

{kind=link}
{kind=link}
{kind=link}
{kind=link}
中红外光谱技术的乳化溢油检测方法研究
[李心怡1  , 孔德明
, 孔德明1, * , 宁晓东2 , 崔耀耀3 ]
, 孔德明, 宁晓东|
|


作者简介: 李心怡, 女, 1999年生, 燕山大学电气工程学院博士研究生 e-mail: lixinyi12342021@163.com
快速、 准确获取乳化溢油的种类和含油量等信息对于海上溢油污染的监测具有重要意义。 中红外光谱技术是一种简单、 高效的检测手段, 可通过光谱特征峰的位置和强度来表征物质分子的结构信息。 然而, 目前将中红外光谱技术应用于乳化溢油的检测还尚未有成熟的研究成果。 基于此, 选取92#、 95#、 98#三种具有代表性的汽油样本, 建立乳化汽油体系; 选取5#、 7#、 10#三种具有代表性的白油样本, 建立乳化白油体系。 利用中红外光谱技术获得乳化溢油样本的光谱数据并进行预处理, 然后选用线性判别分析(LDA)算法实现乳化溢油的油种鉴别。 在此基础上利用竞争性自适应重加权采样法(CARS)和随机森林(RF)分别选择出与含油率呈线性和非线性关系的特征波长, 既降低了数据维度又丰富了特征数据的多样性。 然后选用极端梯度提升(XGBoost)、 一维卷积神经网络(1D-CNN)、 支持向量回归(SVR)作为基学习器, 偏最小二乘回归(PLSR)作为元学习器, 构建两层的Stacking集成学习模型来预测乳化溢油中的含油率。 Stacking集成学习模型获得的乳化汽油和乳化白油的测试集决定系数分别为0.982 4和0.987 3, 均方根误差分别为0.041 0和0.034 0。 与XGBoost、 1D-CNN、 SVR、 PLSR相比, Stacking集成学习模型具有更好的稳定性和准确性。 上述研究结果表明, 基于中红外光谱技术结合LDA和Stacking集成学习的检测方法, 能有效实现乳化溢油的定性与定量分析, 从而为乳化溢油领域的研究提供了新思路。
Quick and accurate acquisition of information, such as emulsified oil spills' types and oil content, is of great significance for monitoring offshore oil spill pollution. Mid-infrared spectroscopy is a simple and efficient detection method that can characterize the structure information of substance molecules by the position and intensity of spectral characteristic peaks. However, applying infrared spectroscopy technology to detect emulsified oil spills has not yet yielded mature research results. Based on this, this paper selected three representative gasoline samples, 92#, 95#, and 98#, to establish an emulsified gasoline system and three representative white oil samples, 5#, 7#, and 10#, to establish an emulsified white oil system. The spectral data of emulsified oil spill samples were obtained by mid-infrared spectroscopy, and pretreatment was carried out. Then, a Linear Discriminant Analysis (LDA) algorithm was used to identify oil species from emulsified oil spills. Based on this, the Competitive Adaptive Reweighted Sampling (CARS) and Random Forest (RF) methods were used to select the feature wavelengths with linear and non-linear relationships with oil content, respectively. This reduces data dimensionality and enriches the diversity of feature data. Then, use eXtreme Gradient Boosting (XGBoost), 1D Convolutional Neural Network (1D-CNN), Support Vector Regression (SVR) as the base learners, and Partial Least Squares Regression (PLSR) as the meta-learner to build a two-layer Stacking integrated learning model to predict the oil content in emulsified oil spills. The test set determination coefficients of emulsified gasoline and emulsified white oil obtained in the Stacking integrated learning model were 0.982 4 and 0.987 3, respectively, and the root mean square errors were 0.041 0 and 0.034 0, respectively. Compared to XGBoost, 1D-CNN, SVR, and PLSR, the Stacking integrated learning model has better stability and accuracy. The above research results indicate that the detection method based on mid-infrared spectroscopy technology combined with LDA and Stacking integrated learning can effectively achieve qualitative and quantitative analysis of emulsified oil spills, providing new ideas for research in emulsified oil spills.
石油是当今社会不可缺少的重要动力能源, 在经济和工业领域中都占据着十分重要的地位[1]。 随着人们对石油的需求量逐渐增大, 导致海上溢油污染事件频发, 对海洋环境造成威胁, 同时也会危害人体健康[2]。 溢油进入海域后会在海面上形成复杂多样的溢油污染类型, 当溢油和海水混合后, 会形成油包水和水包油等不同的乳化状态, 受外界因素影响会使乳化物的粘度不断增加, 为后续的清理工作增添难度[3]。 因此, 研究乳化溢油的检测方法对保护海洋生态系统的可持续发展具有重要意义。
中红外光谱技术可用于分子中各类官能团和结构的检测, 并具有灵敏度高、 检测速度快等优点, 被广泛应用于石油类产品的检测。 王明吉等将不同型号的汽油以及混合汽油作为研究对象, 利用中红外光谱技术获得特征图谱, 建立深度置信网络模型, 提高了汽油鉴别的精确度[4]。 Khorrami等基于中红外光谱技术, 采用遗传算法选择出表征汽油样品中质量参数的特征变量, 再与化学计量学方法相结合, 实现对不同类别的汽油样品分类[5]。 夏延秋等利用中红外光谱技术针对润滑油微量添加剂的检测展开研究, 通过改进遗传算法结合机器学习建模, 高效实现多种润滑油的同步识别[6]。 Lu等利用红外光谱技术获得原油油包水和水包油的反射光谱, 建立反射率与油浓度的光学模型, 为量化溢油量奠定了基础[7]。 杜馨等基于中红外光谱技术结合偏最小二乘法实现了10%~50%原油含水率的定量分析[8]。 综合上述研究现状可以看出目前将中红外光谱技术应用于乳化溢油的研究还相对较少, 且主要研究内容围绕原油的特定乳化阶段进行检测分析。 因此现阶段存在的研究空白是如何利用中红外光谱技术对轻质油的不同乳化阶段展开全面研究。
Stacking集成学习是对多个学习器构建分层模型的集成框架, 该模型弥补了单个学习器在解决问题时存在的不足, 且能够充分融合各个学习器的优势, 提升模型的泛化能力, 达到提高预测精确度的目的[9]。 张晨等采用SVR、 XGBoost和多层感知机作为基学习器, 构建Stacking集成模型实现对蓝莓的无损检测, 结果表明Stacking集成模型比单学习器模型具有更好的预测结果[10]。 Xu等根据Stacking模型将随机森林、 极端随机回归树和梯度提升决策树回归进行集成, 有效预测了混合气体中的浓度[11]。
因此, 本工作选择轻质油作为研究对象, 分别构建乳化汽油体系和乳化白油体系, 并按照不同浓度梯度配制乳化溢油样本, 确保涵盖乳化溢油的不同阶段。 利用中红外光谱技术获得乳化溢油样本的吸收光谱, 建立线性判别分析模型, 实现乳化溢油的分类识别; 采用竞争性自适应重加权采样法和随机森林算法选择特征波长, 以XGBoost、 SVR、 1D-CNN作为基学习器, PLSR作为元学习器, 建立Stacking异构集成回归模型, 实现乳化汽油和乳化白油的含油率预测。 以期为乳化溢油的检测提供一种快速、 准确的方法。
乳化溢油的形成是表面活性剂作用的结果, 表面活性剂能够降低形成乳化液所需的能量, 并保持乳化液处于稳定状态[12]。 因此本实验通过加入微量Span80和Tween80乳化剂制备乳化样本, 两种乳化剂添加的量分别为0.51和0.1 g, 混合后乳化剂的HLB值为6.05, 占油水乳化液总质量的1.22%。 选取92#、 95#、 98#三种汽油和5#、 7#、 10#三种白油作为研究对象。 样本的具体配制过程如下: 首先选用由天津天马衡基仪器公司生产的精密电子秤(型号: FA1004, 精度: 0.000 1 g)作为称量仪器, 分别称取适量实验油、 秦皇岛渤海湾的海水和两种乳化剂; 然后将Span80和Tween80分别加入油和海水中, 使用磁力搅拌器进行搅拌直至呈现均匀的乳状液。 每类乳化溢油配制25个实验样本, 含油率范围为5%~95%。 并且为了保证不同类别、 不同浓度下样本检测的一致性, 所有样本的配制过程均在室温下进行。
利用德国布鲁克公司生产的VERTEX 70傅里叶变换红外光谱仪采集乳化样本的光谱数据。 光谱扫描范围为500~4 000 cm-1(中红外区), 分辨率为4 cm-1。 值得注意的是, 实验环境、 测量背景光以及仪器稳定性均会对实验结果造成影响。 实验环境因素的影响主要体现在空气中的水蒸气会吸收红外辐射, 影响检测结果的可靠性, 因此在红外光谱仪中放入干燥剂, 保证整个检测过程处于干燥环境。 在采集数据时分别获取背景和样本数据, 将两者相减可得到样本的真实光谱数据, 从而降低背景光的影响。 为了增强仪器测量的稳定性以及减少实验测量误差, 每个样本进行30次扫描, 将每5次扫描结果取平均, 最终得到6条光谱数据。 即所构建的乳化汽油体系和乳化白油体系均可获得450组光谱数据。
1.2.1 光谱数据采集
图1所示为92#、 95#、 98#汽油所构成的乳化汽油体系的原始中红外光谱图。 图2所示为5#、 7#、 10#白油所构成的乳化白油体系的原始中红外光谱图。 图1和图2中(a)所示均为含油率5%~95%范围内的光谱图, 图1和图2中(b)所示均为含油率95%时的光谱图, 图1和图2中(c)所示均为含油率5%时的光谱图。 从图中可以看出随着含油率的变化, 不同乳化溢油样本的吸收光谱均呈现出两种波形, 且存在明显差异。 当含油率较高时, 乳化溢油的光谱特征峰较为明显; 当含油率较低时, 乳化液中的水分子起主要作用, 导致光谱图中出现大量表征水分子的毛刺峰, 覆盖了表征油类分子结构的特征峰。 因此, 乳化溢油在低含油率时测得的中红外光谱数据信噪比较低。 乳化汽油的特征峰主要位于谱带的700~800、 1 040~1 055、 1 360~1 385、 1 450~1 470和2 850~3 000 cm-1。 乳化白油的特征峰主要位于谱带的715~740、 1 360~1 385、 1 450~1 470和2 850~3 000 cm-1。 这些特征峰主要是由于烷烃和芳香烃中化学键或基团的振动而产生的, 表征了乳化液中油类分子结构的组成和含量。 两种乳化溢油在3 200~3 500 cm-1谱带处产生的特征峰均为分子间氢键O— H的伸缩振动, 表征乳化液中的水含量。 当乳化溢油只在2 100~2 200 cm-1谱带内存在1个特征峰, 并同时产生大量的毛刺峰时, 表明当前乳化液处于低含油率状态。
 | 图1 乳化汽油的原始中红外光谱图Fig.1 Original mid-infrared spectra of emulsified gasoline samples |
 | 图2 乳化白油的原始中红外光谱图Fig.2 Original mid-infrared spectra of emulsified white oil samples |
1.2.2 光谱数据预处理
选用多元散射校正(multiplicative scatter correction, MSC), 标准正态变量变换(standard normal variable transformation, SNV), 一阶导数(first derivative, FD), S-G(Savitzky-Golay)滤波器等方法对光谱数据进行预处理, 以提高数据的利用率和模型的精确度。 MSC通过计算平均光谱来校正光谱数据中的基线平移量和偏移量, 从而增强数据间的相关性。 SNV是将原始光谱数据转化为标准正态分布的变量, 有效消除光谱数据中的偏移和缩放现象。 FD可将吸光度随波长的变化转换为吸光度变化率随波长的变化, 以突出显示光谱中的峰值和谷值, 提高光谱数据间的分辨率。 MSC、 SNV和FD均可以有效消除由散射引起的基线漂移现象。 S-G滤波器利用多项式最小二乘法对滤波窗口内的数据点进行拟合, 以确定最优的滤波系数。 S-G滤波器主要用于数据的平滑去噪, 常与基线校正方法结合使用。
线性判别分析(linear discriminate analysis, LDA)是将带标签的高维数据投影到低维空间, 使得投影后样本的类间距离更大, 类内距离更小, 从而实现样本分类。 其中二分类问题是将m维的样本数据通过线性变换映射到一维, 由类间散度矩阵SB和类内散度矩阵SW构建目标函数J(w), 寻找目标函数的极大值, 以获得最佳投影方向w。
利用竞争性自适应重加权采样法(competitive adapative reweighted sampling, CARS)和随机森林(random forest, RF)选择出抗干扰能力较强, 更具代表性的特征波长。 CARS先对数据集进行蒙特卡洛采样, 利用衰减指数法确定波长数量, 然后通过自适应加权采样保留回归系数中绝对值权重较大的波长构成新的子集。 CARS算法选择PLSR作为校正模型, 因此筛选出的波长与含油率之间持线性关系。 RF是一种能够有效地处理非线性问题的学习模型。 使用袋外数据错误率来作为评估特征重要性的指标, 通过设置特征重要性阈值选择出相对应的特征波长子集, 作为非线性特征波长集合。
构建两层的Stacking集成学习模型。 第一层的学习模型称为基学习器, 面向的是维度较高、 特征较为复杂的数据, 因此选用XGBoost、 1D-CNN和SVR三种回归预测能力较强且具有明显差异的模型作为基学习器。 第二层的学习模型称为元学习器, 面向的是低维且具有明显特征的数据, 可选择简单稳定的学习器, 因此选择PLSR作为元学习器。
Stacking集成学习的建模过程如下: (1)先将获得的原始红外光谱数据集按照7∶ 3随机划分为训练集和测试集; (2)对于原始训练集采用5折交叉验证的方式对XGBoost、 1D-CNN和SVR模型进行训练, 将得到的结果作为元学习器的训练集; (3)对于原始测试集采用训练得到的模型进行预测, 并将得到的结果取平均, 作为元学习器的测试集; (4)最后将新得到的训练集和测试集输入PLSR模型, 即获得Stacking集成学习的预测结果。
1.5.1 基学习器模型
XGBoost模型是由K个树模型作为基学习器, 利用boosting进行集成的机器学习算法。 该算法运行效率高, 模型构建较为简单[13]。
1D-CNN网络结构由输入层、 卷积层、 池化层、 全连接层和输出层组成。 采用6个5× 1的卷积核和16个5× 1的卷积核构建的两个卷积层均使用ReLU作为激活函数。 在每个卷积层后都会连接1个2× 1大小的池化层, 用于降低卷积层所提取的特征向量维度。 全连接层实现特征向量到输出目标值的映射, 先由Flatten层将获得的数据展开为一维向量, 然后连接Dense层, 使用Linear激活函数得到输出值。
SVR是支持向量机(SVM)应用中的一个重要分支。 选用径向基(RBF)函数作为SVR的核函数。 SVR预测的准确度与参数选取呈高度相关, 利用合适的优化算法对惩罚因子c和核函数参数g进行优化就显得尤为重要。 天鹰优化(aquila optimizer, AO)算法是通过模拟天鹰在捕捉猎物过程中的行为而提出的新型智能优化算法, 该算法强调了四种不同勘探与开发搜索策略之间的均衡性, 使其优于其他的元启发式算法[14]。
1.5.2 元学习器模型
偏最小二乘回归(PLSR)是一种多元回归的统计学方法, 该方法集成了典型相关分析、 主成分分析和线性回归分析的优势。 运用主成分分析提取自变量和因变量中的主成分, 利用典型相关分析探究主成分之间的相关性, 通过多元线性回归建立相关关系模型。 在建模过程中, 通过交叉验证的方法选择合适的主成分数, 以提高模型的准确性。
选用决定系数(R2)和均方根误差(RMSE)进行模型性能的评估。 当决定系数接近1, 均方根误差接近0时, 说明回归拟合的效果较好, 模型检测的精确度更高。
式(1)和式(2)中, m为数据集样本的个数;
将不同的预处理方法与PLSR算法结合建立模型, 模型评价指标如表1所示。 由于获得的原始中红外光谱数据存在大量的毛刺峰, 利用FD进行预处理会导致进一步放大毛刺峰部分的信号, 从而降低检测的精度。 MSC与SNV预处理后的检测精度相差不大, 但MSC在两种不同乳化溢油下的检测效果均优于SNV, 说明MSC能够突出显示含油率与吸光度之间的相关关系, 从而在乳化溢油的中红外光谱数据预处理中具有普适性。 在经过S-G平滑后, 两种方法的检测精度均有所提升。 因此采用MSC和S-G滤波器结合的预处理算法建模, 可在保留光谱特征信息的同时, 提高光谱数据的信噪比, 并为后续模型建立的稳定性和灵敏性奠定了基础。
| 表1 预处理模型评价指标 Table 1 Evaluation index of preprocessing models |
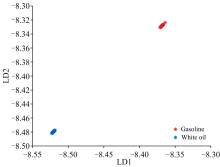
图3所示为利用LDA算法得到的乳化溢油样本分类结果图。 从图3中可以看出两类样本的类间距离相隔较远, 类内距离相隔很近, 类间距离与类内距离相差4个数量级。 说明LDA算法很好的实现了类内聚合, 并成功地将乳化汽油和乳化白油进行了分类。
 | 图3 乳化溢油样本分类结果图Fig.3 Classification results of emulsified oil spill samples |
由于CARS和RF均为随机采样, 因此选择循环运行10次后得到的最优结果作为后续定量分析的数据集。 采用网格搜索算法对RF中的参数进行寻优, 构建100棵决策树, 最优叶子节点数为10。 CARS算法中设置蒙特卡洛采样次数为20。 随着采样次数和阈值的增加, 光谱数据中与含油率信息无关的波长被剔除, RMSECV值呈现下降趋势, 当RMSECV值达到最小后, 开始剔除与含油率信息相关的波长, RMSECV值开始呈现上升趋势。 将CARS和RF选择的特征波长进行合并, 删除重复项, 即可得到乳化汽油的特征波长数量为162个, 乳化白油的特征波长数量为134个。
为了进一步验证本文提出的AO算法优化SVR的有效性, 将其与常用的遗传算法(genetic algorithm, GA)、 蚁群优化(ant colony optimization, ACO)算法进行对比。 将AO-SVR、 GA-SVR和ACO-SVR重复进行20次实验, 取平均值后得到AO-SVR的测试集决定系数均可达到0.94, 而GA-SVR和ACO-SVR的测试集决定系数分别可达到0.93和0.92。 说明AO-SVR的检测结果优于GA-SVR和ACO-SVR。 因此, 在Stacking集成学习模型中选用AO-SVR作为其中的基学习器模型。
以乳化汽油的分析为例, 将CARS和RF结合选择出的162个特征波长按照7∶ 3随机划分为训练集和测试集, 作为Stacking集成学习模型的输入。 在Stacking集成学习模型中XGBoost采用网格搜索算法进行参数寻优, 最大树深为5, 学习率为0.05, 随机采样比例为0.6, 构建树的数量为1 000; 1D-CNN采用Adam优化器自适应调整学习率, 迭代次数设置为20; AO-SVR选取的最优惩罚参数c为3.067 7, 核函数g为0.015 3; PLSR模型通过交叉验证选择主成分数为8。 对于乳化白油数据集也按照上述步骤进行分析。
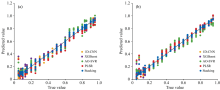
不同回归模型得到的乳化溢油含油率预测结果的可视化如图4所示, 其中(a)是乳化汽油, (b)是乳化白油。 1D-CNN、 XGBoost、 PLSR和AO-SVR均在低含油率阶段得到的预测值和真实值之间存在较大的偏差, 说明当光谱数据存在一定干扰时, 会影响这四种模型对于吸光度与含油率之间相关关系的建立。 而本文建立的Stacking集成学习模型能够有效减小这种偏差, 使其更接近于真实值。 Stacking集成学习模型得到的预测值与实际值的吻合度均高于其他四种单一学习器模型。 从上述分析可以得到, 本文建立的Stacking集成模型将这四种学习器融合在一起, 可以从不同角度探究乳化溢油含油率与特征变量之间的内在联系, 使每种模型之间进行优势互补, 从而提升了模型的总体性能, 在乳化溢油的含油率预测中获得了较高的精确度。
 | 图4 乳化溢油含油率预测结果可视化图Fig.4 Visualization of oil content prediction of emulsified oil spill |
为了进一步验证所建模型的稳定性, 在相同条件下对Stacking、 1D-CNN、 XGBoost、 AO-SVR、 PLSR模型重复进行50次实验, 结果如表2所示。 各单一学习器模型均取得了较好的检测结果。 而Stacking集成学习模型相比于单一学习器模型得到的检测结果有明显的提升。 乳化汽油和乳化白油的测试集决定系数(
| 表2 乳化溢油回归模型检测结果 Table 2 Emulsified oil spill regression model detection results |
基于中红外光谱技术实现对乳化汽油和乳化白油的定性、 定量检测。 利用MSC+SG的预处理方法可有效提高乳化溢油中红外光谱数据的信噪比。 在定性分析中选用LDA算法实现乳化溢油的准确识别。 在定量分析中, 通过CARS和RF结合的方法选择与含油率持线性和非线性关系的特征波长, 以增强数据的抗干扰能力。 建立Stacking集成学习模型对两种乳化溢油的含油率进行预测。 与AO-SVR、 PLSR、 XGBoost和1D-CNN相比, Stacking集成模型的检测精度有较为明显的提升, 模型性能表现得更为优越。 说明Stacking集成模型具有互补性和多样性的特点能够在乳化溢油的检测中发挥极大的优势, 从而为乳化溢油的研究提供了有效的技术支撑。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|