

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Sigmoid函数归一化的多光谱指数特征在油茶林遥感识别和样本迁移研究中的应用
[章海亮1  , 王宇
, 王宇1 , 胡梅3 , 张译之1 , 张晶1 , 詹白勺1 , 刘雪梅2, * , 罗微1, * ]
, 王宇, 罗微]
|
|


作者简介: 章海亮, 1977年生, 华东交通大学电气与自动化工程学院教授 e-mail: hailiang.zhang@163.com
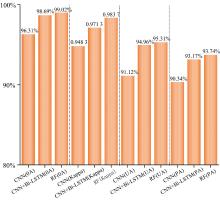
遥感影像分析中, 多光谱指数特征的归一化处理对于提高分类精度和模型的泛化能力至关重要。 采用Google Earth Engine (GEE) 平台, 以Sentinel-1 SAR雷达遥感影像和Sentinel-2 A光学遥感影像为数据源, 通过计算纹理特征、 地形特征、 极化特征和Sigmoid函数归一化前后的多光谱指数特征构建不同的分类场景, 采用随机森林、 梯度提升树、 支持向量机和朴素贝叶斯4种机器学习分类器进行分类实验, 分析对光谱指数特征进行归一化处理是否有利于油茶林识别。 将构建的卷积神经网络(CNN)和结合Bi-LSTM模块的深度学习模型与机器学习分类器进行比较, 分析不同模型对油茶林识别效果。 以吉安市2021年五种土地类型样本点为基础, 将适合油茶林识别的分类场景应用到不同年份(2019年、 2020年、 2022年、 2023年)的样本迁移中, 分析各年份油茶林面积增量与空间分布。 结果表明, 归一化后的光谱指数特征与随机森林相结合对油茶林识别精度最高, 整体精度(OA)为99.02%, Kappa系数为0.9837, 油茶林用户精度(UA)为95.31%, 油茶林生产者精度(PA)为93.74%; 研究中CNN系列的深度学习模型对油茶林识别精度略低于随机森林分类器, 其中结合Bi-LSTM模块的深度学习模型的整体精度(OA)为98.69%, Kappa系数为0.971 3油茶林用户精度(UA)为94.96%, 油茶林生产者精度(PA)为93.17%; 2021年吉安市油茶林种植面积达184.488 1万亩, 其中遂川县占27.67%, 为面积最大县; 油茶林种植分布由地势高向地势低递减, 种植地点多位于家庭农户附近的山坡地和自留地, 油茶林种植面积逐年增加。 研究所提出的油茶林提取方法能够为实现油茶林动态监测与管理提供帮助, 所提出的样本迁移方法能有效减少样本采集和标注成本。
, WANG Yu, LUO Wei
In remote sensingimage analysis, the normalization process of multispectral index features is crucial to improve the model's classification accuracy and generalization ability. This paper was based on the Google Earth Engine (GEE) platform, Sentinel-1 SAR radar remote sensing images and Sentinel-2 A optical remote sensing images were used as the data sources, and different classification scenarios were constructed by calculating the multispectral exponential features before and after the normalization of the texture features, topographic features, polarization features, Sigmoid function, and employing four machine learning classifiers, namely, Random Forest, Gradient Boosting Tree, Support Vector Machine and Simple Bayes which were used to conduct classification experiments to analyze whether normalization of spectral index features was beneficial to the recognition of Camellia oleifera forests. Subsequently, the constructed convolutional neural network (CNN) and deep learning model combined with the Bi-LSTM module were compared with the machine learning classifiers to analyze the effect of different models on Camellia oleifera forest recognition. Based on the sample points of five land types in Ji'an City in 2021, the classification scenarios suitable for Camellia oleifera forest recognition were applied to the sample migration in different years (2019, 2020, 2022, 2023) to analyze the incremental and spatial distribution of Camellia oleifera forest area in each year. The results show that the normalized spectral index feature combined with random forest achieve the highest recognition accuracy in identifying Camellia oleifera forests, with an overall accuracy (OA) of 99.02%, a Kappa coefficient of 0.983 7, a user accuracy (UA) of 95.31% for Camellia oleifera forests, and a producer accuracy (PA) of 93.74% for Camellia oleifera forests; The deep learning model of CNN series in the study has slightly lower accuracy than random forest classifier for Camellia oleifera forests recognition, in which the overall accuracy (OA) of the deep learning model combined with the Bi-LSTM module is 98.69%, the Kappa coefficient is 0.971 3 The user accuracy (UA) of the Camellia oleifera forests is 94.96%, and the producer accuracy (PA) of the Camellia oleifera forests is 93.17%; 2021 The planted area of Camellia oleifera forests in Ji'an reached 1 844 881 000 mu, of which Suichuan County accounted for 27.67%, the largest county in area; the distribution of Camellia oleifera forests planting decreases from high terrain to low terrain, and the planting sites are mostly located in the hillside land and self-retained land near the family farms and the planted area of Camellia oleifera forests is increasing year by year. The extraction method of Camellia oleifera forests proposed in this study can help realize the dynamic monitoring and management of Camellia oleifera forests, and the proposed sample migration method can effectively reduce the cost of sample collection and labeling.
油茶是一种我国特有且营养价值很高的经济作物, 一般生长在中国南方的山地、 丘陵和盆地的山谷地带, 含有丰富的不饱和脂肪酸, 对人体健康有益。 近年来随着人们对健康食品的需求增加和国家油茶产业发展政策的支持, 油茶种植的规模逐渐扩大。 及时准确地了解区域油茶种植的分布情况对于促进国家农业结构的多样化、 帮助农民实现增收致富等具有重要意义。 目前对于油茶种植分布情况多为人工田间调查和无人机空中摄影, 局限性大且时效性低, 难以满足当前精准、 快速获取油茶种植分布情况的实际需求[1, 2]。 随着遥感技术的不断发展和卫星遥感的不断更新, 使用遥感影像对农林进行地表分类、 大范围面积提取以及农林多年动态扩张已成为热点研究。 机器学习和深度学习算法的发展也为农作物分类提供了一种新方法[3, 4, 5, 6]。
随着遥感技术的发展和遥感数据的更新, 采用时间序列遥感影像进行农林分类、 农林产量估算以及农林多年种植结构变化分析已得到广泛的研究和应用[7, 8, 9]。 Phan[10]等采用Sentinel-2数据比较了多种分类器在土地利用覆盖分类中的性能。 Ni[11]等采用时间序列Sentinel-2数据的六个光谱指数识别了四个关键水稻生长期, 提取了2017年— 2019年东北三省水稻的时空分布信息。 冯权泷[12]等采用Sentinel主被动数据提取了黄淮海平原冬小麦的空间分布信息。 近年来有越来越多的研究利用遥感影像监测果园、 茶园和油茶林等经济林木。 徐晗泽宇[13]等通过大量Landsat数据识别了赣南地区的柑橘果园, 分析了赣南地区多年间柑橘果园的扩张动态。 杨艳魁[14]等采用高分二号数据和纹理信息提高了高分辨率数据对茶园的分类精度。 孟浩然[15]等采用光谱纹理和时序信息相结合的方法对湖南省常宁市地区的油茶林进行了遥感识别。
本工作针对油茶林遥感识别困难和遥感分类中如何简化样本数量, 以江西省吉安市为研究区域, 综合油茶林光谱特征、 纹理特征、 地形特征和极化特征, 探索Sigmoid函数归一化前后的光谱指数对油茶林遥感识别的影响程度。 采用多种机器学习分类算法(随机森林、 梯度提升树、 支持向量机和朴素贝叶斯)进行分类和精度验证, 选择最优机器学习分类算法。 将已确定的分类特征和样本数据放入卷积神经网络(convolutional neural network, CNN)和结合双向长短期记忆网络(Bi-LSTM)模块的深度学习模型进行训练和预测。 采用余弦相似度的方法对研究区内样本数据进行样本迁移, 分析油茶林种植面积变化情况。 研究得到2021年江西省吉安市油茶林种植面积和空间分布特征以及2019年至2023年研究区内油茶林种植面积变化情况。
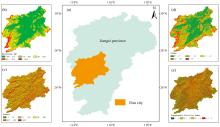
吉安市地处江西省中西部, 位于赣江中游, 主要以山地和丘陵地貌为主, 如图1(a— e)所示, 境内四季分明、 雨量充沛, 为亚热带季风气候, 年日照时数为1 600~1 800 h, 年降水量在1 400~1 600 mm之间, 年平均温度约17 ℃, 极适宜油茶树生长。 在中央财政与当地政府的鼓励下, 吉安市的油茶产业近年来得到了快速发展, 以油茶为主要经营树种的扶贫造林专业合作社超过10家, 油茶企业信息备案登记在册有19家, 油茶林已成为当地农民的重要收入来源之一。
 | 图1 研究区示意图Fig.1 Location of the study area |
选用Sentinel-1 SAR雷达遥感数据和Sentinel-2A光学遥感数据提取油茶林种植区域。 Sentinel-1 SAR是主动微波遥感卫星, 提供四种极化模式(VV、 VH、 HH、 HV), 不受天气、 光照等条件的影响, 对云层具有较强的穿透力。 Sentinel-2A是多光谱遥感卫星, 其搭载了一台多光谱成像仪, 可在13个光谱波段范围内获取图像数据, 捕捉地表的细微特征。
Sentinel-1 SAR雷达遥感数据对大气层的穿透力强, 对地面纹理特征敏感。 由于其成像方法和特点, 目标研究区域的地形会对成像产生干扰和噪声, 不利于后续油茶林分类。 本研究采用Lee滤波器对Sentinel-1 SAR中所用到的波段进行滤波。 Lee滤波器通过计算局部窗口内的平均值, 并结合每个像素点的权重系数, 实现对噪声的抑制。
Sentinel-2A光学遥感影像在进行农作物时空分布信息提取时, 由于数据量化、 传感器限制等因素, 导致图像中地物特征和边界的细节不够突出, 影响油茶林遥感识别和分类。 本研究先对Sentinel-2A光学遥感影像进行去云处理, 再采用基于梯度卷积的Sobel边缘检测算子对影像进行边缘检测处理以增强影像中的高频细节。 Sobel算子通过计算图像中每个像素点周围像素的灰度加权差检测边缘。 图2(a)为遥感影像, 图2(b)为Sobel边缘检测算子效果, 遥感影像用于对比。
 | 图2 遥感影像(a)与Sobel边缘检测算子效果图(b)Fig.2 Remote sensing image with Sobel edge detection operator effects |
采用谷歌地球专业版云平台提供的点取样方法和实地调查。 对油茶林样地进行了实地调查。 其余样地结合谷歌地球专业版在线选取并验证样本准确性, 然后导入 GEE 云平台。 在线选择过程基于多样性、 随机均匀性和可验证性原则, 以确保研究区域内样本的空间分布尽可能满足代表性和均匀性的特点。 为准确反映模型效能, 从中随机抽取70%作为训练样本, 30%作为测试样本。 研究中五种土地类型样本点信息见表1。
| 表1 样本数据集 Table 1 Sample data sets |
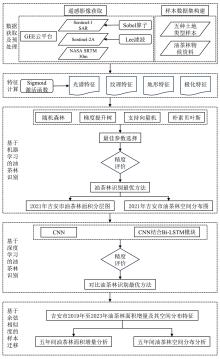
本研究技术路线图如图3所示。 首先采用GEE云平台2021年的Sentinel-1 SAR和Sentinel-2A遥感影像数据, 构建地物类型的光谱特征、 纹理特征、 地形特征和极化特征, 采用Sigmoid激活函数对光谱特征进行处理, 采用多种机器学习分类器和卷积神经网络对2021年油茶林样本点进行训练和精度验证, 并通过基于余弦相似度的样本迁移, 分析2019年至2023年的吉安市油茶林种植面积变化趋势及空间分布。
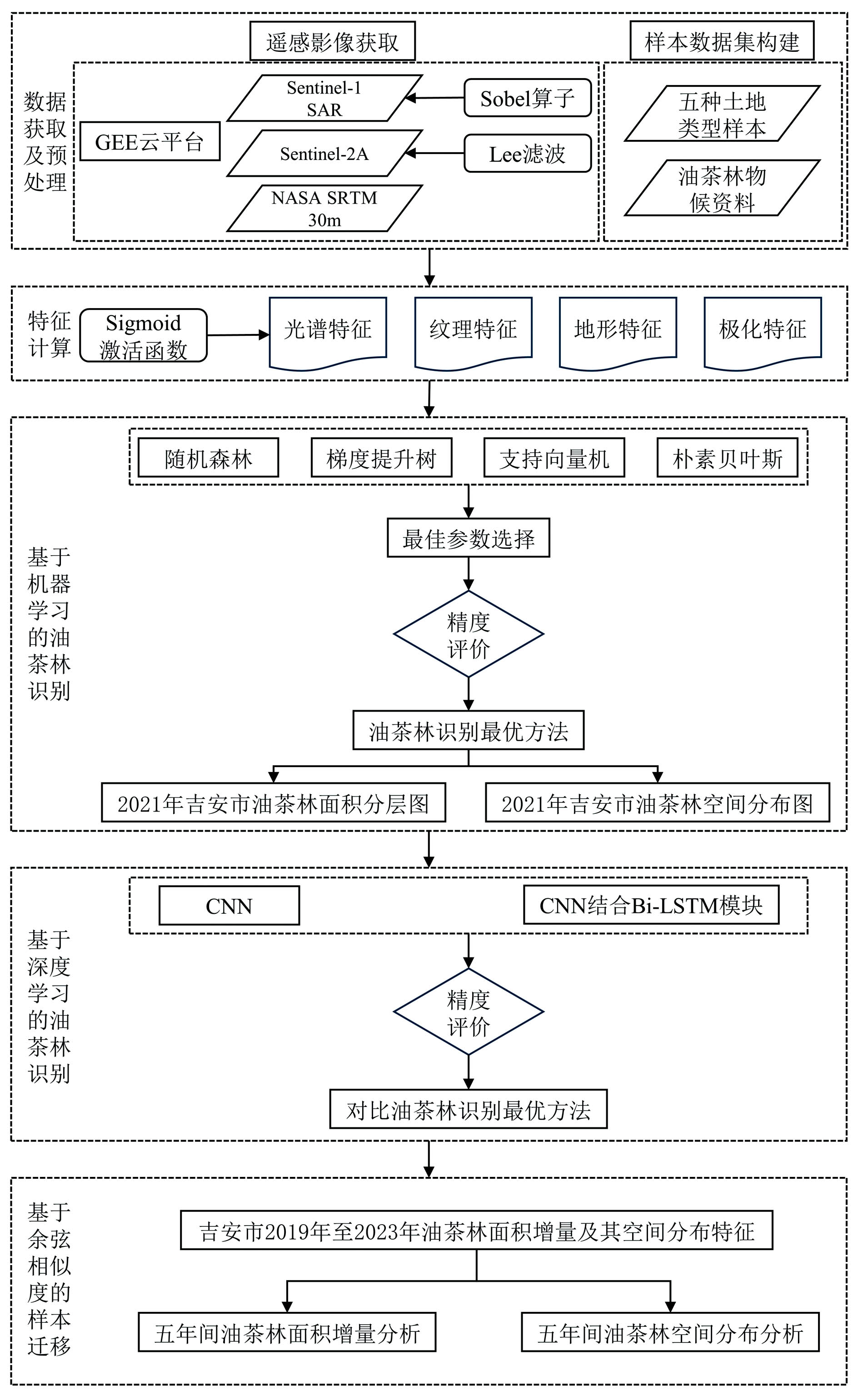 | 图3 技术路线图Fig.3 Flow chart of proposed method |
1.4.1 特征构建
使用Sentinel-1 SAR卫星的VV和VH波段构建极化特征能够提供关于地表覆盖和物理特性的重要信息。 其中VV极化表示垂直发射和垂直接收的极化方式, 主要用于表征地物散射的垂直分量, 对于具有垂直极化特征的地物具有较高的敏感度。 VH极化表示垂直发射和水平接收的极化方式, 主要用于探测地物的极化散射特性和地表的粗糙度, 能够提供更多关于地表物理特性的信息。
结合研究区的地理位置与油茶的物候期, 选取 Sentinel-2A卫星搭载的多光谱传感器获得多光谱波段数据。 通过对光谱波段数据进行数学运算或组合得到相应的指数特征, 进而构建特征集如表2所示。 归一化差值建筑指数(normalized difference built-up index, NDBBI)通过建筑材料和裸土在短波红外和近红外波段的反射差异来识别建筑区域, 用于城市扩展监测和土地利用变化检测。 土壤水分指数(soil water index, SWI)通过短波红外和近红外波段的反射差异来估算土壤水分含量, 用于农业和水资源管理中的土壤湿度监测。 大气阻抗植被指数(atmospherically resistant vegetation index, ARVI)通过使用蓝光波段对红光波段进行校正, 减少大气气溶胶的影响, 用于植被监测, 特别是在大气条件不稳定的地区。 增强型建筑与裸地指数(enhanced built-up and bareness index, EBBI)通过短波红外和红光波段的反射区分建筑物和裸土, 用于城市扩展监测和裸土识别。 水体提取指数(water extraction index, WEI)通过绿光和近红外波段的反射差异来识别水体, 用于水体监测和水资源管理。 增强型植被指数(enhanced vegetation index, EVI)增强了植被信息, 特别是在高生物量区域。 相比NDVI, EVI对大气条件和土壤背景具有更好的校正能力, 用于植被类型识别和覆盖度估算。
| 表2 光谱指数特征公式 Table 2 Spectral index characteristic formula |
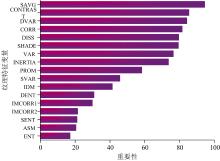
有研究表明农作物遥感分类研究仅计算光谱特征会导致“ 同物异谱、 异物同谱” 的现象, 影响最终分类效果, 而不同地物类型在遥感影像上纹理表现差异较大。 油茶林在遥感影像上具有规则的纹理信息, 易于与其他地物类型和林地进行区分。 本研究采用灰度共生矩阵(gray-level co-occurrence matrix, GLCM)进行纹理特征构建, 根据植被光谱曲线, 植被在近红外B8波段计算纹理特征能够更好地区分植被等信息。 本研究将基于B8波段计算出17个纹理特征变量进行重要性分析, 为避免信息冗余, 只选取重要性排名前4的纹理特征变量。 由图4可选取均值和(sum of averages, SAVG)、 对比度(contrast, CONTRAST)、 差异方差(difference variance, DVAR)和相关性(correlation, CORR)4个纹理特征变量。
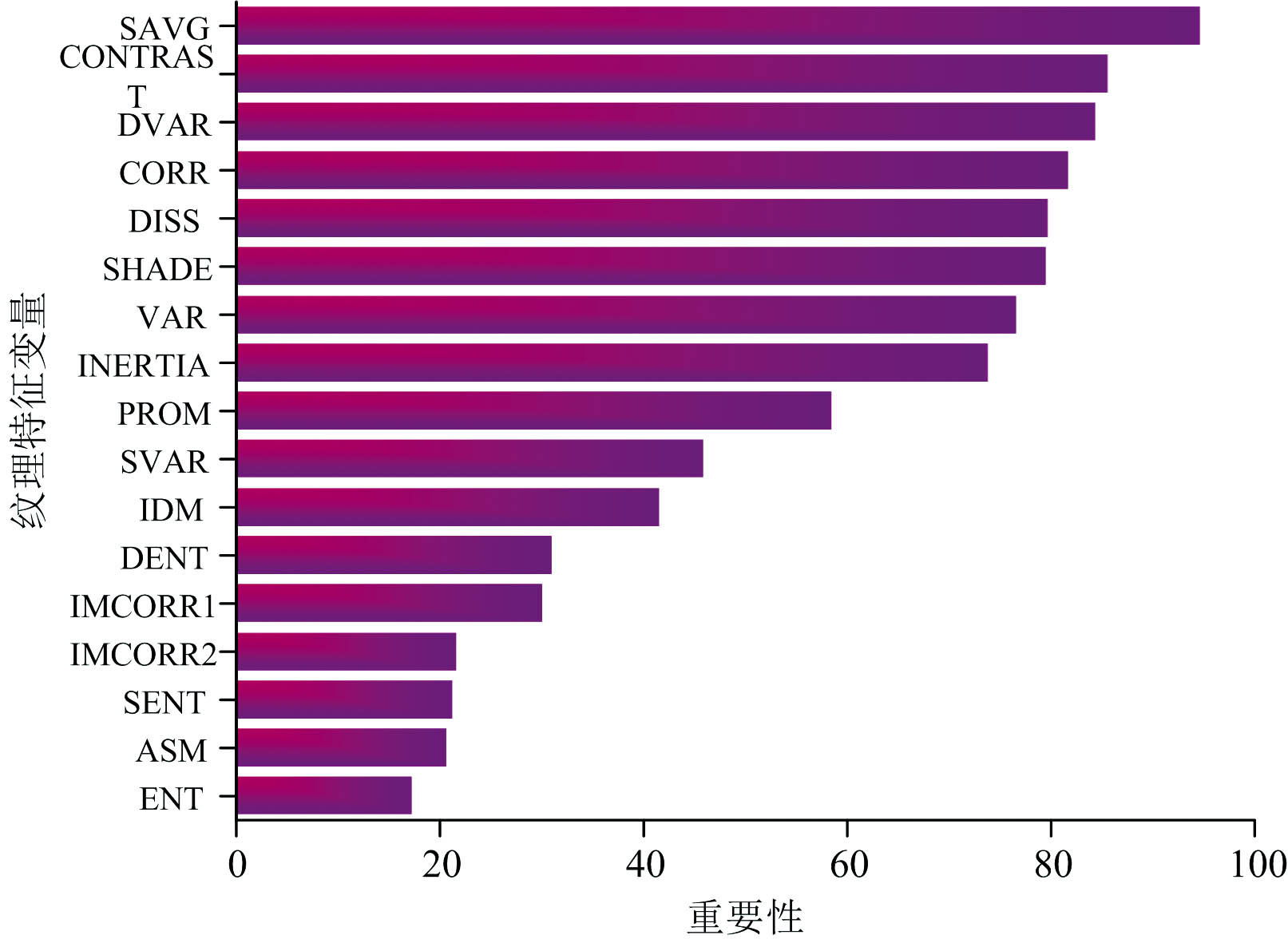 | 图4 基于B8波段的17个纹理特征变量重要性Fig.4 Importance of 17 texture feature variables based on B8 bands |
地形特征反映了地表的形态和地貌特征, 提供了更加详细的地物环境背景与地物空间分布信息。 地形特征可以作为额外的输入特征, 与遥感影像数据一起用于训练分类器, 从而改善分类器的性能。 如表3所示, 本研究所构建的地形特征有坡向(Aspect)、 坡度(Slope)、 阴影分析(Hillshade)和高程(Elevation)。 Aspect 反映了地表在水平面上的朝向, 对地形起伏和地貌特征提供了重要信息。 Slope 表示地表在水平方向上的坡度程度, 对地形起伏和地势高低提供了直观的量化描述。 Hillshade 通过模拟光照效果, 呈现了地形表面的阴影分布, 增强了地形特征的可视化效果。 Elevation 是地表的海拔高度, 提供了地形的垂直信息。
| 表3 特征变量 Table 3 Characteristic variable |
1.4.2 Sigmoid激活函数
由于不同光谱特征在特定条件下可能会产生非常大的值或非常小的值, 会造成未经归一化处理的光谱特征出现某些值域异常的特征值, 在训练过程中占据主导地位进而弱化其他正常特征值, 影响模型的训练效果。 在多光谱分析中, 不同指数的值域不同, 直接比较它们的值可能会导致误导性的结论。 本研究为解决此问题, 通过Sigmoid激活函数对研究中所用到的光谱特征进行归一化, 可以更容易地进行特征间的比较和分析, 提高模型精度。
Sigmoid激活函数适用于分类任务的输出层中, 输出值在0~1之间, 其还具有单调性、 平滑性以及中心对称性, 见式(1)
式(1)中, x是输入值, 输入的值越大, 输出值也越大。 e是自然对数的底数(约为2.718)。 通过Sigmoid激活函数将研究中所用到的光谱特征值域映射到0到1之间, 将光谱特征标准化, 在后续分析和处理时更具有可比性。
1.4.3 时间窗口选取
由于不同植被物候特征、 生长强度以及对水分条件依赖的差异, 不同植被所表现出的光谱和极化的时序特征不同。 本研究采用Sentinel-1 SAR、 Sentinel-2A数据构建包括油茶林在内的五种土地类型的光谱和极化特征以选择最合适的时间窗口提取油茶林种植范围。
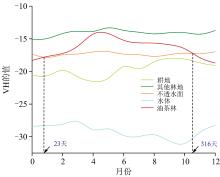
油茶对水的依赖性是识别油茶的关键特征。 因此, 研究中采用对水体敏感性较高且不受云雨天气影响的Sentinel-1 SAR VH极化特征, 用于检测土壤的湿度变化。 图5为五种土地类型在2021年的VH时间序列曲线, 图中油茶林VH时间序列曲线主要位于其他林地和不透水面之间且与不透水面有相交, 而在第23天和第316天之间, 油茶林VH时间序列曲线处于其他林地和不透水面之间且无相交。
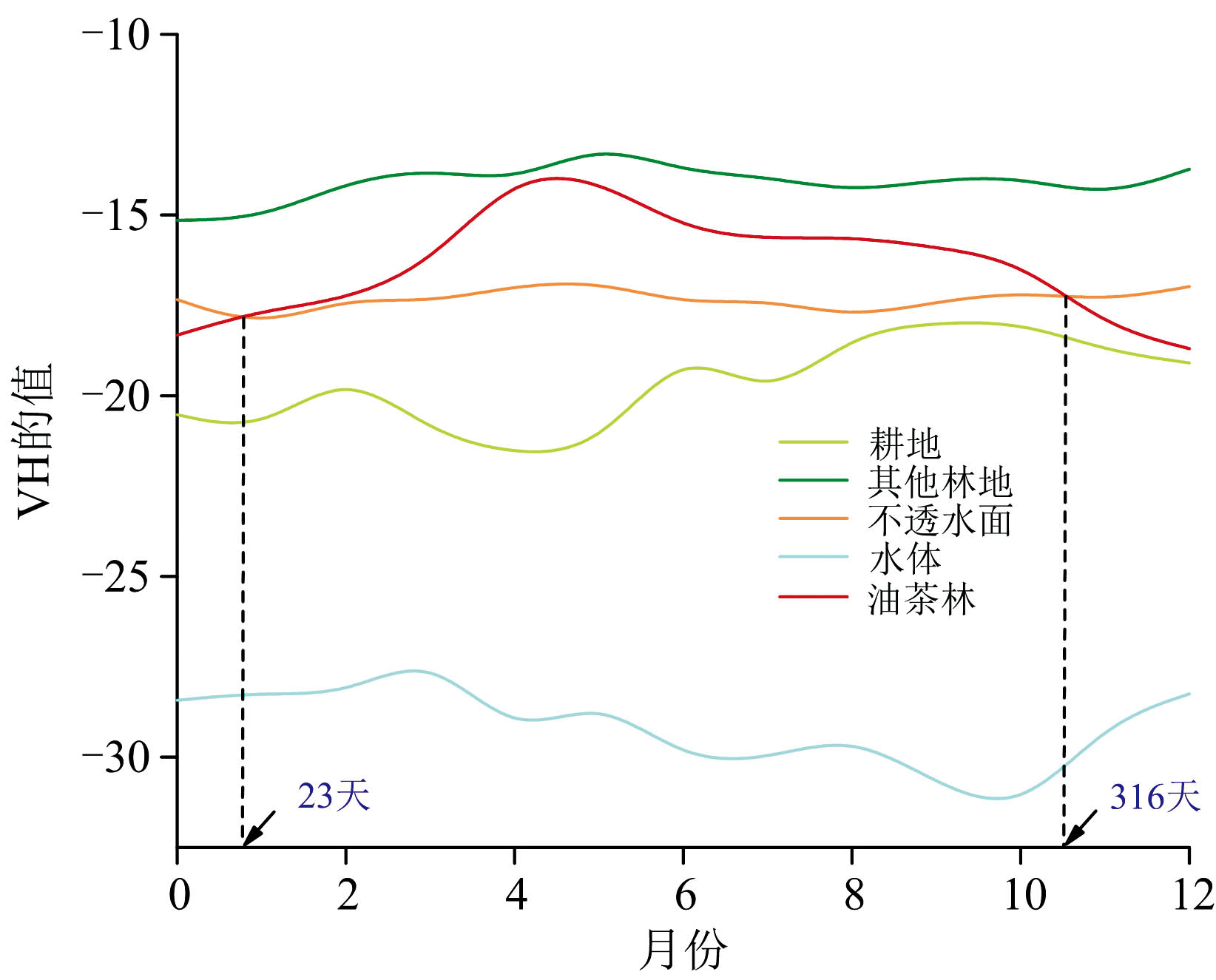 | 图5 五种土地类型的VH时间序列曲线Fig.5 VH time series curves for five land types |
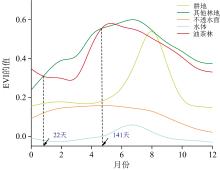
鉴于油茶生长时土壤湿度较高的特点, EVI能够有效减少土壤背景噪声的影响, 提供更准确的植被健康和生物量信息。 研究中采用EVI作为监测油茶生长变化的依据, 构建油茶林2021年EVI时间序列曲线以区分油茶林与其他植被。 图6为五种土地类型在2021年的EVI时间序列曲线, 油茶林和其他林地的EVI时间序列曲线相似且与其他林地和耕地均有相交, 而在第22天和第141天之间, 油茶林EVI时间序列曲线处于其他林地和耕地之间且无相交。
 | 图6 五种土地类型的EVI时间序列曲线Fig.6 EVI time series curves for five land types |
根据五种土地类型所提取出的2021年五种典型地物的VH和EVI时间序列曲线, 选择时间窗口为2021年的第30天到2021年的第140天来研究吉安市油茶林种植范围。 其中在提取EVI时间序列曲线时采用Sentinel-2A的QA60波段对云和卷云覆盖进行剔除以减少异常值的干扰。
1.4.4 分类算法及精度评价
在机器学习中, 随机森林(random forest, RF)集成了多棵决策树, 使随机森林在分类中具有较强的抗过拟合能力, 能够有效地降低模型的方差。 梯度提升树(gradient boosted trees, GBT)通过组合多个决策树来构建一个强大的分类模型。 支持向量机(support vector machine, SVM)的关键思想是通过最大化间隔找到决策边界。 朴素贝叶斯(Naive Bayes, NB)是一种假设特征之间是相互独立的分类算法, 通过计算给定输入数据的每个类别概率, 并选择具有最高概率类别作为预测结果。
本研究所使用的交叉验证是评估机器学习模型性能的统计方法。 通过将训练数据分成若干个互不重叠的子集, 对每个子集轮流作为验证集, 其余部分作为训练集, 反复进行模型训练和验证, 获得对模型性能更准确的评估。 所有分类完成后, 采用四种混淆指标, 包括整体精度(overall accuracy, OA)、 Kappa系数、 用户精度(user accuracy, UA), 生产者精度(producer accuracy, PA), 用于分类结果的评价, 如式(2)— 式(5)。 整体精度是五种土地类型像元被正确分类到实际真实土地类型的概率; Kappa系数的作用是综合利用混淆矩阵中的参数进行离散性多元评价分类; 用户精度的作用是查看五种土地类型像元被正确划分到指定地类的概率; 生产者精度的作用是查看五种土地类型图斑与实际分类数据类型一致的概率。
1.4.5 卷积神经网络
(1) CNN网络
采用卷积神经网络(convolutional neural network, CNN)对油茶林进行分类。 设计并训练了一个深度CNN模型, 包括多个卷积层、 池化层和全连接层。 为保证深度学习与机器学习的数据源相同, 在研究过程中将分类所构建的所有特征均从GEE中导出后再导入深度学习模型中, 避免了因数据源不同而导致的结果差异。
(2) CNN-Bi-LSTM网络
为了进一步提高分类精度, 将卷积神经网络(convolutional neural network, CNN)与双向长短期记忆网络(Bi-LSTM)结合。 Bi-LSTM能够捕捉时间序列数据的前向和后向依赖关系, 将Bi-LSTM应用于时间序列遥感数据, 可以更好地理解和利用时空动态变化。 遥感数据具有时间跨度大、 数据量大的特点。 Bi-LSTM可以处理较长时间序列, 捕捉长时间段内的变化趋势, 增强模型的预测能力。 CNN与Bi-LSTM模块结合的模型图如图7所示。
 | 图7 CNN与Bi-LSTM模块结构Fig.7 Structure of CNN and Bi-LSTM modules |
1.4.6 余弦相似度
余弦相似度是一种衡量两个向量之间相似度的度量方法, 可以用于分析两个向量的方向是否相似, 如式(6)所示。 以2021年吉安市样本点的光谱向量为基础, 通过余弦相似度分析2021年吉安市样本点是否可以用于2019年、 2020年、 2022年、 2023年, 并将适合于其他年份的样本点保留并进行分类, 不适合的样本点则舍弃。
相似度阈值是一个预定义的数值, 用于判定两个样本点之间的光谱差异。 当计算的余弦相似度值大于或等于这个阈值时, 认为两个样本点的光谱不同, 即不是同一土地类型, 反之则认为它们相似。 通过对比2019年至2023年同期遥感影像, 共选取200个土地类型未变化的样本点, 每个土地类型含40个样本点, 并对每个样本点逐年采集研究中所涉及的各光谱波段, 得到最大和最小值范围[16], 如表4所示。 结果表明, 油茶林的波动范围相对稳定, 各工地类型样本点在不同波段之间的波动范围处于0.035~0.534之间。 最终将相似度阈值的上限阈值设定为0.534。
| 表4 无土地类型变化的样本点各波段阈值信息 Table 4 Threshold information of each band for sample points without land class change |
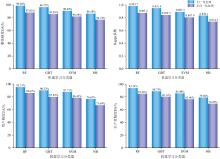
将分类场景分为两类, 一类为光谱特征经过归一化处理, 另外一类为光谱特征未经归一化处理, 两类分类场景均包含纹理特征、 地形特征和极化特征。 运用4种机器学习分类器对研究区进行油茶林识别, 得到研究区整体精度OA和Kappa系数以及油茶林用户精度UA和油茶林生产者精度PA。 由图8可知随机森林在4种机器学习分类器中对油茶林识别精度最高, 且在四种机器学习分类器中, 经过归一化后的光谱特征对油茶林识别精度明显高于未经归一化处理的光谱特征。 故本研究选用归一化光谱特征、 纹理特征、 地形特征、 极化特征和随机森林分类器作为油茶林识别最优方法来构建分类场景, 以进行后续的研究。
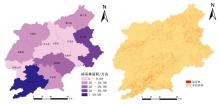
吉安市2021年油茶林面积分层图和空间分布如图9所示。 2021年吉安市油茶林总面积为184.488 1万亩, 其中被誉为“ 中国油茶之乡” 的遂川县油茶林种植面积最大, 占2021年吉安市油茶林总面积的27.67%。 种植分布呈现由地势较高向地势较低递减的趋势。 由图9可看出油茶林的种植普遍呈零散分布, 种植地点常见于家庭农户附近的山坡地和自留地, 利用土地的边缘区域进行栽培。
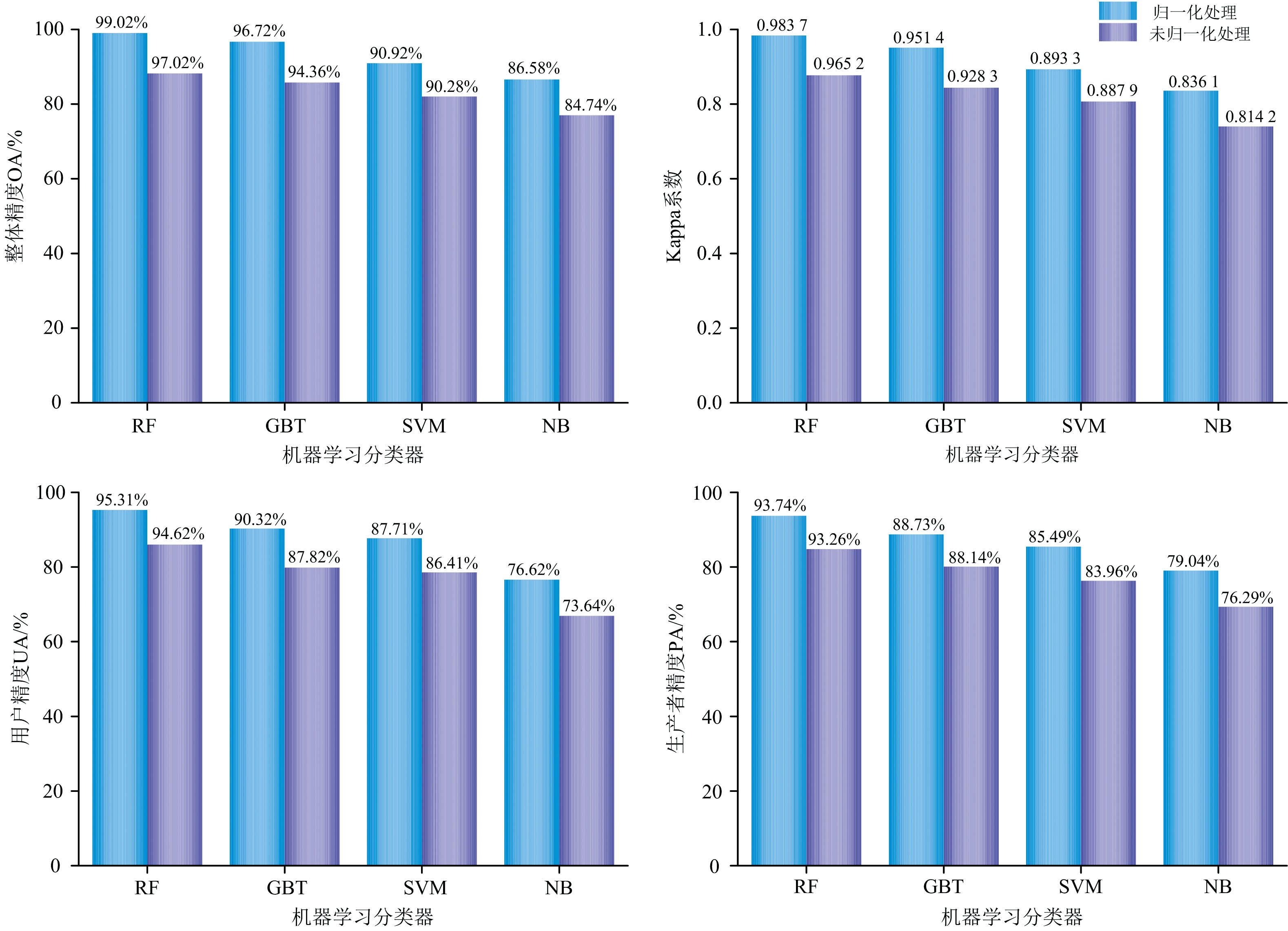 | 图8 不同机器学习分类器与不同分类场景的油茶林分类精度比较Fig.8 Comparison of the classification accuracy of Camellia oleifera forests with different machine learning classifiers and different classification scenarios |
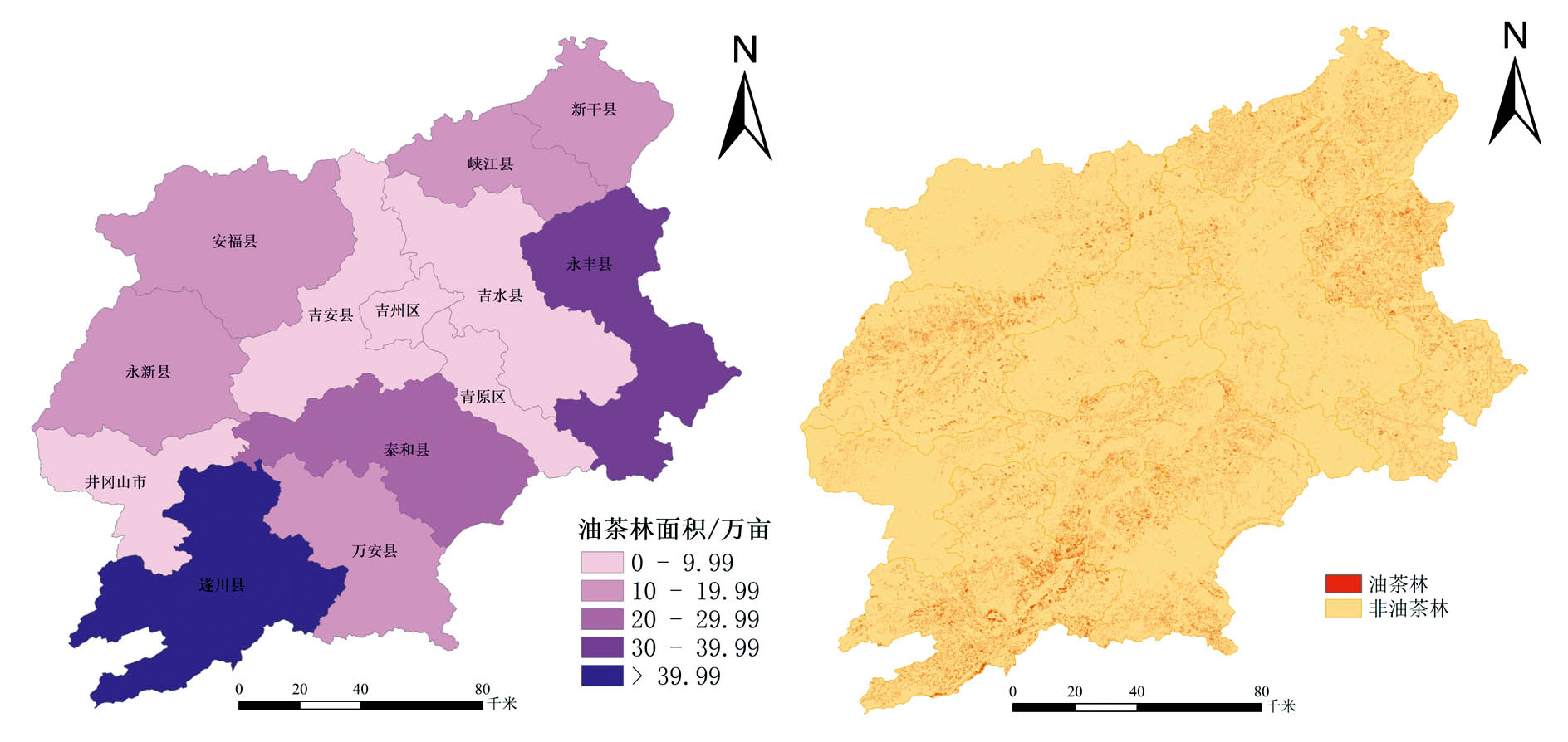 | 图9 2021年吉安市油茶林面积分层、 空间分布图Fig.9 Stratified and spatial distribution of Camellia oleifera forest area in Ji'an, 2021 |
本实验深度学习框架为PyTorch2.2.2。 操作系统为Windows 11, CPU为AMD R5 5600 @4.0 GHz, GPU为NVIDIA RTX 4080super。 编程语言及版本为Python3.12.2, 学习率为10-4, 迭代次数为200次, 批处理大小为64, 损失函数为交叉熵, 优化函数为Adam。
为保证模型之间的可对比性, 研究中CNN、 CNN和Bi-LSTM结合的深度学习模型采用与随机森林分类器一致的特征选取和样本数据, 分别对油茶林识别精度如图10所示。 CNN系列的深度学习模型对油茶林识别精度略低于随机森林分类器。 本研究只尝试了CNN系列模型, 并不能完全代表所有的深度学习模型对油茶林识别精度均低于随机森林分类器。
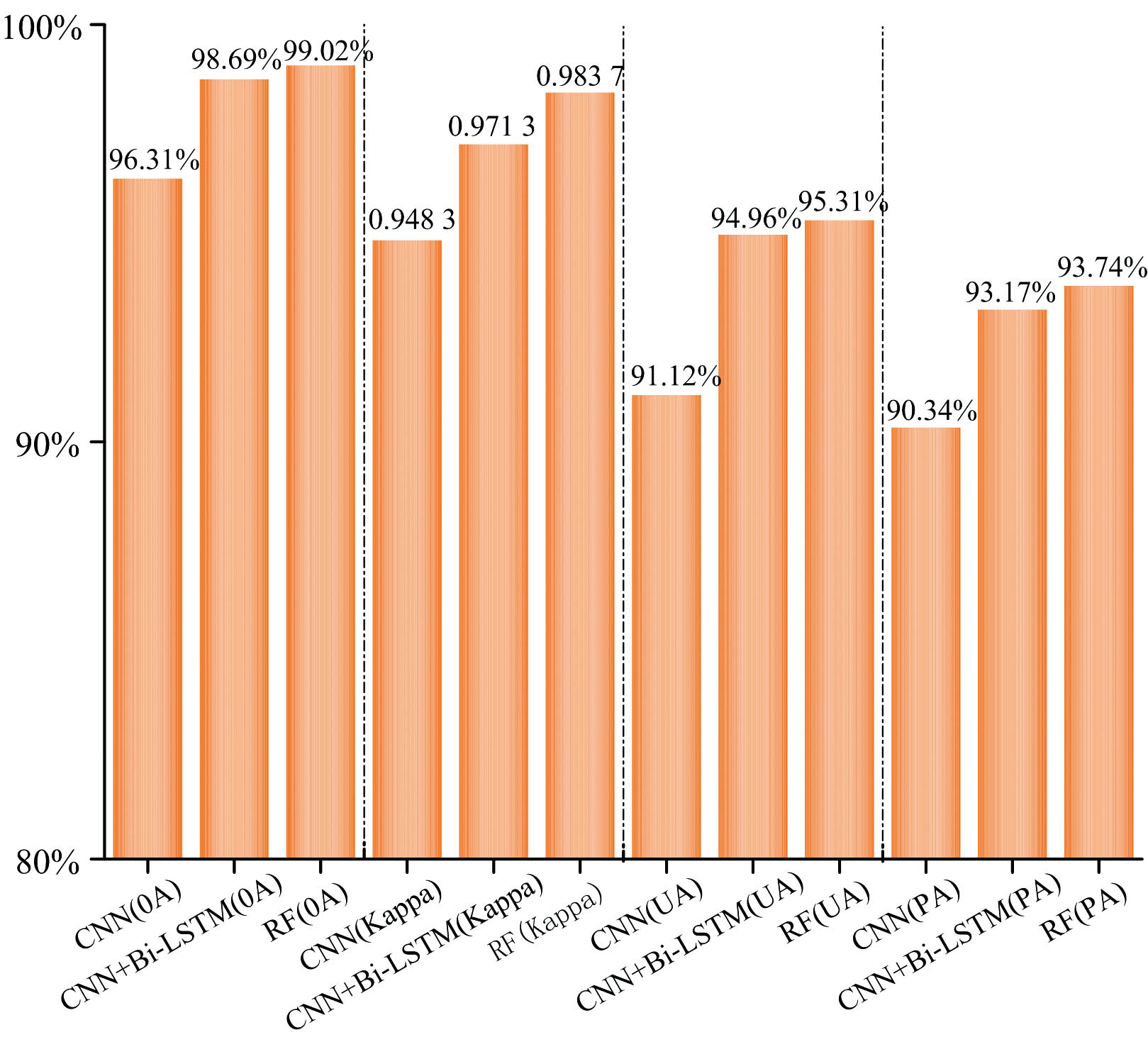 | 图10 不同模型对油茶林识别精度比较Fig.10 Comparison of identification accuracy of Camellia oleifera forests by different models |
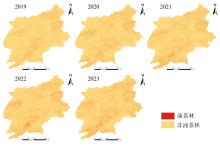
采用余弦相似度的2019年至2023年吉安市油茶林空间分布图如图11所示。 除2021年以外其他年份均以2021年样本点为基础所迁移得到。 由图11吉安市油茶林种植面积随年份的增加而呈现增加的趋势。
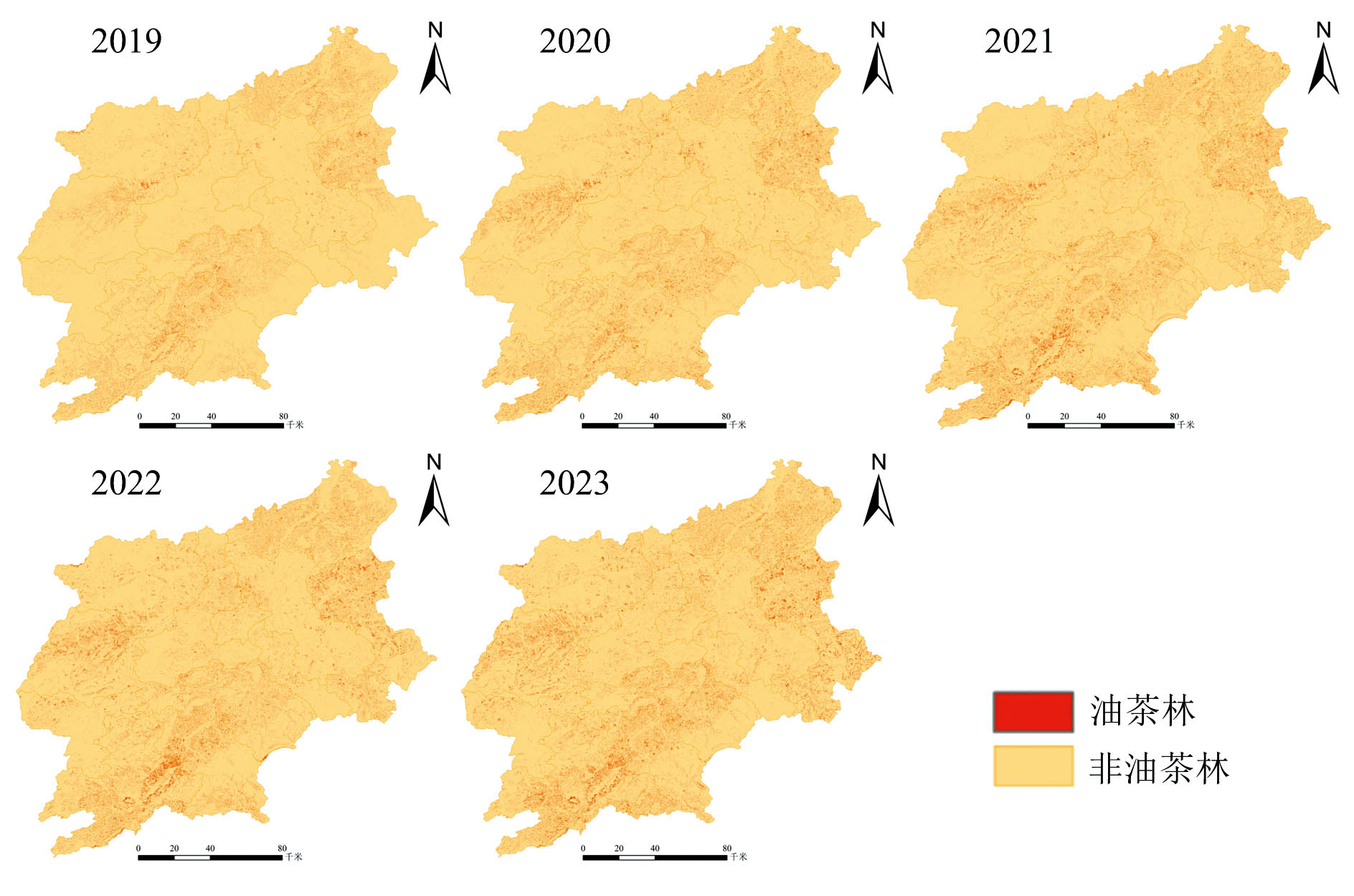 | 图11 2019年至2023年吉安市油茶林空间分布图Fig.11 Spatial distribution of Camellia oleifer forests in Ji'an, 2019— 2023 |
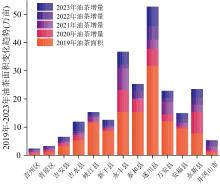
以2019年吉安市油茶林种植面积为基础的2020年至2023年吉安市油茶林种植面积增量如图12所示。 研究区内各县区的油茶林种植面积均在增加, 其中遂川县、 永丰县和永新县在2020年至2023年的整体增加速度较快, 吉州区、 青原区和吉安县在2020年至2023年的整体增加速度缓慢。
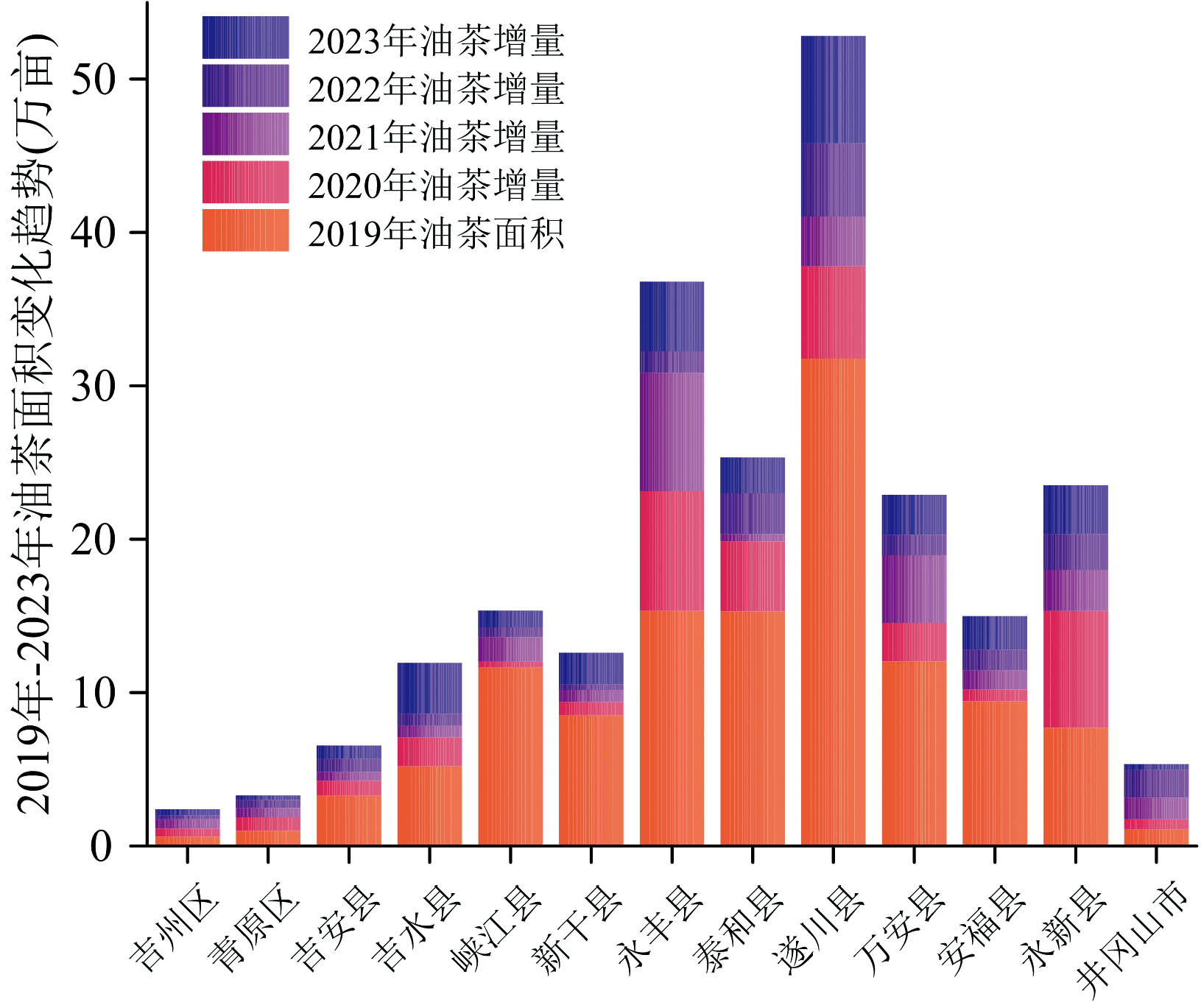 | 图12 2020年至2023年吉安市各县区油茶林增量Fig.12 Increase in Camellia oleifera forests in Ji'an counties and districts from 2020 to 2023 |
以Sentinel-1 SAR雷达遥感数据和Sentinel-2A光学遥感数据作为数据源, 构建油茶林分类特征, 采用Sigmoid激活函数对光谱指数特征进行归一化处理, 选择合适的时间窗口对研究区内油茶林进行分类, 采用余弦相似度对研究区内油茶林进行2019年至2023年之间的动态扩张分析。 旨在发掘可适用于油茶林的提取方法, 以及研究油茶林动态扩张时可减少样本采集和标注成本的方法。 通过对研究结果进行分析, 结论如下:
(1)使用Sigmoid函数对光谱指数特征进行归一化处理可有效提高油茶林识别精度, 归一化后的光谱指数特征可以很好地应用于后续的样本迁移中。
(2)2021年吉安市油茶林总面积为184.488 1万亩, 其中被誉为“ 中国油茶之乡” 的遂川县油茶林种植面积最大, 占2021年吉安市油茶林总面积的27.67%。
(3)由2021年吉安市油茶林空间分布图, 油茶林种植分布呈现由地势较高向地势较低递减的趋势, 多利用土地边缘进行栽培, 种植地点常见于家庭农户附近的山坡地和自留地。
(4)本研究所用4种机器学习分类器中随机森林识别精度最高, 整体精度为99.02%, 其他机器学习分类器的整体精度分别为梯度提升树96.72%, 支持向量机90.92%, 朴素贝叶斯86.58%。
(5)在采用同样的特征选取和样本数据时, CNN系列的深度学习模型识别精度略低于随机森林分类器。
(6)在2019至2023年间, 吉安市各县区油茶林种植面积随年份的增加而呈现增加的趋势, 其中遂川县、 永丰县和永新县整体增加幅度较快, 吉州区、 青原区和吉安县整体增加幅度缓慢。
对于油茶林提取和动态扩张分析中仍存在一些不足之处。 (1) 研究中使用的哨兵系列影像由于其自身的局限性, 可能导致分类结果的不一致性和准确性下降。 (2) 研究中采用的Sigmoid激活函数对光谱指数特征进行归一化处理可能会导致信息丢失, 进而影响分类模型的性能。 未来会尝试更为先进的归一化方法, 以增强模型的适应性和鲁棒性。 研究中采用余弦相似度进行油茶林动态扩张分析在衡量样本数据之间的相似性时较为简单, 可能无法捕捉油茶林扩张过程中的复杂空间模式和微观变化。 未来需探索更加精细的相似度量方法, 以提升动态扩张分析的准确性和可靠性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|