










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于张量字典学习的高光谱图像稀疏表示分类
[宫学亮 , 李玉
, 李玉* , 贾淑涵, 赵泉华, 王丽英]
, 李玉, 贾淑涵, 赵泉华, 王丽英]
|
|


作者简介: 宫学亮, 女, 1995年生, 辽宁工程技术大学测绘与地理科学学院博士研究生 e-mail: 18341841852@163.com
高光谱图像因其蕴含十分丰富的光谱和空间信息已被广泛应用于生产生活的各个领域。 为了充分挖掘高光谱图像中蕴含的光谱和空间信息, 从高光谱数据固有的三维属性出发, 以空-谱张量为基本处理单元, 提出一种基于张量字典学习的稀疏表示分类(Tensor-DLSRC)算法, 以提高高光谱图像分类精度。 首先, 构建以像素及其空间邻域像素光谱向量组成的像素空-谱张量; 其次, 将作为训练样本像素的空-谱张量按照不同维度展开成矩阵, 并以其列向量均值作为字典原子组成初始化张量字典; 同时, 在张量稀疏性约束条件下构建张量稀疏表示(Tensor-SR)模型, 并利用张量字典学习算法学习一组能够精确刻画该类张量空-谱特征的字靛矩阵; 最后, 对待分类像素利用Tensor-SR模型求解其空-谱张量的稀疏表示系数张量, 根据重构残差最小化原则确定该像素类别。 为了分析参数对提出算法分类精度的影响, 在进行分类对比实验之前, 通过一系列实验分别讨论训练样本数 M、 邻域窗口尺寸(2 δ+1)×(2 δ+1)、 字典学习阶段的稀疏度 μ1和稀疏表示阶段的稀疏度 μ2等参数对总体分类精度(OA)的影响。 为了验证提出算法的有效性, 分别在Indian Pines、 Salinas和Xuzhou三个高光谱数据上进行实验, 对比分析本算法与基于光谱向量的SRC算法和DLSRC算法、 增加邻域空间信息的JSRC算法和DLJSRC算法和基于空-谱张量的Tensor-DLSRC算法等五种算法的分类结果, 并采用基于混淆矩阵的平均准确率(APR)、 平均精度(PA)、 OA和Kappa系数对分类结果定量分析。 所提出的Tensor-DLSRC算法在OA和Kappa系数的平均值水平是六种算法中最高的, 且具有最小的标准差, 说明本算法与五种其他算法相比能够提供更准确且稳定的分类结果。
Hyperspectral images (HSI) have been widely used in various fields of production and life due to their rich spectral and spatial information. This paper proposes a tensor dictionary learning-based sparse representation classification (Tensor-DLSRC) algorithm, which directly takes the spatial-spectral tensor as the basic unit to exploit the spectral and spatial information and improve the accuracy of hyperspectral image classification. Firstly, the spatial-spectral tensor comprises the spectral vectors of all pixels in the spatial neighborhood of the central pixels. Secondly, the mean vectors of each order fiber of the training spatial-spectral tensor are used as dictionary atoms to generate an initialized dictionary. The tensor-based dictionary learning (TDL) algorithm is proposed to train a set of structured dictionaries from the training samples. Then, a tensor-based sparse representation model is constructed based on the sparsity constraints of the tensor, and the sparse representation coefficient tensor corresponding to the test spatial-spectral tensor is obtained by solving the model. Finally, the class of the test sample is determined according to the minimization of the reconstruction residuals. To analyze the impact of parameters on the classification accuracy of the proposed algorithm, a series of experiments were conducted to discuss the effects of parameters such as training sample size M, neighborhood window size (2 δ+1)×(2 δ+1), sparsity μ1 in dictionary learning stage, and sparsity μ2 in sparse representation stage on overall accuracy (OA) before conducting classification comparison experiments. To verify the effectiveness of the proposed algorithm, a series of experiments were conducted on three HSIs, (e.g., Indian Pines, Salinas, and Xuzhou) to compare and analyze the classification results of our algorithm with five comparative algorithms: SRC and DLSRC algorithms based on spectral vectors, JSRC and DLSJSC algorithms with added neighborhood spatial information, and Tensor DLSRC algorithm based on spatial-spectral tensor. The classification results were quantitatively analyzed using Average Precision Rate (APR), Average Accuracy (PA), OA, and Kappa coefficients based on the confusion matrix. The proposed Tensor-DLSRC algorithm has the highest average level of OA and Kappa coefficients among the six algorithms. It has the smallest standard deviation, indicating that compared with the comparative algorithms, this algorithm can provide more accurate and stable classification results.
高光谱图像(hyperspectral image, HSI) [1]是通过高光谱成像仪获取的包括从可见光到红外数十甚至数百个连续窄光谱波段的遥感图像。 可以将高光谱图像看成三维数据立方体, 其中包含每个像素的二维空间信息和一维光谱信息。 高光谱图像因其蕴含十分丰富的光谱和空间信息已被广泛应用于目标检测[2]、 环境监测[3]、 文物保护[4]、 精准农业[5]和军事[6]等多个领域。
高光谱图像分类[7, 8, 9]是指根据高光谱图像中不同地物光谱和空间信息的差异, 确定和标注图像中每个像素地物类别属性的过程, 是目前高光谱图像处理领域的研究前沿和热点问题。 传统的高光谱图像分类往往更关注光谱维特征在分类中的作用, 常见的分类方法可以分为基于高维光谱曲线和光谱向量两种形式。 对于基于光谱向量的分类算法, 支持向量机[10, 11], 随机森林[12], 神经网络[13, 14]和稀疏表示分类(sparse representation classification, SRC)[15, 16, 17]等分类算法因其良好的分类性能被广泛关注。 其中, SRC算法通过少量给定的字典矩阵原子的线性组合表示测试像素的光谱向量, 通过最小残差准则确定测试像素的类别。 直接使用高维光谱向量会产生较高的计算成本, 通常需要先降维再分类。 如Zhao等[18]在随机投影框架下, 提出一种严格随机投影算法, 将光谱向量投影到低维空间, 达到在精确分类的同时降低计算成本的目的。 对于基于光谱曲线的分类算法, 一是直接分析光谱曲线的相似性, 如高孝杰等[19]提出基于Fré chet距离度量光谱曲线相似度的高光谱影像分类算法, 取得了较好的效果; 二是分析光谱曲线特性提取特征后分类, 如李玉等[20]根据光谱曲线所呈现出的多峰特性, 提出一种基于加权指数函数模型的高光谱图像分类方法, 采用WEF模型拟合光谱曲线, 利用WEF模型参数集代替光谱测度矢量作为像素特征, 实现地物目标的精确分类。 这些仅考虑光谱特征的方法忽视了高光谱图像的空间信息, 得到的分类结果不尽人意。
以往的研究表明, 空间信息可以提高高光谱图像的分类精度[21, 22, 23, 24, 25]。 Chen等[16]认为高光谱图像中相邻像素通常属于同种地物, 共享同一个稀疏表示模型, 并据此提出联合稀疏表示分类(joint sparse representation-based classification, JSRC)模型, 采用同时正交匹配追踪算法求解该模型。 Zhang等[26]在JSRC模型基础上, 赋予邻域像素与其中心测试像素光谱相似性相关的权重, 提出基于非局部加权联合稀疏表示高光谱图像分类方法。 Gan等[27]从特征多样性角度出发, 采用Gabor滤波、 局部二值模式和拓展形态学轮廓三种不同类型的特征描述算子, 构建多特征核稀疏表示算法, 充分利用高光谱遥感图像空间和光谱特征。 然而, 通过上述将邻域像素的光谱向量排列成矩阵或构建多特征向量的方法表征测试像素的空间信息, 依然会破坏高光谱数据本身固有的内在结构。
为了充分利用高光谱图像的空间和光谱信息, 遵循其三维自然属性, 以给定像素为中心像素, 将其邻域窗口内像素的光谱向量排列组成空间-光谱张量, 并将其作为后续处理的基本单元从而保留其固有的局部结构信息。 首先, 直接在张量框架内定义张量稀疏表示(Tensor-based sparse representation, Tensor-SR)模型, 利用张量字典学习(Tensor dictionary learning, TDL)算法, 从训练样本的空-谱张量中学习三个维度(两个空间维和一个光谱维)的字典矩阵; 然后, 基于训练得到的各阶字典矩阵利用张量正交匹配追踪(Tensor-based orthogonal matching pursuit, Tensor-OMP)算法求解测试样本对应的稀疏表示张量; 最后, 通过比较测试样本各类对应的重构残差张量确定测试样本的类别, 完成高光谱图像的精确分类。
高光谱遥感图像可用三阶张量表示为XHIS=[xijb]I× J× B, 其中i、 j和b分别为像素格点的横、 纵坐标和光谱波段索引, I、 J和B分别图像域在横、 纵坐标方向的像素数和总波段数, xijb为位于格点(i, j)像素(除了表述像素位置外, 还以(i, j)作为像素索引在波段b的光谱测度。 对于给定像素(i, j), 在图像域中取以其格点(i, j)为中心(2δ +1)× (2δ +1)正方窗口内像素为其邻域像素(位于图像对角和边缘的像素可采用邻域填充方式构建正方窗口)。 定义以像素(i, j)及其邻域像素光谱向量组成的三阶张量为其空-谱张量, 记为X(i, j)=[xpqb][i-δ , i+δ ]× [j-δ , j+δ ]× B, 其中p、 q和b分别为空-谱张量三个维度的索引。 由此, 与高光谱遥感图像XHIS对应的空-谱张量集合为
 | 图1 高光谱图像空-谱张量表达Fig.1 Spatial-spectral tensor expression of hyperspectral image |
从
对
式(1)中, d(=1, 2, 3)表示空-谱张量对应的三个不同维度, 即d=1, 2表示两个空间维, d=3表示光谱维; × d表示张量和矩阵的d模积运算。 由于同类像素通常具有相似的光谱性质, 因此同类像素的空-谱张量具有相似的分解模型, 本文假设属于第k类的所有空-谱张量均可由相同的字典矩阵近似表示, 即,
TDL算法的主要目的是利用空-谱张量训练样本集
其中, ‖ · ‖ F表示张量的Frobenius范数, 等于张量中所有元素值平方和的平方根; ‖ · ‖ 0为张量的0范数, 表示张量的非零元素数; μ 1为预先设置的系数张量的稀疏度, 通常表示系数张量非零元素的个数。
采用交替执行稀疏表示和字典更新过程求解式(3)最优化问题中的系数张量
(1) 固定字典矩阵Ψ k, d(l-1)(d=1, 2, 3), 求解系数张量
式(4)的张量稀疏表示模型是一个NP-hard问题, 很难获得一个严格的最优解。 为此, 将基于向量的正交匹配追踪(orthogonal matching pursuit, OMP)[16]算法扩展到张量空间, 提出一种Tensor-OMP算法用于求解该模型。 Tensor-OMP算法的目的是在字典矩阵Ψ k, d(l-1) (d=1, 2, 3)中, 找到与空-谱张量
定义Tensor-OMP算法的初始残差张量
式(5)中, t (=0, 1, …, T)为Tensor-OMP算法的迭代索引, T为最大迭代次数。 更新原子序数(列索引)集合
式(6)中,
重复式(5)— 式(7)的迭代过程, 直到Tensor-OMP算法残差张量
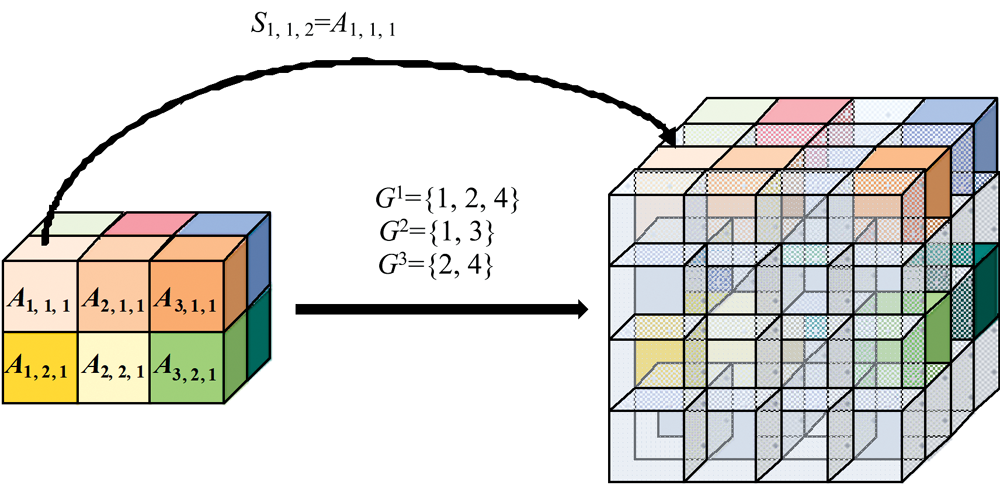 | 图2 将张量A元素放到张量S对应位置上的过程Fig.2 The process of replacing the elements in tensor A to the corresponding position of tensor S |
(2) 固定系数张量集
字典更新包括修剪原子、 更新原子和增补原子三个步骤。 由于在上述求解系数张量
采用交替迭代法更新三个临时字典矩阵中的原子, 即固定其余两个(只包含参与稀疏表示问题求解的原子)字典矩阵, 更新临时字典矩阵Ψ k, d(l)'的原子生成新的临时字典矩阵Ψ k, d(l)″,
其中, 矩阵
为保持字典矩阵的完整性, 需要从d阶展开矩阵
其中, 定义式(12)中的向量稀疏表示模型的稀疏度为(μ 1)1/3。 计算列向量
遍历d阶展开矩阵
重复(1)和(2)的迭代过程, 直到残差张量
张量稀疏表示分类(Tensor-based sparse representation classification, Tensor-SRC)是SRC在张量空间的泛化形式, 其基本思想是对于任意给定测试样本Xn可以通过张量Tucker分解模型由两个空间维和一个光谱维的字典矩阵中的部分原子表示, 然后通过比较各类别的重构误差预测测试样本的类别。
具体地, 将利用上述TDL算法从空-谱张量训练样本集
其中, μ 2为系数张量的稀疏度, 通常表示系数张量中非零元素的个数。
式(14)的张量稀疏表示模型也可以通过Tensor-OMP算法求解。 再利用各类字典矩阵Ψ k, d以及其对应的子系数张量
式(15)中, 子系数张量
为了验证本文提出的张量字典学习的稀疏表示分类(Tensor dictionary learning based sparse representation classification, Tensor-DLSRC)算法的可行性和有效性, 利用三个高光谱数据将Tensor-DLSRC算法与几种高光谱图像分类算法进行对比实验。 三个高光谱数据分别为: Indian Pines、 Salinas和Xuzhou数据, 图3为三个高光谱数据的假彩色合成图像, 图4为三个高光谱数据的真实地物标注图, 表1同时展示了三幅影像的真实地物标注信息及样本数目, 同时对应真实地物标注图中的各类地物。
 | 图3 假彩色合成图像 (a): Indian Pines; (b): Salinas; (c): XuzhouFig.3 The pseudocolor composite image (a): Indian Pines; (b): Salinas; (c): Xuzhou |
 | 图4 真实地物标注图 (a): Indian Pines; (b): Salinas; (c): XuzhouFig.4 The ground truth map (a): Indian Pines; (b): Salinas; (c): Xuzhou |
| 表1 真实地物标注信息及样本数目 Table 1 The ground truth information and number of samples |
在进行分类对比实验之前, 通过一系列实验分别讨论训练样本数M、 邻域窗口尺寸(2δ +1)× (2δ +1)、 字典学习阶段的稀疏度μ 1和稀疏表示阶段的稀疏度μ 2等参数对总体分类精度(overall accuracy, OA)的影响。 实验中除讨论的参数外, 其余参数均取表2中的最优值。 此外, Tensor-OMP算法和TDL算法的残差阈值ε 设置为10-6, TDL算法中的最大迭代次数itermax设置为10。
| 表2 最优参数设置 Table 2 The optimal parameters setting |
2.1.1 训练样本数M
随机选取Indian Pines和Xuzhou数据中每类训练样本样本总数的5%~30%, Salinas数据中每类50~300个训练样本验证随着训练样本数N对Indian Pines、 Salinas和Xuzhou数据分类性能的影响, 其中Indian Pines数据中某几类地物样本总数较少, 当给定实验样本数超过其样本总数时, 则选取该类地物的所有样本作为训练样本参与实验。 图5(a)— (c)分别展示了6种算法在3个高光谱图像上随训练样本数变化的OA值曲线。 由图可知, 各算法的OA值随训练样本数的增加先逐渐增大, 当训练样本数达到一定数值后, OA值趋于平稳。 这表明, 基于稀疏表示的分类算法在一定程度上依赖于训练样本的质量和数量, 训练样本越多, 字典包含的地物特征越丰富。 当训练样本足够多时, 字典的判别信息足够表示测试样本, 因此OA值缓慢变化。 除此之外, 图5所示结果表明, 不论训练样本数取何值, 本文提出的Tensor-DLSRC算法OA值明显高于对比算法, 说明本算法具备一定的优越性。
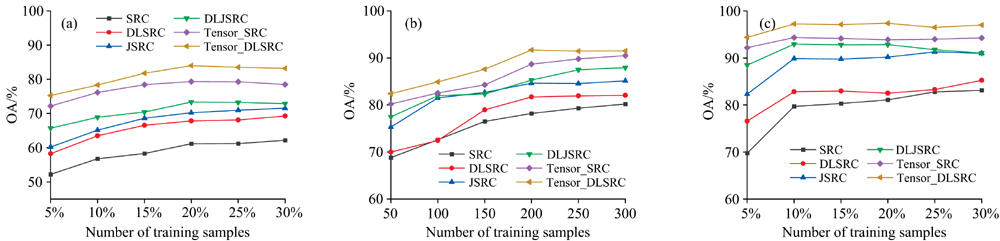 | 图5 训练样本数N对总体精度(OA)的影响 (a): Indian Pines; (b): Salinas; (c): XuzhouFig.5 The influence of the number of training samples on overall accuracy (OA) (a): Indian Pines; (b): Salinas; (c): Xuzhou |
2.1.2 邻域窗口尺寸
本文分别选取大小为3× 3~15× 15像素的邻域窗口进行实验分析, 研究邻域窗口尺寸对JSRC算法、 DLJSRC算法和Tensor-SRC算法以及本文提出的Tensor-DLSRC算法分类精度的影响。 图6(a)— (c)所示分别为3个高光谱图像分类精度随邻域窗口尺寸变化的曲线。 由图6可以看到, 4种分类算法的精度都随着邻域窗口尺寸的增加先升高后下降。 这是因为邻域窗口较小时包含的空间信息较少, 但当邻域窗口过大时, 窗口内可能包括和中心像素类别不一致的像素, 导致分类精度下降。 此外, 由于Salinas数据中地物的面积相对较大, 其最佳邻域窗口尺寸相对于Indian Pines和Xuzhou数据更大。 相比两种联合稀疏表示算法, 本文提出的Tensor-SRC和Tensor-DLSRC算法直接在像素空-谱张量上进行稀疏表示系数的求解, 有效地保留了高光谱数据的内在结构, 因此精度更高。
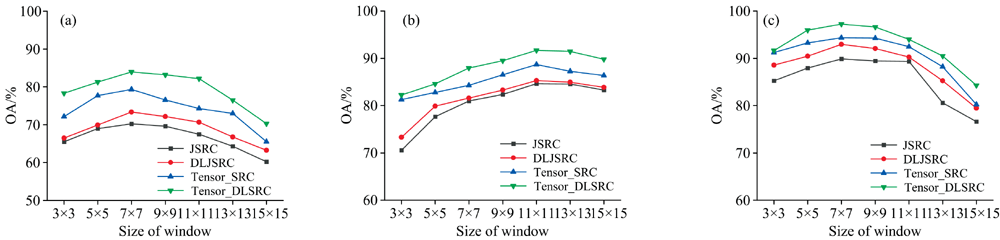 | 图6 邻域窗口尺寸对总体精度(OA)的影响 (a): Indian Pines; (b): Salinas; (c): XuzhouFig.6 The influence of the size of spatial-spectral tensor on overall accuracy (OA) (a): Indian Pines; (b): Salinas; (c): Xuzhou |
2.1.3 稀疏度μ 1和μ 2
对影响Tensor-DLSRC算法分类精度的两个稀疏度参数(字典学习阶段的稀疏度μ 1和稀疏表示阶段的稀疏度μ 2)进行分析讨论。 图7(a)— (c)所示分别展示了稀疏度参数对Indian Pines、 Salinas和Xuzhou数据精度的影响, 其中μ 1和μ 2的取值范围为[20, 40, 60, 80, 100]。 当μ 2固定时, 随着μ 1的增加, 字典学习过程中使用的数目增加, 分类精度随之升高; 当μ 1增加到一定程度后, 然后分类精度开始趋于平稳。 当μ 1固定时, 随着μ 2的增加, 用于表示测试像素空-谱张量的字典原子数目增加, 分类精度也逐步升高, 直到达到当前μ 2下训练的字典表示测试像素空-谱张量能力的极限。
 | 图7 稀疏度μ 1和μ 2对总体精度(OA)的影响 (a): Indian Pines; (b): Salinas; (c): XuzhouFig.7 The influence of the sparsity level on overall accuracy (OA) (a): Indian Pines; (b): Salinas; (c): Xuzhou |
根据上述一系列参数分析实验得到的最优参数值(具体数值如表2所示), 设计对比实验, 将本文提出的将Tensor-DLSRC算法与基于光谱向量的SRC算法、 基于光谱向量的字典学习稀疏表示分类算法(记为DLSRC算法)、 基于邻域内光谱向量的联合稀疏表示分类(JSRC)算法、 基于邻域内光谱向量字典学习的稀疏表示分类算法(记为DLJSRC算法)以及不经过字典学习的Tensor-SRC算法进行比较。 为了对几种分类算法的性能进行全面地比较和分析, 随机选取5次训练样本进行重复实验, 并采用基于混淆矩阵的平均准确率(average precision rate, APR)、 平均精度(average accuracy, PA)、 OA和Kappa系数对分类结果定量分析(如表3— 表5所示)。 为了度量波动性, 表中的分类精度以“ 平均值± 标准差” 的形式表示。 图8— 图10分别为Indian Pines、 Salinas和Xuzhou数据集的Tensor-DLSRC算法和5种对比算法的分类结果图。
| 表3 Indian Pines 数据分类精度 Table 3 The classification accuracy of Indian Pines data |
| 表4 Salinas数据分类精度 Table 4 The classification accuracy of Salinas data |
| 表5 Xuzhou数据分类精度 Table 5 The classification accuracy of Xuzhou data |
 | 图8 Indian Pines数据分类结果 (a): SRC; (b): DLSRC; (c): JSRC; (d): DLJSRC; (e): Tensor-SRC; (f): Tensor-DLSRCFig.8 The classification result of Indian Pines data (a): SRC; (b): DLSRC; (c): JSRC; (d): DLJSRC; (e): Tensor-SRC; (f): Tensor-DLSRC |
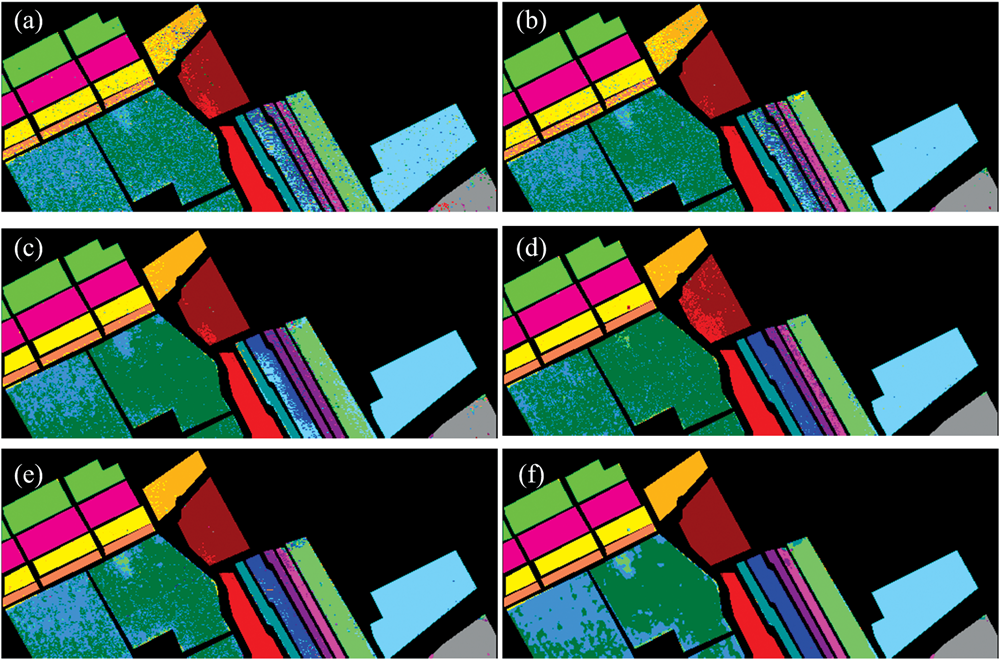 | 图9 Salinas数据分类结果 (a): SRC; (b): DLSRC; (c): JSRC; (d): DLJSRC; (e): Tensor-SRC; (f): Tensor-DLSRCFig.9 The classification result of Salinas (a): SRC; (b): DLSRC; (c): JSRC; (d): DLJSRC; (e): Tensor-SRC; (f): Tensor-DLSRC |
 | 图10 Xuzhou 数据分类结果 (a): SRC; (b): DLSRC; (c): JSRC; (d): DLJSRC; (e): Tensor-SRC; (f): Tensor-DLSRCFig.10 The classification result of Xuzhou (a): SRC; (b): DLSRC; (c): JSRC; (d): DLJSRC; (e): Tensor-SRC; (f): Tensor-DLSRC |
对于Indian Pines数据, 从图8中可以看出, 基于光谱向量的光谱向量的SRC算法和DLSRC算法分类结果存在大量的“ 椒盐” 噪声, 加入邻域空间信息后该现象有所改善, 本文提出的基于空-谱张量的算法效果更为明显, 说明空-谱张量能够完整地保留高光谱数据本身的三维空间结构。 从表3中可知, DLSRC、 DLJSRC和Tensor-DLSRC算法的分类精度高于SRC、 JSRC和Tensor-SRC算法的分类精度, 因为通过学习从训练样本集得到的结构化字典可以更有效地表示测试像素的特征, 有助于提高SR的分类性能。 Tensor-DLSRC算法在6中分类方法中获得最高的精度, 说明TDL算法学习到的结构性字典判别能力最强。
对于Salinas数据, 从图9中可以明显看出, 相比其他对比算法, 基于空-谱张量的Tensor-SRC和Tensor-DLSRC算法不仅平滑了分类结果的噪声, 而且对较难分割的类别, 特别是不同时期同种作物的两个类别(未训练葡萄园1和未训练葡萄园2、 杂草-西兰花1和杂草-西兰花2)分类结果的改善效果十分明显。 说明空-谱张量可以充分挖掘空间和光谱信息, 有助于高光谱图像的精细分类。 根据表4中可知, 本文提出的Tensor-DLSRC算法不仅获得最高的分类精度, OA和Kappa洗漱的平均值分别达到91.66%和0.907, 而且具有最小的标准差, 说明本算法不仅具有较好的分类性能, 还具备一定的鲁棒性。
对于Xuzhou数据, 从图10中的分类结果图不难看出, Tensor-DLSRC算法分类效果最好, 几乎没有错分像素, 而Tensor-SRC在农作物1的分类中表现较差, 这是因为Tensor-SRC算法是直接用训练样本空-谱张量各阶纤维簇的均值向量组成的字典对测试像素空-谱张量进行重建, 而Tensor-DLSRC算法是利用在训练样本空-谱张量集合中通过TDL算法训练得到结构化字典对测试像素空-谱张量进行有效表示, 因此分类效果更好。 从表5中可以看出, Tensor-DLSRC算法的精度最高, OA和Kappa系数的平均值分别为97.23%和0.965, 且标准差最低, 说明TDL算法训练得到结构化字典可以更好地提取空间-光谱张量中的判别特征用于高光谱图像分类, 且稳定性更高。
针对传统分类高光谱图像方法难以充分挖掘的空间和光谱信息的问题, 结合张量Tucker分解理论, 提出一种基于张量的稀疏表示分类模型对类别未知的测试样本的空-谱张量进行精确表示, 根据各类残差张量的最小化准则确定测试样本类别。 并将张量字典学习理论引入到张量稀疏表示框架, 直接利用训练样本的空间-光谱张量学习各阶字典矩阵, 利用这些字典矩阵更精确地表示高光谱图像空-谱张量, 提升高光谱图像的分类精度。 实验结果表明, 本文提出的Tensor-DLSRC算法明显优于其他对比算法, 且鲁棒性更强。 首先, 直接在张量框架内对空-谱张量进行稀疏表示有助于充分挖掘高光谱数据的空间和光谱信息, 为分类提供判别性依据。 其次, 利用空-谱张量训练样本通过字典学习得到的字典矩阵能够完整地表示该类的空-谱张量样本, 有助于提高高光谱图像的分类性能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|