


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于FOD和最优光谱特征的高光谱水质参数反演模型
[张雨晴1, 2  , 赵起超
, 赵起超1, 2, * , 刘其悦1, 2 , 房红记1, 3 , 韩文龙1, 4 , 陈雯玥1, 2 ]
, 赵起超, 刘其悦|
|


作者简介: 张雨晴, 女, 1999年生, 北华航天工业学院遥感信息工程学院硕士研究生 e-mail: 2060643048@qq.com
准确高效获取水体叶绿素a(Chl-a)浓度是水体富营养化情况改善和可持续发展的前提。 以水面野外高光谱反射率和实测水体Chl-a浓度为数据源, 利用分数阶微分(FOD)对原始光谱反射率进行步长为0.1的处理, 通过探寻光谱数据与水体Chl-a浓度之间的相关性来筛选特征波段, 构建可变阶光谱数据集。 使用偏最小二乘模型(PLS)筛选最优特征构建数据集; 按照7∶3的比例划分为建模集和验证集; 采用支持向量机(SVM)和深度森林(DF)模型建立水体Chl-a浓度反演模型, 并与采用原始数据直接构建模型以及常见降维方法构建的模型进行对比验证。 结果显示: FOD技术可以在一定程度上减弱高光谱噪声并挖掘潜在光谱信息, 提高高光谱反射率与水体Chl-a浓度的相关性。 利用FOD结合PLS先筛选特征再建立的水体Chl-a浓度反演模型相较于利用原始数据以及PCA降维后建立的水体Chl-a反演模型来说, R2均有所提高, 均方误差MSE和平均绝对误差MAE均有所下降。 其中DF相对于其他三种模型具有较高的拟合度, 预测精度也相对较高, 建模集 R2=0.96, MSE=0.51 μg·L-1, MAE=0.64 μg·L-1; 验证集 R2=0.89, MSE=0.69 μg·L-1, MAE=0.64 μg·L-1。 总体来看, 基于FOD重组后的可变阶光谱数据集和PLS优选特征建立水体Chl-a浓度反演模型是可行的; 对比分析构建的其他模型反演结果发现, DF对水体Chl-a的反演效果较好。 该工作为内陆二类水体Chl-a高光谱遥感反演提供一定的理论依据和技术支持, 助力白洋淀水质持续监测, 也为以后高光谱卫星遥感影像反演Chl-a提供新思路。
, ZHAO Qi-chao, LIU Qi-yueAccurate and efficient acquisition of chlorophyll-a (Chl-a) concentration in water is the prerequisite for improving eutrophication and sustainable development of water bodies. This study used the hyperspectral reflectance of the water surface and the measured Chl-a water concentration as data sources. The original spectral reflectance was processed with a step size 0.1 by fractional order differentiation (FOD) technology. The characteristic bands were screened by exploring the correlation between the spectral data and the Chl-a concentration of the water body, and the variable-order spectral dataset was constructed. The Partial Least Squares (PLS) model was used to screen the optimal features to construct the dataset, which was divided into modeling set and verification set according to the ratio of 7∶3, and the support vector machines (SVM) and deep forest (DF) models were used to establish the water Chl-a concentration inversion model. It is also compared with the model constructed using the original data and the model constructed by common dimensionality reduction methods. The results show that FOD technology can reduce hyperspectral noise, mine potential spectral information to a certain extent, and improve the correlation between hyperspectral reflectance and the concentration of Chl-a in water. Compared with the Chl-a inversion model established by using the original data and PCA dimension reduction, the R2 of the water Chl-a concentration inversion model established by FOD combined with PLS first screening features was increased, and the mean square error (MSE) and mean absolute error (MAE) were reduced. DF has a higher degree of fitting and prediction accuracy than the other three models, with R2=0.96, MSE=0.51 μg·L-1, and MAE=0.64 μg·L-1. The validation set R2=0.89, MSE=0.69 μg·L-1, MAE=0.64 μg·L-1. In general, it is feasible to establish a water Chl-a concentration inversion model based on the variable-order spectral dataset after FOD recombination and the preferred features of PLS. Comparative analysis of the inversion results of other models shows that DF has a good inversion effect on water Chl-a. This work provides a theoretical basis and technical support for the inversion of hyperspectral remote sensing of Chl-a in inland second-class water bodies, helps the continuous monitoring of water quality in Baiyangdian Lake, and also provides new ideas for the inversion of Chl-a from hyperspectral satellite remote sensing images in the future.
水体富营养化现象在湖泊中普遍存在, 它是指在多种因素下, 水体中的氮、 磷等营养物质富集, 致使水环境质量恶化的一种水污染现象[1]。 水体富营养化是目前全球水生生态系统面临的重要环境问题之一[2]。 白洋淀是华北地区最大的淡水湿地, 同时也是典型的浅水型湖泊, 因此被称为“ 华北之肾” 。 但是近年来, 随着经济的高速发展、 地理位置的限制以及旅游业的发展等因素, 水环境受到不同程度的污染, 进而导致水体富营养化。 叶绿素a(chlorophyll-a, Chl-a)可以有效反映水体富营养化程度, 是估算水中藻类生物量、 评价水体初级净生产力的重要指标。 水体Chl-a浓度的快速获取和准确监测对综合整治改善白洋淀水环境以及恢复白洋淀生态环境的良性循环有重要参考意义。
近年来, 国内外学者利用遥感技术对水体Chl-a浓度的监测和预测开展了较多研究。 高光谱遥感技术具有相邻波段相关性强和光谱分辨率高的优点, 可有效应用于水体Chl-a浓度的快速获取。 利用高光谱估算Chl-a浓度的研究中, 主要通过反射率原始数据[3]、 对数变换数据[4]、 微分变换数据[5]与Chl-a浓度的关系, 构建Chl-a反演模型, 反演Chl-a浓度。 其中, 数学微分变换对噪声更敏感, 可以更好的捕捉到数据的边缘和细微变化, 是有效提升光谱波段敏感性的常见手段。 闻建光[6]等使用一阶微分对原始水体反射率数据处理, 与原始数据、 归一化数据对比验证, 一阶微分处理后数据反演太湖Chl-a精度最高, 均方根误差达到0.009 9 mg· L-1, 证明微分技术可以较好的提高Chl-a反演精度; 吕恒[7]等通过对反射光谱进行一阶微分和二阶微分计算, 同样完成对太湖Chl-a浓度预测, 证明二阶微分处理后的估测精度高于一阶微分处理后的结果。 由于不同的水体遥感反射率会有轻微差别, 一些学者开始探究光谱经过微分处理后反演精度提升是否同样适用于其他水体。 沈蔚[8]运用一阶微分模型对长江口Chl-a进行反演, 相关性为0.95, 均方根误差为2.21 mg· L-1, 证明使用微分技术对光谱进行处理后, 应用于太湖之外的水域也可以达到较好的效果; 黄耀欢[9]通过对水体反射率进行一阶微分处理, 利用相关性分析筛选最优波段, 构建一元线性模型对汤逊湖Chl-a进行反演(R2=0.862 8), 证明了一阶微分结合特征筛选对于Chl-a反演的优越性。
高光谱数据能够实现研究区内高分辨率的连续取样, 因此提供了几乎整个波段的反射率信息。 但大量的数据在一定程度上也造成了数据信息冗余, 对特定研究区的水体, 选择最优敏感光谱波段对Chl-a浓度反演至关重要。 目前, 比较常用的筛选最优波段的方法有皮尔逊相关系数法(Pearson correration coefficient, PCC)、 随机蛙跳算法(random frog, RF)和PCA主成分分析(principal components analysis, PCA)等[10]。 张磊[11]通过对原始光谱进行一阶微分处理后, 使用PCA降维构建土壤含水量反演模型, 证明一阶微分和PCA结合具有良好的预测能力, R2达到0.963 0; 安柏耸[12]通过对高光谱进行倒数对数一阶微分变换, 结合RF算法进行波段选择对土壤铅含量进行预测, 最后训练集和验证集的R2均大于0.8; 李爱民[13]将光谱数据进行一阶微分处理后, 计算反射率与水质参数之间的相关性, 以最佳波段进行CDOM的反演, 建立的回归模型R2达到0.548。
尽管上述研究已经取得较好的结果, 但整数阶微分处理与常用的敏感波段筛选方法在水体Chl-a浓度反演中仍存在一定局限性, 如可能会忽略潜在光谱信息并引入大量噪声峰。 分数阶微分(fractional order differentiation, FOD)作为整数阶微分的扩展, 在提高光谱数据信噪比和挖掘高光谱信息方面的效果均优于整数阶[14]。 此外, 偏最小二乘模型(partial least squares, PLS)作为筛选最优光谱特征的一种方法, 考虑了主成分对因变量的贡献, 在光谱降维方面已经表现出较好的效果, 但目前将FOD技术与PLS结合针对水体Chl-a浓度反演模型的研究较少。
以河北白洋淀水体为研究对象, 基于野外淀区高光谱反射率数据以及实测Chl-a浓度值, 结合FOD技术与PLS模型降维方法挖掘高光谱信息和筛选最佳光谱特征, 在此基础上采用支持向量机(support vector machines, SVM)、 深度森林(deep forest, DF)两种机器学习模型建立水体Chl-a浓度反演模型, 并与使用原始数据直接构建模型和PCA降维构建模型对比验证, 得到最佳的光谱反演模型, 为政府实现内陆水体水环境监测提供理论依据, 进一步保障居民健康生活。
白洋淀位于中国河北省中部雄安新区腹地, 地理坐标为115° 45'E— 116° 07'E、 38° 44'N— 38° 59'N。 这片湖泊是大清河流域中部的一个天然湖泊, 同时也是华北平原上为数不多的淀泊之一。 白洋淀以其天然美景、 宜人气候和独特的地理位置而备受赞誉, 成为中国北方地区一处不可忽视的风光胜地。 白洋淀地理位置属于华北平原北部, 流域地形复杂, 包括山地、 丘陵、 平原和洼地, 形成了地势自西向东逐渐变化的特征。 近年来, 白洋淀环境综合治理取得明显进展, 水环境承载力得到显著提升, 但仍存在一定程度的水体富营养化、 农村水体面源污染等问题, 仍需加强监测。 在白洋淀中, 烧车淀是主要景区, 圈头乡、 端村镇各村庄地处白洋淀中心, 地区人口密集度高, 生产生活活动剧烈, 是具有代表性的内陆水体区域。 因此, 选取烧车淀、 圈头乡、 端村镇各村庄等水域为研究对象, 水体采样点分布如图1所示。
 | 图1 研究区位置及水体采样点图 (a): 京津冀; (b): 雄安新区; (c): 白洋淀Fig.1 Location of the study area and water sampling points (a): Beijing-Tianjin-Hebei; (b): Xiong’ an new area; (c): Baiyangdian |
白洋淀实测水体光谱数据50组, 同步采集水样50个, 采集时间为2023年5月27日、 5月28日、 6月1日、 6月3日, 用GPS记录采样坐标经纬度。 水体光谱采集参考水面以上测量法[15], 使用ASD Hand-Held2手持式地物光谱仪, 采样时段为北京时间10:00— 15:00, 采样时天气晴朗, 水面平静; 同步在光谱测量点位水面下20~30 cm处采集水样, 使用实验室L5S紫外可见分光光度计测定样本Chl-a[16]。
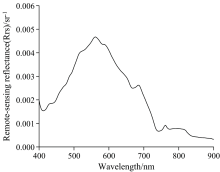
每个样本分别采集了15组光谱数据, 将测量值取平均值后的光谱数据作为研究样本反射率。 此外, 900 nm之后的波段Chl-a与光谱无明显的相关特征, 因此选定400~900 nm波段的样本作为研究数据, 其光谱曲线如图2所示。 由图可见, 光谱反射率在400~500 nm较低, 呈缓慢上升趋势, 在630和670 nm附近存在两个波谷, 在580和690 nm附近形成两个明显的波峰, 在725 nm后迅速减小, 在810~820 nm出现较小波峰, 研究区水体光谱显著呈现出内陆水体特征。
 | 图2 水体光谱曲线Fig.2 Spectral curve of water body |
测量了上述50个水体样本的Chl-a浓度, 通过分析测定结果, 对水体Chl-a浓度进行了描述分析, 其结果如表1所示。 统计分析结果表明: 研究区水体叶绿素a浓度均值为8.902 μ g· L-1, 最小值仅为1.990 μ g· L-1, 最高值则可达20.400 μ g· L-1。 根据国际上经济合作与发展组织(OECD)规定的关于评定湖泊营养状态的Chl-a划分标准以及中国环境科学研究院李子成《中国湖库营养状态现状调查分析》中湖泊、 水库营养状态的分级标准, 目前研究区水域仍存在一定的富营养化问题。
| 表1 水体叶绿素a浓度统计描述 Table 1 Statistical description of Chlorophyll-a concentration in water body |
实测高光谱数据的采集过程中由于基线漂移、 样品不均匀、 散射以及人为操作等影响, 导致光谱曲线会存在少量噪声。 为了避免环境噪声的干扰, 需要对原始光谱数据进行预处理。 研究表明光谱进行微分处理可以有效降低光谱数据受到的杂散光、 噪声、 基线漂移等因素的干扰, 提高数据的信噪比, 提升建模效果[17]。 白洋淀水体组分较为复杂, 不同位置的光谱数据存在较大的差异, 因此在对数据进行预处理时, 常用的整数阶微分可能会过分突出干扰信息, 同时也可能会遗漏一些细微的敏感信息。 而分数阶微分在处理实测高光谱数据时, 可以在强调特征信息的同时减弱无关信息的干扰, 从而达到突出重要光谱特征信息的效果。
分数阶微分是由整数阶微分发展而来, 分数阶微积分的定义有Grunwald-Letnikov(G-L), Riemann-Liouville(R-L)和Caputo三种形式[18], 常用的分数阶微分运算主要基于G-L定义的分数阶微分一元函数差分表达式来实现[19]
式(1)中, x为对应点的值; v为阶数; Γ 为Gamma函数; m为微分上下限之差。 若v=0.0, 则表示未经分数阶微分处理, 即原始数据, v=1.0时表示一阶微分, v=2.0时表示二阶微分。
使用式(1)对所有水体样本的遥感反射率进行0~1阶的分数阶微分变换, 步长为0.1, 在Matlab R2017a中编写代码实现分数阶微分处理程序。
高光谱数据具有波段维度多, 波长范围广的特点, 信息比较集中, 冗余信息较多且波段间相关系数较高, 大量高度相关的高光谱会给后续模型处理带来复杂性, 并会导致模型过度拟合, 引发维数灾难。 姜红[20]等使用PLS作为降维方法对红外光谱特征进行降维, 证明了PLS在处理小样本时具有明显优势。 PLS降维方法通过建立自变量与因变量之间的线性模型来实现降维, 其可以同时兼顾高光谱数据和Chl-a浓度的信息, 在降低数据纬度的同时保持高光谱数据与Chl-a浓度的相关性, 为数据降维提供了有效而可靠的支持。
PLS降维方法是一种有效的数据降维模型, 特别在高维小样本数据的情境下表现出色。 该方法的核心思想是通过找到原始数据中的多个主成分, 将其作为低维表达, 从而实现对数据维度的降低, 可以在保留关键信息的同时, 将数据投影到一个相对较低的维度空间中, 在新的低维表示下, 数据仍然能够有效地捕捉其内在结构和关联关系, 同时考虑输入和输出之间的关系, 可以更好地适应多变量数据集的特征。
偏最小二乘算法分为单因变量偏最小二乘算法和多因变量偏最小二乘算法, 本研究的情况属于单因变量版本。 单因变量偏最小二乘算法建模时, 要求从原始高光谱数据X中提取的第一个特征t1满足两个关键条件:
①信息最大化: t1应尽可能表示X的信息;
②相关程度最大化: t1和Chl-a浓度y的相关程度达到最大。
这两个条件可以转化为式(2)
其中第一个特征t1=Xw1, w1是t1对应的投影方向。
这是PLS算法在建模过程中的一个关键步骤, 以确保提取到最具信息和相关性的光谱特征。 获得投影方向w1后, 分别计算X和y的残差用来更新X、 y
其中, E1与F1表示X与y的残差, 包括特征t1没有表示的信息。
PLS算法使用残差E1与F1作为新的X与y, 而后提取下一个特征光谱t2; 重复同样操作直到残差中包含十分少的信息。
本工作在已有研究的基础上, 着重探究实测高光谱数据经过FOD光谱变换后, 使用PLS筛选最优光谱波段对研究区水体Chl-a浓度的反演能力。
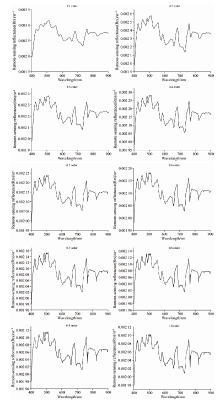
采用FOD算法对原始高光谱反射率数据进行0~1阶(步长0.1)分数阶微分变换处理, 图4为平均后的各阶高光谱反射率曲线。 水体原始高光谱反射率曲线(如图3)呈现出典型的内陆水体反射特征, 在400~500 nm水体反射率逐渐增大, 该波段范围是叶绿素的吸收带, 但在光谱上体现不出明显的吸收谷; 由于受叶绿素、 胡萝卜素弱吸收、 细胞和悬浮颗粒物的散射影响, 520~600 nm波段范围会出现反射峰, 在580 nm左右峰值达到最大; 由于Chl-a的荧光效应, 在700 nm左右形成第二个反射峰; 从725 nm之后, 反射率迅速减小, 在800 nm左右出现一个较小的波峰, 这是水体中悬浮物后向散射和纯水吸收谷的共同影响。
 | 图3 原始光谱均值Fig.3 Original mean spectrum |
 | 图4 分数阶光谱Fig.4 Fractional-order derivative spectra |
经0~1阶(步长0.1)FOD处理后, 如图4所示, 500、 600、 800和900 nm处出现明显波动, 对比原始光谱, 在400~500 nm处, 反射率随波长的增加而快速增加; 在550~650 nm处, 反射率随波长的增加而缓慢降低, 峰值相较于原始光谱提前达到最大, 波段范围内细微变化被突出; 在730 nm处存在显著的吸收峰, 在680和760 nm处存在2个显著的反射峰, 800 nm附近的小波峰逐渐明显。 随着阶数的增加, 整体光谱强度随分数阶的增加而减弱, 波峰波谷的差异越发增大, 光谱曲线变化频率较快, 表明FOD处理光谱数据能够将光谱的波峰、 波谷变化较快的波段信息放大, 有效捕捉光谱的特征值, 有利于挖掘光谱的潜在信息。 综上, FOD处理对于光谱的波峰、 波谷、 变化较为明显的波段有较高的敏感性, 对于放大信号, 挖掘数据有显著作用, 更有利于获取更详细、 更精确的光谱数据。
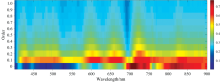
光谱数据与Chl-a浓度含量的Pearson相关系数绝对值计算结果如图5所示, 原始光谱敏感波段主要集中在700~750和800~900 nm, 450~550 nm相关系数绝对值极低, |r|均小于0.2, 进行微分处理后, 敏感波段范围整体上明显增加, 主要集中于420~530、 580~690和710~900 nm处。 0.1阶微分处理的变化最为明显, |r|均大于0.4, 随分解尺度的增加, 敏感波段范围与相关系数逐渐减少。 如图5所示, 经过FOD处理后, 敏感波段范围较原始光谱在0.3阶微分尺度内均有一定扩大, 进一步证明FOD对于放大光谱信号, 挖掘光谱信息有一定的意义。
 | 图5 相关性分布图Fig.5 Distribution of correlation |
传统的水质参数反演方法采用统计回归模型, 但忽略了水质参数浓度与实测高光谱数据之间的非线性关系, 在特征波段的筛选过程中, 通常只考虑了某一波段范围内的敏感波段或波段组合, 而其他波段范围可能也包含重要的光谱信息; 原始未经预处理的实测高光谱数据存在背景噪音和冗余, 而经过FOD光谱变换后, 这些问题可能被进一步加剧, 导致模型反演的精度下降, 甚至出现过拟合问题。 为了解决这些挑战, 本研究对光谱波段进行重组, 并对其进行降维, 以便筛选出最优的特征波段。 这一步骤的目标是在考虑全部波段范围的基础上, 有效地识别出与水质参数相关的特征。
利用皮尔森相关系数筛选最优波段, 如式(6)所示
式(6)中, |r
重复上述步骤, 对400~900 nm范围内的每个波段进行同样的处理, 最终得到一组具有高相关性的波段集合, 可以将其重新组合成可变阶光谱波段, 其中每个波段与Chl-a的相关性都较高。 部分具有代表性的波段(出现反射峰的波段范围)对应的“ 可变阶” 结果如表2所示。
| 表2 重组数据集 Table 2 Recombination data set |
应用PLS减少数据集中波段间的多重共线性, 从X中提取主成分t, 同时最大化t和y之间的相关性。 最终得到的新成分代表了用于估计Chl-a浓度反射光谱中存在的相关信息。
将PLS模型应用于输入的高光谱数据X, 产生了8个主成分ti(i=1, 2, 3, 4, 5, 6, 7, 8), 如表3所示, 累计贡献率达到99%以上, 以此证明对原始高光谱数据进行降维。
| 表3 主成分累计贡献率 Table 3 Cumulative contribution rate of principal components |
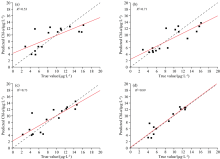
半分析模型选择QAA-V6模型; 传统统计模型选择一元线性回归、 三波段模型; 机器学习模型选择SVM和DF模型。 将数据集按照7∶ 3的比例划分为建模集和验证集。 将建立的多个模型进行汇总, 反演结果如表4所示, 图6、 图7为SVM、 DF反演模型预测值与实测水体Chl-a浓度的散点图。
| 表4 不同建模方法反演结果 Table 4 Inversion results of different modeling methods |
 | 图6 SVM预测结果散点图 (a): SVM; (b): FOD+SVM; (c): PLS+SVM; (d): FOD+PLS+SVMFig.6 Scatter plot of SVM prediction results (a): SVM; (b): FOD+SVM; (c): PLS+SVM; (d): FOD+PLS+SVM |
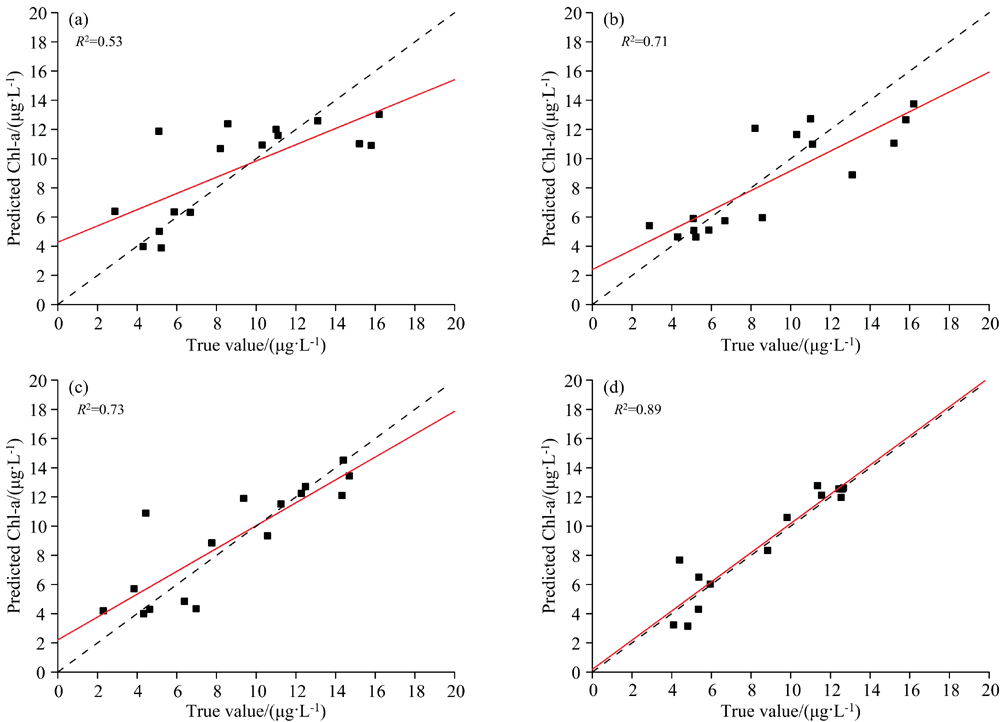 | 图7 DF预测结果散点图 (a): DF; (b): FOD+DF; (c): PLS+DF; (d): FOD+PLS+DFFig.7 Scatter plot of DF prediction results (a): DF; (b): FOD+DF; (c): PLS+DF; (d): FOD+PLS+DF |
由以上结果可以看出, QAA模型的反演效果最不理想, 其原因是QAA算法是基于海洋遥感发展的, 内陆水体的固有光学量更为复杂多变, QAA既定的经验参数并不适合白洋淀Chl-a反演; 同时, 无论传统回归模型还是机器学习模型, 使用原始高光谱数据作为模型输入, 其反演精度也都较低。 造成该结果的根本原因是高光谱数据和水质参数浓度之间的关系是非线性关系, 用皮尔森相关系数难以准确衡量之间的关系; 并且, 在建立机器学习模型中, 参与建模的高光谱数据波段之间存在大量的背景噪音和信息冗余, 没有选择适合Chl-a反演的最优特征, 故以常规方法建立的模型精度普遍较低。 而经过FOD和PLS处理后, 高光谱数据的敏感波段范围被扩大, 深层光谱特征被突显, 同时PLS在进行特征筛选时, 可以同时兼顾保留关键信息和降维的功能, 低维数据中的光谱特征仍然能够有效捕捉其内在结构和关联关系, 更好的考虑了光谱特征与Chl-a之间的关系, 对于模型的精度提升都表现出明显效果。 在所选的反演模型中, 采用DF建立的模型不论是建模集还是验证集, 都具有较高的精度, 其建模集R2=0.96, MSE=0.51 μ g· L-1, MAE=0.64 μ g· L-1, 验证集R2=0.89, MSE=0.69 μ g· L-1, MAE=0.64 μ g· L-1。 通过建模过程中的不断尝试, 确定了最佳的扫描窗口大小为8, 多粒度扫描期间随机森林中的树木数量为50, 级联层中单个随机森林中的树数为300, 在多粒度扫描随机森林训练期间, 节点中执行拆分的最小样本数为0.05, 其余参数均为默认值时, DF模型精度趋于稳定, 此时该模型对于水体Chl-a的反演效果最佳。
以白洋淀水域为研究对象, 通过对50个水体样本的采集, 将数据按照7∶ 3的比例分为建模集和验证集, 基于四种不同模型构建方法, 得出关于利用水体反射率光谱进行水体Chl-a浓度反演的重要结论:
(1)FOD对于提升水体Chl-a浓度与高光谱数据之间的相关性有显著效果。 与原始高光谱反射率数据相比, 经过FOD变换后的数据敏感波段范围扩大, 剔除了光谱无用信息, 有利于挖掘光谱的潜在信息, 有效捕捉光谱特征值。
(2)使用PLS降维后筛选最优特征, 构造了一个结构简化的低维数据集, 其中包含了对解释数据集中的变化最重要的变量, 相较于传统降维方法, 可以对高光谱数据实现降维的同时保留更多的水体辐射信息, 有助于最小化数据集中的多重共线性, 减少潜在过拟合问题。
(3)对比经过其他预处理后的预测结果, 采用FOD-PLS-DF反演Chl-a浓度具有较高的精度。 FOD-PLS-DF的验证集R2=0.89, MSE=0.69 μ g· L-1, MAE=0.64 μ g· L-1, 说明模型在内陆二类水体中可以有效地提取实测高光谱数据的深层特征, 具有较高的鲁棒性和可靠性, 预测精度也比较高, 可以满足实际预测的要求。
本研究主要采用FOD对实测高光谱数据进行预处理, 重组可变阶数据集, 利用PLS方法进行降维处理, 对比分析不同预处理结合不同降维方法构建模型的反演能力, FOD-PLS-DF模型可为水体Chl-a浓度反演提供很好的参考依据, 为今后大规模反演白洋淀地区水体Chl-a浓度提供依据。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|