

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外反射光谱的宣纸含水率无损检测研究
[王建旭1  , 谭银雨
, 谭银雨1 , 覃丹2, * , 汤斌1 , 唐欢2 , 范文奇2 , 杨玟1 , 钟年丙1 , 赵明富1, * ]
, 谭银雨, 汤斌]
|
|


作者简介: 王建旭, 1989年生,重庆理工大学讲师 e-mail: wangjianxu@cqut.edu.cn
含水率是影响纸质文物保存的重要因素之一, 为了建立一种快速无损检测纸质文物本体含水率检测方法, 以重庆中国三峡博物馆提供的棉料四尺单宣为研究对象, 利用近红外光谱仪结合化学计量学的方法无损检测宣纸本体含水率。 将7种不同的湿度盐放入封闭环境箱中, 调整环境湿度范围至37%RH~97%RH, 并将宣纸置于封闭环境箱内平衡7 d, 利用烘干法测得宣纸含水率范围为6.35%~15.55%。 近红外光谱采集的范围为900~1 700 nm, 原始光谱数据采用光谱-距离联合法(SPXY)以4∶1的比例将210条样本划分为168条训练集和42条验证集。 原始光谱数据分别利用标准正态变量变换(SNV)、 基线校正(BC)、 归一化(Normalize)及其组合方法进行数据预处理。 利用连续性投影算法(SPA)和竞争性自适应重加权算法(CARS)选择特征波段, 并建立全波段的线性偏最小二乘回归模型(PLSR)、 特征波段的PLSR模型以及非线性的双层BP神经网络(DL-BPNN)模型。 结果表明, 以全波段数据建立的模型中, 最佳预测模型为SNV-PLSR, 其验证集均方根误差(RMSEP)为0.6445, 决定系数(
, TAN Yin-yu, TANG Bin
Water content is a critical factor affecting the preservation of paper cultural relics. To establish a rapid, non-destructive method for detecting the moisture content of paper artifacts, this study focuses on four-foot single-layer Xuan paper made of cotton. We utilized near-infrared (NIR) spectrometry combined with chemometrics for non-destructive moisture detection. Seven different humidifying salts were placed in a sealed environment box to create humidity conditions ranging from 37% to 97% relative humidity (RH). The Xuan paper samples were equilibrated in this controlled environment for seven days. The water content of the samples was measured to range between 6.35% and 15.55% using the drying method. NIR spectra were collected over the range of 900 to 1 700 nm. The raw spectral data were divided into 168 training sets and 42 validation sets using the spectral-distance joint method (SPXY) at a ratio of 4∶1 for a total of 210 samples. The data were preprocessed using Standard Normal Variate (SNV), Baseline Correction (BC), and normalization, both individually and in combination. Feature bands were selected using Successive Projections Algorithm (SPA) and Competitive Adaptive Reweighted Sampling (CARS). Subsequently, linear partial least squares regression (PLSR) models were established for the full spectrum and selected feature bands, as well as a nonlinear double-layer backpropagation neural network (DL-BPNN) model. The results indicated that the best prediction model for the full spectrum was SNV-PLSR, with a root mean square error (RMSEP) of 0.644 5 and a coefficient of determination (
纸质文物是先辈遗留的瑰宝, 蕴含了中国丰富的文化, 是重要的历史文化载体[1]。 纸质文物在保存过程中极易受到损害, 特别是环境湿度对其影响尤为显著。 作为吸湿材料, 纸质文物在高湿环境下容易吸水, 导致受潮和微生物生长, 最终引发霉变; 在低湿环境下则会脱水, 导致变形和开裂[2]。 因此, 环境湿度的变化直接影响纸质文物的含水率, 进而影响其保存状态和寿命。 然而, 环境湿度与纸质文物的本体含水率之间并不呈简单的对应关系。 因此, 探究纸质文物的本体含水率至关重要。 通过监测和控制纸质文物本体含水率, 可以有效预防环境湿度对文物的损害, 确保文物得到妥善保护, 延长其寿命, 保持其历史和文化价值。
传统的纸质水分检测主要依据现行国家标准GB/T 462— 2023[3], 这种烘干测量方法虽然结果准确, 但对珍贵的纸质文物有显著的局限性。 首先, 烘干测量法会破坏纸质文物, 经过高温加热后纸张会出现明显的变色变脆现象甚至导致其裂化, 这对不可再生的纸质文物来说是不适用的; 其次烘干法所需样品量大, 多数书画文物未装裱之前是单层纸张, 无法用烘干法进行测量; 此外, 目前还没有专门测量单层纸质文物本体含水率的方法。 基于此, 本研究以书画中常用的纸张— — 宣纸[4]为例, 提出了利用近红外光谱法(near infrared spectroscopy, NIRS)测量不同湿度下单层纸张含水率的方法。
NIRS主要通过O— H基团的吸收来无损测定物品中的含水率[5, 6]。 近年来, NIRS在检测物品含水率方面取得了显著成果。 例如, Peng等[7]利用近红外光谱结合化学计量学的方法, 通过SNV-FD-PLSR模型成功预测了核桃仁的水分含量。 Wang等[8]利用近红外光谱结合偏最小二乘法(PLS)建立了一个新鲜茶叶含水量的在线检测系统, 实现了快速无损测量茶叶含水量。 还有Li等[9]结合向量回归(SVR)-自适应提升(AdaBoost)-偏最小二乘回归(PLSR)-AdaBoost模型成功预测了马尾松幼苗的含水率。
这些研究表明, NIRS技术在测量样品含水率方面具有很高的可行性和潜力。 然而, 尽管NIRS已广泛应用于含水率测量, 单层纸张含水率的测量还鲜有报道。 因此, 利用NIRS技术的在线无损测量特点, 对单层纸张含水率进行测量的新方法探索。 以有效实现对纸质文物本体含水率快速、 无损的测量, 进而实现对纸质文物的预防性保护。
纸张样品由重庆中国三峡博物馆提供的棉料四尺单宣, 将其裁剪成~60 cm× 6 cm的纸条, 每条样品约重2 g。 纸质样品放置于封闭的环境箱中, 环境箱湿度设置为37%RH(硅胶)、 47%RH(无水碳酸钾)、 57%RH(溴化钠)、 67%RH(尿素)、 77%RH(氯化钠)、 87%RH(氯化钾)、 97%RH(硫酸钾)共7种湿度环境, 每个环境箱放入30条样品, 共计210条样品。 样品在密闭环境箱中静置7 d, 以确保纸质在各自湿度环境中达到平衡状态, 实验装置如图1所示。 每条样品的实际含水率根据国家标准GB/T 462— 2023通过烘干测量, 样品从封闭环境箱中取出后, 在50s内放入水分测试仪中进行水分含量测定, 使用的设备是XY-P120G水分仪, 测得所有样品的含水率范围为6.35%~15.55%。
 | 图1 不同环境湿度下宣纸样品封闭平衡装置图Fig.1 Sealed equilibrium setup for Xuan Paper samples under different environmental humidity conditions |
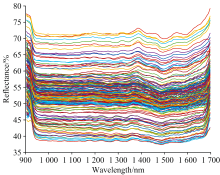
光谱数据采集系统如图2所示, 由莱森光学(深圳)有限公司的制冷型近红外光谱仪(LiSpec-NIR4000-1.7TEC)、 反射式光纤(IFR-7IR200-2-GS)、 卤钨灯光源、 光纤探头支架、 载物台及计算机组成。 光谱采集软件为光谱仪配套的LispecView, 设置积分时间为900 ms, 平均测量次数为2次, 光谱采集波长范围为900~1 700 nm。 为了确保实验数据的准确性, 所有样品采集均在密闭的暗箱中进行, 待测样品从封闭环境箱中取出后, 在50 s内完成光谱数据采集, 每个待测样品连续采集5次, 随后, 取5次采集的光谱数据的平均值, 作为该条样品的光谱数据。 宣纸近红外光谱的原始光谱曲线如图3所示。
 | 图2 近红外光谱采集的系统图Fig.2 Schematic diagram of the near-infrared spectral data collection system |
 | 图3 宣纸近红外光谱原始图Fig.3 Original near infrared spectra of Xuan Paper |
1.3.1 数据集划分
为了有效预测宣纸的含水率, 采用基于联合X-Y距离的样本集划分方法(sample set partitioning based on joint X-Y distances, SPXY), 以确保训练集和验证集的光谱数据(X)和含水率(Y)均具代表性和多样性, 从而提高模型的泛化能力和稳定性[10]。 具体来说, 按照4∶ 1的比例将210条纸质样品划分为168条训练集和42条验证集。 SPXY方法划分的训练集和验证集含水率的最大值、 最小值、 平均值和标准偏差均非常接近, 如表1所示。 这表明样本划分具有良好的代表性和均匀性, 有利于建立稳定的预测模型。
| 表1 SPXY法划分样本集单宣水分含量数据统计表 Table 1 Statistical data of moisture content in Xuan Paper sample sets divided by SPXY method |
1.3.2 数据预处理
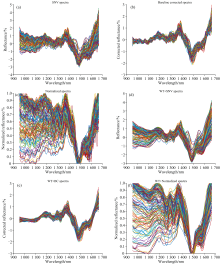
由于仪器噪声和外部环境的影响, 采集到的光谱数据中可能存在干扰信号, 导致原始光谱中出现基线漂移、 散射效应和噪声[11, 12]。 通过分析发现, 仪器的两端边缘部分900~954和1 667~1 700 nm范围内噪声较大, 数据信噪比低, 影响数据质量, 不适合用于进一步分析。 此外, 水分子的O— H伸缩振动和弯曲振动的特征吸收峰集中在1 000和1 500 nm附近, 这些吸收特征能够有效反映纸张中水分含量的变化[13, 14, 15]。 因此, 选择954~1 667 nm波段进行后续分析, 该波段不仅覆盖了水分的关键吸收特征, 还有效避开了高噪声区域, 以提高模型的稳健性和准确性。 主要采用了以下光谱预处理方法: 标准正态变量变换(standard normal variate, SNV)、 基线校正(baseline correction, BC)、 归一化(normalization, Norm)。 此外, 在联合预处理时, 使用了小波变换(wavelet transform, WT)与其他方法结合, 包括WT-SNV、 WT-BC和WT-Norm。 不同预处理方法的结果如图4所示。
 | 图4 不同预处理之后的近红外光谱图Fig.4 Near-infrared spectra after different preprocessing methods |
1.3.3 连续投影算法
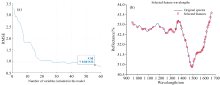
连续投影算法(successive projections algorithm, SPA)旨在减少多重共线性并提高模型的预测性能。 SPA通过选择最小投影相似度的变量来减少冗余信息, 从而选出最具代表性的特征波长[16, 17]。 未预处理的全波段特征选择和经过预处理的光谱均采用相同的SPA方法。 如图5所示, 特征波长的挑选由均方根误差(root mean square error, RMSE)决定, 即较低的RMSE表明模型的预测性能更好。 当RMSE达到最小时, 对应的特征波长数即为最佳特征波长数。 图5(a)展示了当RMSE为0.841 13时, 最佳特征波长数为56个, 原始光谱中的特征波长分布如图5(b)所示。
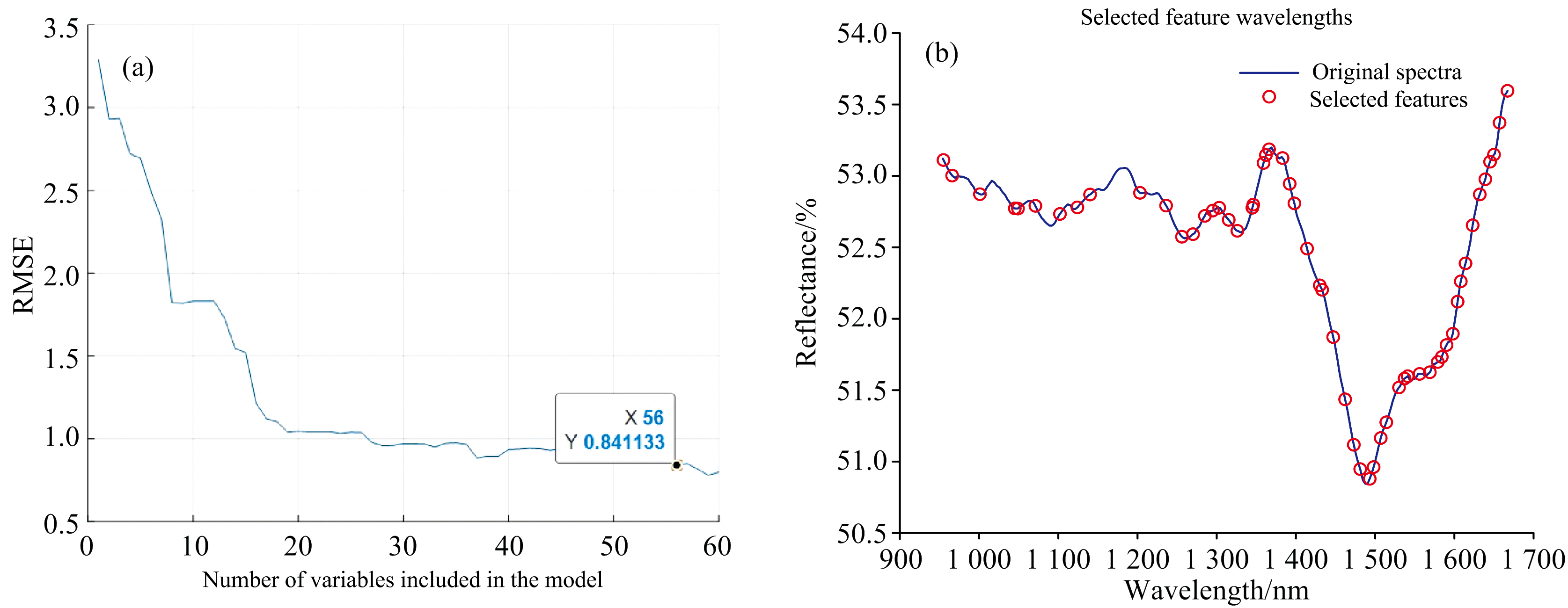 | 图5 SPA算法筛选宣纸光谱特征波长过程图Fig.5 SPA algorithm process for selecting characteristic wavelengths of Xuan Paper spectra |
1.3.4 竞争性自适应重加权算法
竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)基于蒙特卡洛方法, 通过多次采样和重加权筛选出最具代表性的特征波长[18]。 未预处理原始光谱和预处理后的光谱均采用相同的方法。
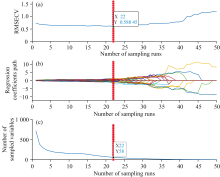
如图6所示, 蒙特卡洛采集次数为50次。 图6(a)展示了RMSECV随采样次数的变化趋势。 RMSECV先缓慢减少至最小值0.588 45, 然后逐渐增大。 这表明在RMSECV最小值处, 选取的特征波长集相关性最好, 进一步增加采样次数则会剔除与水分含量相关的波长, 导致RMSECV值上升。 图6(b)展示了回归系数随采样次数的变化情况, 红色标记点表示最佳采集次数为22次。 图6(c)展示了所选择波长数量随采样次数的变化, 红色标记点表示筛选出的最佳波长数为58个。
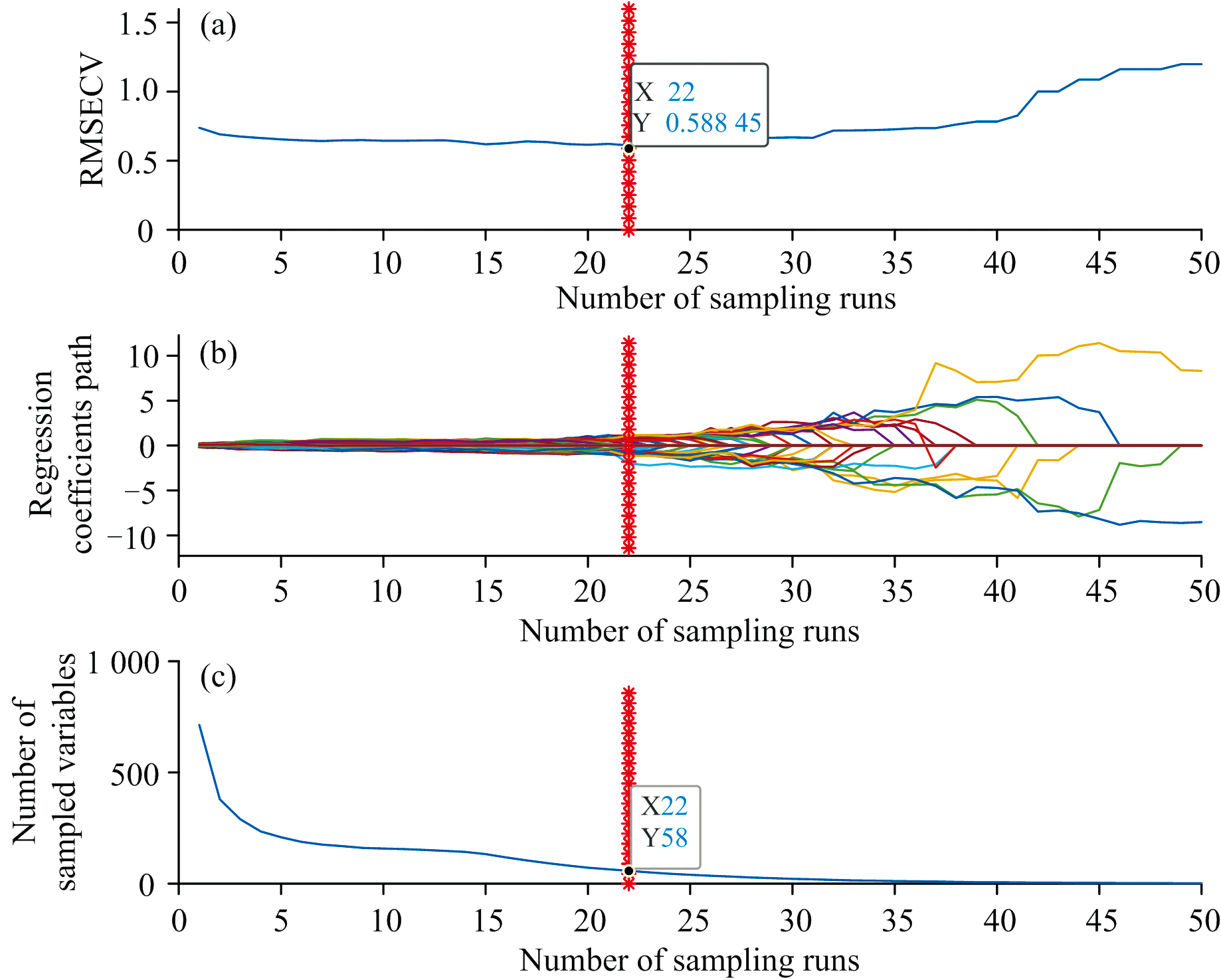 | 图6 CARS算法筛选特征波长过程图Fig.6 CARS algorithm process for selecting characteristic wavelengths |
1.4.1 偏最小二乘模型
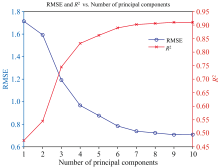
偏最小二乘回归(partial least squares regression, PLSR)用于处理高度相关和多重共线性的光谱数据, PLSR通过考虑预测变量(X)和响应变量(Y), 建立它们之间的线性关系[19]。 找到最佳的主成分数是PLSR建模的关键步骤。 主成分过少可能无法捕捉数据中的主要信息, 过多则可能引入噪声和冗余信息, 导致模型过拟合。 使用留一法结合RMSE和决定系数(R2)确定最佳主成分数。 以未预处理的全波段数据为例, 如图7所示, 随着主成分数的增加, RMSE先减小后趋于平稳, R2则逐渐增大并趋于稳定, 从而确定最佳主成分数。
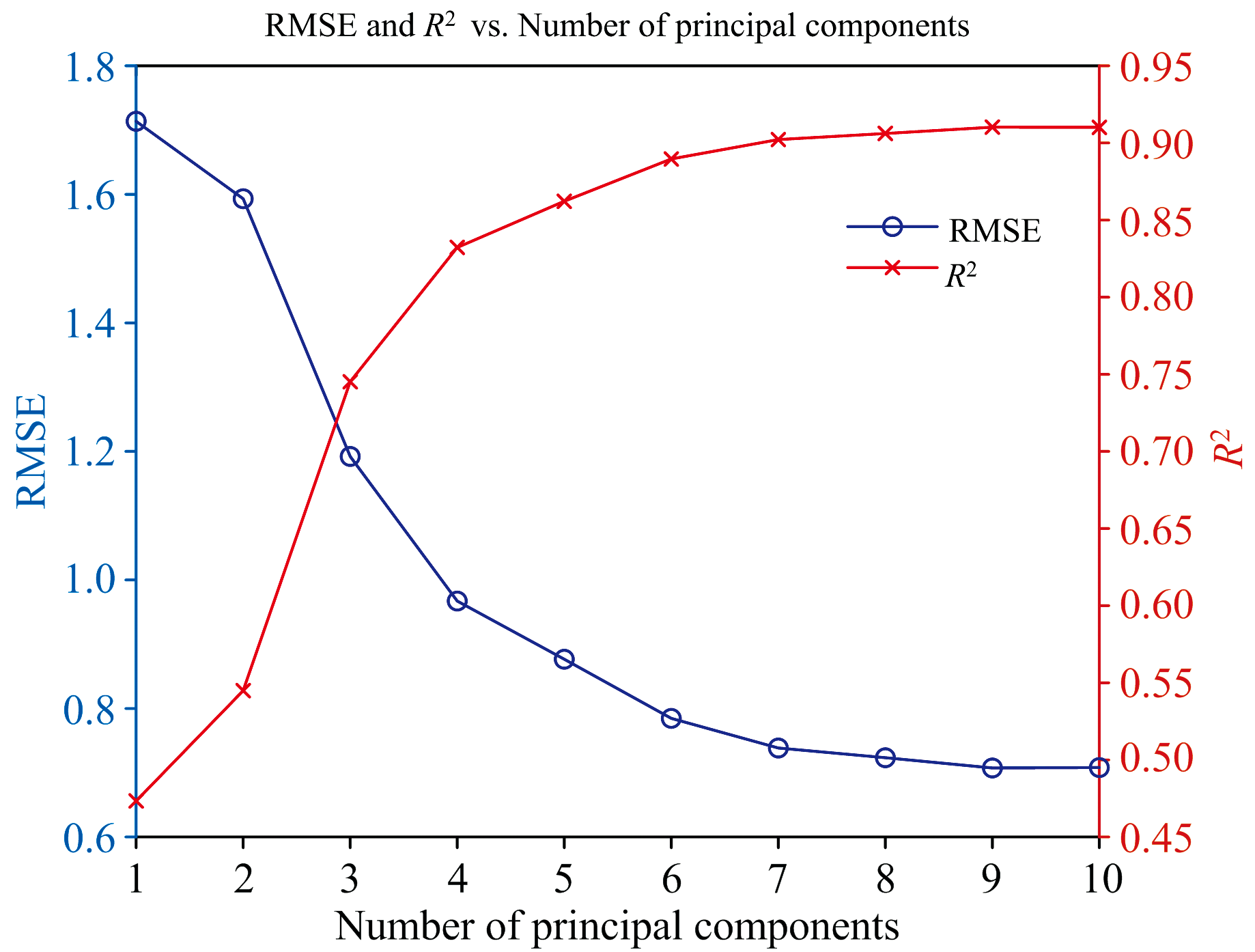 | 图7 均方根误差结合决定系数选择最佳主成分图Fig.7 Selection of the optimal number of principal components based on RMSE and R2 |
1.4.2 双层BP神经网络模型
双层BP神经网络模型(double-layer backpropagation neural network model, DL-BPNN)是在传统BPNN基础上的扩展, 由输入层、 两个隐含层和输出层组成。 每一层的神经元与下一层的神经元完全连接。 两个隐含层分别对数据进行非线性变换, 捕捉输入数据的深层次特征, 从而更好地拟合复杂的非线性数据关系[20, 21]。 其通过前向传播和误差反向传播算法调整网络权重, 以最小化预测误差。
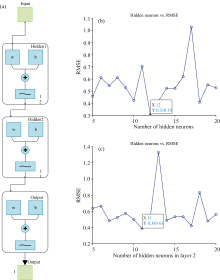
DL-BPNN的训练函数采用了Levenberg-Marquardt(trainlm), 节点传递函数选择了tansig和purelin。 为了优化网络结构, 采用网格搜索法(Grid Search)选择RMSE最小的点作为最佳隐含层神经元的数量。 以SPA提取的未处理波段为例, 图8(a)展示了DL-BPNN的结构, 图8(b)则展示了通过网格搜索法确定最佳隐含层神经元的数量。 这种方法确保了模型的最佳性能, 使其在预测宣纸含水率时能够更准确地反映复杂的非线性关系。
 | 图8 DL-BPNN模型结构及隐含层神经元数量 (a): DL-BPNN结构图; (b): 第一层最佳神经元数量; (c): 第二层最佳神经元数量Fig.8 DL-BPNN model structure and number of neurons in hidden layers (a): DL-BPNN structure diagram; (b): Optimal number of neurons in the first hidden layer; (c): Optimal number of neurons in the second hidden Layer |
1.4.3 评价标准
模型的好坏用一定的指标来衡量。 在此, 用训练集和验证集的均方根误差(RMSEC和RMSEP)、 决定系数(
RMSE和R2的计算公式如式(1)、 式(2)。
$\mathrm{RMSE}=\sqrt{\frac{\sum_{i=1}^{n}\left(X_{i}-Y_{i}\right)^{2}}{n}}$ (1)
式(1)中, Xi为实际值, Yi为预测值, n为样本数量。
式(2)中, Xi为实际值, Yi为预测值,
对比了全波段的PLSR模型、 特征波段的PLSR模型和DL-BPNN模型。 全波段数据量大, 不适合DL-BPNN模型的处理, 因此在全波段建模中未考虑使用DL-BPNN模型。 最后, 通过对比这三种模型选择出最佳的宣纸含水率预测模型。
利用1.3.2中的6种预处理方式建立全波段的PLSR预测模型。 不同预处理方式对模型的预测性能有显著影响。 通过对比这些预处理方法, 找出最合适的预处理方法, 以提高模型的预测精度。 表2列出了不同预处理方法的近红外光谱数据含水率PLSR模型结果。
| 表2 不同预处理的近红外光谱数据含水率PLSR模型结果 Table 2 Modeling results of PLSR for moisture content using NIR spectral data with different preprocessing methods |
通过表2可以看出, 不同预处理方法对全波段PLSR模型的预测能力影响显著。 原始光谱数据未经过预处理时,
由于原始光谱出现了较大的基线漂移, 因此采用SNV、 BC和Norm预处理去除基线漂移。 结果显示, SNV预处理显著提升了模型的预测效果,
经过三种预处理后仍发现存在噪声, 因此引入WT结合三种预处理方式以降低噪声。 然而, 混合预处理后的模型性能下降, 可能是因为WT在去除噪声时也去除了某些有用的信息, 导致模型性能下降。
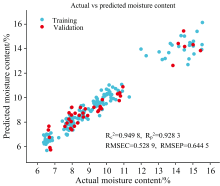
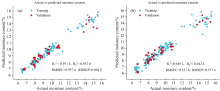
综上所述, 不同预处理方法对PLSR模型的预测效果影响显著, 其中SNV预处理方法表现最佳, 其训练集和验证集的实际值和预测值对比如图9所示, 验证了其在去除基线漂移、 散射效应和提高模型预测精度方面的有效性。
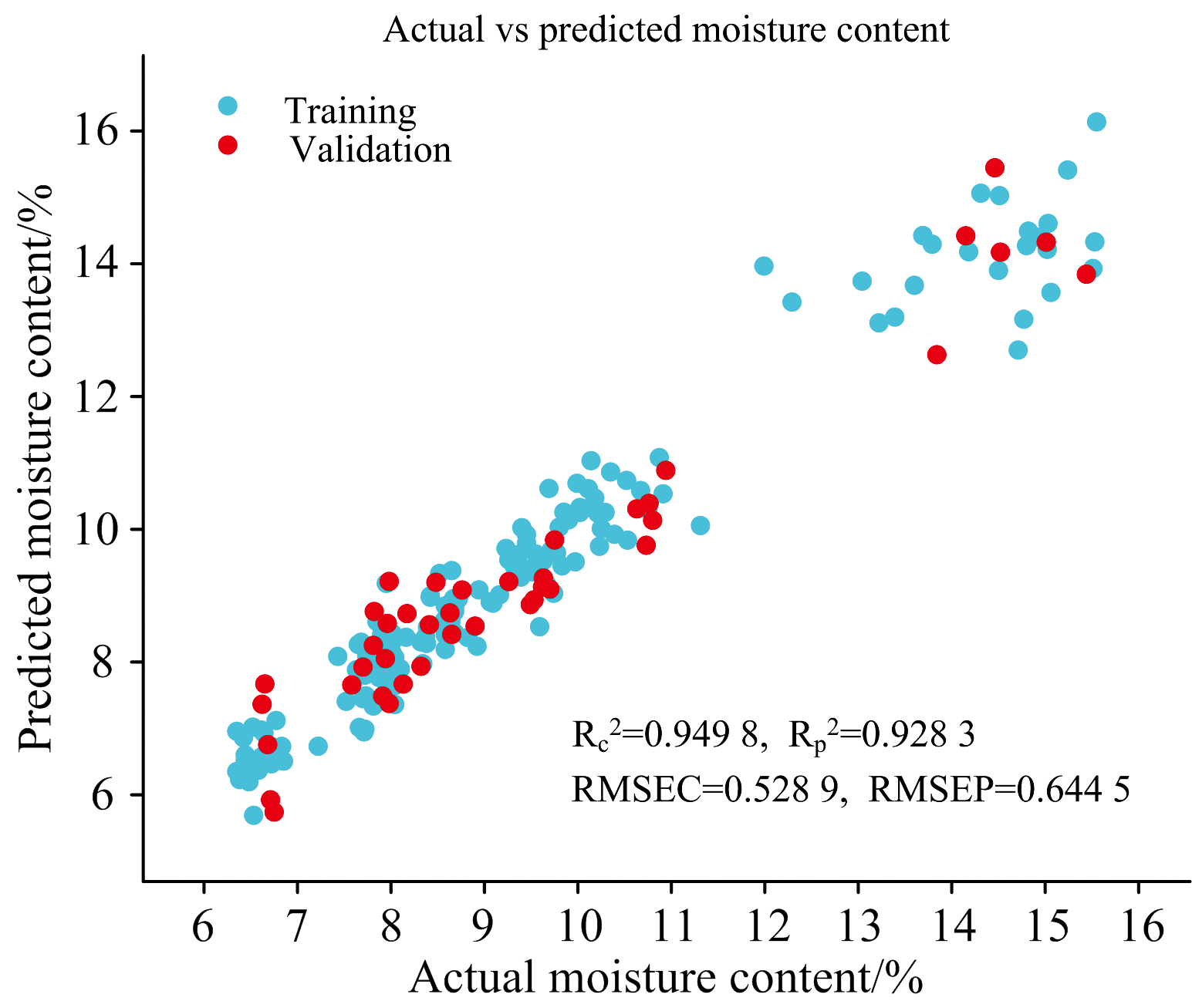 | 图9 SNV-PLSR实际值和预测值对比图Fig.9 Actual vs predicted values for SNV-PLSR model |
利用SPA和CARS两种特征提取的方法对全波段提取特征波长, 然后建立PLSR预测模型, 预测结果如表3和表4 所示。
| 表3 基于SPA特征波长筛选方法建立的PLSR结果 Table 3 PLSR modeling results based on SPA-selected feature wavelengths |
| 表4 基于CARS特征波长筛选方法建立的PLSR结果 Table 4 PLSR modeling results based on CARS-selected feature wavelengths |
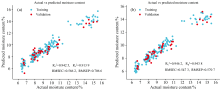
分别对比表3、 表4和表2的结果可知, 经过CARS的特征波段提取之后, 模型的预测精度有显著提升。 这说明特征提取能够有效地提取有用的波段, 并能够降低数据的复杂度。 特别是Norm-SPA-PLSR和未预处理-CARS-PLSR的结果比较突出, 其训练集和验证集的实际值和预测值的对比图如图10(a)和图10(b)所示。 此外, 从单一预处理和混合预处理来看, 两种特征提取方法的混合预处理模型预测能力显著低于单一预处理的预测能力, 可能是混合预处理过多的去除了有用的信息, 这点在表2也有所体现, 所以在特征波段提取时, 精度也不如单一预处理。
 | 图10 用SPA和CARS选择的特征波长建立的PLSR最佳预测模型的实际值和预测值对比 (a): Norm-SPA-PLSR; (b): 未预处理-CARS-PLSRFig.10 Actual vs predicted values for the best predictive models based on the feature wavelengths selected by SPA and CARS (a): Norm-SPA-PLSR; (b): Unprocessed-CARS-PLSR |
对比表3和表4可知, 无论未预处理还是经过预处理, SPA特征提取的模型预测能力略低于CARS特征提取的模型。 可能的原因有①特征波长数量不同, SPA方法提取的波长少于CARS, SPA可能遗失了一些有用的信息。 ②算法机制不同, SPA通过逐步投影减少多重共线性, 但可能无法捕捉所有相关信息。 而CARS通过竞争性加权采样保留更多与目标变量相关的重要波长, 提高了模型预测精度。 ③信息冗余度, CARS方法通过竞争性加权采样, 有效地减少了冗余信息, 保留了更多与目标变量相关的重要波段。
综上所述, 虽然SPA和CARS都是有效的特征提取方法, 但CARS在处理光谱数据时表现出更优的预测能力。 主要是由于CARS能够提取更多与目标变量相关的重要波长, 并且有效减少了信息冗余, 从而在特征提取和模型预测方面优于SPA方法。
由于特征波段相比全波段具有更高的有效性和更低的复杂度, 我们首先用特征波段建立PLSR模型。 为了探索捕捉光谱数据中的复杂非线性关系是否可以进一步提升预测精度, 我们还建立了DL-BPNN模型。 具体来说, 利用SPA和CARS两种特征波长提取方法, 分别建立特征波段的DL-BPNN预测模型, 预测结果如表5和表6所示。
| 表5 基于SPA特征波长筛选方法建立的DL-BPNN结果 Table 5 DL-BPNN modeling results based on SPA-selected feature wavelengths |
| 表6 基于CARS特征波长筛选方法建立的DL-BPNN结果 Table 6 DL-BPNN modeling results based on CARS-selected feature wavelengths |
从表5和表6来看, CARS提取的特征波长建立的模型预测能力略优于SPA提取的特征波长建立的模型预测能力。 对比表3和表4中的PLSR预测模型, SPA-DL-BPNN模型相比于SPA-PLSR模型并没有显著的变化, 而CARS-DL-BPNN模型结果却略低于CARS-PLSR模型。 表5和表6中最佳预测模型是未预处理-SPA-DL-BPNN和WT+Norm-CARS-DL-BPNN, 其训练集和验证集的实际值和预测值的对比图如图11(a)和图11(b)所示。
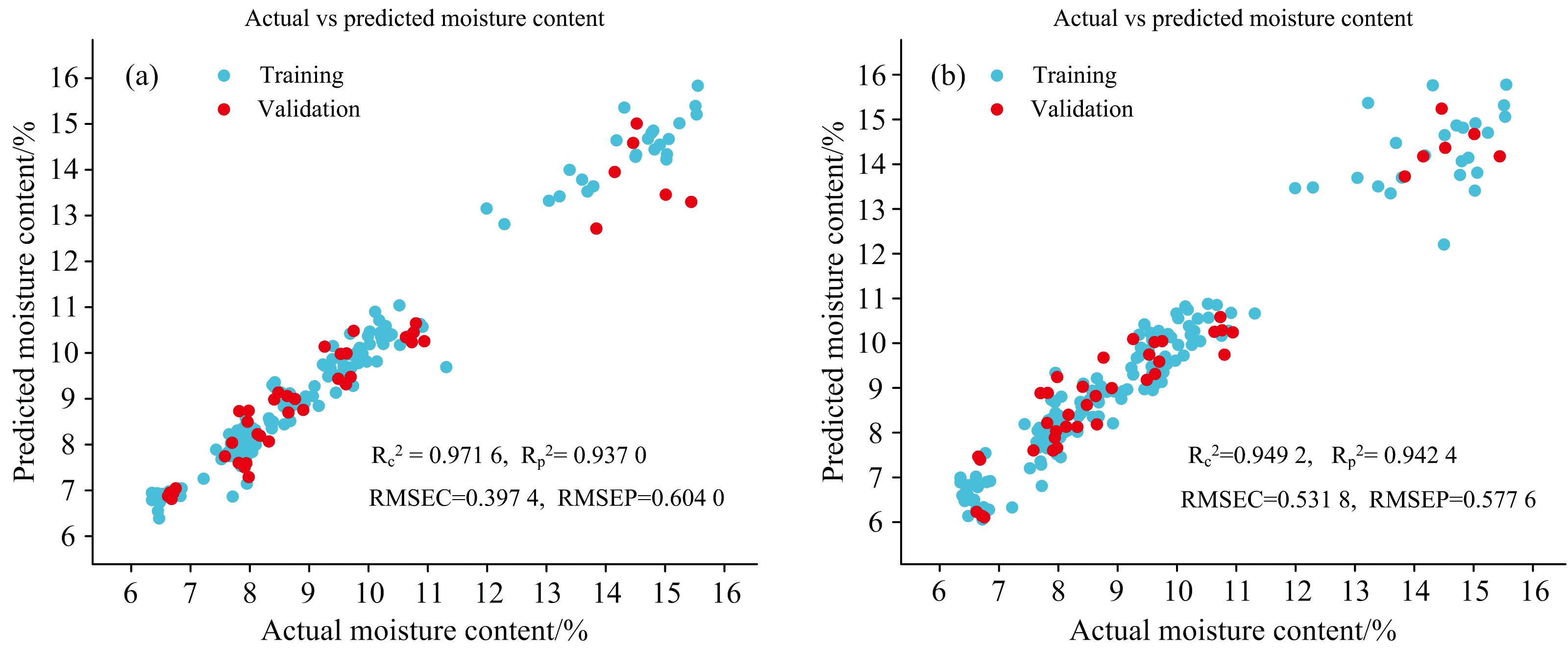 | 图11 SPA和CARS选取的特征波长建立的DL-BPNN最佳预测模型的实际值和预测值对比 (a): 未预处理-SPA-DL-BPNN; (b): WT+Norm-CARS-DL-BPNNFig.11 Comparison of actual and predicted values obtained from the best DL-BPNN predictive models based on the feature wavelengths selected by SPA and CARS (a): Unprocessed-SPA-DL-BPNN; (b): WT+Norm-CARS-DL-BPNN |
这些结果表明, 尽管DL-BPNN模型在理论上能够捕捉更复杂的非线性关系, 但其预测精度并未显著高于PLSR模型。 这可能是由于以下原因①模型复杂度, PLSR作为线性模型, 具有较低的复杂度, 更易于在小样本情况下训练并获得稳定的结果。 相对而言, DL-BPNN是非线性模型, 尽管拟合能力强, 但在样本量较小时, 容易过拟合。 ②参数调优, PLSR模型参数较少, 调优相对简单, 容易获得较好的预测性能。 而DL-BPNN模型的参数较多, 调优过程复杂, 如果调优不当, 可能会导致模型性能下降。 ③数据特征, 对于光谱数据, 当线性关系占主导地位时, PLSR模型能够更好地捕捉这些关系, 从而提供更高的预测精度。 虽然DL-BPNN模型在捕捉非线性关系方面具有优势, 但如果数据中的非线性特征不显著, 模型的优势难以体现。
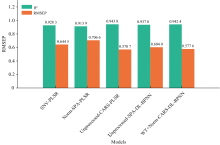
综上所述, 在全波段和特征波段分别建立的模型中, 最佳的预测组合分别为SNV-PLSR、 Norm-SPA-PLSR、 未预处理-CARS-PLSR、 未预处理-SPA-DL-BPNN和WT+Norm-CARS-DL-BPNN。 图12显示了这5种组合的验证集预测精度, 使用RMSE和R2进行对比。
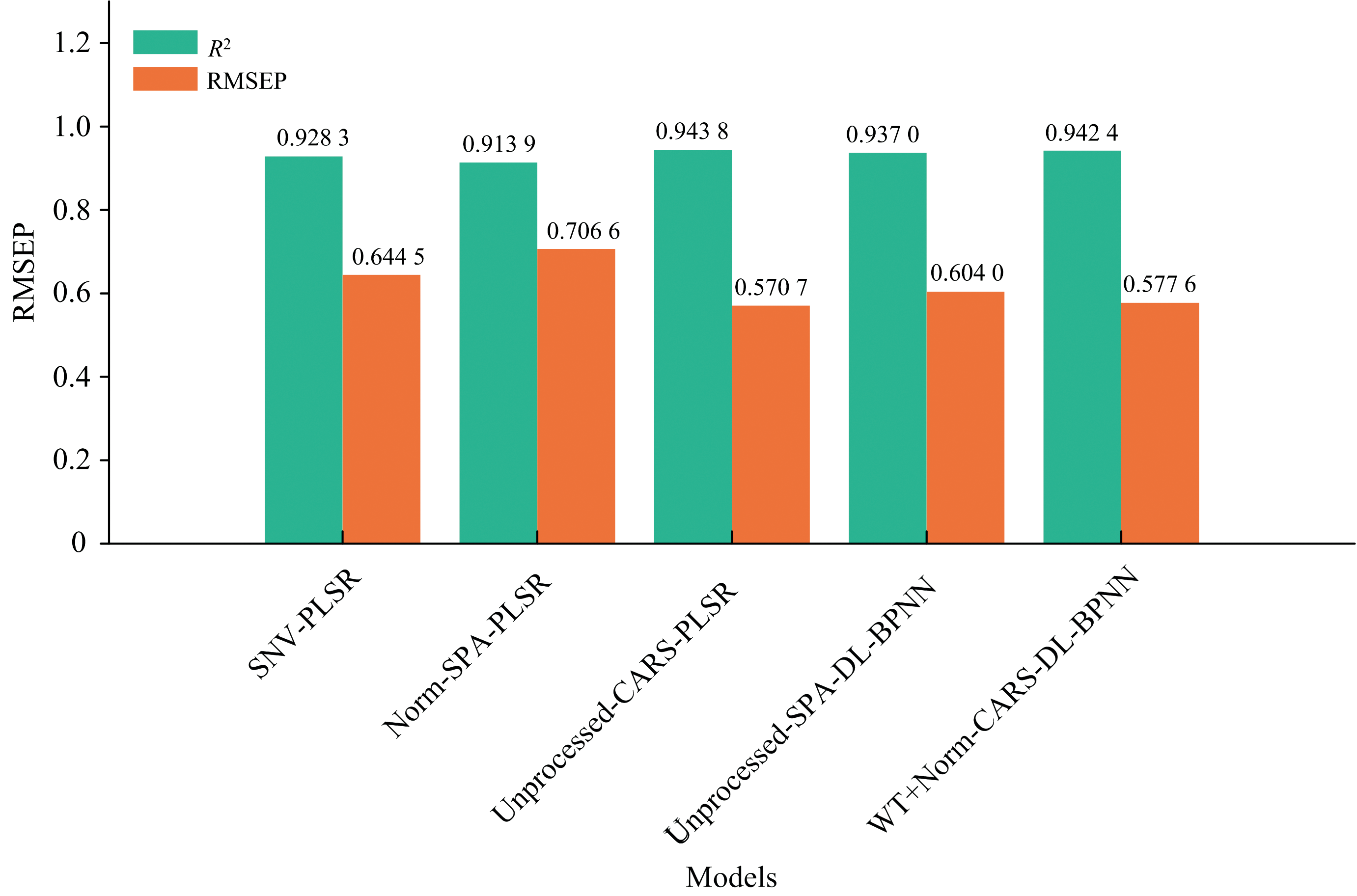 | 图12 五组最佳组合验证集对比图Fig.12 Comparison of R2 and RMSEP for the five best combinations |
通过对不同湿度环境下的棉料四尺单宣进行了近红外光谱分析, 建立了多种含水率预测模型, 并对其预测能力进行了评估。 通过采用SPXY划分法, 将样品按照4∶ 1的比例划分为168条训练集和42条验证集。 随后, 对近红外光谱数据进行预处理, 并通过SPA和CARS方法从原始波长中提取特征波长。 最终, 建立了全波段的PLSR预测模型, 以及基于特征波段的PLSR和DL-BPNN预测模型。
通过对比不同预处理方法和特征提取方法进行评估, 结果显示, 通过CARS特征提取后建立的未预处理-CARS-PLSR模型表现最佳, 其验证集的决定系数为0.943 8, 均方根误差RMSEP为0.570 7, 这表明CARS特征提取方法在保留重要特征和去除冗余信息方面具有显著优势。 相比之下, DL-BPNN模型尽管在理论上能够捕捉更复杂的非线性关系, 但在本研究中, 其预测精度并未显著高于PLSR模型。
总体而言, 成功建立了棉料四尺单宣含水率与近红外光谱之间的关系, 为纸质文物含水率的快速无损检测提供了一种有效的方法, 但是利用近红外光谱建立的宣纸不同含水率的模型预测准确率仍有待提高。 这可能是由于在采集不同湿度样品时受到了外界环境湿度、 光源和探头与样本距离等因素的影响。 此外, 可以考虑增加不同的定量检测模型以及针对不同纸样的定量模型检测, 以进一步提高模型的预测准确率。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|