



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
联合混合卷积与级联群注意力机制的高光谱遥感影像分类
[王晓燕1  , 梁文辉
, 梁文辉2 , 毕楚然1 , 李杰3, * , 王禧钰2 ]
, 梁文辉, 王禧钰|
|


作者简介: 王晓燕,女, 1980年生,北京物资学院系统科学与统计学院副教授 e-mail: wangxy252@163.com
高光谱遥感影像丰富的光谱信息, 能够为地物分类提供可靠的数据支持。 但是, 光谱数据高维、 冗余, 空谱特征联合困难、 光谱特征提取不充分等问题对基于深度学习的高光谱遥感影像分类提出了挑战。 卷积神经网络(CNN)和Vision Transformer(ViT)是两种在计算机视觉领域中广泛使用的深度学习架构, 各自有独特的优势和局限性。 CNN擅长捕捉局部特征和空间层次结构, 对图像的平移不变性有很好的处理能力。 ViT通过自注意力机制能够捕捉图像中的全局依赖关系, 对图像的复杂模式有较好的理解能力。 为了提升高光谱遥感影像的分类精度, 充分发挥CNN和ViT两种模型的优势, 结合CNN的局部特征提取能力和ViT的全局上下文理解能力, 创新性地将3D EfficientViT模块引入混合卷积, 提出了一种联合混合卷积与级联群注意力机制的高光谱遥感影像分类算法EVIT3D_HSN。 本算法在三维卷积提取高光谱遥感影像空谱联合特征及二维卷积提取空间特征的基础上引入3D Efficient ViT模块, 提高了对不同数据集的泛化能力、 更全面地捕捉了高光谱数据的图像特征, 从而增强了分类算法的性能, 同时并未增加模型复杂度。 为了验证本算法的先进性, 将本算法EVIT3D_HSN在高光谱遥感影像分类数据集India Pines、 Pavia University和Salinas, 与算法1DCNN、 2DCNN、 3DFCN和3DCNN进行对比实验, 并于原算法HybridSN进行消融实验。 EVIT3D_HSN在以上三种数据集的分类结果为: OA分别为97.66%、 99.00%和99.65%, Kappa系数分别为97.3%、 98.6%和99.6%。 相比于1DCNN, 模型分类精度分别提升了37.12%、 25.09%和33.67%; 相比于2DCNN, 精度分别提升了59%、 57.43%和46.92%; 相比于3DFCN, 精度分别提升了45.36%、 24.5%和29.72%; 相比于3DCNN, 精度分别提升了28.05%、 14.26%和34.29%; 相比于HybridSN, 分别提升了3.76%、 1.85%和2.57%。 此外, 除IP数据集的Stone-Steel-Towers, PU数据集的Painted metal sheets和Shadows, 以及SA数据集的Stubble地物之外, EVIT3D_HSN对其他共37种地物的F1值均最高。 实验结果表明, EVIT3D_HSN在模型精度和泛化能力上的表现优于上述五种高光谱遥感影像分类算法, 本模型具有良好的实用价值。
The rich spectral information of hyperspectral remote sensing images can provide reliable data support for their feature classification. However, the problems of high dimensionality and redundancy of spectral data, difficulty associating spatial and spectral features, and insufficient spectral feature extraction have challenged the classification of hyperspectral remote sensing images based on deep learning. Convolutional neural network (CNN) and Vision Transformer (ViT) are two deep learning architectures widely used in computer vision, and each has unique advantages and limitations.CNN is good at capturing local features and spatial hierarchies and can deal with the invariance of the image's translation. ViT can capture global dependencies and has a better understanding of complex patterns in images. To improve the classification accuracy of hyperspectral remote sensing images and give full play to the advantages of both CNN and ViT models, this paper combines the local feature extraction capability of CNN and the global context understanding capability of ViT, and innovatively introduces the 3D Efficient ViT module into the hybrid convolution, and proposes a hyperspectral remote sensing image classification algorithm combining the hybrid convolution and cascading group attention mechanism EVIT3D_HSN: This algorithm introduces 3D Efficient ViT module based on 3D convolution to extract the joint features of hyperspectral remote sensing images and 2D convolution to extract the spatial features, which improves the generalization ability to different datasets and captures the image features of hyperspectral data in a more comprehensive way, thus enhances the performance of the classification algorithm without increasing the complexity of the model. To validate the advancement of this algorithm, this paper's algorithm EVIT3D_HSN is compared with algorithms 1DCNN, 2DCNN, 3DFCN, and 3DCNN and the original algorithm HybridSN for ablation experiments on hyperspectral remote sensing imagery classification datasets India Pines, Pavia University, and Salinas. The classification results of EVIT3D_HSN on the above three datasets are 97.66%, 99.00%, and 99.65% for OA and 97.3%, 98.6%, and 99.6% for the Kappa coefficient, respectively. Compared with 1DCNN, the model classification accuracies are improved by 37.12%, 25.09%, and 33.67%, respectively; compared with 2DCNN, the accuracies are improved by 59%, 57.43%, and 46.92%, respectively; compared with 3DFCN, the accuracies are improved by 45.36%, 24.5% and 29.72%, respectively; and compared with 3DCNN, the accuracies are improved by 28.05%, 14.26% and 34.29%; and compared to HybridSN, the accuracy is improved by 3.76%, 1.85% and 2.57%, respectively. In addition, EVIT3D_HSN has the highest F1 values for a total of 37 features, except stone steel towers for the IP dataset, Painted metal sheets and Shadows for the PU dataset, and Stubble features for the SA dataset. CONCLUSION The experimental results show that EVIT3D_HSN outperforms the above five hyperspectral remote sensing image classification algorithms regarding model accuracy and generalization ability, and the model has good practical value.
高光谱影像是一种集成了光谱学与成像技术的高级数据形式, 它通过提供连续且狭窄的光谱范围内的反射、 透射或发射特性[1], 为各种地物提供丰富的空间信息和光谱信息。 高光谱影像的分类作为高光谱图像处理的基础任务, 在多个应用领域发挥主要作用。 然而, 它的光谱分辨率高但空间分辨率有限、 数据集和训练数据的缺乏、 维数灾难等特性[2]对其分类精度有不利影响。 同时, 现阶段基于神经网络的高光谱遥感影像分类算法并不具备全局上下文特征提取能力, 导致模型泛化效果不佳。
近年来, 无论是技术的革新还是应用领域的多元化, 基于深度学习的图像分类技术都在计算机视觉领域取得了蓬勃的发展[3], 并且为高光谱遥感图像的分类技术注入了新的动力源泉。 深度学习可以基于多层神经网络层次结构自动地学习特征, 并自动完成特征的学习和优化[4], 将其应用于高光谱遥感影像分类, 不仅提供了特征的自动提取工具, 还可以在更加精细的层次下[5]对样本进行区分。 2015年, Hu等[6]首次将卷积神经网络应用到高光谱图像分类任务中, 其主要思想是将高光谱图像的每一个像元当做一个1× 1的图像, 每个图像有n个通道(n为波段数), 使用一维卷积核对通道进行卷积运算。 此种分类方式与将卷积神经网络运用到语音识别中类似, 对高光谱图像而言, 此种方式仅针对光谱特征进行分类, 没有利用其空间特征。 2016年, Lee等[7]利用上下文深度卷积, 同时应用多个不同大小的三维局部卷积滤波器, 共同利用高光谱图像的空间和光谱特征。 然后, 将应用不同大小卷积滤波器获得的初始空间和光谱特征图组合在一起, 形成空间-光谱联合特征图。 然后, 代表高光谱图像丰富光谱和空间特性的联合特征图被送入完全卷积层, 最终预测每个像素向量的相应标签。 2018年, Sharma等[8]连续抽取3个高光谱波段, 得到类似RGB图像的三通道输入, 使用2D CNN表征特征, 并结合AdaBoost、 SVM进行波段选择, 此种方法并未利用到高光谱数据的光谱特征。 同年, Hamida等[9]引入一种新的三维深度学习方法3D FCN, 实现光谱和空间信息的联合处理。 2019年, Swalpa Kumar Roy等[10]创新性地提出一种针对高光谱图像分类的混合卷积算法HybridSN, 在使用三维卷积核整体提取数据立方体的基础上, 再使用二维卷积核进一步学习更抽象的空间表示。
综上所述, 深度学习将特征和分类器结合到一个框架中, 自动地从大量数据中学习特征, 在使用中减少了基于传统机器学习需要手工设计特征的巨大工作量, 但是深度学习算法通常需要大量标记数据来训练分类器, 特别是在高光谱数据的类别较多时, 收集和标记这些数据可能非常昂贵和耗时, 使得网络训练出现“ 小样本” 问题, 现阶段提出的改进算法不具备普适性。
基于注意力机制(attention mechanism, AM)的Transformer具有强大的全局特征关联能力, 但其处理高光谱图像时仍遵循类似常规可见光图像的方式, 没有充分利用高光谱图像中的光谱信息。 ViT(Vision Transformer)[11]是Transformer在计算机视觉任务中的应用, 以其轻量化的特点大大降低了模型复杂度并提高了运算效率。 然而, ViT在实际使用中会出现计算量大、 频繁访存等问题。 为了提高ViT的推理效率, Liu等[12]设计了一种“ 三明治” 层次的新架构, 即在Efficient FFN层之间使用内存受限的多头自注意力(multi-head self-attention, MHSA), 同时在传统ViT中引入了级联群注意力机制(Cascaded Group Attention), 提出了一种轻量级多尺度注意力EfficientVit, 此模型在速度和精确度之间实现了很好的平衡。
当前神经网络的高光谱遥感影像分类算法的全局特征提取不足, 泛化能力差。 为利用EfficientViT的全局建模优势, 增强小样本下高光谱图像分类的全局与局部特征融合能力, 本文创新结合3D Vision Transformer(3D ViT)与混合卷积, 在HybridSN基础上联合3D Efficient ViT模块, 通过结合CNN的局部特征提取能力和ViT的全局上下文理解能力, 同时保持模型的复杂度在可控范围内, 提出了一种可用性强、 精度高的高光谱遥感图像分类算法: EVIT3D_HSN。
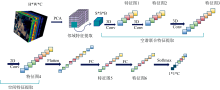
高光谱遥感图像通常有几十上百个波段, 常用于RGB三通道图像的分类网络(如CNN、 RNN和YOLO)不具备对高光谱图像进行特征提取的能力, 无法直接应用于高光谱图像。 三维卷积核既可以提取二维空间信息, 又可以沿着频谱维度滑动, 捕捉光谱特征。 HybridSN在三维卷积提取高光谱图像空谱联合特征的基础上, 混合使用二维卷积进一步提取高光谱图像的空间信息, 其网络结构如图1所示, 具体如下: 高光谱数据(I∈ RH× W× C, H: 高度; W: 宽度; C: 光谱深度)输入后, 首先经过PCA变换, 使其频谱维度降维至B, 以便进行后续的卷积操作。 为了使3D卷积核能提取到每一个像元邻近区域的空间信息, 进行邻域扩展(Neighbourhood Extraction), 即提取该像元周围S个像元的领域块(Patch), 使该邻域块(S× S× B)与第一层8个卷积核进行卷积操作, 生成8个三维特征图(Feature 1)。 后续两层3D卷积操作与此类似, 经过三轮3D卷积后, 网络生成了32个三维特征图(Feature 3), 三维卷积到此结束。 在进行二维卷积之前, 首先需要将特征图个数与光谱维特征图个数相乘, 从而改变特征尺度(Reshape), 使其可以进行二维卷积运算。 此时重新生成了576个二维特征图, 使其与64个二维卷积核进行卷积, 得到64个二维特征图。 随后, 对上述生成的特征通道进行两次全连接(Fully Connected)操作, 同时随机丢弃(Drop Out)结点, 使用ReLU激活函数进行非线性变换。 第三次全连接并进行Softmax后, 得到分类结果。
 | 图1 Hybrid网络结构图Fig.1 Hybrid network structure |
1.2 3D EfficientVIT模块
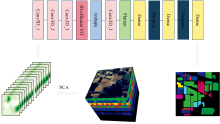
图2所示的3D Efficient ViT是基于Efficient ViT架构的三维视觉变换器(3D Vision Transformer), 通过在三维数据上应用变换器架构, 能够有效捕捉时间和空间的相关性, 从而提高模型对动态场景的理解能力, 对视频和三维医学图像等序列数据具有良好的识别精度。
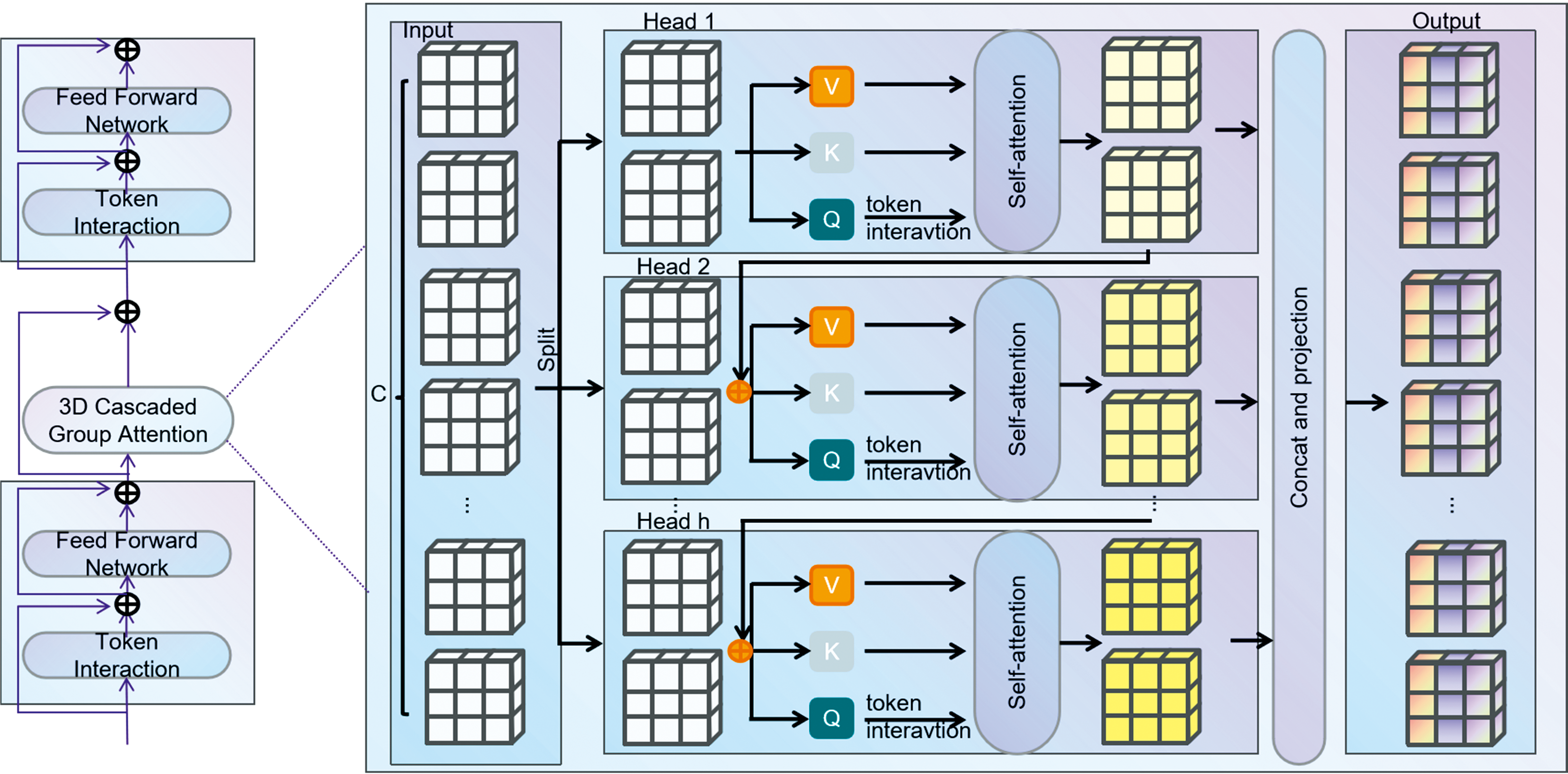 | 图2 3D Efficient ViT模块结构Fig.2 3D EfficientViT module structure |
3D Efficient ViT采用“ 三明治” 布局, 使用更多内存效率高的前馈神经网络层(feed forward netword, FFN)进行通道通信, 而使用较少内存受限的自注意层。 使3D Efficient ViT具备三维空间中捕获复杂的时空关系能力的就是图2中的核心模块3D级联群注意力机制(3D cascaded group attention, 3D CGA)。 CGA可以为多头自注意力(multi-head self-attention, MHSA)的每个头提供不同的特征, 从而将注意力计算分解到各个头, 解决了传统MHSA注意力头冗余的问题。
式(1)中, 第j个头的三维输入Xij(即输入特征的第j次分割)通过投影层Wij被划分为不同的子空间
级联群注意力为每个头部提供不同的特征分割, 提高注意力多样性, 减少网络参数。 同时, 级联注意力头可以增加网络深度, 从而在不引入任何额外参数的情况下进一步提高模型容量。
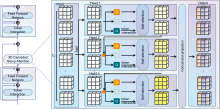
在HybridSN网络混合卷积的基础上, 联合3D Efficient VIT模块, 对HybridSN的混合卷积进行改进, 提出了一种可用性强、 精度高的高光谱遥感图像分类算法: EVIT3D_HSN, 其网络结构如图3所示。 首先将高光谱数据立方体输入网络, 为了降低光谱通道的维度, 对其进行了PCA操作。 经过PAC降维后的数据再进行领域拓展、 逐像元卷积操作, 这些操作步骤与HybridSN的处理方法类似。 随后数据通过三维卷积层进行处理, 以提取局部的空间光谱特征, 在该部分的处理中, 与HybridSN不同的是EVIT3D_HSN在三维卷积操作结束后不进行简单的特征图铺平操作, 而是进行通道对齐操作, 将三维特征图输入3D Efficient ViT, 进一步提取光谱特征。 相比于HybridSN, 本工作引入的3D Efficient ViT模块中使用的级联注意力机制可以帮助模型更好地捕捉高光谱遥感数据的光谱信息, 在没有引入额外的参数, 并未增加计算量的前提下增加了网络深度, 提高了模型分类精度。
 | 图3 EVIT3D_HSN网络结构Fig.3 EVIT3D_HSN network structure |
选取高光谱遥感图像分类数据集India Pines、 Pavia University和Salinas(以下分别简称IP、 PU和SA)进行实验, 数据集基本情况如表1所示。
| 表1 三种数据集的基本情况 Table 1 Basic information about the three datasets |
IP数据集为美国印第安纳州一块印度松树的高光谱成像数据, 空间分辨率为20 m, 横纵各145个像元, 光谱范围为0.4~2.5 μ m, 去除20个吸水(无法被水反射)的波段后, 剩余波段200个。 该数据集共有16种地物类别, 包括玉米(Corn)、 森林(Woods)、 小麦(Wheat)等, 其地物种类及分布情况如图4所示。
 | 图4 IP数据集假彩色图像及地物种类标签Fig.4 False color images and feature type labels for IP |
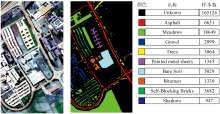
PU数据集采自意大利, 空间分辨率为1.3 m, 横纵各314、 610个像元, 光谱范围为0.43~0.86 μ m, 去除12个无法被水反射的光谱段后, 剩余波段103个。 该数据集共有9种地物类别, 包括树(Trees)、 沥青道路(Asphalt)、 砖块(Bricks)等, 其地物种类及分布情况如图5所示。
 | 图5 PU数据集假彩色图像及地物种类标签Fig.5 False color images and feature type labels for PU |
SA数据集来自美国加利福尼亚州, 空间分辨率为3.7 m, 横纵各217、 512个像元, 光谱范围为0.43~0.86 μ m, 去除20个无法被水反射的光谱段后, 剩余波段204个。 该数据集共有16种地物类别, 包括休耕地(Fallow)、 芹菜(Celery)等, 其地物种类及分布情况如图6所示。
 | 图6 SA数据集假彩色图像及地物种类标签Fig.6 False color images and feature type labels for SA |
采用Linux操作系统, 开发环境为Pycharm, 深度学习Pytorch 1.10.0框架, Python版本为3.8, 使用NVIDIA GeForce RTX 3060进行实验。 设置batch_size为64, 学习率(Learning rate)为0.001, 将数据集像元随机划分为训练样本和验证样本, IP数据集训练样本与测试样本比例为1∶ 9, PU和SA数据集比例为1∶ 19。 具体地, IP数据集使用1 024个像元为训练样本, 9 225个像元为测试样本; PU数据集使用1 638个像元为训练样本, 40 638个像元为测试样本; SA数据集使用2 706个像元为训练样本, 51 423个像元为测试样本。 为验证模型效果, 采用整体准确率(overall accuracy, OA)、 Kappa系数以及每类地物的F1值作为综合评价指标。
为验证本算法的先进性, 将本算法与其他代表性高光谱遥感图像分类算法1DCNN、 2DCNN、 3DFCN和3DCNN做对比实验, 并与原算法(HybridSN)做消融实验, 结果如表2所示。 2DCNN对高光谱遥感数据集分类结果不理想, 在三个数据集上的分类结果最差, 原因在于2DCNN只是依次抽取高光谱数据的3个相邻波段进行类似于RGB图像的二维特征提取, 并未利用到高光谱数据的光谱信息。 1DCNN将每一个像元作为训练对象, 提取其频谱值并使用一维卷积核进行卷积运算。 对于像元分布不均匀、 不利于空间特征提取的数据集PU, 相比于2DCNN, 其OA和Kappa系数分别提高了32.34%和32.8%。 3DFCN通过对抗训练和三维卷积提取高光谱数据的特征。 通常, 使用生成对抗网络的生成器, 再使用三维卷积同时提取光谱与空间信息, 会取得不错的结果。 但在实验中, 其网络训练速度慢, 分类精度差。 与之相比, 3DCNN更优, 特别是对于空间分辨率不高的IP数据集, 其OA和Kappa系数分别提高了17.31%和22.7%。 HybridSN在3DCNN的基础上叠加了2DCNN, 使用三维卷积核提取空间信息后, 将提取到的三维特征图进行Flatten, 使其展平为二维特征图, 进一步使用二维卷积核进行空间特征提取, 其网络精度较高, 优于1DCNN、 2DCNN、 3DFCN以及3DCNN与1D Classifier的结合。
| 表2 实验结果 Table 2 Experimental results |
但本文提出的算法EVIT3D_HSN在提取空谱联合特征后, 引入了3D Efficient ViT模块, 将三维、 二维特征进一步融合, 同时进一步提取一维光谱信息。 不同于HybridSN的Flatten操作, 3D Efficient ViT模块能捕获高光谱数据中复杂的空谱关系, 相比于HybridSN, 分类精度分别提高了3.76%、 1.88%和2.57%, Kappa系数分别提高了4.3%、 6.4%和2.9%, 证明本工作的改进有效。 应用于数据集IP、 PU和SA上, 算法EVIT3D_HSN的OA分别达到了97.66%、 99.00%和99.65%, Kappa系数分别达到了97.3%、 98.6%和99.6%, 模型具有高精确度和可用性。
表3— 表5显示了对于数据集IP、 PU和SA的每类地物的F1值, 本算法EVIT3D_HSN与上述五种算法的对比结果, 结果显示除IP数据集的Stone-Steel-Towers, PU数据集的Painted metal sheets和Shadows, 以及SA数据集的Stubble地物之外, EVIT3D_HSN对其他共37种地物的分类精度均最高。
| 表3 IP数据集各类地物F1值 Table 3 F1 values for each type of feature in IP |
| 表4 PU数据集各类地物F1值 Table 4 F1 values for each type of feature in PU |
| 表5 SA数据集各类地物F1值 Table 5 F1 values for each type of feature in SA |
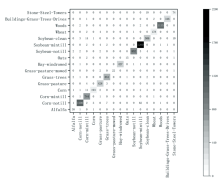
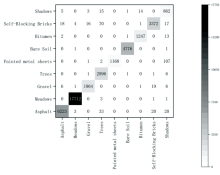
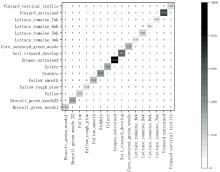
将本算法EVIT3D_HSN的实验结果绘制了混淆矩阵, 横轴是模型的预测结果, 纵轴是正确标签, 如图7— 图9所示。 混淆矩阵的对角线元素表示正确分类的数量, 因此在一个表现良好的混淆矩阵中, 对角线上的数值应该尽可能大, 表示大部分样本被正确分类。 非对角线元素表示分类错误的数量, 理想情况下, 这些数值应该尽可能小, 表示错误分类的样本数量较少。 图7— 图9显示算法EVIT3D_HSN对数据集IP、 PU和SA误分类极少, 分类精度高, 此结论与表2的OA值对应。 同时, EVIT3D_HSN对所有类别表现均衡, 并未出现某些类别被过度分类或分类不足的情况, 此结论与表3— 表5的F1值对应。
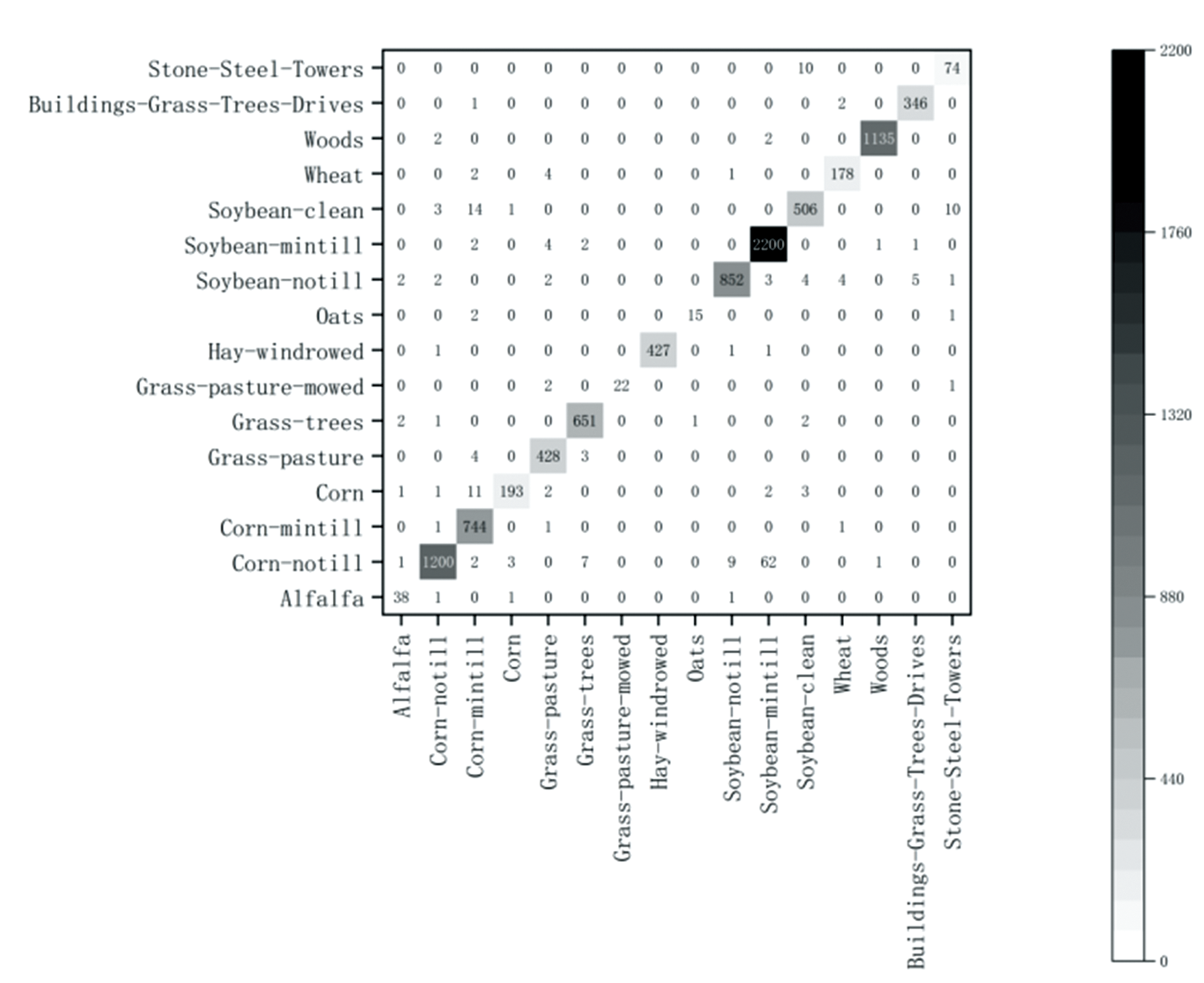 | 图7 IP数据集混淆矩阵Fig.7 Confusion matrix for IP |
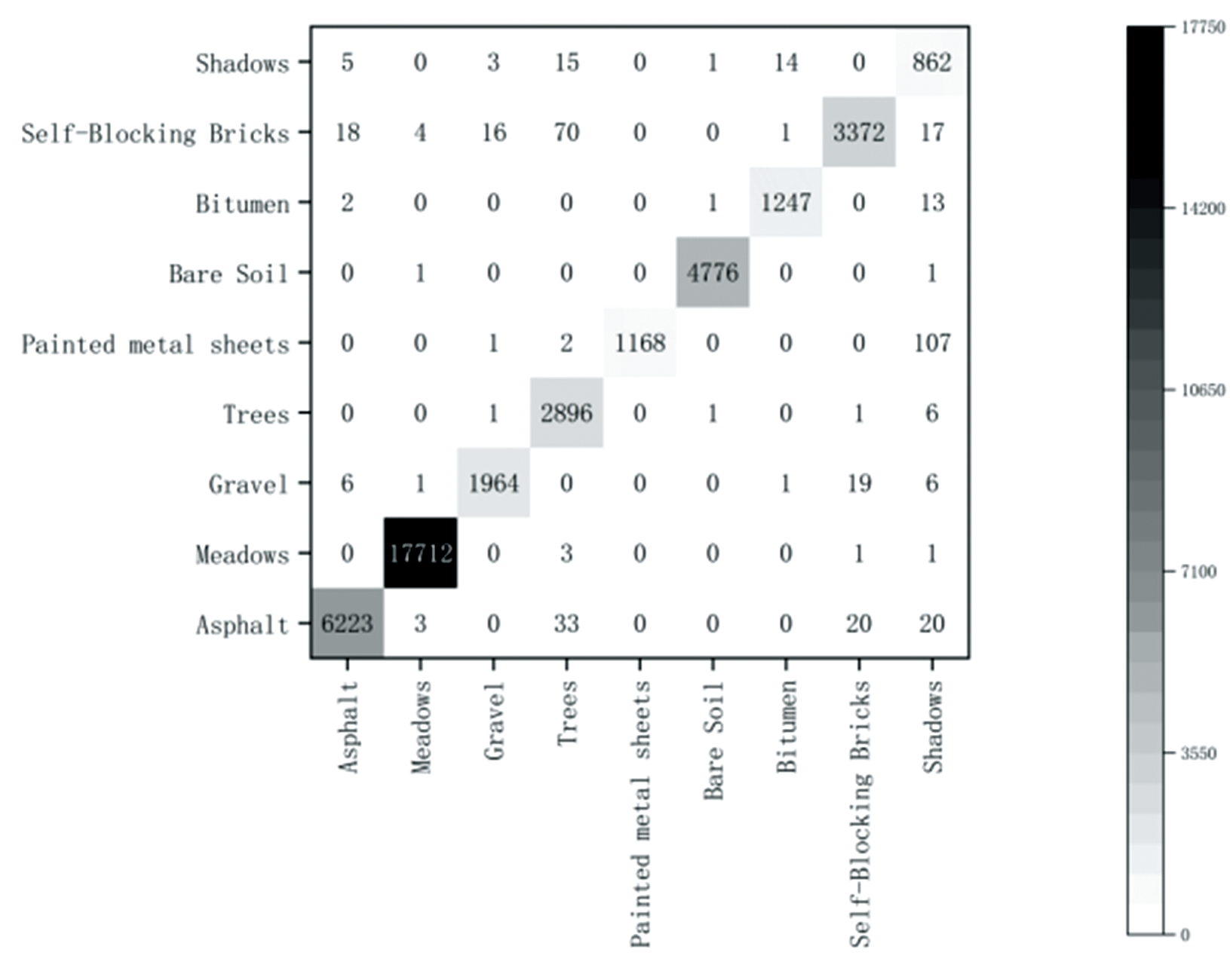 | 图8 PU数据集混淆矩阵Fig.8 Confusion matrix for PU |
 | 图9 SA数据集混淆矩阵Fig.9 Confusion matrix for SA |
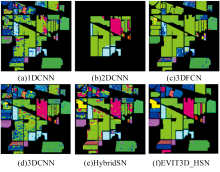
图10— 图12[(a)— (f)]分别展示了对于高光谱遥感数据集IP、 PU和SA, 算法1D-CNN、 2DCNN、 3DFCN、 3DCNN、 HybridSN以及EVIT3D_HSN的逐像元分类结果。 由于高光谱遥感图像训练“ 小样本” 的问题, 单纯提取光谱特征不足以取得良好的实验结果, 如图10— 图12(a)。 2DCNN在进行高光谱遥感图像分类时, 受其单独空间特征提取的影响, 分类出现了成片的错误, 错误样本边界清晰, 有明显的空间关系, 如图10— 图12(b)。 3DFCN分类精度差, 其使用的对抗训练不会对高光谱数据特征提取产生积极作用, 如图10— 图12(c)。 将三维卷积与二维卷积相结合的HybridSN网络效果要优于三维卷积, 如图10— 图12[(d)、 (e)], 同时, 虽然HybridSN分类精度较高, 但其边缘像元分类结果不佳, 且分类结果存在较多噪点, 如图10— 图12(e)。 上述问题均未出现在本算法EVIT3D_HSN中, 表明本算法相较于1D-CNN、 2DCNN、 3DFCN、 3DCNN、 HybridSN等模型具有高精度、 泛化能力强的优点, 如图10— 图12(f)。 同时该模型在地物块内部噪点识别精度上还有进一步提升空间, 如图10(f)。
 | 图11 PU数据集分类效果样例Fig.11 Sample classification effect of PU |
 | 图12 SA数据集分类效果样例Fig.12 Sample classification effect of SA |
针对高光谱遥感影像分类的问题, 提出了一种联合混合卷积与级联群注意力机制的高光谱遥感影像分类算法EVIT3D_HSN, 通过PCA降维以及三维、 二维混合卷积, 有效地捕获了影像在不同尺度下的空间和光谱信息, 从而克服了小样本条件下维度高、 信息冗余等问题。 同时, 利用3D Efficient ViT的级联群注意力机制, 进一步融合全局、 局部特征, 增强了分类精度和模型泛化能力。 通过实验验证, EVIT3D_HSN对HybridSN改进有效, 算法分类精度高, 模型具备良好的可用性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|