

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于显微高光谱成像技术的尿沉渣结晶样本分析
[邓颖佼1  , 陈军
, 陈军2 , 王健生1 , 胡刘平3 , 张晴1 , 杜玉珍3 , 王妍1 , 李庆利1, * ]
, 陈军]
|
|


作者简介: 邓颖佼,女, 1998年生,华东师范大学上海市多维度信息处理重点实验室博士研究生 e-mail: 52215904009@stu.ecnu.edu.cn
尿液有形成分(尿沉渣)的分析在临床中具有重要意义, 医生通过观察尿沉渣中的颗粒、 细胞和结晶等成分, 可以获取患者泌尿系统健康状况信息, 对泌尿系统相关疾病的诊断至关重要。 然而, 目前尿沉渣结晶的识别主要依赖于医师在显微镜下观察, 存在费时费力、 主观性强、 准确性不足等问题。 基于图像分析技术的显微尿沉渣图像自动分析研究备受关注, 但该类方法仅依赖形态信息对结晶样本进行分类, 对于形态相似的结晶样本难以区分、 分类准确率低。 将显微高光谱成像技术引入到尿沉渣结晶样本的分析中, 使用自主研发的显微高光谱成像系统, 获取尿沉渣结晶样本的显微高光谱图像数据并进行分析识别。 获取了包括草酸钙、 胱氨酸、 磷酸钙、 尿酸以及三联磷酸盐五类尿沉渣结晶样本的显微高光谱数据。 在该数据集上训练了支持向量机(SVM)、 K最邻近(KNN)、 决策树(DT)以及神经网络(NN)四种机器学习分类器模型, 对五类尿沉渣结晶样本进行分类。 SVM、 KNN、 DT和NN分类器的五类尿沉渣结晶分类准确率分别达到了0.959 8, 0.959 8、 0.982 9以及0.991 7。 研究结果表明, 将显微高光谱成像技术用于尿沉渣样本的分析, 不仅可以获得尿沉渣结晶样本空间信息, 还能提取具有判别性特征的光谱信息, 从而可以辅助医生进行尿沉渣结晶分类, 为尿沉渣自动化镜检提供了一种新的方法和思路。
, CHEN Jun
The analysis of urine components, called urine sediment, is paramount in clinical practice. By observing particles, cells, and crystals in urine sediment, doctors can obtain important information about the patient's urogenital health, which is crucial for diagnosing urogenital-related ailments. However, identifying urine sediment crystals heavily relies on medical professionals' manual observation under a microscope, which is time-consuming, subjective, and often inaccurate. Consequently, automated microscopic urine sediment image analysis using image analysis technology has gained significant attention. However, these methods rely solely on morphological information to classify crystal samples, making distinguishing between morphology-similar crystals difficult, resulting in low classification accuracy. Microscopic hyperspectral imaging technology integrates spatial and spectral information, revealing distinct spectral characteristics as different substances exhibit varying degrees of light absorption and scattering across different spectral bands. In this study, we introduced microscopic hyperspectral imaging technology to analyze urine sediment crystal samples and used a self-developed microscopic hyperspectral imaging system to acquire hyperspectral images. We collected microscopic hyperspectral image data of five urine sediment crystal sample types, including calcium oxalate, cystine, calcium phosphate, uric acid, and triple phosphate. Additionally, we trained four machine learning classifiers support vector machine (SVM), k-nearest neighbors (KNN), decision tree (DT), and neural network(NN) models on this dataset to classify the five types of urine sediment crystal samples. The classification accuracies of SVM, KNN, DT, and NN models for the five types of urine sediment crystals reached 0.959 8, 0.959 8, 0.982 9, and 0.991 7, respectively. Our research indicates that applying microscopic hyperspectral imaging technology to urine sediment sample analysis enables the acquisition of spatial information and facilitates the extraction of discriminative spectral features, thereby assisting physicians in microscopic examination and supporting the popularization of urine sediment microscopy techniques.
尿常规[1]是医院常规检查项目之一, 也是泌尿系统相关疾病诊断的首选检查项目, 主要包括干化学分析和尿液有形成分分析等。 传统尿液有形成分(尿沉渣)的分析主要由医疗技术人员在显微镜下对尿液样本中的成分进行观察、 识别和分析, 给出尿样中的成分和含量报告。 医疗技术人员通过观察尿沉渣中的颗粒、 细胞和结晶等成分, 可以获取关于患者泌尿系统健康状况的重要信息, 对于肾脏疾病、 尿路感染、 结石形成等泌尿系统相关疾病的诊断和监测至关重要, 在临床中具有重要的意义。 然而, 目前基于显微镜观察和人工识别的尿沉渣结晶识别方法, 依赖于实验室技师的经验和专业知识, 存在费时费力、 主观性强、 准确性不高的问题。 因此, 实现尿沉渣镜检的自动化[2, 3]已经成为当前医学和临床的重要研究方向之一。
随着计算机辅助诊断技术和图形图像处理技术的发展, 自动分析尿沉渣结晶显微图像成为可能。 该类方法通常运用传统的手工设计特征提取方法和深度学习方法, 提取尿沉渣结晶图像的空间特征, 以实现尿沉渣结晶的分类。 程星等[4]提出改进K均值的方法, 对预处理后的尿沉渣图像进行边缘提取和分割; Ji等[5]收集了30万张尿沉渣图像数据集, 提出了一种结合区域特征提取算法的卷积神经网络用于尿沉渣类型识别。 但是, 基于传统特征提取方法的尿沉渣结晶识别精度低, 基于深度学习的方法则依赖大量的人工标注数据用于训练, 且可解释性差。 此外, 尿沉渣结晶的显微图像通常具有成分复杂、 散焦模糊、 局部粘连密集等特点, 且有些同类结晶形态差异大、 不同类结晶形态差异小, 给尿沉渣结晶类型的识别带来困难。 因此, 仅通过尿沉渣结晶图像的空间形态和纹理特征来识别尿沉渣结晶类型具有一定的挑战性。
光谱分析通过测量物质在不同波段或频率的光谱响应来研究其结构、 组成和性质, 已经广泛应用于遥感、 地质勘测、 水质分析、 农业以及工业生产等领域[6]。 目前, 光谱检测技术也已经应用于尿液相关样本的检测中。 例如, Tamoš aitytė 等[7]利用红外光谱对尿沉渣进行了分析, 通过对尿沉渣样本进行非侵入式的光谱分析, 可以在结石形成的早期发现结石, 并区分尿液中的固体药物颗粒; Day等[8]将傅里叶变换红外光谱用于临床肾结石分析中, 并基于人工智能算法分析肾结石的成分和百分比; Durdagi等[9]利用能量色散X射线荧光光谱仪研究肾结石样品中的元素分布, 确定尿结石的组成成分。 然而, 现有研究仅局限于对样本的单点光谱测量, 无法对显微镜下的尿沉渣样本区域进行统计分析。 显微高光谱成像技术[10]将光谱技术与生物显微镜相结合, 能够对微小生物样本区域进行高光谱成像, 同时提取微观尺度的空间信息和光谱信息。 该技术目前已在医学样本分析中取得了初步成功, 如食源性致病菌种的识别[11]、 人体血细胞(不同种类的白细胞)的分类[12]、 胆管癌的癌症组织切片分割[13]等。 这些研究表明, 加入光谱信息可以提升生物样本的识别准确率[18], 解决了仅依靠空间信息难以分辨生物组织样本类别的问题。 但是, 将显微高光谱成像技术应用于尿沉渣结晶的识别分析研究还不多见。
本研究将显微高光谱成像技术引入尿沉渣结晶样本识别任务中, 利用具有判别性特征的光谱信息辅助尿沉渣结晶样本的显微图像区域分析识别。 以尿沉渣结晶样本为研究对象, 利用实验室自主搭建的显微高光谱成像系统, 采集了五类尿沉渣结晶样本的显微高光谱图像数据立方体, 提取了尿沉渣结晶样本的光谱特征, 并使用机器学习算法对不同种类的尿沉渣结晶样本进行分类, 实现了尿沉渣结晶样本的显微高光谱数据快速分析。
尿沉渣结晶样本数据的采集使用了实验室自主搭建的显微高光谱成像系统(microscopy hyperspectral imaging system, MHIS)。 该显微高光谱成像系统的结构如图1所示。 显微成像系统主要包括以下组成部分: 卤素灯光源, 显微镜(备有10x、 20x和40x放大倍数的物镜), 用于采集彩色图像的彩色相机, 用于采集高光谱图像的灰度相机, 声光可调滤波器(acousto-optic tunable filter, AOTF)及其驱动器, 载物台驱动器和计算机。 该显微高光谱成像系统同时配备有实验室自主研发的控制软件, 采用凝采式原理进行显微高光谱成像。
 | 图1 显微高光谱成像系统(MHIS)(a)框图与(b)实物图Fig.1 Scheme diagram (a) and photo (b) of the Microscopy Hyperspectral Imaging System (MHIS) |
用于实验的尿液样本由上海市第六人民医院提供。 尿沉渣样本的显微高光谱图像数据采集流程如下: 首先, 使用吸管吸取定量的尿沉渣样本滴在载玻片上, 待尿液样本静止后, 盖上盖玻片, 并将其放置在载物台上。 随后, 启动配套的操作软件, 设置采集参数。 本实验的成像参数具体设置值如表1所示: 物镜倍数40x, 波段范围400~800 nm, 曝光时间150 ms, 采集波段数为60, 单视场像元数为2 048× 2 448, 高光谱图像数据采用波段序列BSQ文件格式保存, 彩色图像文件采用JPEG文件格式保存。 接着, 由专业的医师使用载物台控制器移动样本, 在目镜下寻找目标尿沉渣结晶所在的区域, 并进行对焦。 完成对焦后, 对尿沉渣结晶进行拍摄和保存。 在采集过程中, 卤素灯光源的光透过放置在载物台上的样本后进入物镜, 然后到达比例分光器。 其中一路进入彩色相机, 用于采集彩色图像; 另一路到达AOTF, 并通过AOTF驱动器在狭窄的波段上切换波长, 实现单波段成像, 经过连续采集获取尿液显微高光谱图像数据。
| 表1 尿结晶样本成像参数设置 Table 1 Acquisition parameters for urine sediment crystalline samples |
本实验中收集到的尿沉渣结晶样本主要包括以下五类: 草酸钙结晶(Calcium Oxalate, CaC2O4, 在显微镜下呈无色方形、 闪烁发光的八面体), 胱氨酸结晶(Cystine, C6H12N2O4S2, 呈无色六角形片状结晶), 磷酸盐结晶(Calcium Phosphate Tribasic, Ca3(PO4)2, 呈屋顶形或楞柱形, 有时可呈羊齿草叶形), 尿酸结晶(Uric Acid, C5H4N4O3, 在显微镜下为黄色或暗红色, 呈菱形、 三菱形、 长方形、 斜方形等形状), 以及三联磷酸盐结晶(triple phosphate crystals, 多呈刺球形或不规则形)。 图2为五类典型尿结晶样本在400x显微镜下放大的示例图, 从图中可以看出, 尽管大多数结晶有固定的形态特征, 但存在一些结晶的形态特征相近、 颜色差异较小的情况, 这直接影响了从彩色图像中分析结晶形态和进行自动分类的准确程度。
 | 图2 尿沉渣结晶样本显微图像 (a): 草酸钙; (b): 胱氨酸; (c): 磷酸钙; (d): 尿酸; (e): 三联磷酸盐Fig.2 Microscopic images of urine sediments crystalline samples (a): Calcium oxalate; (b): Cystine; (c): Calcium phosphate tribasic; (d): Uric acid; (e): Triple phosphate crystals |
由于在采集过程中, 光谱容易受到光源、 暗电流、 电压等因素的影响, 因此需要对采集到的原始显微高光谱图像进行预处理, 以获取反应样本真实光谱特征的数据。 我们将采集到的尿结晶样本的原始显微高光谱图像表示为Iraw∈ Rh× w× c; 在尿结晶样本的显微高光谱图像采集过程中, 同时会采集空白区域的样本, 记作Iblank, 用于数据预处理。
由于本实验中搭建的显微高光谱成像系统采用透射光, 高光谱图像中的像素值反应的物理意义为光的透过程度。 根据透过率公式对采集到的高光谱图像数据进行预处理
使用空白图像Iblank对原始图像Iraw进行预处理后, 得到的显微高光谱图像可以反应样本的真实光谱特征Ipre。 本实验还对显微高光谱数据进行线性函数归一化操作, 将线性变换应用到原始数据上, 以确保原始数据的范围在[0, 1]之间。 线性函数归一化的公式如式(2)
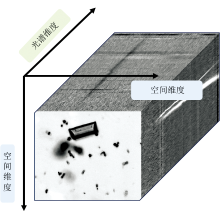
式(2)中, Imin、 Imax分别为数据集中像素点的最小值和最大值, 而Ised则代表完成线性归一化后的输出高光谱数据。 如图3所示为预处理后的尿沉渣结晶显微高光谱图像数据示意图(以三联磷酸盐结晶为例)。 本实验收集的显微高光谱数据是兼具空间维度信息和光谱维度信息的三维数据立方体, 为后续尿沉渣结晶样本分析提供了丰富的图谱信息。
 | 图3 尿结晶样本的显微高光谱数据立方体(以三联磷酸盐结晶为例)Fig.3 Microscopic hyperspectral data cube of urine sediment crystalline samples (taking Phosphatic crystals as an example) |
1.3.1 方法
机器学习[14]方法旨在从训练样本数据中学习知识, 建立模型, 以完成对应测试数据的分类和预测任务。 基于尿沉渣显微高光谱影像数据特点, 选用了机器学习中的四种常用分类算法— — KNN算法(K nearest neighbors, KNN)[15]、 支持向量机(support vector machine, SVM)[16]、 决策树(decision tree, DT)[17]和神经网络(neural network, NN)[19], 训练五类尿沉渣结晶样本的分类识别模型。
KNN算法[13]是简单易用的非参数分类算法, 通过计算测试样本与训练样本集中所有数据的距离, 选取距离最近的K个样本, 以出现次数最多的类别作为分类结果。 KNN算法中的距离度量定义为$L_{p}\left(x_{i}, x_{j}\right)=\left(\sum_{i=1}^{n}\left(x_{i}-x_{j}\right)^{p}\right)^{\frac{1}{p}}$, 在本实验中, 设定p=2, 即采用欧式距离(Euclidean distance)。 邻居数量K值是KNN算法的一个重要超参数, 在本实验中, 通过网格搜索策略寻找最佳模型参数, 我们选择了K=5。 支持向量机SVM[14]算法通过使用核函数将原始数据映射到更高维度的空间, 从而使得数据在新的空间中线性可分。 鉴于本实验需要对五类结晶进行分类, 我们采用了扩展的多分类支持向量机。 多分类支持向量机可以通过成对分类法或一类对余类等策略实现, 在高维空间中构建多个超平面用于分类。 通过网格搜索模型的最佳超参数, SVM超参数设置如下: 正则化项C设置为1, 采用高斯径向基函数核, 采用一类对余类策略实现多分类支持向量机。 决策树DT[15]模拟了人类决策过程中的决策树结构, 决策树由节点和边组成, 其构建过程包括: 从所有特征中选择一个特征, 使得在该特征上对数据进行分割能够带来最大的信息增益或最小的不纯度; 根据所选特征的值将数据集分割成子集; 构建递归子树, 对每个子集重复上述两个步骤, 直到满足停止条件为止, 即达到预设的树的深度或节点中的样本数量少于某个阈值。 该算法能够捕捉数据中的非线性关系, 并在构建过程中自动选择特征。 我们选择不纯度计算方法为信息熵, 并将分枝中的随机模式设置为30。 神经网络NN[19]是一种受人脑结构启发的机器学习模型, 由大量节点(或神经元)组成, 节点间通过加权的方式相互连结, 通过前向传播、 计算损失函数、 反向传播、 参数更新的方私迭代训练。 多层感知机(multi-layer perceptron, MLP)是一种经典的神经网络模型, 在图像分类、 文本预测等任务中有出色的表现。 通过网格筛选超参数, 训练了层数为4的多层感知机用于五类尿结晶分类, 隐藏层大小分别为256、 128、 64和32, 采用ReLU激活函数, 使用Adam优化器并设置初始学习率为0.001, 迭代训练了200轮。
1.3.2 评价指标
为了比较上述四种算法对于五类尿沉渣结晶样本光谱的分类能力, 使用了以下多分类评价指标:
假设类别i的准确率、 精准度、 召回率、 F1-score分别为Accuracy, Precisioni, Recalli, F1i, 它们的计算公式分别为式(3)— 式(6)
$Accuracy=\frac{TP}{\ \ \ TP+TN+FP+FN \ \ \ \ \ }$(3)
$Precisio{{n}_{i}}=\frac{T{{P}_{i}}}{T{{P}_{i}}+F{{P}_{i}} \ \ \ }$(4)
$Recal{{l}_{i}}=\frac{T{{P}_{i}}}{T{{P}_{i}}+F{{N}_{i}} \ \ \ }$(5)
$F{{1}_{i}}=\frac{2\times Precisio{{n}_{i}}\times Recal{{l}_{i}} \ \ \ \ \ \ }{Precisio{{n}_{i}}+Recal{{l}_{i}} \ \ \ }$(6)
式(3)— 式(6)中, TP(true positive)、 FP(false positive)、 TN(true negative)和FN(false negative)分别代表真阳性、 假阳性、 真阴性和假阴性。 准确率Accuracyi衡量了模型正确分类的样本占总样本的比例, 召回率Recalli是真阳性样本占模型预测为阳性的样本的概率, 精度Precisioni是预测为阳性的样本中真阳性样本所占的比例, 而F1i分数则综合考虑了精度Precisioni和召回率Recalli两个参数。
在计算每一类样本评价指标的基础上, 引入了加权平均指标来综合评价模型在所有类别上的表现。 精度和召回率的加权平均指标的定义如式(7)和式(8)
$Precisio{{n}_{w}}=\frac{\mathop{\sum }_{i=1}^{L}Precisio{{n}_{i}}\times {{w}_{i}} \ \ }{\left| L \right|}$(7)
$Recal{{l}_{w}}=\frac{\mathop{\sum }_{i=1}^{L}Recal{{l}_{i}}\times {{w}_{i}} \ \ }{\left| L \right|}$(8)
式(7)和式(8)中, wi为类别i的占所有样本的比例, L为类别数。
F1分数的加权平均指标定义为
$F{{1}_{w}}=\frac{2\times Precisio{{n}_{w}}\times Recal{{l}_{w}} \ \ \ }{Precisio{{n}_{w}}+Recal{{l}_{w}} \ \ \ }$
加权平均指标能够考虑到类别不均衡的情况, 从而缓解由于类别不均衡而导致的评价指标偏差。
共收集了25例尿沉渣结晶的显微高光谱图像数据, 每类结晶各五例。 显微高光谱图像数据的大小为2 048× 2 448× 60, 且每个显微高光谱数据中均包含有多个结晶感兴趣区域。 经过对原始数据进行预处理, 提取了显微高光谱数据中的结晶样本感兴趣区域(region of interest, ROI)。 平均每类样本在感兴趣区域内提取了约10 000条典型光谱曲线, 用以构建尿沉渣结晶样本光谱数据集。 按照7∶ 3划分了训练集和测试集, 训练集中包含五类结晶样本约7 000条光谱曲线, 用于构建分类模型; 测试集包含约3 000条曲线, 独立于训练集, 不参与分类器的训练, 用于预测和计算评价指标。
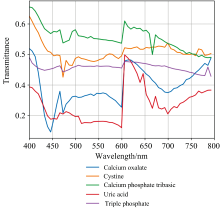
为了初步分析五类尿沉渣结晶的光谱, 我们计算了所选感兴趣区域内各类尿结晶样本的平均光谱, 并绘制了光谱曲线。 如图4所示, 展示了不同种类的尿沉渣结晶样本在400~800 nm波段下的60个波段的平均光谱曲线图。 由于显微高光谱成像系统采用透射光进行成像, 物质对某一波段的吸收越强, 表现在光谱曲线上的值约小。 该光谱曲线图显示, 五类尿沉渣结晶在吸收峰、 谷波波段上各自呈现不同特征, 而在相似趋势的波段上吸收强度存在较大差异, 在光谱曲线上表现出明显的差异。 例如, 草酸钙在第8和第11波段(470 nm)处对光有明显的吸收, 在第31波段(600 nm)处存在大波动; 胱氨酸对11波段(470 nm)附近的光有轻微吸收, 在其他波段上无明显变化; 三联磷酸盐在本实验的成像区域中无明显的特征波段; 磷酸钙在10波段(470 nm)和40波段(664 nm)处有明显的吸收, 在第30波段(600 nm)附近透过较强; 尿酸的光谱特征波段与磷酸钙相似, 但在光谱曲线透过强度和波动趋势上有较大差异。 差异性的光谱信息有助于尿沉渣结晶的类型分析识别。
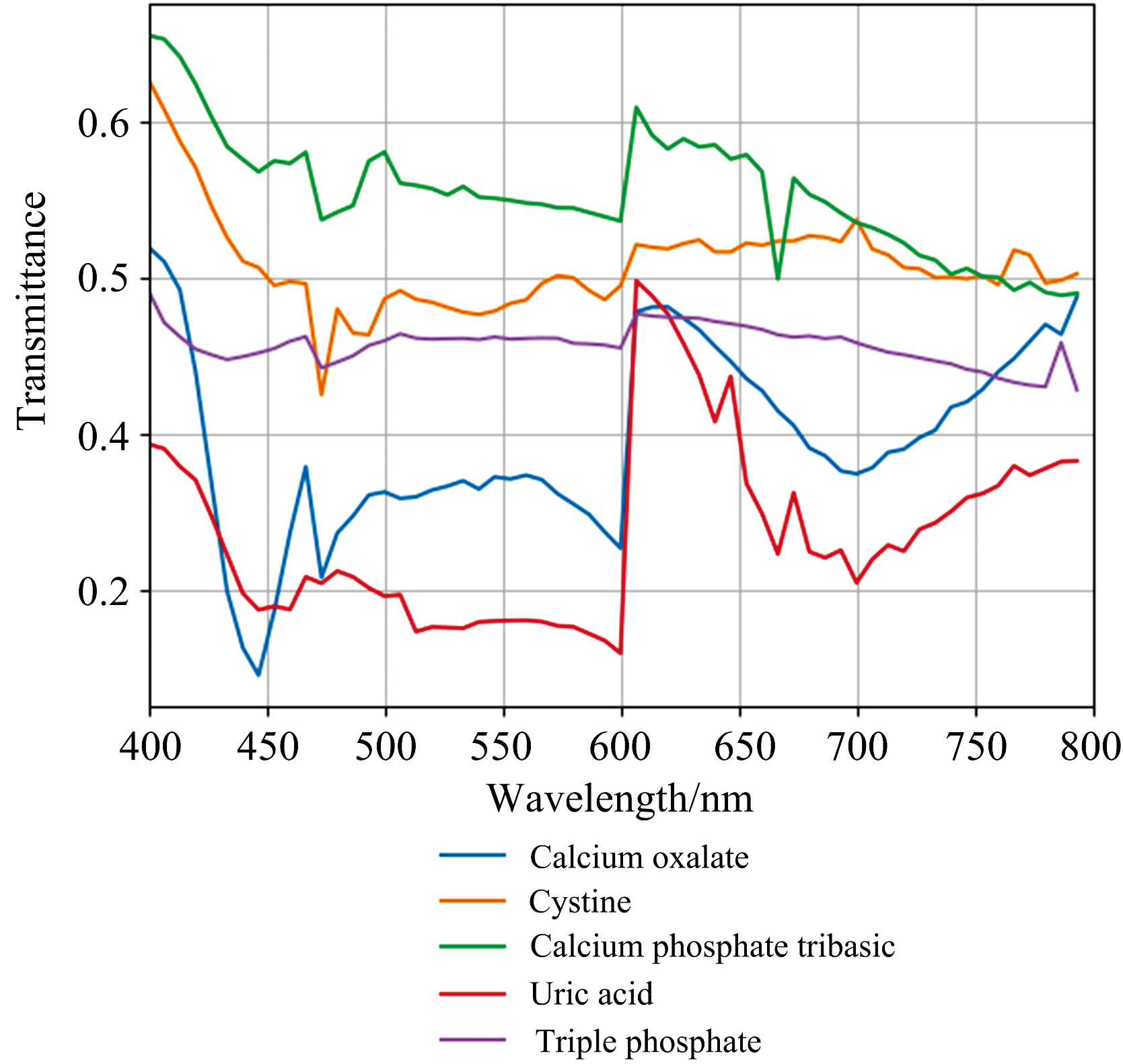 | 图4 五类尿沉渣结晶样本的光谱曲线图Fig.4 Spectra of five types of urine sediment crystalline samples |
使用1.3方法与评估中所描述的机器学习方法训练模型对五类尿结晶样本进行分类, 以验证尿沉渣结晶的光谱信息具有区分性。 表2总结了SVM、 KNN、 DT和NN算法在尿沉渣结晶分类上的各项加权平均指标, SVM、 KNN、 DT和NN算法在尿沉渣结晶数据集上分类的准确率分别可以达到0.959 8、 0.959 8、 0.982 9和0.991 7, 精准率分别可以达到0.960 5、 0.974 7、 0.982 9以及0.991 8, 召回率分别可以达到0.969 8、 0.972 3、 0.982 9和0.991 7, F1分数分别可以达到0.96、 0.972 5、 0.982 8和0.991 7。 基于神经网络的算法通过大量参数学习, 在五类尿结晶样本的分类中性能最好。 不同的机器学习方法构建的分类器均能对尿沉渣结晶样本的光谱信息进行较高准确率的分类, 实现五类尿沉渣结晶的分类。
| 表2 SVM、 KNN、 DT和NN算法在尿沉渣结晶样本检测中的加权平均评估指标 Table 2 Weighted average evaluation metrics of SVM, KNN, DT and NN algorithms for the classification of urine sediment crystalline samples |
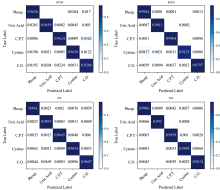
表3给出了SVM、 KNN、 DT和NN算法在每类样本上的准确率、 召回率和F1-score, 同时也计算了这四种分类模型在五类样本上的平均指标。 平均精准率超过了0.93, 平均召回率达到了0.95以上, F1分数达到了0.95以上。 模型对于三联磷酸盐结晶的识别度性能较差, 在尿酸、 磷酸钙和胱氨酸防面的识别性能较好。 图5是四种分类模型的混淆矩阵。 行代表实际类别, 列代表模型预测的类别; 混淆矩阵的对角线则表示正确分类的比例, 非对角线处的数值表示错误分类的比例, 即模型将某一类别错误地预测为另一类别的情况。 混淆矩阵中对角线颜色越深, 表示模型性能越好。 观察混淆矩阵可以发现, 草酸钙结晶被错误分类成其他结晶成分的概率较高, 这表明模型在识别草酸钙样本方面的性能较差。 同时, 通过平均光谱曲线的分布也可以观察到, 草酸钙结晶的曲线与其他结晶成分的曲线重叠较多、 分辨度较差。
| 表3 SVM、 KNN、 DT和NN分类器对五类尿沉渣结晶样本分类的性能评估评价指标 Table 3 Performance evaluation metrics of SVM, KNN, DT and NN algorithms for the classification of five types of urine sediment crystalline samples |
 | 图5 SVM、 KNN、 DT和NN算法的混淆矩阵Fig.5 Confusion matrices for SVM, KNN and DT and NN algorithms |
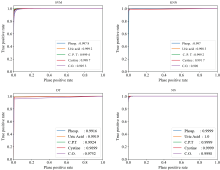
ROC(receiver operating characteristic)曲线是一种用于评估分类模型性能的工具曲线, 它展示了分类器在不同阈值下的真阳率TPR(true positive rate)和假阳率FPR(false positive rate)之间的关系。 ROC曲线下面积(area under ROC, AUROC)用于量化ROC曲线的性能, AUROC值越接近1表示模型性能越好。 如图6所示为四种分类模型对每类样本分类的ROC曲线, SVM、 KNN、 DT和NN算法的AUROC分别达到了0.998 1、 0.996 9、 0.990 0以及0.999 9。
 | 图6 SVM、 KNN、 DT和NN算法的ROC曲线Fig.6 ROC Curves for SVM, KNN, DT and NN algorithms |
针对尿沉渣人工镜检费时费力, 而基于传统图像的分析方法准确度低的问题, 研究将显微高光谱成像技术用于尿沉渣结晶的识别和分类。 使用自主搭建的显微高光谱成像系统采集了五类尿沉渣结晶样本的显微高光谱数据。 由于尿沉渣结晶样本的显微高光谱图像数据不仅可以提供空间信息, 还可以提供光谱维度的信息, 因此在机器学习识别算法支持下, 有助于提高尿沉渣结晶的识别精度。 为了验证光谱信息的加入对提高识别尿沉渣结晶的作用, 选择了5类尿沉渣结晶样本类型包括草酸钙、 胱氨酸、 尿酸、 磷酸钙和三联磷酸盐作为研究对象, 提取了不同类型的尿沉渣结晶的典型光谱曲线。 通过分析光谱曲线特征可以发现, 不同类型的结晶样本在吸收峰谷和亮度分布上存在较大的差异。 采用四种机器学习分类模型SVM、 KNN、 DT和NN对5类尿结晶样本进行了分类。 实验结果表明, 神经网络算法的性能最佳, 对五种尿沉渣结晶样本的平均分类准确率达到了99.17%。 通过对分类结果进行可视化分析, 发现光谱信息可以作为尿沉渣结晶类型判断的重要依据。 现有的研究工作仅针对自研的显微高光谱成像系统获取的尿结晶光谱进行了分析, 存在部分谱段噪声大的问题; 在未来的工作中, 我们会改进成像系统、 提升信噪比, 获取质量更高的光谱信息; 我们也将进一步拓宽显微高光谱成像系统的光谱范围至红外波段, 以获取更丰富的光谱特征进而提升检测效果。
综上所述, 显微高光谱成像技术是一种有效且灵敏的检测尿沉渣结晶化学成分的方法。 将显微高光谱成像技术引入尿沉渣结晶的检验中, 光谱信息的加入有助于弥补空间信息的不足, 提高尿液沉渣结晶样本分析的准确率, 从而为尿沉渣结晶检测的自动化普及提供一种新的方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|