



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Transformer的胃癌显微高光谱图像分割方法
[张然1, 2  , 金伟
, 金伟1, 2 , 牟颖1 , 于丙文2 , 柏怡文2 , 邵益波1, 2 , 平金良3, * , 宋鹏涛3 , 何湘漪3 , 刘飞3 , 付琳琳3 ]
, 金伟, 宋鹏涛|
|


作者简介: 张 然, 1998年生,浙江大学控制科学与工程学院硕士研究生 e-mail: 22132072@zju.edu.cn
胃癌是全球第五常见的恶性肿瘤并死亡率较高, 严重威胁人类的生命健康。 因此, 早期识别胃癌病变对早期胃癌诊断至关重要。 显微高光谱成像技术作为一种新兴技术, 可以在微观层面同时获取生物组织丰富的光谱信息和空间信息, 为早期病理切片诊断提供了一种新的思路。 利用显微高光谱成像系统, 采集了在400~1 000 nm波段范围的胃癌显微高光谱病理图像, 通过光谱校正等预处理构建了包含230张图像的胃癌显微高光谱数据集。 尽管基于空间注意力的方法在图像分类、 分割等领域已取得了显著成果, 但在处理高光谱图像时仍面临计算复杂度高以及光谱信息利用不充分的问题。 为此, 提出了基于卷积和注意力机制的混合双分支Transformer(MDBT)的特征提取主干网络模型。 该模型通过交替应用空间混合模块和通道混合模块, 实现块间和块内的空间和通道特征聚合。 具体而言, 设计了窗口注意力和卷积双分支以及空间和通道交互结构。 这种设计不仅降低了计算复杂度, 还通过卷积交互实现了窗口间信息交互和特征融合, 从而克服了窗口注意力感受野受限的问题, 进一步提高了Transformer的全局建模能力。 在进行图像分割实验中, 采用UperNet模型作为解码头网络对主干网络提取得到的特征进行还原, 以得到最终的分割结果。 在采集得到的胃癌高光谱数据集上进行了五折交叉验证实验, 结果表明本模型的平均mDice和mIoU分别达到85.39、 74.66, 性能优于目前UNet、 Swin、 PVT、 VIT等主流图像分割网络模型。 同时设计一系列消融实验, 验证本文提出空间和通道双混合模块、 卷积与窗口注意力双分支等结构对实验结果的优化效果。 实验结果表明本文提出的MDBT模型能够有效利用高光谱图像丰富的空间和光谱信息, 提高胃癌图像分割准确率, 证明显微高光谱成像技术在胃癌诊断方面具有一定的研究意义和应用价值。
, JIN Wei, SONG Peng-taoGastric cancer is the third leading cause of cancer-related deaths globally, posing a serious threat to human life and health. Therefore, early identification of gastric cancer lesions is crucial for early diagnosis of gastric cancer. As an emerging technique, microscopic hyperspectral imaging technology can simultaneously obtain rich spectral information and spatial information of biological tissues at the microscopic level, providing a new approach for early pathological slice diagnosis. In this paper, gastric cancer microscopic hyperspectral images in the range of 400~1 000 nm were collected using a microscopic hyperspectral imaging system. The gastric cancer microscopic hyperspectral dataset containing 230 images was constructed through preprocessing, such as spectral calibration. Although spatial attention-based methods have achieved significant results in image classification, segmentation, and other fields, they still face challenges of high computational complexity and insufficient utilization of spectral information when dealing with hyperspectral images. Therefore, this paper proposes a backbone network model based on convolution and attention mechanism called Mixing Dual-Branch Transformer (MDBT). This model achieves spatial and channel feature aggregation between blocks and within blocks by alternately applying spatial and channel mixing modules. Specifically, this paper designs window attention, convolution dual branches, and spatial and channel interaction structures. This design not only reduces computational complexity but also achieves window-to-window information interaction and feature fusion through convolutional interaction, overcoming the limitation of window attention's receptive field and further improving the global modeling ability of the Transformer. In the image segmentation experiments, we adopt the UperNet model as the decode head network to reconstruct the features extracted by the backbone network to obtain the final segmentation results. Five-fold cross-validation experiments were conducted on the collected gastric cancer hyperspectral dataset, and the results show that the average priceand mIoU of this paper's model reach 85.39 and 74.66, respectively, outperforming mainstream image segmentation network models such as UNet, Swin, PVT, and VIT. Meanwhile, ablation experiments are designed to verify the optimization effects of the proposed spatial and channel dual mixing modules, convolution, window attention dual branches, and other structures on experimental results. Experimental results demonstrate that the proposed MDBT model can effectively utilize hyperspectral images' rich spatial and spectral information, improve the accuracy of gastric cancer image segmentation, and prove the research significance and application value of microscopic hyperspectral imaging technology in gastric cancer diagnosis.
胃癌是一个全球性的重大健康问题, 根据国际癌症研究机构发布的数据[1], 2022年全球胃癌新发病例约97万例, 因胃癌死亡病例约66万例, 其发病率和死亡率均居恶性肿瘤死亡人数的第5位。 胃癌的治疗效果与诊断、 治疗时机密切相关, 经过早期诊断和治疗, 胃癌患者的5年生存率可以达到90%以上。 然而, 我国胃癌病例临床确诊大多处于晚期阶段, 治疗效果较差, 因此对胃癌病变进行早期诊断具有重要现实意义。 目前胃癌的诊断依赖于内窥镜检查和组织活检, 通常由医生对在胃镜检查中看到的异常组织进行活检, 然后由病理医生在显微镜下进行组织学检查, 以确认癌细胞的存在。 这种方法依赖专家的经验等主观因素, 缺乏统一标准且费时费力。
高光谱成像技术(hyperspectral imaging, HSI)作为一种融合光谱技术和成像技术的先进手段, 能够同时获取探测对象的二维空间图像和一维光谱信息, 通常用于遥感领域, 如农业、 植被检测和地质勘查等[2, 3]。 随着光学系统的不断发展, 高光谱成像技术在医学成像领域, 特别是显微成像领域的应用也取得了显著成果。 在病理切片诊断中, 高光谱成像技术能够揭示肉眼难以分辨的化学成分差异, 为早期病理切片诊断提供了一种新的思路。 然而该技术带来的数据庞大、 信息冗余等问题也为数据处理和利用带来了挑战。
随着人工智能在医学图像处理领域的成功应用, 卷积神经网络在显微高光谱图像处理领域大量应用并取得不错的效果[4, 5]。 然而, 卷积神经网络在全局信息建模方面的不足也限制了其在医学图像处理上的性能。 然而能够建立全局依赖关系的视觉Transformer模型为这个问题提供了新的思路, 一些研究者将Transformer与卷积神经网络结合起来对高光谱图像进行分类[6, 7]。 Transformer核心的自注意力机制在带来全局关系建模能力的同时, 也存在着计算复杂高、 参数量庞大问题, 因此一些研究者将全局自注意力改为窗口自注意力以简化计算复杂度[8], 该方法在将特征图分割成不重叠的窗口并在窗口内应用自注意力计算, 在通道维度上共享权重。 这种方法虽然能够有效提高计算效率, 但也带来了感受野受限、 建模能力下降的新问题。 同时, 这些基于空间维度信息设计的方法在通道维度上进行权重共享, 也使得通道特征建模的能力受到限制。 而高光谱图像中包含大量波段光谱信息对高光谱图像特征提取有重要意义, 但在特征提取过程中这些信息被分散在特征通道中, 因此对其进行有效信息提取能够帮助模型提高特征表征能力。
本工作利用显微高光谱成像系统对胃癌病理组织切片进行数据采集和处理, 构造胃癌高光谱数据集。 同时, 提出一种基于卷积和注意力机制的混合双分支Transformer的特征提取主干网络混合双分支Transformer(mixing dual-branch transformer, MDBT)以用于图像分割任务, 设计窗口注意力与深度卷积混合模块, 在模块间和模块内实现空间和通道维度的特征聚合, 将局部特征与全局特征相融合, 增强模型的图像特征表示能力, 实现对显微高光谱图像的光谱和空间特征的高效提取。
采用杭州彩谱科技有限公司开发的搭载成像高光谱相机FS-23的显微高光谱成像系统采集显微高光谱图像, 该系统主要由相机机身、 镜头、 显微镜、 卤素灯光源等组成, 并配备官方图像采集软件FigSpec。 使用该系统对湖州市中心医院提供的染色后胃癌病理组织切片进行图像采集, 得到胃癌显微高光谱病理图像, 如图1(a)所示。 在采集过程中, 显微镜物镜放大倍数为20倍, 在400~1 000 nm范围采集300个波段, 光谱分辨率为2.5 nm, 空间分辨率为960× 960。 由于在显微成像下视场较小, 无法对整张载玻片进行成像, 因此由医生辅助指导在每张玻片上选取多个感兴趣区域采集图像。 最终共获取胃癌显微高光谱病理图像230张, 并由专业病理医生进行像素级别标注, 标签图像如图1(b)所示。
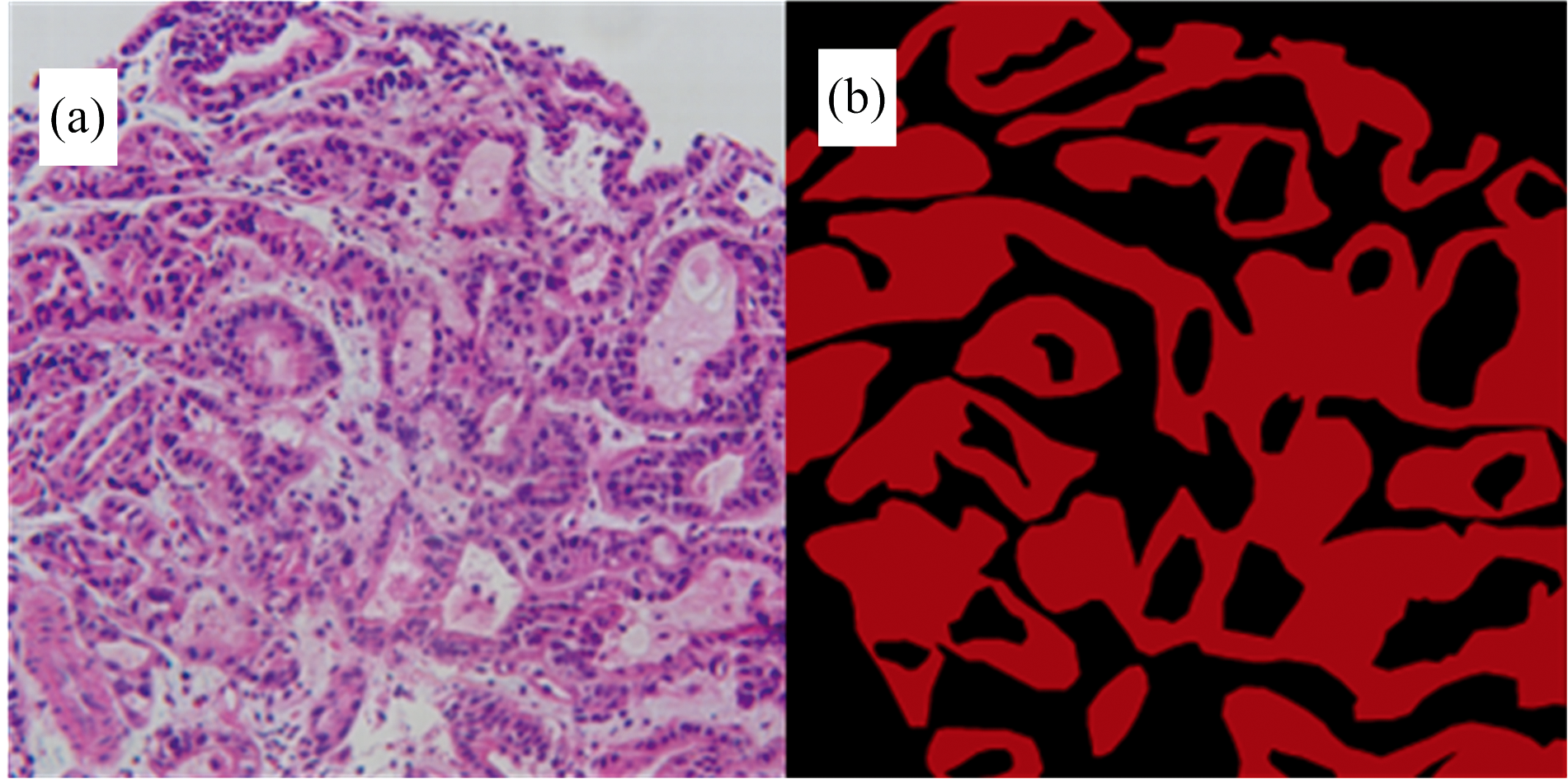 | 图1 (a)胃癌显微高光谱病理图像; (b)标签Fig.1 (a) Microscopic hyperspectral pathological image of gastric cancer; (b) Label |
完成数据采集之后, 使用光谱校正、 中值滤波等预处理方法对高光谱图像进行处理, 以去除由于光源和污渍等因素产生的噪声。 考虑到图像采集过程中的干扰因素, 人为选取较为清晰的0~150波段进行实验。 2 MDBT主干网络模型构建
本文提出的MDBT主干网络模型由四个阶段组成, 每个阶段包含一个可重叠的图像块嵌入层(overlapped patch embedding, OPE)或可重叠的图像块合并层(overlapped patch merging, OPM)和若干个混合Transformer模块(mixing transformer block, MixTB)。 每个MixTB则包含连续的空间混合注意力模块(spatial mixing attention block, SMAB)和通道混合注意力模块(channel mixing attention block, CMAB), 如图2所示为模型结构。
 | 图2 MDBT模型结构Fig.2 Structure of the MDBT model |
图像块嵌入层OPE将特征图划分为可重叠的图像块并将每个图像块转换为Token序列。 假设输入高光谱图像为X∈ RH× W× S, 其中H、 W、 S分别代表输入高光谱图像的高度、 宽度和光谱波段数。 OPE模块使用卷积核大小为7× 7、 步长为4× 4、 填充大小为3× 3、 输入通道为S以及输出通道为C的二维卷积, 将图像可重叠地分割成尺寸为4× 4的图像块, 得到特征图X'∈
图像块合并层OPM将特征图划分为可重叠的图像块, 同时对特征图进行下采样以得到不同分辨率下的图像特征表示。 假设第i阶段的输入特征图为F∈ RH× W× C, 其中H、 W、 C分别代表输入特征图像的高度、 宽度和光谱通道数。 OPM模块使用卷积核大小为3× 3、 步长为2× 2、 填充大小为1× 1、 输入通道为C, 输出通道为C'的二维卷积, 将图像可重叠地分割成尺寸为2× 2的图像块, 得到特征图F'∈
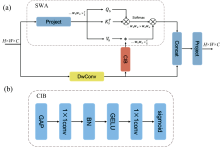
空间窗口注意力虽然能够降低Token序列的长度, 避免了全局注意力计算带来的庞大计算复杂度, 但也导致注意力的计算局限在局部窗口内, 使得感受野受限失去了全局建模的能力。 而深度卷积能够对空间信息进行有效建模并且带来强大的归纳偏置, 具有强大的局部空间特征提取能力, 同时能够为窗口注意力带来跨窗口的连接能力[9]。 因此设计了空间混合模块SMAB, 该模块由空间窗口注意力(spatial window attention, SWA)和深度卷积(depth-wise convolution, DwConv)双分支通路以及通道交互模块(channel interaction block, CIB)组成, 具体结构如图3(a)所示。
 | 图3 (a)SMAB结构; (b)CIB结构Fig.3 (a) SMAB structure; (b) CIB structure |
尽管空间窗口注意力能够在空间维度上进行动态权重的计算, 提升模型的空间特征提取能力, 但其在通道维度上共享权重的机制也限制了模型在通道维度上的建模能力。 因此参考SE通道注意力层[10], 设计了CIB来增强空间窗口注意力在通道维度上的建模能力。 CIB由一个全局平均池化层, 和带有批归一化(batch normalization, BN)以及GELU激活层的两个1× 1逐点卷积组成, 最后经过Sigmoid层生成通道注意力权重, 并与窗口注意力中的Value(即下文Vs)进行逐元素相乘, 具体结构如图3(b)所示。
空间窗口注意力是指在各个窗口内独立进行空间特征注意力的计算。 具体来讲, 假设输入为F∈ RH× W× C, 通过线性映射将其映射为Q, K, V, 具体过程如式(1)
式(1)中, WQ, WK, WV∈ RC× C均为线性映射。 然后将Qs, Ks, Vs划分为大小为Wh× Ww的不重叠的窗口, 并将特征通道划分为h个heads, 则每个heads的特征维度为ds=C/h, 再经过维度交换后得到划分后的Qs, Ks, Vs∈
式(2)中, VCIB为CIB的输出, 表示逐元素相乘, Reshape为维度变换操作可以使得VCIB的在各个维度上与Vs保持一致。 最后将得到的双分支输出在通道维度上拼接后进行线性映射以实现特征融合。
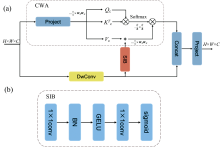
相比于普通三通道RGB彩色图像, 高光谱图像有几十甚至上百个通道, 这些通道包含丰富的光谱信息, 对于像素级的图像任务具有重要意义。 然而, 经过主干网络的各个阶段的特征提取, 这些光谱信息分散在各个特征通道中, 针对空间信息设计的特征提取方法无法对其进行有效利用。 为了解决这个问题, 提出了CMAB来增强通道特征提取能力。 CMAB由通道窗口注意力(channel window attention, CWA)模块和DwConv双分支以及空间交互模块(spatial interaction block, SIB)组成, 如图4(a)所示为其结构。
 | 图4 (a)CMAB结构; (b)SIB结构Fig.4 (a) CMAB structure; (b) SIB structure |
与SMAB不同的是, CMAB专注于高光谱图像的光谱特征表示, 增强了全局特征通道建模的能力, 而在空间维度上进行权重共享, 使得空间特征建模的能力受到限制。 因此, 设计了SIB来增强光谱窗口注意力在空间维度上的建模能力。 SIB由带有BN层和GELU激活层的两个1× 1逐点卷积组成。 经过两层逐点卷积将通道数降为1, 最后经过Sigmoid层生成空间注意力权重与窗口注意力中的Value(即下文Vc)进行逐元素相乘, 具体结构如图4(b)所示。
通道窗口注意力是指在各个窗口内独立进行通道注意力的计算。 具体来讲, 假设输入为F∈ RH× W× C, 通过线性映射将其映射为Qc, Kc, Vc, 具体过程如式(3)
式(3)中, WQ, WK, WV∈ RC× C均为线性映射。 同样将Qc, Kc, Vc划分为大小为Wh× Ww的不重叠的窗口, 并将特征通道划分为h个heads, 则每个窗口包含C/h个Token且每个Token的维度为dc=Wh× Ww, 再经过维度变换后得到划分窗口后的Qc, Kc, Vc∈
式(4)中, VSIB为SIB的输出。 同样, 将双分支输出在通道维度上进行拼接后线性映射, 实现卷积通路的局部特征与通道窗口注意力通路的全局特征的特征聚合。
由于自注意力机制本身在处理图像词符序列数据时无法对其位置信息进行编码, 因此需要位置编码来帮助模型理解图像的空间结构。 例如, VIT[11]采用了绝对编码的方式, 在图像嵌入时引入位置信息, 而Swin[8]则采用相对位置编码的方式计算每个词符与其他词符的相对位置关系, 从而在自注意力计算中引入位置信息。 尽管位置编码能够为输入序列引入位置信息, 但在处理多尺度的输入数据时, 位置编码需要进行插值以匹配不同分辨率的图像输入, 这也通常会导致模型精度下降。 为了解决这个问题, 本文参考PVTv2[12]在前馈网络中加入带有零填充的3× 3卷积来代替固定尺寸的位置编码方式。
具体来讲, 将融合后的特征Fin输入到带有深度卷积层的前馈网络层中, 得到输出Fout, 具体过程如式(5)
式(5)中, FC为全连接层, 第一个全连接层的维度放大系数为4, DwC为带有零填充的3× 3深度卷积。
使用采集得到的230张胃癌显微高光谱病理图像进行分割实验。 考虑到数据量较小, 为避免实验结果的随机性, 因此使用五折交叉验证的方式进行实验。 具体来讲, 将数据集按照采集编号划分为五堆, 每堆46张高光谱图像, 在每折实验中分别选取其中一堆作为验证集, 剩下四堆作为训练集, 每一折训练集中包含184张高光谱图像。
在实验硬件方面, 采用了16核的Intel Xeon Platinum 8350C CPU, 48G内存容量, GPU为显存为24G的RTX 3090。 在软件方面, 操作系统为Ubuntu 20.04.3 LTS, 深度学习框架为PyTorch 1.10.0, 图形计算加速架构CUDA 版本为11.3, 编程语言为Python 3.8.18。 另外使用mmSegmentation 1.1.1[13]图像分割框架为基础进行分割实验。
考虑到数据集的数据量较小, 在读取数据阶段进行数据增强操作, 使用随机0.5到2.0倍缩放并随机裁剪到320× 320的尺寸, 最后使用随机水平翻转。
主干网络模型共分为4个阶段, 图像块嵌入维度C为64, 每个阶段词符通道维度分别为64、 128、 320、 512, 每个阶段的MixDT模块数量分别为3、 4、 6、 3, 每个阶段的SWA、 CWA中使用的窗口的高度、 宽度均为7× 7, 多头数量分别为1、 2、 5、 8。 使用UperNet[14]作为解码头, 同时使用辅助分割解码头网络加速网络训练优化。 使用交叉熵损失函数, 其中解码头权重为1, 辅助解码头权重为0.4。 在训练时, 每个批次大小为4, 使用AdmaW作为优化器, 初始学习率为0.000 5, 使用参数为1.0的poly学习率衰减策略, 共训练100个轮次。 在测试阶段, 尽量使用whole模式输入尺寸为960× 960的数据进行模型评估, 对无法接受动态分辨率输入的模型采用slide模式, 将输入滑动裁剪至320× 320大小进行模型评估。
在图像分割任务中, 像素类别不平衡的问题会导致准确率无法正确评估模型在小类别样本上的表现, 因此本次图像分割任务使用平均Dice系数和平均交并比作为评价指标。
为了验证高光谱图像丰富的光谱信息对图像分割任务结果的提升效果, 设计一组与伪RGB图像的对比实验。 使用高光谱图像第150、 74、 21三波段合成伪RGB图像, 并使用同样的配置在MBDT模型上进行实验, 输入通道改为3。 高光谱图像与伪RGB图像实验结果如图5所示, 表1为高光谱图像与伪RGB图像的分割实验评价指标。 可以看到, 在利用高光谱图像进行图像分割能得到比伪RGB图像更好的结果。 因此可以得出, 相较于伪RGB图像, 显微高光谱病理图像中丰富的光谱信息能够使得模型提取到更多的特征, 从而得到更好的分割效果。
 | 图5 高光谱图像与伪RGB图像对比实验结果 (a): 彩色图像; (b): 真实标签; (c): 伪RGB图像实验结果; (d): 高光谱图像实验结果Fig.5 Experimental results of the comparison between hyperspectral images and fake-RGB images (a): Color image; (b): Real label; (c): Experimental result of fake-RGB image; (d): Experimental result of hyperspectral image |
| 表1 高光谱图像与伪RGB图像对比实验结果 Table 1 Experimental results of the comparison between hyperspectral images and fake-RGB images |
为了验证本文提出的网络结构的效果, 设计了一系列消融实验, 除了需要验证的结构设计之外其余实验参数保持一致。
4.2.1 两种混合注意力模块
为了验证本文提出的两种混合注意力模块SMAB和CMAB对实验结果的影响, 设计了一组实验, 实验结果如表2所示。 其中, 表中第一行和第二行分别代表去除SMAB和CMAB后的模型实验结果, 第三行代表两种混合注意力模块均存在的模型实验结果, 其余实验参数和模型结构均保持一致。 比较三个实验结果可以看到, SMAB和CMAB两者均存在的模型分割结果表现的最好, 表明本文提出的两种混合注意力模块能够对高光谱图像的空间信息和光谱信息进行建模以提升图像分割性能。 除此之外, 相较于只有CMAB的模型, 只有SMAB的模型实验结果表现更好, 这也表明了空间信息在高光谱图像分割任务中起到更重要的作用。
| 表2 混合注意力模块消融实验 Table 2 Ablation experiments of the mixing attention module |
4.2.2 卷积与交互结构
为了验证卷积以及两种交互模块在MDBT模型中的作用, 设计了一组实验, 实验结果如表3所示。 其中, 表中第一行是没有卷积分支以及交互结构的模型实验结果, 第二到四行分别是加入卷积分支以及分别加入SIB和CIB后的模型实验结果, 最后一行为完整模型实验结果。 比较实验结果可以看到, 缺少卷积分支的模型实验结果表现要差于存在卷积分支的模型, 这表明了卷积分支的引入提升了MDBT模型高光谱图像分割的效果。
| 表3 卷积与交互结构消融实验 Table 3 Ablation experiments of the convolutional and interaction structures |
4.2.3 带有卷积的前馈网络
为了验证带有零填充的卷积是否为词符引入位置信息从而使模型性能得到提升, 本文设计了一组实验, 实验结果如表4所示。 其中表中第一行代表前馈网络不包含深度卷积层的模型实验结果, 第二行代表在前馈网络中加入深度卷积层的模型实验结果。 从表中实验结果可以看出, 深度卷积的加入使得模型的性能得到提升, 这也证明了带有零填充的深度卷积能够为注意力的计算引入位置信息, 从而使得模型表现得到提升。
| 表4 卷积前馈网络消融实验 Table 4 Ablation experiments of the convolutional feed-forward network |
为了评估本文提出的MDBT模型对胃癌显微高光谱病理图像的分割表现, 将该模型与其他7个模型: ResNet-50[15]、 UNet[16]、 ViT[11]、 PVT[12]、 Swin[8]、 Twins[17]、 Segformer[18]进行对比试验。 除UNet和Segformer之外, 其余模型均作为特征提取主干网络, 使用UperNet作为解码头进行分割实验。 如图6所示为本文MDBT模型与其他算法在胃癌高光谱显微病理图像上进行分割实验的结果。 可以看到, 本文MDBT模型将绝大部分癌变区域都准确预测出来, 并且相较于真实标签通过线段构成的癌变区域轮廓, 分割结果图像中对癌变区域轮廓预测的更符合癌变区域的边界曲线。 表5为8种模型的分割效果评价指标对比。 可以看到, 本文提出的模型的表现优于其余所有模型。
 | 图6 模型对比实验结果Fig.6 Comparative experimental results of the models |
| 表5 模型对比实验 Table 5 Comparative experimental results of the models |
提出了基于卷积和注意力机制的混合双分支Transformer主干网络对胃癌显微高光谱病理图像进行分割, 做了以下工作:
(1) 利用显微高光谱成像系统对胃癌病理组织切片进行高光谱图像采集, 并进行光谱校正等预处理, 构建胃癌高光谱显微病理图像数据集;
(2) 提出基于空间混合注意力和通道混合注意力的主干网络模型, 实现对高光谱图像中空间信息和光谱信息的特征提取, 有效提升模型性能;
(3) 提出卷积分支与交互结构, 解决窗口注意力机制信息无法跨窗口交互导致感受野受限的问题, 同时使得局部特征与全局特征得到融合, 进一步增强模型表征能力。
通过设计一系列消融实验和对比实验并分析结果, 证明了基于双分支的混合注意力模型能够对高光谱显微病理图像进行高效特征提取, 提升高光谱图像分割的准确性, 也表明高光谱成像技术能够为医学图像领域带来新的思路。 在未来的研究中, 为了更加充分的利用高光谱图像中的光谱信息需要将高光谱图像作为3D数据进行处理, 构建高光谱图像特征提取的3D模型。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|