







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
自适应全变差和低秩约束的高光谱图像稀疏解混
[徐晨光1, 2  , 郭禹
, 郭禹1 , 李峰1 , 刘翼1 , 李艳1 , 邓承志1, * , 刘燕德2, * ]
, 郭禹, 刘燕德]
|
|


作者简介: 徐晨光, 1985年生, 华东交通大学实验师 e-mail: xcg@nit.edu.cn
高光谱稀疏解混是利用一个含有丰富的端元光谱信息的光谱库作为先验, 并对高光谱数据进行分解, 得到与光谱库中各端元光谱对应的丰度的图像处理技术。 然而目前大多数稀疏解混方法, 在高噪声条件下的解混效果不佳, 且很多去噪解混算法只是片面的利用了高光谱的某些特性, 并没有对高光谱特性进行全面考虑, 从而影响了解混算法的精度。 为了解决这一问题, 创新地提出了一种基于自适应全变差和低秩约束的高光谱图像稀疏解混方法。 首先对稀疏解混算法进行了详细的介绍, 接着对自适应全变差和低秩约束的高光谱图像稀疏解混算法进行建模, 提出自适应全变差和低秩约束的高光谱图像稀疏解混算法。 该算法把高光谱数据的低秩特性和自适应TV空间特性进行了融合, 在保持丰度的低秩性和稀疏性的同时, 自适应调整丰度矩阵在不同结构下全变差正则化的水平差和垂直差比例, 达到更好的去噪效果。 然后, 使用ADMM算法对新的模型进行求解。 最后, 利用SUnSAL-TV, ADSpLRU, S2WSU, SU-ATV等几种比较经典的算法与本算法比较, 通过两组模拟数据和一组真实数据来实验验证算法的好坏。 两组模拟数据分别是在背景单一的DC1和背景复杂的DC2中各自加入10、 15和20 dB三种高斯噪声得到的数据。 模拟数据实验通过利用不同算法对这两组数据解混, 对解混结果的信号与重建误差比、 丰度重构正确率和稀疏度三个数值来比较, 并对几种算法解混后的丰度图像、 丰度图像与真实图像的差值图等信息进行观察对比, 从而分析几种算法的好坏。 真实数据实验是利用了内华达州的Cuprite矿区高光谱真实数据对解混结果进行分析对比, 进一步用真实数据验证本算法的优势。 实验结果表明: 本方法相对于较为流行的几种解混方法具有更好的鲁棒性和解混效果, 在SRE方面提高了11.4%~310.2%, 拥有更出色的性能。
Hyperspectral sparse unmixing is an image processing technique that uses a spectral library containing rich endmember spectral information as a prior and decomposes the hyperspectral data to obtain the abundance corresponding to each endmember spectrum in the spectral library. However, most of the current sparse unmixing methods have poor unmixing effect under high noise conditions, and many de-noising unmixing methods only make partial use of some characteristics of hyperspectrum and do not fully consider the characteristics of hyperspectrum, thus affecting the accuracy of understanding the mixing algorithm. To solve this problem, an innovative hyperspectral image sparse unmixing method based on adaptive total variation and low-rank constraints is proposed. In this paper, the sparse unmixing algorithm is introduced in detail. Then, the hyperspectral image's adaptive total variation and low-rank constraint sparse unmixing algorithm are modeled. The hyperspectral image's adaptive total variation and low-rank constraint sparse unmixing algorithm is proposed. The algorithm combines the low-rank characteristics of hyperspectral data with the adaptive TV spatial characteristics. While maintaining the low rank and sparsity of abundance, it adaptively adjusts the ratio of horizontal and vertical differences of total variation regularization of the abundance matrix under different structures to achieve a better denoising effect. Then, the ADMM algorithm is used to solve the new model. Finally, several classical algorithms, such as SUnSAL-TV, ADSpLRU, S2WSU, and SU-ATV, are compared with the proposed algorithm, and two sets of simulation data and one set of real data are used to verify the quality of the algorithm. Two sets of simulation data are obtained by adding 10, 15, and 20 dB high Gaussian noise to DC1 with a single background and DC2 with a complex background, respectively. In the simulation data experiment, different algorithms were used to unmix the two data groups, and the three values of signal and reconstruction error ratio, abundance reconstruction accuracy, and sparsity of the unmixing results were compared. Moreover, the abundance image after unmixing several algorithms and the difference graph between the abundance image and the real image was observed and compared to analyze the quality of several algorithms. The real data experiment uses hyperspectral real data from a Cuprite mining area in Nevada to analyze and compare the unmixing results and further verify the advantages of the proposed algorithm with real data. The experimental results show that the proposed method improves SRE by 11.4%~310.2% with better robustness and performance than several popular methods.
高光谱成像技术是20世纪80年代开始在多光谱遥感成像技术的基础上发展起来的[1]。 它以较高的光谱分辨率获取地物或目标的高光谱图像, 在航空、 航天器上进行陆地、 大气、 海洋等观测中有广泛的应用[2]。 高光谱成像应用在地物精确分类[3]、 地物识别[4]、 地物特征信息的提取[5]等诸多方面。 由于高光谱成像技术的巨大优势, 成为遥感领域的一大热点, 正成为当代空间对地观测的主要技术手段[6]。
由于受到传感器分辨率的限制以及成像地区地物分布复杂, 导致有大量混合像元存在于高光谱图像中[7]。 混合像元的存在对地面信息的分析和解译造成困扰[8], 所以需要对获得的高光谱图像进行解混, 以获得混合像元中纯净的物质和他们对应的比例。 这些纯净物质被称为端元, 对应的比例被称为丰度[9]。
现有的高光谱混合模型主要包括线性光谱混合模型和非线性光谱混合模型两种[10], 由于非线性光谱混合模型参数多且难以求解, 通常用线性光谱混合模型近似[11]。 在线性解混中, 目前稀疏回归算法[12]比较常用。 它借助一个庞大的光谱库作为先验知识, 加之一些正则化条件, 估算出光谱库中端元对应的丰度系数, 实现对混合像元的解混[13]。 目前比较经典且引用广泛的稀疏解混算法是由Iordache和Bioucas-Dias[14]提出的基于分裂增广拉格朗日的稀疏解混算法(sparse unmixing via variable splitting and augmented Lagrangian, SUnSAL), 该方法为稀疏解混开辟了新的途径, 并带来了新的见解。 但SUnSAL算法没有考虑到图像的空间信息, 致使其解混的稳健性不好。 针对此问题, Iordache等[15]把SUnSAL模型与全变差正则化项进行结合, 提出了基于分裂增广拉格朗日和全变差的稀疏解混算法(sparse unmixing via variable splitting augmented Lagrangian and total variation, SUnSAL-TV)。 该算法利用邻域矩阵的相似性, 使得解混效果有所提升。 Zhang等[16]在SUnSAL模型基础上, 对丰度矩阵增加了空谱约束项, 提出了一种空谱加权的高光谱稀疏解混算法(spectral-spatial weighted sparse unmixing, S2WSU), 进一步提高了解混精度。 但这几种算法在高噪声条件下, 解混效果不佳。 为此, 本团队对TV项进行改进, 提出基于自适应总变异化的稀疏解混算法(adaptive total variation regularized for hyperspectral sparse unmixing, SU-ATV)[17]。 该方法通过自适应调整TV正则项的水平差和垂直差的比例, 对不同结构进行自适应调整比例, 使算法的去噪性能和解混精度得到进一步提高。 另外, 考虑到丰度矩阵中的向量高度相关, 使丰度矩阵表现出了低秩的特点, Giampouras等[18]提出了同时具有稀疏性和低秩性丰度矩阵估计高光谱图像解混方法(alternating direction sparse and low-rank unmixing algorithm, ADSpLRU), 提高了解混算法的性能。
以上算法只是在稀疏、 空间信息或低秩上, 片面地对高光谱数据进行解混, 而没有全面充分地利用到高光谱的特性, 为此本文把稀疏、 空间信息和低秩这几个因素进行全面考虑, 提出了一种基于自适应TV和低秩约束的高光谱图像稀疏解混方法, 称为ATVLRSU。 该算法一方面在稀疏解混模型的基础上融合了自适应TV, 促进图像同质区域的空间结构一致性, 另一方面融合了丰度矩阵的低秩性, 对丰度矩阵去相关, 进而达到更好的去噪效果, 提高混合像元的分解精度。
高光谱线性光谱混合模型如式(1)
式(1)中, Y∈ Rl× n表示高光谱图像, A∈ Rl× p表示端元光谱库, X∈ Rp× n表示图像的丰度矩阵, N∈ Rl× n表示高光谱图像的噪声。 l, p, n分别表示光谱波段数、 端元个数和像素个数。
由于X表示为光谱库A对应的丰度系数, 是具有一定物理意义的对象丰度值, 其丰度系数应该满足丰度非负性[19]。 此外, 由于光谱库A中包含的端元个数远大于高光谱图像中真实端元的个数, 所以X丰度矩阵表现出稀疏性[20], 于是在模型中增加了稀疏约束项和非负约束。 综上所述, 线性解混模型可以表示为
式(2)中, ‖ AX-Y
式(3)中,
由于高光谱图像还包含丰富的空间信息, 于是Iordache等提出了SUnSAL-TV算法[15], 在SUnSAL模型中增加了一个TV正则化项以利用图像的空间信息, 提高解混效果, 模型如式(4)
式(4)中, λ TV是正则化参数, 用以调整TV正则化项与其他各项的比例,
通常, 高光谱图像中的空间信息在不同区域拥有不同的结构[21]。 在数据形式和传输过程中, 高光谱数据不可避免的会参杂入噪声。 本团队将自适应全变差(ATV)融合到高光谱解混中, 提出了自适应总变差解混模型(SU-ATV)[17], 以更好地对解混结果去噪, 模型如式(5)
式(5)中, T=diag(t1, t2), t1=1/(1+k|
由于丰度矩阵中的向量高度相关[22], 使丰度矩阵表现出了低秩的特点, 一些方法通过引入低秩性进行约束, 以更好的地对丰度矩阵去相关, 使结果更加鲁棒。 基于此, Giampouras等采用lb, * 范数提出了同时具有稀疏性和低秩性丰度矩阵估计高光谱图像解混模型ADSpLRU[18]
式(6)中,
以上算法很好地利用了丰度的稀疏、 空间信息或低秩特性, 得到了良好的解混效果, 但它们并没有把高光谱的特性全面考虑, 造成解混效果不佳。 为了充分地利用高光谱稀疏、 空间信息和低秩等特性, 更进一步增强解混效果, 本工作把以上几种特性进行了有效融合, 并经过大量的实验验证, 提出了一种新的自适应TV和低秩约束的高光谱图像稀疏解混算法。
高光谱图像中的空间信息在不同区域拥有不同的结构, 为了自适应调整丰度矩阵在不同结构下TV的水平差和垂直差并且保持丰度的低秩性和稀疏性, 达到更好的去噪和解混效果, 把高光谱的稀疏、 低秩与自适应TV性质进行融合, 提出了自适应TV和低秩约束的高光谱图像稀疏解混算法(ATVLRSU)。 具体解混模型表示如式(7)
式(7)中, ‖ AX-Y
式(8)中, T=diag(t1, t2), t1=1/(1+k|
我们用交替方向乘子法(ADMM)[23]来对模型进行求解, 过程如式(9)
令
式(9)中: V1=AX, V2=X, V3=X, V4=∇V3, V5=TV4, V6=X, V7=X, V=[V1, V2, V3, V4, V5, V6, V7]。
可以得到
式(10)中: G[A, I, I, 0, 0, I, I]T, B=[I 0 0 0 0 0 0; 0 I 0 0 0 0 0; 0 0 I 0 0 0 0; 0 0-∇I 0 0 0; 0 0 0-T I 0 0; 0 0 0 0 0 I 0; 0 0 0 0 0 0 I]。 G和B为关系矩阵, 且满足GX=BV。 为了解决这个问题, 我们使用拉格朗日乘数法来计算, 可以得到
$\begin{aligned} L(\boldsymbol{X}, \quad \boldsymbol{V}, \quad \boldsymbol{D})= & \min _{\boldsymbol{X}} \frac{1}{2}\left\|\boldsymbol{Y}-\boldsymbol{V}_{1}\right\|_{F}^{2}+\lambda\left\|\boldsymbol{V}_{2}\right\|_{1, 1}+ \\ & \lambda_{\mathrm{TV}}\left\|\boldsymbol{V}_{5}\right\|_{2, 1}+\lambda_{\mathrm{wT}}\left\|\boldsymbol{V}_{6}\right\|_{b, *}+\tau_{\mathrm{R}+}(\boldsymbol{V})+ \\ & \frac{\mu}{2}\left\|\boldsymbol{A} \boldsymbol{X}-\boldsymbol{V}_{1}-\boldsymbol{D}_{1}\right\|_{F}^{2}+\frac{\mu}{2} \| \boldsymbol{X}-\boldsymbol{V}_{2}- \\ & \boldsymbol{D}_{2}\left\|{ }_{F}^{2}+\frac{\mu}{2}\right\| \boldsymbol{X}-\boldsymbol{V}_{3}-\boldsymbol{D}_{3}\left\|_{F}^{2}+\frac{\mu}{2}\right\| \nabla \boldsymbol{V}_{3} \\ & -\boldsymbol{V}_{4}-\boldsymbol{D}_{4}\left\|\stackrel{2}{F}+\frac{\mu}{2}\right\| \boldsymbol{T}-\boldsymbol{V}_{5}-\boldsymbol{D}_{5} \|{ }_{F}^{2}+ \\ & \frac{\mu}{2}\left\|\boldsymbol{X}-\boldsymbol{V}_{6}-\boldsymbol{D}_{6}\right\| \stackrel{2}{F}+\frac{\mu}{2} \| \boldsymbol{X}-\boldsymbol{V}_{7}- \\ & \boldsymbol{D}_{7} \| \stackrel{2}{F} \end{aligned}$(11)
式(11)中, X, V, D为拉格朗日乘子, D=[D1, D2, D3, D4, D5, D6, D7]为拉格朗日乘数法误差项, 在k+1次迭代中, 我们可以得到:
| 表1 ATVLRSU算法伪代码 Table 1 The pseudo-code of ATVLRSU |
根据 ADMM 交替迭代进行求解, 可以得到
其中FFT和F-1(·)分别表示傅里叶的正反变换。
通过以下几个实验, 将实验结果与几种目前较为流行的算法SunSAL-TV[15]、 ADSpLRU[18]、 SU-ATV[17]、 S2WSU[16]比较, 用以验证提出算法的性能优势。 我们采用信号与重建误差比(signal reconstruction error, SRE)[24]表示环境噪声进行定量分析, 其定义如式(20)
式(20)中, E(·)是期望值,
式(21)中, P(·)假设定义阈值th=10且重构正确率ps=1, 则意味着丰度估计的误差小于1/10, 文献[17]对于阈值的确定给出了说明: 当‖ X-
由于高光谱图像中包含的端元个数远大于高光谱图像中真实端元的个数, 所以丰度矩阵表现出稀疏性, 因此我们引入稀疏度[27]作为第三个评定指标
式(22)中,
为了验证本文提出的基于自适应TV和低秩约束的高光谱图像稀疏解混方法(ATVLRSU)的有效性, 在模拟数据实验中, 我们把经典的SUnSAL-TV算法[15], 具有空谱加权约束的S2WSU算法[16], 具有低秩性的稀疏性解混算法ADSpLRU算法[18]和具有自适应TV的稀疏解混算法SU-ATV算法[17]与融合了稀疏、 自适应TV和低秩功能的本文提出的ATVLRSU算法进行多方面的比较。 选择了高光谱数据集1(DC1)和高光谱数据集2(DC2)进行模拟实验以检验本文提出的ATVLRSU算法解混效果。 为了更有效的证明ATVLRSU算法的效果, 我们准备了背景比较单一DC1模拟解混实验和背景较为复杂的DC2模拟实验共同验证我们的算法的解混效果。 DC1和DC2都利用了A∈ R224× 240作为光谱库。 该光谱库选自于具有权威性的美国地质勘探局(United States Geological Survey, USGS)端元光谱库[28], 并在USGS端元光谱库中随机挑选240条光谱曲线作为模拟数据实验的光谱库。 光谱波段数选取了224个, 波长在0.4~2.5 μ m的范围内均匀分布。 这两组高光谱数据设定了不同的端元丰度, 图1表示DC1中五种端元的真实丰度分布图像, 丰度图像为75× 75像素。 其生成过程可以参考文献[15]。 图2是DC2中九种端元的真实丰度分布图像, 丰度图像为100× 100像素。 两组真实高光谱数据根据线性混合模型(1), 添加10、15和20 dB三种不同信噪比的高斯噪声生成三种不同的带噪高光谱模拟数据。
 | 图1 DC1的真实丰度图Fig.1 True abundance maps of DC1 |
 | 图2 DC2的真实丰度图Fig.2 True abundance maps of DC2 |
在不同的信噪比下, 几种不同算法(SUnSAL-TV, SU-ATV, ADSpLRU, S2WSU, ATVLRSU)对DC1和DC2两组数据在最优参数下的解混结果和对应的参数值展示在表2和表3中, 并且在表中对同一信噪比下的解混效果最好的数值用黑体标出。
| 表2 DC1的解混结果 Table 2 Unmixing results of DC1 |
| 表3 DC2的解混结果 Table 3 Unmixing results of DC2 |
通过对两组实验结果分析, 得到结论如下: (1)使用了自适应TV正则化项的解混算法(SU-ATV、 ATVLRSU)解混效果要优于没有使用的算法(SunSAL-TV、 ADSpLRU、 S2WSU), 特别是在15 dB的DC1数据, SU-ATV和ATVLRSU解混结果SRE值是其他算法的2倍以上, 这说明自适应TV能更好地调节不同结构下的空间信息, 使解混结果更好。 (2)在含有自适应TV正则化项的解混算法(SU-ATV、 ATVLRSU)中, 加入低秩约束项的稀疏解混模型ATVLRSU比没有使用低秩约束项的解混模型SU-ATV, 解混效果提升明显。 例如在20dB的DC1数据里, ATVLRSU算法比SU-ATV的SRE提高了20%以上。 这说明, 低秩能够更有效的对解混结果去相关, 使解混结果鲁棒性更好。 (3)在高噪声条件下(10 dB), ATVLRSU算法的解混效果远好于其他算法, 特别是在DC1数据中, SRE提升比例高达35.7%~310.2%, DC2数据也提高了11.4%~137.7%以上。 这说明融合了自适应TV、 低秩和稀疏特性的本算法在高噪声条件下对于其他几种高光谱解混方法具有明显的优势。 (4)两个实验相比, 背景比较单一的DC1实验比背景较为复杂的DC2实验效果好很多, 这说明自适应TV正则化方法能够更有效的对空间信息比较简单的DC1数据进行自动空间信息调节, 达到更好的去噪目的。
为了更直观的展示不同模型的解混效果, 将五种算法对两组高光谱数据(DC1和DC2)的丰度估计图(图3)、 估计图与真实值的差值图(图4)进行比较。 图3中展现了同一信噪比下(SNR=20), DC1中第五个端元(EM5)的真实丰度图和五种算法最优解混丰度估计图, 相关参数见表2。 可以看到, 对比其他的算法, ATVLRSU和SUnSAL-TV算法噪声点最少, 但SUnSAL-TV过于平滑与真实值偏离较大, 例如解混丰度图的第二行的最后的两个正方形丰度误差严重。 图4是在相同信噪比下, DC1数据实验中几种算法的最优解混结果(见图3)的丰度值与真实值的差值图, 用于比较每种算法结果与真实值的差距, 图中颜色越蓝差值就越小, 颜色越红差值就越大。 图中差值较大的图像用红色方框着重显示。 对比五种算法的差值图像, 其中SUnSAL-TV、 ADSpLRU的差值明显过大, 而其他三种算法的图像中, 本文提出的ATVLRSU算法误差最小, 体现了ATVLRSU算法在稀疏解混模型基础上融合了自适应TV和低秩特性的积极的去噪作用。
 | 图3 真实丰度图与不同算法对20 dB的DC1的解混估计丰度图Fig.3 True abundance maps and estimated abundance maps of DC1 by five methods under 20 dB |
 | 图4 DC1在20 dB时不同算法估计值与真实值的丰度差值图Fig.4 Difference maps between true abundances and estimated abundances of DC1 by five methods under 20 dB |
图5是DC2数据第五个端元(EM5)的真实丰度图与五种算法对SNR为20 dB的DC2数据的最优解混估计丰度图, 相关参数是体现在表3中的20 dB一列。 结合图6中五种算法对DC2数据的最优解混估计丰度(图5)与真实丰度的差值图(图中差值较大的图像用红色方框着重显示), 可以得到和上述DC1相同的实验结果, 即本文提出的算法估算结果与真实丰度图最为相似。 表现出更好鲁棒性能和抗噪声性能, 解混精度最高。
 | 图5 真实丰度图与不同算法对20 dB的DC2的解混估计丰度图Fig.5 True abundance maps and estimated abundance maps of DC2 by five methods under 20 dB |
 | 图6 DC2在20 dB时不同算法估计值与真实值的丰度差值图Fig.6 Difference maps between true abundances and estimated abundances of DC2 by five methods under 20 dB |
为了更全面的展示各算法的性能, 我们把解混后所有端元的丰度图像进行比较, 由于像素过多造成图片太大, 我们随机选取了100个像素。 图7是DC1和DC2在20 dB的情况下, 经过五种算法的最佳解混结果估算的丰度图(相关参数选取见表2和表3)。 在图中, 差异较明显的已经用红色矩形框住。 可以看出, DC1和DC2两个实验中SUnSAL-TV, ADSpLRU和S2WSU算法的图像中出现了明显的噪声, 端元的丰度受到干扰, 而SU-ATV和ATVLRSU的抗噪声效果较好, 在DC1中这两个算法几乎都看不出明显噪声, 说明加了自适应TV的算法具有其他算法不可替代的去噪性能。 而在DC2实验中, SU-ATV中噪声点比ATVLRSU算法多, 融合了低秩特性的ATVLRSU算法表现比SU-ATV要好, 说明了低秩性能更进一步加强了解混结果的鲁棒性。 因此, ATVLRSU算法因为融合了稀疏、 自适应TV和低秩的优点, 更进一步提升了解混的精度, 解混图像与真实图像最为接近。
 | 图7 真实丰度图与不同算法在20 dB时对两组数据解混丰度估计图Fig.7 True abundance maps and estimated abundance maps of DC1 and DC2 by five methods under 20 dB |
结合以上几组实验的比较结果, 可以得出融合了低秩和自适应TV的稀疏解混模型ATVLRSU在促进图像同质区域的空间结构一致性和提升混合像元精度方面具有很好的效果, 使解混效果有了进一步提高。
在本节中, 我们将使用广泛用于高光谱遥感图像分析的机载可见红外成像光谱仪(AVIRIS)于1995年采集的内华达州的Cuprite矿区数据[27]作为真实高光谱进行比较和分析。 图8显示了美国地质调查局(USGS)于1995年利用ricorder3.3软件[29]制作的矿物分类图, 利用该软件产品来反映Cuprite矿区数据中各矿物的分布情况。 矿区原始图像有224个波段, 波长范围为370~2 480 nm, 空间分辨率为20 m, 光谱分辨率为10 nm。 实验图像使用了原始图像的部分场景, 像素大小为250× 191。 在去除了由不同干扰因素影响的波段后[27], 仅留下188个光谱波段。 我们将几种不同的稀疏解混算法的丰度估计图进行比较, 并对他们的性能进行分析。
如图9, 我们分别利用SUnSAL-TV、 SU-ATV、 ADSpLRU、 S2WSU、 ATVLRSU几种算法对矿区高光谱数据进行稀疏解混。 估计出明矾(Alunite)、 水铵长石(Buddingtonite)、 玉髓(Chalcedony)三种物质的分布情况, 即三种端元的丰度图像, 并把他们同真实值(True abundances)进行定性比较。 几种解混算法的参数是通过大量仔细调参把解混结果与参考真实丰度比较取与之最接近的解混值而得到的。 其值分别是SUnSAL-TV(λ =0.02, λ TV=0.02)、 SU-ATV(λ =0.05, λ TV=0.1)、 ADSpLRU(λ =20, λ TV=0.05)、 S2WSU(λ =0.5)、 ATVLRSU(λ =0.05, λ TV=0.05, λ WT=1)。
 | 图8 内华达州 Cuprite 数据中各矿物的分布情况Fig.8 Mineral map of cuprite, Nevada derived from AVIRIS Data |
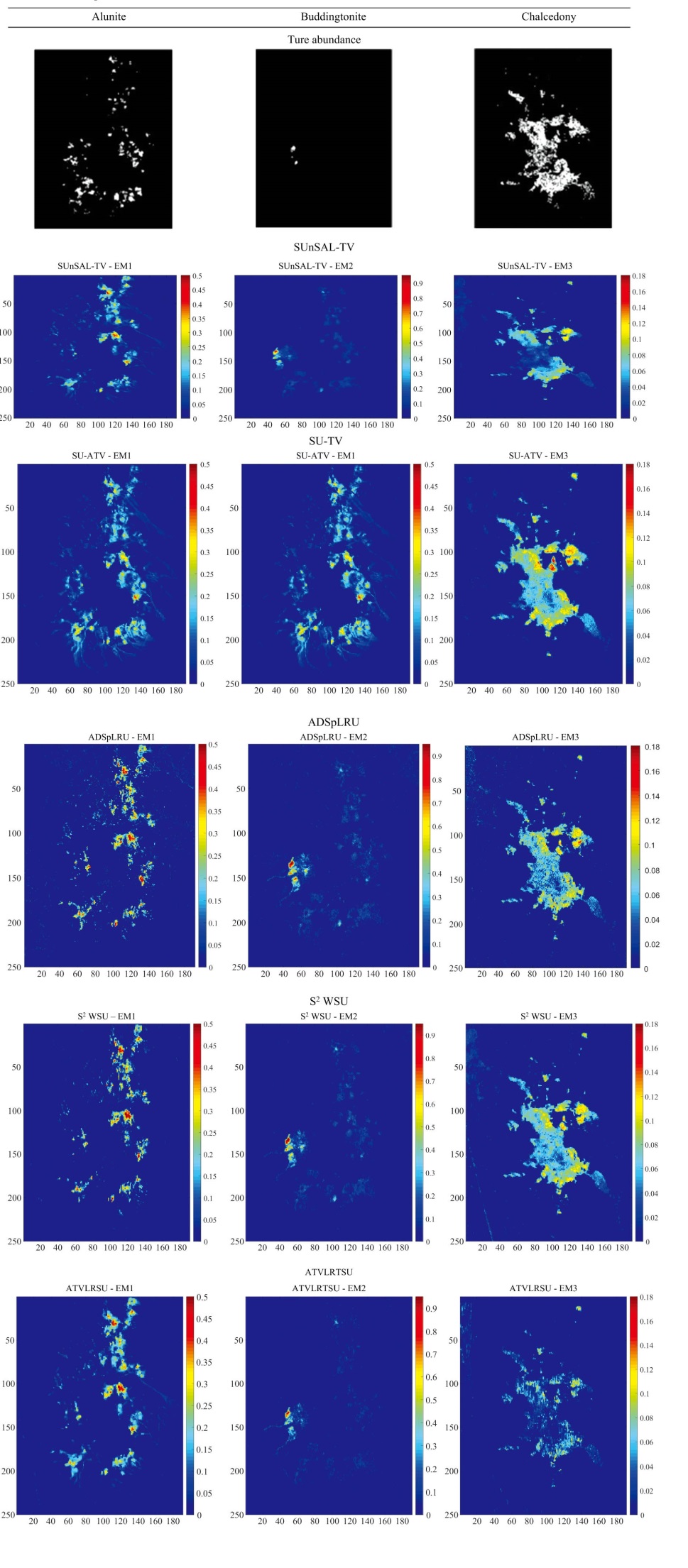 | 图9 几种算法对Cuprite数据的解混丰度图Fig.9 Abundance maps of Cuprite data estimated by five methods |
图9中, 像元丰度值较大的地方(如红色、 黄色、 绿色)为矿物存在较集中的地方。 为了方便比较, 解混丰度结果图与真实丰度图差异较大的作者用红色方框着重显示。 从图9可以看出, 这五种算法解混结果与真实值都比较接近, 表明了这几种稀疏解混算法的有效性。 但细致看来, SUnSAL-TV算法出现了过平滑的现象(例如: 明矾Alunite和玉髓 Chalcedony), 导致图像模糊, 精确度低。 SU-ATV解混效果要优于SUnSAL-TV, 但依旧存在一些过平滑问题(例如: 玉髓 Chalcedony)。 ADSpLRU的图像出现了水铵长石Buddingtonite丰度偏差较大的情况。 S2WSU解混结果中玉髓Chalcedony丰度图像中左上角有明细的错误。 而我们提出的ATVLRSU与真实值最为接近。 总的来说, 通过Cuprite矿区真实数据实验得出的定性结果表明, ATVLRSU算法具有很好的解混效果, 与其他几种算法比较, 其抗噪性能和精确度都有很大的提高。
提出了一种新的基于自适应TV和低秩约束的高光谱图像稀疏解混算法, 该算法一方面在稀疏解混模型的基础上融合了自适应TV, 促进图像同质区域的空间结构一致性, 另一方面融合了丰度矩阵的低秩特性, 对丰度矩阵去相关, 进而达到去噪和提高解混精度的目的。 在模拟和真实数据实验中, 将SUnSAL-TV、 SU-ATV、 ADSpLRU、 S2WSU和ATVLRSU算法进行了详细地分析和对比。 实验结果证明ATVLRSU算法在信号与重建误差比方面提高了11.4%~310.2%, 具有很好的解混效果。 后期我们将对算法的运算效率进行优化和运用场景进行拓展。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|