



{kind=link}
{kind=link}
{kind=link}
{kind=link}
赋权组合模型溯源山楂产地的高光谱方法
[方澳 , 殷勇
, 殷勇* , 于慧春, 袁云霞]
, 殷勇, 于慧春, 袁云霞]
|
|


作者简介: 方 澳, 1999年生,河南科技大学食品与生物工程学院硕士研究生 e-mail: fa1660606@163.com
不同产地的山楂因生长环境和地理气候的差异, 导致其品质的参差不齐, 因此确定山楂的地理产区具有重要的意义。 为了提高山楂产地溯源模型的稳定性和准确性, 提出了一种基于误差倒数赋权的组合鉴别模型。 首先, 利用高光谱成像技术采集了456个山楂的高光谱信息, 通过对比卷积平滑(SG)、 多元散射校正(MSC)和标准正态变量(SNV)3种预处理方法, 并使用预处理后的数据和原始数据构建BP神经网络(BPNN)和随机森林(RF)模型, 根据其准确率确定了SNV为平均光谱值的预处理方法。 然后, 对山楂的高光谱图像进行主成分分析, 选取第1主成分图像并根据全波段下的权重系数筛选出6个特征波长, 对应的平均光谱值作为其光谱信息表征值。 其次, 分别提取第1主成分图像和特征波长对应灰度图像的纹理特征, 并将特征波长的光谱表征值与其对应图像的纹理表征值、 主成分图像纹理表征值进行组合以构造产地溯源鉴别模型的输入向量。 最后, 分别选择BP神经网络(BPNN)、 随机森林(RF)和赋权组合模型(BPNN-RF)3种方法进行鉴别模型构建, 并选取准确率(Acc)和宏F1分数(macroF1)2个评价指标对不同输入向量所构建的山楂产地鉴别模型进行评价分析。 结果表明, 相同输入向量所建BPNN-RF模型的准确率和宏F1分数大都优于BPNN模型和RF模型的准确率和宏F1分数, 其中采用3种表征值组合而成的输入向量, 其所建BPNN-RF模型实测集的准确率由89.01%提高到98.90%, 宏F1分数也由89.32%提高到98.95%, 说明了基于误差倒数赋权BPNN-RF组合模型对山楂产地的鉴别能力最强, 效果最好, 优于单一的鉴别模型。 该研究为不依赖理化分析、 仅靠高光谱信息即可实现山楂产地的溯源提供了一种方法支撑。
Hawthorns from different origins have uneven quality due to the differences in growth environment and geographic climate, so determining the geographic origin of hawthorns is of great significance. A combined identification model based on error reciprocal weighting was proposed to improve the stability and accuracy of the hawthorn origin traceability model. Firstly, the hyperspectral information of 456 hawthorns was collected using hyperspectral imaging technology; and by comparing Savitzky-Golay Convolutional Smoothing (SG), Multiplicative Scattering Correction (MSC), and Standard Normal Variables (SNV) three preprocessing methods, and used the preprocessed data and the original data to construct BP Neural Network (BPNN) and Random Forest (RF) models, the preprocessing method with SNV as the average spectral value was determined based on their accuracy. Then, the hyperspectral image of the hawthorn was subjected to principal component analysis, and the 1st principal component image was selected; at the same time, six feature wavelengths were screened based on the weight coefficients under the full wavelength band, and then the corresponding average spectral value was used as the representation value of the spectral information. Secondly, the texture features corresponding to the 1st principal component image and the feature wavelengths grayscale images were extracted, respectively, and the spectral representation values of the feature wavelengths were combined with the texture representation values of these feature wavelengths grayscale images as well as the texture representation values of the principal component image to construct the input vectors of the origin traceability identification model. Finally, three methods of BPNN, RF, and weighted combination model (BPNN-RF) were selected for the identification model construction, and two evaluation indexes, namely, accuracy (Acc) and macroF1 score (macroF1) were selected to evaluate and analyze the hawthorn origin identification models constructed by different input vectors. The results showed that the accuracy and macroF1 score of the BPNN-RF model with the same input vector were mostly better than those of the BPNN model and the RF model, in which the accuracy of the actual test data set of the BPNN-RF model with the input vector consisting of three kinds of representation values was increased from 89.01% to 98.90%. The macroF1 score was also increased from 89.32% to 98.95%. This indicates that the combined BPNN-RF model based on the error inverse assignment has the strongest discriminative ability and the best effect on the identification of hawthorn origin, which is better than the single discriminative model such as BPNN or RF. This study provides methodological support for the traceability of hawthorn origin without relying on physicochemical analysis and only relying on hyperspectral information.
山楂是国内外普遍使用的中药材, 资源丰富, 药用历史悠久, 临床疗效[1]确切, 且早已列入我国药食同源目录。 山楂的主产区为河南、 河北和山东等地, 这些产区均大量种植, 产量高且集中, 主要品种为大金星、 大五棱、 铁山楂、 大旺山楂、 大棉球等; 其他山楂产区还包括辽宁、 山西和江苏等地。 这就导致了山楂来源复杂, 国内外品种混乱[2]; 再者, 异地引种导致品质变异, 致使市面上出现大量以次充好、 假冒伪劣的山楂出售[3]。 另外, 山楂的品质和风味往往受产地影响, 同品种不同产地山楂的价格相差巨大, 因此产地信息是普通消费者或中药企业采购时的重要依据。 例如兴隆山楂在古代便被视为贡品、 珍品, 如今入选河北省道地药材目录, 并且作为地理标志产品进行保护, 与其他地区生产的山楂相比, 具有更高的商业价值。 为了促进道地药材的良性发展, 保护消费者的权益, 保证市场的公平竞争, 确定山楂的地理产区具有重要的意义。 因此, 需要一种快速、 准确、 高效的检测方法来鉴别不同产地的山楂, 从而为山楂产业的高质量发展提供强有力的技术支持。
高光谱成像(hyperspectral imaging, HSI)技术是一种低损耗、 高效率、 精密绿色的检测技术。 近年来, 在农产品的产地溯源、 成分预测和产品质量检测领域得到了广泛应用。 利用高光谱成像技术对中草药或农产品进行产地溯源已有诸多研究成果, 例如: 草药附子的真伪和地理来源的预测和分类[4]、 中药三七地理来源的溯源[5]、 白茶的产地溯源[6]、 鸭蛋产地分类[7], 这些研究为实现山楂的产地溯源提供了技术支撑。 因此, 利用高光谱技术有望实现山楂产地溯源。
组合检测模型是通过一定规则组合各单项检测模型来提升整体检测性能的一种方法。 如何确定各模型的权重尤为重要[8], 为了提高模型的预测精度, 拟以高光谱成像技术对山楂进行产地溯源为切入点, 分别把单一的BP神经网络(back propagation neural network, BPNN)模型和随机森林(random forest, RF)模型的准确率(accuracy, Acc)作为指标, 来确定两个模型的权重比例, 并对两个模型进行权重组合计算, 进而构建BPNN-RF赋权组合模型。 这种基于误差倒数赋权的组合模型构造方法, 可有效提高山楂产地鉴别的可靠性和准确性。
购买3个产地6种鲜山楂, 每个品种76个样本, 共456个样本。 它们分别是: 产自河南省洛阳市的金星山楂和五棱山楂; 产自山东省潍坊市临朐县的金星山楂和五棱山楂, 且是国家农业部农产品地理标志产品; 产自河北省承德市兴隆县的铁山楂和大旺山楂, 也是中国国家地理标志产品。 购买的鲜山楂因长时间运输可能出现过热和熟化现象, 所以收到鲜山楂后, 立即将其在冷库散开贮藏, 降温24 h后进行试验, 贮藏温度设为-1~0 ℃。 将这6个品种分别标记为LJ、 LW、 WJ、 WW、 XT、 XD。 随机将样本划分为3个部分, 其中274个作为训练集样本, 91个作为验证集样本, 这365个山楂样本用于构建检测模型。 剩余的91个山楂样本用于实测, 以便进一步确认所构建的检测模型的可靠性与准确性。
高光谱图像采集系统由实验室自主设计搭建, 由高光谱成像相机(德国Inno-Spec公司, IST50-3810型, 光谱的分辨率为2.8 nm)、 4个500 W卤素灯(德国EsyluX公司, RK90000420108型)、 传送平台(其速度可在0~10.00 mm· s-1之间调节)、 数据处理软件(SICap-STVR V1.0.X)4部分构成。 光谱的采样范围为371.05~1 023.82 nm, 采样的间距为0.51 nm, 每个测试样本共采集了1 288个波长的光谱信息。
采集参数设置为: 传送系统的传送速率为1.1 mm· s-1, 高光谱相机的曝光时间为20 ms, 物距为23.2 cm。 采集过程中为了减少其他光源或暗电流的干扰, 在采集前对标准白板和黑板分别进行采集, 后对采集的高光谱图像进行黑白校正[9], 光谱图像校正公式为
式(1)中: R为校正后的光谱图像; R0为校正前的光谱图像; Rw为标准白板图像; Rb为标准黑板图像。
光谱信息往往受采集环境或采集系统参数的变化影响。 因此, 光谱信息会出现随机噪声、 基线漂移等干扰信息, 这些干扰信息会影响后续鉴别模型的准确性。 为了消除这些噪声的影响, 使用ENVI 5.3软件选取山楂样本图像的中轴线靠近果柄附近49 P× 49 P范围作为感兴趣区域(ROI)。 该区域的像素平均值称为平均光谱值, 并采用了多元散射校正(multiplicative scattering correction, MSC)、 标准正态变量(standard normal variables, SNV)和卷积平滑(Savitzky-Golay, SG)的方法对各波长对应的平均光谱值进行预处理[7]。
原始的高光谱图像是1 032× 800× 1 288的一个三维矩阵, 其中1 032× 800是图像的尺寸大小, 1 288是采集的波长数量。 每个波长都对应着一个灰度图像, 通过使用ENVI 5.3软件, 对黑白校正后的光谱图像进行主成分分析, 获得了由所有波长图像经线性组合而生成的主成分图像。 图1为6个山楂品种分别对应的第1主成分图像。
 | 图1 6个山楂样本的第1主成分图像Fig.1 The first principal component images of 6 hawthorn samples |
根据主成分图像的累积贡献率确定使用PC1图像进行后续的计算分析, 每个PC图像都是由每个波长图像乘以对应的加权系数叠加而成[10]。 所以, 可根据各品种样本主成分图像的权重系数曲线, 找出各权重系数曲线上的峰谷位置处的波长来作为特征波长。 特征波长对应的灰度图像称为特征波长图像。 另外, 将特征波长图像上感兴趣区域内的像素平均值作为特征波长的光谱值。
对第1主成分图像和特征波长图像分别进行纹理特征的提取。 纹理特征描述了图像的属性, 是对图像各像素之间空间分布情况的一种概括。 山楂表面较为粗糙, 整果呈红色且生有白色斑点, 是山楂的主要特点。 不同产地的山楂因其内部理化成分和外部生长条件不同, 反映出的外表皮纹理会呈现较大的差异。 所以, 可利用图像纹理信息来替代理化指标进行山楂产地的区分溯源。
灰度共生矩阵(GLCM)是一种有效的纹理信息统计方法[11], 表示了在纹理模式下的像素灰度的空间关系。 使用Matlab2022b软件graycomatrix函数, 当空间距离d设为1像素, 角度依次设为0° 、 45° 、 90° 、 135° 时, 对每个山楂样本的第1主成分图像和特征波长图像分别提取对比度(CON)、 相关性(COR)、 能量(EN)、 逆差距(HOM)4个纹理参数, 把4个纹理参数对应的均值和方差作为其纹理表征值。 其中, 对比度反映了图像的清晰度和纹理深浅的程度; 相关性反映了灰度共生矩阵元素在行或列方向上的相似程度; 能量反映了图像灰度分布均匀程度和纹理粗细度; 逆差距反映图像纹理的同质性。
单一的光谱信息可能不足以构建出性能优良的山楂产地鉴别模型, 所以在对山楂样本的特征波长光谱值、 第1主成分图像纹理表征值、 特征波长图像纹理表征值进行提取后[12], 实施3种表征值的两两组合或全组合, 构造成相应的鉴别模型输入向量[13], 以期尽可能地包含较多的样本属性信息来提升鉴别模型的产地区分能力与可靠性。 组合方式采用的是向量堆叠[14, 15], 其表达式为
式(2)中, γ 为组合特征, Xs为平均光谱值, Xt为图像纹理值, φ 为提取特征的线性映射矩阵。
采用BPNN、 RF和BPNN-RF建立山楂产地鉴别模型, 输入向量样本随机分为训练集、 验证集和实测集3部分, 三者样本数量以6∶ 2∶ 2的比例划分。
BPNN是一种多层前馈神经网络, 其主要特点是信号前向传递, 误差反向传播, 不断修正直至误差达到最小。 采用的BPNN是一个4层的网络结构, 即一个输入层、 两个隐含层和一个输出层, 输入层神经元个数与输入向量维数相对应, 两个隐含层的神经元个数均为16, 输出层神经元个数为3, 学习率、 目标误差和迭代次数分别设为0.001、 0.000 1和1 000。 参数设置好后, 将不同输入向量分别输入BPNN模型进行训练。
RF是基于决策树构建的一种集成学习方法, 采用绝对多数投票法(majority voting), 通过组合多个决策树的预测结果来降低模型的方差并提高鲁棒性。 训练函数采用TreeBagger函数, 经过试算, 决策树的个数初步设为50棵, 最小叶子数设为6, 然后将不同输入向量分别输入RF模型进行训练。
BPNN-RF是一种基于误差倒数的赋权组合模型[16], 即单一模型在训练后鉴别或预测结果的误差越小, 则在组合模型所占的权重越大。 常用的评价指标有均方根误差(RMSE)、 均方误差(MSE)和平均绝对误差(MAE)等, 这里使用准确率(Acc)作为确定权重比例的指标, 即单一鉴别模型结果的准确率越高, 在组合模型中该模型所占权重越大。 其建模过程如下: 首先, 输入向量、 产地标签和各模型的参数分别输入对应单一模型中, 在训练集中分别进行BPNN和RF模型的训练, 根据各模型的准确率并利用式(3)和式(4)计算各模型的权重系数; 然后, 在验证集中再次分别进行BPNN和RF模型的训练, 得到两单一模型的预测值, 结合上述得到的权重系数并根据式(5)计算出组合模型的预测值, 并使用Round函数对预测值进行取整, 与真实值对比计算得出鉴别结果; 最后, 在实测集中重复上述过程, 进一步确认所构建的组合模型的稳定性。
式(3)— 式(5)中, ω 1为模型1的权重系数, Acc1为模型1的准确率, T1为模型1的预测值, ω 2为模型2的权重系数, Acc2为模型2的准确率, T2为模型2的预测值, T12为组合模型预测值。
对于模型鉴别效果的评价, 采用了准确率(Accuracy)和宏F1分数(macro F1 score)2个指标[17]。 使用式(6)计算得到准确率, 它用于评价模型的整体鉴别性能。 对于宏F1分数的计算, 过程如下: 首先使用式(7)和式(9)对3个产地的鉴别结果分别计算精确率(P)和召回率(R); 然后使用式(8)和式(10)对3个产地的精确率和召回率进行平均处理得到宏精确率(macroP)和宏召回率(macroR); 最后使用式(11)计算得到用宏F1分数。 因宏F1分数不受类别的样本数量的影响, 平等地对待每个类别, 兼顾宏精确率和宏召回率, 可用来评价模型在各个类别鉴别的平均性能。
式(6)— 式(11)中, TP表示正样本归类为正样本的数量, FN表示为正样本归类为负样本的数量, FP表示负样本归类为正样本的数量, TN表示负样本归类为负样本的数量。
每个山楂高光谱数据包含了1 288个波长的平均光谱值, 波长的范围是371.05~1 023.82 nm。 由于光谱信息采集时的噪音影响, 371.05~447.77 nm的平均光谱值差异巨大, 易干扰后续的结果, 因此只保留447.77~1 023.82 nm范围的波长进行后续的处理。 以XD品种76个样本的平均光谱值曲线图为例, 图2(a)平均光谱值曲线中出现基线漂移和毛刺的现象, 为了消除这些影响, 采取SNV、 MSC和SG三种方法对原始图像数据进行预处理。
 | 图2 不同预处理山楂的平均光谱值曲线图 (a): 原始曲线图; (b): SNV处理后曲线图; (c): MSC处理后曲线图; (d): SG处理后曲线图Fig.2 Average spectra of hawthorn with different processing methods (a): Original spectra; (b): Spectra after SNV processing; (c): Spectra after MSC processing; (d): Spectra after SG processing |
从平均光谱值曲线图的处理前后变化可以清晰地看出, 三种方法对原始图像数据都进行了不同程度的优化。 经分析比对图2(b)、 (c)与(a)可知, 采用SNV和MSC的方法有效校正了样本间因散射而引起的相对基线平移和偏移。 而对比分析图2(a)与(d), 可以看出平均光谱值曲线毛刺显著减少, 表明经过SG处理, 能够去除样本光谱数据中的噪声和波动。
对预处理后的平均光谱值数据分别构建BPNN和RF模型, 采用准确率(Acc)作为模型的评价指标, 准确率越高说明模型性能越可靠。 表1给出了不同预处理方法的BPNN模型和RF模型对应的准确率。 与原始数据所建立的模型相比, 采用3种预处理方法所建立的模型性能均优于原始数据所建立的模型, 其中经SNV处理后的光谱数据所建立模型与原始数据所建立模型相比, 准确率提高了约12%, 极大提升了模型的性能。 因此, 确定采用SNV作为原始数据的预处理方法。
| 表1 不同预处理的BPNN和RF模型的结果 Table 1 Modeling results of BPNN and RF models with different pretreatments |
对每个山楂样本的高光谱图像都进行主成分分析, 得到每个主成分图像都是由每个波长图像经过线性组合而生成的。 表2给出每个品种所有样本第1主成分图像的最小贡献率, 可以看出所处理的每个样本第1主成分图像的贡献率均在98%以上, 表明第1主成分图像包括了原高光谱图像的大部分信息, 所以可选第1主成分图像进行后续的分析。
| 表2 第1主成分图像的贡献率 Table 2 The contribution rate of the first principal component image |
每个品种山楂随机选出一个样本的PC1图像并计算其权重系数, 权重系数曲线上的峰谷值对应一个波长, 根据峰谷值的位置可筛选特征波长[18], 如图3(a)所示, 共选出506.17、 579.45、 637.29、 699.10、 772.89和866.41 nm 6个特征波长, 并计算出6个特征波长对应光谱表征值。 图3(b)为6个特征波长对应的灰度图像(特征波长图像)。
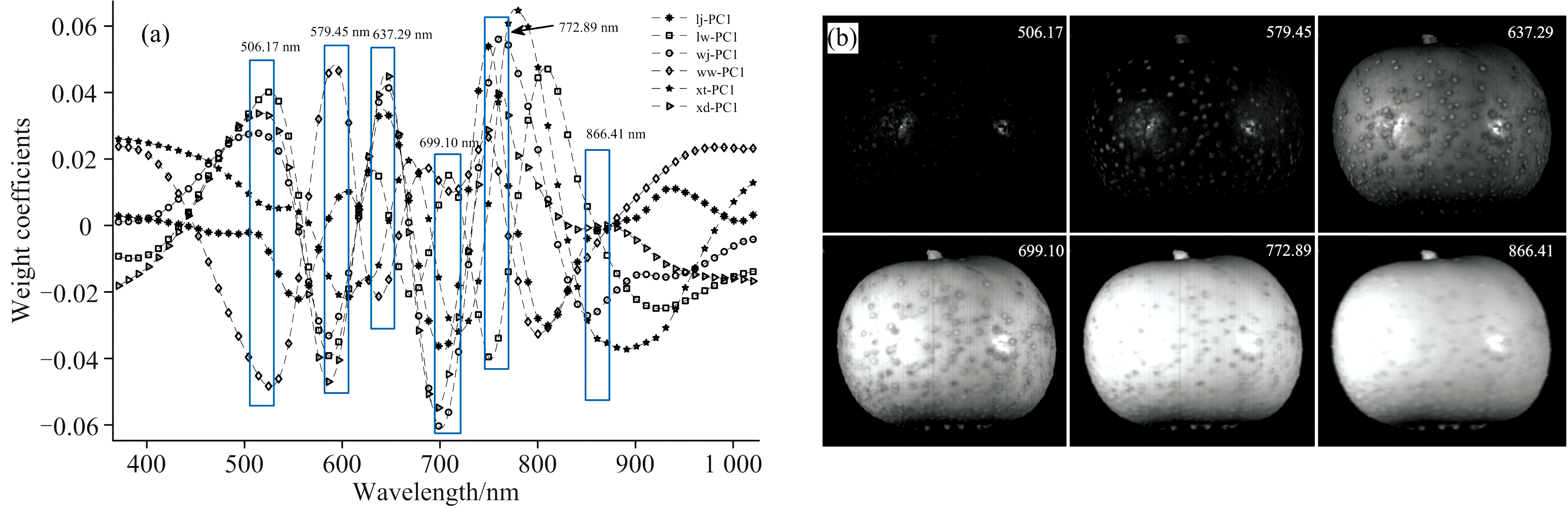 | 图3 特征波长的提取与特征波长图像 (a): PC1图像的权重系数图; (b): 6个特征波长图像Fig.3 Feature wavelength extraction and images at feature wavelengths (a): Weight coefficient of PC1 images; (b): 6 iamges at feature wavelengths |
对第1主成分图像和特征波长图像分别进行纹理特征提取前, 先对主成分图像和特征波长图像进行二值化、 背景去除、 灰度化等预处理, 目的是消除山楂样本的背景和阴影对后续处理的影响; 然后计算每个图像的对比度、 相关性、 能量和逆差矩4个纹理参数, 并以这4个纹理参数的均值和方差作为纹理表征值。 每1个样本选取1个主成分图像和6个特征波长图像, 则1个主成分图像可提取4× 2=8个纹理特征, 6个特征波长图像可提取6× 4× 2=48个纹理特征。
每个产地2个品种共计76× 2=152个山楂样本, 三个产地共计456个样本。 以不同的表征值作为3种模型的输入向量, 分别建立山楂的BPNN、 RF和BPNN-RF产地溯源模型。 由表3中的模型1、 2、 3分析结果可知, 基于误差倒数赋权的组合模型BPNN-RF与其单一模型相比, 无论准确率还是宏F1分数其组合模型的结果更优(如在模型1实测集中: BPNN模型的Acc为80.22%, F1为80.49%, RF模型的Acc为83.52%, F1为83.48%, BPNN-RF模型的Acc为89.01%, F1为89.32%), 说明当单一模型对样本鉴别的效果表现不佳时, 利用误差倒数赋权的组合模型能够利用多个模型各自特点进行组合, 实现模型性能的优化提升。
| 表3 基于不同特征参量模型对山楂产地的鉴别结果 Table 3 Identification results of hawthorn origin based on different characteristic parameter models |
同时, 可以看出基于特征波长图像纹理表征值所建立的3种山楂模型与主成分图像纹理表征值、 光谱表征值建立的模型相比, 前者的鉴别效果更佳, 其准确率和宏F1分数均高于后两者, 表明了同产地不同品种的山楂会因生长环境的因素影响, 会出现与产地相关的纹理信息, 也导致同品种不同产地山楂纹理特征上的差异性。 所以, 纹理表征值所蕴含的山楂产地信息更多。 这侧面说明以光谱表征值建立的山楂鉴别模型, 易受到同产地不同品种山楂和同品种不同产地山楂的影响; 而主成分图像是各波长图像的线性叠加, 可能掩盖或缺失了一部分原有纹理信息, 导致主成分图像纹理表征值所建立的模型准确率和宏F1分数也不理想。
为了满足复杂样本的鉴别精度要求, 将光谱表征值与两类纹理表征值两两或三者进行组合, 采用向量堆叠的方案, 使得输入向量包含更多的产地信息。 由表3中模型4、 5的分析结果可知, 组合表征值模型的准确率和宏F1分数与单一表征值模型相比, 基于组合表征值的BPNN、 RF和BPNN-RF模型鉴别精度均得到了较大的提升, 说明了纹理表征值与光谱表征值的组合产生有利于产地溯源的样本属性信息, 这种方式可以提高鉴别模型的鉴别精度。
根据表3的比较, 模型1、 2、 3与模型4、 5、 6相互印证显示, 在山楂的产地溯源中, 图像的纹理特征信息更具有产地的可分性属性。 表3中模型6是基于2种纹理表征值的模型, 对鉴别模型的性能提升最大, 其中BPNN-RF模型的鉴别结果十分优异, 实测集的准确率和宏F1分数达到了100%。 表3模型7是基于3种表征值的模型, 输入向量所含山楂样本属性信息最多, BPNN、 RF和BPNN-RF模型的鉴别性能均达到最优, 三者验证集和实测集的准确率或宏F1分数大都达到100%, 说明3种表征值组合后构成的输入向量, 信息表征更为全面。 图4是模型7中BPNN-RF实测集的混淆矩阵, 图中1、 2和3分别对应河南、 山东和河北3个产地, 仅有1个产自河南的山楂样本错判为山东。 综上所述, 使用3种表征值组合的输入向量, 基于误差倒数赋权的BPNN-RF是山楂产地鉴别的最佳模型。
 | 图4 模型7中BPNN-RF实测集的混淆矩阵Fig.4 Confusion matrix of test set of BPNN-RF in Model 7 |
对于不同输入向量的鉴别模型, 赋权组合模型(BPNN-RF)可以根据各模型的准确率进行加权, 均能较好地利用两个单一模型的特点进行模型鉴别性能的优化提升。 同时可以看出, 当各单一模型的鉴别能力优异且差距不大时, 组合模型对单一鉴别模型的性能提升有限; 当各单一模型的鉴别结果一般且彼此之间有一定的差距时, 基于误差倒数赋权的组合模型对模型的性能提升效果最好。 说明以单一模型的准确率为指标, 通过误差倒数赋权的方法, 构建赋权组合模型可以有效地提升鉴别性能并具有普遍性。
以3地6品种山楂为研究对象, 对不同预处理方法的BPNN和RF模型对应的Acc结果进行分析, 确定了SNV为平均光谱值的预处理方法。 对高光谱图像进行主成分分析, 利用第1主成分图像全波段下的权重系数提取特征波长并筛选出对应的平均光谱值作为光谱表征值。 对特征波长图像与主成分图像分别提取纹理特征, 通过对高光谱图像的光谱表征值与两类纹理表征值组合前后的对比, 并经BPNN、 RF和BPNN-RF三个鉴别模型的检测与分析, 确定了最优的产地鉴别溯源模型, 并得出以下结论。
(1)纹理特征所蕴含的山楂产地信息最多, 且光谱表征数据与两类纹理表征数据进行组合, BPNN、 RF和BPNN-RF模型对山楂产地的鉴别性能最好。
(2)基于误差倒数赋权的BPNN-RF组合模型, 实现了不依赖理化指标就能对3个产地6个品种的山楂进行准确又快速的产地溯源, 这一成果也为其他中药的产地溯源提供了溯源方法的参考。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|