


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱与宽度学习检测草莓叶片含水率
[李泽祺1  , 杨铮
, 杨铮1 , 周壮飞1 , 彭继宇1 , 朱逢乐1, * , 何青海2 ]
, 杨铮, 何青海|
|


作者简介: 李泽祺, 2004年生,浙江工业大学机械工程学院本科生 e-mail: 478402481@qq.com
水分是影响草莓生长发育的关键因素, 对其栽培具有重要意义。 传统的水分测量方法虽精确但繁琐且具有破坏性; 高光谱成像技术(HSI)因其高效、 非破坏性和多属性检测优势, 成为植物水分检测的理想选择。 HSI数据量大且信息冗余, 深度学习方法虽然能提取数据深层特征, 但对大规模标注数据的依赖性限制了其应用。 为此, 引入了宽度学习系统(BLS)以解决在小样本上的训练问题, 提出了一种基于BLS的草莓叶片含水率检测方法。 首先制备了健康及干旱胁迫的草莓叶片样本, 获取其高光谱图像及水分含量数据。 通过分析3种超参数调优方法和4种预处理算法, 构建了BLS含水率测定模型, 并与偏最小二乘回归(PLSR)、 支持向量机回归(SVR)、 梯度增强决策树回归(GBDTR)和残差神经网络(ResNet)等对比模型进行了性能评估。 结果显示, BLS模型在测试集上的决定系数( R2)达到0.797 4, 均方根误差(RMSE)为0.004 5, 优于其他模型, 比ResNet模型高0.039 4, 证明其具有良好的泛化能力和预测准确性。 此外, 基于最优模型实现了草莓叶片含水率的可视化, 通过生成含水率伪彩图直观展示草莓叶片的水分状态。 研究结果表明, BLS模型在小样本的高光谱数据分析和草莓叶片含水率检测中具有可行性, 为草莓叶片含水率的在线检测提供了科学依据。
Moisture content is a critical factor influencing the growth and development of strawberries, and it holds significant importance for their cultivation. Traditional methods of moisture measurement, although precise, are cumbersome and destructive. Hyperspectral Imaging (HSI) has emerged as an ideal technique for plant moisture detection due to its efficiency, non-destructive nature, and multi-attribute detection capabilities. However, the large volume and redundancy of HSI data present challenges. While deep learning methods can extract deep features from the data, their reliance on large-scale annotated datasets limits their application. To address this issue, our study introduces a Broad Learning System (BLS) to solve the training problem with small sample sizes. It proposes a BLS-based method for detecting moisture content in strawberry leaves. The study first prepared samples of healthy and drought-stressed strawberry leaves, obtaining their hyperspectral images and moisture content data. By analyzing three hyperparameter tuning methods and four preprocessing algorithms, a BLS moisture determination model was constructed and its performance was evaluated against comparative models, including Partial Least Squares Regression (PLSR), Support Vector Machine Regression (SVR), Gradient Boosting Decision Tree Regression (GBDTR), and Residual Network (ResNet). The results showed that the BLS model achieved a coefficient of determination (
水分是影响草莓生长发育的关键元素, 对其栽培具有至关重要的功能。 水分不足会破坏草莓植株的生理和形态完整性, 进而影响其生长、 果实产量和整体质量。 一些传统的植物水分测量方法如干燥法、 蒸馏法等虽然精确度高, 但过程繁琐且具有破坏性[1]。 而高光谱成像(hyperspectral image, HSI)技术则能解决这些问题。 高光谱成像技术与传统的化学及物理分析方法相比拥有显著的优势: 其测量时间短, 样品准备简便, 无需化学试剂干预, 能够同时对多个属性进行精确估计[2]。
HSI技术可以同时获取光谱和图像, 不同于传统光谱仪仅能测量平均光谱数据, HSI能够实时捕捉图像中每个像素的光谱信息。 得益于其在生理研究中的高效率和非侵入性特点, HSI技术已被广泛应用于监测植物叶片的水分含量。 例如, Li等[3]利用HSI估测冬小麦叶片水分含量, 通过分析350~1 350 nm的高光谱数据及小麦各生长阶段的水分数据, 验证了HSI在实时监控和评估作物生理状态的有效性。 Asaari等[4]运用HSI提出了一种基于k均值聚类联合标准正态变换(standard normal variable, SNV)的玉米早期干旱胁迫检测方法, 凸显了HSI数据对水分变化的高度敏感性。 Li等[5]应用近红外高光谱技术和偏最小二乘法结合逐步多元线性回归, 对活体玉米叶片水分进行无损检测和建模。 由于高光谱数据的庞大和信息冗余, 近期深度学习模型越来越多地应用于HSI数据分析; 深度学习具有强大的非线性表示能力, 能够提取数据的深层特征[6]。 例如, Hao等[7]采用基于数字图像的卷积神经网络方法监测雪茄叶在干燥过程中的水分含量, 该方法通过分析提取的颜色、 形状和纹理特征, 学习图像与相应水分含量之间的关系。 An等[8]则提出了一种基于卷积神经网络(convolutional neural networks, CNN)置信度的红茶萎凋水分检测方法。 通常, 深度学习依赖于大量样本以提高模型精度, 然而在植物科学领域, 收集大规模标注的光谱数据集既费时又昂贵[9]。 此外, 深度学习易出现过拟合问题, 并可能陷入局部最小值[10]。 面对这些挑战, 宽度学习系统(broad learning system, BLS)提供了一个前景广阔的解决方案。
BLS是近年来Chen与Liu[11]提出的一种新算法, 有效地解决了小样本训练的问题。 BLS算法呈扁平结构, 通过扩展神经网络的宽度而非深度, 来处理高维数据问题, 能够快速且以增量方式构建网络模型。 在像素级HSI分析方面, Zhao等[12]基于BLS提出了一种针对高光谱图像的光谱-空间联合分类方法, Ma等[13]提出了一种基于BLS的混合空间-光谱特征分类方法。 在对象级HSI分析方面, 叶荣珂等[14]融合随机森林与BLS对虾的新鲜度进行分类检测。 然而, 在植物叶片含水率检测问题中, 目前尚未见研究使用BLS构建模型的报道。 经过大量调研与理论研究后, 尝试在可见-近红外HSI技术检测植物含水率的定量研究中, 引入BLS算法。
综上所述, 本研究以草莓叶片含水率为研究对象, 采用BLS方法应对小样本数据的模型训练问题, 为草莓叶片含水率的在线检测提供科学依据。 本研究的内容如下: (1)基于BLS模型探索最佳超参数搜索及预处理方式; (2)构建草莓叶片含水率检测的BLS模型; (3)构建对比模型包括线性偏最小二乘回归(partial least squares regression, PLSR)模型、 非线性支持向量机回归(support vector machine regression, SVR)、 梯度增强决策树回归(gradient boosting decision tree regression, GBDTR)以及残差神经网络(residual network, ResNet)深度学习模型; (4)基于最佳模型实现草莓叶片含水率的分布可视化。
首先, 制备健康及干旱胁迫的草莓叶片样本, 并采集它们的高光谱图像及水分含量。 随后, 对高光谱数据集进行测试集、 预测集的划分和平均光谱提取。 接着, 基于BLS模型, 比较了3种超参数优化策略和4种不同预处理方法的结果, 以构建最优BLS模型。 随后, 所得的最优BLS模型与PLSR、 SVR、 GBDTR和ResNet的最优模型进行了性能对比。 最终, 将经过预处理的草莓叶片高光谱数据输入到最优模型中, 以预测每个像素点的水分含量, 并通过生成水分含量的伪彩图来直观展示草莓叶片的水分状态。
实验数据样本来自于2022年10月在杭州温室中培育的“ 红颜” 草莓幼苗(Fragaria x ananassa Red Face)。 经过28 d的培养期后, 精心挑选出生长均匀且健康的幼苗, 并将它们移植到50个花盆中, 每个花盆种植三株。 随后一半的草莓幼苗接受了一周的连续干旱胁迫处理, 未进行浇水; 而另一半幼苗则每天进行约200 mL的定期灌溉。 分别命名为干旱和健康类别。 对两个类别分别采集543个叶片样本的HSI。 之后, 根据Sinija和Mishra[15]的方法进行了含水率测定。 采用微量天平(Sartorius Ltd., Germany)测定样本的初始鲜重(G1), 并在电加热风机恒温烘箱(Guangzhou Hongjing Energy-saving Technology Co. Ltd, China)中以105 ℃烘干至恒重。 烘干后的叶片在20 ℃的干燥器中冷却30 min, 随后测定其干重(G2)。 每片叶子的含水率(moisture content of leaves MCL)按照如式(1)计算
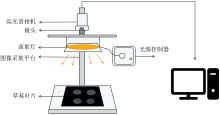
HSI系统如图1所示, 包括一个SNAPSCAN VNIR可见近红外高光谱相机(IMEC, Leuven, Belgium)、 一个焦距为17 mm的相机镜头、 一个150 W的环形钨卤灯用于照明、 一个图像采集平台以及一台装有HSImager图像采集软件的计算机。 得益于SNAPSCAN传感器在相机内部的移动, 避免了在图像采集过程中相机与样本产生相对运动而导致的图像变形问题。 根据白色参考板的反射率, 调节曝光时间至30 ms, 以防止传感器过饱和。 每次可同时对四4个叶片样本进行成像, 样本放置于距离相机镜头32 cm的位置。 空间分辨率设为1 088× 1 800, 生成的三维数据立方体涵盖了470~900 nm的140个波长。 为减少照明强度和暗电流对采集图像的影响, 所有原始图像均经过黑白校准以获得反射率值
式(2)中, Ic与I0分别代表校准后和原始的高光谱图像; ID与Iw分别是暗参考图像和白参考图像。
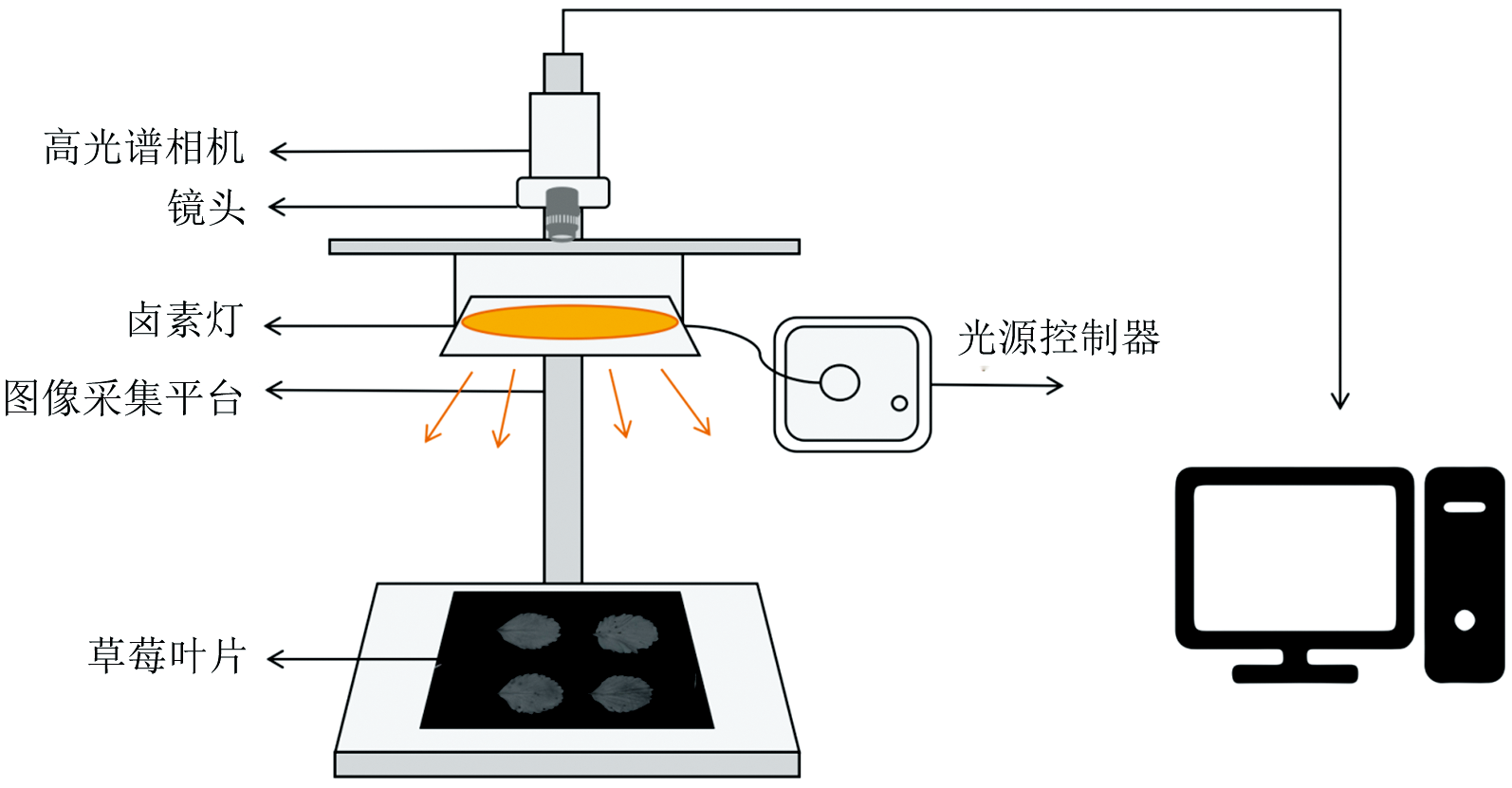 | 图1 HSI系统原理图Fig.1 The schematic diagram of hyperspectral imaging system |
1.3.1 数据集划分
为了构建叶片含水率检测模型, 根据Li等[16]提出的方法将全部样本划分为训练集和测试集, 得到了724个样本的训练集和362个样本的测试集, 两个数据集含水率的最大值、 最小值、 平均值与标准差统计数据见表1。
| 表1 样本数据集划分 Table 1 Division of the sample dataset |
1.3.2 光谱数据提取与预处理
草莓叶片的光谱数据提取包括一系列如下预处理步骤, 如图2所示。 首先, 利用连通域方法分割每个草莓叶片样本。 随后, 应用阈值0.18(800 nm)进行背景分割。 每片草莓叶的整个区域均被划为其感兴趣区域(ROI)。 提取ROI内所有像素点的反射率值并求均, 以形成每个样本的原始代表性光谱数据。
 | 图2 光谱数据提取流程Fig.2 Spectral data extraction process |
鉴于高光谱数据的高维度和复杂性, 使用高光谱仪获取的信息易受到多种噪声的影响, 如杂散光、 高频随机噪声及基线漂移等[17]。 因此, 在模型建立之前, 需要进行适当的高光谱数据预处理, 以提取有效的光谱信息并提高光谱质量。 在470~900 nm的光谱范围内, 采用了5种典型的原始光谱数据预处理方法: 一阶导数(first-order derivative, D1)、 二阶导数(second-order derivatives, D2)、 SNV、 多元散射校正(multiple scattering calibration, MSC)以及SG卷积平滑(Savitzky-Golay, SG)。 其中, D1和D2是常用的预处理方法, 用于探测光谱变化速率及增强光谱特征和边缘信息, 能有效减少噪声和背景干扰[18]。 SNV通过使每个光谱曲线的分布与正态分布对齐来标准化每个样本的光谱[19]。 MSC则通过减少样本间的基线偏移来凸显与草莓叶片含水率相关的光谱吸收信息[20]。 SG卷积平滑通过在数据的滑动窗口中应用多项式最小二乘拟合, 本质上是进行加权平均处理[21]。 其作为一种常用且有效的平滑与特征增强技术, 被广泛应用于光谱数据处理中。 为进一步提升预处理效果, 在SG平滑滤波的基础上, 结合了SG-D1、 SG-D2、 SG-SNV、 SG-MSC, 以探究不同预处理方法对所构建模型性能的影响, 所采用SG平滑的窗口大小为7。
1.3.3 BLS模型
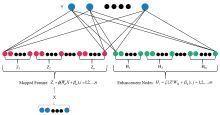
BLS是一种新型的建模方法, 它避开了由于过滤器和层之间众多连接参数导致训练耗时的深层多级网络。 BLS采用扁平网络结构, 将初始输入在特征节点中转化为“ 映射特征” , 并通过“ 增强节点” 扩展系统的宽度。
BLS的核心是随机向量函数链接神经网络(RVFLNN), 该网络为模型提供了高效的增量更新能力, 避免了扩展时重新训练的繁琐。 BLS模型结构展示在图3中。
 | 图3 BLS模型结构Fig.3 Framework of the broad learning system |
输入数据X包含N个样本, 每个样本有M个维度, 首先通过n个特征映射, 每个映射生成k个节点, 形成特征节点矩阵Zi
转换过程涉及随机权重Wei和偏置β ei, 以及激活函数Φ i, 最终得到连接的特征节点矩阵Zn。 在特征节点生成后, BLS引入了从特征节点通过增强映射得到的增强节点Hd, 以此增强系统的表征能力
其中ξ j为激活函数, r表示每组增强变换对应的增强节点数, 这确保了系统宽度的扩展以增强其学习和泛化能力。 Whj是第j组增强映射的权重矩阵, 帮助将第i组特征节点Zi转换为第j组增强节点Hj。 矩阵β hj是第j组增强映射的偏置矩阵, 为增强映射提供必要的偏置项。 计算过程表示为
式(7)中, Y为预测的水分含量, W为优化后的权重矩阵, 构建了从特征和增强节点集合到预测输出的连接。
总的来说, BLS的简洁强大架构易于快速训练和适应。 它通过简化结构, 支持动态环境中的快速增量学习和即时模型更新。
1.3.4 对比模型
PLSR是一种融合了主成分分析、 典型相关分析及多元线性回归原理的经典机器学习模型。 该方法通过提取关键的潜在变量来有效降低高维数据集的复杂度, 进而揭示预测变量与响应变量之间的关系。
SVR的基本思想是在高维空间中构建一个能够明确将数据点分为不同类别的超平面[22]。 其核函数包括线性核、 多项式核、 径向基函数核等, 不同的核函数使得SVR能够有效地处理线性及非线性回归问题。 本研究在训练SVR时所利用的核函数为径向基函数。
GBDTR是一种基于增强算法的集成学习模型, 采用CATR回归树作为弱学习器[23]。 GBDTR的核心思想是构建一系列学习器(树), 并通过综合多个决策树的结果来连续拟合损失函数, 以此形成最优模型。
ResNet在传统CNN的基础上进一步发展, 构建更深的模型, 从而更好地学习数据集中的复杂和抽象特征。 其设计核心是采用残差块, 每个块由一系列卷积层组成, 这些层已证明便于模型的优化[24]。 在后续实验中, 考虑到计算效率与性能的平衡, 选用了ResNet18作为对比模型。
1.3.5 模型训练与评价
模型训练过程中对超参数进行了寻优, 搜索范围如表2所示。 在评估草莓叶片含水率检测的模型性能时, 选用决定系数(correlation coefficient of cross-validation, R2)和均方根误差(root mean square error, RMSE)作为评价指标。 R2值越接近1, 说明光谱信息与叶片含水率的相关性越高。 RMSE值越小, 预测的误差越低, 模型的效果越佳。
| 表2 相关模型超参数调优范围 Table 2 Range of hyperparameters for tuning relevant models |
1.3.6 含水率预测成图可视化
提取草莓叶片各像素点在470~900 nm波长区的光谱反射率, 采用上述所确定的最佳预处理方法进行光谱数据预处理, 随后将其输入到最佳性能的模型中, 得到每个像素点含水率的预测值。 通过伪色处理技术生成含水率分布伪彩可视化图。 每个像素点的颜色代表了对应位置叶片的含水率, 使用从蓝色(低含水率)到红色(高含水率)的渐变色来表示含水率的差异。
表3展示了所有草莓叶片样本的含水率统计值。 将草莓叶片分为健康组和干旱胁迫组, 其具体的实物图片如图4所示。 Mann-Whitney U检验的统计分析结果表明, 健康组与干旱胁迫组之间的平均水分含量存在显著差异, U值为278 903, P值远小于常见的显著性水平(P=0.05)。 这些显著性差异验证了本研究中干旱胁迫处理的有效性。 此外, 干旱胁迫组的标准差(0.130 1)较健康组(0.018 0)要大, 表明其样本中的水分含量分布变异更大。 在干旱胁迫下, 草莓幼苗表现出多种形态和生理生化的变化, 如气孔关闭、 根部和茎部的鲜重和干重减少、 光合色素浓度降低以及叶绿素荧光的减弱, 这些变化严重制约了它们的生长[28]。 轻度和重度干旱样本的标准差分别为0.078 1和0.074 1, 显著高于健康样本的标准差(0.018 0), 说明健康样本中水分含量的分布更集中, 而干旱胁迫样本的分布则更广。
| 表3 草莓叶片样本的含水率数据统计 Table 3 Statistical analysis of moisture content in strawberry leaf samples |
 | 图4 健康(a)和干旱(b)胁迫草莓叶片样本的代表性实物图片Fig.4 Representative images of healthy (a) and drought-stressed (b) strawberry leaf samples |
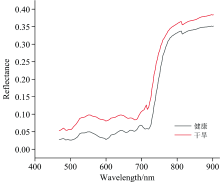
如图5所示, 健康和干旱胁迫草莓叶样本的原始平均光谱曲线在两个组别中表现出相似的趋势。 在470~680 nm的可见光区域内, 反射率因叶绿素和类胡萝卜素等植物色素对光谱能量的强烈吸收而显著降低[29]。 在680~780 nm的红边区域, 叶绿素对红光的强烈吸收以及叶片在近红外谱区的强反射效应, 导致反射率急剧上升[30]。 而在780~900 nm的近红外区域, 反射率保持在较高水平, 这主要与叶片样品的内部结构相关[31]。 干旱胁迫导致植物色素及其他成分含量减少, 导致光谱吸收下降, 反射率增高。
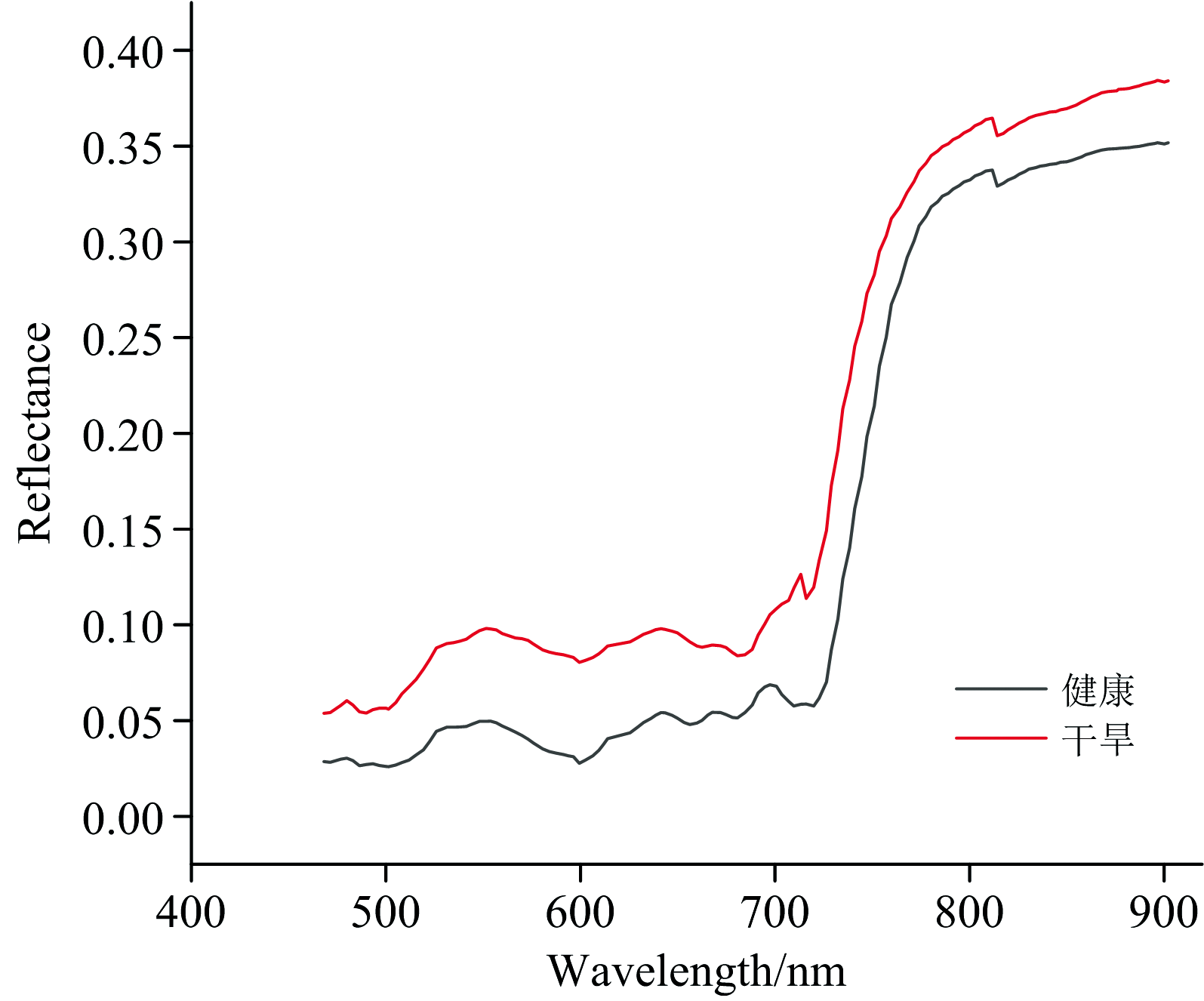 | 图5 健康和干旱胁迫草莓叶片样本的平均光谱曲线Fig.5 The averaged spectral curves of healthy and drought-stressed strawberry leaf samples |
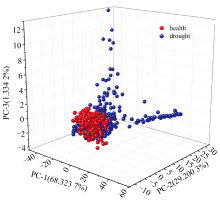
对草莓叶片样本的原始光谱进行了主成分分析(principal components analysis, PCA)。 此方法通过计算主成分(PCs)实现数据维度的压缩。 前三个主成分(PC1、 PC2、 PC3)的分布图如图6所示, 其累计贡献率达到98.858 2%, 这三个主成分捕获了数据中的大部分方差, 提供了一个直观且丰富的数据呈现。 在三维PCA空间中, 健康样本(红色点)与干旱胁迫样本(蓝色点)展现出一定的聚类趋势, 这表明干旱胁迫对草莓叶片样本有明显影响。 第一主成分(PC-1)和第二主成分(PC-2)在空间上展示了两组样本之间的主要差异, 而第三主成分(PC-3)提供了更多的分离信息。 这些结果显示, 在草莓叶片样本响应干旱胁迫的过程中, 发生了一系列复杂的生理和生化变化。 通过对光谱数据进行PCA, 揭示了这些变化在数据中的主要趋势。 但PCA无法对叶片的含水率进行定量分析, 因此采用构建机器学习模型的方法进行回归建模。
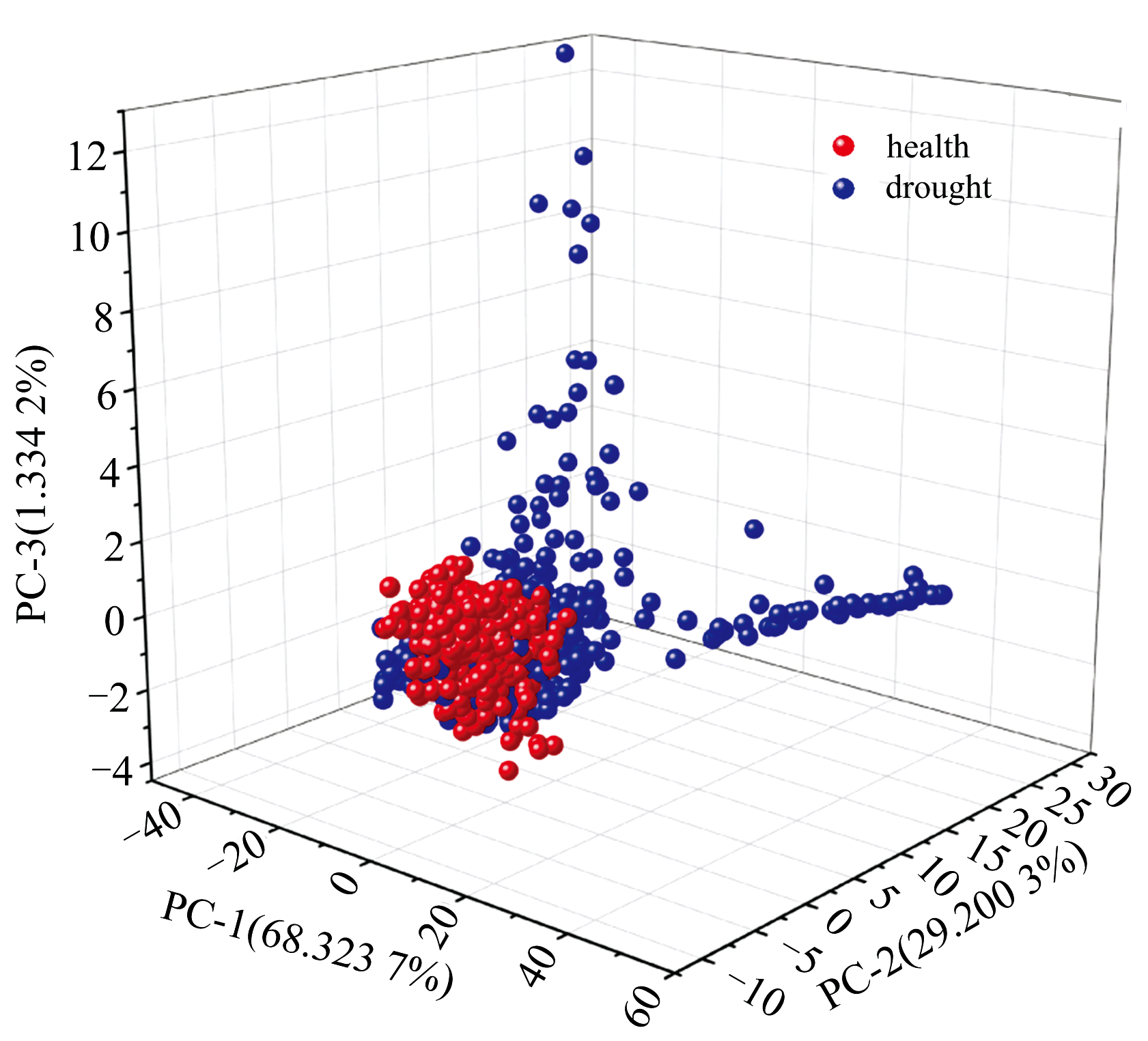 | 图6 草莓叶片高光谱的前三个PC变量分布图Fig.6 Distribution of the first three PCs of hyperspectral data for strawberry leaves |
分别利用原始光谱数据与经四种预处理方法(SG-D1、 SG-D2、 SG-SNV、 SG-MSC)后的光谱数据建立BLS模型。 为了优化建模算法的性能, 分别采用随机搜索(random search, RS)、 网格搜索(grid search, GS)和贝叶斯优化(Bayesian optimization, BO)[32]对BLS模型进行超参数调优, 得到在不同光谱预处理下的最优模型, 如表4所示。 在不同的超参数优化策略中, GS在大多数预处理方法下取得了稳定且优异的泛化能力。 BO的SG-D1取得了最高的训练集
| 表4 不同预处理方法和超参数优化方式下构建的BLS模型结果 Table 4 Modeling results of BLS models constructed using various preprocessing methods and hyperparameter optimization techniques |
为了评估BLS模型预测草莓叶片含水率的性能, 将BLS模型与经典机器学习模型PLSR、 SVR、 GBDTR以及深度学习卷积神经网络模型ResNet 18进行了对比分析。 上述模型构建都分别采用三种不同超参数优化策略及不同光谱预处理方式以获得最佳结果, 各模型的最优结果如表5和图7所示。 在各个模型的超参数优化过程中, GS表现出最佳的优化效果。 此外, SG-D1预处理在大部分模型中均取得了最佳结果, 表明SG-D1有效增强了关键光谱特征并减少了噪声干扰, 从而提升了模型预测草莓叶片含水率的准确性。 在测试集上, BLS模型展示了更高的
| 表5 不同建模算法的结果 Table 5 Modeling results of different algorithms |
 | 图7 不同模型的草莓叶片含水率实测值与预测值散点图Fig.7 Scatter plots of actual and predicted moisture contents in strawberry leaves for different models |
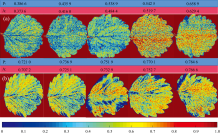
在干旱和健康样本中, 分别随机选择了5片草莓叶片作为可视化样本。 提取每个像素的光谱反射率, 将经SG-D1平滑处理后的光谱数据输入已建立的BLS模型中, 以预测每个像素的含水率, 并绘制了不同草莓叶片的含水率分布图, 如图8所示。 图中使用了从蓝色(低含水率)到红色(高含水率)的渐变色来表示含水率。 可以看出, 健康样本的含水率显著高于干旱胁迫样本, 同时叶脉和叶茎部分的水分含量整体高于于叶肉部分, 进一步表征水分通过叶茎在叶脉间传输至整个叶片, 这与Song等[38]的实验观察结果一致。 图中的含水率预测值与真实值较为接近, 偏差范围为0.011 8~0.054 5, 证明了BLS模型具有良好的泛化能力。
 | 图8 不同类型草莓叶片含水率预测可视化 P: 预测值; A: 实际值; (a): 干旱组; (b): 健康组Fig.8 Visualization of predicted water content distribution in different types of strawberry leaves P: Predicted values; A: Acutal values; (a): Drought; (b): Healthy |
(1)结合3种超参数调优策略(随机搜索, 网格搜索、 贝叶斯优化)和4种预处理方法(SG-D1、 SG-D2、 SG-SNV、 SG-MSC)分别对原始光谱数据构建BLS模型。 相比之下, 基于网格搜索优化的SG-D1预处理方法所构建的BLS模型效果最佳。
(2)为了评估BLS模型的性能, 对比了传统机器学习模型(PLSR、 SVR、 GBDTR)和深度学习模型(ResNet 18)的建模结果。 结果表明BLS模型具有最佳的拟合和泛化能力, 测试集
(3)研究结果表明BLS模型用于光谱检测领域的可行性。 该方法可以为草莓叶片健康状况在线检测提供科学依据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|