





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
沃柑可溶性固形物含量高光谱检测模型的建立与优化
[李炜琪1  , 王一帆
, 王一帆1 , 俞越1 , 刘洁1, 2, 3, * ]
, 王一帆]
|
|


作者简介: 李炜琪,女, 1999年生,华中农业大学工学院硕士研究生 e-mail: 1939346545@qq.com
针对沃柑品质快速检测需求, 提出一种基于高光谱图像数据的沃柑可溶性固形物含量(SSC)检测方法, 并分析随贮藏时间变化的SSC伪彩色分布图。 分别获取307个整果样本和227个半果样本以及它们的SSC数据。 比较标准正态变换(SNV)、 多元散射校正(MSC)、 Savitzky-Golay(SG)滤波、 归一化(NM)、 一阶导数(FD)、 标准化(SD)和小波变换(WT)对偏最小二乘回归(PLSR)模型检测性能的影响以选择光谱预处理方法; 比较PLSR、 最小绝对值收缩与选择算子(LASSO)回归、 支持向量机回归(SVR)、 人工神经网络(ANN)、 决策树(DT)、 随机森林(RF)、 轻量级梯度提升机(LightGBM)模型对独立验证集的检测能力以确定最佳模型建立方法, 并利用遗传算法(GA)筛选特征波长以优化模型。 结果表明: 采用FD预处理结合LASSO回归算法所建模型对整果SSC检测效果最优, 验证集决定系数($R_{p}^{2}$)和验证集均方根误差(RMSEP)分别为0.925 7和0.976 5; SD预处理结合RF模型对半果SSC检测效果最好, 其$R_{p}^{2}$和RMSEP分别为0.896 3和1.063 0; GA能够滤除53.85%和50.58%的整果和半果波长变量数, 基于选择变量的整果和半果最优建模算法分别为SVR和RF, 其模型$R_{p}^{2}$、 RMSEP分别为0.918 9、 1.017 3和0.895 3、 1.084 3。 研究结果为沃柑SSC高通量无损检测提供了一种可行方案。
To develop a rapid measurement method of SSC in Fortunella margarita, the detection models based on hyperspectral imaging data were established and optimized by employing various preprocess and regression algorithms, and the pseudo-color distribution of SSC with storage time was analyzed. The 307 whole citrus and 227 hemisected citrus samples were involved in hyperspectral data collection and the SSC values. The effects of preprocessing, including standard normal variate (SNV), multiplicative scatter correction (MSC), Savitzky-Golay (SG) filtering, normalization (NM), first derivative (FD), standardization (SD), and wavelet transformation (WT), on the performance of the partial least squares regression (PLSR) model were compared to select the appropriate preprocessing method. Then, the detection models were established by using PLSR, least absolute shrinkage and selection operator (LASSO) regression, support vector machine regression (SVR), artificial neural networks (ANN), decision trees (DT), random forest (RF) and light gradient boosting machine (Light GBM) algorithms. Furthermore, the models were optimized using genetic algorithms (GA) to select characteristic spectral wavelengths. The results indicated that for the whole citrus samples, the FD preprocessing could extract more features, and the LASSO regression model performed better than other models with 0.925 7 and 0.976 5 as the prediction determination coefficient ($R_{p}^{2}$) and root mean square error of prediction (RMSEP), respectively. For the hemisected samples, the RF model based on the spectral after SD preprocessing had higher $R_{p}^{2}$ at 0.896 3 and lower RMSEP at 1.063 0. The GA could remove 53.85% and 50.58% wavelength variables to reduce the computational complexity for the whole and hemisected sample spectral, of which the SVR model has $R_{p}^{2}$ at 0.918 9. RMSEP at 1.017 3 RF model having $R_{p}^{2}$ at 0.895 3 and RMSEP at 1.084 3 performed better than other models. The results provided a feasible solution for high-throughput, non-destructive detection of SSC of Fortunella margarita.
沃柑(Fortunella margarita)是柑橘类中的大宗品种之一, 具有重要经济价值和食用价值[1]。 沃柑属晚熟杂柑品种, 其果实汁多味甜、 细嫩无渣、 营养价值高, 栽种面积逐年增加。 柑橘类果实的可溶性固形物含量(soluble solids content, SSC)是判断其品质的主要指标之一[2], 在采摘、 流通、 贮藏过程中, 检测沃柑SSC并评价其品质特性有利于优化采收流程、 减少果实腐败率、 最大化实现水果的商品价值。 快速无损检测沃柑SSC是提高分级效率、 提升产业效益的有效途径。
传统滴定法检测SSC对样本具有破坏性且耗时耗力, 光谱技术凭借其无损、 快速特性在水果内部品质检测领域中具有独特优势[3]。 高光谱以高分辨率光谱对物体连续成像, 获取整体的空间信息和光谱信息[4], 相较于近红外光谱的单点检测, 更适于非均质的农产品检测。 高光谱数据结合化学计量学方法建立水果样品的实际化学成分含量与其光谱的稳健联系, 能最大限度提取有用信息和增强模型的可解释性[5]。 现有研究能够证实利用高光谱信息检测水果品质的可行性, Ma等估算在高光谱漫反射下苹果的光穿透深度在1 198 nm处达到0.33 cm[6]。 Guantao等利用高光谱漫反射装置采集桃果实高光谱图像并提取其平均光谱, 建立多元线性回归模型对SSC和硬度检测的相对分析误差分别为2.510和2.401[7]。 Ma等利用带旋转平台的高光谱系统获取整个猕猴桃图像, 并建立其SSC和pH值的偏最小二乘模型, 其交叉验证决定系数分别为0.74和0.64[8]。 Sontisuk等通过高光谱成像实现酸橙总可溶性固形物和可滴定酸含量检测与可视化[9]。 Zhang等基于高光谱透射成像系统获取全波长橙果光谱数据, 并利用偏最小二乘算法建立橙果SSC检测模型, 其预测集相关系数为0.885 4, 预测集均方根误差为0.484 6[10]。 Li等提出由4层卷积、 2层池化加1层全连接组成的一维卷积神经网络模型, 实现高光谱对小样本枇杷SSC定量检测, 其验证相关系数为0.904, 验证均方根误差为0.344%[11]。 高升等使用高光谱成像技术采集生长期红提数据, 并建立其总酸和硬度的偏最小二乘模型[12]。 张晨等利用竞争性自适应重加权采样(competitive adaptive reweighted sampling, CARS)算法筛选特征波长, 并结合集成学习模型实现蓝莓维生素C、 SSC和花青素等指标的综合检测[13]。 姜小刚等采用后向区间偏最小二乘法和CARS选择光谱变量以提高模型性能, 模型的预测均方根误差由全光谱的0.628 1分别降至0.598 4和0.581 0[14]。 杨宝华等基于堆栈自动编码器算法实现了鲜桃高光谱SSC检测[15]。 上述研究表明, 机器学习和深度学习在高光谱检测模型建立中的探索日益增多。
本工作以沃柑为对象, 针对鲜食和加工果品质检测需求, 分别获取整果和无表皮干扰的横剖半果高光谱图像数据。 比较标准正态变换(standard normal variate, SNV)、 多元散射校正(multiplicative scatter correction, MSC)、 Savitzky-Golay(SG)滤波、 归一化(normalization, NM)、 一阶导数(first derivative, FD)、 标准化(standardization, SD)和小波变换(wavelet transform, WT)等7种预处理方法对特征信息提取的影响, 借助遗传算法(genetic algorithm, GA)选择波长, 分别建立偏最小二乘回归(partial least square regression, PLSR)、 最小绝对值收缩与选择算子(least absolute shrinkage and selection operator, LASSO)回归、 支持向量机回归(support vector regression, SVR)、 人工神经网络(artificial neural networks, ANN)、 决策树(decision tree, DT)、 随机森林(random forest, RF)和轻量级梯度提升机(light gradient boosting machine, LightGBM)模型, 以分析整果和半果光谱信号特点, 建立基于高光谱的沃柑整果和半果SSC快速检测方法。
分别在11月沃柑早熟期和次年6月留树晚期选择果形完好、 无虫害损伤的广西武鸣沃柑果实共计307个, 拭除表面灰尘并编号, 利用天平和游标卡尺逐一测量质量、 横径和纵径后用于光谱数据采集。
样本光谱数据借助Zolix Hyper SIS-VNIR-CL型高光谱漫反射成像系统(Spectral Imaging Ltd, Finland)获取, 参数设置如表1所示。
| 表1 高光谱成像系统参数设置 Table 1 Parameters of hyperspectral imaging system |
采集黑白板光谱数据并利用系统自带软件进行黑白校正以保障光谱数据准确性。 校正公式如式(1)
式(1)中, I为图像反射强度, Id为采集的暗光谱反射强度, Iw为白板反射强度, Iref为校正后图像反射率。
整果样本果蒂朝上放置于样品池内获取其漫反射图像; 之后沿果实赤道处横剖, 将剖切面平行于相机平面放置后获取其漫反射图像。 受果实切面平整度影响, 获得有效半果样本227个。 光谱数据经校正后按样品编号命名并保存文件。
高光谱图像采集后, 按NY/T2637— 2014《水果和蔬菜可溶性固形物含量的测定 折射仪法》测定SSC。 整果样本取光谱采集处果皮下非相邻部位果肉2~3份, 半果样本沿赤道平面等距取2~3瓣非相邻部位果肉, 手动榨汁混合均匀后用一次性滴管吸取2 mL混合液滴于PAL-1型折光仪(ATAGO, Japan)的台面上, 取三次测量平均值记为该样本的SSC值。
考虑到果实橘瓣间SSC值有差异, 故在样本图像中选择四个感兴趣区域(region of interest, ROI)进行分析, 如图1所示。 使用ENVl 4.6软件计算ROI在390~1 043 nm波长范围内的平均光谱作为该样本光谱。
 | 图1 整果(a)和半果(b)样本的高光谱图像和ROI选取Fig.1 Hyperspectral image and ROI of (a) whole citrus and (b) hemisected citrus |
原始光谱受环境杂散光、 噪声等因素影响, 预处理是优化光谱数据的有效手段。 通过单一预处理方法从光谱中提取与沃柑SSC相关信息, 建立PLSR模型并对比模型决定系数和均方根误差确定合适预处理方法, 模型主因子数由网格搜索以五折交叉验证的最低均方根误差为依据获取。 选择SNV、 MSC、 SG滤波、 NM、 FD、 SD和WT等方法分别对数据做预处理以提高信噪比。 其中, SG滤波可有效减少系统噪声, WT可去除高频噪声信号; FD可实现基线校正; SNV和MSC主要用于处理光散射问题[5]; NM和SD属于特征缩放算法用以消除量纲差异; SD算法还可不受数据中个别极大极小值影响。 分别利用不同方法预处理后的整果和半果光谱数据建立SSC的偏最小二乘模型, 比较模型检测能力以确定适用于沃柑SSC检测的预处理方法。
1.5.1 样本划分方法
选择光谱-理化值共生距离法(sample set partitioning based on joint x-y distance, SPXY)以3∶ 1划分样本集。 该算法综合考虑样本理化值及其光谱空间分布[7], 能够基于样本在目标变量空间和特征空间分布情况进行样本集划分, 以保障其代表性和多样性。
1.5.2 模型建立方法
为比较不同建模方法检测能力, 选取经典PLSR、 LASSO回归、 3种机器学习和2种集成学习算法建立回归模型, 其中PLSR是光谱建模中最常用的定量分析模型, 应用最广泛[3], 模型具有较好稳健性。 LASSO算法在回归系数绝对值小于给定常数条件下, 将某些回归系数缩小到零来减少变量[16], 因此可降低模型复杂度、 防止过拟合。 SVR可利用核函数将输入映射到高维空间中用以处理非线性回归问题, 对光谱类高维数据有较好处理能力[11]。 ANN是常见的前馈神经网络, 由输入层、 隐藏层、 输出层以全连接形式组成, 具有较好非线性处理能力, 但其模型参数量较多、 数据处理效率低[17]。 DT通过划分类别并逐层推进形成树状结构, 处理效率高, 但容易出现误差累积问题使得某节点错误延续到后续节点[18]。 集成学习有利于处理复杂变量、 降低过拟合风险, 常见的集成学习方法包括RF和LightGBM。 RF是以多棵树模型整合形成的集成学习算法, 引入随机性防止模型过拟合, 回归模型结果通过求平均方式得出。 LightGBM算法采用分布式梯度提升框架集成多棵树模型, 引入直方图对特征离散化并利用优先生长信息增益大节点的策略加快训练速度, 在拟合精度和响应时间上得到很大提升[19]。
上述数据处理及建模分析均利用python3编写代码, 所用编辑器及开发环境为PyCharm2022。
1.5.3 特征波长选择
鉴于全波段光谱数据维数高, 使用特征波长选择方法可有效降低冗余和消除共线性, 以提高模型预测能力并减少计算量。 GA通过选择、 交叉和变异算子不断迭代搜索逼近最优解, 从而得到最优波长组合, 是常用特征波长选择方法。 利用该方法对预处理后光谱数据进行特征波长筛选, 用于优化检测模型。
以模型校正集决定系数(
式(2)— 式(6)中:
307个整果样本单果质量、 横径、 纵径的平均值分别为83.48 g、 55.53 cm和46.44 cm, SSC最大值、 最小值、 均值和标准差分别为20.9、 8.5、 13.30和3.67° Brix; 227个半果样本SSC最大值、 最小值、 均值和标准差分别为20.9、 8.1、 13.90和3.64° Brix。
利用SPXY法按3∶ 1划分为校正集和验证集, 各统计参数如表2所示。 其中整果校正集样本230个、 验证集样本77个, SSC平均值分别为13.14、 13.77° Brix; 半果校正集样本170个、 验证集样本57个, SSC平均值分别为13.18、 16.03° Brix。 可见, 两类数据经SPXY算法选取的校正集取值范围和标准差均大于验证集取值范围和标准差; SSC值较小的样本多分布于校正集, 使校正集均值低于验证集均值。
| 表2 SPXY算法划分后沃柑SSC参数统计 Table 2 Statistics of SSC of citrus divided by SPXY algorithm |
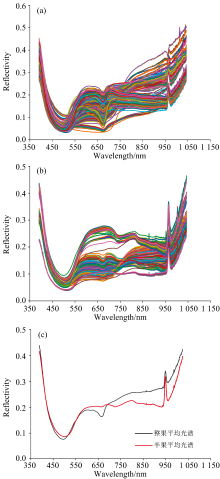
由ROI计算的平均光谱如图2(a)、 (b)所示, 图2(a)显示整果光谱反射率在可见光波段下降, 而近红外波段反射值呈上升态势, 与Cayuela等的研究结果相同[20]。 图2(b)显示半果光谱在390~530 nm波段范围谱线出现下降趋势, 530~640 nm谱线上升后保持平稳, 在670和730 nm出现小波动, 直至970 nm左右出现明显的尖峰后反射率继续增加。 从单个光谱曲线来看其变化趋势基本一致, 在530 nm附近出现吸收峰, 与类胡萝卜素吸收波段相对应[21]; 在670和970 nm出现波谷、 波峰分别对应果肉、 果皮中的叶绿素吸收波段[3], 以及水和碳水化合物的O— H二级倍频吸收[7, 22]。 不同沃柑样本反射率强度有差异, 因此可建立反射值和SSC指标之间回归模型以检测SSC。
 | 图2 (a)整果原始光谱图; (b)半果原始光谱图; (c)整果和半果平均光谱Fig.2 (a) Original spectra of whole citrus; (b) Original spectra of hemisected citrus; (c) Average spectra of whole citrus and hemisected citrus |
图2(c)为307个整果样本和227个半果样本平均光谱图。 530 nm附近波谷段和970 nm附近波峰段在两者平均光谱中均有出现, 且半果平均光谱的970 nm峰值变化幅度大于整果平均光谱在此处的变化幅度, 可能与沃柑中水分等物质有关。 在600~900 nm光谱范围内半果光谱相比于整果光谱曲线更平稳、 波动小, 且整果光谱在670 nm处反射率变化并未在半果光谱中出现, 说明在半果光谱中缺失沃柑表皮相关信息, 如叶绿素等。
分别利用经SNV、 MSC、 SG滤波、 NM、 FD、 SD和WT处理后的整果光谱数据建立PLSR模型, 结果列于表3。 相较于原始光谱直接建模, 预处理光谱所建模型的校正集和验证集性能参数均有改善。 其中, FD预处理模型检测结果最优, 其
| 表3 基于不同预处理整果光谱的SSC检测PLSR模型参数 Table 3 The parameters of the PLSR models for SSC measurement based on the spectra of whole citrus with different preprocessing methods |
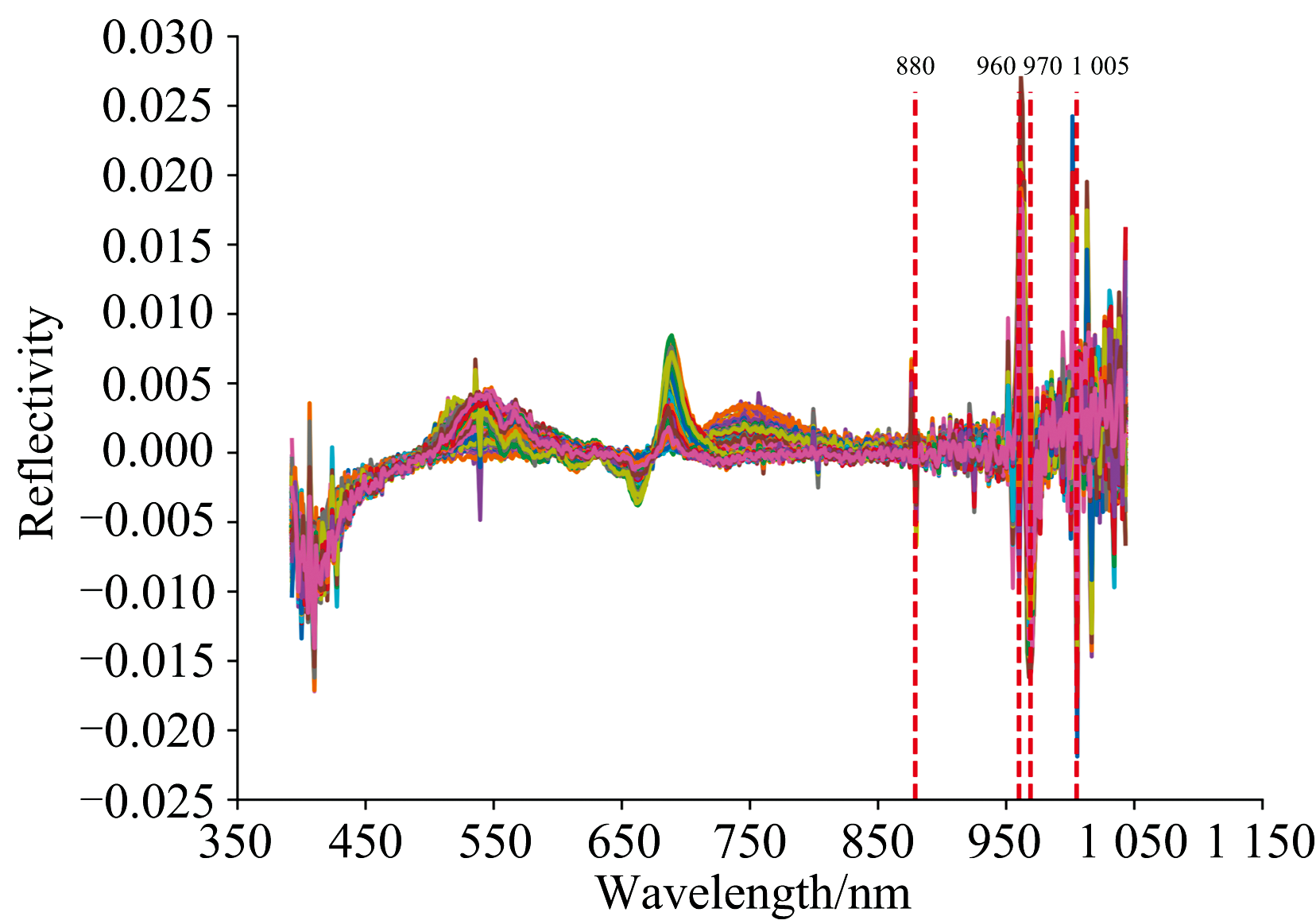 | 图3 FD预处理后整果样本光谱Fig.3 Spectra of whole citrus preprocessed by first derivative |
半果光谱数据经上述预处理后分别建立PLSR模型, 结果列于表4。 由表中数据可见, SG滤波、 SD、 FD、 WT相比于原始光谱在验证集的建模效果上均有提升, SD预处理后模型
| 表4 基于不同预处理半果光谱的SSC检测PLSR建模效果 Table 4 Modeling results of PLSR models for SSC based on the spectral data of hemisected citrus with different preprocessing methods |
 | 图4 SD预处理后半果样本光谱Fig.4 Spectra of hemisected citrus preprocessed by SD |
结合表3、 表4看出, 针对半果光谱建立的沃柑SSC预测模型精度低于整果光谱模型精度, 原因可能是柑橘的剖切面存在水分, 在漫反射检测模式下易导致反射值减弱[23]。
上述结果表明, 预处理能够提升沃柑整果和半果光谱中SSC特征信息提取效果。 整果和半果光谱的最佳预处理方法分别是FD和SD, 说明光谱特性有区别, 其原因可能与果皮对光谱的吸收和散射有关。
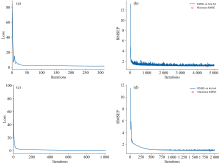
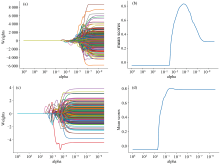
分别利用FD预处理后的沃柑整果光谱和SD预处理后的半果光谱建立基于PLSR、 LASSO回归、 SVR、 ANN、 DT、 RF和LightGBM算法的SSC检测模型。 其中, ANN模型设置为单隐含层、 神经元个数为200个, 并以最佳预处理后光谱为输入、 以SSC预测值为输出, 模型的迭代曲线分别见图5(a)、 (b)、 (c)、 (d)所示, 随着迭代次数增加整果和半果SSC检测模型损失值及RMSEP均减小并趋于稳定, 因此可确定整果ANN模型迭代次数为4700、 半果ANN模型迭代次数为1 900为最优。 基于LASSO回归alpha学习曲线图为图6(a)、 (b)、 (c)、 (d), 可确定整、 半果LASSO回归模型最佳正则化参数取值分别为10-5、 10-4。 其余建模算法参数根据RMSECV最低为准进行选取, 整果和半果检测模型性能参数分别列于表5和表6。
 | 图5 整果和半果ANN模型的损失函数(a, c)和RMSEP(b, d)Fig.5 Loss functions and RMSEP vs iteration of ANN models for whole citrus (a, c) and hemisected citrus (b, d) |
 | 图6 整果和半果LASSO模型的权重(a, c)和交叉验证平均得分(b, d)随alpha的变化Fig.6 Weights and mean scores vs alpha of LASSO models for whole citrus (a, c), and hemisected citrus (b, d) |
| 表5 整果SSC不同算法建模结果 Table 5 Modeling results for SSC in whole citrus using different algorithms |
| 表6 半果SSC不同算法建模结果 Table 6 Modeling results for SSC in hemisected citrus using different algorithms |
对于整果光谱, RF、 SVR和LASSO回归模型预测性能比PLSR模型均有提升, 其中, LASSO回归模型
 | 图7 整果LASSO模型SSC预测结果Fig.7 Scatter plot of measured vs predicted SSC values in whole citrus using LASSO model |
对于半果光谱, RF、 SVR和ANN模型预测性能均优于PLSR方法, 其中, RF预测结果最佳(
 | 图8 半果RF模型SSC预测结果Fig.8 Scatted plot of measured vs predicted SSC values in hemisected citrus using RF model |
结果表明整果和半果具有不同的最优建模方法, LASSO回归算法对沃柑整果SSC的预测性能提升效果最好, RF算法对沃柑半果SSC预测效果最好。
利用所建沃柑整果SSC检测最佳模型, 分析不同贮藏时长沃柑高光谱图像每个像素点的光谱数据, 结合颜色映射和动态颜色调整得到沃柑SSC随贮藏时长变化的可视化分布。 如图9所示, 从左至右为贮藏时长依次增加的样本SSC伪彩色分布图, 图9(a)和图9(b)分别为成熟早期样本和成熟晚期样本; 蓝色表示较低SSC值, 而红色表示较高SSC值。 可见随贮藏时长增加, 两类样本SSC值均有升高趋势, 且在果实内部出现SSC相对集中分布的现象; 成熟早期样本SSC值明显低于成熟晚期样本SSC值, 这与柑橘类果实的后熟特性相符, 说明模型可用于沃柑SSC含量检测和货架期优化等场合。
 | 图9 (a): 不同贮藏时长的成熟早期沃柑样本SSC伪彩色分布图; (b): 不同贮藏时长的成熟晚期沃柑样本SSC伪彩色分布图Fig.9 (a): Pseudo-color distribution maps of SSC in early maturity Fortunella margarita in a storage period; (b): Pseudo-color distribution maps of SSC in late maturity Fortunella margarita in a storage period |
利用GA对全波段模型进行特征波长选择以优化模型。 设置种群规模为30、 最大迭代次数为100、 交叉率为0.5、 变异率为0.01。 GA优化后整果光谱和半果光谱通道数分别从520个下降为240个和257个, 减少53.85%和50.58%。
比较全波段光谱各算法模型检测能力后, 选择PLSR、 RF、 SVR和LASSO回归算法分别建立基于整果特征波段的SSC检测模型, 分别利用PLSR、 RF、 SVR和ANN算法建立基于半果特征波段的SSC检测模型, 模型性能参数列于表7。 由表7数据, 对于整果光谱, 基于特征波长的PLSR、 RF和SVR模型
| 表7 基于特征波长的整果和半果SSC建模结果 Table 7 Modeling results for SSC in whole citrus and hemisected citrus based on selected wavelengths |
针对沃柑SSC检测需求和变化特点, 采集整、 半果高光谱图像和SSC数据。 由ROI求得平均光谱, 可知沃柑整果光谱和半果光谱的波形和特征峰有差异。 分别利用不同预处理后的光谱建立PLSR检测模型, FD对整果光谱预处理效果最好, SD对半果光谱预处理效果最好。 利用PLSR、 LASSO回归、 SVR、 ANN、 DT、 RF和LightGBM共7种算法建立SSC检测模型, 结果表明, FD预处理结合LASSO回归算法所建整果模型预测性能最佳, 其
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|