





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于近红外光谱的稻种秕谷含量等级快速判别
[廖娟1  , 曹佳雯
, 曹佳雯1 , 田泽丰1 , 刘晓丽1 , 杨玉青1 , 邹禹2 , 王玉伟1 , 朱德泉1, * ]
, 曹佳雯]
|
|


作者简介: 廖 娟, 女, 1986年生, 安徽农业大学工学院副教授 e-mail: liaojuan@ahau.edu.cn
为实现水稻考种中秕谷含量的快速有效检测, 基于近红外光谱技术, 构建了稻种秕谷含量判别模型。 制作不同秕谷含量的稻种样品并采集其近红外光谱数据; 为提高模型判别精度, 选取两种不同组合Savitzky-Golay平滑(SG)+多元散射校正(MSC)+多项式基线校正(PBC)和SG+标准正态变量转换(SNV)+多项式基线校正(PBC)的预处理方法降噪处理; 为减少光谱中冗余信息对模型运算速度和预测精度的影响, 利用连续投影算法(SPA)、 竞争自适应重加权采样(CARS)和主成分分析(PCA)三种方法对预处理后的光谱进行特征波长变量提取, 并建立支持向量机(SVM)、 K-最近邻算法(KNN)、 决策树(DT)、 线性判别分析(LDA)、 偏最小二乘判别分析(PLS-DA)、 朴素贝叶斯(NB)等6种稻种秕谷含量等级判别模型。 试验结果表明, 在SG+SNV+PBC预处理方法下, 使用CARS方法选择158个特征波长, KNN模型的测试集等级判别准确率可达99.47%。 表明近红外光谱技术为实现稻种秕谷含量等级判别提供了一种可行的方法, 为实现稻种品质的无损检测提供了支撑。
, CAO Jia-wen
A model for determining empty grain content in rice seed examination was established based on near-infrared spectroscopy to rapidly and effectively detect empty grains in rice seeds. Firstly, rice samples with different empty grain contents were prepared, and their near-infrared spectral data were collected. To improve the discrimination accuracy of the model, two different combinations of preprocessing methods, including Savitzky-Golay smoothing (SG)+multiplicative scatter correction (MSC)+polynomial baseline correction (PBC) and Savitzky-Golay smoothing (SG)+standard normal variate transformation (SNV)+polynomial baseline correction (PBC) were selected for noise reduction. Besides, three methods of sequential projection algorithm (SPA), competitive adaptive reweighted sampling (CARS), and principal component analysis (PCA) were used to extract the characteristic wavelength variables of the preprocessed spectra, thereby reducing the impact of redundant information in the spectra on the model computation speed and prediction accuracy. Then, based on support vector machine (SVM), K-nearest neighbor algorithm (KNN), decision tree (DT), linear discriminant analysis (LDA), partial least squares discriminant analysis (PLS-DA), and naive Bayes (NB), 6 different identification models for empty grain content of rice seeds were established. Experimental results show that after SG+SNV+PBC preprocessing, the performance of the identification model is better than that of without preprocessing and SG+MSC+PBC. The 158 bands were selected based on the CARS combination SG+SNV+PBC preprocessing band selection. The KNN model established using the selected bands has a better prediction effect, where the testing set identification accuracy of the KNN model could reach 98.47%. The research indicates that near-infrared spectroscopy technology provides a feasible method for discriminating rice seed husk content grades, which provides theoretical support for the non-destructive testing of rice seed quality.
水稻是我国主要粮食作物, 发展水稻生产, 对维护我国粮食供给安全具有举足轻重的作用[1]。 选择优质水稻品种是水稻种植的第一要素, 而结实率作为水稻的重要性状, 对判断水稻种粒的饱满度、 千粒重和充实度等质量参数有着重要的意义, 一定程度上影响着水稻产量以及稻米的品质。
农艺性状分析是水稻品种选育的主要环节之一, 其中, 水稻结实率的测定可为育种人员对高品质水稻品种的决选提供重要依据。 测量水稻种粒结实率, 关键是对水稻种粒中结实粒和秕谷粒的含量比进行判别。 我国育种人员每年需要长时间重复开展水稻种粒计数、 计量及表型性状特征检测等繁重的统计工作[2]。 传统的水稻种粒的结实情况判别主要依赖人工完成, 通过人工观察和经验判断来完成对水稻种粒群的数量统计、 质量称量及部分性状参数的统计分析, 存在主观性强、 效率低下、 误差大的问题, 导致测量准确率不能满足现代水稻育种研究提出的要求[3, 4]。 因此, 有必要进行水稻种粒结实情况的自动快速判别方法研究, 帮助育种人员快速、 准确地获取水稻性状信息, 辅助指导育种人员挖掘更优质的水稻品种, 对水稻实现增产与高产有着重要意义。
近年来, 近红外光谱技术因其快速、 准确、 无损伤等优点而被广泛应用在各种农作物质量检测和分级中[5, 6, 7]。 Shi[8]等为实现大米新鲜度的快速预测, 采集不同新鲜度大米的光谱数据, 通过偏最小二乘判别分析(PLS-DA)、 支持向量机(SVM)和分类回归树(CART)几种方法构建新鲜度预测模型, 结果表明, PLS-DA和SVM在分类大米新鲜度方面表现出色, 其灵敏度和特异度均为1, 原始光谱在测试集中以100%的准确率确定了大米新鲜度。 Qiu[9]等利用傅里叶变换近红外光谱技术结合判别分类模型对不同品种甜玉米种子的光谱信息进行分类鉴别, 通过遗传算法筛选126个特征波长, 建立K-最近邻(KNN)、 类间软独立法(SIMCA)、 偏最小二乘判别分析(PLS-DA)和支持向量机判别分析(SVM-DA)四种分类模型, 结果显示在特征波长下, PLS-DA模型表现出99.19%的高精度。 孙阳[10]等利用便携式近红外光谱仪采集面粉的光谱数据, 采用标准正态变换和多元散射校正对光谱数据进行预处理, 通过最小二乘法对面粉中水分、 灰分、 面筋含量进行预测, 取得了较好的预测效果, 预测集相关系数为0.897 7, 均方根误差为0.327 1。 张静[11]等使用便携式近红外光谱仪结合多变量分析方法检测水稻水分含量, 采用9种不同预处理算法对光谱数据信息进行预处理, 基于连续投影算法(SPA)和竞争性自适应重加权算法(CARS)等对预处理后的光谱数据进行特征波段提取, 并建立偏最小二乘回归(PLSR)和主成分回归(PCR)模型, 实验验证了近红外光谱检测水稻籽粒水分含量的可行性, 其预测集相关系数和均方根误差分别为0.810 3、 0.388。 Qi[12]等基于近红外高光谱成像检测自然老化种子的活力, 并针对样品稀缺的问题, 采用光谱角度映射生成对抗网络(SAM-GAN)生成水稻种子光谱数据, 通过将SAM-GAN与真实数据混合建立卷积神经网络(CNN)模型, 取得了接近100%的准确率, 为快速、 无损、 准确测定水稻种子活力提供了一种有效的方法。
上述研究表明, 通过近红外光谱技术可定性或定量地获取作物或农产品的品质信息, 但目前未见针对稻谷秕谷含量进行判别从而为稻种结实情况判断提供依据的研究。 为此, 本文提出采用近红外光谱技术解决稻种秕谷含量检测问题, 以安徽省长粒稻为研究对象, 优选数据预处理方法、 特征选择方法, 建立最佳稻种秕谷含量等级判别模型, 实现稻种秕谷含量的快速、 准确判别, 以期为水稻种粒的结实情况判别提供依据, 从而辅助指导育种人员挖掘更优质的育种方法, 并为农业生产者改进栽培措施提供指导, 对水稻实现增产与高产有着重要意义。
光谱采集选择深圳谱研互联科技有限公司的手持式反射型近红外光谱仪NIR-R210, 波长范围为900~1 700 nm, 波长分辨率为14 nm, 信噪比为6 000∶ 1, 波长精度为± 1 nm, 其测量参数为吸光度。 通过MicroUSB接口直接连接到计算机设备, 并配备ISC-NIRScan软件使用, 可将采集的光谱数据导入计算机。 白板使用STD-DR100型号的标准白板, 用于取参考强度值。 光谱数据采集实验平台如图1所示, 由近红外光谱仪、 MicroUSB数据线和计算机组成。
 | 图1 光谱数据采集平台Fig.1 Collection platform of spectral data |
实验所用稻种由安徽省农业科学院水稻研究所生产, 根据中华人民共和国农业行业标准《NY/T 2915— 2016水稻高温热害鉴定与分级》中水稻结实率五个等级的划分标准和实际生产中水稻结实率较常见分类, 将水稻的结实情况分为Ⅰ 、 Ⅱ 、 Ⅲ 、 Ⅳ 、 Ⅴ 五个等级, 等级越高, 水稻秕谷含量越少, 水稻的结实情况越好。
水稻结实率常以总粒数中实粒数占比来衡量, 其中总粒数为实粒数与秕谷粒数之和。 为获取不同秕谷含量的稻种样品, 采用实粒数与秕谷粒数之比来制作样品, 制备包括0%秕谷、 25%秕谷、 50%秕谷、 75%秕谷和100%秕谷的样品, 其秕谷粒数和实粒数之比分别为: 0∶ 1、 1∶ 3、 1∶ 1、 3∶ 1、 0∶ 1。 选取待测的不同秕谷含量的水稻种子样品, 将水稻种子放入培养皿中进行数据采集。 采集时, 设定每个样本重复扫描12次, 测量时间为4.7 s。 为避免稻种堆积所造成的偏差, 在每个样本的多个不同位置选点进行测量, 取平均值作为光谱的原始数据。 不同秕谷含量的稻种样品分别扫描500个样本, 共2 500个样本。 采用基于联合X-Y距离的样本划分法(sample set partitioning based on joint X-Y distance, SPXY)按7∶ 3的比例划分数据集, 训练集1 750个, 测试集750个。
光谱仪采集的原始光谱数据除包含稻种样本真实信息外, 还包括光谱噪声、 杂散光、 基线漂移等干扰信息, 它们降低了光谱数据的质量, 影响了对稻种样本关键光谱信息的准确提取, 从而影响模型的判别性能。 因此, 在建立稻种秕谷含量等级判别模型前, 有必要对光谱数据进行预处理, 以降低各种干扰信息对稻种样本光谱数据的影响, 提高模型的判别精度。 在常用的光谱预处理方法中, 卷积平滑(Savitzky-Golay smoothing, SG)[13]基于滑动窗口和多项式拟合实现光谱数据中噪声的平滑处理; 多元散射校正(multiplicative scatter correction, MSC)[14]和标准正态变换(standard normal variate, SNV)[15]以样品光谱的平均光谱为参照, 并结合线性回归或正态变换修正每个光谱, 以降低多元散射的干扰; 而多项式基线校正(polynomial baseline correction, PBC)[16]通过多项式拟合基线漂移的变化趋势, 并在原始光谱中校正基线漂移。 为最大程度地减少噪声、 多元散射和基线漂移的影响, 本研究采用SG+MSC+PBC (SMP)和SG+SNV+PBC (SSP)两种组合预处理方法对光谱进行预处理, 基于SG平滑处理降低光谱信号中的背景噪声, 结合PBC校正光谱基线, 并通过MSC或SNV处理, 消除水稻籽粒表面差异带来的散射影响, 从而提高光谱的质量, 提升模型的准确性。
预处理虽减少了稻种样本光谱的干扰信息, 提高了光谱数据的质量, 但预处理后的光谱数据仍可能存在大量冗余信息, 甚至某些对稻种秕谷敏感的波段被其他波段共同解释或替代。 为从光谱数据中提取对建模有用的特征信息, 采用连续投影算法(successive projection algorithm, SPA)[17]、 竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)[18]和主成分分析(principal component analysis, PCA)[19]三种特征波段选择方法进行稻谷特征波段选择的降维处理。 SPA通过测量光谱之间的角度来评估光谱波长间相似性, 优选出能反应稻种秕谷含量的有效特征波段, 从而降低样品光谱特征维度, 提高模型的精确性和可解释性。 CARS采用偏最小二乘回归系数绝对值的大小对光谱数据各波长的重要性进行评估, 基于自适应加权重采样选择出回归系数绝对值大的波长, 有效去除无关特征波长。 PCA通过线性变换将原始特征转换为一组互相无关的主成分, 以保留数据的主要变化方向, 帮助捕捉最具代表性的特征, 减少冗余特征波段信息, 优化建模效率。
采用支持向量机(support vector machine, SVM)、 K-最近邻算法(k-nearest neighbor, KNN)、 决策树(decision tree, DT)、 线性判别分析(linear discriminant analysis, LDA)、 偏最小二乘判别分析(partial least squares discriminant analysis, PLS-DA)、 朴素贝叶斯(naive bayes, NB)对稻种的不同秕谷含量进行定性预测。 SVM[20]是一种经典的有监督机器学习方法, 结合核函数对秕谷含量已知样本进行训练, 可实现对稻种中不同秕谷含量的分类判别。 KNN[21]通过度量待分类样本与秕谷含量已知样本之间的距离实现对稻种秕谷含量的判别。 DT[22]基于递归切割方法沿平行于特征变量轴的方向选择最佳特征分裂, 进而判别稻种样本的秕谷含量。 LDA[23]通过最大化类别间方差和最小化类别内方差来区分不同秕谷含量的光谱数据, 实现稻种中秕谷含量的判别。 PLS-DA[24]结合了偏最小二乘回归的属性和分类分析技术的判别能力, 区分稻种不同秕谷含量组间差异性以实现秕谷含量判别。 NB[25]是基于贝叶斯定理的概率分类器, 通过计算给定的秕谷含量等级类别的条件概率选择最大概率的等级类别, 以判别稻种中秕谷含量。
为了评估模型在稻种秕谷含量判别中的性能, 采用查准率、 查全率、 F1分数(F1-score)以及准确率(Accuracy)为模型评价指标, 其中, 查准率表示模型在预测为正例的样本中, 有多少比例是真正的正例; 查全率表示模型在所有真正正例样本中, 有多少被模型正确预测为正例; F1分数是查准率和查全率的调和平均值, 综合考虑了分类器的查准率和查全率。 准确率是分类器正确分类样本的比例, 它考虑了模型在所有类别上的预测准确, 能够衡量模型的总体性能。 查准率(Precision)、 查全率(Recall)、 F1-score以及准确率(Accuracy)的定义如式(1)— 式(4)
式(1)— 式(4)中, TP是模型正确预测为正类别的样本数, TN是模型正确预测为负类别的样本数, FP是模型错误地预测为正类别的样本数, FN是模型错误地预测为负类别的样本数。
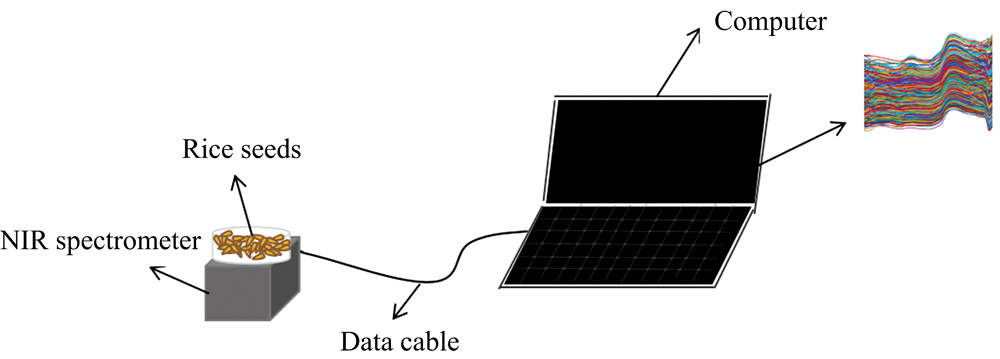
为直观分析不同秕谷含量的光谱差异, 对采集的不同秕谷含量的光谱进行可视化。 图2(a)所示为采集的不同秕谷含量稻种样本的原始光谱, 虽不同光谱在吸光度值上呈现细微差异, 但很难直观地区分不同秕谷含量的稻种样品的光谱信息。 为突出不同秕谷含量的稻种样品的光谱差异, 对原始光谱进行平均, 图2(b)所示为不同秕谷含量稻种样本的一组平均光谱曲线。 由于不同秕谷含量样品中饱满籽粒与空秕籽粒的淀粉成分差异导致其吸光度发生改变, 由图2(b)中光谱曲线可以看出稻种秕谷的含量越高, 平均吸收度越低, 不同秕谷含量稻种样本的平均光谱虽在某些波段呈现差异小, 但可以通过吸收峰、 吸收谷和波段明显地看出不同秕谷含量稻种样本的光谱差异, 如图2(b)中的红色箭头标记所示, 0%秕谷、 25%秕谷、 50%秕谷、 75%秕谷含量的平均光谱在波长为1 000、 1 200和1 450 nm等处存在吸收峰, 而在1 130、 1 310和1 680 nm等处存在吸收谷, 如图2(b)中的蓝色箭头标记所示, 并且在1 680 nm处50%秕谷、 75%秕谷、 100%秕谷含量的吸光度下降幅度大, 故可对光谱数据进行建模处理, 实现秕谷含量的判别。
 | 图2 不同秕谷含量的样本光谱曲线 (a): 不同秕谷含量样本的原始光谱; (b): 不同秕谷含量的平均光谱Fig.2 Comparison of spectra of samples with different grain contents (a): Original spectra of samples with different empty grain contents; (b): Average spectra of samples with different empty grain contents |
为减少原始光谱中噪声、 基线漂移和散射等因素的影响, 采用SG+MSC+PBC (SMP)和SG+SNV+PBC (SSP)对原始光谱进行预处理。 图3(a)为不同秕谷含量稻种样品的原始光谱, 预处理后的光谱如图3(b)和(c)所示, 对比预处理前后的光谱图可知, 经SMP和SSP预处理后的光谱具有极高的相似度, 能够有效抑制噪声、 散射效应和基线漂移的干扰。 为了选取较优的预处理算法, 对SMP和SSP预处理后的光谱均建立SVM、 KNN、 DT、 LDA、 PLS-DA和NB等6种判别分类模型, 结果如表1所示。 相比于使用原始光谱数据直接建模, 经SMP和SSP预处理后的各个分类模型性能都得到了不同程度的提升, 其中KNN、 LDA及PLS-DA在两种预处理方法下的准确率均达97%以上, 而SVM、 DT与NB在SSP预处理方法下的模型性能提升较为明显。 综合考虑各个分类模型在SMP和SSP预处理后的性能表现, 选择SG+SNV+PBC (SSP)为不同秕谷含量稻种样品的最佳预处理方法。
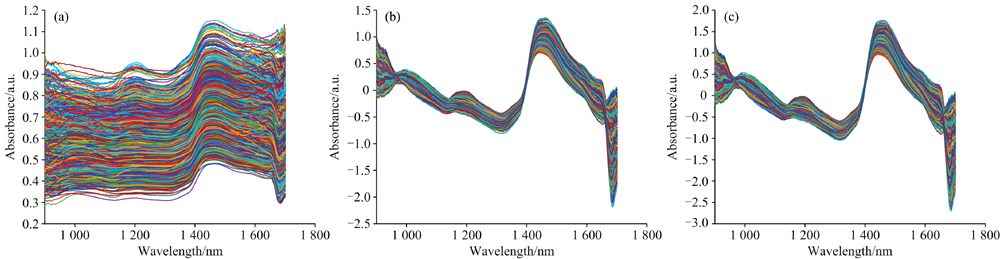 | 图3 原始光谱与预处理光谱对比 (a): 原始光谱; (b): SG+MSC+PBC预处理后光谱; (c): SG+SNV+PBC预处理后光谱Fig.3 Comparison between original and preprocessed spectra (a): Original spectra; (b): Spectra after SG+MSC+PBC pretreatment; (c): Spectra after SG+SNV+PBC pretreatment |
| 表1 基于预处理后全波段光谱的分类模型的预测准确率对比 Table 1 Comparison of prediction accuracy of classification models based on pre-processed full-band spectra |
为减少冗余波长, 降低模型计算复杂度, 在保证模型判别准确率的前提下, 有必要提取用于区分稻种不同秕谷含量的特征波长。 对经过预处理的稻种样本光谱数据分别采用SPA、 CARS和PCA 方法去除光谱中的冗余信息, 并结合SVM、 KNN、 DT、 LDA、 PLS-DA、 NB分类模型, 构建不同秕谷含量判别模型, 其中, CARS根据回归系数的大小调整各波长的权重, 在迭代过程中逐步剔除权重小的波长, 保留对模型最有信息价值的波长, 从而减少了不必要的信息负载; SPA基于向量的投影分析, 将波长投影到其他波长上, 通过计算其他波长与已选择波长之间的角度, 选择相似性最低的波长, 以有效降低数据的共线性。 由于不同分类模型可能需要不同的特征波长数来获取最佳的判别效果, 为确定不同分类模型中最优特征选择的数量, 通过5折交叉验证(5-Fold Cross-Validation)方法进行交叉验证, 计算每次交叉验证的准确率, 最后根据交叉验证的结果确定最佳特征数量。 不同分类模型的特征波长分布如图4所示, 图中蓝色实线为平均光谱, 红色点为光谱的特征波长在平均光谱上的分布。 SVM、 KNN、 DT、 LDA、 PLS-DA、 NB模型在SPA方法下选择的特征波长数依次是203、 158、 72、 223、 222、 227, 采用CARS方法选择的特征波长数依次是228、 223、 158、 219、 219、 145。 可见, 不同模型需要特定数量的波长特征才能达到最佳准确率, 并且不同特征波长选择算法筛选的特征数量存在差异, 需结合秕谷含量判别准确率选择最优的特征选择方法。
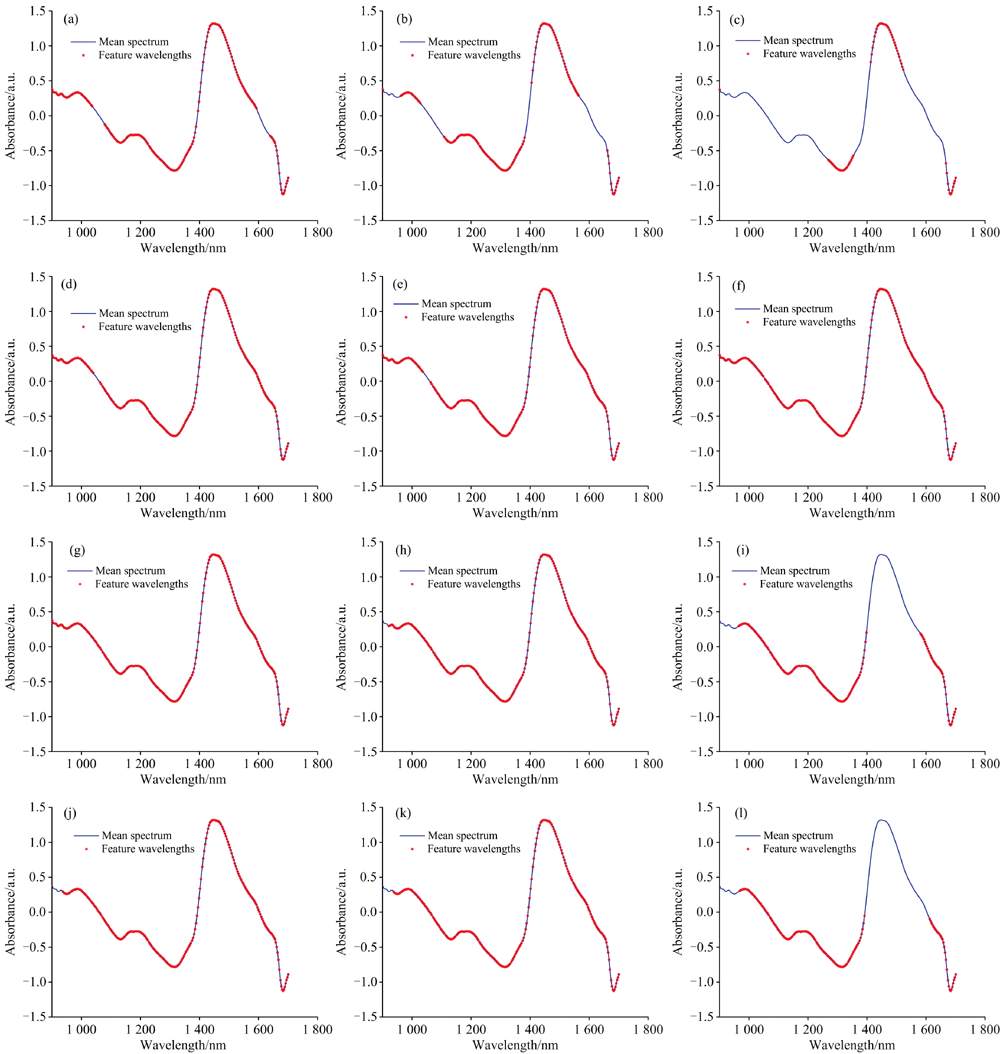 | 图4 不同模型用SPA和CARS特征选择方法得到的特征波长分布 (a): SSP-SPA-SVM; (b): SSP-SPA-KNN; (c): SSP-SPA-DT; (d): SSP-SPA-LDA; (e): SSP-SPA-PLS-DA; (f): SSP-SPA-NB; (g): SSP-CARS-SVM; (h): SSP-CARS-KNN; (i): SSP-CARS-DT; (j): SSP-CARS-LD; (k): ASSP-CARS-PLS-DA; (l): SSP-CARS-NBFig.4 Feature wavelength distributions of different models under SPA and CARS feature selection methods (a): SSP-SPA-SVM; (b): SSP-SPA-KNN; (c): SSP-SPA-DT; (d): SSP-SPA-LDA; (e): SSP-SPA-PLS-DA; (f): SSP-SPA-NB; (g): SSP-CARS-SVM; (h): SSP-CARS-KNN; (i): SSP-CARS-DT; (j): SSP-CARS-LD; (k): ASSP-CARS-PLS-DA; (l): SSP-CARS-NB |
PCA的目标是最大化数据方差, 通过选择主成分来保留数据中的主要信息, 从而实现降维。 通过计算每个主成分的方差, 并观察累积方差贡献率, 选择累积方差解释率达到或超过95%的主成分。 图5所示为主成分方差贡献率变化图, 经SG+SNV+PBC预处理后的光谱数据需选择数据的前三个主成分就能够解释至少95%的方差, 保留了98.86%的光谱信息。 图6展示了前三个主成分的载荷向量, 即在每个波长上的权重, 权重的绝对值大小表示了预处理后的特征在主成分上的重要性或贡献度, 其中1 667~1 700 nm波长段对于第一个主成分的贡献最大, 900~921和1 630~1 665 nm波长段对第二个主成分贡献最大, 900~940和1 005~1 093 nm波长段对第三个主成分的贡献率最大, 这些高权重值在相应的主成分中有更大的影响力, 对最终的PCA结果有更显著的贡献。
 | 图5 主成分方差贡献率变化Fig.5 Change of the contribution rate of principal component variance |
 | 图6 前三个主成分的波长权重Fig.6 Wavelength weights of the first three principal components |
为验证SPA、 CARS与PCA选择的特征波长对各模型判别结果的影响, 基于特征波长建立不同判别模型, 结果如表2所示。 由表2可知, 不同的判别模型在PCA降维下的性能均差于SPA和CARS, 这是由于PCA并未考虑类别信息, 而更专注于最大方差的方向。 对比表2中不同模型在SPA和CARS特征波长选择下的秕谷含量判别准确率, KNN的秕谷含量判别准确率最高, 在训练集上的准确率达100%, 测试集准确率高达98%以上, 而NB模型假设各个特征之间是相互独立, 不能捕捉特征之间存在较强的相关性, 导致模型的秕谷含量判别准确率最差; 相较于NB、 LDA和PLS-DA模型在训练集和测试集上的秕谷含量判别准确率有着较好的改善, LDA和PLS-DA模型通过最大化不同秕谷含量特征波长之间的差异, 以有效捕捉到光谱数据的类别关系, 实现秕谷含量的分类判别, 而SVM和DT在训练集上均获得90%以上的秕谷含量判别准确率, 但由于其在降维后可能会对训练集中的噪声和局部特征进行过度拟合, 导致测试集的性能下降。
| 表2 不同模型对稻种秕谷含量等级判别的准确率 Table 2 Accuracies of different models for determining grade of empty grain content in rice seed |
对比上述等级判别模型, SSP-CARS-KNN模型在训练集获取100%准确率, 且测试集准确率高达99.47%, 表明该模型在训练集上能够完美拟合数据, 同时在测试集上也有很好的泛化能力。 经交叉验证, 模型的K值设为1, 对训练数据的拟合非常灵活, 能够较好地适应训练数据的特点。 图7为SSP-CARS-KNN模型的混淆矩阵可视化, 对于150个水稻秕谷含量等级Ⅲ 样本, 仅有4个被误判为Ⅱ 级, 其他等级的样本均判定正确。 表3为SSP-CARS-KNN模型的评价指标值, 不同稻种秕谷含量等级的平均查准率为99.48%, 平均查全率为99.47%, 平均F1值为99.47%, 所有等级判别准确率为99.47%, 模型性能已经达到较好效果, 最终选择SSP-CARS-KNN模型作为稻种秕谷含量等级判别模型。
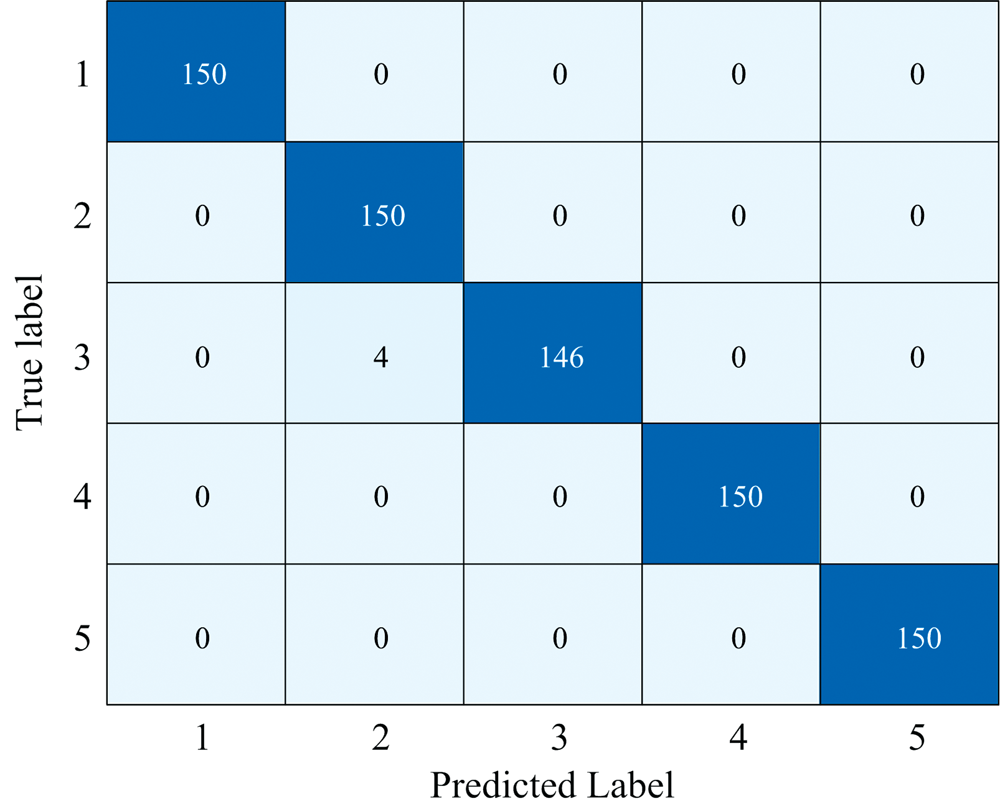 | 图7 混淆矩阵可视化Fig.7 Confusion matrix visualization |
| 表3 SSP-CARS-KNN模型对秕谷含量判别效果 Table 3 Determination effect of SSP-CARS-KNN model for grade of empty grain content in rice seed |
(1) 以安徽省长粒稻为研究对象, 研究了近红外光谱技术在稻种秕谷含量等级快速判别应用的可能性, 由于饱满籽粒与空秕籽粒的淀粉成分导致其吸光度发生改变, 不同秕谷含量稻种样本的平均光谱呈现明显差异, 此差异性对稻种秕谷含量等级的预测表现出良好的效果。
(2) 通过制备不同秕谷含量的稻种样品并采集光谱数据, 对原始光谱数据采用了多种预处理和特征选择技术, 建立了SVM、 KNN、 DT、 LDA、 PLS-DA和NB等六种判别模型, 并对不同模型在不同预处理和特征选择条件下的性能进行比较。 结果表明, 相较于原始光谱, 经SG+SNV+PBC (SSP)预处理后能有效提高模型精度, 且在SG+SNV+PBC预处理下, SSP-CARS-KNN模型在训练集和测试集上均表现出色, 训练集和测试集的等级判别准确率都可达到98%以上, 测试集750个样本仅有4个样本等级划分错误, 显示出对水稻秕谷含量等级判别具有较好的泛化能力, 说明了此模型能够用于稻种秕谷含量等级的快速判别。 后续研究将考虑继续结合水稻品种扩大样本的种类和范围, 使得模型具有更好的普适性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|