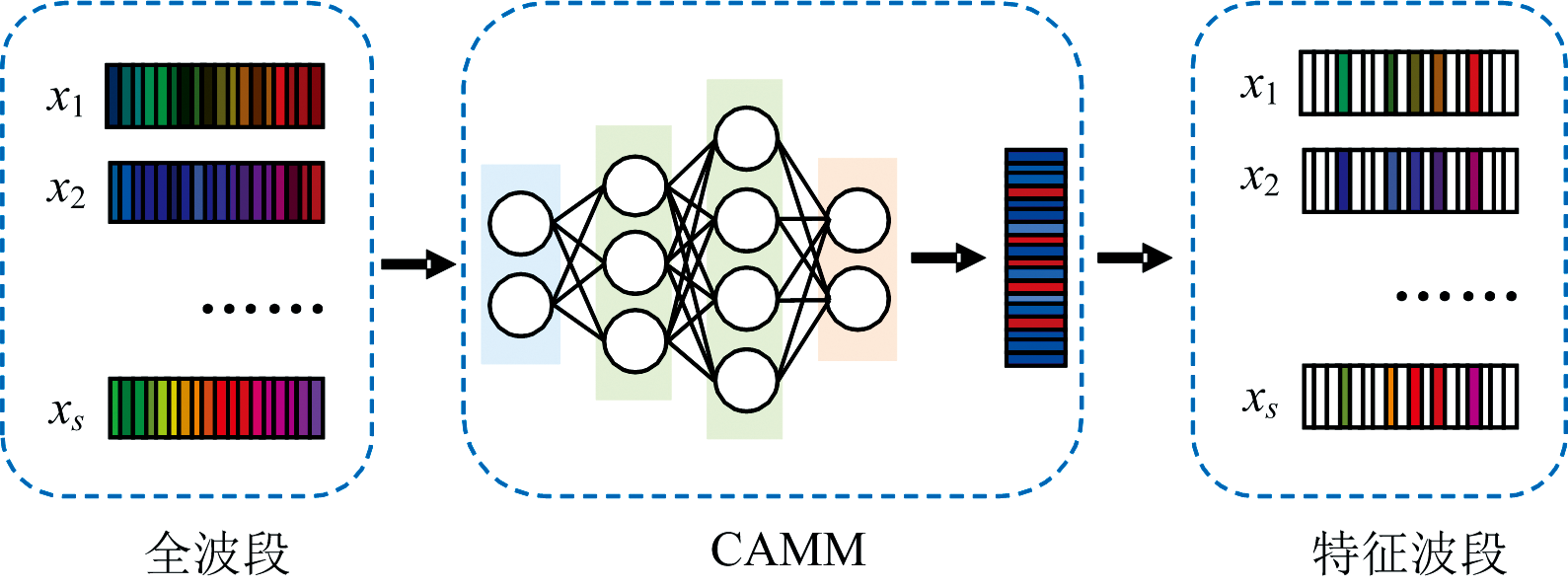 | 图3 CAMM的全连接神经网络结构Fig.3 Fully connected neural network architecture of CAMM |
分别采用偏最小二乘判别分析(partial least squares-discriminant analysis, PLS-DA)、 支持向量机(support vector machine, SVM)算法和卷积神经网络(convolutional neural network, CNN)对提取特征波长后的光谱数据进行建模。 通过对比分析, 确定分类效果最好的模型。
SVM是将原始特征空间中的样本映射到高维空间中进行分类[29]。 原理是使用映射函数将输入的光谱数据映射到高维特征空间中, 然后在高维特征空间中找到一个使得样本点到超平面的距离最大化的超平面, 将不同类别的样本点分隔开。 通过将新的样本点映射到特征空间, 并根据其在超平面的位置来进行分类。 如果新的样本点位于最优超平面的一侧, 那么它将被划分为一个类别, 而位于另一侧的样本点则被划分为另一个类别。
PLS-DA是一种基于多元线性回归与主成分分析的判别算法[30]。 该算法的目的是寻找自变量(光谱数据)与因变量(指定淀粉类别)之间协方差最大的潜在变量。 这些潜在变量是通过将自变量投影到一个低维子空间中, 利用PLSR计算得到的, 它们能最有效地区分不同类别之间的差异。
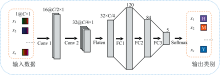
CNN是一种带有卷积结构的前馈神经网络, 作为深度学习的代表算法之一, 与其他传统的机器学习模型相比, CNN在捕捉获取输入数据的特征方面表现出更强大的能力[31]。 本研究从输入数据大小、 模型计算速度和分类效果等方面考虑, 设计了一个轻量的1D-CNN深度学习模型来完成本研究的分类任务。 如图4所示, 模型主要包含两个一维卷积层, 一个展平层和三个全连接层。 将S个波段数为C的一维光谱输入网络, 每个大小为C× 1的一维光谱向量首先经过第一个一维卷积层提取一维光谱的局部特征, 得到16张大小为C/2× 1的特征图, 再将这些特征图通过第二个一维卷积层进一步提取特征, 得到32张C/4× 1的特征图, 接着将32张特征图展平变成一个长度为32× C/4的特征向量, 展平后的一维特征向量依次通过三个全连接层FC1, FC2, FC3将所有局部特征连接起来, 输出经过Softmax激活函数转换为红薯淀粉(H)、 木薯淀粉(M)、 藕粉(O)、 马铃薯淀粉(T)和玉米淀粉(Y)共五个输出类别的概率分布, 从而实现对不同淀粉的识别和分类。 其中, 每个卷积层和全连接层都使用了Relu激活函数, 因为Relu函数没有复杂的指数运算, 可以提高运算效率且收敛速度更快[32]。
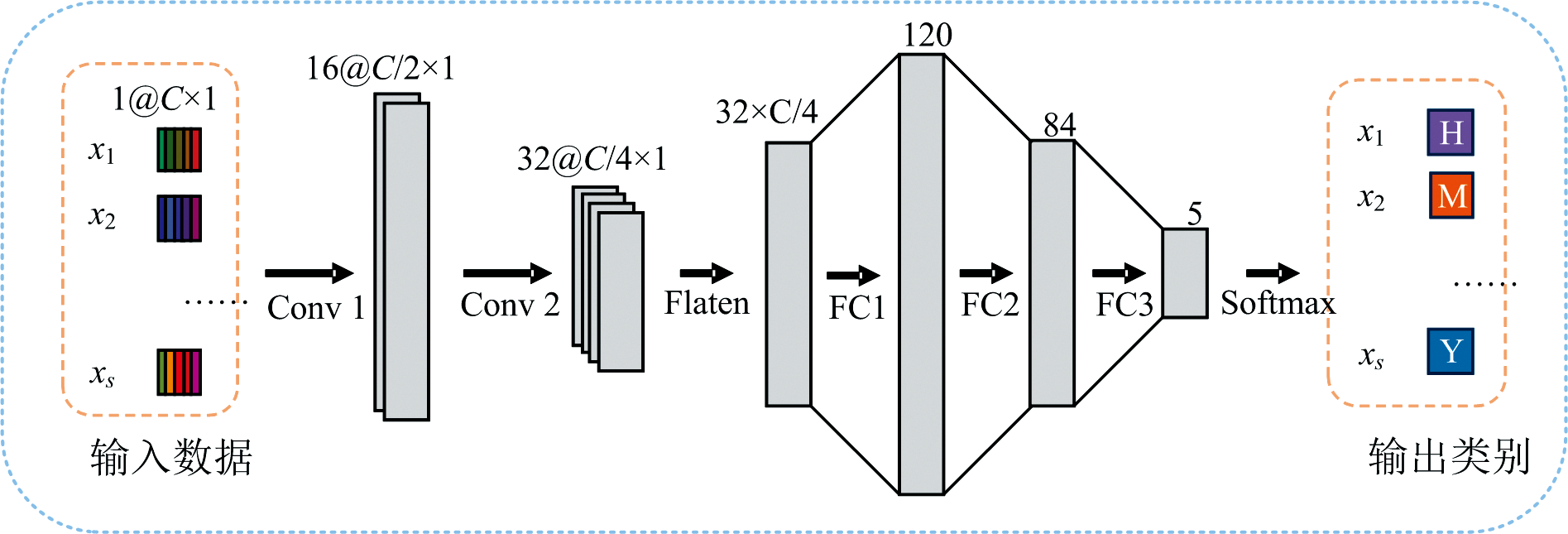 | 图4 1D-CNN深度学习模型结构Fig.4 Architecture of 1D-CNN deep learning model |
为了更好地评估模型的性能, 采用训练集和测试集的准确率和精确率作为模型评价指标。 准确率是所有样本中被正确预测的样本个数占总样本个数的比值, 是最直观的模型性能评估指标。 准确率越高, 说明模型的判别效果越好。 精确率定义为模型预测为正类的样本中, 实际为正类的比例, 用于衡量模型对正类预测的准确性。 准确率和精确率的计算方法如式(7)和式(8)
式(7)和式(8)中: TP表示正类淀粉被正确预测为正类的样本数; TN表示负类淀粉被正确预测为负类的样本数; FP为负类淀粉被错误预测为正类的样本数; FN表示正类淀粉被错误预测为负类的样本数。
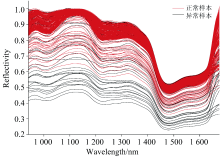
在使用IF算法剔除异常光谱数据之前, 需要去除光谱数据前后受噪音影响的异常波段。 具体去除了全波段中最前端33个波段和最后端36个波段, 从而保留了940~1 675 nm之间的443个波段。 随后, 利用IF算法剔除光谱数据中的异常数据。 图5以纯藕粉为例, 展示了从光谱数据中剔除异常数据的效果。 其中红线对应的是正常藕粉样本的光谱曲线, 黑线对应的是异常藕粉样本的光谱曲线, 可以清楚的观察到部分离群的光谱曲线被“ 孤立” , 从而识别为异常数据。
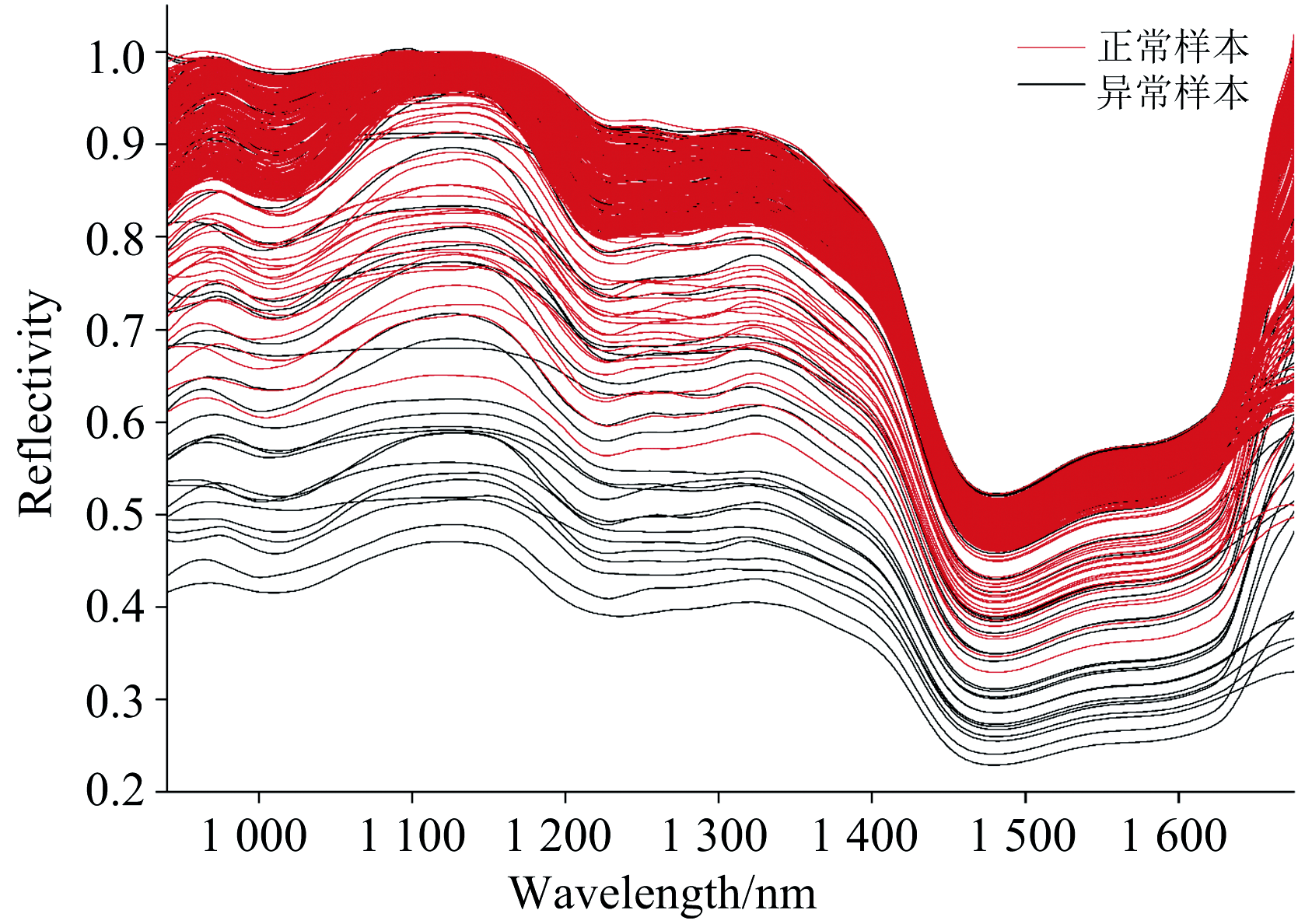 | 图5 藕粉样本的光谱曲线Fig.5 Spectral curves of lotus root starch samples |
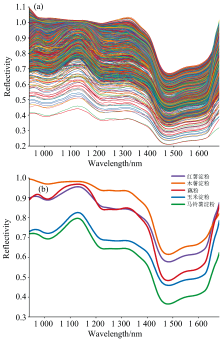
图6(a)展示了所有样本的光谱曲线和红薯淀粉、 木薯淀粉、 藕粉、 马铃薯淀粉和玉米淀粉五种纯淀粉的平均光谱曲线。 可以看出五种淀粉的光谱曲线表现出相似的趋势、 波峰和波谷。 在1 150~1 200 nm波段, 光谱反射率急剧降低, 然而, 峰谷位置略有不同, 这主要是由于不同淀粉的化学成分含量不同。 在980 nm左右的吸收峰O— H第二泛频的伸缩振动有关, 1 200 nm左右的吸收峰归因于C— H第二泛频的伸缩振动, 在1 450 nm附近的吸收峰来自O— H第一泛频的伸缩振动, 1 620 nm附近的吸收峰对应C— H第一泛频的伸缩振动[33, 34]。
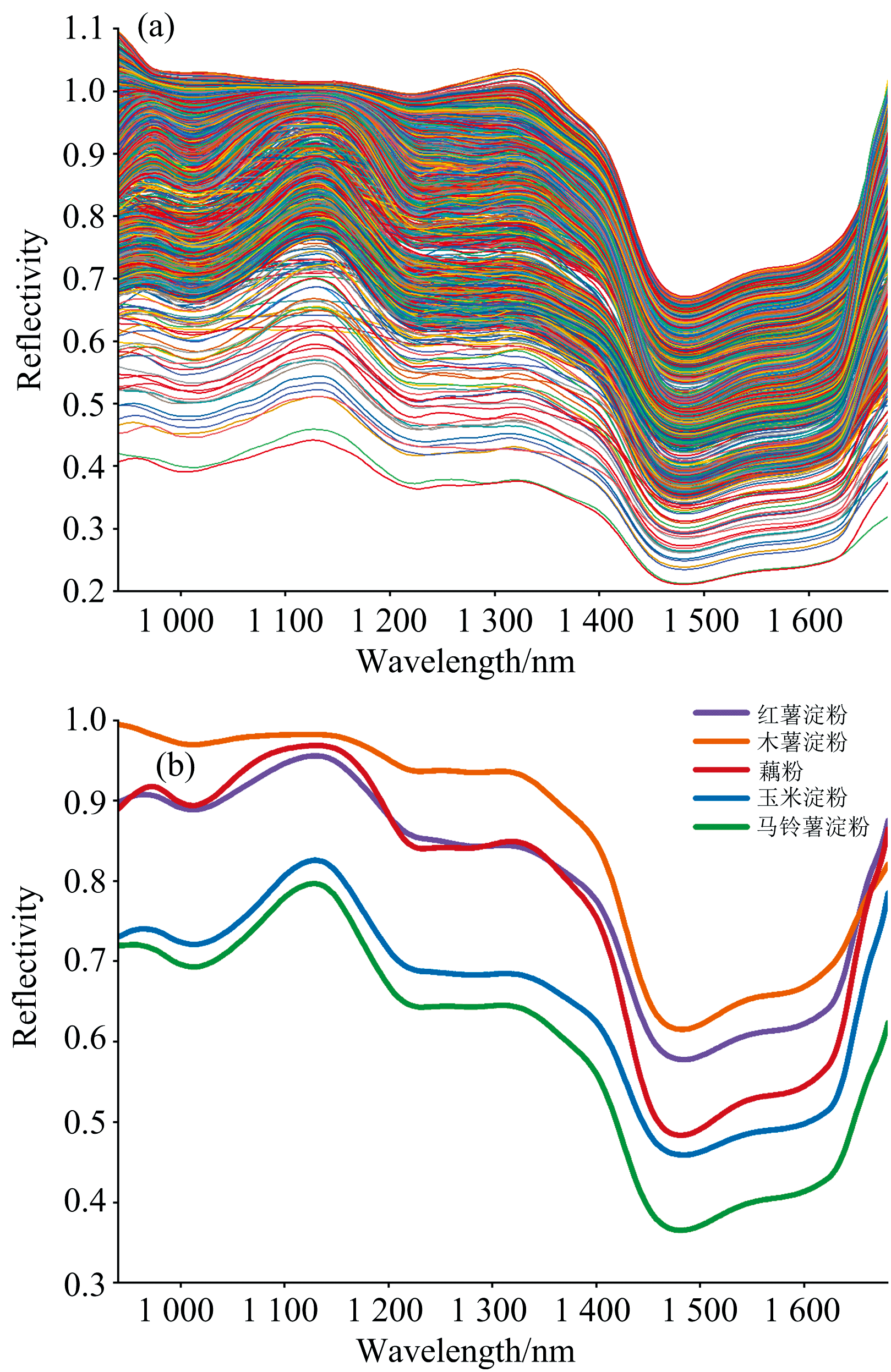 | 图6 藕粉和四种普通淀粉的光谱曲线 (a): 原始光谱曲线; (b): 平均光谱曲线Fig.6 Spectral curves of lotus root starch and four common starches (a): Original spectral curve; (b): Average spectral curve |
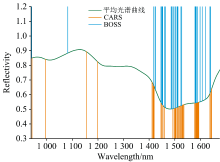
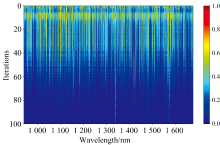
图7展示了CARS算法和BOSS算法提取的特征波长位置, 它们主要集中在1 400~1 650 nm之间, 这可能是因为样品的光谱曲线在这些波段有着更明显的区分度。 将CAMM算法迭代过程中的所有波段权值缩放到[0, 1]范围内, 波段权重变化如图8所示。 可以看到, 随着迭代次数的增加, 波段权重分布逐渐变得越来越稀疏。 同时, 由于冗余波段最终会被赋予很小的权值, 使得特征波段更容易被区分。
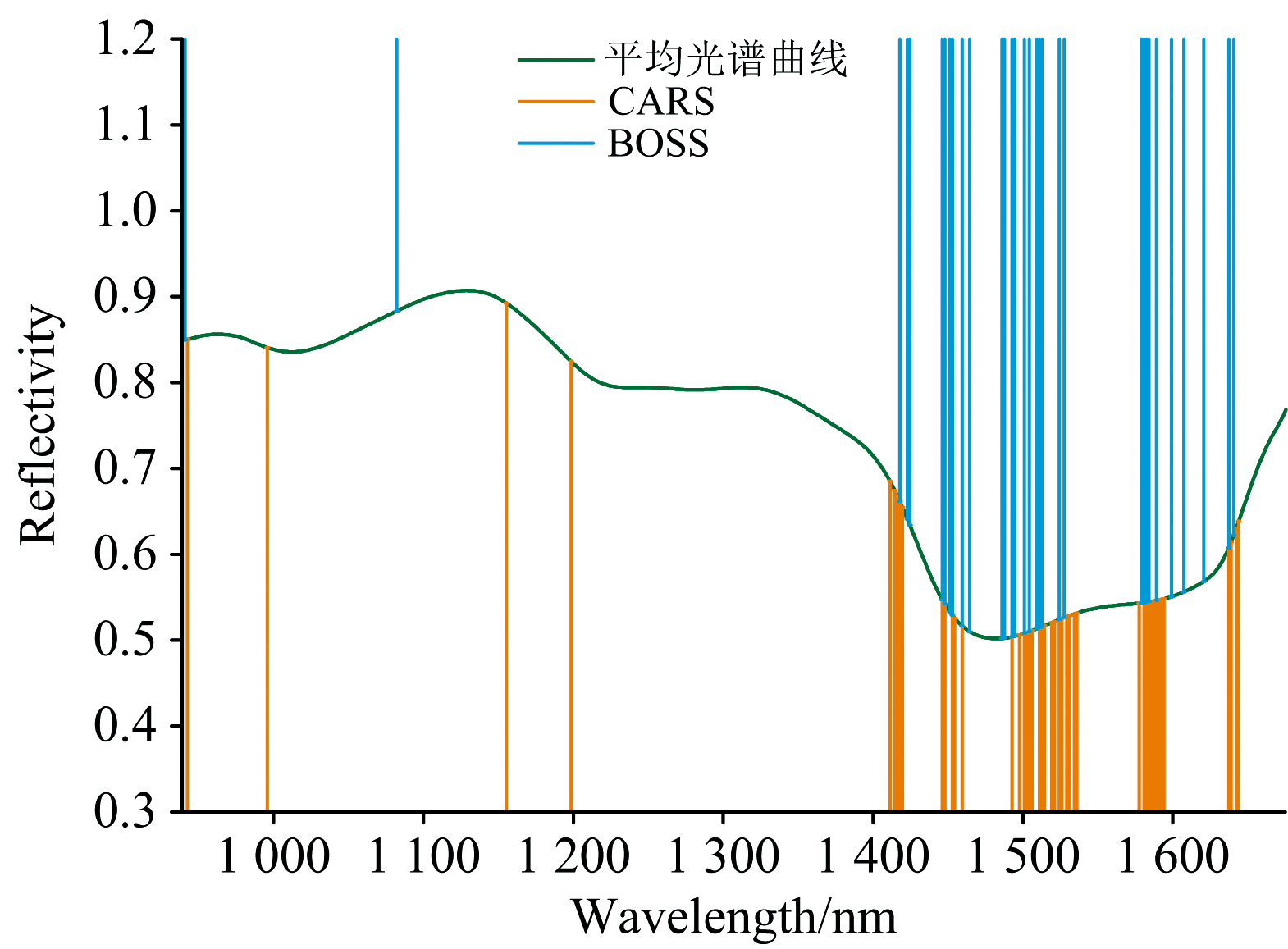 | 图7 CARS和BOSS提取的特征波长分布Fig.7 Distribution of characteristic wavelengths extracted by CARS and BOSS |
 | 图8 CAMM迭代过程中的波段权重可视化Fig.8 Visualization of band weight during CAMM iteration process |
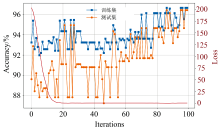
为了分析CAMM的收敛性和效果, 将每次迭代中波段权重最大的12个波段构成特征波段向量集, 输入到PLS-DA分类模型中。 CAMM的损失函数曲线和PLS-DA分类精度变化可视化如图9所示。 从图中可以看出, 随着迭代次数增加, 训练损失快速减小, PLS-DA分类精度逐渐提高。 当迭代到20次左右, CAMM的损失值非常接近于零。 而PLS-DA经过80次迭代, 训练集和测试集的分类准确率都稳定在96%左右。 同时, 可以发现PLS-DA的分类准确率从88%提高到96%, 提高了8%, 进一步证明了CAMM的有效性。 以上分析表明, CAMM易于训练且收敛速度快。
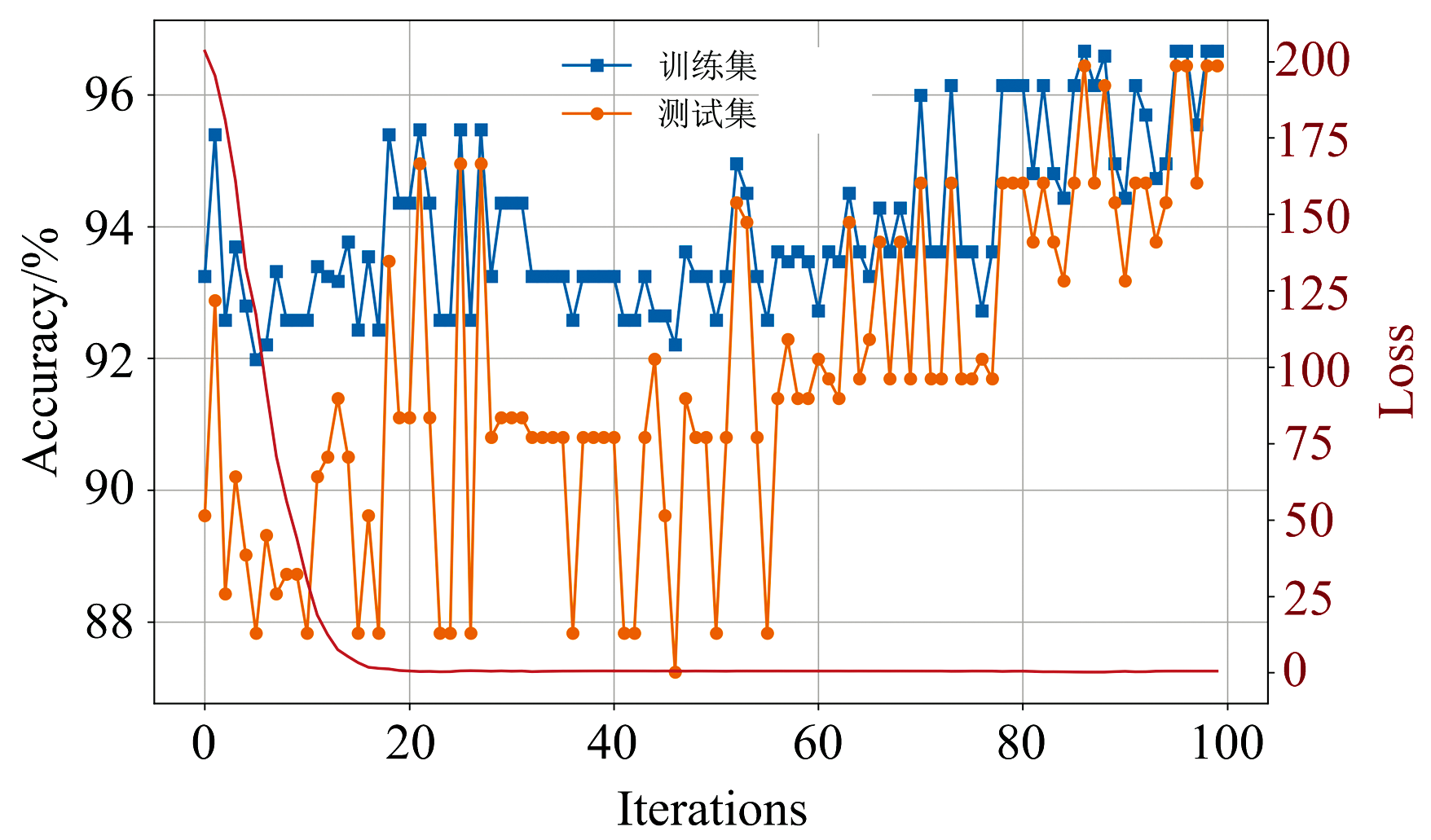 | 图9 CAMM迭代过程中的损失和分类准确率Fig.9 Losses and classification accuracy during CAMM iteration process |
为了挑选出最佳特征提取算法, 基于PLS-DA分类算法, 对比了CARS、 BOSS和CAMM算法提取特征波长后的模型分类效果, 具体分类结果如表1所示。 从表中可以看出, CARS, BOSS和CAMM选择的波长数分别为45, 32和12。 虽然基于CAMM算法的分类准确率和全波段相比, 训练集和测试集分别降低了1.11%和1.77%, 但远远高于CARS和BOSS算法下的分类准确率, 并且明显CAMM筛选的特征波长数更少, 说明CAMM在选择更少特征波段的同时, 取得了更好的分类效果。 造成这种情况的原因可能是CARS和BOSS没有完全消除冗余波长, 而且消除了部分弱特征波长, 导致模型精度有所降低。 此外, 这两种算法以RMSECV和RC的绝对值为评价指标, 搜寻具有最小RMSECV和最大RC绝对值的特征波段子集。 这种基于极值搜索的波段选择过程具有一定的随机性, 需要研究人员不断的进行实验选择出最佳的特征波段子集, 具有很大的不稳定性并加大了计算量[35]。 而CAMM的神经网络结构能够充分学习波段之间的非线性关系, 并在迭代过程中, 不断增加重要特征波段的权重, 降低无关或冗余波段的权重, 这就避免了随机划分特征波段子集的不确定性。 综合以上分析结果表明, CAMM在保证模型效果的同时, 极大的降低了模型的复杂度。 因此, 本研究将选择CAMM作为最佳特征提取算法应用于藕粉的真伪判别。
| 表1 不同特征提取算法的建模结果 Table 1 Modeling results of different characteristic extraction algorithms |
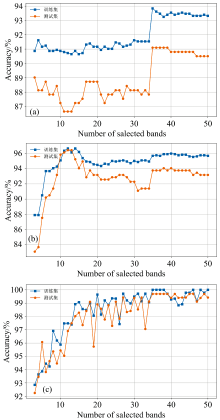
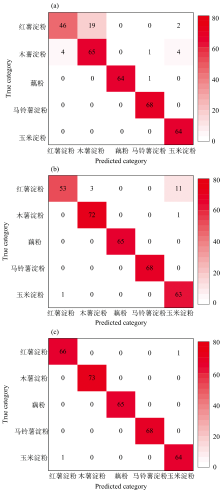
前面的分析表明CAMM提取的特征波长分类效果更优异, 因此将CAMM选择的特征波长构成特征光谱数据集输入到不同分类算法中探寻最佳分类模型。 在特征波段大小为3~ 50、 波段间隔为1的情况下, SVM、 PLS-DA和CNN三种分类算法的分类准确率如图10所示。 在图中, 首先发现了一个反自觉的现象, 即准确率并不会随着特征波段子集的增大而一直提高。 一开始随着特征波段的增大, 三种算法的准确率均有一定程度的提高, 但当特征波段大小增大到35后, 准确率又有缓慢降低的趋势, 这种现象可以被称呼为休斯现象, 即当特征维度增加时分类精度会上升, 但增加到某个临界值时, 如果继续增加维度, 分类精度反而会下降[26]。 导致这种现象的原因可能是特征波段子集较小时, 都是一些波段权重大的显著特征波段, 可以帮助提高模型分类精度, 但当特征波段子集大小到达到一定数目后, 再增加的波段权重较小, 特征较弱, 对模型效果提升不大, 甚至是冗余、 无关的干扰波段, 反而影响模型分类精度。 在图10中, 可以看到SVM和CNN均在特征波段子集大小为35时表现出最佳的分类性能, 而PLS-DA在特征波段子集大小为12达到最佳。 虽然PLS-DA取得最佳分类性能所需的特征波段最小, 但在同样特征波段大小的情况下, CNN有着比PLS-DA更高的分类准确率。 进一步地, 绘制了它们各自取得最佳分类性能时的测试集混淆矩阵(图11), 以及对应的详细分类结果(表2)。 通过图11和表2的结果可以直观地看到, CNN只有一个红薯淀粉样本被误判为玉米淀粉样本, 其他类别全部分类正确, 总体准确率达到了99.69%, 精度高于SVM和PLS-DA。 考虑到CNN的优异分类效果, 进一步分析CNN的收敛性和有效性。
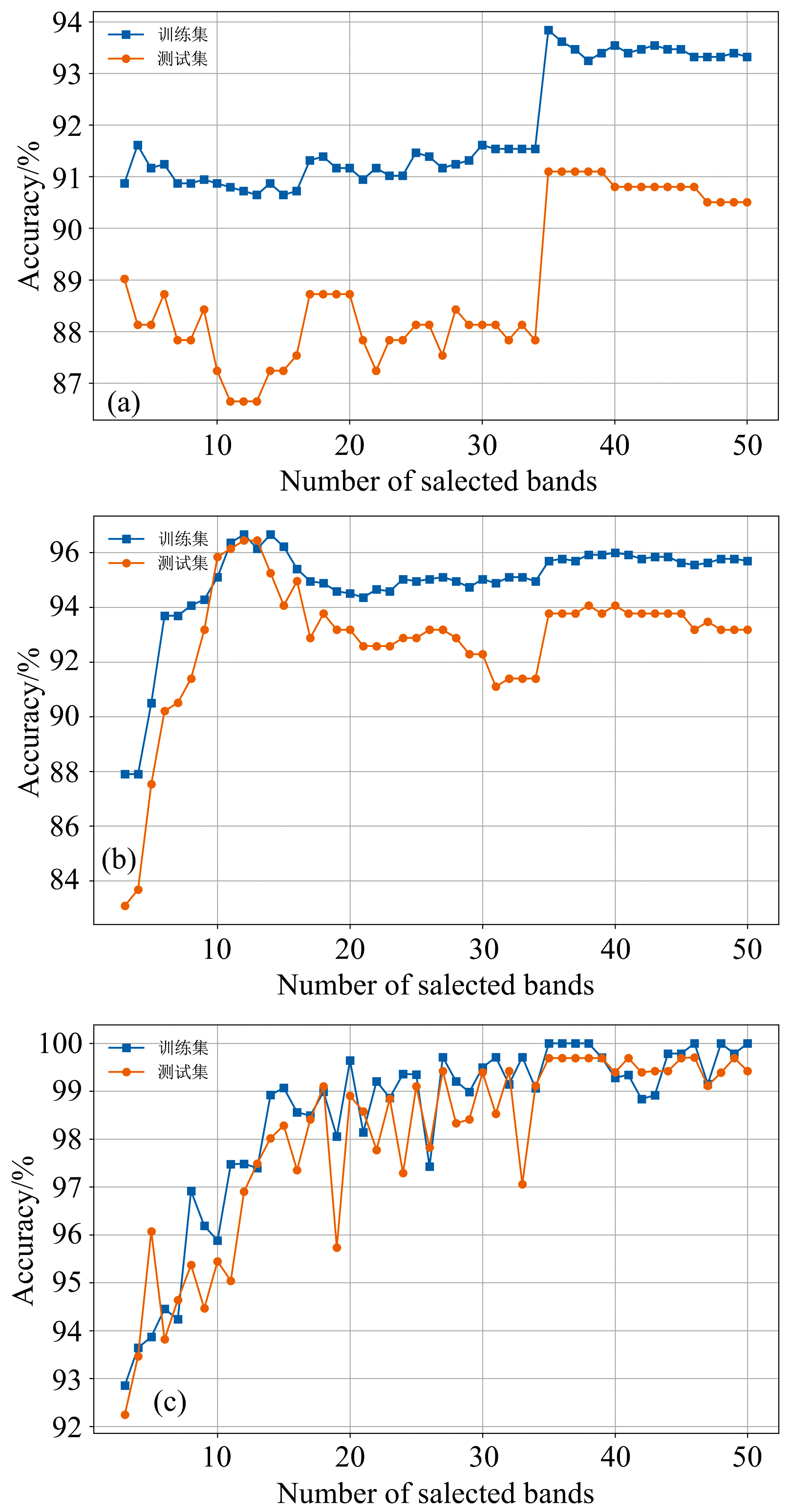 | 图10 (a)SVM、 (b)PLS-DA和(c)CNN基于CAMM选择特征波段的分类表现Fig.10 Classification performances of (a) SVM, (b) PLS-DA, and (c) CNN based on CAMM selected characteristic bands |
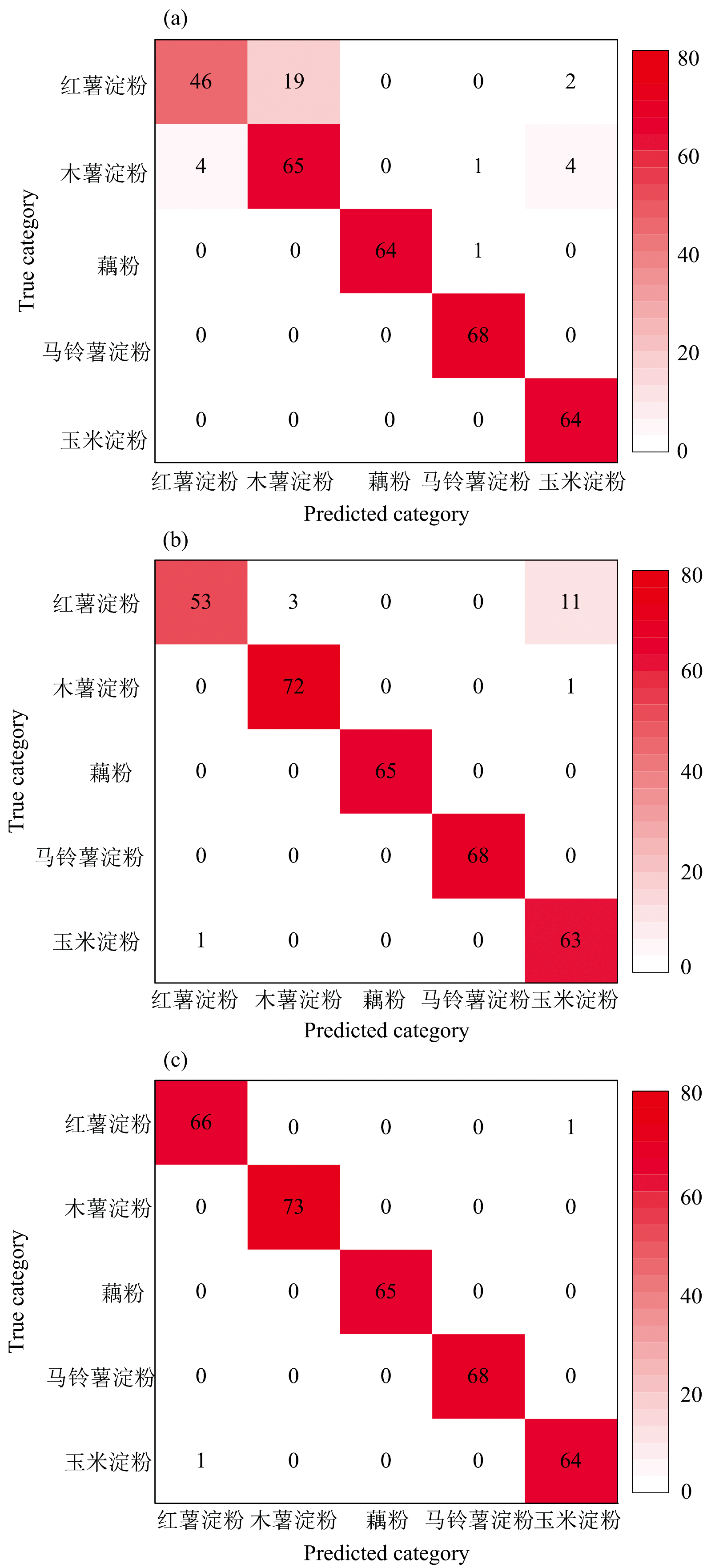 | 图11 (a)SVM、 (b)PLS-DA和(c)CNN最佳分类效果下的测试集混淆矩阵Fig.11 Test set confusion matrices for (a) SVM, (b) PLS-DA, and (c) CNN with optimal classification performance |
| 表2 (a)SVM、 (b)PLS-DA和(c)CNN最佳分类效果下的测试集分类结果 Table 2 Test set classification results of (a) SVM, (b) PLS-DA, and (c) CNN with optimal classification performances |
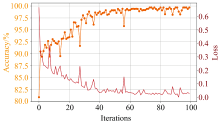
基于CAMM选择出的35个特征波段对CNN进行100次迭代训练, 并绘制训练过程中的损失变化曲线和测试集准确率变化曲线, 如图12所示。 从图中可以看出, CNN的收敛速度较快, 在迭代次数到达40次左右达到收敛。 同时, 测试集准确率从最初的80.88%提升到了98.84%, 之后逐渐趋于平稳, 在99%左右波动, 最终达到99.69%的分类准确率, 说明CNN的训练效果优秀, 能够有效的学习输入光谱数据的特征。
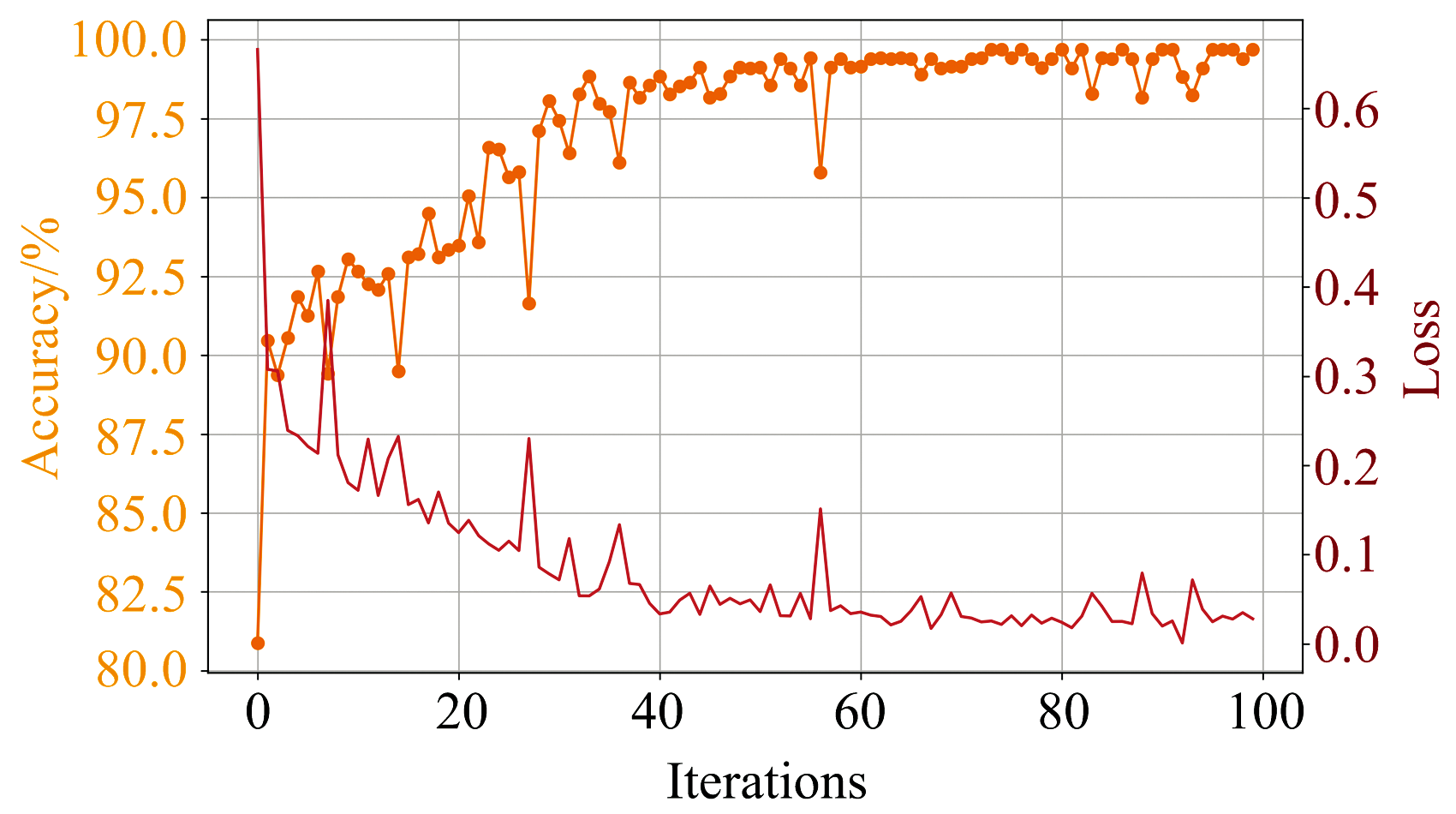 | 图12 CNN迭代过程中测试集的损失和准确率Fig.12 Loss and accuracy of test set during CNN iteration process |
综上所述, CAMM比CARS和BOSS提取的特征波长更具区分度, 特征信息更明显, 能带给模型更好的分类效果。 同时CNN比SVM和PLS-DA的分类准确率更高, 分类效果更好。 因此, 选择CAMM-CNN作为最佳分类模型, CAMM-CNN的最佳分类表现筛选出了波段权重最大的35个波段, 仅占全波段的7.9%, 同时模型训练集和测试集分类准确率分别达到了100%和99.69%, 取得了令人满意的结果。 CAMM-CNN的关键参数如表3所示。
| 表3 CAMM-CNN模型的关键参数 Table 3 Key parameters of the CAMM-CNN model |
建立的CAMM-CNN分类模型不仅能够利用光谱数据鉴别出藕粉和普通淀粉, 还可以通过高光谱数据中的二维图像在空间维度上对掺假藕粉进行可视化。 在二元混合掺假藕粉中掺入马铃薯淀粉, 接着加入玉米淀粉制备三元混合掺假藕粉, 再掺入红薯淀粉构成四元混合掺假藕粉, 最后加入木薯淀粉得到五元混合掺假藕粉。 通过提取掺假样品所有像素点的光谱数据, 输入到训练好的CAMM-CNN模型中得到每个像素点的所属类别。 为了直观表现分类结果, 对不同类别的像素点赋予不同的颜色, 并根据每个像素点的坐标信息在伪彩色图像中呈现出来, 从而实现对掺假藕粉的可视化分析。
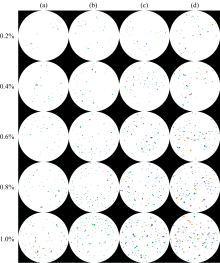
图13展示了20个混合掺假藕粉的伪彩色图像, 其中白色像素点代表藕粉, 绿色像素点代表马铃薯淀粉, 蓝色像素点代表玉米淀粉, 紫色像素点代表红薯淀粉, 橙色像素点代表木薯淀粉。 从可视化结果来看, 掺假物像素点的数量随着掺假浓度的提高而增加, 说明CAMM-CNN模型能够准确识别藕粉中的掺假物。 此外, 最低0.2%掺假浓度的混合掺假藕粉样品也被CAMM-CNN模型成功识别出掺假物, 证明了高光谱成像技术结合深度学习方法对粉状物质进行快速准确判别的巨大潜力。
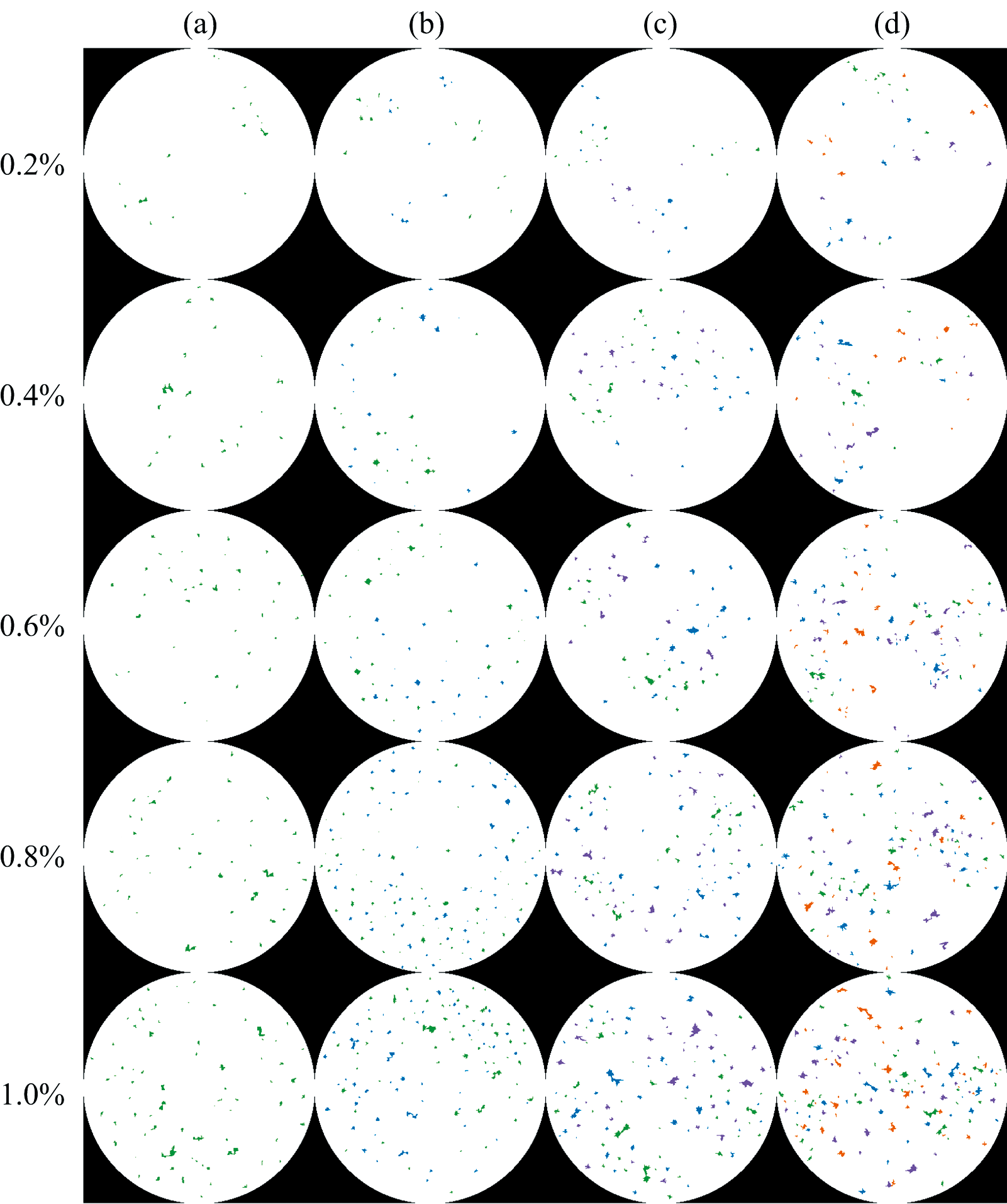 | 图13 四种混合掺假藕粉不同掺假浓度下的可视化结果 (a)— (d)图依次是二、 三、 四、 五元混合掺假藕粉Fig.13 Visualization results of four types of mixed adulterated lotus root starch with different adulteration concentrations Figures (a) to (d) represent binary, ternary, quaternary, and quinary mixed adulterated lotus root starch, respectively |
利用高光谱成像技术结合深度学习算法, 搭建了能够准确判别藕粉和其他普通淀粉的分类模型。 不同于传统的机器学习方法和数据处理方式, 本研究在不经过数据预处理的情况下, CAMM-CNN模型根据波段权重筛选了35个特征波长, 减少了92.10%的波长数, 在测试集中的总体分类准确率达到了99.69%, 比SVM和PLS-DA分别高了8.59%和4.45%。 对模型进行多元掺假藕粉识别验证, 也取得了良好的判别效果, 准确识别出了最低0.2%掺假浓度下的掺假物。 基于不同算法的模型结果和掺假藕粉的验证结果表明, CAMM-CNN模型能够快速、 准确的识别藕粉和其他淀粉, 此模型的建立对高光谱技术应用于藕粉的质量检测和淀粉的掺假判别具有重要的参考价值。
此外, 得益于CAMM和CNN的灵活性, 两个网络模块还可以拆分到不同的网络模型中进行应用, 为其他分类模型网络框架的搭建提供了新的选择。 在未来的工作中, 将扩大样本种类和数量, 进一步验证模型的泛化能力。 如增加小麦淀粉、 绿豆淀粉等其他常见淀粉种类, 以及不同品牌和产地的藕粉样本, 确保模型在不同场景下的适用性。 同时优化深度学习网络模型的结构和参数, 探索模型的检测下限, 目标是将检测灵敏度提高到0.1%甚至更低, 以满足更高标准的食品安全检测需求。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|