
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
高光谱成像的草莓缺陷检测及可视化
[赵路路1, 2  , 周松斌
, 周松斌1, 2 , 刘忆森1, 2, * , 庞锟锟1, 2 , 殷泽轩1, 2 , 陈红1, 2 ]
, 周松斌, 庞锟锟|
|


作者简介: 赵路路, 1995年生,广东省科学院智能制造研究所工程师 e-mail: ll.zhao@giim.ac.cn
草莓在采摘、 运输、 贮藏、 包装和销售过程中容易造成不同程度损伤与缺陷, 如淤伤、 冻伤, 真菌感染等, 给果农和销售商带来较大的经济损失。 高光谱技术是光谱传感与视觉技术的结合, 可实现水果各类品质缺陷的无损检测。 然而, 目前高光谱水果检测的建模方法仍存在两个方面的问题: 首先, 输入信息主要采用平均光谱为主, 对高光谱的图像信息利用不足; 其次, 目前卷积网络已成为高光谱信息处理的发展趋势, 但卷积网络存在感知域较小, 难以获得谱段或图像信息的长程关系。 为解决上述问题, 实现多种草莓缺陷的准确检测与识别, 提出空间光谱变换网络(SSTN)对四类(健康、 瘀伤、 冻伤、 感染)草莓的近红外高光谱数据(900~1 700 nm)进行分类。 SSTN以Vision Transformer(ViT)网络为主体, 将高光谱数据块进行位置编码作为输入信息, 从而实现“图谱联合”建模, 其内部的多头注意力机制还可捕获长距离谱段/图像关系。 实验方面, 以128个健康、 128个淤伤、 128个冻伤、 118个感染, 共计502个草莓作为样本, 按照1∶1的比例随机划分训练集和测试集, 进行分类建模实验。 结果显示, SSTN模型的分类准确率最高, 达到99.20%, 相比于一维卷积神经网络(1D-CNN)、 二维卷积神经网络(2D-CNN)和注意力卷积网络(CBAM-CNN), 精度分别提升了3.8%、 3.3%及1.5%。 为了能够进一步可视化各类草莓缺陷的具体位置, 将训练好的2D-CNN、 CBAM-CNN和SSTN模型分别与Score-CAM结合进行可视化。 缺陷可视化结果显示, CBAM-CNN模型中的卷积注意力机制能够提升缺陷定位的准确性, 而具有多头注意力机制的SSTN模型结合Score-CAM获得最佳的可视化效果, 能够准确的显示出缺陷的位置和缺陷形状轮廓。 该研究为建立一种快速、 无损、 自动化的草莓缺陷检测方法提供参考。
Strawberries can be easily damaged during harvesting, transportation, storage, packaging, and sales. The damages and defects encountered include bruising, frost damage, and fungal infections, which can cause great economic losses to fruit farmers and sellers. Hyperspectral technology combines spectral sensing and machine vision to non-destructively detect various quality defects in fruits. However, there are currently two problems in modeling hyperspectral fruit detection: First, the input information is mainly based on average spectra, and the hyperspectral image information is not adequately utilized. Secondly, convolutional networks (CNN) have become the main focus of development in hyperspectral data processing. Still, CNNs have a relatively narrow domain of perception, and it is difficult to obtain long-term correlations for spectral segments or image information. To solve the above problems and accurately detect and recognize various strawberry defects, a spatial-spectral transformation network (SSTN) was proposed to classify the near-infrared hyperspectral data (900~1 700 nm) of four categories of strawberries (healthy, bruised, frost damaged, and infected). The SSTN uses the Vision Transformer (ViT) network as the main body and hyperspectral data patches with encoded position information are used as inputs to achieve “spectra-spatial” modeling. The model's internal multi-head attention mechanism can also capture long-distance spectral/spatial correlations. In the experiment, 502 strawberries were sampled, including 128 healthy, 128 bruised, 128 frost damaged, and 118 infected strawberries. The training and test sets were randomly divided according to a1∶1 ratio. Half of the data was used to train the model to classify defects, and the other half was used to test the model's performance. The results show that SSTN achieved a maximum classification accuracy of 99.20%. Compared with one-dimensional convolutional neural network (1D-CNN), two-dimensional convolutional neural network (2D-CNN), and convolutional network with attention mechanism (CBAM-CNN), our SSTN model achieved accuracy improvements of 3.8%, 3.3%, and 1.5%, respectively. The trained 2D-CNN, CBAM-CNN, and SSTN models were combined with Score-CAM for visualization to further visualize the location of various strawberry defects. The results of defect visualization show that the convolutional attention mechanism in CBAM-CNN can improve the accuracy of the defect location, while the SSTN model with multi-head attention mechanism combined with Score-CAM had the best visualization performance, which can be used to accurately display the location and outline of the defect shape. This study provides a reference for establishing a fast, non-destructive, and automatic detection method for strawberry defects.
草莓(Strawberry)为蔷薇科、 草莓属植物, 原产于南美, 20世纪传入我国, 目前已成为我国重要的经济水果之一。 然而, 由于草莓没有较厚的果皮包裹, 且果实十分柔软, 因此在采摘、 包装、 冷冻储存、 运输等过程中, 容易形成机械损伤、 真菌/细菌感染, 冻伤、 果肉沾污等品质缺陷, 给果农和商家造成极大的经济损失。 目前草莓采摘期后的品质检测一般采用人工目检, 该方法存在着受主观影响大、 效率低、 准确性差等问题, 且早期的淤伤、 感染、 冻伤等质量缺陷仅通过人工目测不易识别。 因此, 发展快速无损的草莓缺陷检测与可视化技术, 对于发现草莓的早期缺陷[1]、 降低草莓的食品安全风险、 预测草莓的货架期[2]、 研究草莓缺陷的发展规律、 降低各环节的草莓浪费等具有重要意义, 具有迫切的行业需求与较高的实际应用价值[3, 4, 5]。
近年来, 高光谱成像作为一种新兴的无损检测技术, 由于集成了光谱信息和成像信息, 且具有较高的光谱和空间分辨率, 在水果品质与安全检测方面受到研究者的广泛关注。 例如, Liu等[6]使用连续投影算法(SPA)选择最佳波长, 并比较偏最小二乘判别分析(PLS-DA)、 支持向量机(SVM)和反向传播神经网络(BPNN)算法, 以识别擦伤和真菌感染的草莓, 基于全波段的支持向量机(SVM)模型最高分类精度达96.91%。 Zhang等[7]使用主成分分析(PCA)从草莓的光谱数据获取最佳波长后, 基于特征光谱数据结合纹理特征建立支持向量机(SVM)分类模型, 以区分三种成熟度的草莓, 分类准确率达到了85%以上。 Shen等[8]采集不同冷藏时间草莓的可见光和近红外(Vis/NIR)光谱数据, 基于竞争自适应重加权采样(CARS)选取特征波长后, 建立偏最小二乘判别分析(PLS-DA)分类模型, 其分类准确率达到97.4%。 传统机器学习方法的局限性在于, 一般采用平均光谱进行建模, 未能充分利用草莓高光谱数据的图像信息, 也较难通过该类方法实现缺陷的可视化与定位。
当前, 深度学习方法, 尤其是深度卷积神经网络(CNN), 在高光谱数据处理方面取得突破, 逐渐成为高光谱数据处理的发展趋势。 相比于上述传统方法仅采用草莓的平均光谱建模, 卷积网络能够更好的利用草莓高光谱数据的空间信息, 实现“ 光谱-空间” 信息联合建模。 Liu等[9]创建一种用于光谱空间分类和有效波长选择的双分支卷积神经网络(2B-CNN)模型对健康草莓和淤伤草莓进行识别, 通过同时提取光谱和空间信息, 其判别准确率高达99%。 Gao等[10]采集早熟草莓和成熟草莓的高光谱图像并提取了前3个主成分空间特征图像, 使用预训练好的AlexNet卷积神经网络对草莓成熟度进行分类, 准确率达到98.6%。 Chun等[11]对比了1D-CNN、 VGG-19和ResNet-50等基于卷积的深度网络, 发现ResNet-50对于草莓的灰霉病感染具有最好的识别精度, 并能够显著的提早灰霉病感染的识别期。 卷积神经网络中的卷积窗具有良好的局部上下文建模能力, 但是受到CNN的卷积窗尺寸限制, 其信息感知域有限, 难以处理高光谱数据中的长距离谱段或图像块的依赖关系。 因此, 也有学者利用空洞卷积网络等手段, 来增大卷积操作的感知域, 从而提升光谱数据处理过程中的长程相关性分析能力[12]。
除了分类识别研究, 也有不少研究者采用深度学习方法进行水果的缺陷可视化与定位方面的工作。 这类研究主要分为两类, 一类是直接采用深度网络进行缺陷区域定位。 例如, Lu等[13]采用YOLO网络并采用可见光图像和近红外图像对草莓缺陷进行定位, 输出缺陷位置坐标。 另一类方法采用类激活映射(CAM)方法, 主要是梯度类激活映射(Grad-CAM)方法进行。 田有文等[14]采用im-ResNet50模型进行蓝莓果蝇病虫害的识别检测, 并发现Grad-CAM可以实现病虫害部位的可视化。 Echim等[15]则采用Grad-CAM方法可视化草莓叶子上的病虫害侵害部位。 目前Grad-CAM是最常见的可视化方式之一, 但仍然存在着对梯度依赖大, 网络梯度饱和或梯度消失的问题, 使Grad-CAM的可视化出现错误或严重噪声。
本文提出空间光谱变换网络(SSTN), 进行四类(健康、 瘀伤、 冻伤、 感染)草莓高光谱数据分类。 该方法以Vision Transformer(ViT)网络为基础, 以整个高光谱数据进行分块编码作为输入。 与传统CNN的方法相比, ViT以具有多头注意力的Transformer为基本结构, 因此具有更强大的全局建模能力[16], 从而可以捕获长距离谱段或图像块之间的关系, 使得高光谱数据的“ 全局图谱融合” 建模成为可能。 此外, 采用Score-CAM方法结合SSTN网络对草莓的淤伤、 冻伤、 腐烂等缺陷进行可视化。 Score-CAM是Grad-CAM方法的进一步改进, 它采用置信度来获得权重, 从而摆脱了对梯度的依赖性, 实现对草莓缺陷位置的高精度可视化与定位。 此外, 通过对比Score-CAM分别与SSTN、 2D-CNN及注意力卷积网络(CBAM-CNN)结合的可视化效果图, 可以分析不同注意力机制对于缺陷定位与可视化效果的影响, 验证了多头注意力机制在缺陷可视化中的优势。
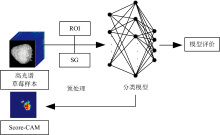
实验对象为草莓, 在获取各类草莓样本后, 通过高光谱成像系统采集各类草莓样本的光谱数据。 将各类草莓样本的光谱数据经过数据预处理后, 输入到不同的分类模型中, 并对各分类模型进行评价。 最后通过不同分类模型结合Score-CAM进行草莓缺陷定位与可视化。 整个实验的检测流程如图1所示。
 | 图1 基于高光谱成像的草莓缺陷检测流程图Fig.1 Flowchart of strawberry defect detection based on hyperspectral imaging |
所有的草莓样品都是从中国广州当地的超市所购买, 共计502个。 为了提高模型的稳健性和泛化性能, 草莓样品购于不同季节, 包括四个不同品种(红颜、 红宝、 双流和章姬)。 实验前, 对健康草莓样本进行人工目检, 保证其外观无缺陷及损伤。 共选取128个草莓作为健康草莓样品。
具有缺陷的草莓样品具体包括淤伤、 冻伤、 和腐烂三类。 其中淤伤的草莓样品是通过使用机械振动和压力模拟包装和运输过程中的损伤过程, 在受到损伤后的30 min内, 采集淤伤草莓的高光谱图像, 共计128个淤伤草莓样本; 冻伤草莓样品是将草莓样品在-1 ℃的温度下持续放置0.5~6 h, 然后从冷库将冻伤草莓取出, 在室温下放置4 h后, 采集冻伤草莓的高光谱图像, 共计128个冻伤草莓样本; 腐烂的草莓样本是通过对健康草莓注射灰葡萄孢的孢子溶液, 灰葡萄孢的孢子溶液浓度为1× 105 CFU· mL-1, 注射深度为2 mm, 在注射后的24~84 h的存储期内, 采集腐烂草莓的高光谱图像, 共计118个腐烂草莓样本。 各类草莓的部分样品如图2所示。
 | 图2 各类草莓样品Fig.2 The strawberry samples |
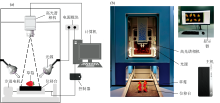
所有草莓样品的图像数据用近红外(NIR)高光谱成像系统采集, 如图3所示, 该系统主要由计算机、 高光谱相机(Specim, Spectral Imaging Ltd, Finland)、 光源模块、 电源模块、 控制器和位移台等组成。 相机镜头与位移台表面的垂直距离为28 cm, 光源模块由4个50 W的卤素灯组成, 它们放置在两个相对的框架中, 与位移台表面成45° 角。 高光谱相机以20.0 Hz的帧率逐行扫描草莓样品, 获得空间维度256× 320× 640(波段数× 像素数× 帧数)的三维数据。 高光谱相机的光谱分辨率为5 nm, 所获得的光谱范围在885~1 733 nm, 去除首尾两端噪声大的光谱数据, 保留1 000~1 600 nm范围的光谱用于后续建模分析。
 | 图3 高光谱成像系统 (a): 系统示意图; (b): 系统真实图Fig.3 Hyperspectral imaging system (a): Schematic diagram of system; (b): Real system diagram |
预处理是将原始高光谱数据转换成适应各模型的标准数据立方体。 预处理包括三个步骤: 高光谱图像校正、 光谱一阶导数预处理和高光谱图像分割。 图像校正是为了减小暗电流、 光源强度不均匀以及镜头不同位置透过率的差异等因素对原始高光谱图像的干扰, 其校正公式如式(1)所示。
式(1)中, R是校正后的高光谱图, Rraw是原始高光谱图像, Rw标准白板获取的光谱图像, Rd是将光源关闭和遮挡相机镜头采集的光谱暗电流图像。 对图像校准后的高光谱数据进行Savitzky-Golay(SG), 一阶导数预处理及归一化处理, 用于消除光谱中的基线漂移, 提高光谱的平滑性。 最后, 使用分水岭算法[17]去除高光谱图像的背景, 并从整个高光谱图像中提取草莓样品的三维光谱数据用于后续建模分析; 其中单个草莓数据的空间维度为180× 120× 120(波段数× 像素数× 像素数)。
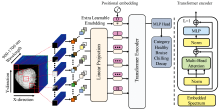
Vision Transformer(ViT)以其强大的全局建模能力而受到广泛关注, 并且ViT中的注意力机制可以捕获长距离谱段之间的关系, 可以更好地对光谱序列建模[18, 19]。 为了有效利用草莓数据集中光谱特征的序列属性, 检测不同缺陷的草莓; 如图4所示, 基于ViT构建了空间光谱变换网络(SSTN)分类模型。 SSTN主要由光谱映射模块、 Transformer编码器和基于多层感知机(MLP)分类器组成。
 | 图4 空间光谱变换网络(SSTN)模型结构图Fig.4 Structure diagram of the spatial spectral transformation network (SSTN) model |
1.4.1 光谱映射模块
为了同时使用高光谱图像维与光谱维的信息, 将完整的高光谱数据作为模型输入。 由于高光谱数据为三维光谱数据, 而Transformer编码器则以一维序列作为输入, 因此需要进行光谱映射, 将高光谱数据进行分块-拉伸-编码操作, 转化为一维序列。 首先, 将输入的光谱图像x∈ RN× W× C分割成N个独立的图像块xp∈
1.4.2 Transformer编码器
Transformer编码器旨在通过多头自注意力层获取高光谱图像中各图像块之间的关系, 包括波段之间关系与图像块之间关系, 从而同步感知光谱维与图像维的光谱信息。 具体地, 定义三个可学习的权重矩阵查询Q、 键K和值V; 使用点积运算出所有键K的查询, 然后使用softmax函数计算值V的权重。 自注意力的输出定义如式(2)所示。
式(2)中, dk是K的维数。 将查询Q、 键K和值V投影h次, 然后将结果合并组成多头注意力。 这些平行注意力计算的每一个结果被称为头。 多头自注意力的定义如式(3)所示。
式(3)中, $\operatorname{head}_{i}=\operatorname{Attension}\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right)$ , $W_{i}^{Q} \in R^{d_{\text {model }} \ \ \ \times \ d_{Q}}$ , $W_{i}^{K} \in R^{d_{\text {model }} \ \ \ \times \ \ d_{K}}$ , $W_{i}^{V} \in R^{d_{\text {model }} \ \ \ \times \ d_{V}}$ , $W^{0} \in R^{h \times d_{V} \times d_{\text {model }}} \ \ \ $是参数矩阵。
1.4.3 MLP分类器
通过Transformer编码器提取的信息会输入到MLP分类器中, 用于融合多头注意力的信息, 并输出分类结果。 MLP由两个全连接和一个高斯误差线性单元(GELU)激活组成, GELU公式为
式(4)中, ϕ (x)为高斯积累分布函数
为了验证SSTN模型的性能, 选择一维卷积网络(1D-CNN)、 二维卷积网络(2D-CNN)、 注意力卷积网络(CBAM-CNN)三种具有代表性的分类方法建立对比模型。
1.5.1 一维卷积神经网络(1D-CNN)
采用平均光谱作为输入, 构建典型的1D-CNN模型作为对比模型。 1D-CNN模型架构由3个一维卷积层、 2个池化层和2个全连接层组成。 卷积层的卷积核尺寸均为1× 5, 步长为1, 卷积核数量为16, 激活函数为ReLu函数; 池化层均采用1× 3的平均池化层; 两个全连接层的节点数分别为16和4。 采用交叉熵函数作为网络的损失函数, 并使用Adam优化器实现训练过程中神经网络的权值优化。 模型的学习率和迭代次数分别设置为0.000 5和500。
1.5.2 二维卷积神经网络(2D-CNN)
为了实现图像与光谱信息的融合, 以三维高光谱数据作为输入信息, 建立2D-CNN模型作为对比模型。 所构建的2D-CNN的模型架构由3个二维卷积层、 2个池化层和2个全连接层组成。 该网络卷积层的卷积核尺寸为5× 5, 卷积层的步长为1× 1, 卷积核数量为16; 池化层采用3× 3的平均池化层; 两个全连接层的节点数分别为144和4。 模型的学习率和迭代次数分别设置为0.001和100, 其他参数的选取与1D-CNN模型保持一致。
1.5.3 注意力卷积网络(CBAM-CNN)
为了与SSTN的多头注意力进行对比, 将CBAM注意力机制与2D-CNN结合, 进行草莓的分类以及缺陷可视化。 CBAM是一种混合注意力模型, 它通过在通道和空间两个维度上产生注意力特征图信息, 然后分别与之前的原输入特征图进行相乘, 进行自适应特征修正, 产生混合注意力特征图; 从而实现特征的增强, 提升分类效果。 CBAM的基本过程可表示为
其中, F∈ RC× H× W为网络主干生成的特征图, Mc∈ RC× 1× 1为光谱维通道注意力特征图, Ms∈ R1× H× W为图像维通道注意力特征图, $\otimes$表示元素级相乘, 最终得到的F″为混合注意力特征图。 CBAM-CNN除添加混合注意力机外, 其余所有参数设置与2D-CNN保持一致。
将各类草莓样本按照1∶ 1的比例随机划分训练集和测试集, 最终得到251个数据作为训练集、 251个数据作为测试集, 并建立草莓四分类模型。 为公平对比模型表现, 所有建模方法采用一致的样本集划分; 以准确率(Accuracy)、 精准率(Precision)、 召回率(Recall)和F1值(F1-score)作为评价指标, 以评估各模型的优劣; 各评价指标定义如式(7)— 式(10)所示。
其中, TP为将正类预测为正类的个数; FN为将正类预测为负类的个数; FP为将负类预测为正类的个数。
Score-CAM是一种类激活映射(CAM)的可视化解释方法, 与其他类激活映射(CAM)的方法不同, Score-CAM通过每个激活映射在目标类上的正向传递得分来获得其权重, 从而摆脱了对梯度的依赖, 最终由权重和激活映射的线性组合得到结果[20]。
Score-CAM包含三个步骤: ①通过模型提取特征图, 这也是所有CAM系列方法共有的步骤。 ②对特征图上采样, 然后将其作为掩码信息与原始图进行点乘并重新输入到模型中, 得到模型对新图像的预测分数; 然后, 将预测分数与模型对原始基线图像(baseline image)的预测分数相减, 所得差值称为置信度提升值(CIC), 代表特征图对模型预测目标类别置信度的贡献; 其求解过程如式(11)所示。 ③使用CIC分数作为权重, 与相应的特征图进行加权线性组合。 然后应用ReLU激活函数来生成最终的Score-CAM可视化结果, 突出显示对模型决策有重要影响的图像区域。
其中
式(11)和式(12)中,
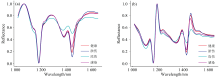
健康、 淤伤、 冻伤、 感染四类共计502个草莓样品的原始平均光谱与预处理后的平均光谱见图5。 从原始平均光谱[图5(a)]可见1 200和1 450 nm附近有吸收峰; 1 200 nm的吸收峰主要是由碳水化合物对光谱吸收引起, 1 450 nm处的吸收峰主要是由水分对光谱吸收引起。 四类草莓样本近红外光谱的谱带整体趋势接近一致, 光谱轮廓互有交叠, 仅通过肉眼不易区分不同类别。 如图5(b)所示, 通过对光谱数据进行SG一阶导数预处理, 可实现对原始平均光谱数据进行基线校正和平滑的效果, 使各类草莓的特征更加明显, 从而提高鉴别的准确率。
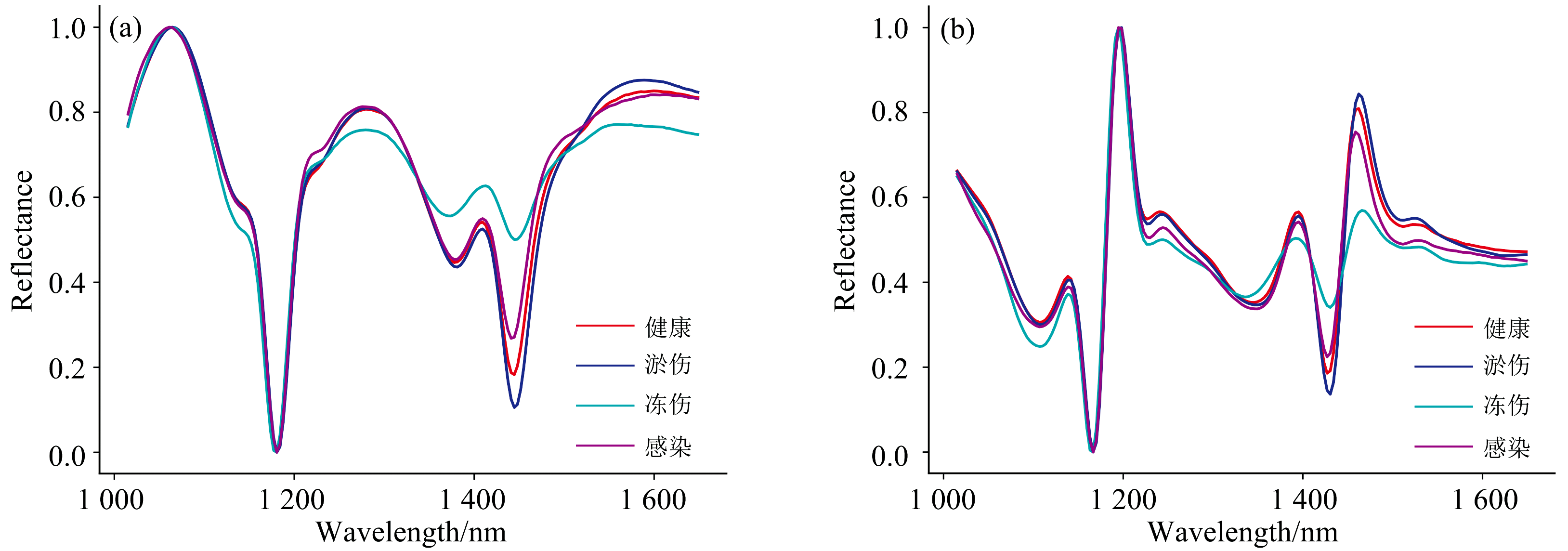 | 图5 光谱数据预处理 (a): 原始平均光谱; (b): SG一阶导数预处理Fig.5 Spectral data preprocessing (a): Original average spectra; (b): SG first-order derivative preprocessing |
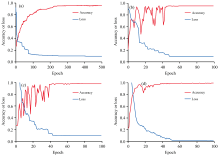
图6(a)、 (b)、 (c)、 (d)展示了1D-CNN、 2D-CNN、 CBAM-CNN和SSTN模型在训练过程中的测试集准确率和训练损失变化曲线。 由图6(a)可见, 1D-CNN模型的收敛较为缓慢, 但测试集精度平稳提升。 由图6(b)和图6(c)可见, 2D-CNN和CBAM-CNN以图像信息为主进行建模, 模型收敛较快, 但过程中测试集精度出现震荡, 然后逐渐平稳。 由图6(d)可见, 相比于2D-CNN和CBAM-CNN, SSTN综合光谱与图像信息, 训练过程中测试集的预测精度波动较小, 最终达到最高分类精度。
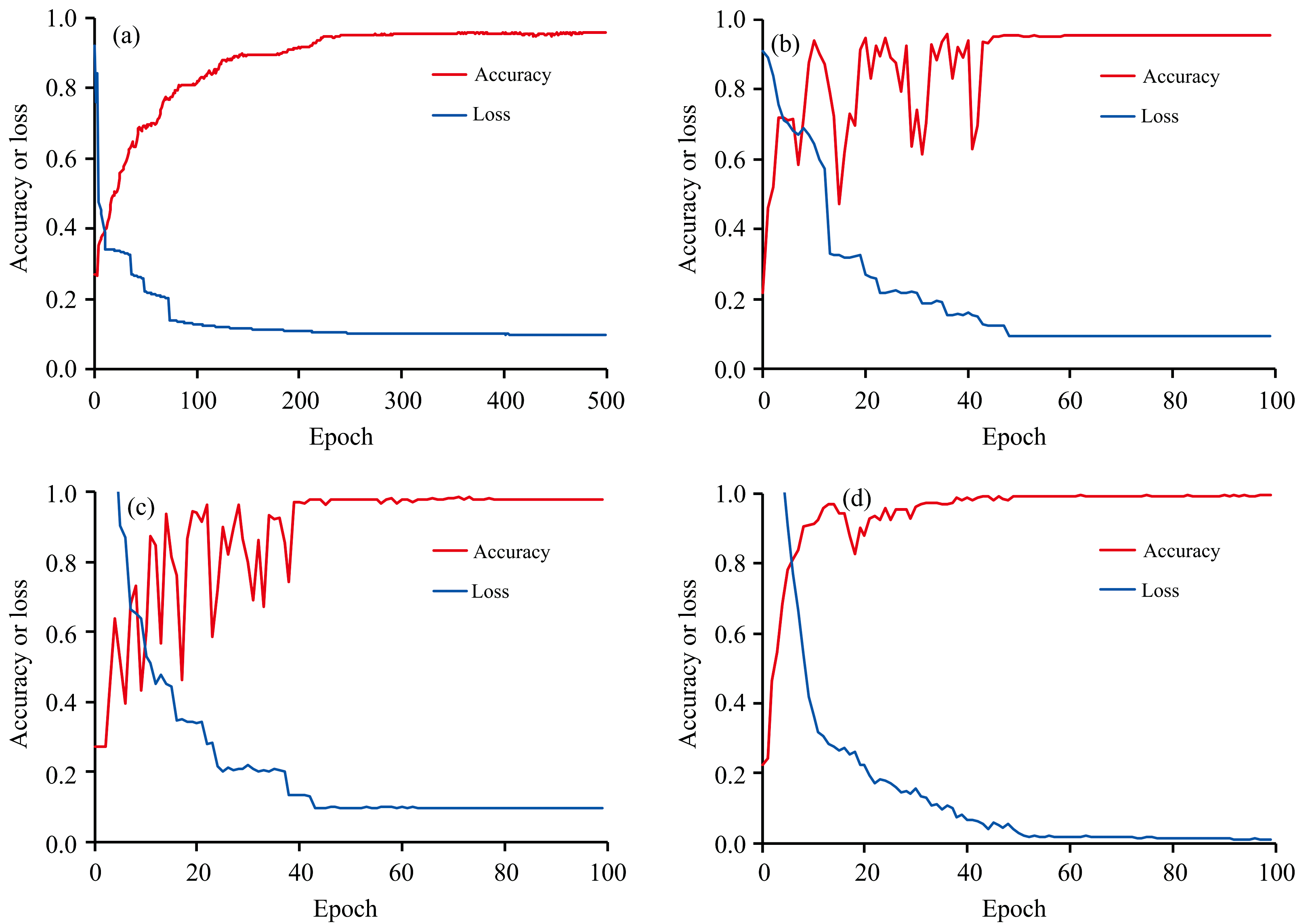 | 图6 准确率与损失变化 (a): 1D-CNN; (b): 2D-CNN; (c): CBAM-CNN; (d): SSTNFig.6 Variations of accuracy and loss (a): 1D-CNN; (b): 2D-CNN; (c): CBAM-CNN; (d): SSTN |
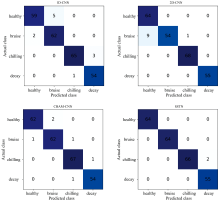
为评价各模型的稳健性和泛化性能, 将各模型的预测集准确率、 精准率、 召回率以及F1值的均值列于表1。 通过对比各模型的表现可得出, 采用光谱与图像信息结合的方法(2D-CNN、 CBAM-CNN及SSTN)表现总体优于仅使用光谱维信息作为输入方法(1D-CNN), 采用注意力机制的方法(CBAM-CNN及SSTN)的表现总体优于其他未加入注意力机制的方法(1D-CNN及2D-CNN), 说明通过使用图像维信息以及注意力机制能够明显提升草莓各类品质缺陷的识别效果。 相比于三种对比方法, SSTN方法取得了最优的准确率、 精准率、 召回率以及F1值, 其平均准确率相比1D-CNN、 2D-CNN、 CBAM-CNN分别提升了3.8%、 3.3%及1.5%。 为了进一步展示各模型的分类效果, 计算其混淆矩阵, 结果如图7所示。
| 表1 五种分类模型的性能比较 Table 1 The performance comparison of five classification models |
 | 图7 混淆矩阵Fig.7 The confusion matrices |
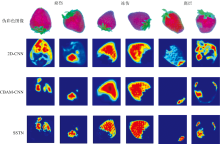
采用Score-Cam方法实现草莓缺陷的定位与可视化, 并分别在2D-CNN、 CBAM-CNN及SSTN上添加Score-CAM, 以对比不同网络缺陷定位与可视化的效果。 如图8所示, 基于Score-CAM方法可以较好地显示淤伤、 冻伤和腐烂三种缺陷的位置。 其中, 冻伤会对整个草莓的组织产生影响, 缺陷区域显示为除了草莓叶以外的所有果肉区域, 而淤伤和腐烂表现为草莓的局部缺陷。 对比不同分类网络对于缺陷定位的效果, 可以得出2D-CNN模型结合Score-CAM可以大致显示出缺陷区域, 但准确度不高, 不少非缺陷区域也会被高亮; CBAM-CNN模型相比于2D-CNN添加了CBAM注意力机制, 在分类模型建立过程中会对缺陷区域提高权重, 因此可以显著提升定位的准确性, 且对于淤伤和腐烂两种缺陷, 在非缺陷区域的干扰明显降低; 而由图8可见, SSTN模型因为采用了多头注意力机制, 所以对于缺陷的定位相比于CBAM更加准确, 且在缺陷处的成像更加清晰。
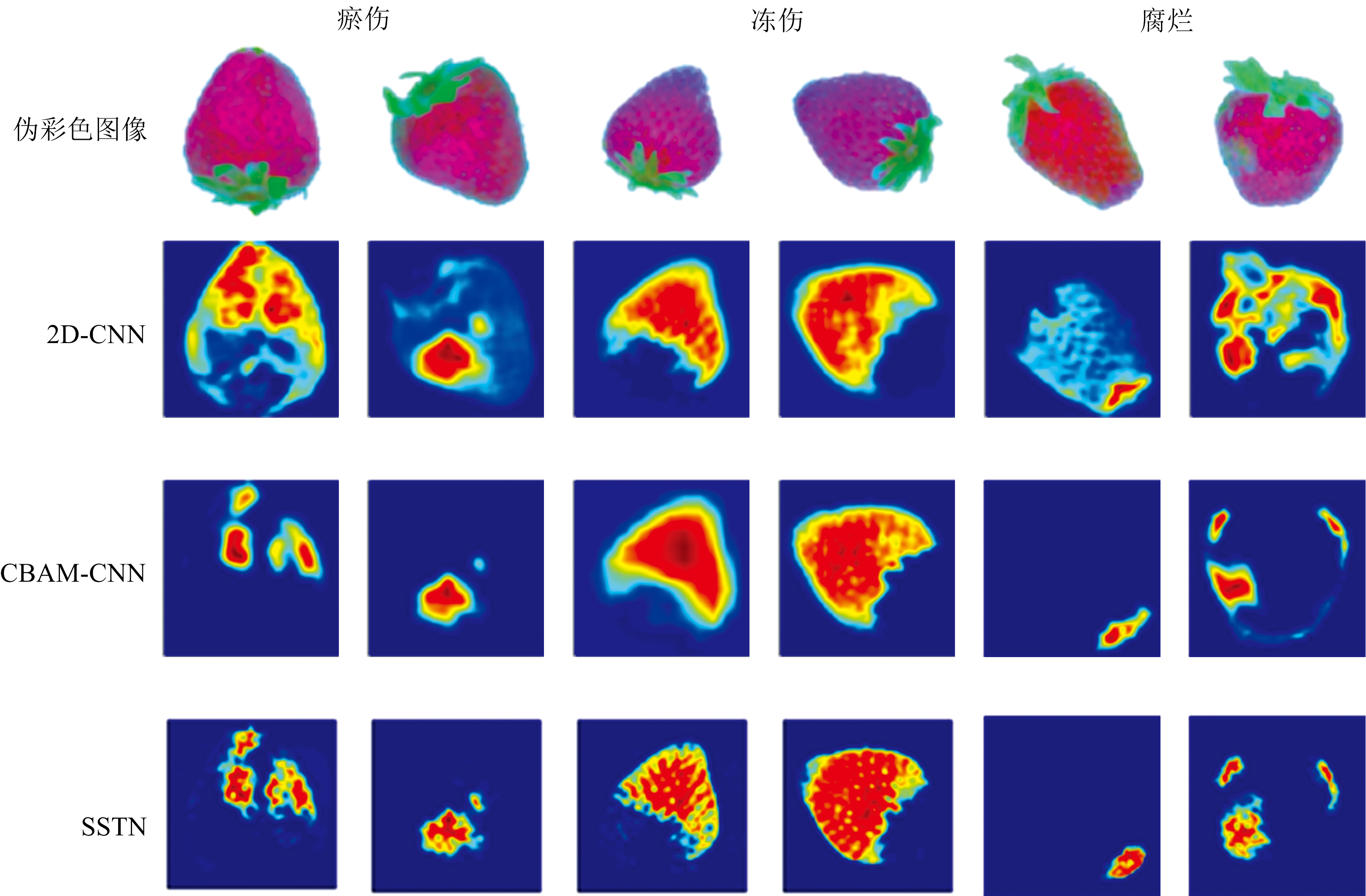 | 图8 草莓缺陷的可视化图Fig.8 The visualizations of strawberry defects |
采用高光谱成像技术结合深度学习实现草莓品质缺陷的识别与定位。 分别建立1D-CNN、 2D-CNN、 CBAM-CNN和SSTN模型, 进行健康、 淤伤、 冻伤、 腐烂四种草莓的分类。 结果表明, 1D-CNN、 2D-CNN、 CBAM-CNN和SSTN在测试集上的总体准确率分别为95.61%、 96.01%、 97.64%和99.20%; 其中, SSTN模型内部引入多头注意力机制, 可以获取各光谱序列之间的关系, 更好地捕捉光谱图像中的长距离依赖关系, 并且可实现光谱信息与图像信息的同步提取与融合, 其准确率、 精准率、 召回率、 F1值优于其他对比方法。
使用Score-CAM结合2D-CNN、 CBAM-CNN和SSTN模型, 实现草莓的缺陷定位与可视化。 结果表明, Score-CAM结合各类深度学习模型, 均可成功可视化各类草莓缺陷的位置; 其中SSTN由于采用了多头注意力机制, 所得缺陷可视化图比CBAM-CNN采用的混合卷积注意力机制更加精确。 综合实验结果表明, SSTN方法结合Score-CAM可成功实现健康与多种缺陷草莓的识别与分类, 并准确实现缺陷的定位与可视化, 为实现基于高光谱的草莓品质在线检测提供了方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|