















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于GEE云平台的小江流域泥石流迹地空间分布制图
[宗慧琳1, 2  , 袁希平
, 袁希平2, 3 , 甘淑1, 2, * , 杨明龙1 , 吕杰1 , 张晓伦1 ]
, 袁希平, 杨明龙|
|


作者简介: 宗慧琳, 女, 1987年生, 昆明理工大学博士研究生, 高级工程师 e-mail: 30211008@kust.edu.cn
快速、 准确、 详尽调研泥石流孕灾区域的分布信息能够帮助了解、 深刻认识泥石流分布范围、 分布规律及成因, 并进一步根据具体情况找到科学的监测、 预测、 预防和治理的技术手段, 从而减少泥石流灾害带来的问题与损失。 为寻求高效、 高精度的泥石流空间分布提取方法, 以云南省小江流域作为研究区, 利用谷歌地球引擎(Google Earth Engine, GEE)平台和随机森林算法, 有效地提取了泥石流迹地的空间分布。 首先利用2022年Sentinel-2影像及地形数据构建4类特征变量(光谱特征、 指数特征、 地形特征、 纹理特征)作为特征集合, 接着将随机森林特征变量重要性评分和J-M距离结合进行特征优选研究与分析, 探讨了各个特征变量对泥石流迹地提取的重要性; 最后设置不同特征组合形成6种不同的提取方案, 对比分析6种试验方案提取泥石流迹地的精度, 确定最优方案以提高识别精度。 研究表明: (1)无论是否进行特征优选, 加入地形特征变量的泥石流迹地提取精度均优于仅使用光学影像数据的精度, 可见地形数据有利于泥石流迹地信息提取; (2)不同类型的特征变量对分类精度的影响不同, 特征重要性评分由高到低的特征类型为地形特征、 指数特征、 纹理特征、 光谱特征; (3)基于Sentinel-2光学影像和地形数据的多源数据构建多维特征变量并进行特征优选的试验方案6, 提取到的2022年云南省小江流域泥石流迹地空间分布图最优, 总体精度为94.95%, Kappa系数为0.94, 泥石流迹地的制图精度为91.01%, 用户精度为95.29%, 该方案不仅提高了分类精度还有效降低了数据冗余。 利用Google Earth Engine平台, 光学遥感影像和地形数据相结合的多源数据以及随机森林算法, 能够快速、 准确、 高效地制作较大范围地物覆盖复杂地区的泥石流迹地空间分布图, 具有较大的应用潜力。
Rapid, accurate and exhaustive research on the distribution of mudslide-hostile areas is of great significance, enabling us to understand and have a deep understanding of the scope of distribution of mudslides, the distribution pattern, the causes of the mudslides, and to further find scientific monitoring, prediction, prevention and management of the technical means by the specific situation, to reduce the problems and losses brought about by the mudslide disaster. To seek an efficient and high-precision method for extracting the spatial distribution of mudslides, this study chooses the Xiaojiang River Basin in Yunnan Province as the study area, employed the random forest algorithm based on the Google Earth Engine (GEE) platform to extract the spatial distribution of debris flow traces efficiently. Firstly, Four types of feature variables(spectral features, index features, topographic features, and texture features)were constructed using the 2022 Sentinel-2 image and topographic data, then the random forest feature variable importance score and the J-M distance were combined for the feature preference research and analysis, explored the importance of each feature variable on the extraction of mudslide traces, and finally, set up various feature combinations to create six schemes, compared and analyzed the accuracy of the debris flow traces extracted by the six experimental schemes, and found the best scheme to increase the recognition accuracy. The study shows that: (1) regardless of feature optimization, the accuracy of debris flow trace identification with the addition of terrain feature variables is higher than that with merely optical image data, indicating the utility of using terrain data for debris flow trace information extraction; (2) classification accuracy is affected differently by different feature variable kinds; topographic, index, texture, and spectral features are the feature types with the highest to lowest feature importance scores; (3)the experimental scheme 6 is the best results of the spatial distribution map of debris flow traces in Xiaojiang River Basin, Yunnan Province, in 2022, which constructed multi-dimensional feature variables and feature optimization based on the multi-source data of Sentinel-2 optical images and topographic data. This resulted in an overall accuracy of 94.95%, a Kappa coefficient of 0.94, a debris flow trace mapping accuracy of 91.01%, and a user accuracy of 95.29%. Furthermore, the scheme effectively reduced data redundancy while improving the classification accuracy. This study makes use of the Google Earth Engine (GEE) platform. These multi-source data combine topographic and optical remote sensing imagery and the Random Forest algorithm, which can quickly, accurately, and efficiently extract information on debris flow traces in areas with complex feature coverage over a large range of terrain and has a large potential for applications.
在林业中, 采伐后还未重新种植或者利用的土地被定义为迹地。 将迹地概念引申至泥石流的研究中, 把泥石流体发生时产生的侵蚀区、 流通区和堆积区, 但未重新开发利用的土地定义为泥石流迹地。 根据泥石流流变和冲淤的特征可知, 泥石流迹地主要有三种类型, 一种是分布在陡峭山坡坡面的冲刷侵蚀面, 第二种是泥石流流通的沟道, 第三种是分布在沟谷下游平缓地区的堆积扇区域[1]。 及时、 准确地获取泥石流迹地区空间分布信息, 有利于充分认识泥石流灾害分布规律、 发生的诱因等, 从而协助相关部门找到有效的技术手段, 实现科学合理地预测、 预防和治理。
遥感技术因其具有获取数据速度快、 覆盖面积广和数据时效性强的优势, 已被广泛应用于地球地表信息探测。 近年来, 研究者们积极探索在不同遥感平台和数据源下, 各类算法自动识别和定位泥石流区域的效能。 张晓东等[2]利用SPOT6遥感影像建立地质灾害解译标志, 采用支持向量机分类方法(SVM)成功解译出65处崩塌、 26条泥石流沟和3处地面塌陷, 并深入分析了长时间尺度下的地表环境的变化。 李梁等[3]则将改进后的Mask R-CNN的深度学习目标检测方法应用于不同高度航拍影像灾害检测中, 并在Tensorflow深度学习框架, 对森林火灾、 滑坡、 泥石流、 地震四类灾害进行了检测实验, 展现了该技术在多灾害识别领域的潜力。 赵岩等[4]采用深度学习模型Faster R-CNN对谷歌地球遥感影像中的泥石流堆积扇进行自动识别。 张雄浩等[5]以高分二号影像(GF-2)为数据源, 融合NDVI、 NDWI、 NDSI指数特征, 基于ENVI遥感数据处理平台中U-net架构下的ENVINet5模型进行了泥石流迹地信息提取试验, 发现ENVINet5模型要明显优于面向对象分类方法, 但是该试验在样本选择时主要集中于流通沟道和堆积区, 较少顾及区域内处于陡峭山坡冲刷侵蚀面, 因此试验结果中陡峭山坡冲刷侵蚀面存在较多漏提图斑。 张良洁等用高分影像数据, 通过支持向量机算法进行泥石流迹地与居民地制图, 总体精度达到90.69%, Kappa系数为0.86[1], 进一步挖掘了遥感技术在灾害制图中潜力。
上述研究在进行泥石流信息提取时, 已逐渐考虑多源数据结合的优势。 然而, 尽管这些方法在特征构建和选择上展示了一定的潜力, 但仍存在以下问题: 一方面, 现有研究成果中, 鲜有定量评价各个特征对于泥石流信息提取的作用, 导致在实际应用中存在一定的盲目性和不稳定性, 对泥石流区信息识别效果因特征选择而异, 不同的特征适用于何种遥感数据和分类场景尚未形成统一的定论; 另一方面, 基于多源遥感数据构建多特征的面向较大范围地物覆盖复杂地区的泥石流信息识别面临着数据下载和预处理工作量大、 高计算量和存储空间需求大等困难。 特别地, 2015年与2017年欧洲航天局(European Space Agency, ESA)发射的第2组卫星(Sentinel-2A和Sentinel-2B)为地物遥感识别提供了高时空分辨率(5 d, 10 m)的卫星数据。 相比于Landsat系列卫星数据, Sentinel-2卫星数据不仅空间分辨率更高, 5天的高重访周期更是有效地减轻了云污染的影响, 从而为全球地表监测提供了前所未有的机会, 成为世界各地土地利用类型分类、 自然保护、 气候变化、 作物长势监测、 环境问题和自然灾害等研究的理想数据源[6]。 此外, 随着Google Earth Engine、 PIE-Engine和AI Earth云平台等云计算平台的兴起, 进一步革新了地理空间数据存储、 管理和分析方式, 大大提高了数据资源整合利用及海量卫星遥感数据处理运算效率, 被广泛用于大规模、 复杂的地球科学研究[7]。
鉴于此, 借助GEE云平台, 利用Sentinel-2光学影像和地形数据构建多元特征变量, 设计6种分类方案, 深入探讨光谱特征、 指数特征、 纹理特征及地形特征对较大范围地物覆盖复杂地区泥石流迹地提取的重要性, 定量分析各个特征对于泥石流信息提取的重要程度并进行特征优选, 以寻找有利于泥石流迹地提取的最优特征组合; 然后, 采用随机森林算法对中国云南省小江流域泥石流迹地进行自动识别与提取, 提高泥石流迹地信息提取精度。 希望未来能够将本方法用于更大地理区域的泥石流迹地信息提取。
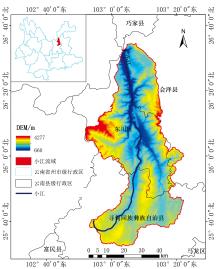
研究区为小江流域, 位于中国云南省东北方向(25° 32'N— 26° 35'N, 102° 52'E— 103° 22'E), 总面积约3 370 km2。 小江是金沙江段东岸的一条一级支流, 全长约为138 km, 流经东川县、 会泽县和寻甸回族彝族自治县。 流域内地形起伏变化大, 高差大于3 500 m, 主要构造地貌表现为山体的强烈陡升, 河流的迅速深切, 如图1所示。 小江流域是我国暴雨型泥石流的发育区, 沿着著名的小江深大断裂带两岸发育了140多条泥石流冲沟, 每年降雨集中在5月— 10月, 这一时期是泥石流的高发期。 流域以林地、 耕地、 裸地、 建设用地等土地利用类型为主。 由于该区长期泥石流灾害频发、 矿产资源过度开发、 坡地开耕面积大, 导致植被破坏、 水土流失严重、 生态功能极度退化, 是长江上游生态环境最为恶劣的流域之一。 在《全国地质灾害防治“ 十四五” 规划》中, 该流域被划入“ 川南滇东北黔东黔西高山峡谷区滑坡崩塌泥石流重点防治区” , 在《云南省地质灾害“ 十四五” 规划(2021年— 2025年)》中, 也被划入“ 滇东北金沙江中下游重点防治区” , 为了减少该区泥石流灾害带来的问题与损失, 必须了解、 认识泥石流, 详尽调研泥石流孕灾区域并对泥石流沟谷进行不同尺度全方位的监测。
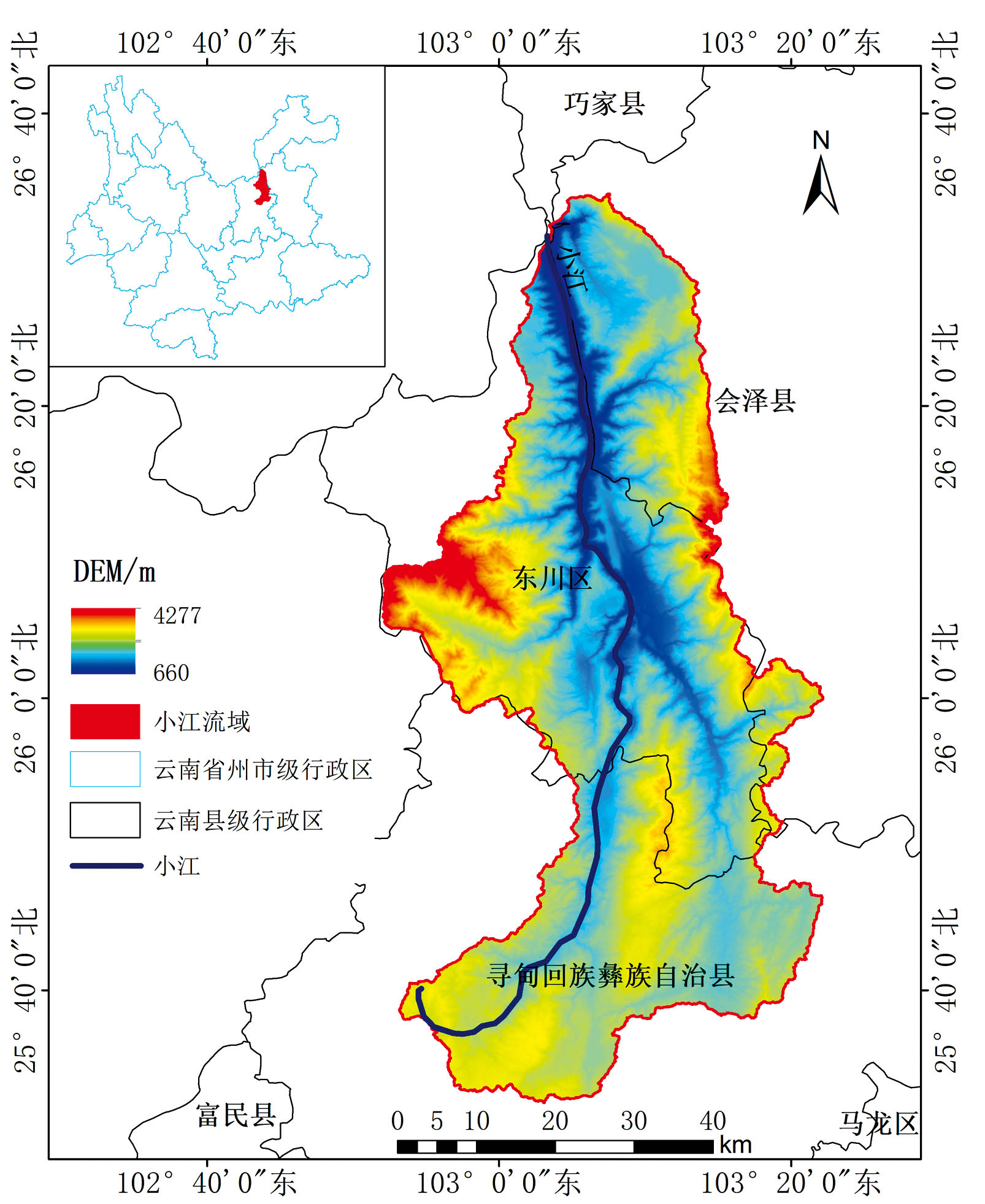 | 图1 小江流域地形图Fig.1 Topographic map of the Xiaojiang River Basin |
1.2.1 Sentinel-2与SRTM DEM数据
Sentinel-2是由欧空局从法属圭亚那的库鲁航天中心分别于2015年6月23日和2017年3月7日发射的Sentinel-2A和Sentinel-2B两颗地球观测卫星组成。 其搭载的新型多光谱成像仪(multispectral instrument, MSI), 具有13个光谱波段, 幅宽达290 km, 空间分辨率从小到大分别为10、 20和60 m。 总的来说, 哨兵2号成像能力强, 空间分辨率高、 重访周期短、 监测频率高, 加之良好的运转效果且可免费使用, 方便了遥感应用研究, 使其成为了全球范围内最受欢迎、 使用率最高的地球观测卫星之一。
Sentinel-2影像中, 波段1(B1)为气溶胶波段, 主要用于大气校正, 特别是气溶胶的监测和去除; 波段2(B2)为蓝光波段, 对植物衰老、 褐变、 类胡萝卜素及土壤环境敏感, 也可用于监测海洋水色及浮游生物; 波段3(B3)为绿光波段, 对植被覆盖和植被健康状况敏感, 且对水体有一定穿透力, 可用于植物识别、 潜水区域研究等; 波段4(B4)为红光波段, 是叶绿素吸收最强的波段, 用于植物生长监测, 农业产量预测; 在光学数据中, Sentinel-2数据是唯一一个在红边范围含有4个波段(B5、 B6、 B7和B8A)的数据, 波段5(B5)、 波段6(B6)、 波段7(B7)为红边波段(红光波段的边缘), 是介于红光和近红外波段之间的过渡区域, 与植被各类理化参数(叶绿素含量、 叶片结构等)息息相关, 波段8A(B8A)为窄近红外波段和近红外波段的峰值, 对总叶绿素、 生物量、 叶面积指数敏感, 这些红边波段对监测植被健康信息非常有效, 主要负责监测森林覆盖情况; 波段8(B8)为近红外波段, 是植被反射的主要区域, 用于叶面积指数的计算和植被覆盖度的监测, 它也是水体强吸收波段, 常用于水体提取和监测; 波段11(B11)为短波红外波段, 对土壤湿度、 木质素、 地上森林生物量及淀粉含量敏感, 常用于植被分类、 土壤湿度监测, 也可用以区分雪、 云、 冰; 波段12(B12)为短波红外波段, 对植物水分含量极为敏感, 可用于植被干旱状况评估, 也可用以区分活生物量、 死生物量和土壤, 例如火烧迹地测绘。
使用的遥感数据均来源于GEE平台数据库, 有Sentinel-2多光谱卫星数据2A级产品和数字高程数据SRTM DEM(30m), 在参与分类时将各数据的空间分辨率重采样至10 m。 影像的筛选、 去云、 中值合成、 重采样、 裁剪等预处理操作, 影像特征计算, 波段合成, 特征重要性评分和泥石流迹地识别等全部试验过程均通过线上JavaScript编程接口实现。 为了获取雨季后泥石流迹地的影像, 影像选择时间段为2022年10月1日至2022年11月30日, 共获取41景Sentinel-2影像, 利用包含云信息的QA60波段去除影像中云的影响, 中值合成镶嵌成一幅研究区的无云高质量影像。
1.2.2 样本数据
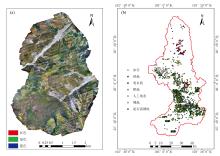
对于遥感信息提取至关重要的是目标样本数据的选择, 样本数量、 样本可靠性、 样本的空间分布均会影响最终提取结果的准确性。 为获取可靠样本数据, 以验证试验结果, 往往需要野外实测数据。 本次针对小江流域的泥石流迹地进行提取, 考虑该区地理条件限制, 难以实现大范围的外业调查和样本数据实地采样, 在采集外业调查数据时主要选择了典型泥石流沟大白泥沟与小白泥沟, 用经纬M300RTK无人机搭载Rainpoo M6Pro近景摄影测量相机, 进行了为期2天的实地无人机航拍(2022年11月4日— 11月5日, 航拍时间与光学影像时期相近), 总共拍摄有效照片2 145张, 作为野外实测数据, 详细展示了典型区域的泥石流迹地位置信息[如图2(a)]。 同时, 参考10 m近实时(NRT)土地利用/土地覆被(LULC)数据集Dynamic World V1[8], 结合Google Earth高分辨率实时影像辅助判断与实地调查结果, 采用目视解译的方式, 对研究区内的地物覆盖类型进行了调查。 调查发现, 研究区大概可分为冰雪、 林地、 明水面、 耕地、 人工地表、 裸地、 泥石流迹地7种地物类型, 表1为具体各地类的遥感识别样本。 总共采集并筛选出具有代表性的样本点共2 587个, 样点分布如图2(b)所示。 然后, 根据GEE中提供的Random Colum算法将数据集随机打乱, 总样本点的70%作为训练样本, 用于模型的拟合、 调参, 剩余的30%作为验证样本, 用于对最终分类结果的精度检验。 最终各类型样本采集数量分布如表2所示。
 | 图2 野外无人机实测数据及研究区的样本点概况示意 (a): 大、 小白泥沟低空无人机正射影像; (b): 样本点分布图Fig.2 Schematic representation of drone survey data and sample points distribution in the study area (a): Drone orthophoto taken at low altitude at Bainigou; (b): Distribution of sampling points |
| 表1 各地类的遥感识别样本 Table 1 Samples for identification of various land types |
| 表2 样本数据集的情况 Table 2 Sample data set |
1.3.1 试验方案
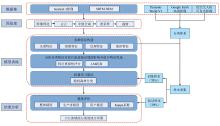
研究的技术方案如图3所示。 采用预处理后得到的无云合成影像, 构建光谱特征、 指数特征、 纹理特征、 缨帽变换特征等特征, 结合SRTM DEM数据提取的高程、 坡度、 坡向等地形特征, 进行波段合成, 形成多维特征集合, 利用随机森林算法中的袋外数据重要性评分进行特征优选, 进一步结合J-M距离探讨优选特征的可分离度, 进而揭示优选结果的可靠性。 共设计6个试验方案(表3), 均采用随机森林算法对泥石流迹地进行提取, 以此分析特征优选操作对泥石流迹地提取精度的影响, 并探究不同的特征变量对提取泥石流迹地的贡献度。
 | 图3 技术路线Fig.3 Technical scheme |
| 表3 试验方案 Table 3 The information of experimental programs |
1.3.2 特征构建
泥石流迹地区的提取实质属于遥感影像解译范畴, 不同地物间存在“ 同物异谱、 异物同谱” 的问题, 采用单一的光谱信息无法有效解决这个问题, 因此在GEE云平台中调用2022年10月1日— 11月30日的云量低于2%的Sentinel-2影像和SRTM DEM地形数据, 构建基于Sentinel-2影像的光谱特征、 指数特征、 缨帽变换特征、 纹理特征和基于DEM数据的地形特征共30个特征变量, 作为输入特征集, 表4详细描述了各种特征及相应表达方式, 本研究时将缨帽变换特征归入指数特征类中。
| 表4 多维分类特征集 Table 4 Multidimension classification feature collection |
光谱特征是对遥感影像中各地物类型判断与分类的直接依据。 选取Sentinel-2影像的B2、 B3、 B4、 B5、 B6、 B7、 B8、 B8A、 B11、 B12共10个原始波段作为原始光谱特征。
利用遥感影像的不同光谱波段进行数学运算形成的各种光谱指数能够有效增强目标地类, 已被广泛应用于各种地物的区分。 因此, 为了放大不同地物间特征数值的差异, 增加地物目标之间的区分度, 引入植被、 建筑、 水体等相关指数特征。 泥石流沟道内往往地形起伏变化大, 植被损毁严重, 选取相关植被指数来反映植被破坏情况。 考虑泥石流物源区、 流通区、 堆积区的松散物质含水量往往较高, 选取缨帽变换(K-T变换)[9]的湿度分量(Wet)来表征。 具体地, 通过提取归一化植被指数(normalized difference vegetation index, NDVI)、 增强型植被指数(enhanced vegetation index, EVI)、 归一化差值山地植被指数(normalized difference mountain vegetation index, NDMVI)、 归一化差异水体指数(modified normalized difference water index, MNDWI)、 裸地指数(bare soil index, BSI)、 建筑指数(index-based built-up index, IBI)、 缨帽变换(K-T变换)的绿度(Green)、 亮度(Bright)、 湿度(Wet)分量, 作为指数特征集, 突出相应地物的信息, 共同参与泥石流迹地识别与提取。
纹理是影像中的一种由纹理基元组成的全局空间特征结构, 本质上反映的是影像中同质现象的视觉特征, 不同地物具有不同的纹理, 体现为影像中地物表面所具有的周期性变化或缓慢变换的结构排列属性, 通过像素及其周围空间邻域的灰度空间分布规律来表达。 相较于其他空间特征(形状、 大小等), 纹理特征不需要事先对图像进行分割, 使用较便捷。 灰度共生矩阵(GLCM)[10]是目前应用最广泛的纹理统计分析方法, 它通过研究灰度的空间相关特性来描述纹理。 本文参考Tassi等[11]研究结果对Sentinel-2影像的近红外、 红色、 绿色波段进行线性组合生成Gray图像。 如式(1)所示
式(1)中, ρ NIR, ρ RED, ρ GREEN分别代表Sentinel-2影像的第8、 4、 3波段的反射率。
对生成的Gray图像进行GLCM构建。 GEE云平台提供了快速计算GLCM纹理特征的函数glcmTexture, 可迅速得到Haralick提出的14个GLCM 指标以及Conners等提出的4个附加指标, 共18个纹理特征。 为了避免过多的纹理特征在训练模型过程中造成冗余, 选取了角二阶矩(Angular second moment)、 对比度(Contrast)、 相关性(Correlation)、 方差(Variance)、 差异性(Dissimilarity)、 总和平均值(Sum average)、 同质性(Homogeneity)及熵(Entropy)共计8个常用统计量, 参与泥石流迹地提取。
地形特征主要利用DEM数据计算了高程(Elevation)、 坡度(Slope)和坡向(Aspect)。
1.3.3 随机森林算法
随机森林[12]是一种集成学习方法, 通过构建多个决策树并投票决定最终结果[13], 能处理高维数据、 防止过拟合, 且在小样本情况下表现稳定。 构建随机森林时, 首先用bootstrap抽样选取约63%的原始样本作为训练集, 然后基于这些样本建立多棵CART决策树, 每棵树在分裂时随机选择特征[14]。 最终, 随机森林将多棵决策树的分类结果进行投票, 得票最多的类别作为样本的最终分类结果。
在GEE平台上, 集成了多特征变量, 采集样本数据后, 运用随机森林算法提取研究区泥石流迹地, 并通过算法评估特征重要性进行特征优选。 随机森林构建中, 决策树数量N和节点分裂过程中随机抽取的特征数m是最为关键的两个参数, 用来调整随机森林的效果。 理论上, 决策树的个数N越多其分类精度越高, 但时间成本也越高。 研究中调用GEE平台的随机森林算法, 并对决策树数量及随机抽取的特征数m进行调整。 通过几个方案的大量试验发现, 在固定抽取特征m的基础上, N增至80时, 袋外数据误差逐渐趋于稳定, 分类精度最高, 继续增加N无显著提升, 故设定N为80[15]。 Belgiu等[16]研究发现, 当树的个数固定为500, 特征数m的选取在特征总数的不同比例间对精度影响有限。 本工作将N固定为80, 参考不同学者所给出的设置比例进行试验, 最终发现解毅等[17]建议的0.8在本研究任务中得到的分类精度最高, 因此将bagFraction设定为0.8。
1.3.4 特征优化
在遥感影像地物分类中, 综合利用多类特征进行分类能够在一定程度上提升分类精度, 但全部特征参与分类往往造成信息冗余, 一些特征之间存在较高的相关性, 甚至出现维数灾难, 反而影响分类精度, 导致精度下降。 因此, 进行特征的筛选、 组合与优化非常重要, 可以有效降低特征维度, 减少计算量且提升分类精度。 一般可以通过特征优选操作来降低特征维度, 从而提高模型的泛化力。 随机森林算法可以通过计算各个特征变量的重要性评分来衡量特征变量对预测目标变量的贡献率, 从而达到特征选择和降维的作用。 特征的评分大小代表了该特征分类能力的强弱, 评分越大意味着分类能力越强, 评分越小则分类能力越弱。 在随机抽样的过程中, 未被抽中的样本被称为袋外数据OOB(Out-of-bag)。 袋外数据误差(Out-of-bag-error)可以用于计算不同特征的重要性评分(variable important, VI), 从而进行特征选择。
假设随机森林有N棵树, 该特征变量重要性评分计算公式为
式(2)中, I表示特征变量的重要性评分, E1为某个特征未加入噪声干扰时计算得到相应的OOB误差, E2为加入一定噪声干扰后再次计算得到相应的OOB误差, N为生成的决策树棵树。
若某个特征变量在随机加入噪声干扰后, 袋外数据误差大幅增加, 准确率大幅度下降, 则说明该特征变量对于样本的分类结果影响大, 也就说明它的重要程度比较高, 相应的重要性评分也就高。 特征优选即通过特征重要性评分从高到低累计添加得出最高分类精度以确定最优特征数量。
J-M距离(Jeffries-Matusita distance)用来衡量不同类别间样本的可分离程度[18], 样本服从正态分布时, 基于某一特征两类样本的J-M距离, 计算表达式为
式(3)和式(4)中, J表示J-M距离, B表示不同类别样本之间的巴氏距离(Bhattacharyya distance, BD), ei为某类特征的均值,
通过随机森林算法计算特征重要性评分进行特征优选, 进一步结合J-M距离探讨优选特征的可分离度, 进而揭示优选结果的可靠性。
1.3.5 精度评价
为有效评估不同方案对泥石流迹地的提取精度, 选择利用混淆矩阵生成的整体精度(overall accuracy, OA)、 生产者精度(producer accuracy, PA)、 用户精度(user accuracy, UA)和Kappa系数、 F1分数(F1 score)共5个指标进行模型精度评价。 Kappa系数用于检验验证样本与预测结果一致性, 取值范围为0~1, 取值越接近于1, 模型一致性越高, 通常被分为5个不同级别: [0, 0.20]为一致性极低、 (0.20, 0.40]为一致性一般、 (0.40, 0.60]为一致性中等、 (0.60, 0.80]为高度一致性、 (0.80, 1]为几乎完全一致。 F1是PA和UA的加权平均值, 同时兼顾了PA和 UA两个指标, 能更全面的表示模型精度的好坏, 取值范围也为[0, 1], 取值越趋近1, 代表模型效果越好[20]。 计算式如式(5)— 式(9)所示。
式(5)— 式(9)中, Mi为第i类的分类正确样本数; Xi为第i类的真实像元总数; Yi为第i类的分类像元总数; N为所有验证样本总数; n为类别数, 本工作中, n为7。 方案1— 方案5主要用于探测不同特征变量在泥石流迹地信息提取中的作用和影响。 在所有30个特征的基础上, 采用随机森林算法计算各个特征变量重要性评分, 再通过逐一累加重要性评分从高到低特征变量的方式, 分别采用随机森林分类器对泥石流迹地信息进行提取, 最后选择总体精度最高的特征子集作为方案6。
基于GEE平台计算特征组合中各个变量的重要性得分, 再结合随机森林算法, 在分类过程中通过累计添加重要性评分从高到低的特征变量得到最高分类精度以确定最优特征数量和特征集合。 为了更清晰直观地反映重要程度高的特征变量, 结合不同特征变量个数与所对应的总体分类精度和Kappa系数的关系进行分析(图4)。 统计不同特征变量的重要性得分发现: 不同特征变量的重要性评分差异较大, 特征Slope的重要性评分最高, 高达138.34(图5), GLCM_ent特征重要性评分最低, 为58.38。 地形特征中, 海拔特征在分类中重要性得分最高(138.34), 而坡向特征则对分类的贡献较小(78.73)。 Sentinel-2影像的光谱波段中, B11、 B2的重要性得分要高于其他的光谱波段, 这表明B11、 B2这两个波段对提取泥石流区的帮助更大, 而B8A、 B7、 B4、 B8这几个波段则对于泥石流区的提取帮助较小。 指数特征中, MNDWI、 Green、 Wet、 NDVI几个指数特征的重要性要高于BSI、 NDMVI、 EVI、 IBI、 Bright。 基于灰度图Gray构建的纹理特征中, CLCM_diss差异性的重要性要高于其他的纹理特征。 总体而言, 四类特征中, 均存在一定数量对泥石流区提取贡献较为突出的特征, 尤其以地形特征中的坡向与高程特征最为突出。
 | 图4 特征变量个数与分类总体精度和Kappa系数的关系曲线Fig.4 The relationship between number of characteristic variables and classification accuracy and Kappa coefficient |
 | 图5 特征变量重要性排序Fig.5 Variable importance ranking |
特征变量累积个数与总体分类精度和Kappa系数关系总体可分为2个阶段, 总体分类精度的总体趋势先急速上升迅速达到顶峰后开始逐步趋于稳定(图4)。 随着参与分类的特征变量的增加, 前期(前8个累加特征)分类精度呈现急速上升并迅速达到最高精度, 从单个特征分类精度的54.46%随着特征数量的累加迅速上升到94.95%, 这主要因为前期加入的各项特征变量重要性评分高, 特征之间的相关性小且冗余特征少, 从而提高了分类器的性能; 后期(9~30个特征), 分类精度逐渐呈现平稳甚至少许下降的趋势, 这是因为后期冗余特征和相关特征逐渐增加, 降低了分类器的整体性能, 导致分类精度趋于稳定并有所下降。 因此, 将前8个特征作为方案6, 具体为Slope、 Elevation、 MNDWI、 Green、 GLCM_diss、 Wet、 NDVI、 B11。
6种不同试验方案的提取结果如图6所示, 分类精度统计如表5所示, 用于评价与分析各方案对泥石流迹地提取精度的影响。 综合来看: 各个试验方案提取的结果显示, 所有类别中冰雪的提取精度最高, 裸地和泥石流迹地的分类精度最低。 其中, 以Sentinel-2的所有原始光谱特征和以Sentinel-2数据计算得到的指数特征组合进行分类的方案3精度最低, 总体精度为85.12%, Kappa系数为0.81。 Sentinel-2影像和地形数据共同构建特征集并进行特征优选组合的方案6精度最高, 总体精度为94.95%, Kappa系数为0.94。
 | 图6 各试验方案的提取结果 (a): 方案1; (b): 方案2; (c): 方案3; (d): 方案4; (e): 方案5; (f): 方案6Fig.6 Classification results of each scheme (a): Scheme 1; (b): Scheme 2; (c): Scheme 3; (d): Scheme 4; (e): Scheme 5; (f): Scheme 6 |
| 表5 各方案分类精度统计 Table 5 Classification accuracy statistics for each scheme |
从数据源方面来看, 方案1、 3、 4的整体分类精度不理想(图7), 相应的泥石流迹地信息提取精度也普遍较低(表5), 这3个方案均只涉及单一数据源Sentinel-2影像, 分类结果显示不同类别之间存在较多错分的情况。 如, 在东川主城区位置直接将人工地表错分为泥石流迹地, 在大、 小白泥沟等泥石流典型区存在较严重的漏提, 将泥石流迹地错分为人工地表, 同时在高海拔寒冷地区还存在较大面积的裸地与耕地两种类别混分的现象。 方案2、 5、 6的整体分类精度和泥石流迹地信息提取结果均较好, 这3个试验方案中均利用到Sentinel-2影像和地形数据。 这说明, 相比于单一光学数据特征, 综合利用多源数据构建的特征集融合了光学和地形数据的优势, 对整体分类精度和泥石流迹地的提取精度提高效果明显。
 | 图7 各试验方案的总体精度和Kappa系数Fig.7 Overall accuracy and Kappa coefficient for each scheme |
从利用的特征角度方面来看: 在原始光谱数据中加入本工作计算的9个指数特征后构建的试验方案3并未能提高泥石流迹地的提取精度, 反而总体精度有所下降, 说明加入的指数特征与原光谱特征存在高度特征相关或特征冗余; 在原始光谱数据中加入8个纹理特征后构建的试验方案4, 提取结果精度有所提高, 泥石流迹地的制图精度上升了7.37%, 用户精度上升了6.76%, 总体精度和Kappa系数提高了4.01%和0.05, 说明加入的纹理特征对泥石流迹地提取有一定的正向作用; 在原始光谱数据中加入3个地形特征后构建的试验方案2, 分别使泥石流迹地的制图精度和用户精度提高了17.89%和15.6%, 总体精度和Kappa系数提高了8.28%和0.10, 显然, 与指数特征和纹理特征相比, 地形特征对提高泥石流迹地提取的作用更大; 所有特征都参与的试验方案5泥石流迹地的制图精度和用户精度相比方案1分别提高了16.84%和12.61%, 总体精度和Kappa系数提高了8.15%和0.1, 虽然也取得了较好的分类效果, 但是由于存在严重的信息冗余问题, 整体提高的幅度不如方案2。 试验方案6通过特征优选保留8个有效特征, 取得了最好的分类效果, 泥石流迹地的制图精度和用户精度相比方案1分别提高了16.27%和17.27%, 总体精度和Kappa系数提高了8.92%和0.12, 比方案5和方案2均有优势。 可见, 通过特征优化的试验方案6, 不仅取得了比全部30个特征都参与分类的方案5稍好的精度, 而且有效的降低了数据量, 使得特征数减少到8个, 显著降低了信息冗余, 提高了运算效率, 分类结果碎片化的现象也明显少于其他几种分类方案(图6)。 这说明特征优选操作能提高泥石流迹地识别与提取的精度, 通过筛选保留下了对泥石流迹地提取影响更大的特征, 去除了重要性低的特征, 降低了数据维度和减少了数据冗余, 达到了提高精度的效果。
此外, 表5通过对比6种不同试验方案下7种地物类型的生产者精度和用户精度, 结果表明, 综合利用多源数据构建特征集并进行特征优选能够有效减少地物漏分和错分。 泥石流迹地在各试验方案的生产者精度和用户精度均高于74.74 %, 可见, 采用随机森林算法对泥石流迹地进行提取是可行性的。
为更深入分析各特征变量对泥石流迹地与其他地物区分能力的影响, 按重要性排序逐个加入特征变量, 并计算泥石流迹地与其他地类的J-M距离, 图8直观地展示了这一过程及其结果。 从图中可以看出, 随着特征数量的依次加入, 泥石流迹地与其他地类的J-M距离逐渐增大。
 | 图8 按重要性评分从大到小依次加入特征变量后泥石流迹地与其他地类的J-M距离Fig.8 J-M distances between debris flow site and other land types after adding the feature variables according to their importance scores from big to small |
具体来说, 当仅加入第一个特征Slope时, 泥石流迹地与其他各类地物的J-M距离均小于1, 此时区分能力较弱, 无法很好的区分各类地物, 可观察到部分永久水体被分出, 这是因为永久水体表面平整, 坡度几乎处处为零; 然而当加入第二个特征Elevation时, 泥石流迹地与冰雪的J-M距离迅速增加到1.7, 与冰雪的分离基础显著增强, 这是由于冰雪区相较于泥石流迹地区而言主要分布在区内的高海拔地区; 当加入第三个特征MNDWI后, 泥石流迹地与冰雪的J-M距离高达1.8, 已完全可以区分, 泥石流迹地与明水面和裸地的J-M距离也提升至1.3, 表明该特征进一步增加了与这3类地物的区分能力; 进一步地, 当第四个特征Green被引入时, 泥石流迹地与林地的J-M距离迅速增加至1.2, 表明其在与林地区分方面发挥了明显的作用; 随着第五个特征GLCM_diss加入后, 泥石流迹地与裸地的J-M距离继续上升至1.6, 进一步提升了与裸地的区分能力; 接着, 第六个特征Wet被引入, 不仅再次显著提高了泥石流迹地与林地的J-M距离至1.7, 还使得与人工地表的J-M距离达到1, 显示出该特征在与这两类地物区分的重要性; 当NDVI作为第七个特征被引入后, 其对泥石流迹地与耕地的区分贡献明显, J-M距离又一次得到提升, 累积到了1.6; 最后, 加入第八个特征B11, 泥石流迹地与人工地表的J-M距离再次累积, 增加至1.3。 此时, 泥石流迹地与其他所有地类的平均J-M距离达到1.77, 其中与冰雪、 林地、 明水面、 裸地的J-M距离均已超过1.8, 表现出较强的区分能力, 仅与耕地和人工地表分别是1.6和1.3。
但值得注意的是, 尽管继续增加特征变量时, 泥石流迹地与耕地、 人工地表的J-M距离仍在缓慢增加, 但增速已明显减缓(图8)。 同时, 结合图4所示的特征变量个数与分类总体精度及Kappa系数的关系, 可明确发现, 当特征累积增加至8个时, 分类总体精度和Kappa系数均达到了最优, 随后趋于平稳。 这表明, 对于本研究的分类任务而言, 8个特征变量已能提供足够的区分信息, 无需再额外增加特征以追求轻微的分离度提升。
在识别泥石流迹地的过程中, 各类特征的重要性不尽相同。 进一步地, 对提取精度最高的方案6特征组合进行分析, 不同类型的占比如表6所示。 按数据源分, Sentinel-2特征占比为75.00%, 地形数据特征占比为25.00%, 说明Sentinel-2数据是参与分类的关键基础数据源, 地形数据的补充可有效提高分量精度。 按特征类型分, 地形特征占比高达66.67%, 指数特征占44.44%, 纹理特征占12.50%, 原始光谱特征仅占10.00%; 可见, 地形特征是区分泥石流迹地最为关键的因素之一, 这是因为泥石流通常发生在具有陡峭坡度和复杂地形的区域; MNDWI、 Green、 Wet和NDVI这4个指数能够反映地表的水体分布、 植被覆盖状况及生长状态等, 对于区分泥石流迹地与水体丰富的区域或其他植被覆盖良好区域具有重要意义; 纹理特征提供了地表覆盖物的粗糙度等额外的信息, 帮助进一步细化裸地与泥石流迹地的不同; 尽管原始光谱特征是遥感分类的基础, 但在本例中其占比最低, 仅为10.00%, 这表明在复杂的地表覆盖情况下, 仅依靠光谱特征来区分泥石流迹地与其他地物存在较大的局限性。 因此, 在识别泥石流迹地时, 为了确保分类的准确性和全面性, 应当采取综合性的分类框架, 综合考虑地形特征、 指数特征、 纹理特征以及原始光谱特征等多种特征信息, 而不是仅仅局限于识别目标地类所独有的特征, 更要全方位、 多角度地审视并挖掘区内其他地类的独特特征作为参照和对比, 以达到更细致地刻画各地类间的边界, 减少误判的目的, 从而显著提升目标地类的提取精确度和能力。
| 表6 优选特征占比分布 Table 6 Distribution of the proportion of preferred features |
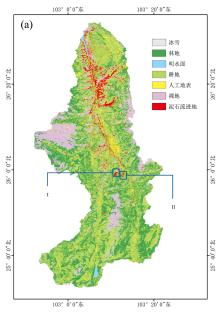
图9(a)为分类结果图, 选择小江流域内典型区域大白泥沟[图9(b)]与小白泥沟[图9(c)], 将Sentinel-2影像中两条泥石流沟迹地分布情况与6种试验分类结果图[图9(d)、 图9(e)]进行对比分析, 并结合外业采集的无人机高分辨率影像成果[图2(a)]进行验证, 本次试验共采集了293个验证点。 结果表明, 不同试验方案分类结果的制图存在较大差异。 仅从数据源看, 相较于多源数据, 以Sentinel-2影像作为单源数据的试验方案1、 3、 4[图9(d)和图9(e)]分类结果破碎, 泥石流迹地区缺失严重, 且“ 椒盐” 噪声较严重, 无法满足制图要求。 虽然分类精度统计结果(表5)显示, 加入纹理特征的方案4比方案1、 方案3整体分类精度更高, 制图结果中, 区域Ⅰ 也基本与统计结果一致[图9(d)中蓝色和绿色框], 但在区域Ⅱ 中, 方案4在泥石流迹地制图方面的效果还不如方案1和方案3, 漏分现象极为严重[图9(e)中蓝色框], 对泥石流迹地地块无法完整提取。 加入了地形特征的方案2明显比方案1、 3、 4效果好; 特征更丰富的方案5, 整体而言分类效果较方案1、 3、 4好, 但是可能由于过多特征参与分类, 造成数据冗余严重, 相较于方案2, 分类精度提高并不明显, 从制图效果来看, 甚至出现轻微的“ 破碎” 。 总体来看, 方案5中, 加入地形数据后构建的多源数据特征集, 一方面明显提高了整体分类精度, 但是在另一方面, 过多的特征参与分类同时造成数据冗余, 在对泥石流迹地的提取上带来了一定的负面影响。 对特征优选前后的试验结果进行分析, 方案6分类结果相对未进行特征优选的方案5分类结果, 分类效果有较明显的提升, “ 地物破碎” 现象得到了一定的改善, 提取到的泥石流迹地地块更完整。 进一步地, 将各方案的分类结果与无人机高分辨率影像叠加对比, 方案6一致性最高, 错分漏分现象最少, 且各类别的边界最为清晰, 明显改善了泥石流迹地与其他地物错分现象, 提高了泥石流迹地制图精度。
 | 图9(a) 分类结果图Fig.9(a) Map of spatial distribution |
 | 图9(b) 大白泥沟影像(区域Ⅰ)图9(b) Images of the Dabainigou (regionⅠ) |
 | 图9(c) 小白泥沟影像(区域Ⅱ)图9(c) Images of the Xiaobainigou (region Ⅱ) |
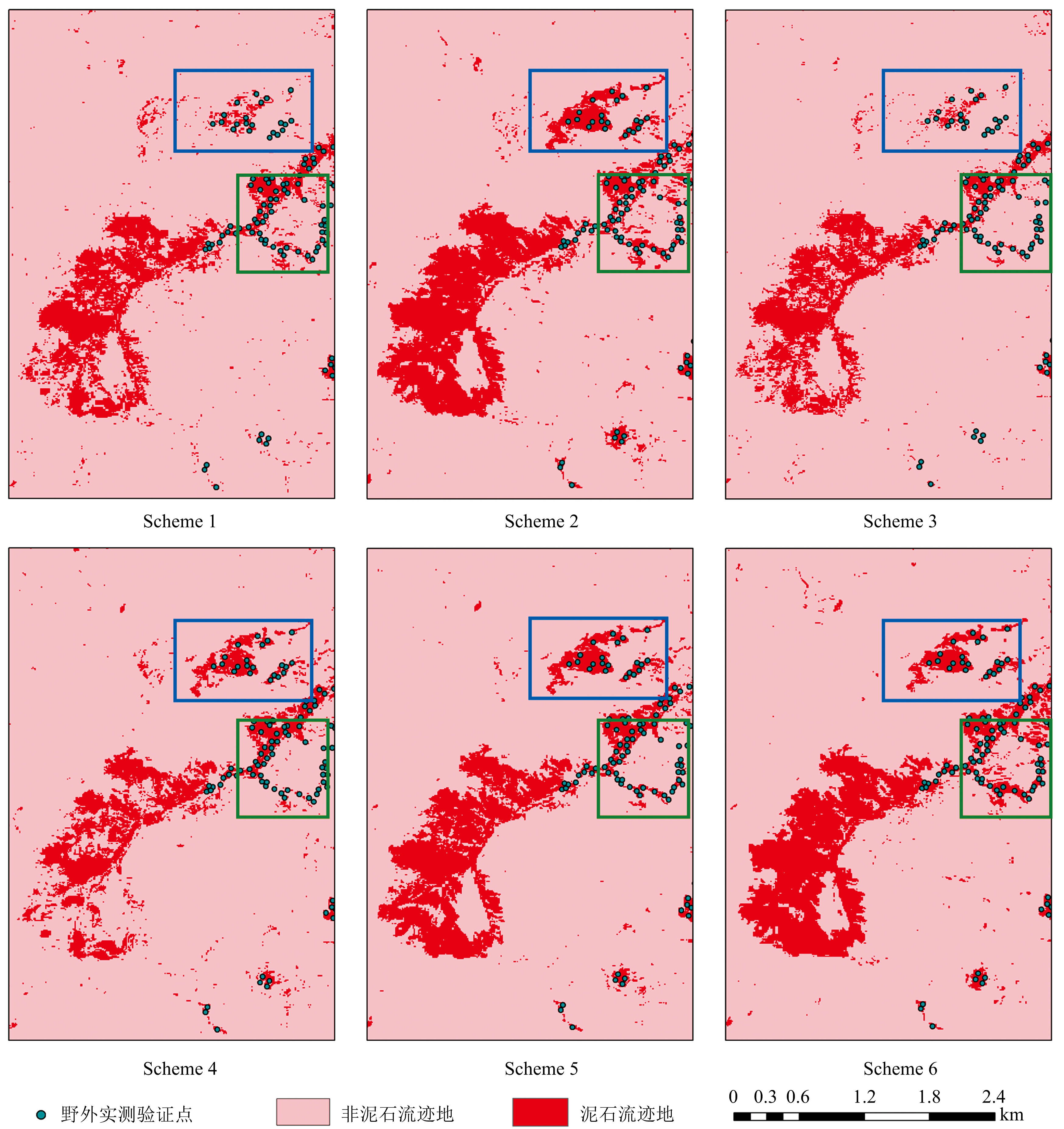 | 图9(d) 6种试验方案在区域Ⅰ 的提取结果图9(d) Classification results of six schemes in region Ⅰ |
 | 图9(e) 6种试验方案在区域Ⅱ 的提取结果图9(e) Classification results of six schemes in region Ⅱ |
通过以上研究及分析, 充分说明进行特征优选的试验方案6是几组方案里效果最佳的提取方案。 因此采用该方案作为最终的小江流域泥石流迹地提取方案。 由泥石流迹地空间分布图[图9(a)]可以发现, 小江流域的泥石流迹地主要分布在小江两岸的侧切沟, 靠北段比南段分布数量更多, 密度更大。
依托Google Earth Engine云平台, 结合哨兵2影像和SRTM DEM数据, 构建多维特征集, 设置了多种分类方案, 对比分析优选特征性能, 深入探讨了光谱、 指数、 纹理及地形特征的作用, 并运用随机森林算法, 实现流域尺度泥石流迹地提取, 提升了泥石流迹地信息提取的精度。 主要得出以下结论:
(1)在泥石流迹地提取时, Sentinel-2光学遥感数据融入地形数据后的多源特征组合比单一Sentinel-2数据特征得到的分类精度普遍更高, 说明多源数据融合能优势互补, 有效提高泥石流迹地识别的精度。
(2)利用随机森林算法对泥石流迹地特征重要性进行评分, 实现特征优选。 对比实验显示, 融合Sentinel-2与地形数据的多源数据特征集并进行优选操作的方案6, 总体精度达94.95%, Kappa系数为0.94, 泥石流迹地制图精度与用户精度分别为91.01%和95.29%, 为最优方案。 相比于包含所有30个特征的方案5, 方案6不仅精简数据, 消除冗余, 还提升了分类精度, 验证了特征优选在提升泥石流迹地识别效能上的关键作用。
(3)在泥石流迹地识别与提取中, 优选特征包括地形(坡度、 高程)、 指数(MNDWI、 绿度、 湿度、 NDVI)、 纹理(GLCM_diss差异性)及光谱(短波红外B11)。 这些特征对识别精度贡献显著不同, 重要性排序由高到低依次为: 地形特征、 指数特征、 纹理特征、 光谱特征。
(4)多源数据融合、 特征优选均能够提高泥石流迹地识别与提取精度。 方案6是基于多源数据并进行特征优选得到的最优特征组合方案, 该方案采用随机森林算法, 可高效绘制出小江流域泥石流迹地精准空间分布图。
本工作为较大范围地物覆盖复杂地区的泥石流迹地信息提取提供了一套新的方法和技术流程。 在利用J-M距离进行选用特征的可分离性分析时发现, 研究区内区分难度较大的地物类型主要为人工地表与泥石流迹地, 后续将在本研究的基础上, 从以下几个方面继续深入研究: 一方面加强对人工地表和泥石流迹地的研究, 可以进一步扩展SAR、 航空遥感、 LiDAR等多源遥感数据特征变量, 引入合适特征以提高人工地表和泥石流迹地的分类精度, 不断提高多源遥感数据在地质灾害方面的应用研究; 另一方面, 知识图谱和深度学习等技术为代表的新一代遥感影像智能解译方法的出现为泥石流地质灾害的精确提取提供了新的研究思路, 特征提取过程不需要或仅需少量人为参与, 能够有效提取目标本质、 抽象出有用特征, 且具有较强的面向大数据处理的能力, 但是对抽象出的有用特征的相关分析和解释还比较缺乏, 下一步将从特征优选出发, 探讨特征优选得到的特征子集是否能更有利于提升深度学习算法在泥石流迹地提取的精度。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|