{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于高光谱成像结合机器学习的半夏饮片鉴别
[李若彤1  , 胡会强
, 胡会强2 , 曹诗宇1 , 卢孟瑶1 , 刘梦然1 , 付嘉玥1 , 毛晓波2 , 王海波3, * , 符玲1, 3, * ]
, 胡会强, 曹诗宇, 符玲]
|
|


作者简介: 李若彤, 1999年生,郑州大学药学院硕士研究生 e-mail: liruotongg@gs.zzu.edu.cn;胡会强, 1998年生,郑州大学电气工程学院博士研究生 e-mail: huhuiqiang@163.com;李若彤,胡会强:并列第一作者
《中国药典》2020版关于“半夏”项下收载有: 生半夏、 清半夏、 姜半夏和法半夏四种饮片。 由于它们的外形相似、 气味特征小, 在生产管理、 市场流通以及临床使用中极易混淆。 常规化学检测受限于仪器试剂, 且步骤繁琐, 因此非常有必要探索建立一种准确、 快速、 无损的半夏饮片检测方法。 尝试采用高光谱成像技术结合机器学习对四种半夏饮片进行了鉴别。 采用主成分分析法(PCA)对高光谱数据进行特征提取, 并基于全波段数据模型建立了支持向量机(SVM)、 逻辑回归(LR)、 多层感知机(MLP)、 随机森林(RF)四种分类模型; 通过四种分类模型对半夏饮片的训练集准确率和测试集准确率进行了考查, 对四种模型在最佳性能下主成分占比进行了分析; 此外, 还对四种半夏饮片的高光谱数据进行了可视化降维分析(t-SNE)。 基于PCA构建的SVM、 LR、 MLP和RF四种分类模型均能实现对四种半夏饮片的精准鉴别, 其测试集精度分别为80.76%、 96.45%、 96.59%、 86.77%, 其主成分占比分别为60%、 80%、 70%、 80%。 t-SNE可视化降维分析结果说明了姜半夏和清半夏比较接近, 和生半夏相比, 成分有部分改变; 法半夏经过炮制后, 化学成分变化较大, 和其他三种饮片差异非常明显。 四种半夏的平均光谱反射率结果也与此一致。 该研究首次将高光谱成像技术结合机器学习应用于半夏饮片预测建模, 实现了准确、 快速、 无损鉴别, 为其生产流通、 临床正确使用提供了新的鉴别方法和科学依据。
, HU Hui-qiang, CAO Shi-yuAuthor: LI Ruo-tong and HU Hui-qiang: joint first authors
There are four kinds of decoction pieces for Pinelliae Rhizoma, namely Pinelliae Rhizoma, Pinelliae Rhizoma praeparatum cum alumine, Pinelliae Rhizoma praeparatum cum zingibere et alumine, and Pinelliae Rhizoma praeparatum, recorded in the current Chinese Pharmacopoeia (2020 edition). Due to their similar appearance and weak odor characteristics, it's easy to confuse their manufacturing management, market circulation, and clinical application. Because of the requirement for instruments, reagents, and intricate detection steps, exploring and establishing an accurate, rapid, and non-destructive detection method for Pinelliae Rhizoma decoction pieces is necessary.This paper used hyperspectral imaging combined with machine learning to identify the four kinds of Pinelliae Rhizom adecoction pieces. The principal component analysis (PCA) was utilized to extract features from the hyperspectral data, and support vector machine (SVM), logistic regression (LR), multi-layer perceptron (MLP), and random forest (RF) classification models were established based on the full-band data model. The accuracy of both training and test sets of four classification models was evaluated, along with an analysis ofthe principal component proportion of the four models under optimal performance. Additionally, the t-distributed stochastic neighbor embedding (t-SNE)visual dimensionality reduction analysiswas conducted on the hyperspectral data of the fourkinds of decoction pieces. The SVM, LR, MLP, and RF classification models based on PCA can achieve accurate identification for PinelliaeRhizoma decoction pieces. The accuracy of the test set is 80.76%, 96.45%, 96.59%, and 86.77%; in addition, the proportion of principal components is 60%, 80%, 70%, and 80%, respectively. The t-SNE analysis by dimensionality reduction showed that the components of Pinelliae Rhizoma praeparatum cum zingibere et alumine and Pinelliae Rhizoma praeparatum cum alumine were relatively close and partly changed compared with Pinelliae Rhizoma. However, the chemical composition of Pinelliae Rhizoma praeparatum changed greatly after processing, which was very different from the above three kinds of decoction pieces. These results also agree with the average spectral reflectance result. It's the first application of hyperspectral imaging combined with machine learning to develop a predictive model for different decoction pieces of Pinelliae Rhizoma. This approach -successfully identifies Pinelliae Rhizoma decoction pieces accurately, rapidly, and non-destructively, thereby providing a novel identification method and scientific foundation for these products' rational production, circulation, and clinical application.
半夏饮片来自天南星科植物半夏Pinellia tetnata (Thb.) Breit.的干燥块茎[1]。 作为临床常用中药, 始载于《神农本草经》。 其功效广泛, 药理作用丰富, 止咳化痰疗效确切, 有“ 化痰圣药” 之称。 生半夏味辛, 性温, 有毒。 因此, 历代医药书籍中均有许多关于半夏炮制方法的记载。 现行2020版《中国药典》一部收录生半夏、 法半夏、 姜半夏、 清半夏四种饮片。 其中, 清半夏经白矾炮制后, 增加燥湿化痰的功效; 姜半夏中出现了新成分6-姜辣素, 增加了姜半夏温中止呕、 镇咳的功效; 法半夏增加了甘草酸铵、 甘草苷, 消除半夏麻辣感, 还可协调半夏的祛痰、 止咳作用, 扩大了该药的临床用药范围。 目前常用半夏饮片的鉴别方法, 有性状观察、 薄层鉴别、 色谱法[2, 3]等。 上述方法存在主观性强, 需要借助过程繁琐的试剂和仪器分析, 同时还有损耗样本较多等问题。 因此, 如何开发一种精准、 快速、 无损鉴别半夏饮片的方法, 对于该药的生产、 流通和临床应用具有重要意义。
高光谱成像(hyperspectral image, HSI)技术可以将光谱与图像相结合, 获得图像中每个像素的光源信息, 是一种可以捕获和分析空间区域内逐点光谱的精细技术, 能够同时获取物体内部与表面信息, 因此HSI可以检测到视觉上无法区分的物质[4]。
近年来, 高光谱成像技术不断深入发展, 在农业、 食品、 生物医学、 地质、 航天和环境等领域应用越来越多, 如对棉花种子的质量筛选[5]; 对地面物体大范围快速精细识别和自然资源勘查、 碳排放监测和地表异常等监测[6]及文物保护[7]等。 作为先进的检测手段, 高光谱成像技术以其准确、 快速、 无损、 无污染的特点成为各领域共同关注的焦点。 高光谱技术在中药材及饮片领域的应用, 目前有对中药葛根生长年限检测[8]; 对中药易混淆品种如杏仁、 桃仁的鉴别[9]; 对栀子[10]、 甘草[11]的产地鉴别; 对西洋参皂苷的含量检测等[12]。
本工作首次利用高光谱成像技术结合机器学习对半夏饮片进行快速、 精准、 无损鉴别, 主要内容包括: (1)采用标准正态变换对半夏的四种饮片高光谱数据进行预处理; (2)选用主成分分析法对预处理后的数据进行特征提取; (3)基于全波段数据和主成分分析(principal component analysis, PCA)降维后的数据分别建立了支持向量机(support vector machines, SVM)、 逻辑回归(logistic regression, LR)、 多层感知机(multi-layer perceptron, MLP)、 随机森林(random forest, RF)四种分类模型, 并在此基础上分析了实验结果; (4)探讨不同主成分占比对四种分类模型整体性能的影响。 本方法建立的高光谱识别模型, 实现了半夏饮片的快速、 无损鉴定, 为其生产、 流通和应用提供了可靠的借鉴, 为下一步开发能够直接应用于实践的饮片智能识别设备提供了参考。
半夏饮片样品来自甘肃省山绛县, 由郑州大学药学院从产地收集, 符玲副教授鉴定确认为天南星科半夏Pinellia tetnata (Thb.) Breit.的干燥块茎, 并统一干燥保存。 饮片总数为400片, 每种饮片按照4∶ 1的比例划分为训练集和测试集(见表1)。
| 表1 半夏不同饮片的训练集和测试集数 Table 1 Sample numbers of training and test sets for different types of Pinelliae Rhizoma decoction pieces |
实验用高光谱成像设备为HySpex系列高光谱成像光谱仪(Norsk Elektro Optikk AS), 其组成主要由2个卤钨灯、 CCD探测仪以及SN0605 VNIR与N3124 SWIR两个镜头、 移动平台、 仪器自带计算机与内置软件。 在采集半夏样品的高光谱数据时, 高光谱成像仪的镜头与半夏样品的距离为25 cm, 平台移动速度为1.5 mm· s-1。 高光谱成像系统的SN0605 VNIR镜头的积分时间为9 000 μ s, 帧时间为25 500 μ s, 光谱仪的光谱范围: 410~990 nm, 波段间隔为5.37 nm, 总共108个波段; N3124 SWIR镜头积分时间为3 500 μ s, 帧时间66 482。 光谱仪的光谱范围为949~2 513 nm, 波段间隔为5.43 nm, 总共288个波段。 本实验使用的光谱范围为: 949~2 513 nm。
在光谱采集过程中, 由于暗电流和不稳定光源对数据的影响, 需要利用黑白板校正对采集图像进行校正。 首先利用系统自带的RAD校正软件对采集到的高光谱数据进行校正, 消除高光谱成像系统对样品高光谱数据的影响, 得到半夏四种饮片的原始高光谱数据。 随后对该数据进行黑白板校正, 用于消除空气以及环境对原始高光谱图像的影响, 得到清晰、 不变形的校正后高光谱数据。 校正公式如式(1)所示
式(1)中, In为样本的相对反射率, Ir为样本的原始光谱反射率, Id为黑板光谱反射率, Iw为白板光谱反射率。
针对校正后高光谱数据, 通过ENVI 5.3提取感兴趣区域(region of interest, ROI), 使样品与背景分离。 本实验采用棋盘法对半夏不同饮片的高光谱图像进行提取, 其中每个ROI内相对反射率的平均值作为一个样本。 具体采样情况如表2。
| 表2 四种半夏饮片的ROI数量 Table 2 The quantities of ROI of four kinds of Pinelliae Rhizoma decoction pieces |
由于高光谱采集过程中易产生随机噪声, 需要进行光谱预处理以降低样品背景和形态差异等影响。 常见的高光谱预处理方法有: 标准正态变量变换(standard normal variate transformation, SNV)[13]、 乘法散射校正(multiplicative scatter correction, MSC)[14]、 Savitzky-Golay (SG)平滑[15]、 一阶导数[16]、 二阶导数[17]等多种方法。
Savitzky-Golay (SG)平滑预处理是一种常用于信号处理和数据分析的技术, 主要用于平滑数据曲线以减少噪音和提取趋势信息。 其基本思想是使用窗口滑动在数据上进行局部多项式拟合。 具体来说, 该方法将一个滑动窗口(通常是奇数大小的窗口)在数据上移动, 并在每个窗口内使用多项式进行拟合。 这个多项式的次数和窗口的大小是可以调整的参数。 通过在每个窗口内进行拟合, SG平滑可以有效地去除高频噪音, 同时保留数据的整体趋势。 本工作选择SG平滑对半夏高光谱数据进行预处理。 对于给定的数据序列yi, SG平滑的输出
$\hat{y}_{i}=\sum_{j=-k}^{k} c_{j} y_{i+j}$(2)
式(2)中, k是滑动窗口半宽度, 而系数cj则是通过最小二乘法确定的多项式系数。
中药高光谱数据量大, 且波段之间相关度非常高, 因此需要进行特征提取, 即采用合适方法来提取尽可能数量较少的特征, 用来表征尽可能多的光谱有用信息, 以去除原始光谱数据的冗余现象, 保证后期模型识别的准确性和运算的效率。
在对高光谱进行特征提取时, 可以从光谱降维和图像特征两个角度来考虑, 常用的光谱降维方法有: 主成分分析算法(principal component analysis, PCA)、 独立成分分析(independent component analysis, ICA)、 连续投影算法(successive projections algorithm, SPA)、 线性判别分析(linear discriminant analysis, LDA)、 回归系数法(regression coefficient, RC)等; 常用的图像特征包括中药图像的形状特征、 纹理特征和颜色特征[18, 19]。
采取PCA对半夏饮片高光谱数据进行特征提取。 PCA的原理如下:
(1)设光谱数据为X=M× N的矩阵, 其中M表示样本数, N表示特征维度;
(2)对X进行标准化后, 计算协方差矩阵C, 然后对C进行特征值分解: C=VΛ VT, 其中V是特征向量矩阵, Λ 是对角矩阵, 其对角线上的元素是特征值。
(3)选择前k个特征值对应的特征向量组成矩阵W, 将数据集X投影到新的空间中Y=XW
Y是降维后的数据矩阵。 通过选择合适的k, 即保留的主成分数目, 可以实现对数据的降维。
采用支持向量机、 逻辑回归、 随机森林、 多层感知机建立分类模型, 比较不同半夏炮制品的分类准确率。 实验随机将总她据集划分为训练集(90%)和测试集(10%)。
1.7.1 支持向量机
支持向量机(support vector machine, SVM)是一种利用超平面对样本进行分类的方法, 遵循结构风险最小化原则[20]。 具有运算时间短、 泛化能力强等优点, 被广泛应用于求解非线性问题, 在光谱数据分析中十分有效[21]。 SVM的学习策略为间隔最大化, 通过训练集的间隔最大化得到一个最优分离超平面, 可形式化为求解凸二次规划的最优化结果[22]。 对于线性不可分的问题, 需引入合适的核函数, 通过构造一个非线性映射, 将样本从低维映射到高维的特征空间以求解最佳的分割曲面。 核函数的选取影响SVM的性能, 若选择不合适, 可能导致模型的效果不佳。 常用的核函数有线性核、 多项式核、 高斯核、 拉普拉斯核、 Sigmoid核等。 本实验分类模型SVM使用高斯核函数。
1.7.2 逻辑回归
逻辑回归(logistic regression, LR)是一种广义的线性回归分析模型, 主要通过最大似然估计寻找模型的最佳拟合参数来获得良好的鉴别效果。 LR模型简单, 速度快, 易于理解, 泛化能力强, 被广泛应用于各种实际问题。 对LR模型一般采用L1范式和L2范式来防止模型过拟合。 本实验基于LR构建模型选择的正则化参数为L2, 损失函数的优化算法选择坐标下降法(liblinear), 算法收敛最大迭代次数为200。
1.7.3 多层感知机
多层感知机(multi-layer perceptron, MLP)是机器学习中常用的分类模型, 具有高度的自适应和较强鲁棒性, 能很好地解决模式识别等相关问题[23]。 使用MLP处理分类问题时, 主要任务为找到合适的权重使损失函数最小化, 常见的优化方法有梯度下降法、 拟牛顿法等。 本研究使用的多层感知机模型为单隐层神经网络, 由输入层、 隐藏层、 输出层构成, 以反向传播的监督学习算法进行训练。 其中隐藏层的神经元个数为500, 隐藏层的激活函数选择relu函数, 权重优化的求解器选择adam, 初始学习率为0.001, 最大迭代次数为500。
1.7.4 随机森林
随机森林(random forest, RF)是基于决策树的集成学习算法, 在解决回归和分类问题时具有良好的识别能力[24]。 近年来随着高光谱成像技术的发展, 随机森林算法也逐步被应用于解决该领域的各类问题。 随机森林的主要参数有决策树的数量、 决策树的最大深度, 叶子的最小样本数等。 本实验基于RF建模时, 决策树的数量和最大深度分别设为200和40。
分类模型构建完成后, 需要对模型的效果进行评估。 为了直观地判断模型优劣, 采用预测精度(Accuracy)作为模型评桔标准。 如式(3)所示
式(3)中, TP、 TN、 FP、 FN分别表示真正例, 即正样本被预测为正样本的数量; 真负例, 即负样本被预测为负样本的数量; 假正例, 即负样本被预测为正本的数量; 假负例, 即正样本被预测为负样本的数量。
使用ENVI5.3软件实现半夏高光谱图像数据可视化, 原始数据的预处理和样本的采集借助MATLAB2018b完成, 最终的实验环境则由Python3.7软件实现。 为了避免实验的偶然性, 实验的所有结果均为30次独立运行平均值。
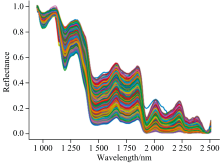
按照1.3中所述方法对高光谱数据进行校正后, 按照1.4中方法对半夏四种饮片进行采样, 得到样本的光谱曲线如图1。 其中每条曲线代表一个样本。 从图1中可知四种半夏饮片的光谱反射率趋势大致相同, 难以对其区分。
 | 图1 四种半夏饮片的原始光谱曲线Fig.1 The original spectra of four kinds of Pinelliae Rhizoma decoction pieces |
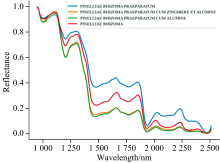
为了清晰地比较半夏不同饮片之间的区别, 分别对四种样本求平均, 得到的光谱曲线如图2所示, 每条代表一个样本的平均光谱曲线。 从图2中能直观的看出半夏不同饮片的平均光谱反射率存在差别, 其中蓝色代表法半夏, 橘色代表姜半夏, 绿色代表清半夏, 红色代表生半夏, 四种半夏饮片的平均光谱反射率大小为: 法半夏> 生半夏> 姜半夏≈ 清半夏, 法半夏和其他三种半夏饮片的差别较大, 生半夏其次, 姜半夏和清半夏比较接近, 这说明四种半夏饮片的光谱特征存在差异, 基于高光谱成像技术对其饮片品种进行鉴别是一种可行手段。
 | 图2 四种半夏饮片的ROI平均光谱曲线Fig.2 Average spectra of ROI for four kinds of Pinelliae Rhizoma decoction pieces |
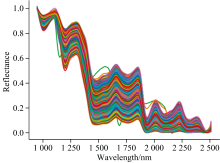
采用Savitzky-Golay (SG) 平滑法为光谱数据预处理, 经过SG预处理后的光谱曲线如图3所示, 经SG处理后, 能有效消除光谱散射和漫反射的影响, 减少各种干扰信息。
 | 图3 SG预处理后的四种半夏饮片光谱曲线图Fig.3 SG pretreated spectra of four kinds of Pinelliae Rhizoma decoction pieces |
为验证PCA对高光谱数据降维的有效性, 首先基于对全波段数据进行建模。 将预处理后的光谱数据作为输入变量, 分别导入四种分类模型中(SVM、 LR、 MLP、 RF), 建模结果如表3所示。 波段范围为949~2 513 nm, 四种模型的测试集准确率分别为80.76%、 96.45%、 96.59%、 86.77%。 由此可见, 在处理全波段数据时, MLP模型的准确率最高, 相较于其他三种模型具有更好的性能; 然而, 从整体的分类精度来看, 基于全波段建立的模型仍然有较大的提升空间, 因此在2.4节基于PCA构建半夏饮片的分类模型。
| 表3 半夏饮片在不同分类模型下的准确率(%) Table 3 Accuracies of different classification models for Pinelliae Rhizoma decoction pieces (%) |
PCA是一种具有最大可分性的线性变换方法, 通常用于将高维、 强相关的数据转换为低维的表示。 在高光谱数据分析中, 通过矩阵变换, PCA能够提取数据中的主成分, 即和目标最相关的数据, 从而实现降维。 在本实验中选择主成分分析(PCA)作为处理不同半夏饮片高光谱数据的方法, 旨在优化数据表示, 提高预测精度, 并更好地理解不同样本之间的变化趋势。
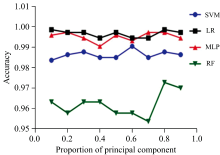
在PCA分析中, 主成分的保留比例是一个至关重要的参数, 其选择直接影响分类模型的性能。 如果该比例设置得太小, 将导致大部分有效特征被剔除, 可能损失关键信息; 反之, 如果设置得太大, 无关变量的存在可能直接降低模型的预测精度。 因此, 我们分析和讨论了PCA参数对各种分类模型的影响。 这有助于确定最优的主成分保留比例, 以优化模型性能, 并提高对不同半夏饮片的分类准确性。 仔细的调整PCA参数, 旨在实现在特定问题背景下更为有效的数据降维和特征提取。 基于PCA分别建立SVM、 LR、 MLP、 RF四种机器学习分类模型, 结果如图4所示。
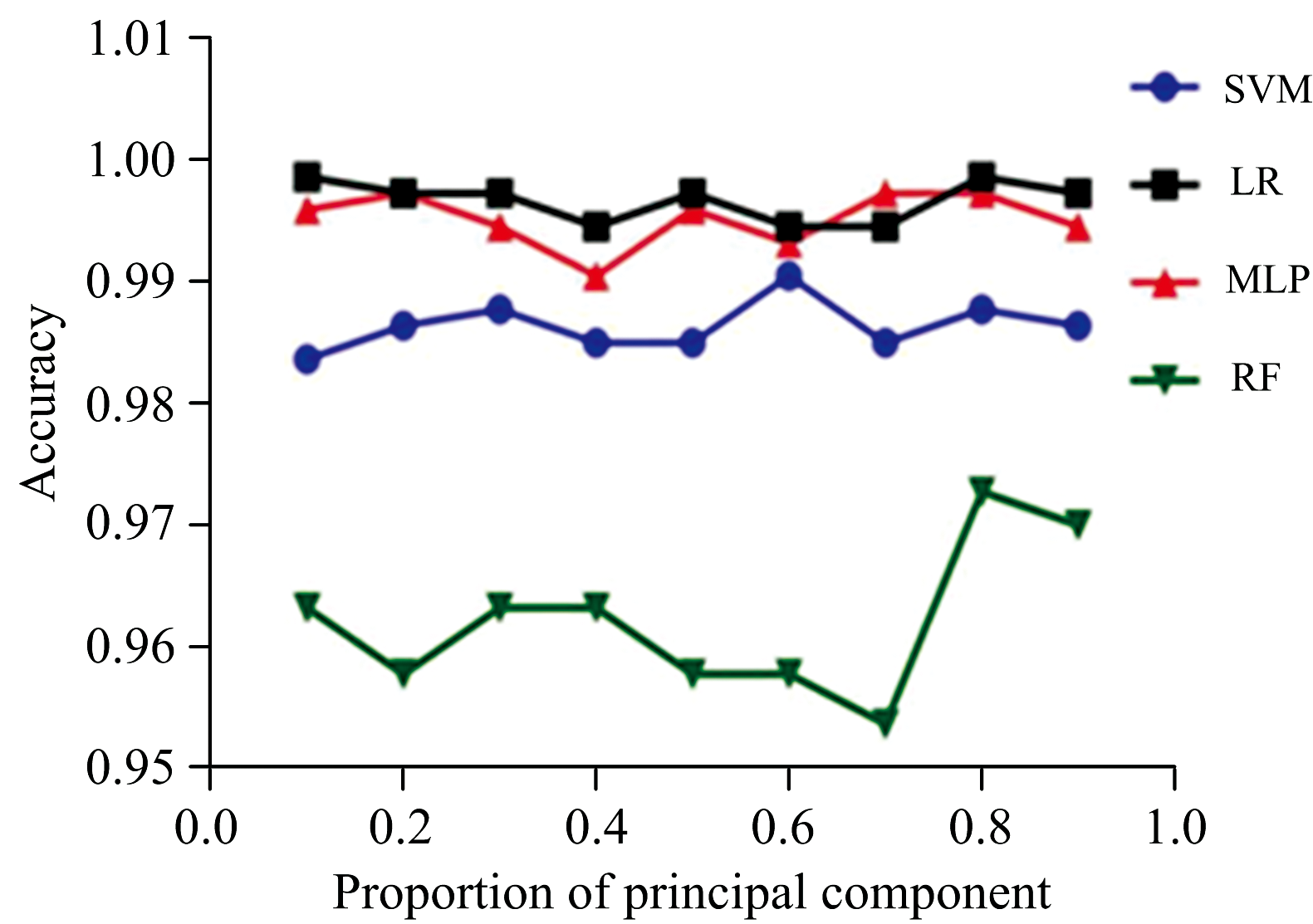 | 图4 不同分类模型的预测精度随主成分占比增加的趋势Fig.4 The prediction accuracies trend of different classification models with the increased proportion of principal components |
结果表明, 基于PCA降维后的四种机器学习分类方法都可以对半夏四种饮片进行较好的分类, 测试集的准确性均超过95%以上, 在四种方法中LR法和MLP法的准确度不仅最高, 且非常一致; SVM法的准确度其次, RF法的准确度最低。 因此, 采用主成分分析方法对不同半夏饮片的高光谱数据降维后, 采用LR和MLP法进行后续的机器学习预测结果较好, 其平均预测集的结果分别为99.65%和99.51%。
此外, 采用主成分分析的结果还表明, 选取适当的主成分比例对于各模型的性能具有显著影响。 在实验中, 我们观察到当主成分比例设置得过小时, 各分类模型的性能普遍下降, 因为关键信息被丢失, 导致模型难以捕捉数据的重要特征。 表4列出了四种分类模型在最佳性能下所占主成分比例, 结果表明, 不同模型在取得最佳性能时, 所对应的主成分比例均偏高。 因此, 选择合适的主成分比例是至关重要的, 这确保了模型在降维的同时仍然保留了足够的有用信息, 以更好地预测样本的分类。
| 表4 基于PCA降维后不同分类模型的最高准确率(%) Table 4 The best accuracies of different classification models based on dimensionality reduction by PCA (%) |
t-SNE(t-distributed stochastic neighbor embedding)全称叫做t分布式随机邻域嵌入。 该算法是一种非线性技术, 主要用于数据探索和可视化高维数据。 t-SNE可以提供和展示数据如何在高维空间中排列的感觉或直觉, 即点之间的相似度。
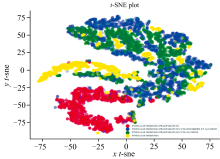
对四种半夏饮片进行可视化t-SNE降维分析结果如图5所示: 蓝色代表姜半夏, 绿色代表清半夏, 黄色代表生半夏, 红色代表法半夏。 从图中可以看到, 蓝色和绿色区域基本重合, 黄色和蓝色和绿色有部分重合, 而红色和其他颜色几乎没有重合的交集。 这个结果也进一步说明了姜半夏和清半夏这两种饮片比较接近, 和生半夏相比, 这两种炮制品的表面特征以及内部成分有部分改变; 法半夏经过炮制后, 变化较大, 和以上三种饮片相差非常明显。 这个结果和前面图2半夏不同饮片的平均光谱反射率结果是一致的。
 | 图5 四种半夏饮片的可视化t-SNE降维分析结果Fig.5 Visualizing data using t-SNE dimension reduction analysis for the four kinds of Pinelliae Rhizoma decoction pieces |
将高光谱成像技术和主成分分析法结合, 建立四种机器学习模型, 能够准确的鉴别四种半夏饮片。 由于红外光谱和饮片化学成分具有较强的对应性, 基于四种饮片的原始光谱反射率和t-SNE可视化降维分析结果, 均说明了姜半夏和清半夏在化学成分上具有高度的重合性, 生半夏和此二种炮制品的成分有部分相同, 但是法半夏和其他三种半夏饮片的化学成分相差较远。 这种差异不仅和半夏饮片的表面特征以及内在成分密切相关, 也和其炮制方法和工艺直接相关。
经高光谱成像系统采集半夏不同饮片样本数据, 采用SG预处理方法去除干扰因素, 选用主成分分析方法(PCA)获取样品的特征光谱信息, 最后比较 SVM、 LR、 MLP、 RF四种分类模型的效果。 结果表明, 基于400~1 000 nm全波段范围的数据, 建立的MLP模型效果最好, 预测精度分别为训练集为97.24%, 测试集为96.59%; 基于PCA构建的四种模型效果均高于数据模型, 其中LR、 MLP分类模型的综合表现最佳, 其相对较少的主成分就能达到最高的准确率。
实验结果表明高光谱成像技术结合机器学习算法可以实现对四种常用的半夏饮片的精准鉴别。 未来将进一步研究如何优化模型, 同时改进硬件设施, 将获得稳定、 准确的模型并植入便携式设备中, 实现对不同半夏饮片的快速、 无损的工业化检测, 为半夏饮片的加工和炮制, 以及临床应用提供理论依据与方法。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|