
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱与深度域自适的芒果品种识别
[李统乐1  , 陈潇
, 陈潇2 , 陈孝敬1 , 陈熙1 , 袁雷明1 , 石文1 , 黄光造1, * ]
, 陈潇]
|
|


作者简介: 李统乐, 1997年生,温州大学电气与电子工程学院硕士研究生 e-mail: 22451842008@stu.wzu.edu.cn
不同品种的芒果不仅具有不同的品质, 还具有不同的经济效益。 传统芒果品种识别方法通常较为依赖从业者的经验费时费力。 如何快速地对芒果品种进行识别是需要解决的问题。 近红外光谱是一种快速、 无损的检测方法。 通常可以通过结合机器学习方法和近红外光谱数据识别不同品种的芒果。 由于仪器、 季节或年份等原因, 同一品种芒果的近红外光谱可能会有差别。 差别会导致先前批次测量的样本(源域)和新批次测量的样本(目标域)之间的数据分布有所不同。 数据分布的不同会导致先前建立好的分类模型不能对新测量的芒果样本准确分类。 本工作重点研究工作温度和季节等因素导致芒果近红外光谱数据的分布差异。 域自适应方法可以解决由于数据分布不同而导致的模型不适用。 使用深度域自适应神经网络(DANN)模型解决这类问题。 DANN模型通过对抗性的学习方式将两个域之间的特征对齐, 有效实现了跨领域的样本分类。 将DANN与无监督动态正交投影(uDOP)和联合分布适配(JDA)两种基于统计学习的传统域自适应方法进行了对比。 应用这三种方法的实验结果表明, DANN模型在芒果种类的二分类任务中, 对测试集的分类准确率达到94%。 在芒果种类的多分类任务中, DANN模型的分类准确率相比uDOP和JDA方法高超过10%。 结果表明, DANN模型可以很好地解决由于两个领域之间近红外光谱数据分布不同所导致的芒果品种识别的问题。
Different cultivars of mangoes can not only represent different qualities but also produce different economic benefits. Traditional mango variety identification methods often rely more on the experience of practitioners and are time-consuming and laborious. Therefore, how to quickly classify mango cultivars is an emerging problem that needs to be solved. Near-infrared (NIR) spectroscopy technology is a fast and non-destructive approach. Users can often identify different mangoes by combining machine learning methods with near-infrared spectroscopy data. However, the NIR spectral information of the same variety of mangoes can vary due to variations in different instruments, seasons, and years. These differences result in a different distribution between the previously measured sample data (source domain) and the newly measured sample data (target domain). Consequently, the present classification model cannot correctly classify new mango samples. Domain adaptation methods can solve this problem of model inapplicability caused by different data distributions. This article focuses on the distribution differences of mango near-infrared spectroscopy data caused by factors such as working temperature and season. The domain adaptation methods can solve the problem of model unsuitability caused by different data distributions. This article used a deep domain adaptive neural network (DANN) model to solve this problem. The DANN model effectively achieves cross-domain sample classification models by aligning features between two domains through adversarial learning. This article compared DANN with unsupervised dynamic orthogonal projection (uDOP) and joint distribution adaptation (JDA), two traditional domain adaptation methods based on statistical learning. The experimental results of applying these three methods in this article showed that the DANN model could achieve a classification accuracy of 94% for the test set in the binary classification task of mango varieties. In the multi-classification task of mango varieties, the classification accuracy of the DANN model was over 10% higher than that of uDOP and JDA. The results indicated that the DANN model could effectively solve the problem of mango variety recognition caused by the different distribution of near-infrared spectral data between two fields.
芒果是一种非常重要的美食和农作物, 在全球范围内受到广泛欢迎和大面积种植。 随着农业技术的发展, 各种芒果新品种不断涌现。 不同品种的芒果在味道、 口感和经济价值有所不同。 由于不同品种之间外观的相似性以及环境等因素对果实发育的影响, 芒果品种的准确识别是一个需要解决的问题。 许多传统方法已被用于确定芒果的品种, 如形态学鉴定、 细胞鉴定和脱氧核糖核酸(DNA)分析[1]等方法。 形态学鉴定的检测速度快, 但准确率取决于从业者的经验。 其他方法的识别准确率虽然高, 但对操作者的特定技能要求很高, 需要大量的时间处理[2]。 需要一种便捷的方法来准确地对芒果品种进行分类。 近年来, 近红外光谱技术在水果无损检测方面已有广泛使用。 研究使用近红外光谱检测技术对梨和桃子的不同品种进行了分类[3, 4]。
近红外光谱技术需要结合机器学习方法来构建芒果品种的分类模型。 这些模型使用训练集数据进行训练, 然后对测试集中的数据进行样本类别预测。 该领域的现有研究通常假设测试集的数据分布符合训练集的数据分布, 以确保模型在训练集上的预测性能能够有效地推广到测试集。 在近红外光谱用于芒果分类的实际应用中, 训练集的数据分布和测试集的数据分布一致的假设可能不成立。 近红外光谱仪不同的工作环境和芒果不同的生长环境等因素会导致训练集和测试集的数据分布存在差异。 这些差异使所构建的模型在测试集上的预测不再有效。 对于训练集和测试集数据分布不一致, 需要进行模型的校准转移。 目前, 近红外光谱领域常用的校准转移方法主要包括以下两类。
第一类是基于标准样本, 针对样本相同, 而外部环境不同产生的模型不适配问题, 比如相同样品在不同仪器或者不同测试环境下采集光谱。 这些方法使用标准样本从训练集和测试集收集标准光谱, 以此计算出测试集光谱到训练集光谱的传递函数。 传递函数用于标准化测试集的光谱, 以满足训练集校准模型的数据分布要求[5]。 Wang等[6]用转换矩阵来转换和校正全波段近红外光谱的直接标准化(direct standardization, DS)方法。 Bouveresse等[7]提出基于DS方法的分段直接标准化(piecewise direct standardization, PDS)方法。 Du等[8]提出光谱空间变换(spectral space transformation, SST)方法。 如果无法获得标准样本, 或难以同时测量训练集和测试集中标准样本的光谱, 这类方法很难应用。
第二类方法是域自适应方法。 域自适应方法的基本思想是对一个从源域学习到的模型, 借助无标注的目标域样本对模型进行自适应的调整, 使其能够转移到目标域中, 解决目标域中样本属性的预测问题[9, 10]。 该类方法只需用带标签的源域数据和不带标签的目标域数据训练模型, 就能够处理样本和外部条件不同产生的模型不适配问题。 在芒果品种分类的域自适应中, 训练集数据来自源域, 测试集数据来自目标域。 域自适应方法能够满足实际中复杂的芒果品种分类模型校准转移的要求。
在机器学习领域有许多领域自适应方法。 Zeaiter等[11]提出了一种称为动态正交投影(dynamic orthogonal projection, DOP)的方法, 需要在新的条件下使用一些额外的测量值进行校准转移。 为了简化操作, 更好地推广DOP方法, Valeria等[12]在DOP的基础上开发了不需要额外测量的无监督动态正交投影(unsupervised dynamic orthogonal projection, uDOP)。 Pan等[13]引入了一种被称为迁移成分分析(transfer component analysis, TCA)技术, 该技术匹配两个域之间的边缘分布, 以实现域自适应。 Wang等提出的联合分布适配(joint distribution adaptation, JDA)方法, 将边缘分布和条件分布联合适配。 已经有域自适应方法在橄榄干物质预测和小麦种子分类中的应用[14, 15]。 这些方法的性能取决于其算法的设计。 深度学习可以从数据中提取特征, 并将学习到的特征集成到建模过程中, 减少人工设计算法的局限性。
随着深度学习方法的快速发展, 越来越多的研究人员使用深度学习网络进行模型的校准转移。 基于对抗性网络的深度学习模型成为校准转移的热点。 一个典型且广泛使用的模型是域自适应神经网络(domain adversarial neural networks, DANN)[16]。 先前对DANN模型的研究更多地用于图像领域。 Javier等[17]使用改进的DANN模型准确计数和定位航空图像中的热带植物。 根据所查的资料, DANN模型很少用于近红外光谱的芒果分类。
针对训练集与测试集分布不一致的芒果品种分类, 采用域自适应方法构建近红外光谱的分类模型, 目前这方面的相关研究很少。 本工作使用不同季节和仪器工作温度的芒果近红外数据集验证DANN模型的有效性, 并与uDOP和JDA这两种近红外光谱领域中常用的域自适应转移方法对比。
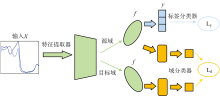
实验使用芒果的近红外光谱公共数据[18], 该数据集中包括数千个芒果样品, 波长范围在309~1 059 nm之间。 该数据集在不同的背景条件下收集, 包括不同的季节、 芒果品种和仪器工作温度。 所用品种如图1所示, 包括(a)“ 大澳芒” (R2E2)、 (b)“ 卡里普索” (Caly)、 (c)“ 蜂蜜黄金” (HG)和(d)“ 肯辛顿骄傲” (KP)。 芒果的成熟阶段分为硬绿色和成熟两个阶段。 仪器工作温度指仪器在不同环境温度下扫描芒果样品。 数据集中的温度是指扫描芒果时的样品温度。 有三种仪器工作温度分别为低(15 ℃)、 中(25 ℃)和高(30 ℃)。
 | 图1 数据集中所用芒果品种 (a): 大澳芒; (b): 卡里普索; (c): 蜂蜜黄金; (d): 肯辛顿骄傲Fig.1 The mango varieties used in the data set (a): R2E2; (b): Calypso; (c): Honey Gold; (d): Kensington Pride |
使用芒果数据集进行了三个实验。 表1为三个实验中使用的芒果样品。 在实际测量中, 仪器使用时的环境温度对测量结果的影响难以避免。 第一个实验使用仪器的工作温度作为两个域之间的转移背景。 实验1中两个域样品是测量于不同仪器工作温度的品种Caly和品种KP。 实验2设计目的是模拟样本自身变化所导致的数据分布差异问题, 两个域的样品为不同季度的品种Caly和品种KP。 实验3同实验2一样用不同的季节作为转移背景, 同样用于研究样本自身变化所导致的数据分布差异问题, 而分类的品种从两个增加到三个, 分别为品种Caly、 品种HG和品种R2E2。 同时实验3中用于分类的芒果样品中包含两个成熟阶段, 即硬绿色和成熟。 不同的成熟度并不作为两个域之间的转移差异, 即可以增加两个域之间转移的难度。
| 表1 三个实验中使用的芒果数据集的描述 Table 1 Description of the mango datasets used in the three experiments |
等距空间映射(ISOMAP)用于直观显示潜在空间中的数据特征分布。 将来自两个域的样本随机分为训练集(70%)和测试集(30%)并进行数据标准化预处理。 对于两种比较方法, 在校准转移后分别使用随机森林算法(random forest, RF)和线性判别分析算法(linear discriminant analysis, LDA)对特征进行分类。 分类准确率由式(1)提供
式(1)中, TP(真阳性)为将正类预测为正类数; TN(真阴性)为将负类预测为负类数; FP(假阴性)是将负类预测为正类数; FN(假阳性)是将正类预测为负类数。
DANN模型由三个部分组成, 其结构如图2所示。 输入样本X由来自源域和目标域的多个一维真实光谱数据组成。 第一部分是特征提取器。 特征提取器可以分别从两个域的光谱数据中提取特征。 第二部分是标签分类器。 特征提取器和标签分类器共同构建了一个前馈神经网络, 该网络被训练用来对输入样本X进行分类。 最后一部分是域分类器, 用于区分提取的特征来自源域还是目标域。
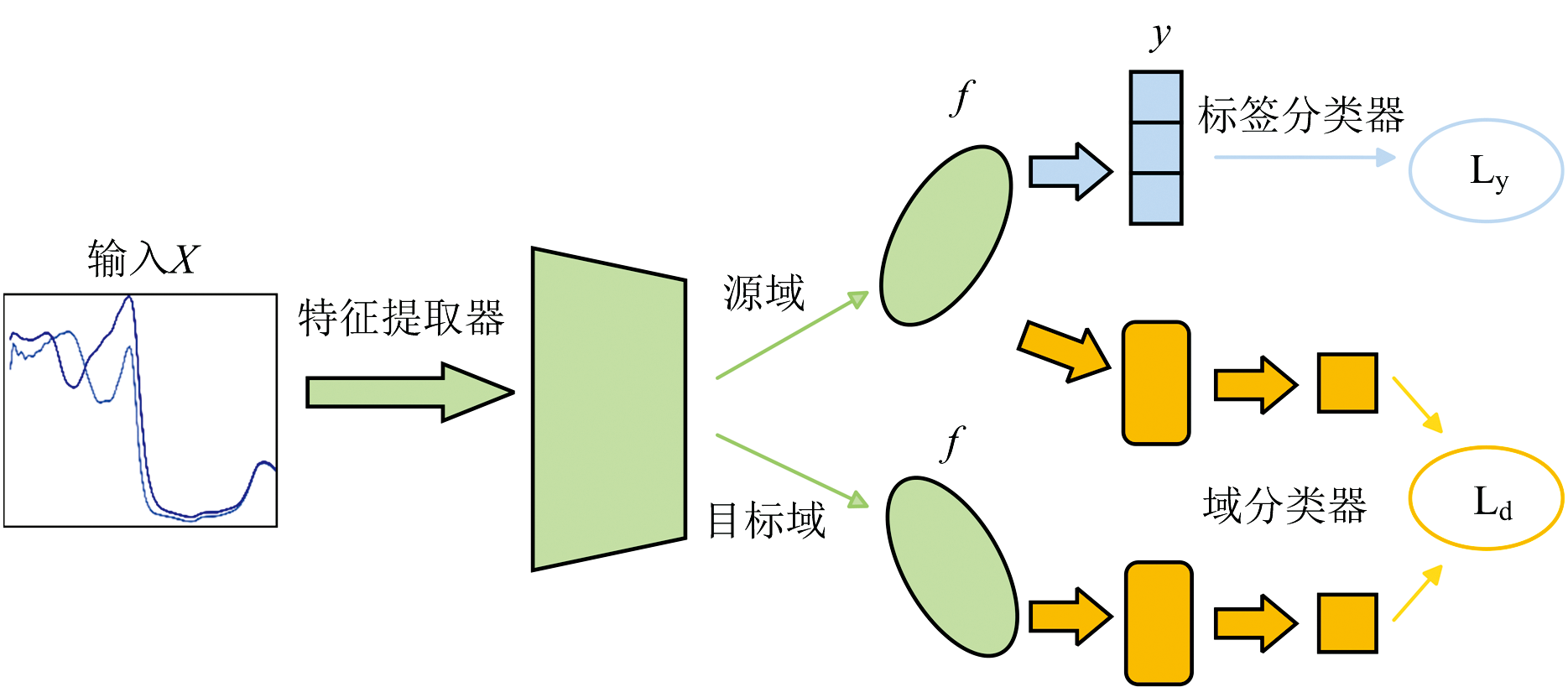 | 图2 使用的DANN模型由三个部分组成 特征提取器用于提取数据的特征; 标签分类器对来自特征提取器的特征进行分类; 域分类器用来区分特征的来源是源域还是目标域Fig.2 The diagram of DANN used in this article consists of three parts The feature extractor extracts data features; The label classifier classifies features from the feature extractor; The domain classifier determines whether the features come from the source domain or the target domain |
在DANN模型的训练过程中, 特征提取器将每次从源域和目标域中提取特征提供给标签分类器和域分类器(见图2)。 DANN用从源域中提取的特征和源域的标签来训练标签分类器。 这样训练出来的标签分类器并没有经过域自适应转移, 对目标域的分类效果较差。 DANN通过特征提取器和域分类器之间的对抗性学习来实现域自适应转移。 当域分类器能区分出提供的特征来哪个域时, 两个域提取的特征之间数据分布差异仍然较大。 在数个训练周期中, 所有模块参数同时更新, 特征提取器不断将提取的特征提供给域分类器区分, 直到域分类器无法区分特征提取器提取的特征来自哪个领域, 这时对抗性训练就完成了。 通过这种对抗学习的方式, 特征提取器从两个域提取的特征足够相似, DANN可以使用源域提取的特征训练的标签分类器对目标域提取的特征进行准确分类。
在与近红外光谱相关的机器学习领域中, 域自适应方法大多基于统计学习。 这类方法大体分为基于特征重构的域对齐方法和基于特征分布的域对齐方法。 本研究选择无监督动态正交投影(uDOP)方法作为基于特征重构的域对齐方法和联合分布适配(JDA)作为基于特征分布的域对齐方法。
uDOP方法: uDOP是动态正交投影(DOP)结合光谱空间变换(SST)的无监督版本。 uDOP通过奇异值分解(SVD)得到源域数据和目标域数据的负载和投影, 通过使用两个域的投影并结合源域的负载构建虚拟的目标域样本。 域间差异由虚拟的目标域样本和真实的目标域样本之间的差异构建。 uDOP使用域间差异和源域样本来构建虚拟的源域样本, 这样重新构建的虚拟源域样本就同时包含源域和目标域的信息。 uDOP通过这种方式来实现域自适应学习。
JDA方法: JDA将两个域中的数据同时映射到高维再生核希尔伯特空间中, 并在这个空间中使用最大均值差异(MMD)距离求两个域的边缘分布差异。 JDA通过带标签的源域数据训练分类器(所使用的是随机森林和线性判别分类两种分类器), 求得目标域数据的伪标签。 JDA通过迭代提高伪标签预测的准确性, 并根据伪标签来计算两个域的条件分布差异。 JDA同时适配两个域的边缘分布和条件分布来实现域自适应学习。
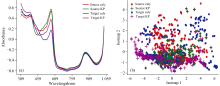
光谱分析以实验2为例, 研究样品自身变化对芒果近红外光谱的影响。 图3(a)为两个品种在不同域中的近红外的平均光谱。 在580~1 059 nm范围内, 同品种在不同域之间存在较小的差异, 在309~459和459~580 nm波长范围内同品种在不同域之间有较大的差异。 尤其是在350~550 nm波长范围内, 无论是在源域中还是目标域中的两个品种的平均光谱有重叠部分。 说明不同季节对芒果近红外光谱测定有一定影响。 如果不使用一些方法消除这种影响, 很可能会使品种的分类出现错误。 图3(b)二维ISOMAP评分图可以直观显示实验2中两个品种在不同域的差异。 品种Caly和品种KP的样品无论是在源域中还是在目标域中, 都可以看出存在一定的品种间的差异性和品种间的相似性。 同一品种在不同域之间的特征和同一域内不同品种的特征又有重叠。 这是由于不同季节间有许多复杂因素对芒果生长造成影响, 由图3(b)中可以看出简单地使用降维等方法很难消除这种影响。 采用域自适应的方法来解决两个领域之间的数据分布差异问题非常必要。
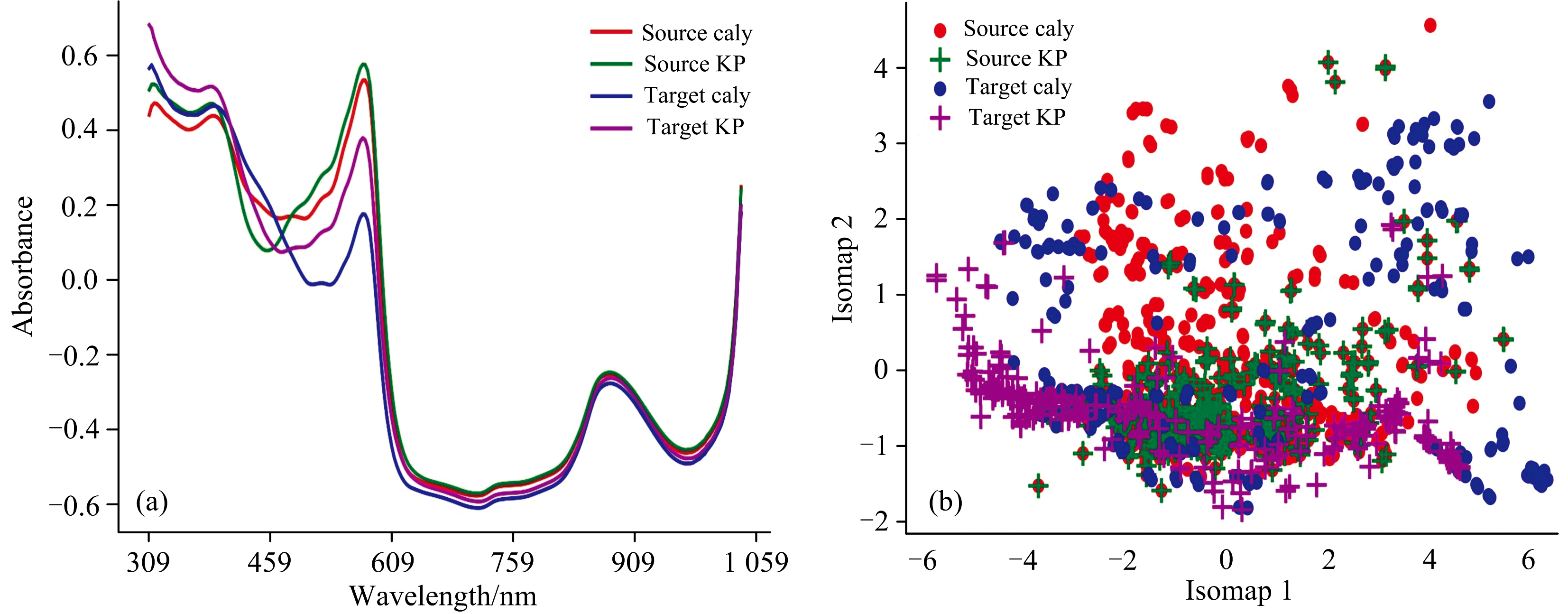 | 图3 (a)实验2中两个域中样品的平均光谱图; (b)实验2中两个域样品在ISOMAP1× ISOMAP2空间中的得分图 源域Caly为红色; 源域KP为绿色; 目标域Caly为蓝色; 目标域KP为紫色Fig.3 (a)The average near-infrared spectra for Experiment 2 samples of the two domains; (b) Score plots of Experiment 2 samples from the two domains in the ISOMAP1× ISOMAP2 space The source domain Caly is red, the source domain KP is green, the target domain Caly is blue, and the target domain KP is purple |
由光谱分析可以看出, 环境因素会使芒果的近红外光谱数据发生改变。 这种改变会影响机器学习算法对芒果品种的正确分类。 三个实验的结果如表2所示。 用于对比的两种方法, 使用随机森林算法和线性判别分析算法的分类准确率相差不大, 说明分类器对域自适应算法的分类准确率影响较小。 三种方法在实验1和实验2中的分类准确率都在84%以上, 在实验1中的准确率更高。 表明仪器温度或季节作为单一的转移背景时, 通过域自适应方法可以很容易消除域之间的数据分布差异。 两个品种的芒果样品通过近红外光谱可以轻易区分, 同时季节对芒果近红外光谱的影响大于仪器对芒果近红外光谱的影响。 三个方法中uDOP方法的分类准确率最低, 说明uDOP消除域间差异能力最弱。 而DANN和JDA的分类准确率较高的原因在于有源域的标签参与训练。
| 表2 三种方法在三个实验中对芒果品种分类的准确率 Table 2 The accuracy of three methods in classifying mango varieties in three experiments |
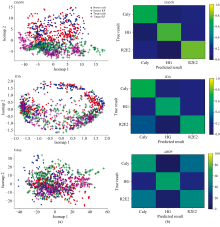
图4(a)为实验2中三种方法对样品域自适应转移后在ISOMAP空间中的得分。 如图4(a)所示, uDOP可以较好地对齐域之间的特征, 而很难保留不同品种之间的差异, 两个品种的可分性较差。 JDA可以很好地将两个域的特征对齐, 而两个品种的特征仍有较多重叠部分, 两个品种的可分性较好。 DANN模型不仅将两个域之间的特征很好地对齐, 并很好地确保了两个品种的可分性。
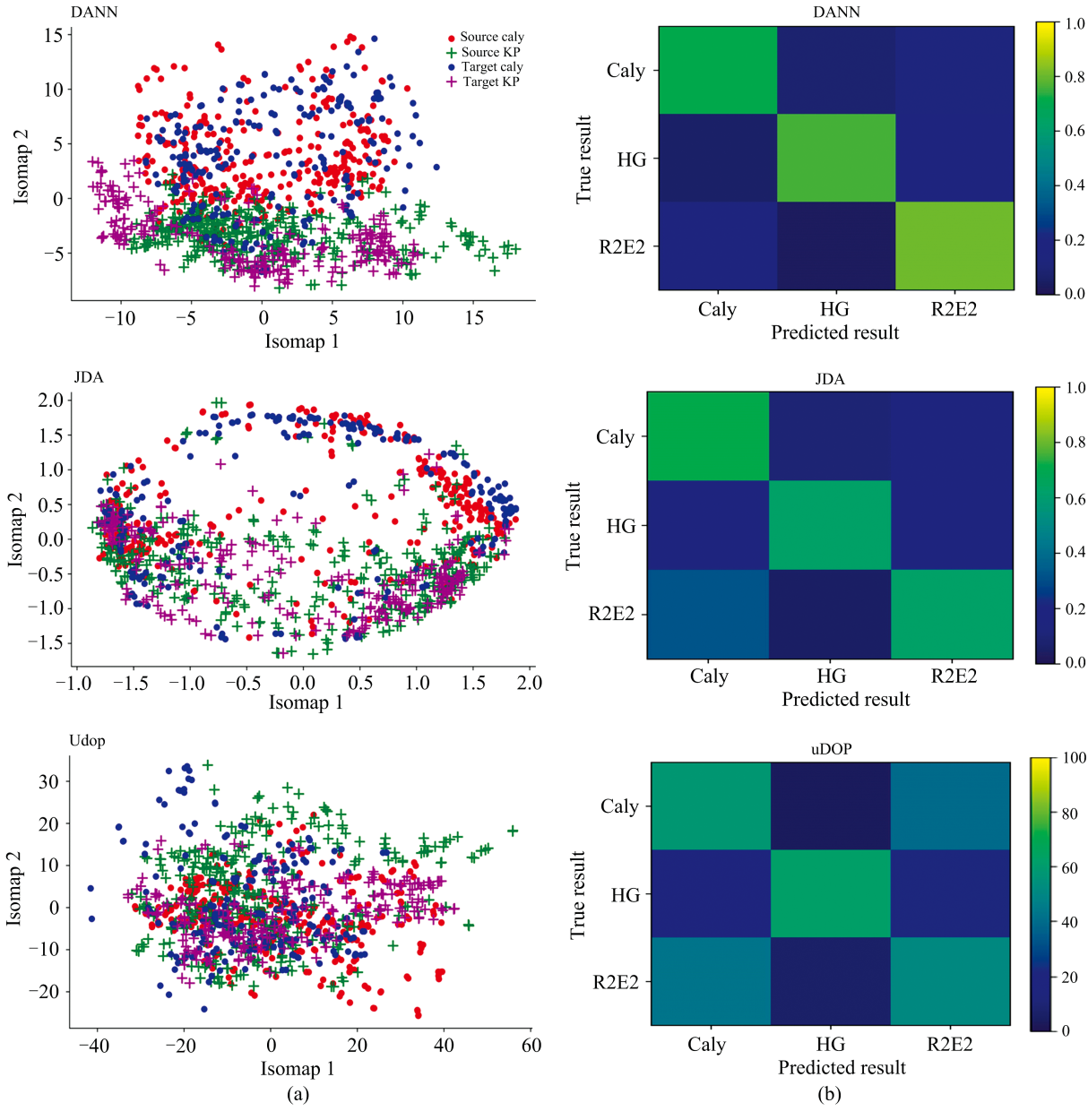 | 图4 (a)实验2中三种方法对样品域自适应转移后在ISOMAP1× ISOMAP2空间中的得分图; (b)实验3中的分类准确率混淆矩阵Fig.4 (a) Score plots of samples from Experiment 2 in the ISOMAP1× ISOMAP2 space after transfer by 3 methods separately; (b) The confusion matrix of accuracy in Experiment 3 |
实验3中, 三种方法的准确率都有较大幅度的降低, 表明多分类任务和不同成熟阶段会增加域之间的转移难度。 uDOP的准确率最低, 由于uDOP在创建虚拟标准样本时更多地基于源域的负载。 导致目标域中与源域相似的部分被保留, 而大多数不相关的信息被消除。 结果表明uDOP对三分类和对具有多因素转移背景任务的校准转移能力十分有限。 JDA方法同时适配两个域之间的边缘分布和条件分布, 并为它们分配相同的学习权重。 然而这两种分布的重要性并非总是相同。 当预测目标域伪标签所使用的分类器准确率较差时, JDA也很难通过迭代方式提高伪标签的准确率。 如果仍然为两个分布分配相同的权重, 会使得两个域之间的特征对齐效果变差。 与JDA基于MMD距离进行域间特征对齐的方式相比, DANN通过对抗性的深度学习网络更有优势, 可以更好地减小域间的特征分布差异, 也不需要对样本差异进行先验假设。 优于JDA的性能说明, 通过神经网络提取数据特征的方式可以使DANN在不细分多因素的转移背景的三分类任务中, 比基于统计学习的方法具有更好的适用性和灵活性。 图4(b)为实验3中三种方法对目标域测试集分类结果的混淆矩阵。 三个品种的分类准确率如图所示, DANN对样本数最少的R2E2品种的分类准确率最高, 而uDOP和JDA方法对R2E2品种的准确率最低。 说明基于神经网络的DANN方法对小样本数据的域自适应转移更具有优势。
由图4(b)看出, DANN模型对Caly和R2E2品种分类错误的概率约为25%。 图4(a)中, DANN模型源域中不同品种的特征分布边界和目标域中不同品种的特征分布边界非常相似。 说明DANN模型在两个域转移时有较多考虑将域中的特征作为一个整体进行对齐, 而较少考虑域中各类特征的特点。 DANN模型的这种特点虽然能较简单直接地将两个域的特征进行对齐, 而对特征相近的多分类任务的效果不够理想。
文章应用深度域自适应神经网络(DANN)解决芒果近红外光谱数据由于分布不同所导致源域模型无法对目标域样本准确分类的问题。 DANN模型通过对抗学习的方式将两个域提取的特征较好地对齐。 与uDOP和JDA方法相比, DANN的分类准确率通常高出10%。 当两个域之间存在较大差异时, DANN比JDA更有效, 并远优于uDOP。 结果表明, DANN模型在芒果不同品种的检测中具有较高的准确度和实用性。 DANN模型可易于处理分类任务中由于季节和仪器不同而造成的差异。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|