




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于双路多尺度卷积的近红外光谱羊绒羊毛纤维预测模型
[陈锦妮 , 田谷丰
, 田谷丰* , 李云红, 朱耀麟, 陈鑫, 门玉乐, 魏小双]
, 田谷丰, 李云红, 朱耀麟, 陈鑫, 门玉乐, 魏小双]
|
|


作者简介: 陈锦妮, 女, 1980年生, 西安工程大学电子信息学院讲师 e-mail: 396161675@qq.com
羊绒具有轻盈舒适、 光滑柔软、 稀释透气以及保暖好的特点, 由于羊绒价格十分昂贵, 因此市场上的羊绒产品质量良莠不齐。 现有的显微镜法、 DNA法、 化学溶解法和基于图像的方法具有损坏样本、 设备昂贵、 主观性强等不足。 近红外光谱技术是一种非破坏性、 可进行建模操作的快速测量方法。 针对传统的建模方法通常无法学习出通用的近红外光谱波段特征, 导致泛化能力弱, 且羊绒羊毛纤维的近红外光谱波段特征相似, 难以区分的问题, 本文提出一种基于双路多尺度卷积的近红外光谱羊绒羊毛纤维预测模型。 采集了羊绒羊毛样品的近红外光谱波段数据共1 170个进行验证, 近红外光谱波段数据范围是1 300~2 500 nm。 利用两个并行卷积神经网络来提取近红外光谱波段的特征, 采用原始近红外光谱波段数据和降维近红外光谱波段数据同时输入的方式, 并利用多尺度特征提取模块进一步提取中间具有贡献力的近红外光谱波段特征, 利用路径交流模块用于两路近红外光谱波段特征的信息交流, 最后利用类级别融合得到羊绒羊毛纤维预测结果。 在实验过程中, 将采集的80%近红外光谱波段数据用于模型训练, 20%近红外光谱波段数据用于模型测试。 模型测试集的平均预测准确率为94.45%, 与传统算法中的随机森林、 SVM、 1D-CNN等算法相比较分别提升了7.33%、 5.22%、 2.96%, 并进行消融实验对所提模型的结构进一步验证。 实验结果表明, 本文提出的双路多尺度卷积的近红外光谱羊绒羊毛纤维预测模型可实现羊绒羊毛纤维的快速无损预测, 为近红外光谱羊绒羊毛纤维预测提供了新的思路。
Cashmere is characterized by lightness and comfort, smoothness and softness, dilution and breathability, and good warmth. Because it is very expensive, the quality of cashmere products in the market is mixed. Existing microscopy, DNA, chemical dissolution, and image-based methods have shortcomings such as damaged samples, expensive equipment, and high subjectivity. NIR spectroscopy is a rapid measurement method that is non-destructive and allows for modeling operations. Aiming at the problems that traditional modeling methods usually fail to learn universal near-infrared spectral band features, resulting in weak generalization ability, and that the near-infrared spectral band features of cashmere wool fibers are similar and difficult to distinguish, this paper proposes a near-infrared spectroscopy cashmere wool fiber prediction model based on two-way multi-scale convolution. In terms of data preparation, a total of 1 170 near-infrared spectral band data of the original cashmere wool samples are collected for validation, and the range of the near-infrared spectral band data is 1 300~2 500 nm; in terms of model design, two parallel convolutional neural networks are utilized to extract the features of the near-infrared spectral band, and both the original near-infrared spectral band data and the downscaled near-infrared spectral band data are used as simultaneous. The original near-infrared spectral band data and the downscaled near-infrared spectral band data are input simultaneously. The intermediate contributing near-infrared spectral band features are further extracted using the multi-scale feature extraction module, and the path exchange module is used for the information exchange of the two near-infrared spectral band features. Finally, the cashmere wool fiber prediction results are obtained using the class-level fusion. In the experimental process, 80% of the collected near-infrared spectral band data are used for model training and 20% of the near-infrared spectral band data are used for model testing. The average prediction accuracy of the test set of the model proposed in this paper is 94.45%, which is improved by 7.33%, 5.22%, and 2.96%, respectively, compared with the traditional algorithms such as Random Forest, SVM, and 1D-CNN, etc. Ablation experiments are conducted to further validate the structure of the proposed model. The experimental results show that the proposed two-way multi-scale convolutional near-infrared spectroscopy cashmere wool fiber prediction model can realize the fast and nondestructive prediction of cashmere wool fibers, which provides a new idea for the prediction of cashmere wool fibers in near-infrared spectroscopy.
目前, 我国在世界范围内作为羊绒原料制造、 生产和面料加工出口最大的国家, 在国际贸易中优势明显。 羊绒比羊毛更加轻薄、 细腻、 柔软, 是舒适、 保暖服饰的主要原材料, 但受天然的环境影响, 羊绒的产量稀少, 羊毛的产量是羊绒的几十倍。 来自羊绒与羊毛的动物纤维原料加工一直是毛纺领域、 纺织品检测领域中的热点, 因此需要一种快速高效的羊绒羊毛纤维预测方法[1]。
在纺织领域中, 传统的识别方法为显微镜法、 DNA法、 化学溶解法和基于图像的方法。 光学显微镜检测法仍然是当前鉴别羊绒羊毛纤维的主流方法。 该方法主要是通过检测人员借助光学显微镜来观察和辨别纤维表面的物理形态特征, 凭借检测人员的经验来识别纤维的种类。 这种依靠人工的光学显微镜的纤维鉴别方法受主观因素的影响较大、 检测速度相对较慢、 人力成本高。 Tang等[2]采用DNA法对动物纤维进行鉴别, 设计了针对线粒体12s核糖体(rRNA)基因特异性反应的TaqMan聚合酶链反应(PCR)引物和探针, 可以有效的检测出羊绒/羊毛混合物中的每种成分, 但此方法使用的设备价格昂贵且检验过程非常复杂, 通常需要专业的工作人员。 张金良[3]将不同纤维放入pH值不同的化学溶液中, 发现纤维会出现不同的溶解度。 实验发现, 锦纶可以很快的溶解于化学溶液, 而涤纶不能溶解于化学溶剂, 可以有效的识别两种纤维。 Zhu等[4]将多特征选择与随机森林法结合, 形成了可靠稳定的羊绒羊毛纤维分类方法, 准确率在90%左右。 Zhu等[5]提出一种改进版本的ShuffleNetV2和迁移学习, 实现了羊绒羊毛纤维快速准确的纤维分类。
羊绒和羊毛两种纤维的主要成分都是角蛋白, 因此, 羊绒羊毛的近红外光谱图像非常相似, 但是由于羊毛中的半胱氨酸(H-CYS-OH)含量相较于羊绒少。 而半胱氨酸含量的多少会影响吸收峰的高低, 半胱氨酸含量高具有较高的吸光度峰值而含量低具有较低的吸光度峰值, 这就导致了羊绒羊毛纤维近红外光谱波段数据具有一定的差异。 因此, 很多研究者将机器学习的传统算法与近红外光谱技术相结合。 吕丹等[6]利用PCA结合波长最大距离法对羊绒羊毛纤维进行预测。 实验结果表明, 对于羊绒预测准确率为80.76%, 羊毛的预测准确率为87.02%。 王彩虹等[7]利用PSO-SVM对羊绒羊毛纤维建立了定性模型, 对于羊绒羊毛纤维预测准确率达到93%, 实现了对羊绒羊毛的定性分析。 现有的方法对于羊绒羊毛的预测性能仍有待提高, 需要对数据进行复杂的预处理和波段选择。 近红外光谱技术对于其他物质的预测有了较多有效的模型, 但是对于羊绒羊毛的快速、 无损、 准确的预测还没有比较好的模型, 因此本文结合深度学习技术针对羊绒羊毛纤维预测提出了一种有效的模型。
深度学习中作为一种网络模型的神经卷积网络CNN, 在一些任务中都表现出色, 例如, 图像分割、 分类、 检测和检索等。 近几年来, 利用卷积神经网络(CNN)与近红外光谱技术快速发展并应用于农业[8]、 医疗[9]、 食品[10]以及煤矿[11]等领域。 Liu等[12]提出一种采用深度卷积神经网络对RRUFF矿物拉曼光谱数据实现多分类的方法, 得到较好的分类效果。 蒲姗姗等[13]提出的1D-CNN的近红外光谱分类算法, 对药品、 啤酒、 芒果以及葡萄有良好的分类效果。 杨友等[14]提出的CNN结合特征选择回归方法对小麦蛋白质含量检测取得很好的效果。 张效艇等[15]利用图卷积神经网络与近红外光谱建模, 提高对脑力负荷的抽象特征提取能力与识别精度。
深度学习技术可以自行的从数据中学习和提取出特征且鲁棒性强, 在数据挖掘[16]、 机器翻译[17]、 自然语言处理[18]、 面部识别[19]、 目标识别[20]等领域有着广泛的应用。 本文提出双路多尺度卷积神经网络模型, 结合深度学习技术与近红外光谱技术, 设计了近红外光谱波段降维模块、 多尺度特征提取模块和路径交流模块, 对1D-CNN卷积神经网络进行改进, 解决传统1D-CNN特征提取不充分, 导致预测精度低的问题, 从而实现快速、 无损、 准确的羊绒羊毛纤维预测。
羊毛近红外光谱波段数据集有21份样本, 包含澳洲羊毛、 赤峰敖汉土种分梳绵羊毛、 国产新疆细毛羊羊毛、 清河县丝光长羊毛、 赤峰敖汉土种分梳绵羊羔毛、 新疆长羊毛、 山羊毛等, 每种样品各三份, 羊绒近红外光谱波段数据集有18份样本, 包含阿富汗紫绒、 新疆白山羊绒、 紫无毛绒(外蒙、 西藏)、 赤峰敖汉羊绒、 陕西套子无毛绒各三份。
近红外光谱波段数据采集使用RZNIR 7900近红外光谱分析仪, 仪器如图1所示。 该仪器测量波长范围是1 000~2 500 nm, 近红外光谱波段数据波长采样间隔设置为1 nm, 采用漫反射方式采集羊绒羊毛纤维近红外光谱波段数据。 由于不同成分染料的结构会对反射性能产生影响, 导致近红外光谱波段数据有偏差, 而影响最严重的波段范围是1 000~1 300 nm, 本实验中羊绒羊毛纤维近红外光谱波段数据集都采用1 300~2 500 nm波段范围进行后续的处理和纤维预测。 采集步骤如下: (1)羊绒羊毛纤维样本收集阶段, 为确保纤维样本近红外光谱波段数据的稳定性, 所采用的样本均为羊绒羊毛的原始纤维; (2)近红外光谱波段数据采集阶段, 近红外光谱分析仪在常温条件下, 开机预热半小时。 随后, 将羊绒羊毛纤维样本平铺放入到近红外光谱分析仪的检测光圈内, 使纤维样本在光圈内是均匀分布且保证厚度不低于3 mm, 并用秤砣扣压, 确保纤维样本在光圈内; (3)对纤维样本进行扫描, 获得红外光谱曲线。
 | 图1 RZNIR 7900近红外光谱分析仪Fig.1 RZNIR 7900 near-infrared spectroscopy analyzer |
在不影响分析速率的条件下, 适当增加近红外光谱扫描次数, 将每份纤维样本正反两面各作一次测量, 取其平均值放入到数据集中。 每份样品测量30次, 然后将平均近红外光谱数据导出, 并保存为csv文件。 羊绒羊毛纤维近红外光谱数据总共采集1 170个, 其中羊毛近红外光谱数据有630个, 羊绒近红外光谱数据有540个。 羊绒羊毛近红外光谱曲线如图2所示。
 | 图2 羊绒羊毛近红外光谱曲线图Fig.2 Near infrared spectra diagram of cashmere and wool samples |
本文提出双路多尺度卷积神经网络模型。 在保留原始近红外光谱波段的基础上, 通过近红外光谱波段降维模块得到降维后的具有分类判别力的近红外光谱波段。 每个路径内部均采用多尺度特征提取模块提取更加丰富的特征。 此模型还包括两个信息交互块, 以确保从原始近红外光谱波段和降维后的近红外光谱波段提取的特征进行交流融合。 最后利用类级别的融合, 以得到最终的羊毛羊绒纤维预测。 双路多尺度卷积神经网络模型结构图如图3所示。
 | 图3 双路多尺度卷积神经网络模型结构图Fig.3 Structure of a two-way multi-scale convolutional neural network model |
1.2.1 近红外光谱降维模块
一般来说, 在处理近红外光谱波段数据时, 常常会采用无监督的主成分分析(principal component analysis, PCA)线性降维方法, 以及有监督的线性判别分析(linear discriminant analysis, LDA)降维方法。 PCA通过对数据线性投影, 可以实现把更高维的数据映射到更低维的目标空间上, 但同时要保证在投影到的维度空间上方差最大, 以确保在使用更低维度数据的同时保留更多原始数据的维度。 这就会导致经过PCA降维后的特征不如原始特征的解释度强, 由于要确保方差最大, 因此可能会丢失方差小的重要信息, 不利于后续光谱数据的纤维预测。 将数据投影采用有监督的降维方法LDA分类输出, 使得类内方差在投影后呈现最小的同时, 类间方差也达到最大。 LDA的降维只能降到比类别数少一个, 这就导致了特征提取的不够全面, 同时LDA也可能会导致过拟合的情况。
为此, 提出了利用一维卷积的降维方式, 来提高降维的泛化能力。 如式(1)所示, 给定原始近红外光谱X∈ RN× 1, N表示原始近红外光谱波段长度, 经过近红外光谱波段降维模块得到新的光谱波段X'∈ RN'× D', N'表示降维后的近红外光谱波段长度, 并作为新分支的输入。 创建新分支的目的在于学习出更具有预测判别力的近红外光谱波段。
1.2.2 多尺度特征提取模块
针对一维数据特征提取方法通常为一维传统卷积。 一维传统卷积只对近红外光谱波段相邻特征点之间进行卷积, 这就会导致一些关键判别信息丢失, 而跨特征点之间通常隐含更具判别力的关键信息。 因此, 本模块采取一维空洞卷积代替一维传统卷积, 为进一步得到更加丰富的近红外光谱波段特征。 具体结构图如图4所示。 以新分支某个近红外光谱波段特征为例, 同时采用了不同空洞率的空洞卷积叠加得到近红外光谱波段M=
 | 图4 多尺度特征提取模块Fig.4 Multi-scale band feature extraction module |
1.2.3 路径交流模块
本模块用于近红外光谱波段跨路径之间的特征融合补充。 如图5所示, 由于原始近红外光谱波段经过多尺度提取模块后的近红外光谱波段Xup1包含原始近红外光谱波段特征信息, 因此模块先由近红外光谱波段Xup1补充到降维后的近红外光谱波段Xdown1, 随后由经过多尺度特征提取后的近红外光谱波段Xdown2补充到近红外光谱波段Xup1中得到近红外光谱波段Xup2。 本模块的目的是使新得到的原始近红外光谱波段和降维后的近红外光谱波段包含更加丰富具有辨别力的特征信息, 在后续模型的纤维预测中才能更有利于分类。 具体如式(4)和式(5)所示, 其中Sig.为Sigmoid激活函数
 | 图5 路径交流块Fig.5 Path communication module |
1.2.4 融合模块
为了更好地将原始近红外光谱波段Xup2和降维后的近红外光谱波段Xdown2结合, 此模块采用类级别融合, 涉及到的计算公式如式(6)— 式(8)所示, 其中u可以平衡原始光谱波段和降维光谱波段类别的平衡超参数。
1.2.5 模型损失函数
本研究的主要目标是进行羊绒羊毛纤维预测, 这是一个二分类问题。 为了实现这个目标, 将采用二元交叉熵函数(binary cross entropy loss, BceLoss)作为损失函数来衡量二分类问题中模型的预测质量, BceLoss公式如式(9)所示。 P1(y)和P2(y)分别代表yi× logp(yi=1)和(1-yi)× log(1-p(yi=1)), yi指的是第i个样本的二元标签值, 值为0或1, p(yi=1)是模型对第i个样本的预测值, 即模型预测第i个样本的标签值为1的概率。 当预测结果和真实标签一致时, 损失函数的值接近于0, 表示模型的预测是准确的; 而当预测结果和真实标签不一致时, 损失函数的值变大, 表示模型的预测有误。
基于PyTorch框架建立模型。 实验环境: 13th Gen Intel(R) Core(TM) i9-13980HX 2.20 GHz; 计算机内存为1T; NVIDIA GeForce RTX 4080 Laptop GPU; 12G显存。 为优化模型以及其他模型进行对比, 系统中配置了conda虚拟环境, 统一利用python3.7.0以及pytorch1.10.0版本进行不同模型的对比实验, 此外还安装了一些Numpy、 Pandas、 Sklearn等python算法库和视觉库, 以实现神经网络的正常运行。
对羊绒羊毛纤维近红外光谱波段数据集进行训练和测试, 先将模型在训练集上进行相同数据的反复训练, 充分学习数据特征, 然后用测试集对模型进行评估。 将测试集输入到模型中进行分类预测, 采用召回率(Recall, R)、 准确率(Accuracy, ACC)、 F1(F1-Score)、 精确率(Precision, P)以及混淆矩阵作为评价模型纤维预测效果指标。 评价指标如式(10)— 式(13)所示。
式中, TP是指将羊绒或羊毛纤维样本预测为正类的数量; TN指的是非羊绒羊毛纤维被正确识别为负样本; FP是指将非羊绒羊毛纤维预测为羊绒羊毛的数量; FN是指将正类样本预测为负类样本的数量。 本工作主要是用作羊绒羊毛纤维的二分类问题, 即如果将羊毛这一类别看作正类的话, 那么羊绒就属于负类, 对于羊绒来说也是一样的。 一般来说, ACC的值越接近1表示模型分类预测的准确度越高。 用n× n的混淆矩阵, 来评估网络模型的预测准确度; 各列代表羊绒或羊毛纤维预测的种类, 各列总数为预测到的羊绒或羊毛纤维对应类别的数量; 每行代表纤维样本的真实种类, 每行总数代表该种类纤维样本的真实数量。
共采集的630个羊毛和540个羊绒数据作为模型建立和评估的研究对象。 将数据集的80%划分为模型的训练集, 在训练集中再随机划分出20%作为验证集, 20%的数据集作为模型的测试集。 网络模型的训练使用训练集的羊绒羊毛近红外光谱波段数据, 验证集的羊绒羊毛近红外光谱波段数据当作选取最佳模型的依据, 测试集的羊绒羊毛近红外光谱波段数据用来验证羊绒羊毛纤维预测效果。 羊绒羊毛近红外光谱波段数据集划分如表1所示。
| 表1 羊绒羊毛近红外光谱波段数据集划分 Table 1 Data set partitioning of cashmere and wool samples |
本研究的核心是分类问题, 采用的是上文中介绍的损失函数BceLoss, 同时采用Adam优化器优化网络模型训练过程。
将训练模型的学习率(learning rate)设置为0.01, 批样本(Batchsize)设置为8, 迭代轮数设置为100次。 训练集和验证集的准确率与loss曲线如图6所示。 从训练的损失函数曲线来看, loss值随着迭代的次数在逐渐下降, 其中前25轮成波动式快速下降, 25轮后趋于平稳; 验证集的准确率曲线在前25轮的时候还有明显的波动, 25轮后区域平稳, 模型得到很好的收敛。 对模型训练100轮后进行保存所训练的模型, 并选取最佳模型对测试集中的近红外光谱数据进行测试, 并评估模型的预测性能。
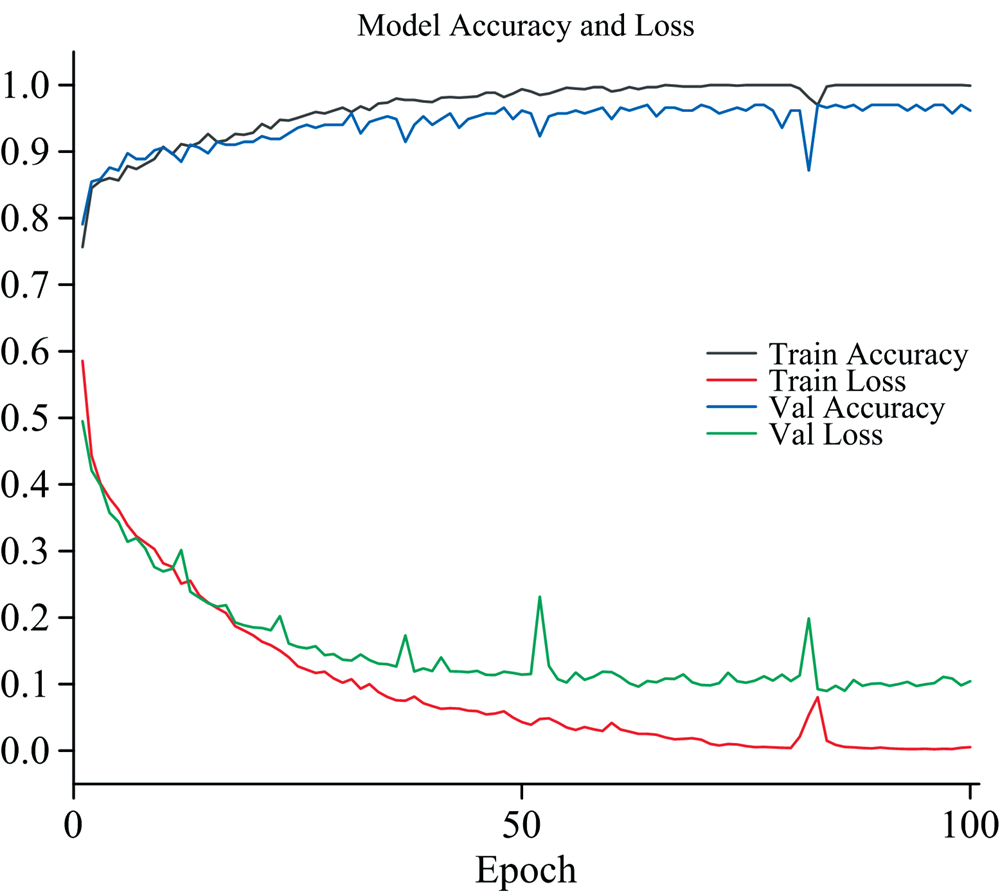 | 图6 训练集和验证集的准确率和Loss曲线Fig.6 Accuracy and loss curves of training set and test set |
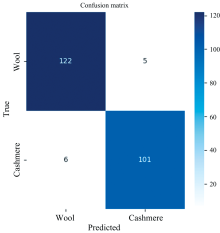
双路多尺度卷积神经网络模型一次预测结果的混淆矩阵如图7所示。 从图中可以看出, 羊毛总数为127, 预测正确的个数为122; 羊绒总数为107, 预测正确个数为101, 基本可以预测出羊绒羊毛纤维。
 | 图7 双路多尺度卷积模型一次预测结果的混淆矩阵Fig.7 Confusion matrix of the first prediction results of the two-way multi-scale convolution model |
为了比较双路多尺度卷积神经网络模型与传统模型的性能, 使用多种算法进行实验, 包括多层感知机(multilayer perceptron, MLP)、 决策树模型(decision tree algorithm, DTA)、 K-近邻算法(K-nearest neighbors, KNN)、 随机森林(random forest, RF)以及支持向量机(support vector machine, SVM)与本文所提出的改进的算法进行预测结果对比。 为公平比较不同模型的羊绒羊毛纤维预测效果, 均采用原始羊绒羊毛近红外光谱波段数据作为输入, 对不同模型进行训练。 不同模型羊绒羊毛纤维的预测结果如表2所示。 从表2可以看出, 在使用相同的羊绒羊毛近红外光谱波段数据集对模型进行训练的情况下, 本模型预测的平均准确率可达到94.45%, 相较于随机森林算法提升7.33%, 明显优于传统机器学习的算法和神经网络模型; 这是因为本文提出的模型通过近红外光谱降维模块和多尺度特征提取模块进行深层次的近红外光谱波段特征提取, 而路径交流模块也对两路近红外光谱特征进行特征交互, 最后利用类融合方法进行特征融合, 从而提高了模型预测的平均准确率。 进而证明本文提出的模型可以实现近红外光谱羊绒羊毛纤维的快速无损准确的预测。
| 表2 不同模型预测羊绒羊毛的预测结果(%) Table 2 The prediction results of different models for distinguishing cashmere and wool (%) |
为验证本文所提算法对羊绒羊毛纤维预测效果的影响, 在自建的数据集上进行一系列消融实验。 设置的实验如下: 原始数据单路输入、 仅移除路径交流模块、 仅移除多尺度特征特征提取模块以及整体改进后的模型, 消融实验结果如表3所示。
| 表3 在羊绒羊毛数据集上进行消融实验 Table 3 Ablation studies on dataset of cashmere and wool |
表3中的结果表明, 原始数据单路输入在经过多尺度特征提取模块后, 平均预测准确率提高了0.37%; 对于仅移除路径交流模块后的网络模型, 平均预测准确率提高了1.74%; 对于仅移除多尺度特征提取模块后的网络模型, 平均预测准确率提高了0.55%; 总的模型相较于原始的1D-CNN平均准确率提高了2.96%。 综上所述, 本文提出的改进模型在预测准确率上有提高。
由于近红外光谱技术具有高效、 无损以及成本低的优点, 使用近红外光谱仪获取的羊绒羊毛光谱数据并结合深度学习技术提出了一种双路多尺度卷积神经网络模型, 从而实现了羊绒羊毛快速准确的预测。 实验结果表明所提出的双路多尺度卷积神经网络模型通过多尺度光谱波段特征提取以及双路近红外光谱波段特征交流等过程可以有效的提取出具有辨别力的近红外光谱波段特征, 并用于纤维预测。 使用20%的近红外光谱波段数据进行测试评估发现, 本模型可以对于羊绒羊毛纤维进行预测, 预测的准确率可达到94.45%、 召回率为94.36%、 精确率为93.89%, 相比传统的模型如SVM、 随机森林、 MLP等有着更好的预测效果, 并进行消融实验, 验证了模型的有效性。 研究也表明了深度学习与近红外光谱波段数据结合可以有效的提取近红外光谱波段数据所含更深层次的特征信息, 因此, 后续可以将更新的深度学习网络模型引入近红外光谱纤维预测领域, 为近红外光谱预测羊绒羊毛纤维技术提供一种新的方向。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|