










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于1DCNN和PLSDA酸枣仁真伪高光谱图像鉴别中的关键特征分析
[赵昕1, 4  , 石玉娜
, 石玉娜1 , 刘怡彤1 , 姜洪喆2 , 褚璇3 , 赵志磊1, 4 , 王宝军1, 4, * , 陈晗1 ]
, 石玉娜, 陈晗|
|


作者简介: 赵 昕,女, 1992年生,河北大学质量技术监督学院讲师 e-mail: zhaoxinzj@hbu.edu.cn
酸枣仁因其养心益肝的功效, 是安神助眠类保健品和中药制剂的重要原料。 目前市售酸枣仁掺假现象严重, 极大损害了消费者利益, 扰乱了市场秩序。 传统人工检测或基于实验室的高效液相色谱方法存在效率低, 推广难的问题。 本研究基于卷积神经网络和偏最小二乘判别提出了一种高光谱成像酸枣仁真伪鉴别方法, 并对两类模型中的关键光谱特征进行了讨论研究, 为后续多光谱系统和便携式仪器开发提供借鉴。 提取酸枣仁及其常见伪品(理枣仁、 兵豆和枳椇子)高光谱图像(400~1 000 nm)中所有单籽粒的平均光谱。 基于平均光谱分别建立偏最小二乘判别分析(PLSDA)模型和一维卷积神经网络(1DCNN)模型。 PLSDA建模前采用竞争性自适应重加权算法(CARS)挑选特征波长。 在1DCNN模型中添加了自定义波长选择层, 并对卷积层和全连接层输出结果应用t分布随机邻域嵌入(t-SNE)进行可视化分析。 为了与CARS-PLSDA模型进行有效对比, 构建了基于五个波长的5W-1DCNN模型。 结果表明CARS-PLSDA和1DCNN模型都能获得理想的预测效果, 校正集和预测集分类正确率均在99%以上。 对比CARS与自定义层挑选的特征波长, 670、 721和850 nm附近的波长在两种模型中均具有重要作用。 研究结果为酸枣仁真伪快速鉴别的多光谱和便携式检测设备提供参考。
, SHI Yu-na, CHEN HanZiziphi spinosae semen is an important raw material of health care products and traditional Chinese medicine preparations because it nourishes the heart and the liver, making it ideal for calming the nerves and helping sleep. At present, the adulteration of ziziphi spinosadsemen in the market is serious, which greatly damages the interests of consumers and disrupts the market order. Traditional manual detection or laboratory-based high-performance liquid chromatography methods have problems of low efficiency and difficult promotion. In this study, a hyperspectral imaging method for ziziphi spinosadsemen authenticity identification was proposed based on convolutional neural network and partial least squares discrimination, and the key spectral features in the two types of models were discussed and studied. The study will reference the subsequent development of multispectral systems and portable instruments. The average spectra of all single kernels in the hyperspectral images (400~1 000 nm) of ziziphi spinosae semen and its common counterfeits (Ziziphus mauritiana lam, Hovenia dulcis Thunb. and Lens culinaris) were extracted. The partialleast squares discriminant analysis (PLSDA) model and the one-dimensional convolutional neural network (1DCNN) model were respectively established based on the average spectra. The competitive adaptive reweighting algorithm (CARS) selects characteristic wavelengths before PLSDA modeling. A custom wavelength selection layer was added to the 1DCNN model. T-distributed stochastic neighborhood embedding (t-SNE) was applied to the outputs of convolutional and fully connected layers for visual analysis. To effectively compare with the CARS-PLSDA model, a 5W-1DCNN model based on five wavelengths was constructed. The results showed that both the CARS-PLSDA and1DCNN models could achieve precision prediction results, and the classification accuracies of both the calibration set and the prediction set are above 0.99. Comparing the feature wavelengths selected by CARS and custom layers, wavelengths near 670, 721, and 850 nm play important roles in both models. The research results provided a reference for multispectral systems and portable equipment for rapid detection of the authenticity of ziziphi spinosad semen.
酸枣仁为鼠李科植物酸枣(Ziziphus jujuba Mill. var. spinosa (Bunge) Hu ex H. F. Chou)的干燥成熟种子, 是现代中医临床常用的镇静安神类中药和我国首批药食同源的中药材之一。 酸枣分布广泛以野生资源为主。 随着人们生活节奏加快, 酸枣仁市场需求量增加, 野生资源萎缩, 导致价格攀升。 不法商贩为谋取暴利, 常掺伪掺杂。 中国食品药品检定研究院在中药材及饮片抽验中发现, 掺假是酸枣仁的主要质量问题[1]。
根据中华人民共和国药典(2020版), 酸枣仁的质量评估方法主要有性状鉴别、 薄层色谱法和高效液相色谱法。 然而性状鉴别基于物理外观特征, 需要有经验的药师人工检查, 主观性强, 效率低。 后两种方法聚焦于关键化学成分, 需要精密昂贵的分析仪器, 且要对样品进行复杂繁琐的化学前处理。 以上方法都只能采用抽样送检方式, 导致监管流程长, 效率低, 极大限制了市场流通各环节的监管效力。 随着现代化加工环境和数字网络化物流发展, 能实现现场快速实时评价的检测技术亟待研发。 高光谱成像技术有机融合了机器视觉和近红外光谱技术, 能快速、 无损获得被测样本的物理外观和内部化学成分信息, 在谷物[2]、 禽肉[3]和果蔬[4]的质量评估领域, 已实现了现场在线分析应用。
高光谱图像具有维度高、 数据量大的优点, 同时其共线性、 冗余性和维数灾难等问题使得模型构建和有效信息挖掘成为关键挑战。 对此, 偏最小二乘(partial least squares, PLS)、 支持向量机(support vector machines, SVM)、 随机森林(random forest, RF)等经典机器学习算法, 常结合连续投影算法(successive projections algorithm, SPA)、 竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)和遗传算法(genetic algorithm, GA)等波长筛选方法, 提取数据中与目标量相关的关键特征, 构建定性定量预测模型。 林珑等[5]采用SPA算法挑选了8个特征波长, 建立了SVM判别模型, 对东北/非东北大米进行鉴别。 李威等[6]选用CARS和SPA算法提取特征波长, 分别建立了多元线性回归(multiple linear regression, MLR)模型和偏最小二乘回归(partial least squares regression, PLSR)模型, 实现了芒果表面轻微损伤的有效鉴别。 以上列举的数据分析中, 建模前需要特征变换和提取等特征工程, 且特征选择的结果对模型表现具有重要影响[7]。
近年来, 深度学习发展如火如荼, 基于端到端的建模思想, 能够从原始数据中自动提取隐藏特征, 避免了复杂的人为特征设计。 卷积神经网络(convolutional neural network, CNN)是最典型的深度学习算法之一, 基于多层卷积结构, 能够捕捉细微光谱差异, 构建精确的非线性数学模型。 高文强等[8]利用一维卷积神经网络研究了紫丁香叶片叶绿素含量预测。 王蓉等[9]构建了基于主成分分析算法的一维卷积神经网络模型, 检测粮食作物主要成分的含量。 尽管CNN简化了特征工程, 但也导致模型无法进行解释性分析。 Zhou等[10]通过添加具有可学习权重系数的自定义层, 获取了建模关键波长, 实现了CNN模型的解释性分析。 Meng等[11]利用一种基于流形学习的可视化方法, 即t分布-随机邻域嵌入(t-distributed stochastic neighbor embedding, t-SNE)可视化CNN模型提取的深度特征, 分析模型对高光谱卫星图像中作物的鉴别区分能力。
理枣仁、 枳椇子和兵豆是市售酸枣仁中的常见掺杂物。 综上, 本研究开发一种基于高光谱成像技术的酸枣仁真伪无损鉴别方法, 分别利用1DCNN结合自定义波长选择层和t-SNE可视化方法, 以及基于CARS特征提取的PLSDA建模。 对比1DCNN和CARS-PLSDA模型中的重要波长, 进一步明确酸枣仁鉴别区分中的关键特征, 为后续多光谱或便携式仪器开发提供理论基础。
实验所用酸枣仁及其伪品理枣仁、 兵豆和枳椇子, 购买于河北安国中药材市场远光药业有限公司。 选样过程中人工去除一些破损、 干瘪和过小籽粒, 每类样本选取400粒完整饱满籽粒, 置于4个玻璃培养皿中均匀分布。 每类样品按照3: 1的比例随机划分校正集(300粒)和预测集(100粒)。
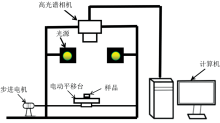
系统主要由高光谱相机、 光源、 电动平移台和步进电机等构成(图1所示)。 选用杭州彩谱科技有限公司的FS-13型高光谱相机采集酸枣仁及其伪品的高光谱图像, 光谱范围为400~1 000 nm, 光谱分辨率为2.2 nm, 图像分辨率为0.1 mm· 像素-1。 为消除仪器暗电流和环境光变化等引入的干扰噪声, 样本采集前, 先采集黑白参考, 用于对获得的高光谱图像进行校正。
 | 图1 高光谱成像系统示意图Fig.1 Schematic diagram of hyperspectral imaging system |
对原始高光谱图像进行裁剪拼接。 利用主成分分析和二维散点图提取籽粒感兴趣区域并构建掩模图像, 基于掩模图像提取单籽粒样品的平均光谱。
1.3.1 卷积神经网络
1DCNN模型架构如图2所示。 采用2个卷积层进行特征提取, ReLu作为激活函数, 每个卷积层后面增加了最大池化层, 以去除一些无信息的特征。 参考Zhou等[10]方法, 通过在输入层之后添加一个自定义选择层来实现关键波长选择。 该选择层按照元素乘法操作, 定义的可学习权重表示相应波段的重要程度。 训练采用交叉熵损失函数(cross-entropy loss), 使用Adam优化器。 学习率、 迭代次数(epoch)和批尺寸(batch size)分别设置为0.000 5, 4 800和50。
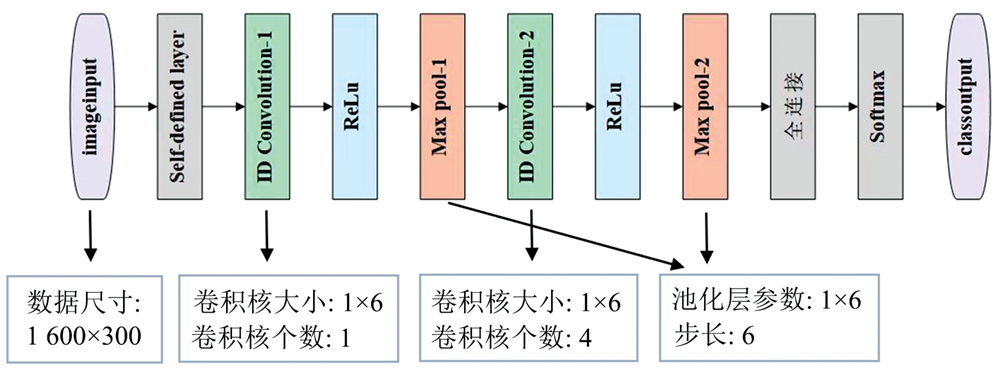 | 图2 1DCNN网络结构图Fig.2 Diagram of 1DCNN network structure |
1.3.2 t分布随机邻域嵌入
t分布随机邻域嵌入(t-SNE)是一种非线性的机器学习算法, 通过映射变换将每个数据点映射到相应的概率分布, 并在低维空间里也保持其在高维空间里所携带的信息[12], 有效实现数据的降维并进行数据可视化。 本研究中, 将每个卷积层和全连接层的输出数据输入t-SNE进行降维可视化。
1.3.3 偏最小二乘判别分析
偏最小二乘判别分析(partial least squares discriminant analysis, PLSDA)是一种用于定性分类的多变量统计分析方法, 在对样本数据降维后, 建立回归模型, 并对结果进行分类判别。
1.3.4 竞争性自适应重加权采样
竞争性自适应重加权采样(CARS)是基于蒙特卡罗(MC)采样和偏最小二乘(PLSR)模型中回归系数的一种特征波长变量选择方法, 旨在筛选出最具有核心竞争力的波长组合。 利用CARS对原始数据进行重要波长选择, 减少光谱特征的冗余信息, 提高计算速率。
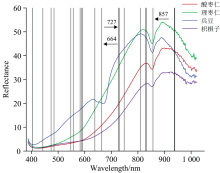
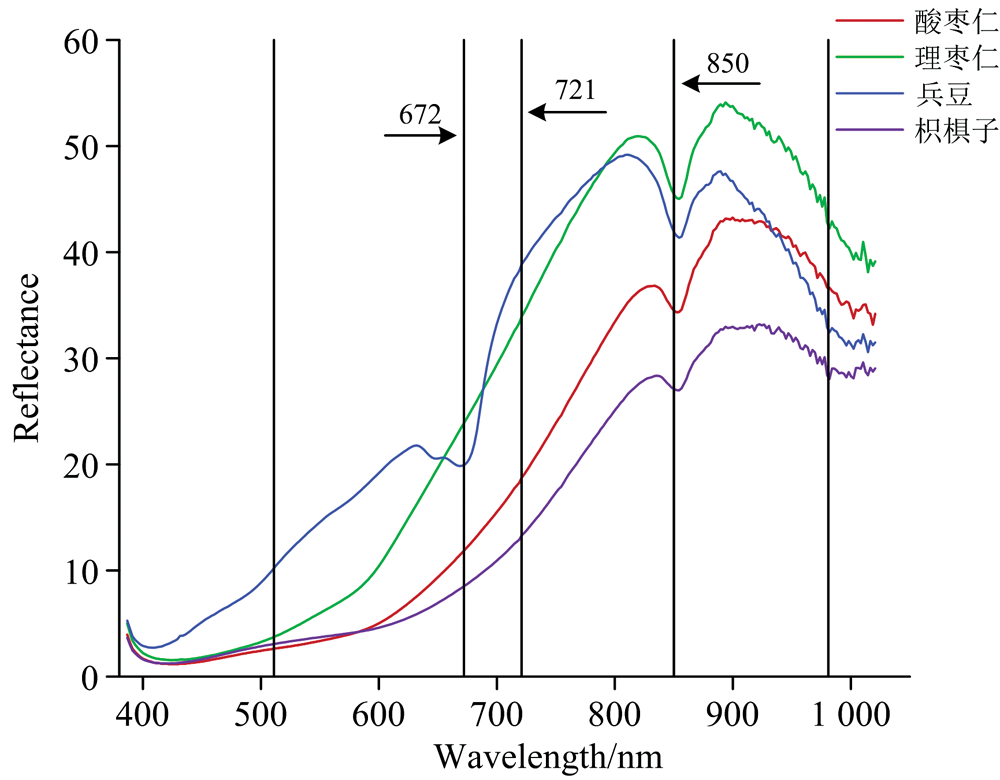
图3所示为酸枣仁及伪品理枣仁、 兵豆和枳椇子的平均光谱及误差带。 由图可知, 酸枣仁及三种伪品的平均光谱曲线整体轮廓较相似, 反射率及其变化程度存在差异, 理枣仁和兵豆的反射率值总体高于酸枣仁和枳椇子。 由于400~1 000 nm主要反映颜色特征, 酸枣仁和枳椇子颜色最接近, 理枣仁颜色较浅, 故酸枣仁和枳椇子的平均光谱曲线最为相似, 理枣仁整体反射率值较高。 酸枣仁及三种伪品均在832和891 nm附近有波峰, 854 nm处为波谷。 兵豆在632和670 nm处还有一个波峰和波谷。 Zerbini等[13]在对芒果的光学特性研究中指出670 nm附近的波段为叶绿素a吸收区。 Siedliska等[14]在对草莓果实进行高光谱成像技术检测研究中指出842 nm附近的峰与糖的O— H键拉伸振动有关。 880~900 nm范围内出现的峰与水分中的O— H官能团拉伸的第三泛音有关[15]。 综上表明, 平均光谱中的峰、 谷主要反映了样品中叶绿素、 水和糖等主要成分的信息。
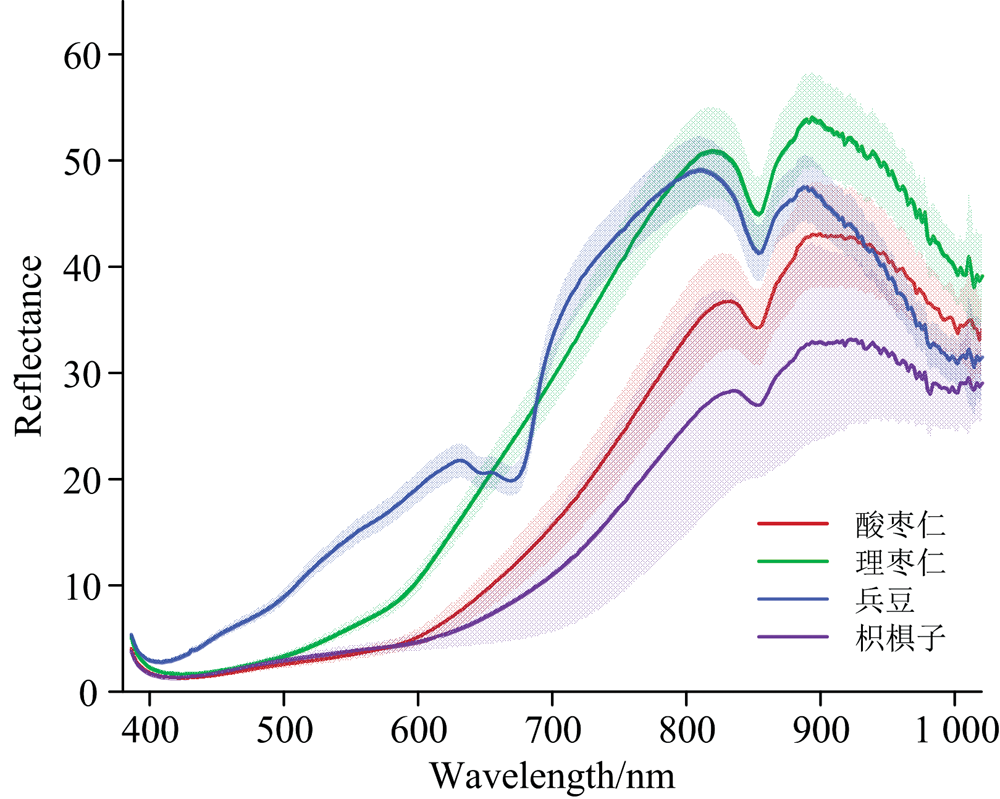 | 图3 酸枣仁及三种伪品的平均光谱及误差带Fig.3 Average spectra and error bands of ziziphi spinosae semen and three kinds of counterfeits |
2.2.1 CARS特征变量选择
图4为CARS特征变量筛选结果。 图4(a)显示了蒙特卡洛采样次数和采样变量数之间的关系。 筛选波长的速度随运行次数的增加而减慢, 在前30次采样中, 采样变量数快速下降, 体现出了CARS算法粗略选择波长的过程; 当运行次数大于30后, 波长变量筛选速度越来越慢, 波长数量也越来越少, 表现了CARS算法对变量精选的过程。 由图4(b)可知, 运行次数在81次时, RMSECV值达到最小, 说明在运行第81次时, 基本上已完成波长剔除工作。 之后的运行过程可能淘汰了比较重要的相关波长变量, 因此导致RMSECV值增大。 图4(c)中, “ * ” 对应的RMSECV值最小且变量数最少, 即第81次采样。
 | 图4 CARS特征变量筛选 (a): 波长数量的变化趋势图; (b): RMSECV的变化趋势图; (c): 波长变量回归系数的变化趋势图Fig.4 CARS feature variable screening (a): Trend chart of the number of wavelengths; (b): Trend chart of RMSECV; (c): Regression coefficients vs sampling runs |
经CARS特征波长提取后, 共得到5个重要波长, 分别为: 511、 672、 721、 850和981 nm, 它们在原始光谱上的分布如图5所示。 675 nm附近的波长可能与种皮中的叶绿素a、 b以及花青素有关[16], 反映了种皮的颜色。 720 nm附近的波段与样品内部的碳水化合物有关[17]。
 | 图5 挑选的5个特征波长在原始光谱曲线上的分布Fig.5 Distribution of the 5 selected characteristic wavelengths on the original spectral |
2.2.2 PLSDA分类模型结果分析
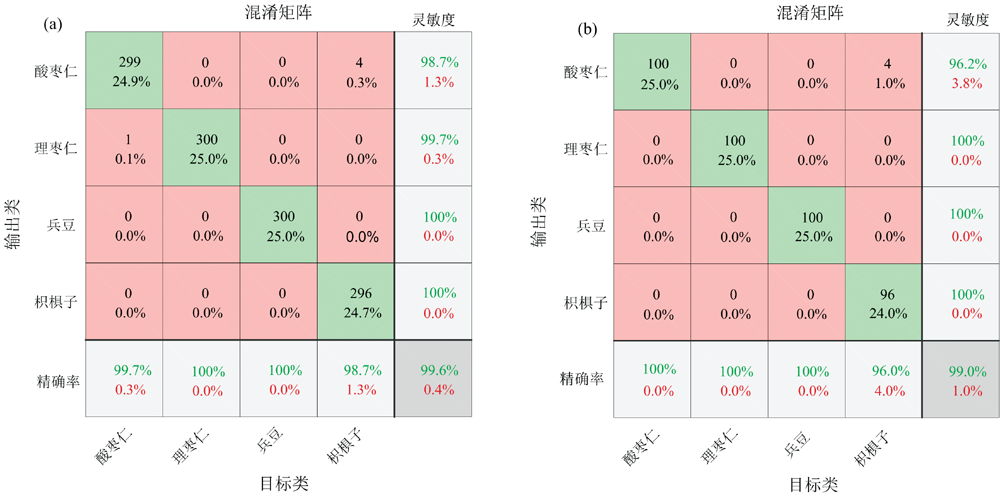
CARS-PLSDA判别模型的混淆矩阵如图6所示。 样品的灵敏度和精确率均大于等于96%, 校正集的总体准确率为99.6%, 预测集的总体准确率为99.0%。 由图可知, 校正集中酸枣仁样品有1个错判为理枣仁, 枳椇子样品中有4个误判为酸枣仁。 在预测集中, 酸枣仁样品全部判别正确, 枳椇子中有4个样品错判为酸枣仁。 原因可能是酸枣仁与枳椇子具有相近的颜色和光谱特征。 模型对部分样本的可视化预测结果如图7所示, 四类样本均被正确鉴别。 图7(a)为基于R: 700 nm 、 G: 546 nm 和B: 438 nm 波段的伪彩色图像。
 | 图6 CARS+PLSDA模型结果混淆矩阵 (a): 校正集; (b): 预测集Fig.6 Confusion matrices of CARS+PLSDA modeling results (a): Correction set; (b): Prediction set |
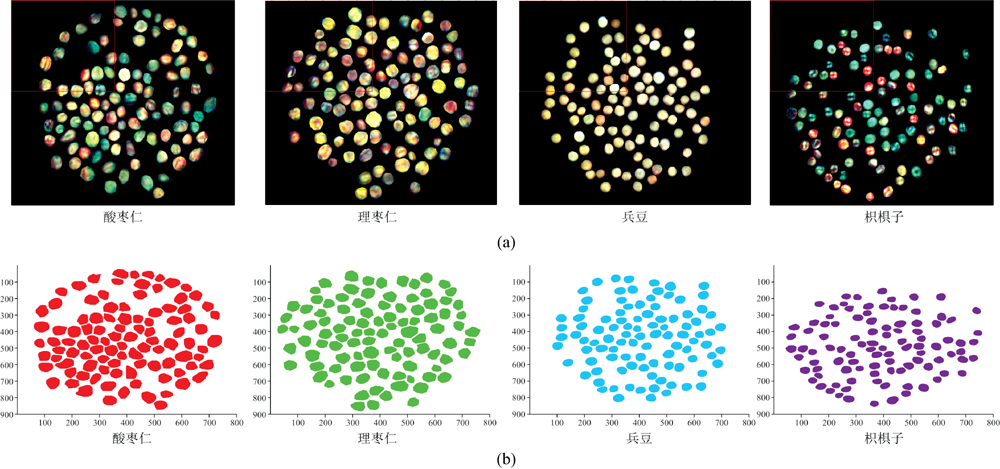 | 图7 CARS+PLSDA模型结果可视化图 (a): 伪彩色图像(R: 700 nm 、 G: 546 nm 和B: 438 nm); (b): 可视化结果Fig.7 Visualization of CARS+PLSDA modeling results (a): Pseudo color image(R: 700 nm, G: 546 nm, B: 438 nm); (b): Visualization results |
2.3.1 自定义层特征选择
从训练好的1DCNN模型的自定义选择层获得一组权重向量, 该向量与原始光谱向量具有相同的维度, 即1× 300。 权重参数数值大小被认为可以反映波长在建模任务中的重要性。 在光谱特征的选择中, 通常期望以较少的波长提供足够的信息; 相对复杂的数据集, 通常接受10~20个左右的选定特征[10]。 本工作选取了对应权重绝对值最大的前20个特征波长, 其在原始光谱上的分布如图8所示。 分别为405、 443、 474、 485、 548、 557、 583、 587、 591、 638、 664、 727、 729、 748、 809、 828、 832、 857、 937和939 nm。 其中664、 727和857 nm与CARS挑选的波段中的672、 721和850 nm较为接近。 858 nm附近的波段主要归因于样本中C— H基团的三级倍频。
 | 图8 挑选的20个特征波长在原始光谱曲线上的分布Fig.8 Distribution of 20 selected characteristic wavelengths on the original spectra |
2.3.2 1DCNN分类模型
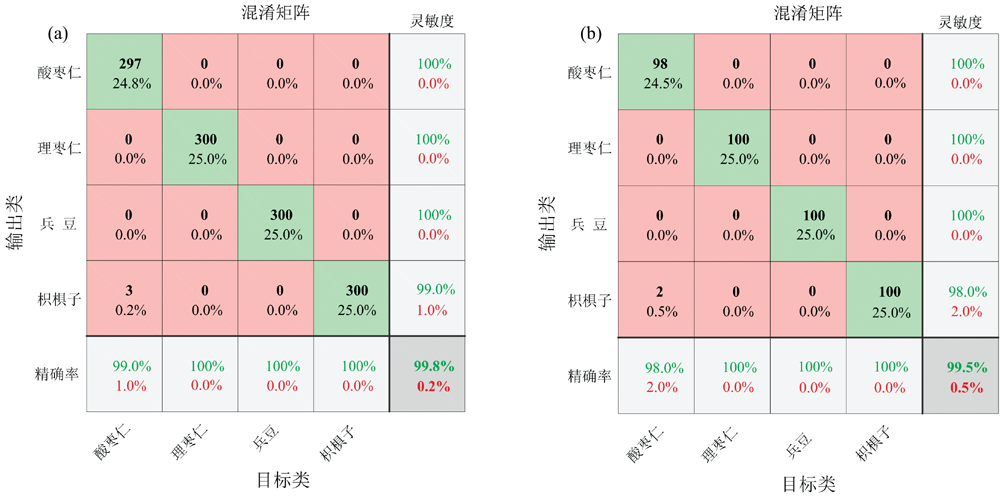
图9为经1DCNN模型分类后校正集和预测集的混淆矩阵。 样品的灵敏度和精确率均大于等于98%, 校正集的总体准确率为99.8%, 预测集的总体准确率为99.5%, 模型预测精度略优于CARS-PLSDA。 由图可知, 误差主要是酸枣仁被误判为枳椇子。 在校正集的300个酸枣仁样本中, 有297个判别正确, 有3个误判为枳椇子。 在预测集的100个酸枣仁样品中, 有两个误判为枳椇子。 与PLSDA模型相比, 1DCNN模型判别误差主要是正品被误判为伪品, 从实际检测应用来说, 具有更好的安全性。
 | 图9 1DCNN模型结果混淆矩阵 (a): 校正集; (b): 预测集Fig.9 Confusion matrices of 1DCNN modeling results (a): Correction set; (b): Prediction set |
为了进一步了解1DCNN模型的分类过程, 利用t-SNE方法对两个卷积层与全连接层的输出结果进行了降维可视化, 结果如图10所示。 由图可知, 经卷积层处理后的数据, 可以清楚分离出理枣仁和兵豆, 但酸枣仁和枳椇子仍有一定程度的混淆。 全连接层输出的数据, 各类样本数据具有很好的可分性, 仅有个别酸枣仁和枳椇子数据点重合混淆。
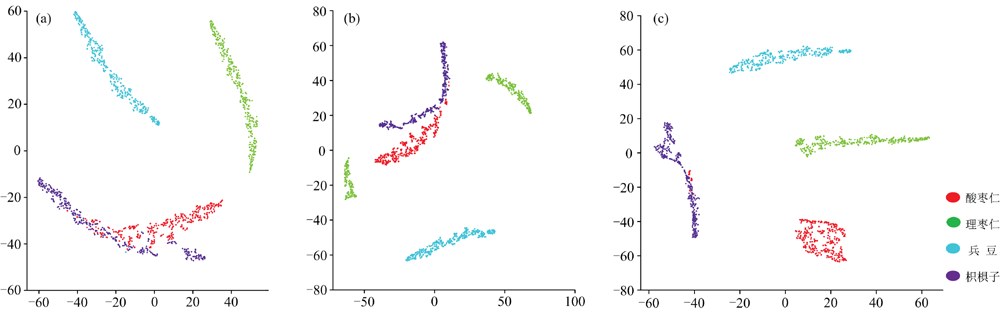 | 图10 t-SNE可视化分析 (a): 第一层卷积; (b): 第二层卷积; (c): 全连接层Fig.10 t-SNE visualization analysis (a): The first convolutional layer; (b): The second convolutional layer; (c): Fully connected layer |
1DCNN模型对部分样本预测的可视化结果如图11所示, 四类样本同样均被正确判别。
 | 图11 1DCNN模型结果可视化图 (a): 伪彩色图像(R: 700 nm、 G: 546 nm 和B: 438 nm); (b): 可视化结果Fig.11 Visualization results of 1DCNN modeling (a): Pseudo color image (R: 700 nm, G: 546 nm, B: 438 nm); (b): Visualization results |
2.3.3 5W-1DCNN分类模型结果分析
从自定义层的权重向量中, 挑选权重绝对值最大的前5个特征波长, 建立5W-1DCNN分类模型。 5W-1DCNN模型结构在图2所示结构的基础上去掉自定义选择层, 输入层数据尺寸相应修改为1 600× 5, 第一层卷积尺寸修改为1× 2× 1, 第二层卷积尺寸修改为1× 2× 4, 最大池化层参数改为1× 1, 其余参数不变。 5个特征波长分别为557、 748、 809、 857和937 nm。 模型校正集和预测集的混淆矩阵如图12所示。 校正集的总体准确率为100%, 预测集的总体准确率为99.5%。 在预测集的100个酸枣仁样品中, 有2个误判为枳椇子。 5W-1DCNN模型与1DCNN模型预测效果基本相同, 但模型输入大幅度减小, 有助于降低检测硬件成本。 与CARS-PLSDA模型相比, 5W-1DCNN模型预测效果更好。 模型对部分样本的可视化预测结果如图13所示。
 | 图12 5W-1DCNN模型结果混淆矩阵 (a): 校正集; (b): 预测集Fig.12 Confusion matrices of 5D-1DCNN modeling results (a): Correction set; (b): Prediction set |
 | 图13 5W-1DCNN模型结果可视化图 (a): 伪彩色图像(R: 700 nm、 G: 546 nm和B: 438 nm); (b): 可视化结果Fig.13 Visualization results of 5W-1DCNN model (a): Pseudo color image (R: 700 nm, G: 546 nm, B: 438 nm); (b): Visualization results |
上述结果表明, CARS-PLSDA和1DCNN模型均能实现酸枣仁和伪品理枣仁、 兵豆和枳椇子的有效判别。 5W-1DCNN模型分类效果略优于CARS-PLSDA。 CARS-PLSDA模型需要进行人工特征筛选, 1DCNN建模过程中可以自动实现特征筛选, 但基于数据驱动的建模所需样本数量和质量要求较高。 CARS和自定义选择层特征分析表明, 两种模型具有类似/相近分布的特征波长, 这些波长与样本表面颜色和内部成分特征相关。
本研究中所使用的高光谱图像波段范围为可见近红外波段(400~1 000 nm), 与短波红外波段(1 000~2 500 nm)相比, 可见近红外波段主要反映可视特征及与颜色相关的内部成分信息。 酸枣仁与三种伪品: 理枣仁、 兵豆和枳椇子在外观颜色、 纹理等特征上存在差异, 可有效被可见近红外高光谱图像捕获。 短波红外高光谱图像在内部成分信息的反映上更具优势, 对于不同品种的酸枣仁及伪品, 同样具有分类鉴别的可行性。 但是短波红外高光谱相机价格更高, 在可见近红外波段图像已有良好分类效果的条件下, 不是检测方案的最优选择。 未来对于粉状酸枣仁等初加工产品的鉴别检测研究, 由于样本的物理形态被破坏, 可优选短波红外高光谱图像进行深入研究。
利用近红外高光谱成像技术研究了酸枣仁及其常见3种伪品, 即理枣仁、 兵豆和枳椇子的定性判别方法。 对比分析了CARS-PLSDA和1DCNN两种分类模型。 其中1DCNN模型中添加了自定义层进行特征波长选择, 并结合t-SNE算法进行可视化分析。 为了方便对比分析, 进一步建立了与CARS-PLSDA模型具有相同输入量(5个波长)的5W-1DCNN模型。 CARS-PLSDA模型校正集和预测集的总体准确率分别为99.6%和99.0%; 1DCNN模型校正集和预测集的总体准确率分别为99.8%和99.5%; 5W-1DCNN模型校正集和预测集的总体准确率分别为100%和99.5%。 CARS-PLSDA模型和1DCNN模型均可对酸枣仁及其伪品进行有效区分, 其中1DCNN模型预测为酸枣仁的样本精度更高, CARS-PLSDA模型预测为酸枣仁的样本中容易混入枳椇子, 因此1DCNN模型效果更优。 两种模型均挑选了位于670、 721和850 nm附近波长为关键特征。 本研究结果为后续酸枣仁真伪鉴别便携式仪器或多光谱检测系统开发提供参考依据和理论基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|